什么是机器学习?
利用数学中的公式,总结出数据中的规律
机器学习的步骤:
1.收集数据 (数据量越大,最终训练的结果越正确)
2.建立数学模型训练 (针对不同的数据类型需要选择不同的数学模型)
3.预测(预测数据)
KNN算法介绍
全称(K-Nearest Neighbors),通过寻找k个距离最近的数据,来确定当前数据值的大小或类别,是机器学习中最为简单和经典的一个算法
距离计算公式

其实,欧式距离其实就是点到点之间的距离,除了这两种,还有其他很多距离计算公式
KNN算法--sklearn
sklearn是基于python语言的第三方机器学习库。它建立在Numpy,SciPy,Pandas和Matplotlib库之上,里面的API设计的非常好,适合新手上路
安装方法就是pip install
scikit-learn库提供了KNeighborsClassifier(分类)和KNeighborsRegressor(回归)两个类,主要参数包括:
n_neighbors:K值,默认5。weights:邻居权重,可选uniform(均等权重)或distance(按距离反比加权)。metric:距离度量方式,如欧式距离(euclidean)、曼哈顿距离(manhattan)
KNN算法的实例
1.鸢尾花的分类
python
import pandas as pd
train_data=pd.read_excel(r"E:\xwechat_files\wxid_qi43v1w2nqcb12_e432\msg\file\2025-12\鸢尾花训练数据.xlsx")
test_data=pd.read_excel(r"E:\xwechat_files\wxid_qi43v1w2nqcb12_e432\msg\file\2025-12\鸢尾花测试数据.xlsx")
train_X=train_data[['萼片长(cm)','萼片宽(cm)','花瓣长(cm)','花瓣宽(cm)']]
train_Y=train_data[['类型_num']]
from sklearn.preprocessing import scale#对输入的数据
data_tra= pd.DataFrame()#空的表格数据对象
data_tra['萼片长标准化']= scale(train_X['萼片长(cm)'])
data_tra['萼片宽标准化']= scale(train_X['萼片宽(cm)'])
data_tra['花瓣长标准化']= scale(train_X['花瓣长(cm)'])
data_tra['花瓣宽标准化']= scale(train_X['花瓣宽(cm)'])
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors =11)
knn.fit(train_X,train_Y)
train_pre=knn.predict(train_X)
score=knn.score(train_X,train_Y)
print(score)
test_X=test_data[['萼片长(cm)','萼片宽(cm)','花瓣长(cm)','花瓣宽(cm)']]
test_Y=test_data[['类型_num']]
data_tes= pd.DataFrame()
data_tes= pd.DataFrame()#空的表格数据对象
data_tes['萼片长标准化']= scale(test_X['萼片长(cm)'])
data_tes['萼片宽标准化']= scale(test_X['萼片宽(cm)'])
data_tes['花瓣长标准化']= scale(test_X['花瓣长(cm)'])
data_tes['花瓣宽标准化']= scale(test_X['花瓣宽(cm)'])
score=knn.score(test_X,test_Y)
