一、neo4j介绍
(一)什么是 Neo4j?
Neo4j是一个原生图数据库,采用图结构来存储和处理数据。与关系型数据库不同,它专门设计用于处理高度关联的数据。
(二)图数据库 vs. 关系型数据库
Neo4j与关系型数据库(如 MySQL)的对比:
| 维度 | 关系型数据库 | Neo4j 图数据库 |
|---|---|---|
| 数据模型 | 表、行、列。数据通过外键关联。 | 图 ,由节点 、关系 和属性构成。 |
| 存储核心 | 表结构。关联是隐式的(通过外键值)。 | 关系 是一等公民,有自己的存储空间,像"箭头"一样直接连接节点。 |
| 查询方式 | SQL(结构化查询语言),使用 JOIN 来连接表。 | Cypher 查询语言,使用模式匹配来遍历图。 |
| 性能特点 | 多表深度 JOIN 时性能下降严重。 | 无论关系多深,遍历速度恒定(O(1) 级别),特别擅长处理关联密集型查询。 |
| 适用场景 | 高度结构化、模式固定的数据(如会计系统)。 | 高度互联、关系复杂的数据(如社交网络、推荐引擎、知识图谱、风控)。 |
(三)Neo4j 的核心组件
- 节点 :表示实体,例如人、产品、公司。可以带有属性 (键值对,如
name: "张三", age: 30)。 - 关系 :连接两个节点,表示它们之间的关联。关系是有方向 的(单向或双向),并且必须有类型 (如
FOLLOWS,PURCHASED),也可以拥有属性(如since: 2020)。 - 属性:附加在节点和关系上的键值对数据。
- 标签 :对节点进行分组的标记,类似于"类型"。一个节点可以有多个标签(如
Person:Customer)。
(四)Cypher 查询语言
Cypher 是 Neo4j 的声明式图查询语言,非常直观。
例子:查找张三的所有朋友
cypher
MATCH (zhang:Person {name: '张三'})-[:FRIEND_OF]->(friend)
RETURN friend.name()表示节点。:Person是节点标签。{name: '张三'}是节点属性。-[:FRIEND_OF]->表示一个类型为FRIEND_OF的关系,从zhang指向friend。
(五)JDK和Neo4j的关系
-
运行依赖关系
Neo4j是用Java开发 的,因此必须依赖JDK 才能运行
JDK提供了Neo4j运行所需的Java虚拟机(JVM)环境
没有JDK,Neo4j无法启动
-
版本对应关系
不同版本的Neo4j对JDK版本有不同要求:
- Neo4j 3.x → 通常需要JDK 8
- Neo4j 4.x → 需要JDK 11或更高版本
- Neo4j 5.x → 推荐JDK 17或更高版本
(六)Neo4j 社区版
这是一个数据库服务器软件。它是 Neo4j 的免费、开源版本。
- 定位: 用于生产或开发环境的服务器端部署。
- 核心功能 :
- 完整的 Cypher 查询语言支持(包括核心的图遍历和操作)。
- 支持 ACID 事务。
- 提供 HTTP API 和 Bolt 协议驱动。
- 可以与各种编程语言(Java, Python, JavaScript, .NET等)通过驱动进行连接。
- 支持基本的导入/导出功能。
- 限制 :
- 集群功能不支持: 只能以单实例运行,无法构建高可用或负载均衡集群。
- 容量限制: 理论上无硬性限制,但由于单实例,性能和容量受限于单台服务器的能力。
- 缺少高级管理工具: 没有图形化的监控、用户管理、备份恢复等企业级功能(需要通过命令行或API操作)。
- 在线备份功能有限: 仅支持"冷备份"(需要停止服务)。
(七)Neo4j 桌面版
这是一个本地桌面应用程序。它是为开发者和学习者设计的"一体化"图形界面工作台。
- 定位: 本地开发、学习和探索的集成环境。
- 核心功能 :
- 管理多个 Neo4j 数据库实例 : 可以轻松地在本地创建、启动、停止和管理多个不同版本的 Neo4j 数据库(默认安装并包含社区版服务器)。
