TL;DR
- 场景:基于 Elasticsearch 7.3.0,用 Java/Rest High Level Client 完成索引与文档的全套 CRUD。
- 结论:通过 Maven 依赖、Client 初始化、索引与文档操作示例,可以快速跑通一个可用的 ES Demo 工程。
- 产出:一套可复制的工程骨架 + 索引/文档增删改查代码片段 + 常见坑位速查表。
版本矩阵
| 组件/版本 | 已验证 | 说明 |
|---|---|---|
| Elasticsearch Server 7.3.0 | 是 | 文章代码示例基于 ES 7.3.0 版本测试通过 |
| Elasticsearch Rest High Level Client 7.3.0 | 是 | 与服务端版本匹配,用于索引与文档 CRUD |
| Elasticsearch Core 7.3.0 | 是 | 通过 Maven 显式引入,与 Client 同版本 |
| Java 17 | 是 | Maven 配置 maven.compiler.source/target=17 实测可编译运行 |
| IK 分词器(ik_max_word) | 是 | 用于 description 字段分词,需在 ES 中预先安装插件 |
| Elasticsearch 6.x | 否 | 未在本文工程中验证,API 存在差异,需按官方文档调整 |
| Elasticsearch 8.x+ | 否 | High Level Client 已被新客户端替代,代码需迁移 |
| JUnit 4.12 | 是 | 使用 @Before/@After/@Test 组织用例 |
| TestNG 6.14.3 | 否 | POM 已引入,但示例中未使用 |
| log4j-core 2.11.1 | 部分 | log4j2.xml 可正常输出日志,未覆盖复杂日志场景 |
索引操作
-
创建索引:创建索引是存储数据的第一步。在 Elasticsearch 中,索引相当于关系数据库中的表。创建索引时,你可以指定映射(Mapping),定义字段类型(如 text、keyword、date、geo_point 等)。可以通过 Java API 传递索引设置(Settings)和映射来灵活定义索引的结构。
-
获取索引信息:通过 Java API 可以获取现有索引的详细信息,例如索引的元数据、字段映射、分片数量、副本数量等。这有助于用户分析和优化索引的性能。
-
索引存在性检查:在执行某些操作之前,检查索引是否存在是常见需求。例如,在插入数据前确保索引已经创建,或在删除索引之前确认它的存在性。
-
删除索引:删除不再需要的索引可以节省磁盘空间。需要小心的是,删除索引会清除该索引中的所有数据,操作不可逆,因此通常建议在执行此操作前进行备份。
-
更新索引设置:当集群扩展或数据增长时,你可能需要动态调整索引的分片数量或副本数量。Java API 提供了修改索引设置的功能,可以对现有索引进行优化调整。
文档操作
-
插入文档:文档是 Elasticsearch 中的最小数据存储单元,类似于关系数据库中的行。每个文档以 JSON 格式存储在索引中。通过 Java API,可以向特定索引插入单个文档,并指定文档的 ID(如果不指定,Elasticsearch 会自动生成一个 ID)。
-
获取文档:Java API 可以根据文档 ID 从索引中获取单个文档,返回的结果会包含文档的元数据信息,如 _id、_index、_version 等。获取文档操作通常用于精确查询和显示某个特定数据。
-
更新文档:更新文档时,Elasticsearch 并不会直接修改原始文档,而是通过创建一个新版本的文档来完成。Java API 支持部分更新(Partial Update),即只更新文档中的某些字段,而不必重新提交整个文档。
-
删除文档:删除文档同样基于文档 ID 进行操作。如果文档需要从集群中移除,可以通过 Java API 进行删除操作。此外,删除文档时也可以基于查询条件进行批量删除。
-
批量操作:在处理大量文档时,批量操作(Bulk API)非常重要。Java API 提供了批量插入、更新、删除文档的功能,可以提高大规模数据处理的效率。批量操作通常应用于数据迁移、批量更新、或者从其他系统同步数据到 Elasticsearch。
文件工程
IDEA新建Maven工程,开始对Elasticsearch的学习。 由于重复度很高,这里就跳过了,大家自行创建即可。
导入依赖
xml
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.3.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.3.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
</dependencies>配置文件
我们要在Resource目录下,新建 log4j2.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-mm-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" />
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>创建Client
java
package icu.wzk;
public class ElasticsearchTest {
RestHighLevelClient client;
@Before
public void init() throws Exception {
RestClientBuilder builder = RestClient.builder(
new HttpHost("h121.wzk.icu", 9200, "http"),
new HttpHost("h122.wzk.icu", 9200, "http"),
new HttpHost("h123.wzk.icu", 9200, "http")
);
final RestHighLevelClient highLevelClient = new RestHighLevelClient(builder);
System.out.println(highLevelClient.cluster().toString());
client = highLevelClient;
}
@After
public void destroy() throws IOException {
if (null != client) {
client.close();
}
}
}索引操作
创建索引
JSON方式
java
@Test
public void createIndex() throws Exception {
final CreateIndexRequest indexRequest = new CreateIndexRequest("wzk-icu-es-test");
// mapping 信息
// mapping 信息
String mapping = "{\n" +
" \"settings\": {},\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"description\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"pic\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": false\n" +
" },\n" +
" \"studymodel\": {\n" +
" \"type\": \"text\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
indexRequest.source(mapping, XContentType.JSON);
// 创建索引
CreateIndexResponse indexResponse = client.indices().create(indexRequest, RequestOptions.DEFAULT);
boolean acknowledged = indexResponse.isAcknowledged();
System.out.println("创建结果: " + acknowledged);
}执行结果如下图所示,创建成功! 
