前言
欢迎到我们的交流群一起交流各种前端技术,同时欢迎访问我的 headless 组件库,同时感谢你的 star:
nest.js / hono.js 一起学系列,最终会封装一个通用的架子,例如有鉴权,日志收集,多环境配置等等功能,用两种框架去实现。 之前写了两篇关于这两个框架编程思想相关的
这一篇主要是涉及到我们马上开发前需要具备的一些基础知识,包含:
- 命令行工具使用
- 最佳工程实践(目录规划篇)
- 如何调试
- docker 入门 + 深入 docker 基本原理
命令行上手
全局安装 CLI
建议,全局安装 CLI, 然后试着创建一个项目试试:
css
npm i -g @nestjs/cli
nest new project-name后续,你按照命令行提示即可完成项目初始化,然后安装完包,最后看一下 package.json 中 scripts 中的启动命令是什么,启动项目即可。
hono.js 初始化项目是采用:
sql
npm create hono@latest project-name同样,你按照命令行提示即可完成项目初始化,然后安装对应的包即可,最后看一下 package.json 中 scripts 中的启动命令是什么,启动项目即可。
但是 hono.js 并没有类似 nest 的 cli 管理工具,毕竟 nest 的写法要繁琐很多,所以官方提供了一些快速创建模板的命令。可以通过以下命令查看:
bash
nest --help
最常见的使用 generate 或者 g 来生成模板, 我们可以用 -d 命令,来让 cli 告诉你,你的 generate 或者 g 命令会生成什么文件,咱们来试试,假设我们要创建一个 名字为 user 的 class
kotlin
nest g class user -d 显示:
scss
CREATE src/user/user.spec.ts (139 bytes)
CREATE src/user/user.ts (21 bytes)
Dry run enabled. No files written to disk.注意最后一行: No files written to disk. 也就是没有真的把文件写入,而是提示如果你使用nest g class user 可能创建的文件有哪些。
还有,我们有时候不太喜欢测试,可以使用
kotlin
nest g class user --no-spec来省去测试文件的创建。
最佳工程实践
我们这里列举一些比较好的工程实践的点,欢迎大家一起讨论。
工程目录
我们采用"约定大于配置"的思想,无论使用什么 node.js 后端框架,我们的目录名尽可能一致。
nest.js 的建议,如果以下目录名意思不清楚没关系,后续学到控制器,service 等等章节的时候,就会明白了:
ruby
src/
├── modules/ # 核心:按业务领域划分的模块
│ ├── users/ # 用户模块
│ │ ├── dto/ # 数据传输对象(请求/响应结构)
│ │ ├── entities/ # 数据库实体
│ │ ├── users.controller.ts
│ │ ├── users.service.ts
│ │ └── users.module.ts
│ └── products/ # 产品模块(结构类似用户模块)
├── common/ # 共享资源
│ ├── filters/ # 全局异常过滤器
│ ├── interceptors/ # 拦截器
│ └── guards/ # 守卫
├── config/ # 全局配置
├── database/ # 数据库连接配置
└── app.module.ts # 应用根模块核心设计原则:
- 功能内聚:与"用户"相关的所有文件(控制器、服务、实体、DTO)都应放在 users 目录下。
- 分层管理:使用 common、core 等目录管理跨模块共享的组件和全局配置。
hono.js 的建议如下,当然 config ,utils 这些比较常见的全局模块也可以提到第一层级,也就是 src 目录下:
csharp
src/
├── modules/ # 每个模块独立
│ ├── user/
│ │ ├── routes.ts # 只放路由注册(薄层)
│ │ ├── controller/ # handlers 控制器层
│ │ │ ├── get-user.ts
│ │ │ ├── list-users.ts
│ │ │ ├── create-user.ts
│ │ │ └── update-user.ts
│ │ ├── service/ # 业务逻辑
│ │ │ └── user.service.ts
│ │ ├── repository/ # DB / 外部API
│ │ │ └── user.repo.ts
│ │ ├── middleware/ # 与 user 模块强相关的中间件
│ │ │ └── user-auth.middleware.ts
│ │ ├── validators/ # DTO / 校验器(zod / valibot)
│ │ │ ├── create-user.validator.ts
│ │ │ └── update-user.validator.ts
│ │ ├── dto/ # 请求 / 响应类型
│ │ │ ├── user.dto.ts
│ │ │ └── index.ts
│ │ ├── constants.ts # 与 user 相关的常量
│ │ ├── index.ts # 模块总出口