- 内置 Neo4j Browser: 提供强大的图形化 Cypher 查询和结果可视化界面。
- 插件生态系统 :
- Neo4j Bloom: 商业智能风格的图探索和可视化工具(桌面版免费)。
- Neo4j ETL Tool: 将数据从关系数据库导入到 Neo4j。
- APOC 和 GDS 库: 一键安装强大的扩展过程库和图数据科学库。
- 项目管理: 将数据库、查询、插件和设置与特定项目关联。
- 轻松配置: 通过图形界面轻松修改数据库配置(如内存设置、安全认证等)。
- 限制 :
- 仅限本地使用,不适合生产部署。
- 本质上是用于管理和运行本地社区版服务器的工具。
二、下载安装步骤(以Windows为例)
Neo4j Desktop官网下载(失败)
(一)系统要求
- 操作系统:MacOS 10.10+ (Yosemite), Windows 10+ with PowerShell 5.1+, Ubuntu 22.04, Debian 11
- 内存:建议至少 4GB RAM(8GB以上更佳)
- 硬盘空间:至少 2GB 可用空间
- Java环境:Neo4j Desktop自带Java运行(无需单独安装JDK)
(二)下载步骤
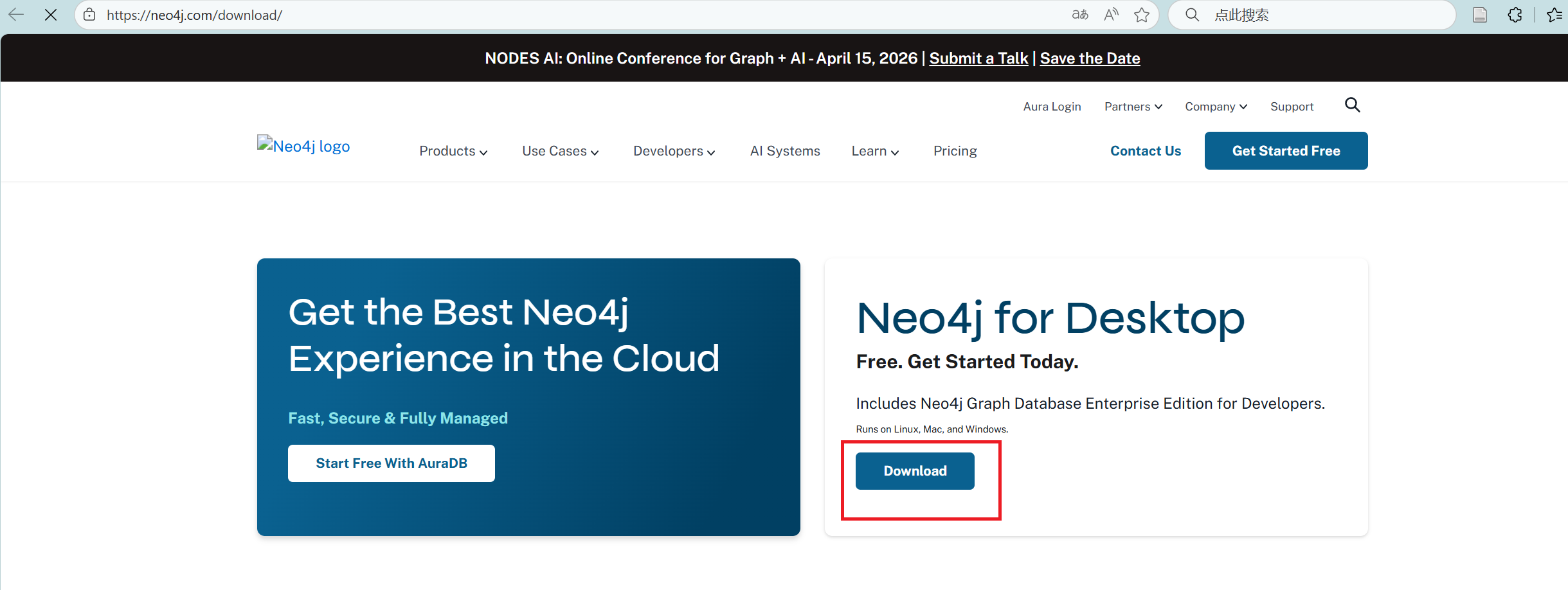
- 访问官网
打开 Neo4j官网下载页面, 点击Download
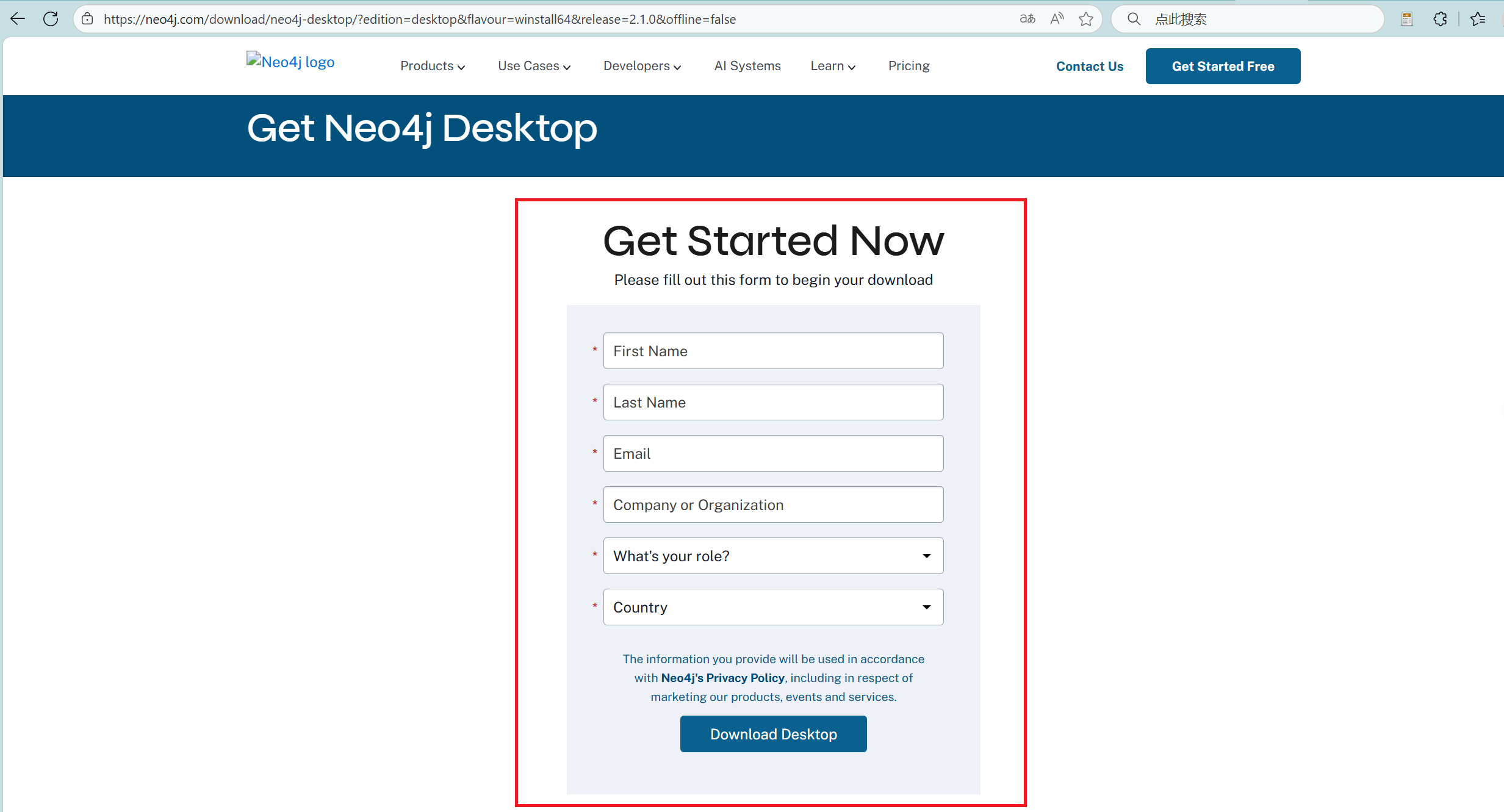
- 选择版本
完成注册,点击Download Desktop
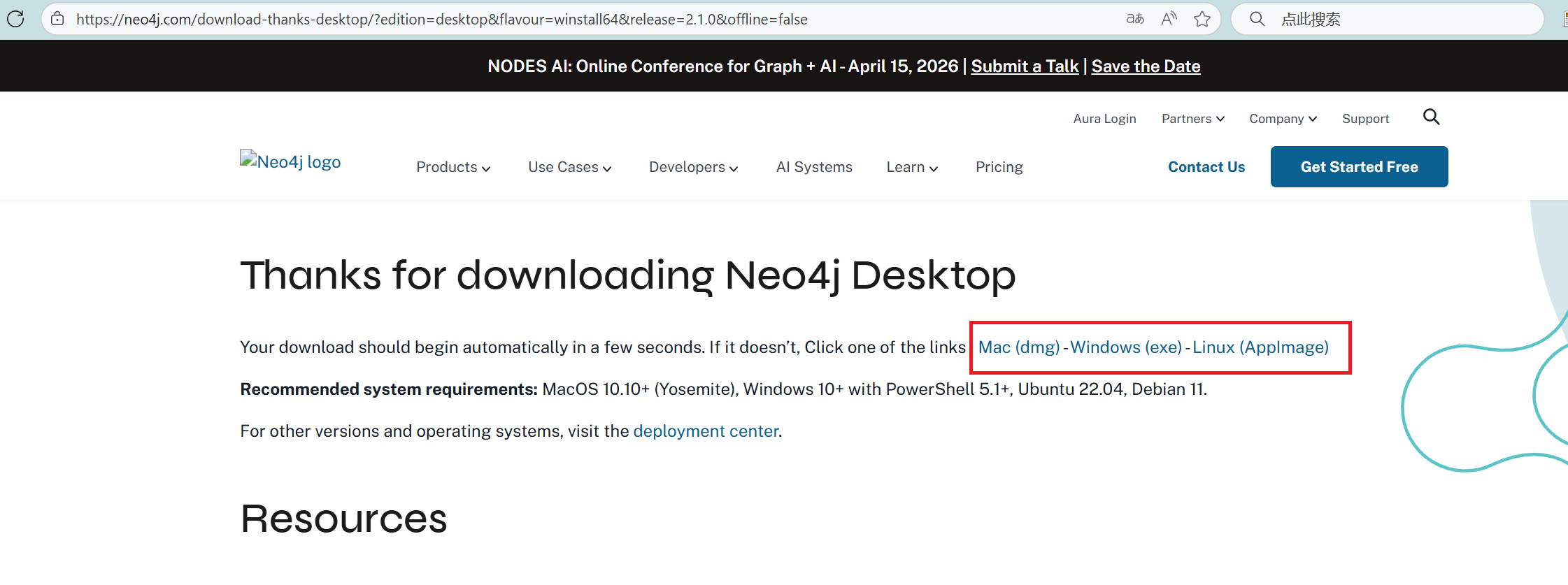
选择对应操作系统的安装包:- Windows:
.exe安装程序 - macOS:
.dmg镜像文件 - Linux:
.deb(Ubuntu/Debian)或.rpm(CentOS/RHEL)
- Windows:
- 下载安装(失败)
Neo4j Community安装包下载(成功)
(一)系统要求
- Neo4j版本:neo4j-community-5.26.0-windows
- 操作系统:Windows 10+
- 内存:建议至少 4GB RAM(8GB以上更佳)
- 硬盘空间:至少 2GB 可用空间
- Java环境:JDK 17 或更高版本
(二)前置条件
- 确保系统已安装 Java 11 或 17 运行时环境(JRE)。Neo4j 是基于 Java 开发的
- 在终端输入
java -version检查 - 若未安装,可前往 JDK官网 下载安装

- 在终端输入
(三)JDK安装教程(如JDK已安装,可跳过)
(1)JDK安装
-
打开 JDK官网 ,选择合适JDK版本与操作系统并下载
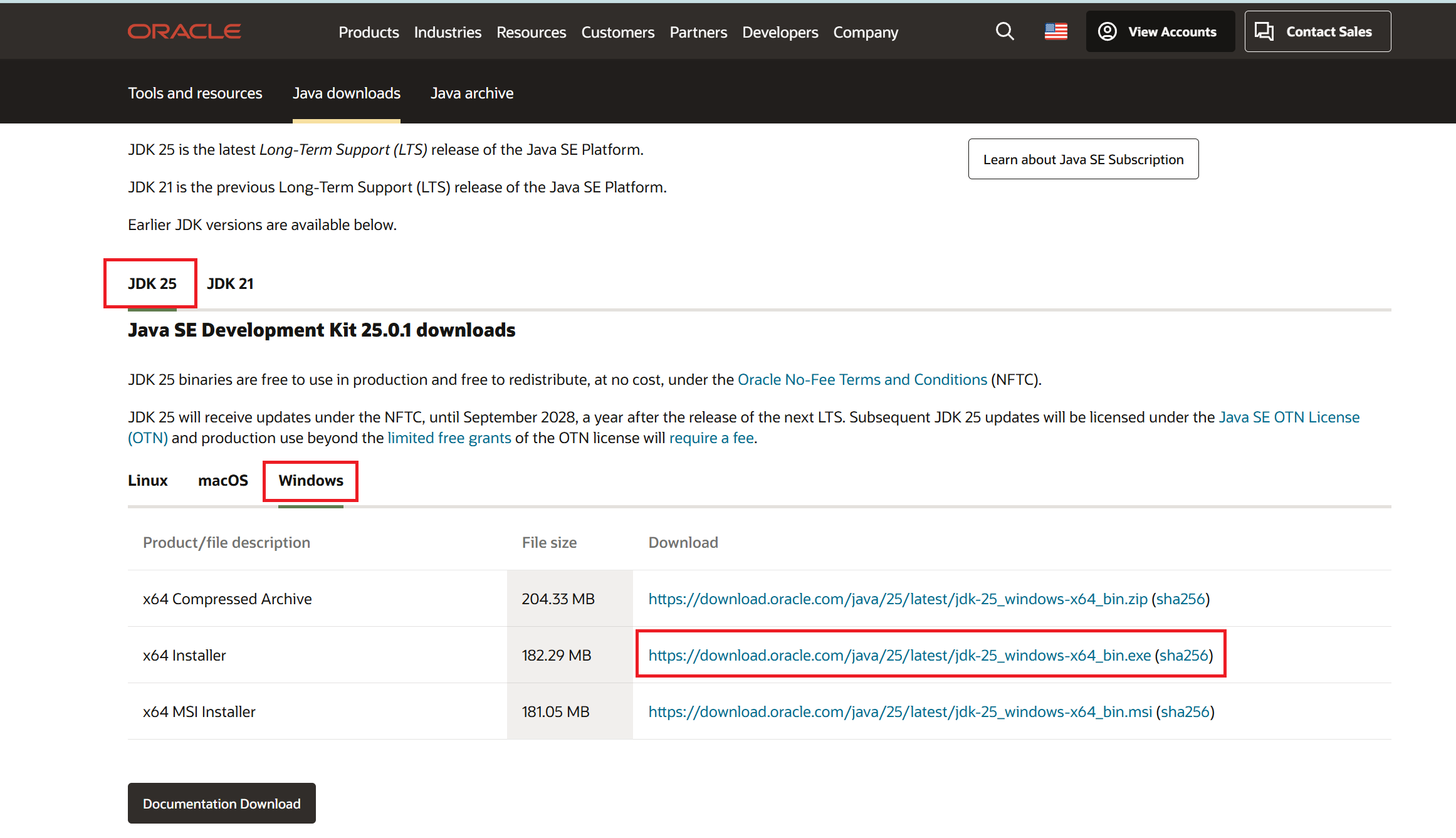
注意:在开发时,会在同一台电脑上安装多个jdk版本,以适应不同的项目需求的要求,普遍都是选.exe文档进行安装)
dk不同的安装包:
.zip: 下载后,需要解压
.exe:下载后,双击安装(安装简单)
.msi:适合企业环境,适合批量安装
-
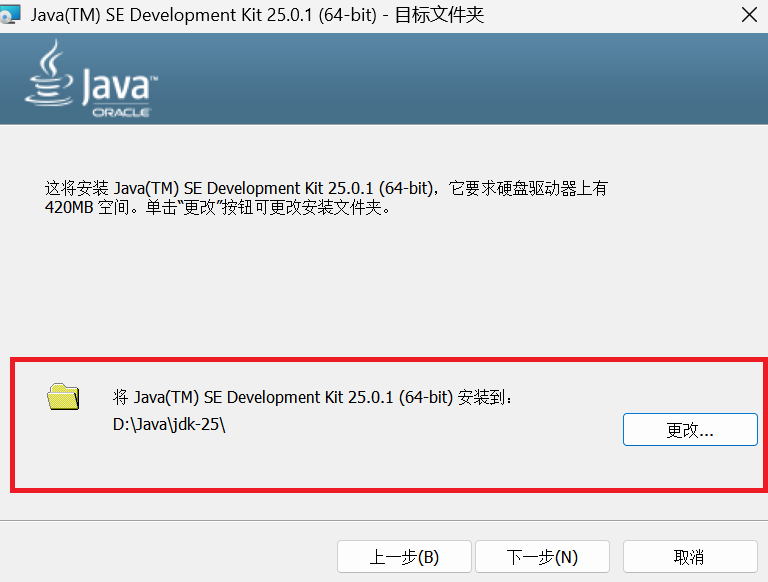
双击运行.exe,启动安装程序,更改安装位置,完成下载
-
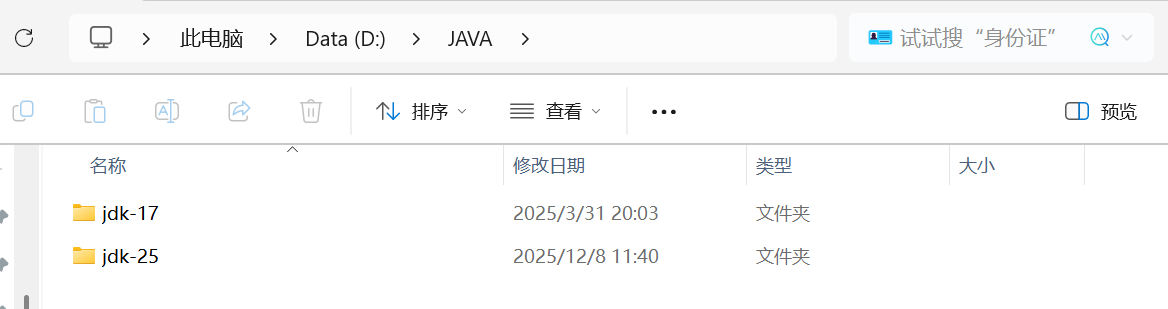
找到对应的安装目录,查看已安装的JDK版本
-
输入cmd,回车进入命令行模式,终端输入
java -version,查看JDK的版本信息
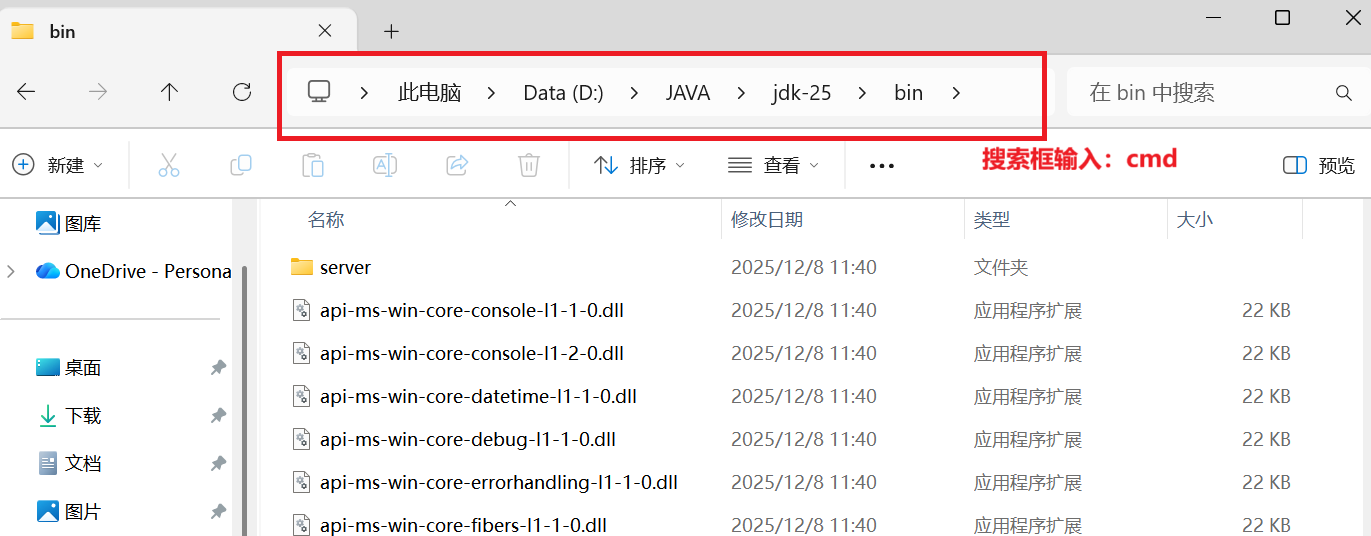

(2)配置JDK的环境变量
-
选中桌面
我的电脑------右键选择属性,选择高级系统设置,点击环境变量
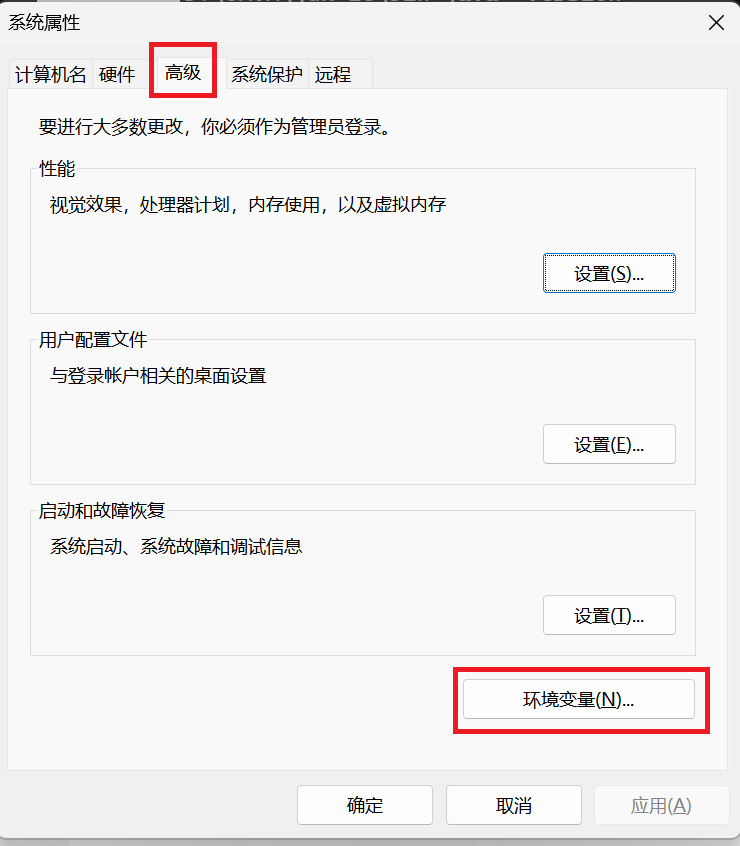
-
新增系统变量
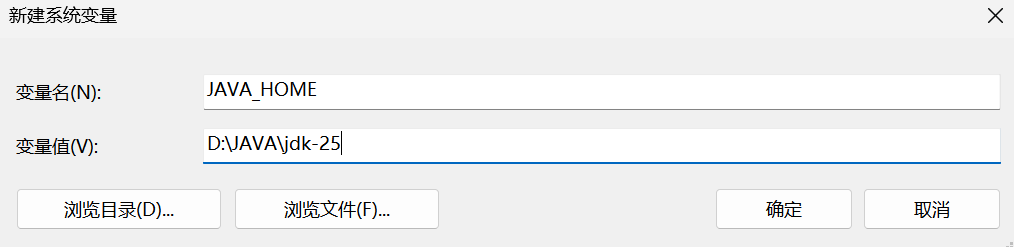
新增
JAVA_HOME,变量值为相应版本的JDK安装目录,点击确定