我们通过 Elasticsearch-Head 工具,可以看到如下的内容: 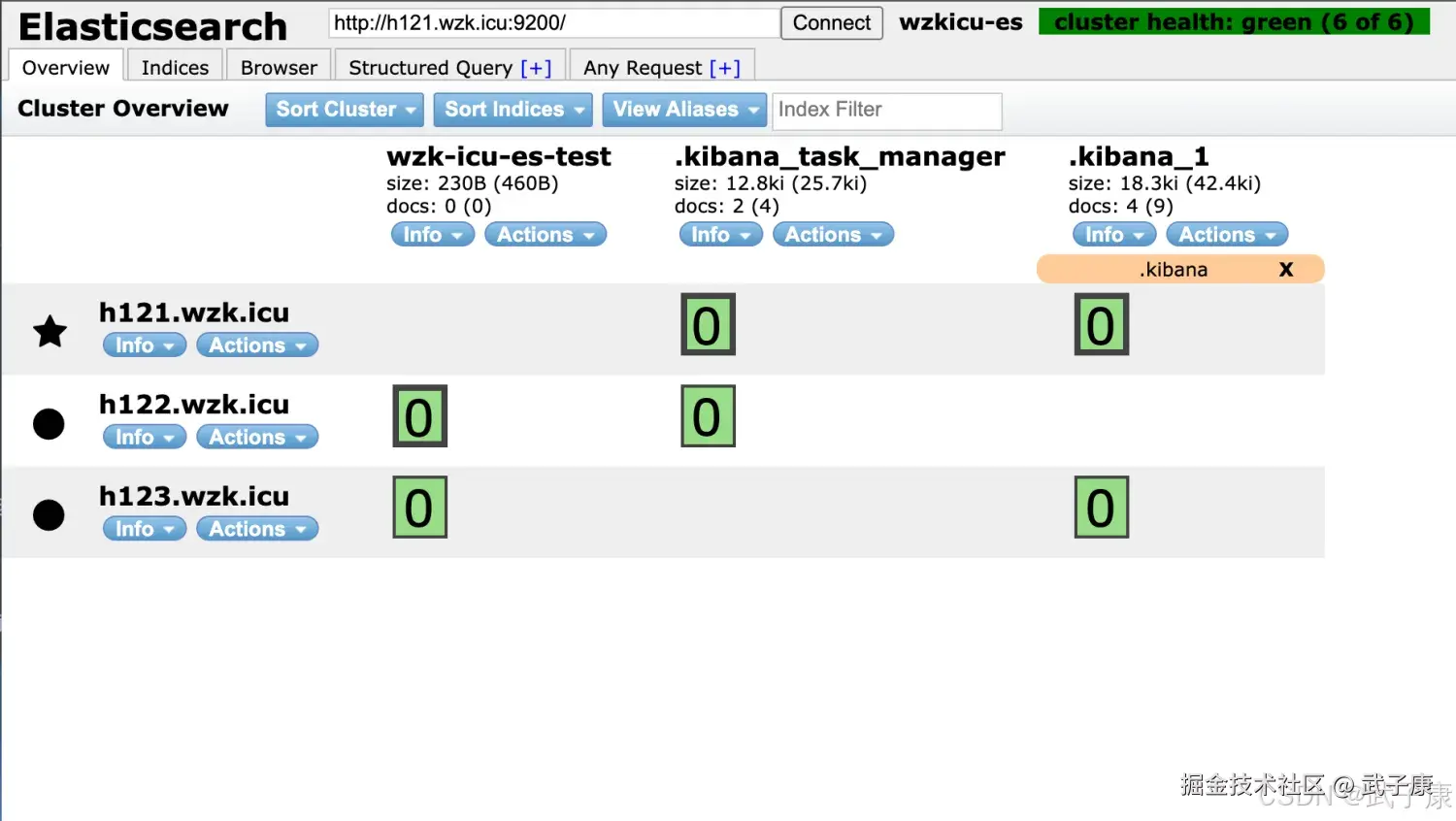
对象方式
java
@Test
public void createIndex2() throws Exception {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("wzk-icu-es-2");
createIndexRequest.settings(Settings
.builder()
.put("index.number_of_shards", 5)
.put("index.number_of_replicas", 1)
.build());
// 指定 mapping
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
xContentBuilder.startObject();
xContentBuilder.startObject("properties");
xContentBuilder.startObject("description")
.field("type", "text")
.field("analyzer", "ik_max_word")
.endObject();
xContentBuilder.startObject("name")
.field("type", "text")