│ │ └── types.ts # 模块相关类型
│ │
│ ├── product/
│ │ ├── routes.ts
│ │ ├── controller/
│ │ ├── service/
│ │ ├── repository/
│ │ ├── middleware/
│ │ ├── validators/
│ │ └── dto/
│ │
│ └── auth/
│ └── ...
│
├── common/ # 全局复用层(不属于任何模块)
│ ├── app.ts # app 初始化(全局中间件、错误处理)
│ ├── router.ts # 合并 modules 的 routes
│ ├── middlewares/ # 全局中间件
│ ├── config/ # 配置(DB、ENV等)
│ ├── utils/ # 工具
│ ├── errors/ # 全局错误类
│ ├── types/ # 全局类型
│ └── logging/ # 日志系统
| # 也可以把一些重要模块单独放在根目录,例如 config , log
│
└── index.ts # 启动文件注意:也可以把一些重要模块单独放在根目录,例如 config , log等等,看业务需要。
最后,我们可以借鉴一下 angular 团队的一些代码风格指南。例如
-
总则
- 坚持每个文件只定义一样东西(例如服务或者组件)
- 考虑把文件大小限制在 400 行代码以内
- 坚持定义简单函数来组装复杂函数
-
命名
- 使用点和横杠来风格文件名,不建议驼峰
- 坚持在描述性名字中,用横杠分割单词
- 坚持遵守先描述组件特性,再描述它的类型的模式,例如
feature.type.ts
调试
接下来介绍一下,如何借助 vscode(其它编辑器,cursor,trae 是同样的方式),来调试 nest.js 和 hono.js 代码
首先我们简单介绍一下如何调试单文件 node.js 文件,这个对于我们 demo 也算比较有用。
首先,随便在跟目录建一个 index.js
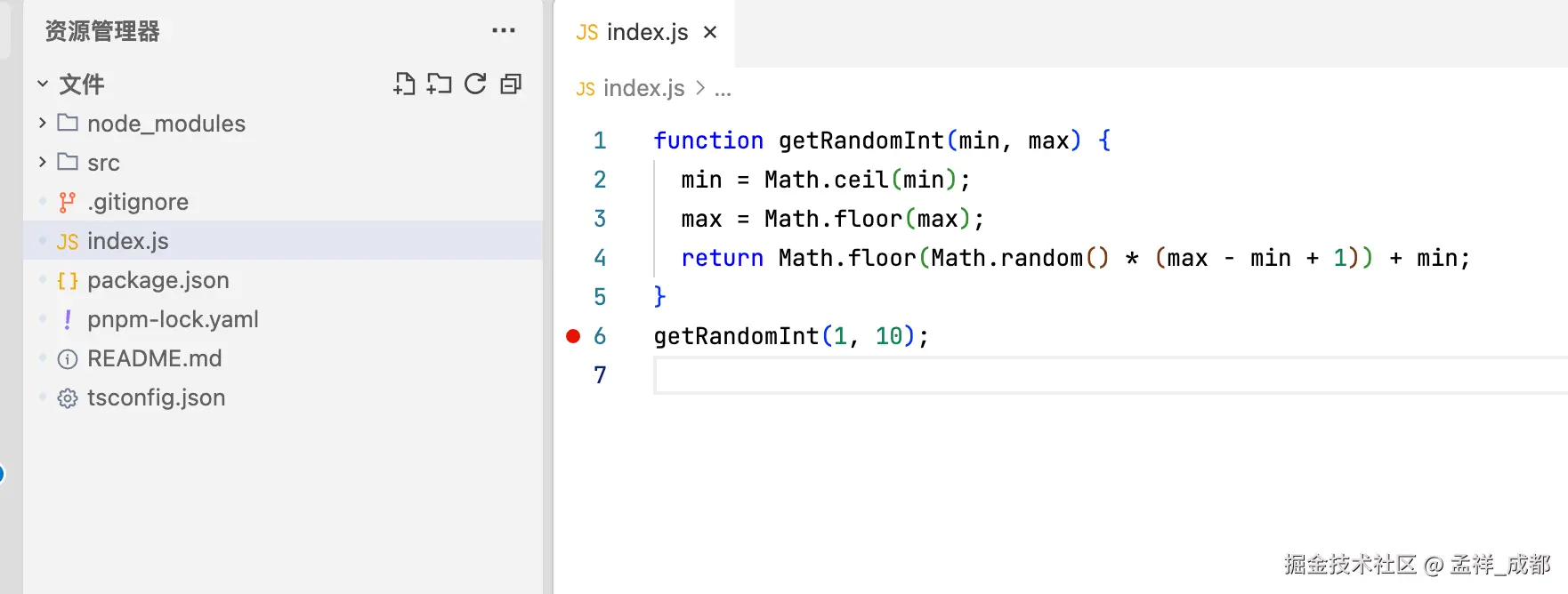
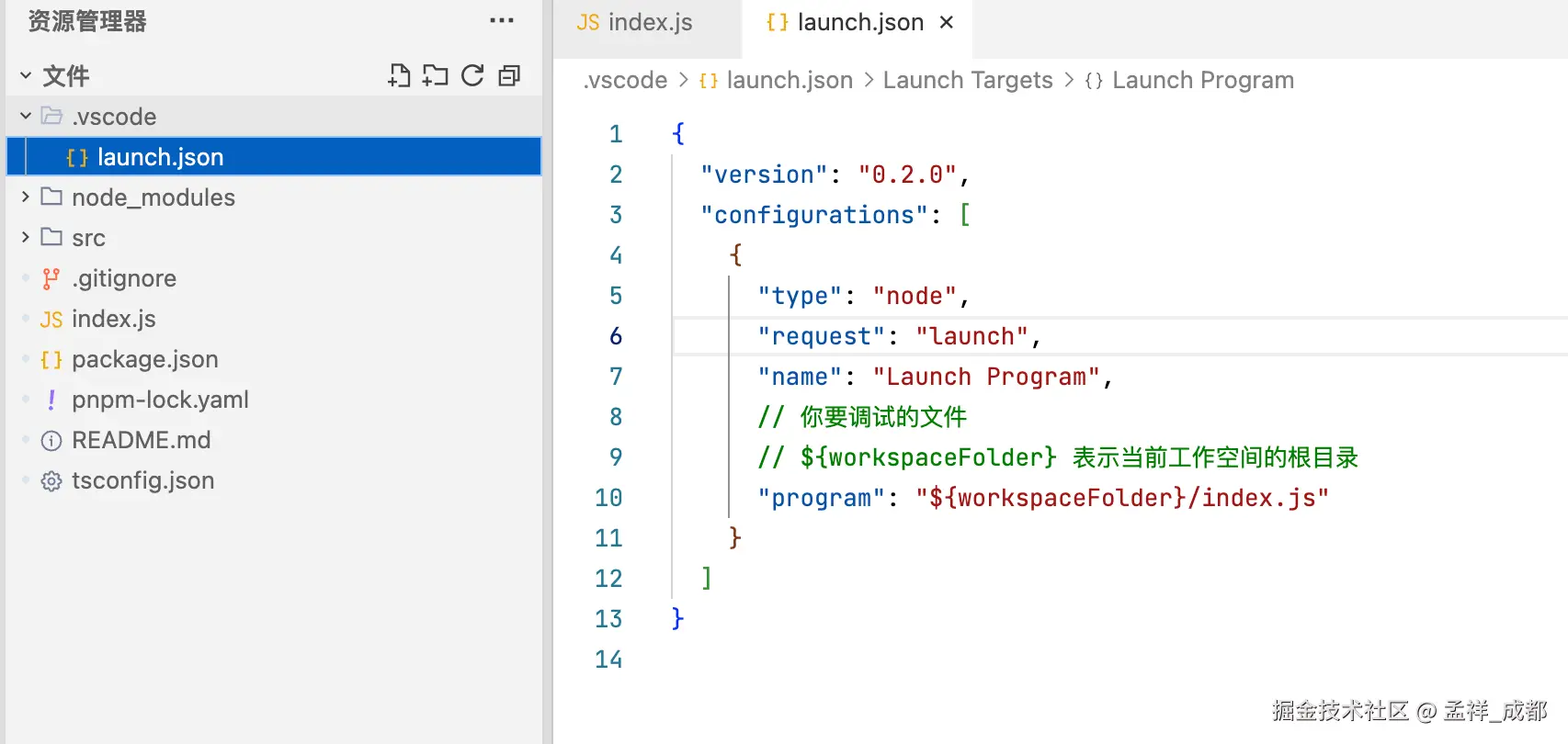
然后我们在第 6 行,打了一个断点,可以看到红色标记。然后再根目录,建立一个 .vscode 文件夹,文件夹内建立一个 launch.json
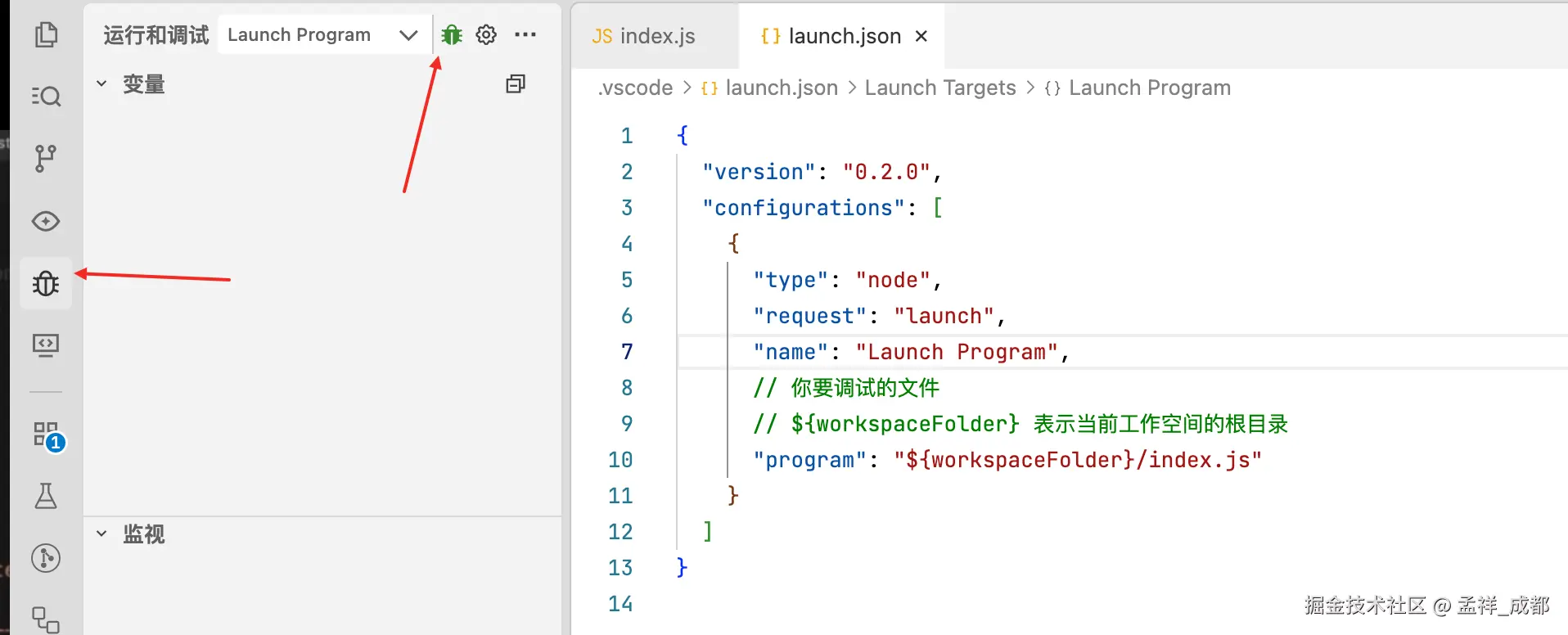
接着点击 如下的 bug 按钮,就可以调试了
调试 nest
调试 nest 和 hono 都很相似,只是 launch.json 的配置不一样,
我们 launch.json 的配置如下(调试 nest 的):
json
{
// 配置文件的版本号,遵循VSCode调试协议。0.2.0是当前常用版本。
"version": "0.2.0",
// 定义调试配置的数组,一个文件可以包含多个独立的调试配置。
"configurations": [
{
// 指定调试器类型。`node` 表示使用Node.js调试适配器,用于调试JavaScript/TypeScript。
"type": "node",
// 调试请求类型。`launch` 表示启动一个新程序进行调试;另一种是`attach`(附加到已运行进程, 这个不纠结,我们都用 launch)。
"request": "launch",
// 在VSCode调试下拉菜单中显示的名称,随便起个就行。
"name": "Launch Program",
// 指定实际用来运行程序的命令。这里使用`pnpm`包管理器作为启动器。
// 如果不设置此项,默认值为`node`。
"runtimeExecutable": "pnpm",
// 传递给`runtimeExecutable`(pnpm)的命令行参数。
// 等同于在终端执行:`pnpm run start:dev`
"runtimeArgs": ["run", "start:dev"],
// `runtimeVersion`主要用于通过`nvm`等版本管理器切换Node版本。
"runtimeVersion": "20.16.0",
// 调试时跳过(不进入)的文件。
// `<node_internals>/**` 表示跳过所有Node.js内置核心模块代码,使调试更聚焦于应用自身。
"skipFiles": [
"<node_internals>/**"
]
}
]
}这里的关键是什么呢,就是 runtimeExecutable + runtimeArgs, runtimeExecutable 代表我们执行的命令使用 pnpm, 你可以改为 yarn, npm,都行,然后执行的命令参数runtimeArgs,合起来就是
arduino
pnpm run start:dev为什么这样呢,因为 start:dev 是 nest.js 的 package.json 中注明的启动开发环境的命令,如下:
sql
"scripts": {
"build": "nest build",
"format": "prettier --write \"src/**/*.ts\" \"test/**/*.ts\"",
"start": "nest start",
"start:dev": "nest start --watch",
"start:debug": "nest start --debug --watch",