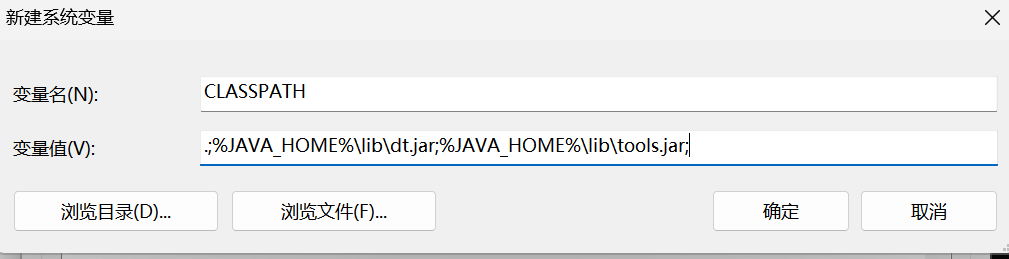
新增
CLASSPATH,变量值为.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;,点击确定
-
编辑Path系统变量
选中
Path,点击编辑
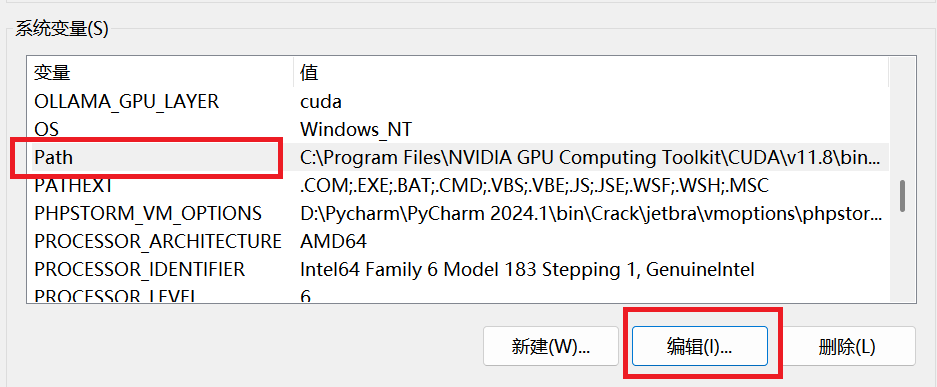
新建环境变量
%JAVA_HOME%\bin与%JAVA_HOME%\jre\bin,点击确认

(四)Neo4j安装教程
(1)Neo4j安装
下载安装包(neo4j-community-5.26.0-windows.rar),解压下载的压缩包到指定目录D:\neo4j
(2)配置Neo4j的环境变量
-
选中桌面
我的电脑------右键选择属性,选择高级系统设置,点击环境变量
-
选中Neo4j解压文件夹里的目录,复制该路径
D:\neo4j\neo4j-community-5.26.0
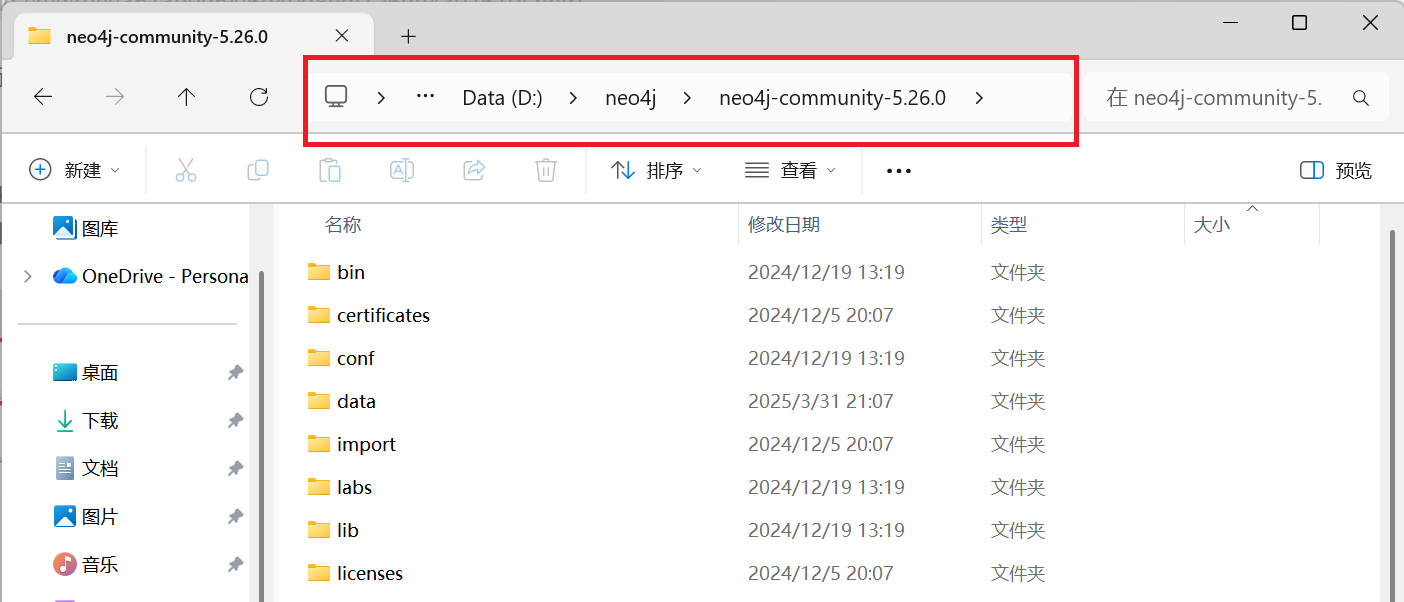
-
新增系统变量
新增
NEO4J_HOME,变量值为Neo4j安装目录,点击确定
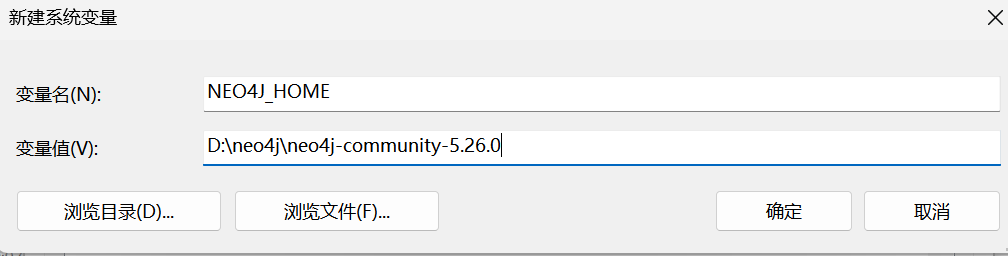
-
选中Neo4j解压文件夹里的bin目录,复制该路径
D:\neo4j\neo4j-community-5.26.0\bin
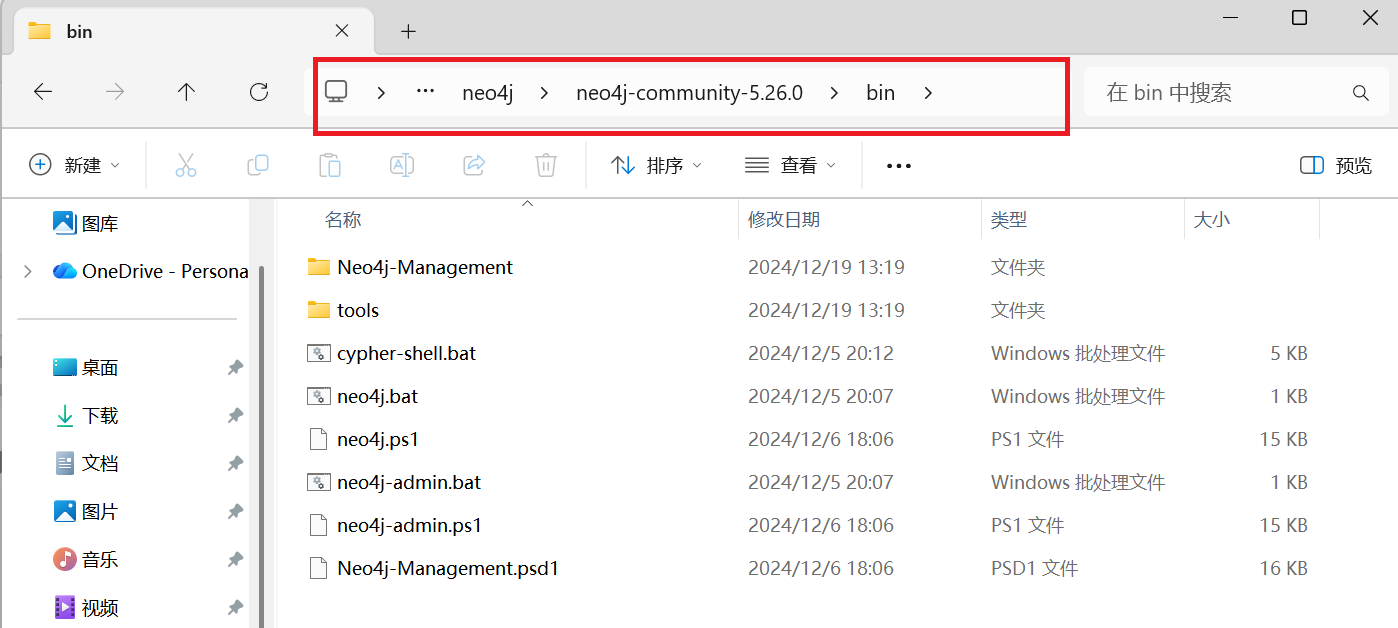
-
编辑Path系统变量
选中
Path,点击编辑
新建环境变量
D:\neo4j\neo4j-community-5.26.0\bin,点击确认

-
验证Neo4j安装是否成功
打开终端cmd,输入
neo4j console,出现Started代表安装成功
http://localhost:7474/为neo4j的启动网址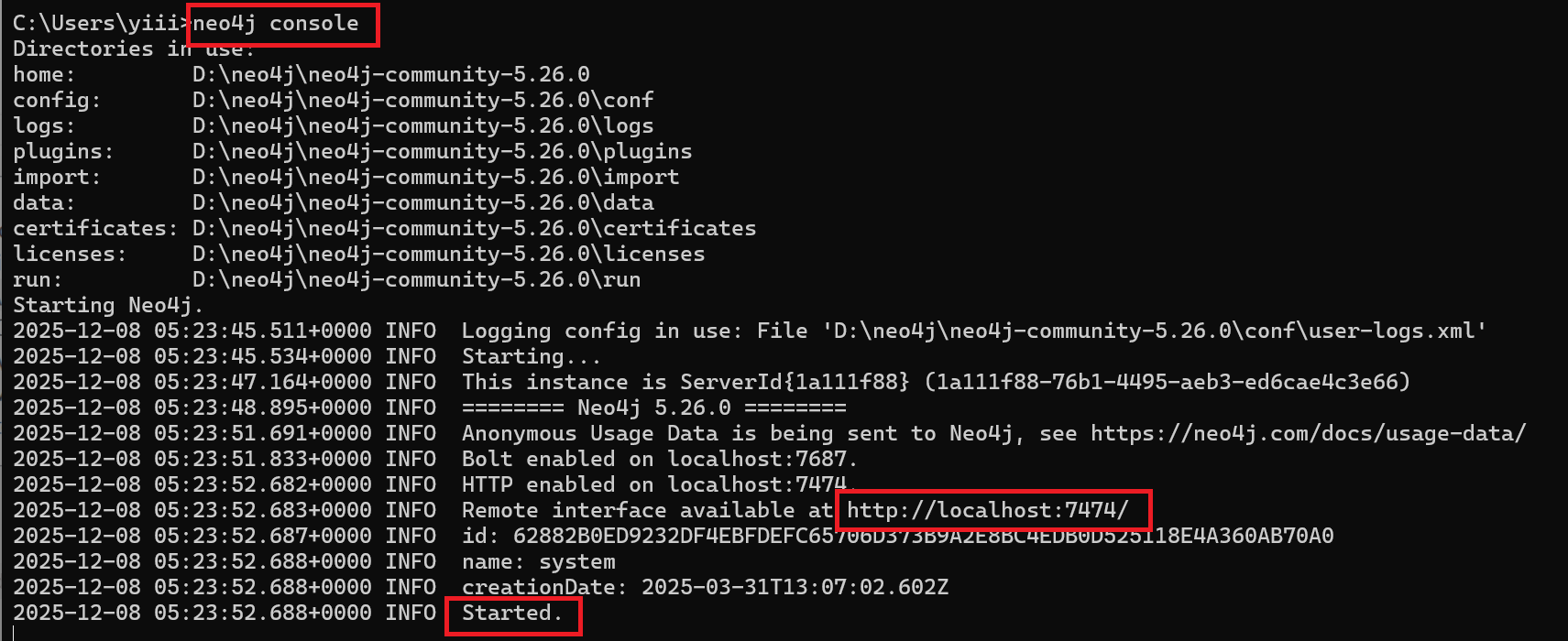
三、Neo4j使用教程
(一)运行Neo4j
-
打开终端cmd,输入
neo4j console,出现Started代表启动成功
http://localhost:7474/为neo4j的启动网址
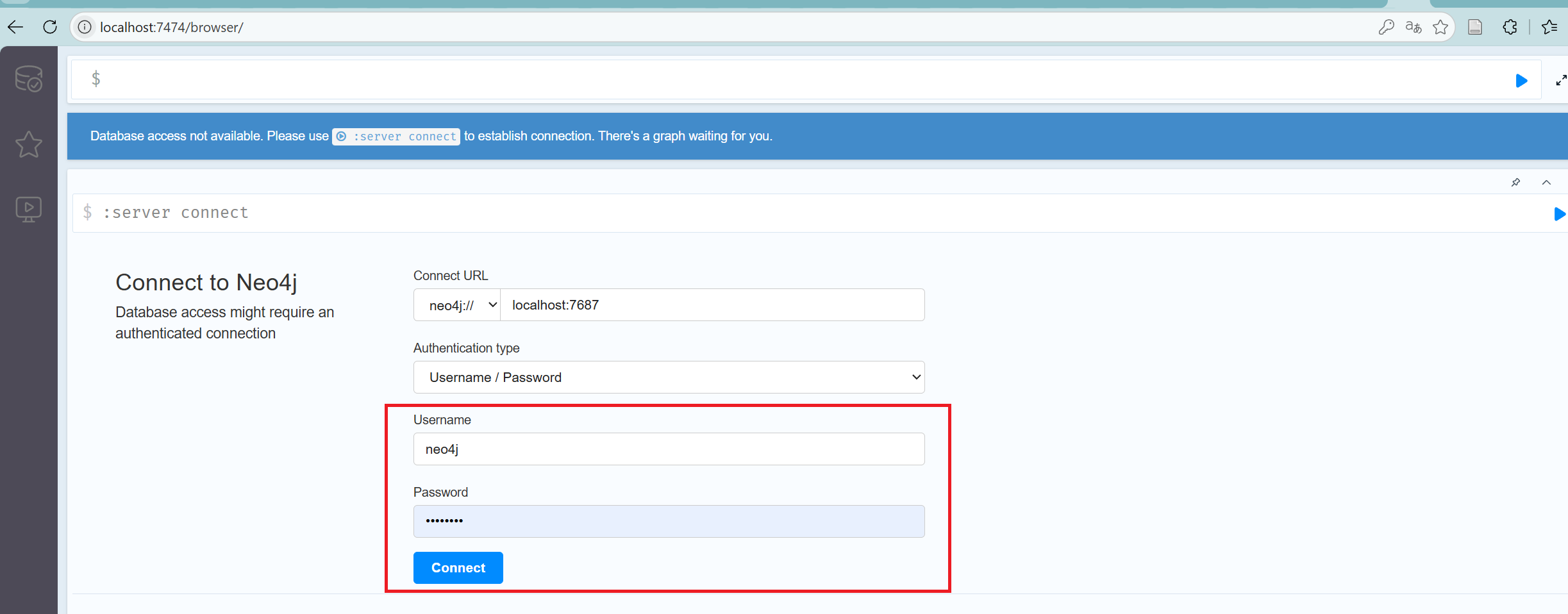
-
使用任意浏览器访问默认网址
http://localhost:7474/,输入账号密码初始用户名:neo4j 密码:neo4j,然后点击Connect,登录Neo4j
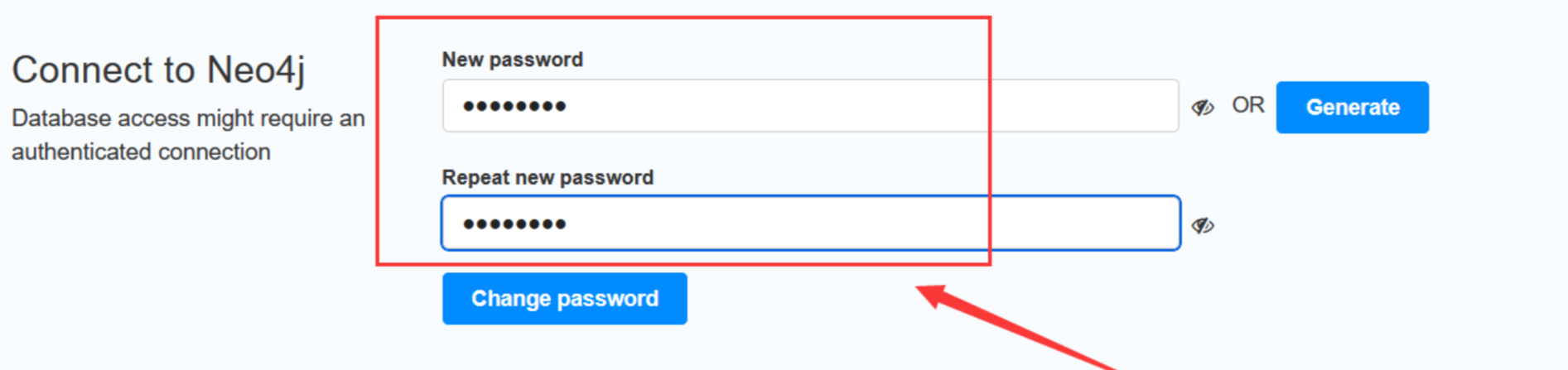
-
首次登录后会提示修改密码
输入新密码和确认密码之后,点击Change password
-
登录成功的界面
-
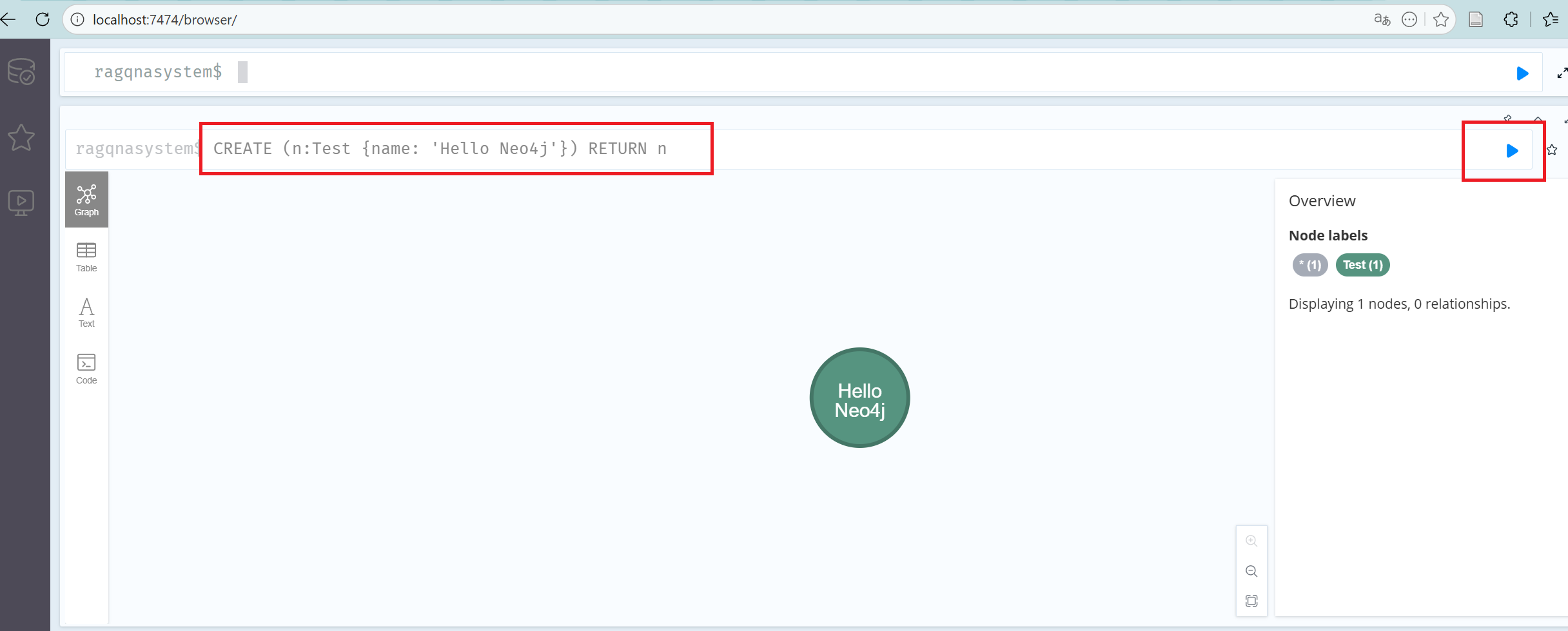
执行第一个查询
在顶部输入栏输入Cypher语句:cypherCREATE (n:Test {name: 'Hello Neo4j'}) RETURN n
(二)Cypher查询语言
Cypher 是一种声明式的图查询语言,用于Neo4j图数据库。它的语法设计类似于自然语言,使得查询易于理解和编写。允许用户使用直观的图形模式来描述想要查询或操作的数据,而无需关心底层的实现细节。
(1)Cypher基础语法结构
1. 基本模式
cypher
(节点)-[关系]->(节点)2. 语法规则
- 节点:用圆括号表示
() - 关系:用方括号表示
[] - 属性:用花括号表示
{} - 标签:以冒号开头
:Label - 变量:用于引用节点、关系或路径
- 区分大小写:标签、关系类型、属性键名区分大小写
(2)节点语法
1. 节点表示形式
cypher
-- 匿名节点(无标签、无属性)
()
-- 带变量的节点
(p)
-- 带标签的节点
(:Person)
-- 带标签和变量的节点
(p:Person)
-- 带属性、标签和变量的节点
(p:Person {name: 'John', age: 30})