.endObject();
xContentBuilder.startObject("pic")
.field("type", "text")
.field("index", "false")
.endObject();
xContentBuilder.startObject("studymodel")
.field("type", "text")
.endObject();
xContentBuilder.endObject();
xContentBuilder.endObject();
// mapping塞进去
createIndexRequest.mapping(xContentBuilder);
final CreateIndexResponse createIndexResponse = client
.indices()
.create(createIndexRequest, RequestOptions.DEFAULT);
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println("创建结果2: " + acknowledged);
}执行的结果的如下图所示: 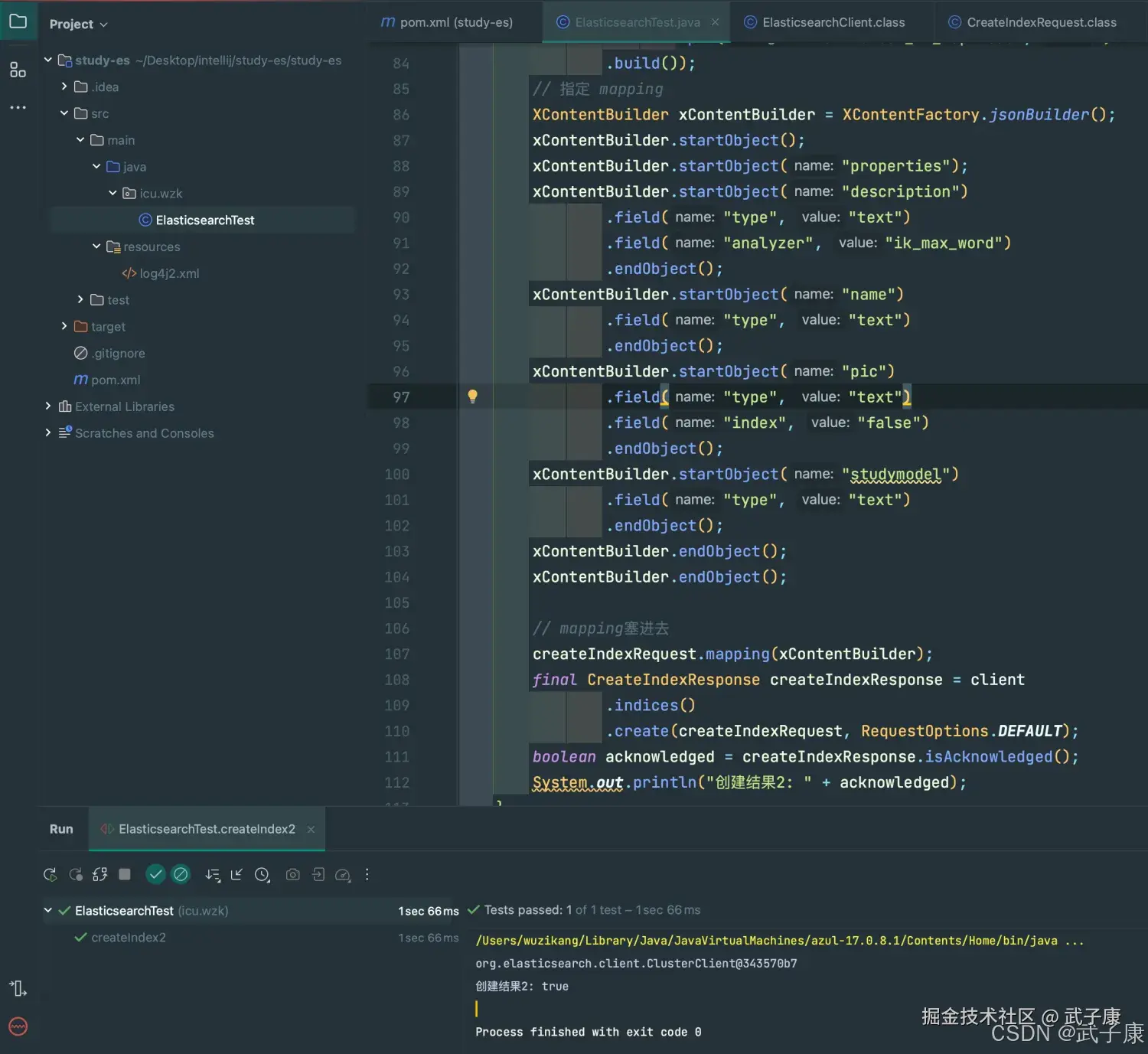 Elasticsearch-Head 查看,可以看到刚才创建的ES索引,分片的分布情况如下:
Elasticsearch-Head 查看,可以看到刚才创建的ES索引,分片的分布情况如下: 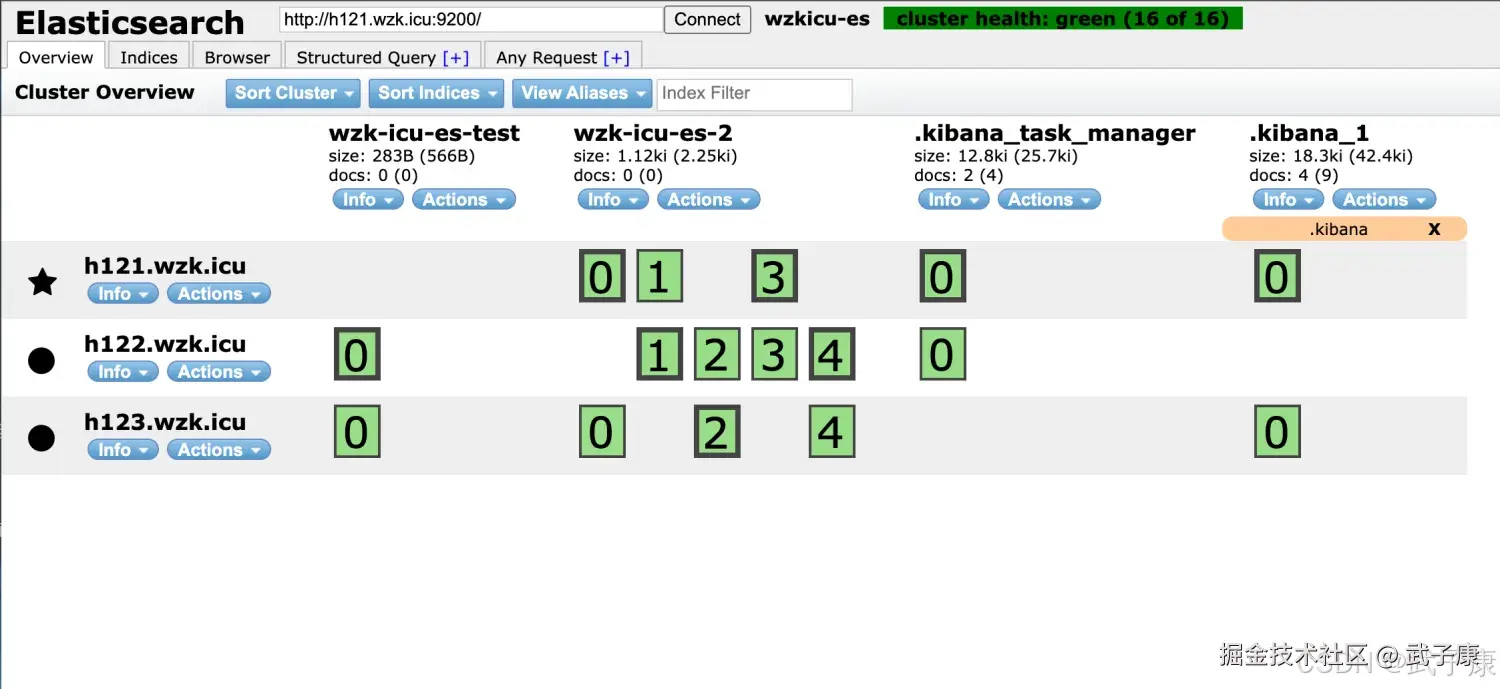
删除索引
java
@Test
public void deleteIndex() throws Exception {
DeleteIndexRequest deleteRequest = new DeleteIndexRequest("wzk-icu-es-test");
AcknowledgedResponse deleteResponse = client
.indices()
.delete(deleteRequest, RequestOptions.DEFAULT);
boolean acknowledged = deleteResponse.isAcknowledged();
System.out.println("删除索引: " + acknowledged);
}执行结果如下图所示: 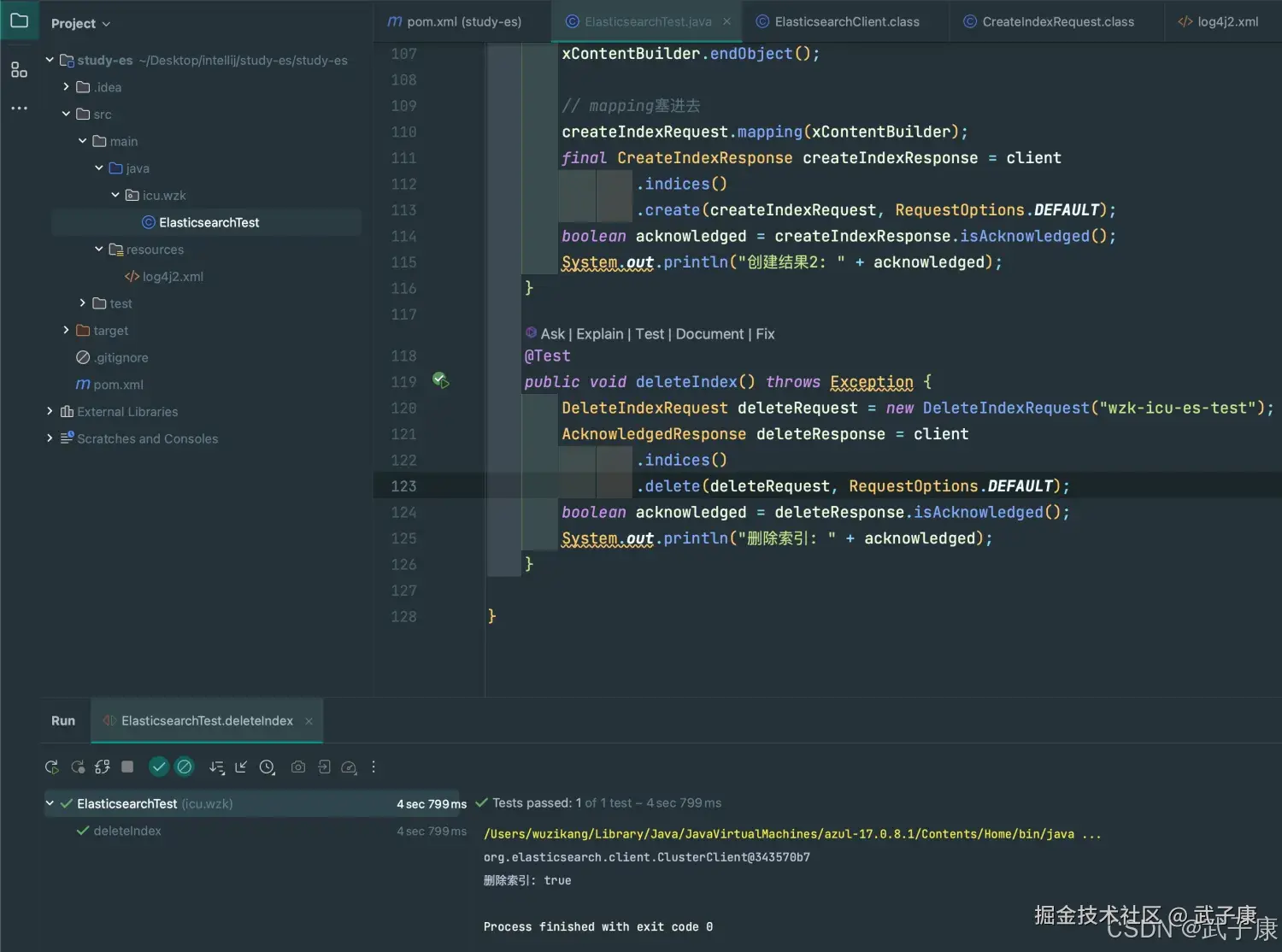 对应的Elasticsearch-Head查看,可以看到索引已经移除了:
对应的Elasticsearch-Head查看,可以看到索引已经移除了: 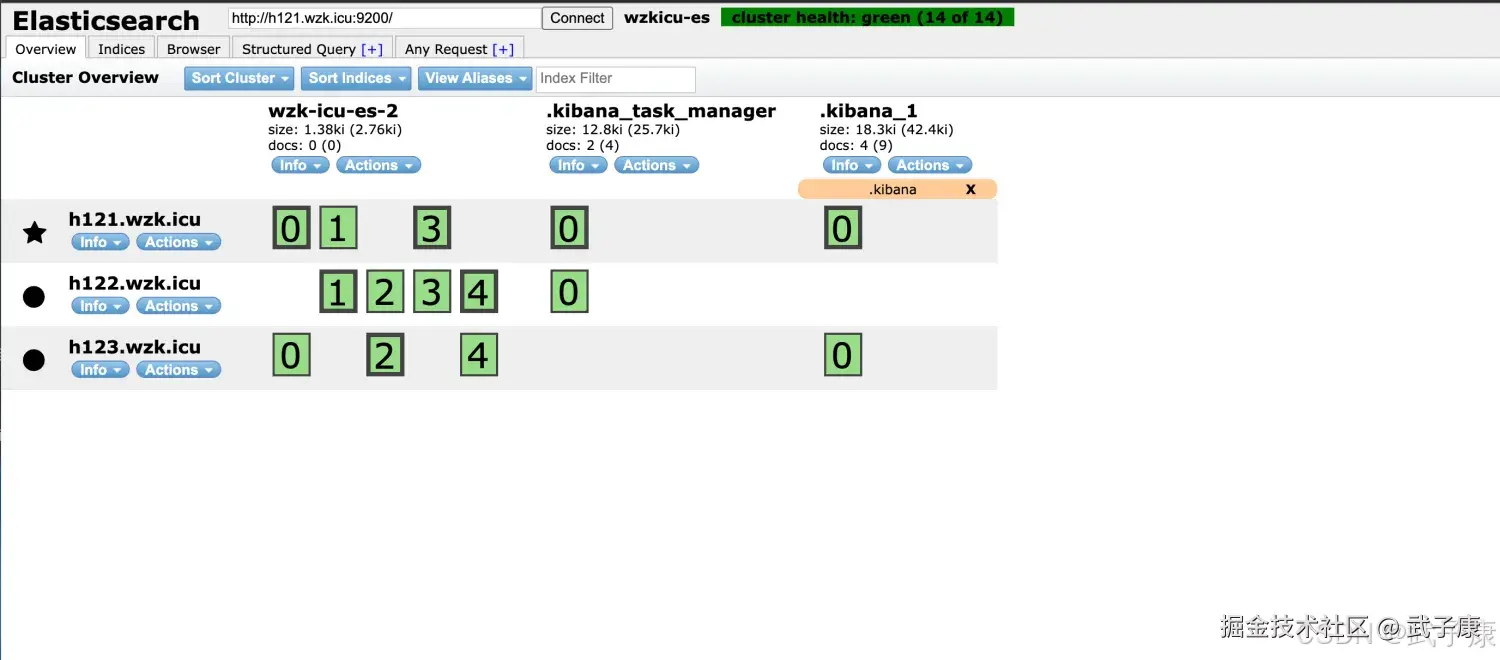
文档操作
添加文档
java
@Test
public void addDoc() throws Exception {