"start:prod": "node dist/main",
"lint": "eslint \"{src,apps,libs,test}/**/*.ts\" --fix",
"test": "jest",
"test:watch": "jest --watch",
"test:cov": "jest --coverage",
"test:debug": "node --inspect-brk -r tsconfig-paths/register -r ts-node/register node_modules/.bin/jest --runInBand",
"test:e2e": "jest --config ./test/jest-e2e.json"
},当然,你可以用 start 命令,start:debug 命令都行,假设就用
perl
// 指定实际用来运行程序的命令。这里使用`pnpm`包管理器作为启动器。
// 如果不设置此项,默认值为`node`。
"runtimeExecutable": "pnpm",
// 传递给`runtimeExecutable`(pnpm)的命令行参数。
// 等同于在终端执行:`pnpm run start:dev`
"runtimeArgs": ["run", "start:dev"],然后我们在 app.controller.ts 上打个断点:
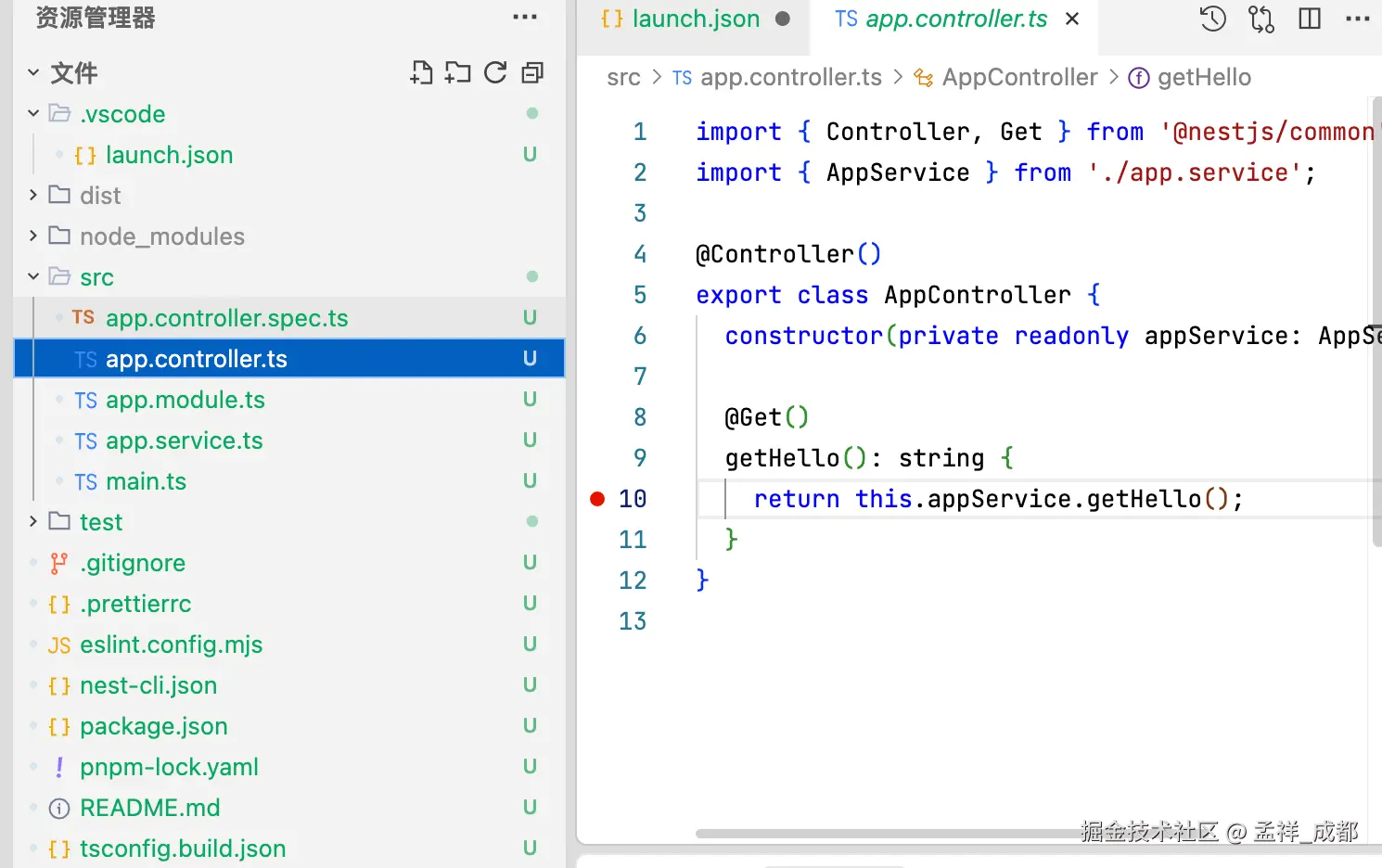
然后启动调试
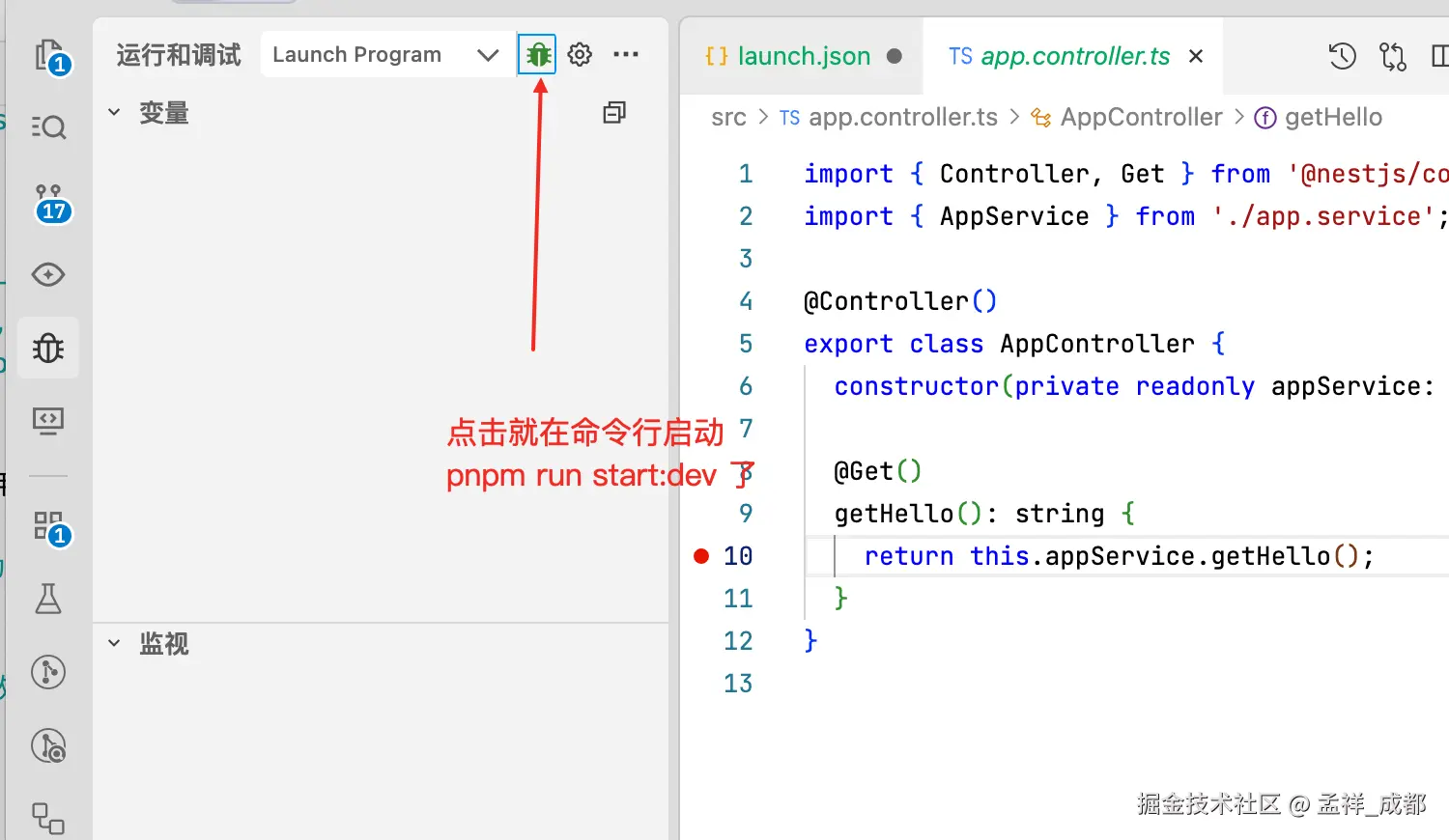
点击后,相当于在命令行输入:
arduino
pnpm run start:dev接着你浏览器访问 http://localhost:3000 就能触发断点了!
调试 hono
所以根据上面的理论,我们来创建一个 launch.json,用来调试 hono
json
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"runtimeExecutable": "pnpm", // 核心:告诉调试器用pnpm来运行
"runtimeArgs": ["run", "dev"], // 传给pnpm的参数:运行"dev"脚本
}
]
}同理,其实就是触发了:
arduino
pnpm run dev命令, dev 这个命令其实就是 hono 项目 package.json 中的内容:
json
"scripts": {
"dev": "tsx watch src/index.ts",
"build": "tsc",
"start": "node dist/index.js"
}容器部署
接下来是很长的关于 docker 和我们前端全栈相关的知识,有深入的原理介绍,有兴趣的同学可以一起交流。
为什么需要 Docker?
即便是纯前端开发者,不涉及 Node.js、Nginx 或数据库等服务器相关软件,在中小企业部署应用时,后端团队或项目经理常常会要求前端团队提供一个 Dockerfile,以便将前端应用部署到 Nginx 上。这种要求在容器化时代变得越来越普遍。所以是有必要了解容器的知识的。
容器化的基本概念
在容器化时代,通常通过 Dockerfile(用于描述如何构建 Docker 容器的配置文件)构建开发或生产环境的 Docker 镜像,然后启动这些镜像,使外部网络可以访问对应的应用。
在 Docker 流行之前,前端应用的部署方式一般是直接在服务器上下载相关软件(如 Nginx、MySQL 或 PostgreSQL),配置并启动服务,再将打包后的前端内容放入 Nginx 的指定目录,以便外部访问。这种方式被称为物理机直接部署。
为何转向容器化部署?
容器化部署的优势主要体现在以下两个方面,我们用前端的视角去理解:
- 环境一致性:
- 前端常见的问题,为什么在 Chrome 中功能正常,但在其他浏览器中却无法运行?
- 简化环境配置:
- 前端项目通常需要配置 ESLint、Prettier、TSConfig、Vite/Webpack 等工具。这些配置繁琐,且需要一定的知识才能定制适合项目的配置。为了解决这些问题,前端社区提供了许多 CLI 工具,如 React 的 create-react-app、Vue 的 Vue CLI、Next.js 的 @nextjs/cli 等,这些工具为项目提供了现成的模板,并在 Babel/SWC 和 Browserslist 的配置中解决了兼容性问题。
同样,服务器端也面临环境一致性和配置繁琐的问题,并且这些问题相当棘手。为什么会这样呢?我们可以回顾一下 Docker 流行之前的 PaaS 项目。
PaaS 的背景
PaaS(Platform as a Service)是云计算的重要服务模型,旨在提供一个完整的应用开发、运行和管理环境,使开发者能够专注于编写代码,而无需担心底层基础设施或操作系统。
PaaS 受欢迎的原因
PaaS 项目受到广泛接纳的一个主要原因是它提供了"应用托管"能力。如今,许多人使用阿里云、腾讯云、AWS 等云服务,实际上就是将本地应用托管到云端。然而,这一部署过程常常会遇到云端虚拟机与本地环境不一致的问题。因此,当时的云计算服务竞争的焦点在于谁能更好地模拟本地服务器环境,从而提供更优质的"上云"体验。而开源 PaaS 项目的出现,正是为了有效解决这一问题。
docker 的出现
正当大家比谁能更好模拟本地服务器环境的时候,docker 跳出来说,对不起,在做的各位都是垃圾。。。我能完全模拟本地服务器环境,嘿嘿!