-- 多个标签
(p:Person:Employee:Manager)2. 节点属性操作
cypher
-- 创建时设置属性
CREATE (p:Person {name: 'Alice', age: 25, city: '北京'})
-- 更新属性
MATCH (p:Person {name: 'Alice'})
SET p.age = 26,
p.skills = ['Java', 'Python'],
p.lastUpdated = timestamp()
-- 移除属性
MATCH (p:Person {name: 'Alice'})
REMOVE p.city
-- 合并属性(保留已有,添加新的)
MATCH (p:Person {name: 'Alice'})
SET p += {age: 27, department: 'IT'}(3)关系语法
1. 关系表示形式
cypher
-- 匿名关系
-[r]->
-- 带类型的关系
-[:KNOWS]->
-- 带类型和变量的关系
-[r:KNOWS]->
-- 带属性的关系
-[:KNOWS {since: 2010, close: true}]->
-- 无方向关系(查询时使用)
-[r:KNOWS]-2. 关系类型规则
- 以冒号开头
- 可以包含字母、数字、下划线
- 推荐使用大写驼峰命名法,如:
FRIEND_OF,WORKED_AT - 不能以数字开头
3. 关系属性操作
cypher
-- 创建带属性的关系
CREATE (a:Person)-[r:KNOWS {since: 2020, level: 'close'}]->(b:Person)
-- 更新关系属性
MATCH (a:Person)-[r:KNOWS]->(b:Person)
WHERE a.name = 'Alice' AND b.name = 'Bob'
SET r.since = 2021,
r.meet_at = 'conference'
-- 移除关系属性
MATCH ()-[r:KNOWS]->()
REMOVE r.level(4)基本查询子句
1. MATCH - 模式匹配
cypher
-- 基本匹配
MATCH (p:Person) RETURN p
-- 多模式匹配
MATCH (p:Person), (m:Movie) RETURN p, m
-- 可选匹配(类似左连接)
MATCH (p:Person)
OPTIONAL MATCH (p)-[r:REVIEWED]->(m:Movie)
RETURN p.name, m.title
-- 最短路径匹配
MATCH path = shortestPath((a:Person)-[*]-(b:Person))
WHERE a.name = 'Alice' AND b.name = 'Bob'
RETURN path2. WHERE - 条件过滤
cypher
-- 基本条件
WHERE p.age > 25
-- 字符串匹配
WHERE p.name STARTS WITH 'Al'
WHERE p.name ENDS WITH 'ce'
WHERE p.name CONTAINS 'lic'
-- 正则表达式
WHERE p.email =~ '.*@gmail\\.com'
-- IN操作符
WHERE p.name IN ['Alice', 'Bob', 'Charlie']
-- 空值判断
WHERE p.address IS NULL
WHERE p.phone IS NOT NULL
-- 复合条件
WHERE (p.age > 25 AND p.gender = 'female')
OR p.city = '北京'3. RETURN - 返回结果
cypher
-- 返回节点
RETURN p
-- 返回特定属性
RETURN p.name, p.age
-- 返回所有属性
RETURN properties(p)
-- 返回路径
RETURN path
