一.二进制日志
1.介绍
MySQL中最重要的日志,以"事件"的形式记录了所有DDL 和DML语句对数据库的更改,如:表的创建操作或表数据的更改,不会记录 SELECT 和 SHOW 操作。
二进制日志还包含每个语句更新数据时花费的时间信息,启动二进制日志,对服务器性能稍微有些影响。
二进制日志有如下作用:
|----------|-----------------------------------------------------------------------------------|
| 主从节点数据复制 | 从节点服务器读取主节点服务器上的二进制日志文件,并根据二进制日志中记录的事件在从节点上执行相同的操作,保证主从节点服务器上数据一致,实现数据复制功能,并于数据复制 |
| 数据恢复 | 重新执行记录在二进制日志中的事件,可以完成任一事务之前的数据恢复 |
2.配置
通过下面的命令可以查看二进制日志的核心配置项:
sql
show variables like '%log_bin%';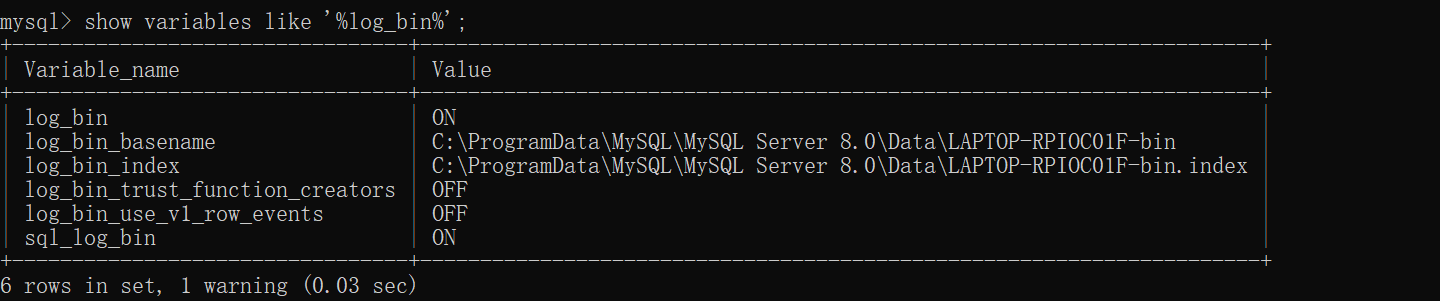
通过下面命令可以临时关闭二进制日志,如果要设置全局要在配置文件中修改:
sql
set session sql_log_bin = 0;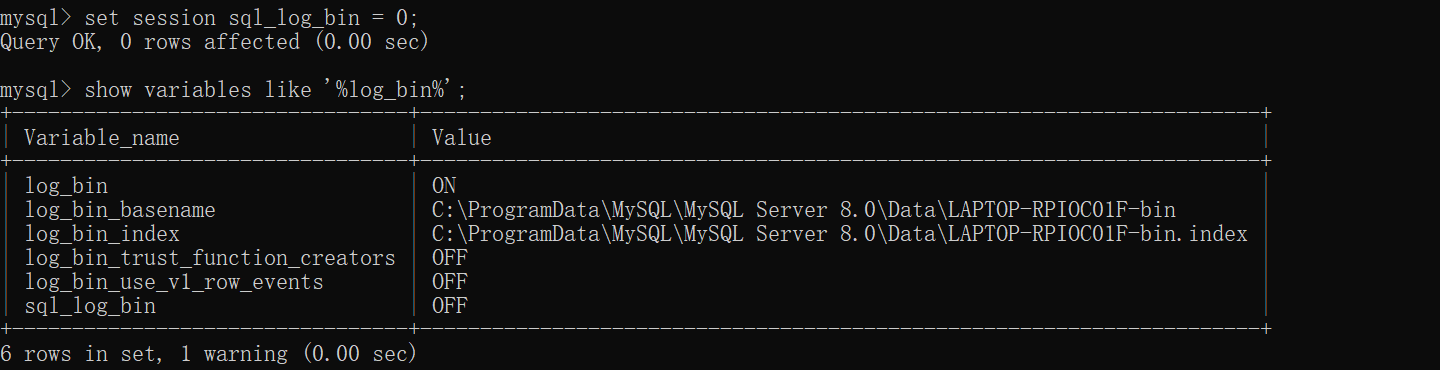
磁盘文件
二进制日志文件名是由基本名+数字扩展名 组成的,服务器每次创建一个新的日志文件时,数字扩
展名都会增加,从而保证有序的文件序列,发生以下事件时,服务器都会在创建一个新的日志文件:
1)服务器已启动或重新启动;
2)服务器刷新日志(flushlogs);
3)当前日志文件的大小达到 max_binlog_size(单个日志文件的最大字节数,最小值 4096 字节,最大值和默认值 1GB)。
 这是我主机的日志文件。
这是我主机的日志文件。
使用下面语言可以删除二进制文件:
sql