并且 docker 提供了非常便捷的打包机制, 并且这个压缩包包含了完整的操作系统文件和目录,也就是包含了这个应用运行所需要的所有依赖。只需:
arduino
docker build 打包自己的服务
docker run 启动自己的服务如此,docker 轻松击败了 pass 本身的打包机制,后来逐渐使容器技术成为云服务的基础设施之一。
你可以想象,就跟前端使用 vite 和 webpack 一样,一键 npm run build xxx 打包后,你的前端应用能在各个浏览器上运行,并帮助我们解决了浏览器兼容性问题,如此便捷,谁能不喜欢这样的技术呢?
所以这个小节我们可以回答常见的面试题:
- 为什么需要容器化 (docker)?
既然 docker 这么好用,那 docker 镜像,docker 容器,docker 镜像仓库等等常见概念是什么意思呢?我们拿前端的 npm 包管理来帮助我们理解。
Docker 必需了解的基础概念
1. Docker 镜像和 Docker 容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。
- Docker 镜像 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。
- Docker 容器 的实质就是一个进程,但是跟普通进程不一样的是,因此容器可以拥有自己的
root文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。
2. Dockerfile
dockerfile 是一个文本文件,包含了一系列指令,一般我们都是用这个文件配合 docker build 命令来构建 docker 镜像。
3. Docker Client、Docker hub、Docker Daemon
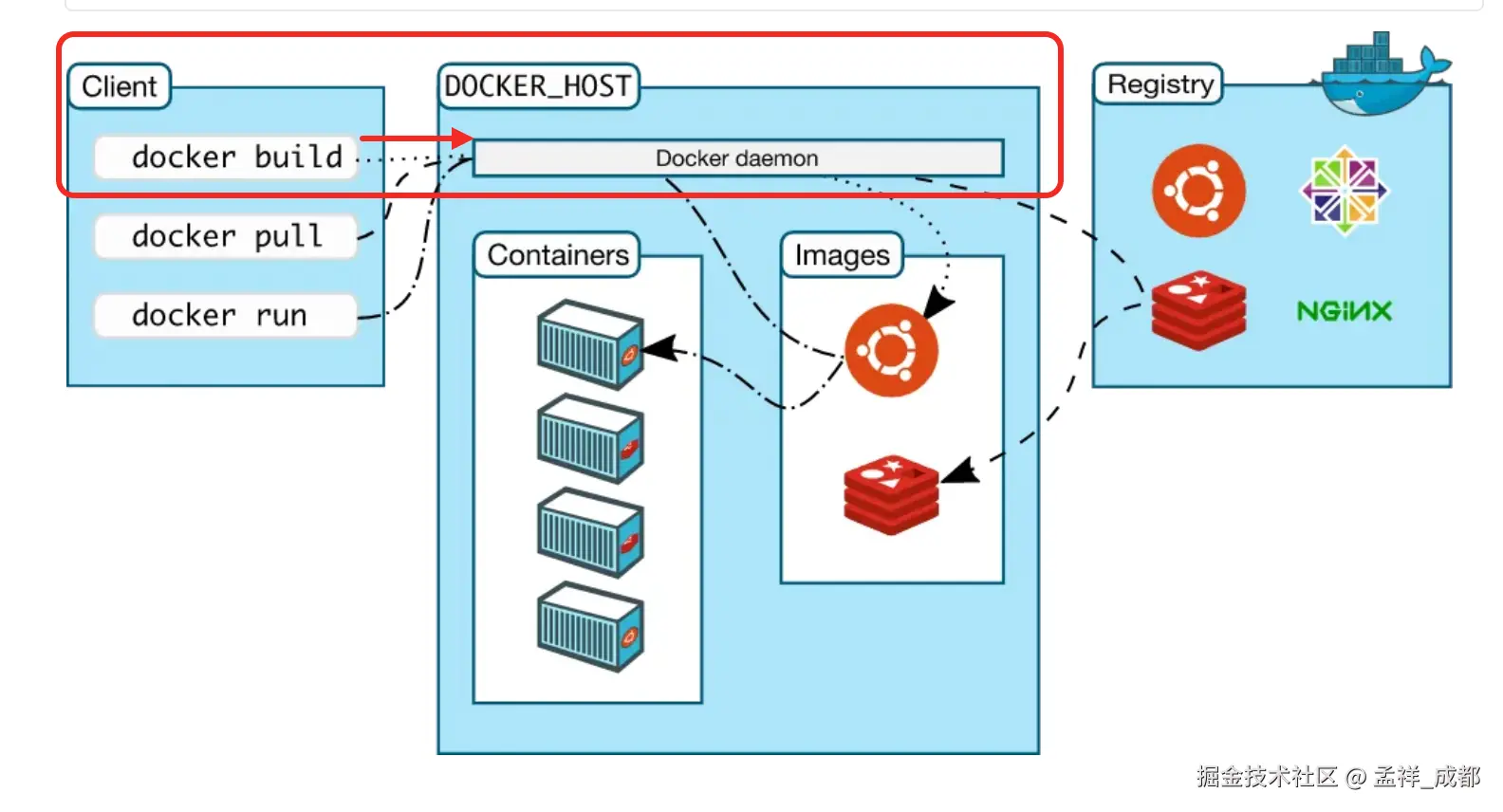
关系如下图:
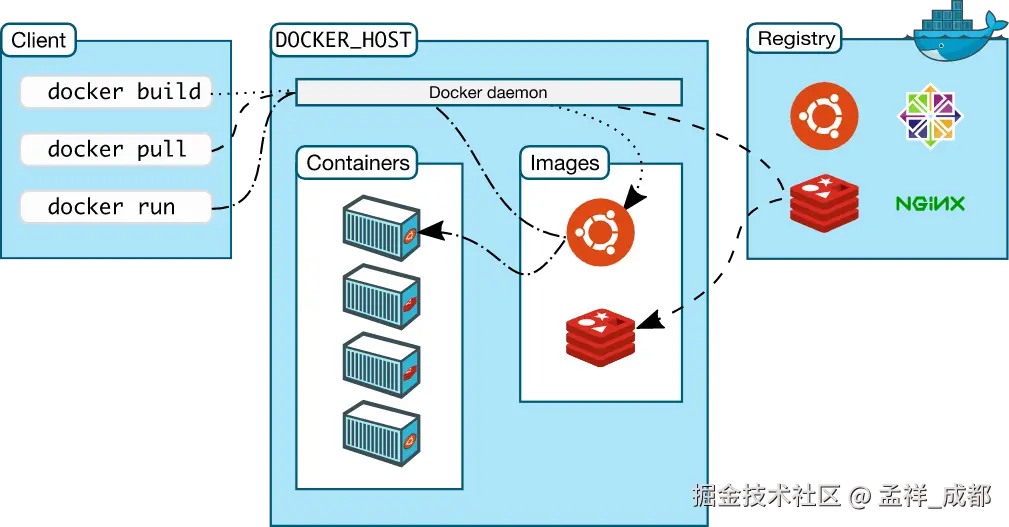
上图中涉及 3 个重要的概念
- Docker Hub:Docker Hub 是一个云端托管的Docker镜像库,用户可以在其中存储和共享 docker 镜像。它类似于 npm 仓库。
- Docker Daemon:守护进程是一个后台服务,负责管理 docker 容器和镜像。它监听来自的 docker 客户端的命令,并执行相应操作。
- Docker Client:允许用户与守护进程交互的命令行工具。
【延伸补充】深入原理1:一定要理解 Docker 镜像的分层的原理
上面我们说了,Docker 镜像 是一个特殊的文件系统,其中有一个特别重要的特性,称之为文件系统分层。为了说明这个原理,我们需要从 linux 本身的文件系统讲起。
首先 linux 启动的时候,首先加载的是 bootfs 文件系统,它包含了 boot 加载器和 kernel 内核。kernel 内核作用是什么呢?我们知道计算机是由硬件构成的,例如 cpu、主板、外设、内存等等,最终这些硬件会被操作系统接手管理,例如,将在硬盘的程序映射为一个个动态的进程,然后增加 cpu 调度算法,让每个进程按照特定的规则不断运行,还需要管理内存,不断的读取内存指令给 cpu 运行。。。
然后 linux 会挂在 rootfs 文件系统,什么是 rootfs 呢?作用是什么呢?我们知道在玩 windows 操作系统的时候,C 盘一般都是用来存储操作系统相关的文件的,例如 C 盘下的 Program Files 一般用来存放操作系统相关的配置文件。
而 linux 中的 rootfs 在初始化的时候,也是把操作系统相关的文件放入其中。linux 有很多不同的发行版本,例如 centos,ubantu 等等,他们都有自己的 rootfs,规则有所不同。
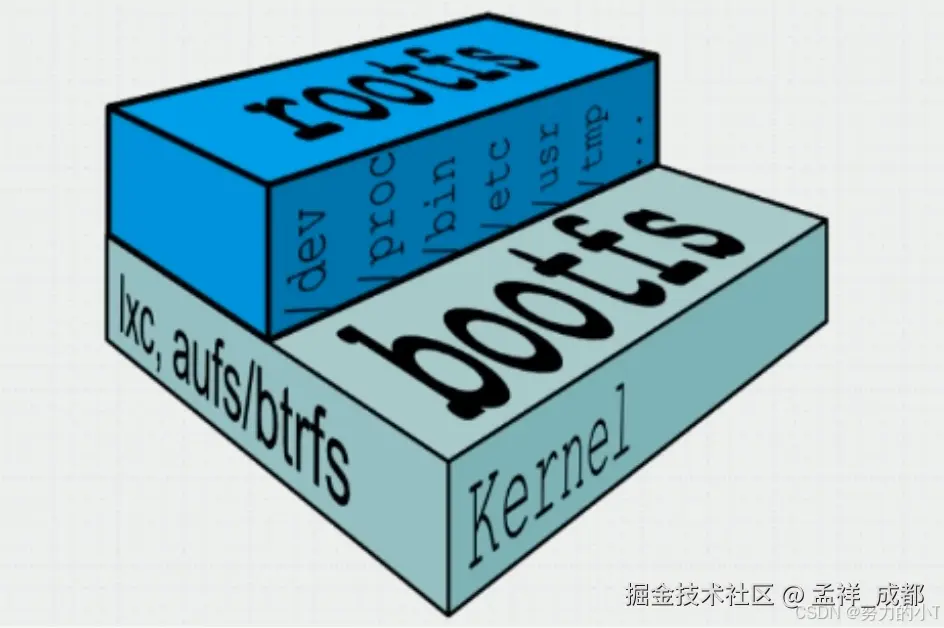
而上面说的两个文件系统,在 docker 中,并不是混在一起的,而是如上图分层了的,这意味着,如果正在使用不同的 docker 镜像,他们最底层的 bootfs 很可能是一样的(相同的 linux 版本),那么这些镜像就可以共享这一层,而不是每个镜像都分别有一个 bootfs。
同理 rootfs 也是一样,如果我们使用的镜像都是基于 ubantu 的 linux 发行版本,版本号也是一样的话,那么 rootfs 也是可以共享的。
这样就会大大降低 docker 的体积,这也是为什么大家说 docker 轻量的原因。
docker 镜像本身提供的这些数据层是只读的,我们后续用 dockerfile 去自定义我们自己的镜像时,实在可读层上面加一个读写层,但是修改 docker 的,所以共享底层的数据层也不会影响我们定制化的 docker 镜像。

为什么理解分层如此重要呢?我们举个例子(以下 dockerfile 文件每个命令是什么意思会详细讲解,现在不用在意),以下 docker file 中,我们注意 RUN 命令:
sql
FROM ubuntu:20.04
RUN apt-get update
RUN apt-get install -y python3
RUN apt-get install -y python3-pip
RUN apt-get clean这里执行了 4 个 RUN 命令,而每个 RUN 命令都会单独在 docker 镜像上建立一个单独的读写层,这样会增大构建后的 docker 镜像体积,我们可以将其合并:
sql
FROM ubuntu:20.04
RUN apt-get update && \
apt-get install -y python3 python3-pip && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*同样的,如果分层中,分层的内容没有变,docker 会重复利用这些已经打包好的层,什么意思呢?我们前端应用打包的时候,往往 package.json/package.lock.json 的依赖是没有变化的,所以我们如果能利用之前已经下载好的 npm 包的层,就不用重复下载了。
perl
# 使用 Node.js 作为基础镜像
FROM node:22-slim
# 将 package.json 和 package-lock.json 复制到容器中
COPY package*.json ./
# 安装依赖(会在此层缓存 node_modules)
RUN npm install
# 复制应用程序的其他源代码到容器中
COPY . .