IndexRequest indexRequest = new IndexRequest("wzk-icu-es-2").id("1");
String str = " {\n" +
" \"name\": \"spark添加文档\",\n" +
" \"description\": \"spark技术栈\",\n" +
" \"studymodel\":\"online\",\n" +
" \"pic\": \"http://www.baidu.com\"\n" +
" }";
indexRequest.source(str, XContentType.JSON);
// 新增
IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("新增的结果:" + index.status());
}执行代码的结果如下图所示: 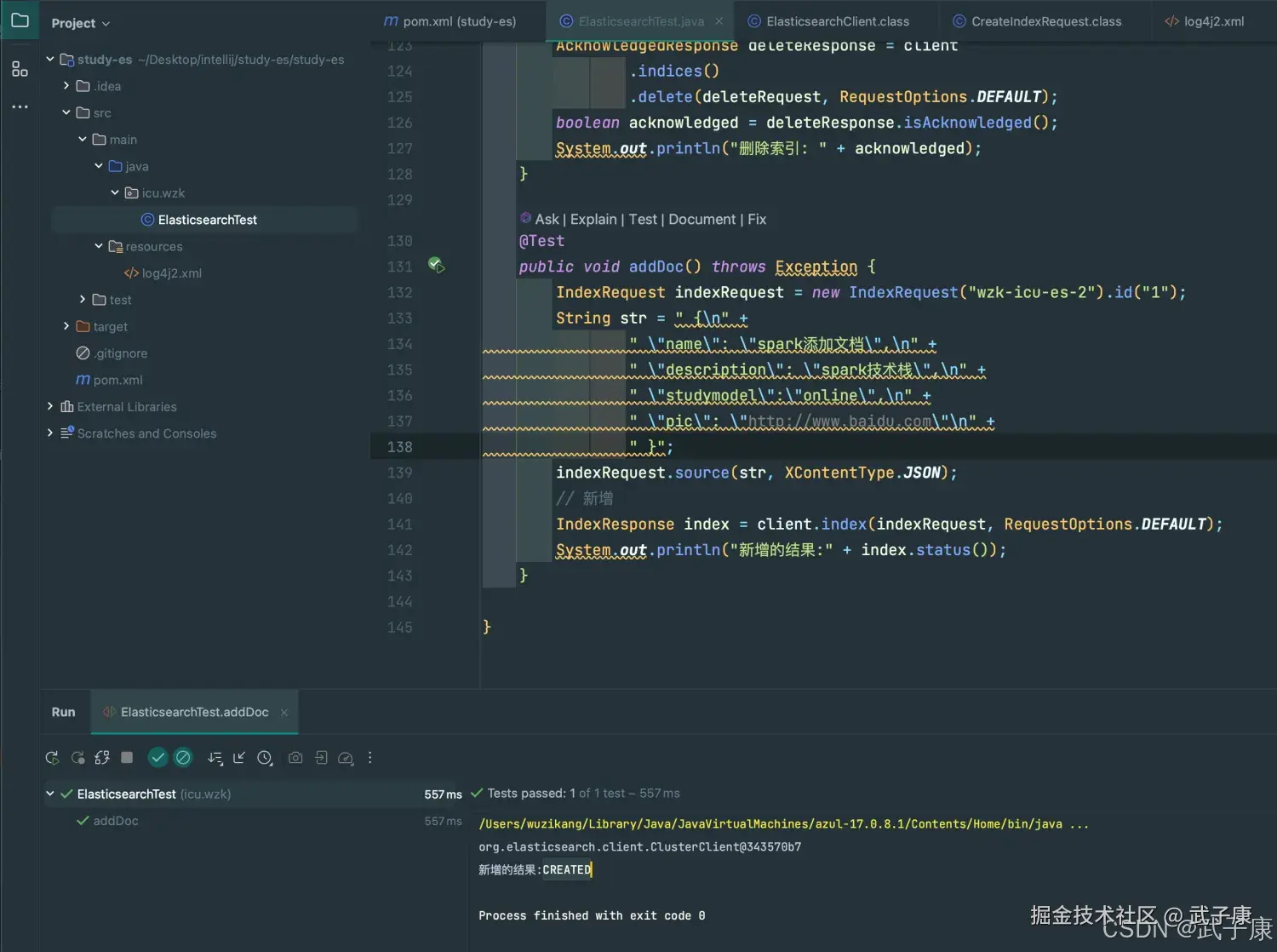
查询文档
java
@Test
public void getDoc() throws Exception {
GetRequest getRequest = new GetRequest("wzk-icu-es-2");
getRequest.id("1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