-- 返回计数
RETURN COUNT(*)
-- 返回去重结果
RETURN DISTINCT p.city
-- 使用AS重命名
RETURN p.name AS 姓名, p.age AS 年龄
-- 使用表达式
RETURN p.name + ' from ' + p.city AS info4. ORDER BY - 排序
cypher
-- 升序排序
ORDER BY p.age ASC
-- 降序排序
ORDER BY p.salary DESC
-- 多字段排序
ORDER BY p.department, p.salary DESC5. LIMIT & SKIP - 分页
cypher
-- 限制结果数量
LIMIT 10
-- 跳过前N条
SKIP 20
-- 分页(每页10条,第3页)
SKIP 20 LIMIT 10(5)基本操作------创建(Create)
1. 创建节点
语法:
cypher
CREATE (变量名:标签 {属性名: 属性值})示例:
cypher
-- 创建简单节点
CREATE (p:Person {name: '张三', age: 30})
-- 创建多个节点
CREATE
(:Person {name: '李四', age: 25}),
(:Person {name: '王五', age: 35})
-- 创建带多个标签的节点
CREATE (p:Person:Employee {name: '赵六', department: 'IT'})2. 创建关系
语法:
cypher
-- 新节点之间创建关系
CREATE (节点1)-[关系变量:关系类型 {属性}]->(节点2)
-- 已有节点之间创建关系
MATCH (节点1), (节点2)
CREATE (节点1)-[关系变量:关系类型 {属性}]->(节点2)示例:
cypher
-- 创建节点和关系(一次完成)
CREATE
(a:Person {name: 'Alice'}),
(b:Person {name: 'Bob'}),
(a)-[:FRIEND {since: 2020}]->(b),
(a)-[:WORKS_WITH]->(b)
-- 为已有节点创建关系
MATCH
(a:Person {name: '张三'}),
(b:Person {name: '李四'})
CREATE (a)-[:KNOWS]->(b)
-- 创建双向关系
CREATE
(a)-[:FRIEND]->(b),
(b)-[:FRIEND]->(a)(6)基本操作------查询(Match)
1. 基本查询
语法:
cypher
MATCH (变量:标签 {条件})
RETURN 变量或属性示例:
cypher
-- 查询所有Person节点
MATCH (p:Person) RETURN p
-- 查询特定属性
MATCH (p:Person)
RETURN p.name, p.age
-- 带条件的查询
MATCH (p:Person)
WHERE p.age > 25 AND p.city = '北京'
RETURN p.name, p.age
-- 查询关系
MATCH (p1:Person)-[r:FRIEND]->(p2:Person)
RETURN p1.name, p2.name, r.since2. 关系查询
语法:
cypher
MATCH (节点1)-[关系:关系类型]->(节点2)
RETURN 节点1, 关系, 节点2示例:
cypher
-- 查询所有朋友关系
MATCH (p1:Person)-[r:FRIEND]->(p2:Person)
RETURN p1.name, p2.name, r.since
-- 查询张三的所有朋友
MATCH (p:Person {name: '张三'})-[:FRIEND]->(friend)
RETURN friend.name, friend.age
-- 查询朋友的朋友(2度关系)