# 暴露应用程序运行的端口
EXPOSE 3000
# 启动应用程序
CMD ["npm", "start"]以上我们会看到 RUN npm install 这一步,如果命令跟以前一样,会利用缓存,不会下载 npm 包,具体缓存规则,官方叙述如下(建议后续看完 dockerfile 章节后再回来看这部分,非常重要):
在镜像的构建过程中,Docker 会遍历 Dockerfile 文件中的指令,然后按顺序执行。在执行每条指令之前,Docker 都会在缓存中查找是否已经存在可重用的镜像,如果有就使用现存的镜像,不再重复创建。如果你不想在构建过程中使用缓存,你可以在 docker build 命令中使用 --no-cache=true 选项。 但是,如果你想在构建的过程中使用缓存,你得明白什么时候会,什么时候不会找到匹配的镜像,遵循的基本规则如下:
- 从一个基础镜像开始(
FROM指令指定),下一条指令将和该基础镜像的所有子镜像进行匹配,检查这些子镜像被创建时使用的指令是否和被检查的指令完全一样。如果不是,则缓存失效。 - 在大多数情况下,只需要简单地对比
Dockerfile中的指令和子镜像。然而,有些指令需要更多的检查和解释。 - 对于
ADD和COPY指令,镜像中对应文件的内容也会被检查,每个文件都会计算出一个校验和。文件的最后修改时间和最后访问时间不会纳入校验。在缓存的查找过程中,会将这些校验和和已存在镜像中的文件校验和进行对比。如果文件有任何改变,比如内容和元数据,则缓存失效。 - 除了
ADD和COPY指令,缓存匹配过程不会查看临时容器中的文件来决定缓存是否匹配。例如,当执行完RUN apt-get -y update指令后,容器中一些文件被更新,但 Docker 不会检查这些文件。这种情况下,只有指令字符串本身被用来匹配缓存。
一旦缓存失效,所有后续的 Dockerfile 指令都将产生新的镜像,缓存不会被使用。
【延伸补充】深入原理2:一定要理解什么是构建上下文
上面有一个很容易混淆的路径问题,COPY package*.json ./ 中 package*.json 指的并不是 docker build 命令的目录,也不是 Dockerfile 所在的目录,而是执行上下文的目录。执行上下文目录我们是在 docker build 的时候指定的,这里我们指定的 .,表示执行 docker build 命令时的目录。
为什么这个概念如此重要,很有可能你你设置的不对,根本找不到 package*.json,例如你这样
bash
COPY ../package*.json ./../package*.json,指的是构建上下文上一层目录的 package*.json,其实是找不到的,因为我们将构建上下文复制到 docker host 的时候,docker 只会复制构建上下文内的内容(并且除开 .dockerignore file 指定的排除的内容)。
所以你在构建上下文之外找 package*.json,肯定是找不到的。
并且有相当多网上的人误以为 . 是指定 Dockerfile 所在目录呢?这是因为在默认情况下,如果不额外指定 Dockerfile 的话,会将上下文目录下的名为 Dockerfile 的文件作为 Dockerfile。
这只是默认行为,实际上 Dockerfile 的文件名并不要求必须为 Dockerfile,而且并不要求必须位于上下文目录中,比如可以用 -f ../Dockerfile.php 参数指定某个文件作为 Dockerfile。
当然,一般大家习惯性的会使用默认的文件名 Dockerfile,以及会将其置于镜像构建上下文目录中。
最后最最重要的就是需要写一份 .dockerignore 文件,例如,我们前端项目往往都有 node_modules 目录,而且体积相当大,所以没必要将其复制到 docker host。
- 这会显著增加镜像的体积,从而影响镜像构建时间和传输效率。
node_modules中的某些依赖可能是平台相关的(例如,使用了原生代码或编译步骤),在不同的操作系统(如 Windows 和 Linux)上会有所不同。
好了,我们接着编写完 dockerfile 文件继续说。
然后,就可以运行 docker 镜像
arduino
docker run -d -p 3000:80 react-app-d:以后台模式运行容器。-p 3000:80:将本地的 8080 端口映射到容器的 80 端口。
然后本地访问 localhost: 3000,或者你的机器有外网地址,使用 <外网地址>: 3000,访问即可。
这里还会牵扯到一个需要深入讨论的内容,就是容器网络的原理,我们后续再谈。
这里我们总结一下一些常用的 docker 命令,帮助大家快速用起来 docker。
常用命令总结
下载镜像:docker pull <镜像名>,例如下载 node.js 22 版本的镜像
docker pull node:22-slim注:可以用 docker hub 来搜索支持的版本。方法如下:
- 进入docker hub的官网,地址:hub.docker.com
- 然后搜索需要的镜像:
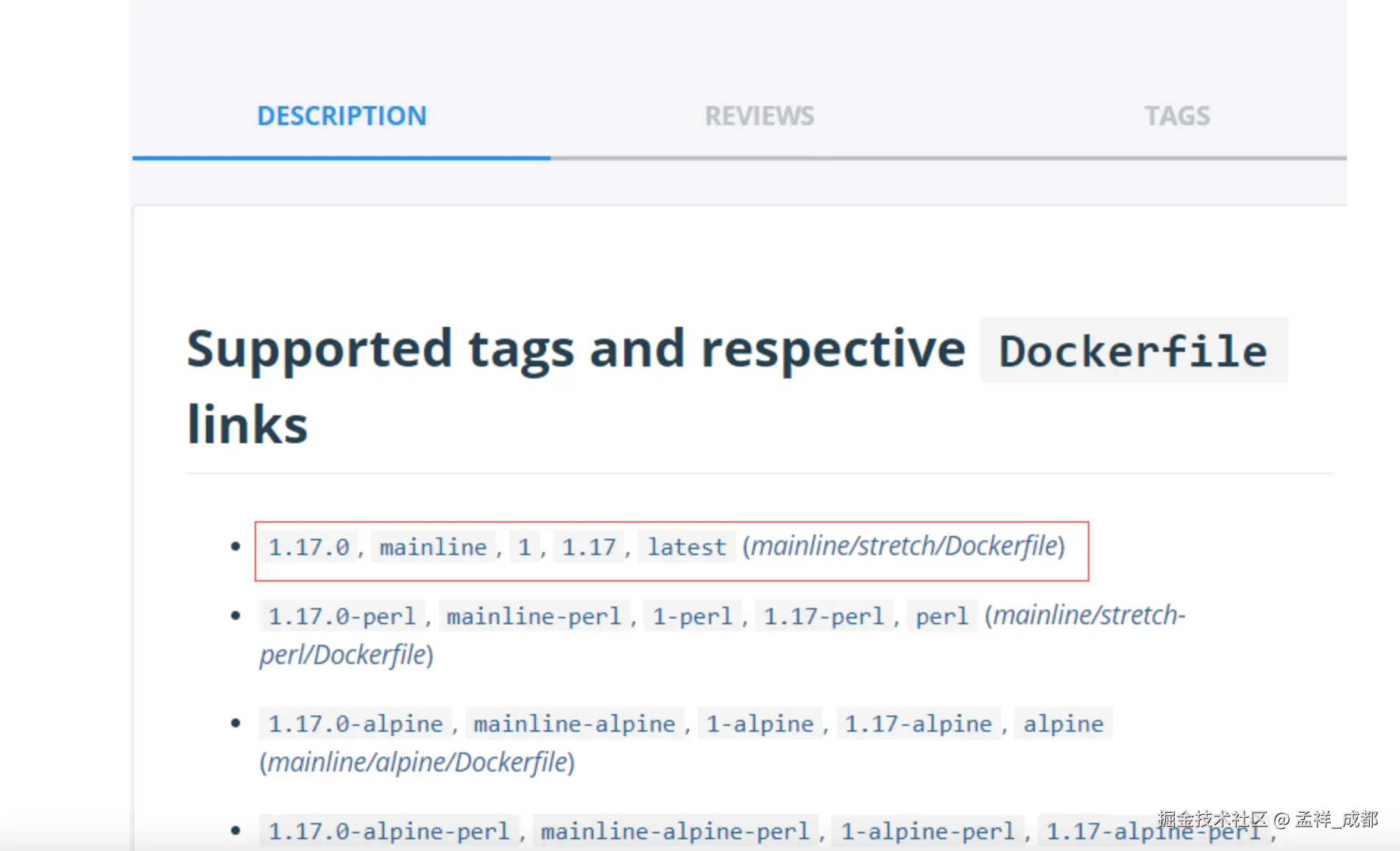
- 查看镜像支持的版本:
列出镜像:
docker images 
删除镜像:docker rmi -f <镜像名>,例如:
docker rmi -f nginx新建并启动容器:docker run -d -p <本地端口>:<容器端口> <镜像名>,例如
arduino
docker run -d -p 80:80 --name nginx nginx:1.17.0-
-d 选项:表示后台运行
-
--name 选项:指定运行后容器的名字为nginx,之后可以通过名字来操作容器
-
-p 选项:指定端口映射,格式为:hostPort:containerPort
列出容器:
docker ps查看运行中的容器:
docker ps如果加入 -a 参数,即使暂停的容器也会被列出来。
停止容器:
arduino
docker stop <容器ID | 容器名字>删除容器:
bash
docker rm <容器ID | 容器名字>在宿主机查看docker使用cpu、内存、网络、io情况:
xml
docker stats <容器ID | 容器名字>进入Docker容器内部的bash
bash
docker exec -it <容器名字> /bin/bash注意,有的镜像里面没有 bash 命令,例如 nginx,可以将 /bin/bash 改为 /bin/sh
以上的知识,足够前端应付常见的场景了,遇到问题搜索一下,看懂也不是难事。其实容器的网络,是比较特殊的,因为容器实际上看起来是有自己独立的文件系统,独立的网络,独立的进程的(也就是在容器中,你会看懂容器进程的 id 是 1)等等。
既然有自己独立的网络,那么容器的网络如何跟外界打通,原理又是什么呢?(这个问题特别重要,无论对于你自己本地调试,还是生产环境解决容器无法访问的问题)
既然有自己独立的文件系统,那么容器销毁,容器里面的文件也随之销毁,那么容器如何做到将文件跟物理机上的文件系统共享的呢?