Map<String, Object> sourceMap = getResponse.getSourceAsMap();
System.out.println("查询结果:" + sourceMap);
}执行结果如下图: 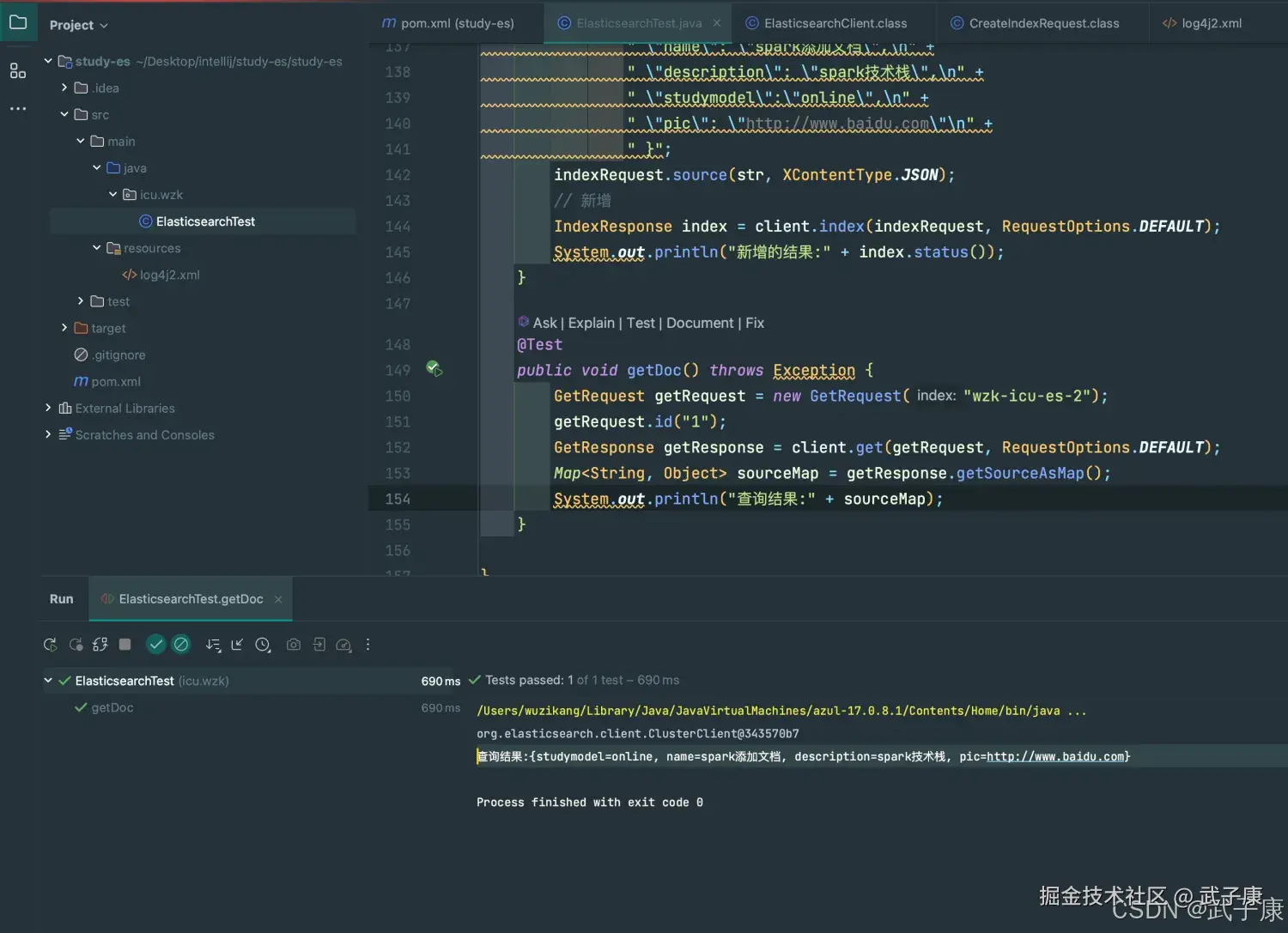
查询所有
java
@Test
public void getAllDoc() throws Exception {
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("wzk-icu-es-2");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
RestStatus status = searchResponse.status();
System.out.println("查询结果状态: " + status);
SearchHits hits = searchResponse.getHits();
SearchHit[] hits1 = hits.getHits();
for (SearchHit sh : hits1) {
System.out.println("---");
Map<String, Object> map = sh.getSourceAsMap();
System.out.println("查询的结果: " + map);
}