MATCH (p:Person {name: '张三'})-[:FRIEND]->(friend)-[:FRIEND]->(fof)
RETURN fof.name, fof.city3. 路径查询
语法:
cypher
MATCH 路径变量 = (起点)-[:关系类型*最小..最大]->(终点)
RETURN 路径变量示例:
cypher
-- 查询1-3度关系
MATCH path = (a:Person {name: 'Alice'})-[:FRIEND*1..3]->(b:Person)
RETURN b.name, length(path) as 度数
-- 查询最短路径
MATCH path = shortestPath(
(a:Person {name: '张三'})-[:FRIEND|KNOWS*]-(b:Person {name: '李四'})
)
RETURN path(7)基本操作------更新(Update)
1. 更新节点
语法:
cypher
MATCH (节点:标签 {条件})
SET 节点.属性 = 新值示例:
cypher
-- 更新单个属性
MATCH (p:Person {name: '张三'})
SET p.age = 31
-- 更新多个属性
MATCH (p:Person {name: '李四'})
SET p.age = 26, p.city = '上海', p.salary = 15000
-- 添加新属性
MATCH (p:Person {name: '王五'})
SET p.email = 'wangwu@example.com', p.phone = '13800138000'
-- 添加新标签
MATCH (p:Person {name: '赵六'})
SET p:Manager, p.department = '市场部'2. 更新关系
语法:
cypher
MATCH (节点1)-[关系:关系类型]->(节点2)
SET 关系.属性 = 新值示例:
cypher
-- 更新关系属性
MATCH (a:Person {name: 'Alice'})-[r:FRIEND]->(b:Person {name: 'Bob'})
SET r.since = 2022, r.closeness = 'best'
-- 更新购买时间
MATCH (u:User {id: 123})-[r:BOUGHT]->(p:Product {id: 101})
SET r.quantity = r.quantity + 1, r.last_purchase = date()(8)基本操作------删除(Delete)
1. 删除节点
语法:
cypher
-- 删除节点及其关系
MATCH (节点:标签 {条件})
DETACH DELETE 节点
-- 只删除节点(必须先删除关系)
MATCH (节点:标签 {条件})
DELETE 节点示例:
cypher
-- 删除特定节点及其所有关系
MATCH (p:Person {name: '张三'})
DETACH DELETE p
-- 删除多个节点
MATCH (p:Person)
WHERE p.age < 18
DETACH DELETE p
-- 先删除关系再删除节点
MATCH (p:Product {name: '过时商品'})
MATCH (p)-[r]-()
DELETE r
DELETE p2. 删除关系
语法:
cypher
MATCH (节点1)-[关系:关系类型]->(节点2)
DELETE 关系示例:
cypher
-- 删除特定关系
MATCH (a:Person {name: '张三'})-[r:FRIEND]->(b:Person {name: '李四'})
DELETE r
-- 删除过期关系
MATCH ()-[r:FRIEND]-()
WHERE r.since < 2010
DELETE r3. 删除属性
语法:
cypher
MATCH (节点:标签 {条件})
REMOVE 节点.属性名示例:
cypher