【延伸补充】深入原理3:docker 容器的底层三大核心技术
三大核心技术分别是 namespace、Cgroup 以及联合文件系统,联合文件系统上面已经讲了,现在就剩下 namespace 和 Cgroup 了。我们先来看看 pid namespace 是什么。
首先再次强调,容器就是一个进程。举个例子

我们首先使用以下命令来获取到容器的进程 id 为 2526
bash
docker inspect <容器 id> | grep Pid 然后使用 ps 命令来过滤出 2526 进程
perl
ps -ef | grep 2526发现确实有对应的进程。
但是跟普通进程不一样的是,容器的进程利用 namespace 技术,让我们进入容器后,发现容器主进程的 pid 是 1 ,而不是 2526。也就是容器使用了"障眼法",来让自己跟别的容器都隔离开。就拿进程隔离来说,容器是如何修改进程视图的呢?如下图:
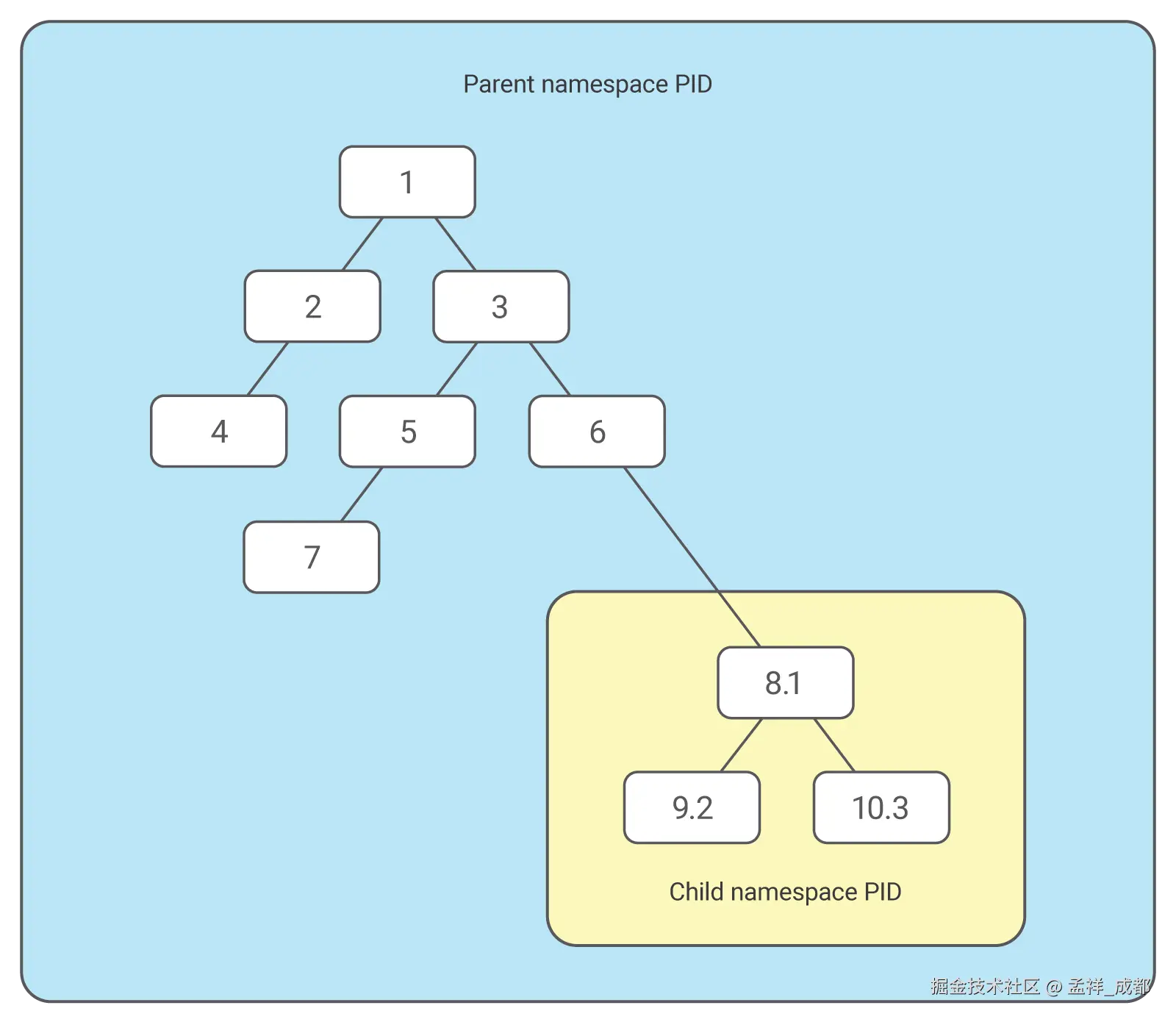
如上图,1、2、3、4、5、6、7、8、9、10,都是在物理机操作系统上的进程号(PID),而进入容器后,PID 8 是容器的主进程,linux 将其修改为进程号(PID)为 1,子进程也同样修改 PID,这样你在容器里,看到主进程是 PID 1,但是你退出容器,查看这个容器的进程号,就是 8。
namespace 不仅仅隔离了进程的 pid,还包括网络、用户、IPC 等等。接着我们看看 Cgroup 是什么。
你想想,虽然视图可以改变,但是却没法限制这个容器对 cpu 的使用,所以是有可能单个容器把 cpu 跑满的。所以如果能限制 cpu、内存的使用就更好了,Cgroup 就是做这个事的。
Cgroup 的原理如下图:

Cgroup 对不同资源进行了分组,例如 cpu 总共是 100%,假设分配给某个容器是 25%,当你进入容器中,你看到的自己 cpu 总共是 100% ,也就是这个容器里的 100% 是假的,其实是从真实的 25% 里面去分的。
Cgroup 如何操作是有对应的 linux 命令的,这里我们就不深入了,因为性价比并不高,用好 docker 就可以了。