print(score)代码执行结果为:0.9545454545454546
0.8888888888888888
2.寝室分类问题
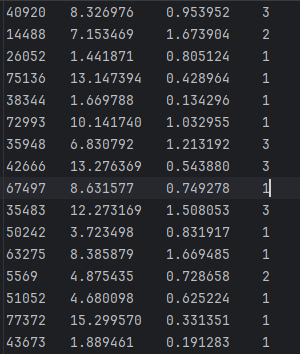
(每年旅游公里数,每天零食消耗量,每天游戏时长)和成绩好坏的对应关系
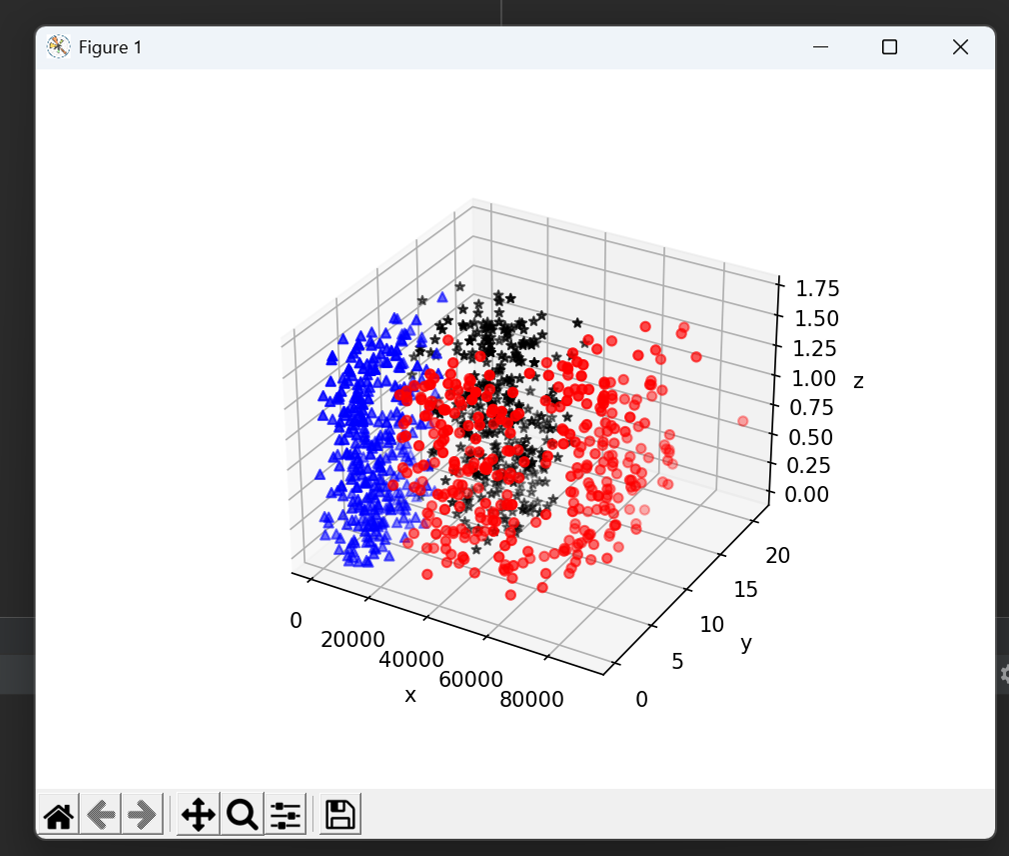
可将上述数据做成一个可视化的三维散点图
python
import matplotlib.pyplot as plt
import numpy as np
data= np.loadtxt(r"E:\学习\datingTestSet2.txt",delimiter='\t')
data_1=data[data[:,-1]==1]
data_2=data[data[:,-1]==2]
data_3=data[data[:,-1]==3]
fig = plt.figure()
ax= plt.axes(projection="3d") #图像轴为维。
ax.scatter(data_1[:,0], data_1[:,1],zs=data_1[:,2], c="red", marker="o")
ax.scatter(data_2[:,0], data_2[:,1],zs=data_2[:,2], c="blue", marker="^")
ax.scatter(data_3[:,0], data_3[:,1],zs=data_3[:,2], c="black", marker="*")
ax.set(xlabel='x',ylabel='y',zlabel='z')
plt.show()结果如下图所示:
对数据进行分类
python
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
data= np.loadtxt(r"E:\学习\datingTestSet2.txt",delimiter='\t')
X=data[:,:-1]
Y=data[:,-1]
neigh =KNeighborsClassifier(n_neighbors =3)
neigh.fit(X,Y)
print(neigh.predict([[19739,2.816960,1.686219]]))结果为:2.,实现了对数据的分类
KNN算法的优缺点
KNN算法的优点
简单易理解
KNN算法原理直观,无需复杂数学推导,适合初学者理解。分类或回归仅依赖邻近样本的投票或平均值,逻辑清晰。
无需训练阶段
KNN是惰性学习(lazy learning)的代表,模型不进行显式训练,仅存储样本数据。新增数据可直接参与预测,适合数据频繁更新的场景。
适应非线性数据
由于基于局部相似性计算,KNN能自然处理非线性分布的数据,无需像线性模型那样依赖特征变换。
参数调节灵活
核心参数仅有邻居数k和距离度量方式。通过调整k可平衡噪声敏感度与模型偏差,距离度量(如欧氏、曼哈顿)可根据数据特性选择。
多分类支持
天然支持多分类问题,无需像某些二分类算法需扩展处理(如OvR策略)。
KNN算法的缺点
计算复杂度高
预测时需计算待测样本与所有训练样本的距离,时间复杂度为O(nd)(n为样本数,d为维度)。大数据集下效率低下,需借助KD树等优化结构。
维度灾难敏感
高维数据中,样本间距离趋于相似,导致区分度下降。特征选择或降维(如PCA)常为必要预处理步骤。
类别不平衡问题
多数类样本可能主导邻近投票,导致少数类被忽略。可通过加权投票(如距离倒数权重)或过采样缓解。
噪声与冗余特征影响
噪声点或无关特征会扭曲距离计算。需结合特征缩放(如归一化)和特征选择提升鲁棒性。
内存消耗大
需存储全部训练数据,内存占用随样本量线性增长,不适合资源受限场景。
k值选择依赖经验
k过小易过拟合噪声,k过大会模糊决策边界。常用交叉验证或网格搜索确定最佳k,但增加计算成本。