-- 删除单个属性
MATCH (p:Person {name: '张三'})
REMOVE p.nickname
-- 删除多个属性
MATCH (p:Person)
WHERE p.age > 60
REMOVE p.salary, p.position(三)使用Python运行Neo4j
(1)官方 neo4j 驱动基础语法
1 安装和导入
bash
pip install neo4j
python
from neo4j import GraphDatabase2 连接数据库
python
# 创建驱动
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "your_password")
)
# 测试连接
driver.verify_connectivity()3 基本查询模式
python
# 写操作(CREATE, UPDATE, DELETE)
def write_query(tx, query, **params):
result = tx.run(query, **params)
return result.data() # 或 result.single() 或 result.value()
# 读操作(MATCH, RETURN)
def read_query(tx, query, **params):
result = tx.run(query, **params)
return result.data()
# 使用示例
with driver.session() as session:
# 写操作
session.execute_write(write_query,
"CREATE (p:Person {name: $name, age: $age})",
name="Alice", age=30
)
# 读操作
people = session.execute_read(read_query,
"MATCH (p:Person) RETURN p.name, p.age"
)
print(people)4 数据处理方法
python
# 获取单条记录
result = session.run("MATCH (p:Person) RETURN p LIMIT 1")
single_record = result.single() # 获取第一条
value = result.single()[0] # 获取第一个字段的值
value = result.single().value() # 同上
# 获取所有记录
result = session.run("MATCH (p:Person) RETURN p")
all_records = result.data() # 返回字典列表
all_values = result.values() # 返回值列表的列表
list_of_records = list(result) # 转换为Record对象列表
# 获取特定字段
result = session.run("MATCH (p:Person) RETURN p.name AS name")
names = [record["name"] for record in result] # 通过键名
names = [record[0] for record in result] # 通过索引
names = result.value() # 所有第一个字段的值5 关闭连接
python
driver.close()(2) 第三方库py2neo 基础语法
1 安装和导入
bash
pip install py2neo
python
from py2neo import Graph, Node, Relationship2 连接数据库
python
# 创建连接
graph = Graph("bolt://localhost:7687",
auth=("neo4j", "your_password"))