【延伸补充】深入原理4:docker 容器网络的秘密
为了更通俗的解释 docker 的桥接网络,我们先从计算机网络基本的知识讲起:
如下图,只需要一根网线相互连接,然后在计算机上配置一下自己的 ip 地址(在一个网段里),两台计算机就可以相互通信了。例如 A 计算机的 ip 我们写死 ip 到网卡,地址为 192.168.1.1/24,B 计算机是 192.168.1.2/24 ,他们都是 192.168.1.xxx 网段。

有些同学可能不理解,为啥要分配 ip 地址?因为我们很多通信协议是基于 ip 协议的,例如 http,tcp。所以必须分配 ip 地址,才能让数据包走出网卡。我们接着聊:
现在我们多加一些电脑,这时候一根网线肯定就不够了,我们就加入一个交换机(虚拟交换机是有 ip 的,但是现实生活中的交换机是没有 ip),如下图
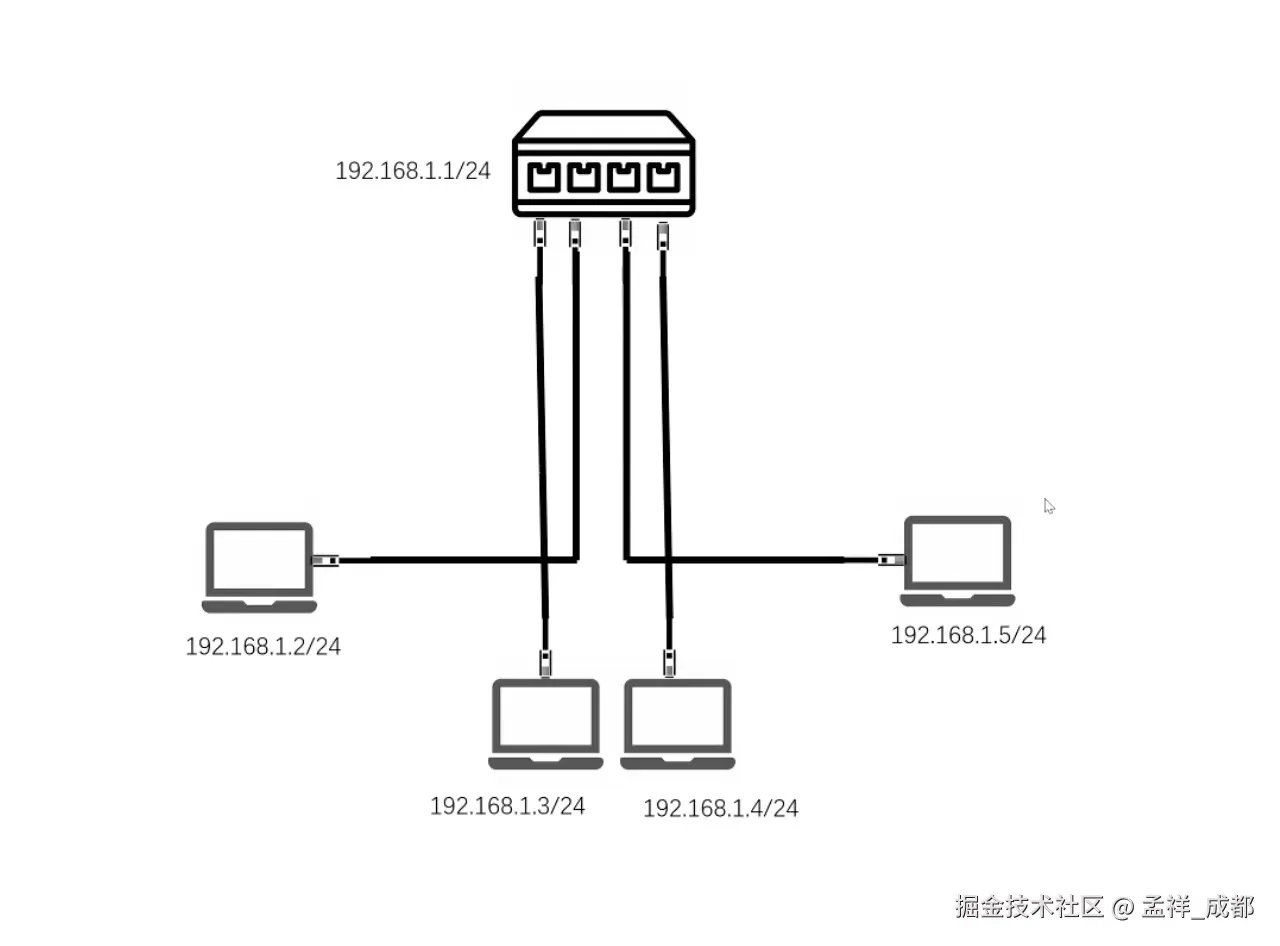
假设交换机的 ip 是 192.168.1.1/24,这个交换机还可以自动分配 ip(dhcp协议),只要计算机连接交换机,就会自动分配一个不重复的 ip 地址,那么多台计算机互相通信就解决了。
其实 docker 内部默认有一个叫做 docker0 的网桥,这个网桥工作机制就跟我们上面说的交换机类似。而容器默认情况下,会连接 docker 0 网桥。如下图:
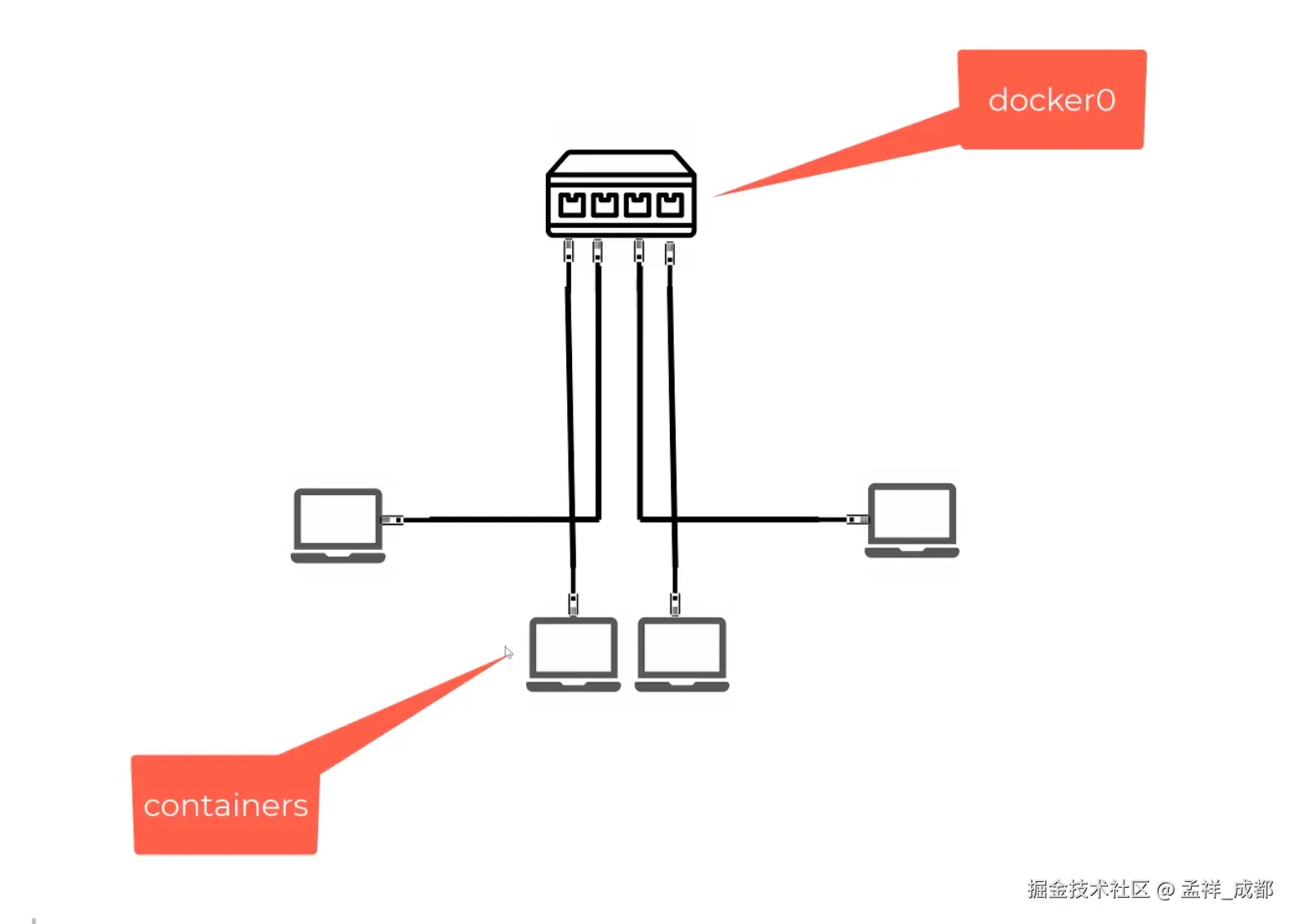
这样容器之间互通的问题我们就解决了。
那么如何解决容器跟外部网络通信的问题,例如某个容器去访问微信登录。
如下图,其实 docker0 是连接到我们真实物理机的网卡 eth0 来转发数据,从而让容器的数据通过 -> docker0 -> eth0 发送到计算机外部
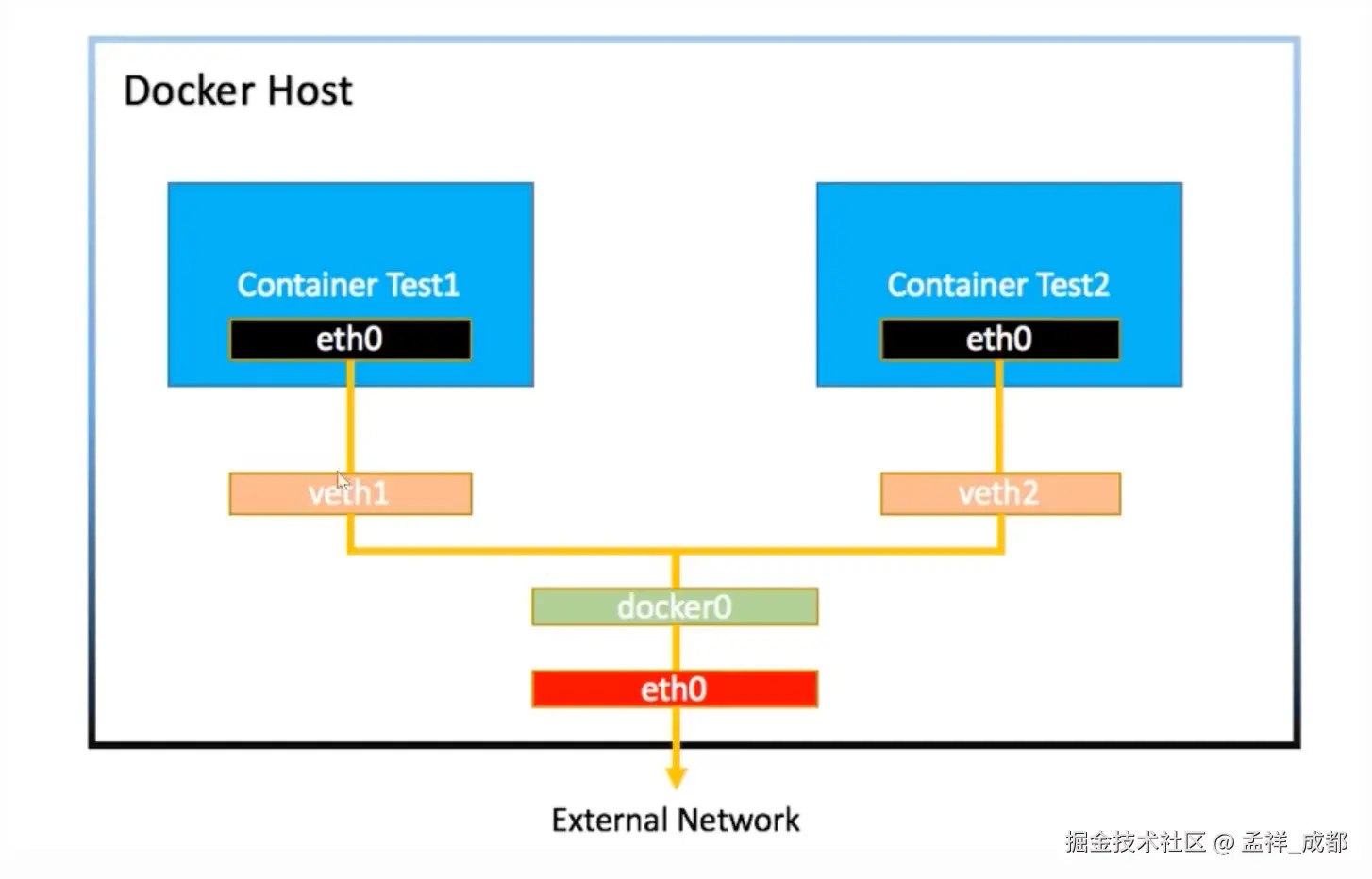
这里又有问题了,容器内部的 ip 往往是一个内部地址,什么是内部地址?你会看到,我们前端启动前端应用,经常看到启动的 ip 地址是 192.168.x.x,你回到家启动前端应用分配的地址居然是一样的 192.168.x.x。我们知道 ip 地址必须全网唯一,为啥在家里分配的 ip 和在公司分配的 ip 一样呢?