}执行的结果如下图所示: 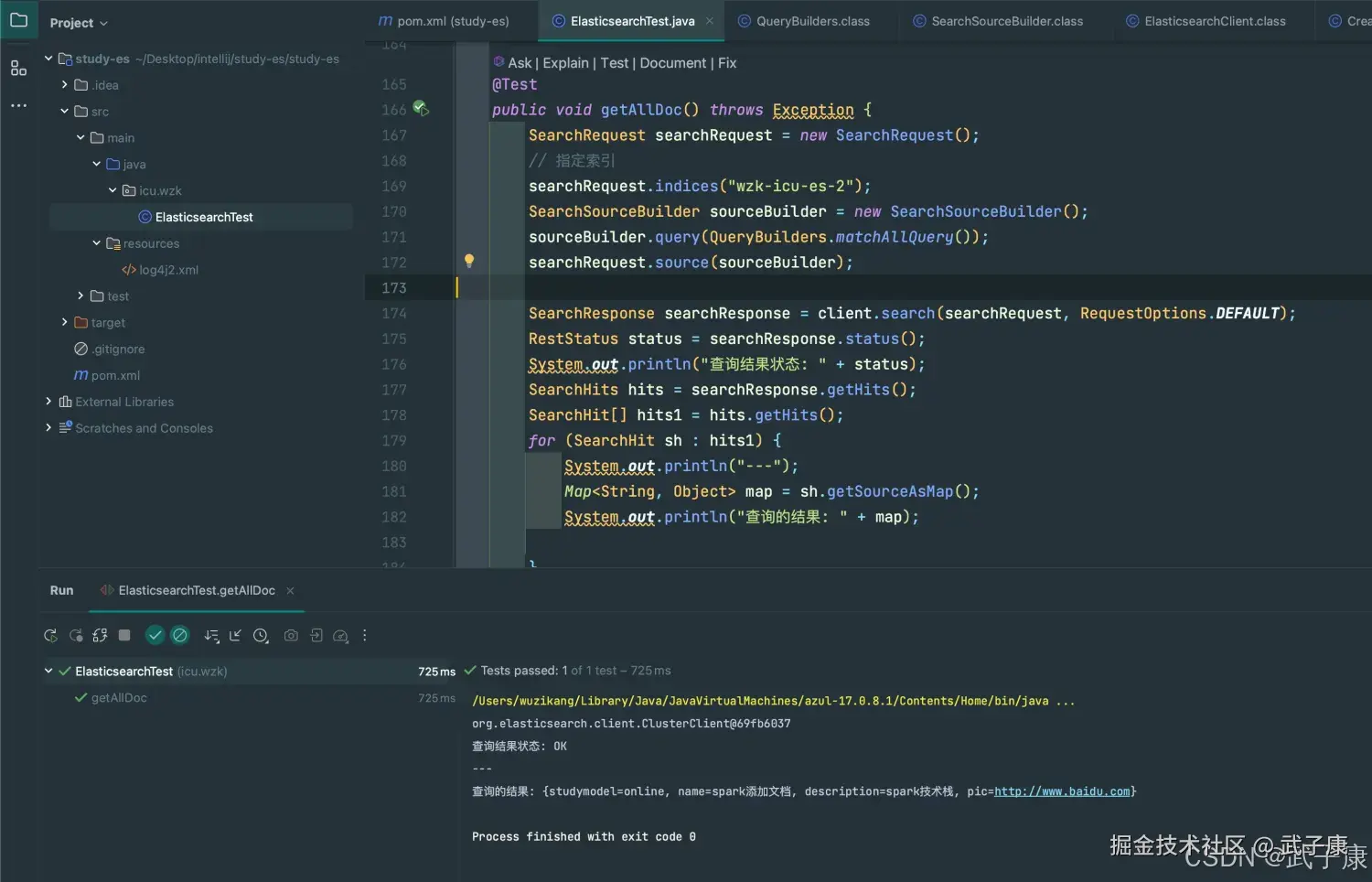
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 启动测试用例时报连接失败:Connection refused / UnknownHost | ES 节点地址或端口配置错误,如 h121.wzk.icu:9200 无法访问 | 检查 ES 节点 IP/域名、端口及防火墙;本地 curl 测试 /_cluster/health | 修正 HttpHost 地址或端口;确保 ES 集群已启动且网络连通 |
| 创建索引时报错:索引已存在 / resource_already_exists_exception | 重复创建相同名称索引 wzk-icu-es-test | 查看 ES Head/Kibana 索引列表;或在代码里先执行 indices().exists | 创建前先做存在性检查;或在调试阶段先删除旧索引再重建 |
| 创建索引报 Mapping/Settings 解析异常 | JSON 字符串 mapping 结构/语法错误,或字段类型配置不合法 | 打印 mapping 字符串并用 Kibana Dev Tools 测试 | 使用在线 JSON 校验工具;优先在 Kibana 控制台验证 mapping 后再拷贝入 Java 字符串 |
| 文档插入成功,但搜索结果为空或分词不符合预期 | 字段类型/分词器配置不当,如未对需要分词的字段使用 text+analyzer | 通过 GET index/_mapping 查看字段类型与 analyzer | 重新设计 mapping,使用 text + ik_max_word;如需精确匹配另加 keyword 子字段 |
| 删除索引时报错:索引不存在 / index_not_found_exception | 代码中索引名与实际索引不一致,如多环境/多前缀场景 | 查询 Head/Kibana 确认实际索引名 | 调整 DeleteIndexRequest 的索引名;或先判断 indices().exists 再删除 |
| search 返回状态 OK,但迭代 hits 时 NPE 或 Map 为空 | 查询条件不匹配现有文档,或未向目标索引插入测试数据 | 打印 hits.getTotalHits() 与 hits.getHits().length | 先用 match_all 与少量样例数据自测;为每个索引准备固定的种子文档方便验证 |
| JUnit @Before 初始化时报 client 为 null | 初始化过程中抛出异常未被注意,导致 client 未赋值 | 在 init() 中增加日志/断点,确认 RestHighLevelClient 创建是否成功 | 捕获并处理初始化异常;确保集群可用后再执行用例,@After 中加空指针保护 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解