# 测试连接
graph.run("RETURN 1") # 简单查询测试3 节点操作
python
# 创建节点
person = Node("Person", name="Alice", age=30)
graph.create(person)
# 批量创建
people = [
Node("Person", name="Bob", age=25),
Node("Person", name="Charlie", age=35)
]
graph.create(people[0] | people[1]) # 使用|操作符合并
# 查找节点
from py2neo import NodeMatcher
matcher = NodeMatcher(graph)
alice = matcher.match("Person", name="Alice").first()
all_people = matcher.match("Person").all()
# 更新节点
alice["age"] = 31
graph.push(alice) # 更新到数据库
# 删除节点
graph.delete(alice) # 删除节点及其关系
graph.separate(alice) # 只删除关系,保留节点4 关系操作
python
# 创建关系
alice = Node("Person", name="Alice")
bob = Node("Person", name="Bob")
knows = Relationship(alice, "KNOWS", bob, since="2020")
graph.create(knows)
# 查询关系
query = """
MATCH (a:Person)-[r:KNOWS]->(b:Person)
WHERE a.name = $name
RETURN b.name, r.since
"""
result = graph.run(query, name="Alice")
for record in result:
print(record["b.name"], record["r.since"])5 通用查询
python
# 执行Cypher查询
result = graph.run("MATCH (p:Person) RETURN p.name, p.age")
# 获取数据的不同方式
data = result.data() # 返回字典列表
df = result.to_data_frame() # 转换为pandas DataFrame
table = result.to_table() # 转换为表格格式
records = list(result) # 转换为Record对象列表
# 带参数的查询
result = graph.run(
"MATCH (p:Person) WHERE p.age > $min_age RETURN p.name",
min_age=25
)
# 获取单个值
name = graph.evaluate(
"MATCH (p:Person {name: $name}) RETURN p.age",
name="Alice"
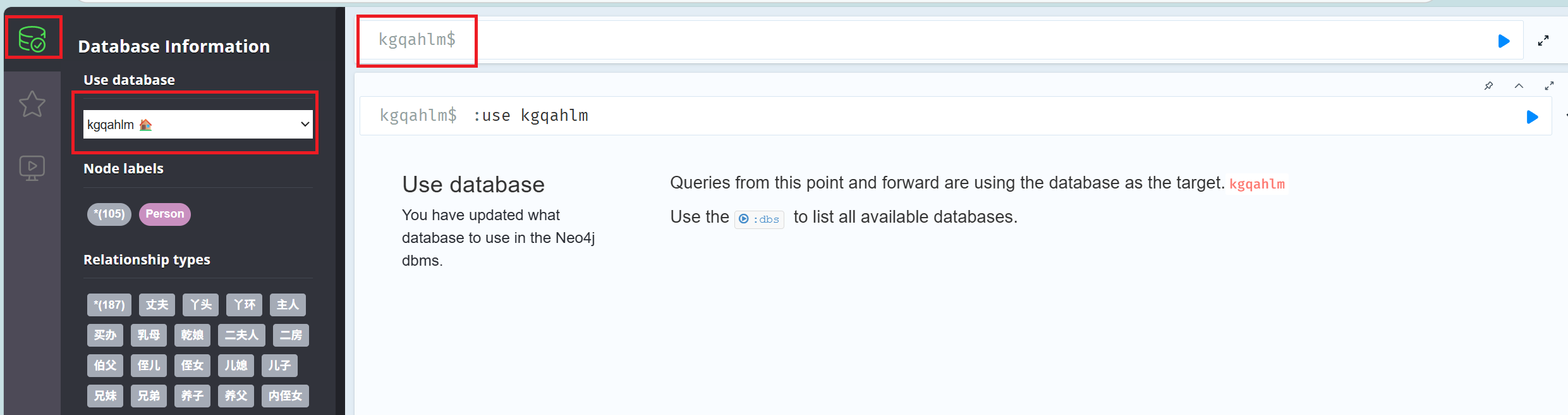
)(四)切换Neo4j数据库
社区版只能同时运行一个数据库,通过修改neo4j.conf内数据库名,实现切换数据库操作
-
找到文件
neo4j.conf,使用记事本打开。(路径目录:D:\neo4j\neo4j-community-5.26.0\conf)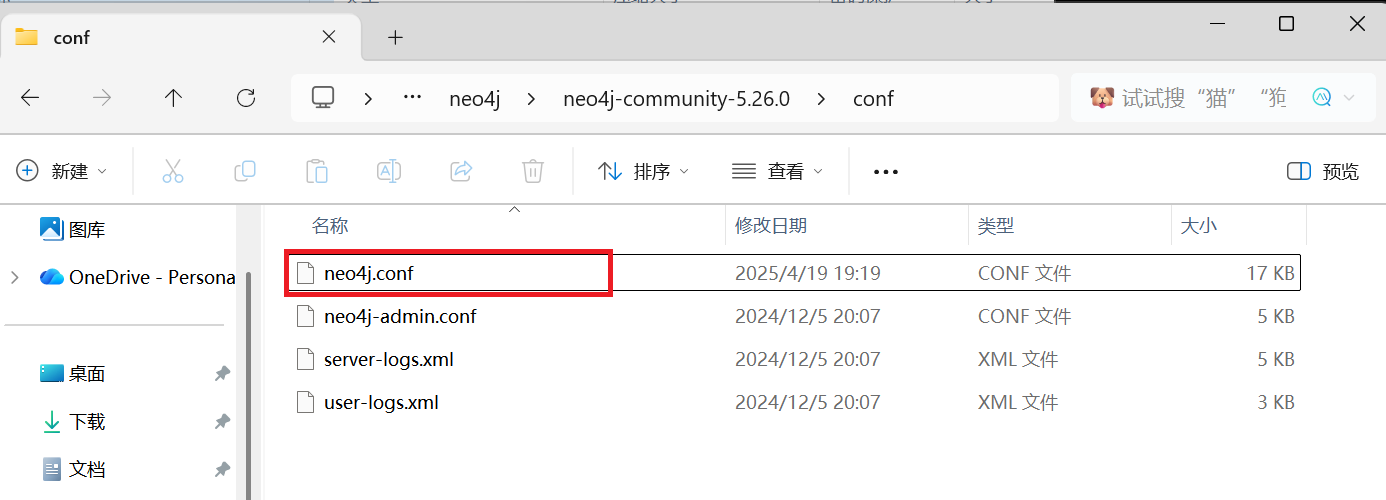
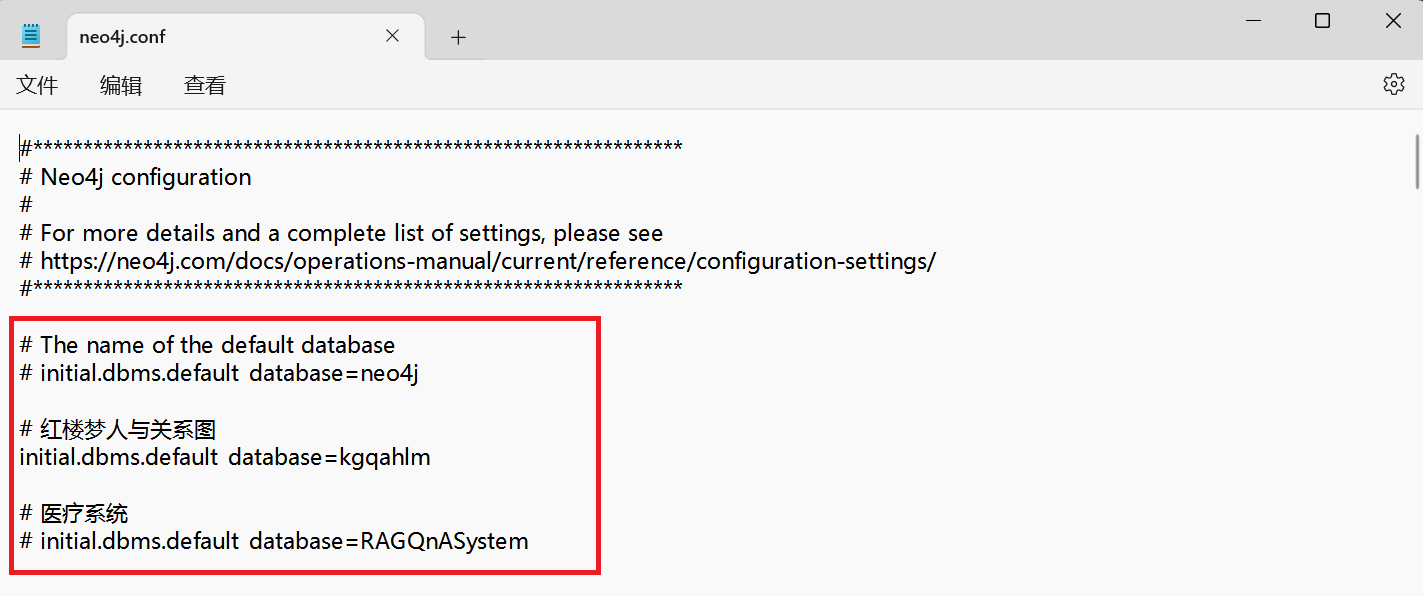
-
修改使用的数据库名称,其余数据库用
#注释掉
initial.dbms.default_database=名称
-
重新运行
neo4j console,打开Neo4j网页http://localhost:7474/,完成数据库的切换