这是因为 ip 地址规定了一些只能在内网通讯的地址,不能用在外网,例如 192.168.x.x 就是不会用在外部网络访问的 ip 地址。
这对于 docker 容器访问外部网络就有问题了,你想想 docker容器 -> docker0 -> eth0 将数据包传给了微信服务器,微信服务不能说我回传的 ip 地址是 docker容器的 ip,因为 docker容器的 ip 是内部地址,不能在网络上传输。
这里又涉及一个概念,叫 nat 转换,也就是 docker 容器将数据包传给 eth0 的时候,会改写自己数据包发送端的 ip 地址为 eth0 的公网地址。
这样就解决了容器访问外部网络的问题了。
问题又来了哦,那返回给 eth0 的数据,如何知道这个数据包最终转发给哪个容器呢?这里涉及到一个叫做 iptables 的工具(NAT 转换也是依赖它),它可以记录转发规则,例如如果这个数据是从 80 端口出去的,那么返回的时候,就返回给 A 容对应的内部 ip。
【延伸补充】深入原理5:docker 容器文件隔离和共享的秘密
文件隔离
docker 容器的文件系统是跟宿主机隔离的,在 docker 里,我们能看到一份独立的文件系统。linux 如何实现的呢?
实际上 linux 也是用了障眼法做到的,如下图,首先假设下图是正常的某台 linux 机器的目录结构:
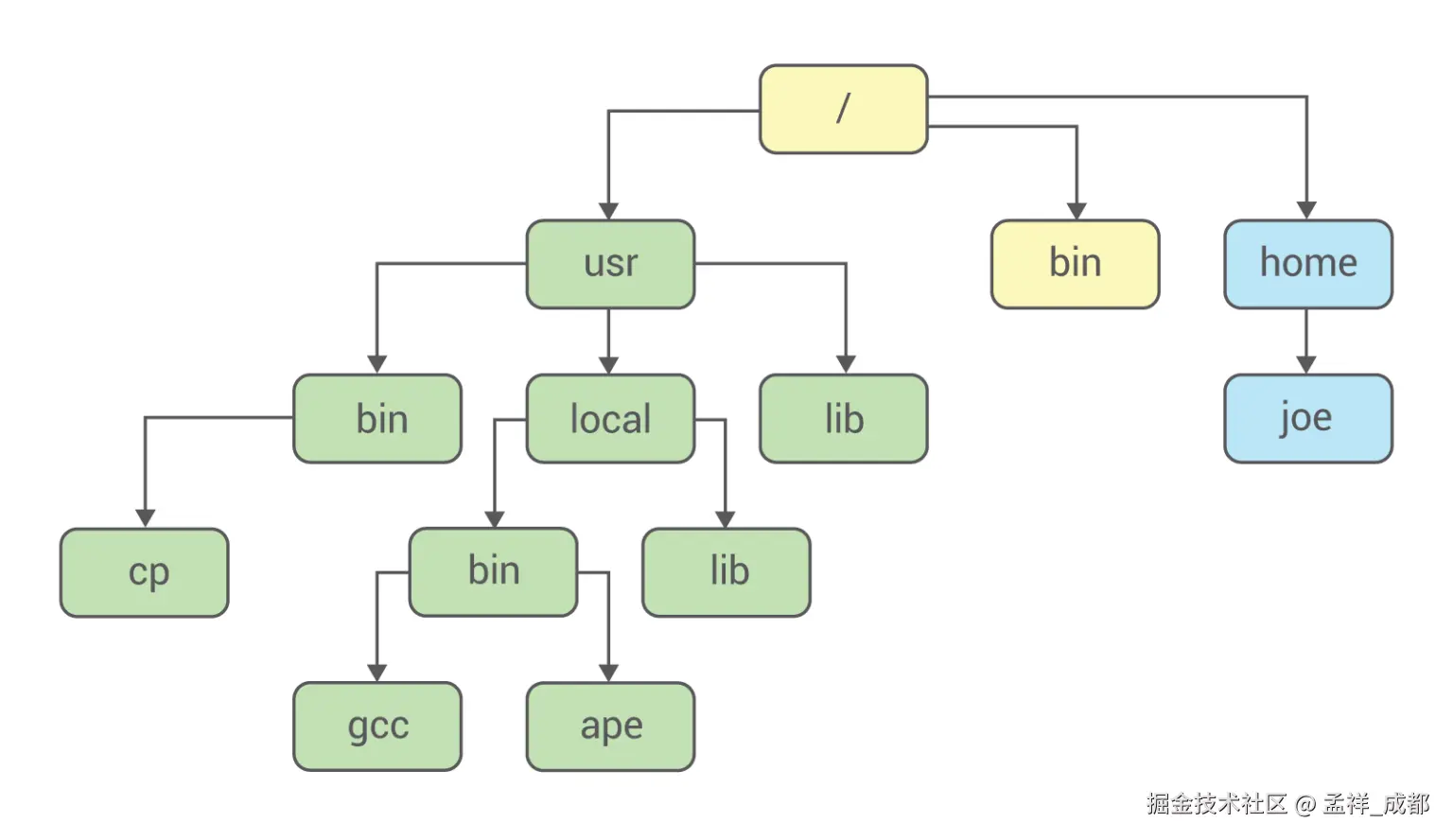
然后我们希望 docker 容器跟 joe 目录(最右边最后一个目录)拿来作为容器的根目录,使用 linux 的 Mount Namespac 功能 + chroot 命令,结果如下图:

容器的根目录,挂载到了宿主机的 joe 目录。由于 Mount Namespace 技术的特性,这个容器的根目录对于宿主机是看不见的。
而这在某些情况下不是我们想要的。比如数据库文件,我们想留在宿主机上,这样重启容器的时候,依然保留了数据库的数据。
而这里要使用到的挂载技术,就是Linux的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
文件共享
由于容器的特性,如果容器删除,那么容器里的数据也会删除,之前的挂载功能也会解除。可是在某些情况下,我们希望保留容器里的数据,例如数据库,方便再下一次启动镜像的时候能共享之前容器的数据。
这个功能在 docker 叫做绑定 Volume 功能。 这个功能的实现其实很简单,之间我们讲的绑定挂载,其实需要分为两步,第一步开启 Mount Namespace,此时容器内部仍然可以看到宿主机的目录,但是宿主机看不到容器的目录,第二步执行类似 chroot 命令,可以简单理解为执行后,容器就看不到宿主机目录了。
所以我们可以在第一步之前,把 Volume 指定的宿主机目录(比如/home目录),挂载到指定的容器目录(比如/test目录)在宿主机上对应的目录上,这个 Volume 的挂载工作就完成了。
最后补充
补充,之前前端部署的 dockerfile 一般都会用分阶段构建的方法,首先借助 node.js 镜像打包前端应用,然后将打包好的内容放入 nginx 镜像中,最后借助 nginx 作为 web 服务器,来让外网访问。我们简单实现一下,可用在生产环境:
bash
# Use the official Node.js runtime as the base image
FROM node:20-slim as build
# Set the working directory in the container
WORKDIR /app
# Copy package.json and package-lock.json to the working directory
COPY package*.json ./
# Install dependencies
RUN npm install
# Copy the entire application code to the container
COPY . .
# Build the React app for production
RUN npm run build
# Use Nginx as the production server
FROM nginx:alpine
# Copy the built React app to Nginx's web server directory
COPY --from=build /app/build /usr/share/nginx/html
# Expose port 80 for the Nginx server
EXPOSE 80
# Start Nginx when the container runs
CMD ["nginx", "-g", "daemon off;"]需要注意的是
bash
COPY --from=build /app/build /usr/share/nginx/html--from build , 这个 build 就是 FROM node:20-slim as build 中,node.js 镜像的别名。意思是把这个镜像中 /app/build 目录下的文件复制到 nginx:alpine 镜像的 /usr/share/nginx/html 文件夹下。
欢迎加入交流群
欢迎大家一起进群讨论前端全栈技术和 ai agent ,一起进步!