# 删除指定⽇志⽂件之前的所有⽇志⽂件并更新索引
PURGE BINARY LOGS TO 'binlog.000010';
# 删除指定时间之前的所有⽇志⽂件并更新索引
PURGE BINARY LOGS BEFORE '2029-11-11 22:56:26'
# 重置⼆进⾏⽇志⽂件和索引⽂件为初始状态
RESET MASTER;过期时间
在选项文件中配置 binlog_expire_logs_seconds 可以设置二进制日志的过期时间,单位为秒,默认2592000秒,即30天。二进制日志文件过期后,会自动删除。
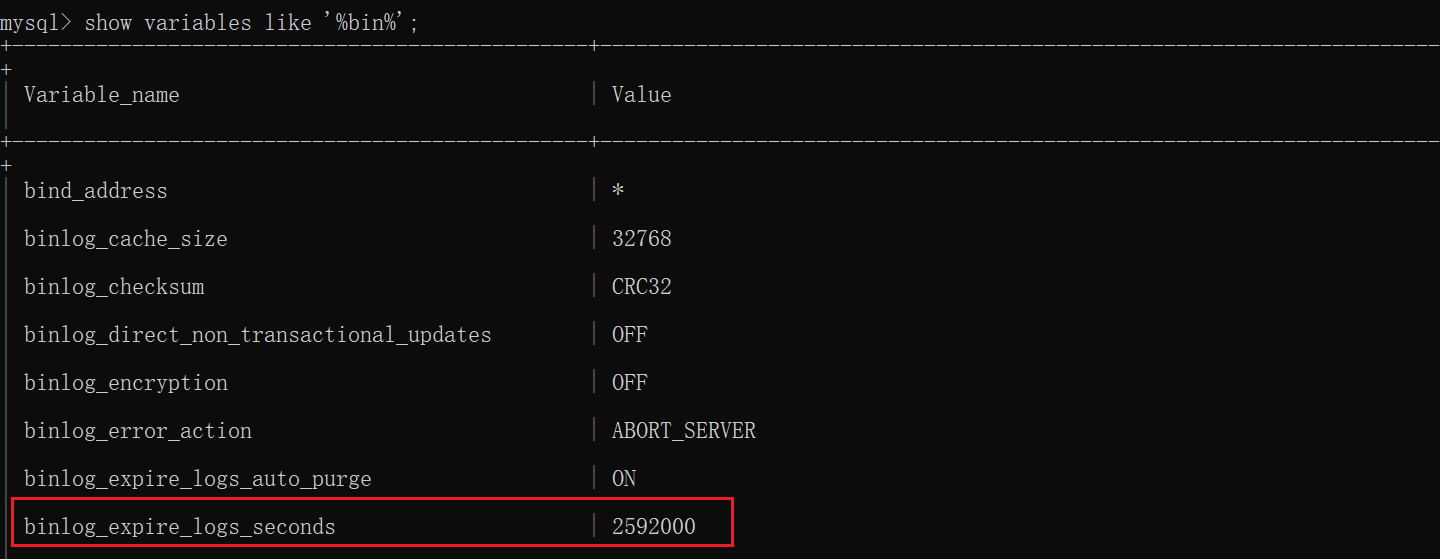
日志格式
记录二进制日志时使用的格式有以下三种:
|----------------------|-----------------------------------------------------------------------------------------------------------------------------|
| 基于语句的日志格式(STATEMENT) | 最初 MySQL 是基于 SQL 语句复制实现主从节点同步 |
| 基于行的日志格式(ROW,默认) | 主节点将事件写入二进制日志,表示各个表中受影响的数据行 |
| 混合日志记录格式(MIXED) | 默认情况下使用基于语句的日志记录,如果MySQL认为基于语句的格式不能保证主从复制过程中的数据安全时,会自动切换到基于行的日志格式,比如主节点在语句中用了UUID() 函数,那么日志文件中记录的是UUID生成的真实值而不是直接使用原始的SQL语句 |
生产环境中使用 ROW 格式,因为一般我们需要 binlog 来做更多的操作,比如数据同步和日志解析;Mixed 混合模式日志处理有些困难,很多同步工具无法使用。
通过修改配置文件中的 binlog_format = 格式名称 改变格式。
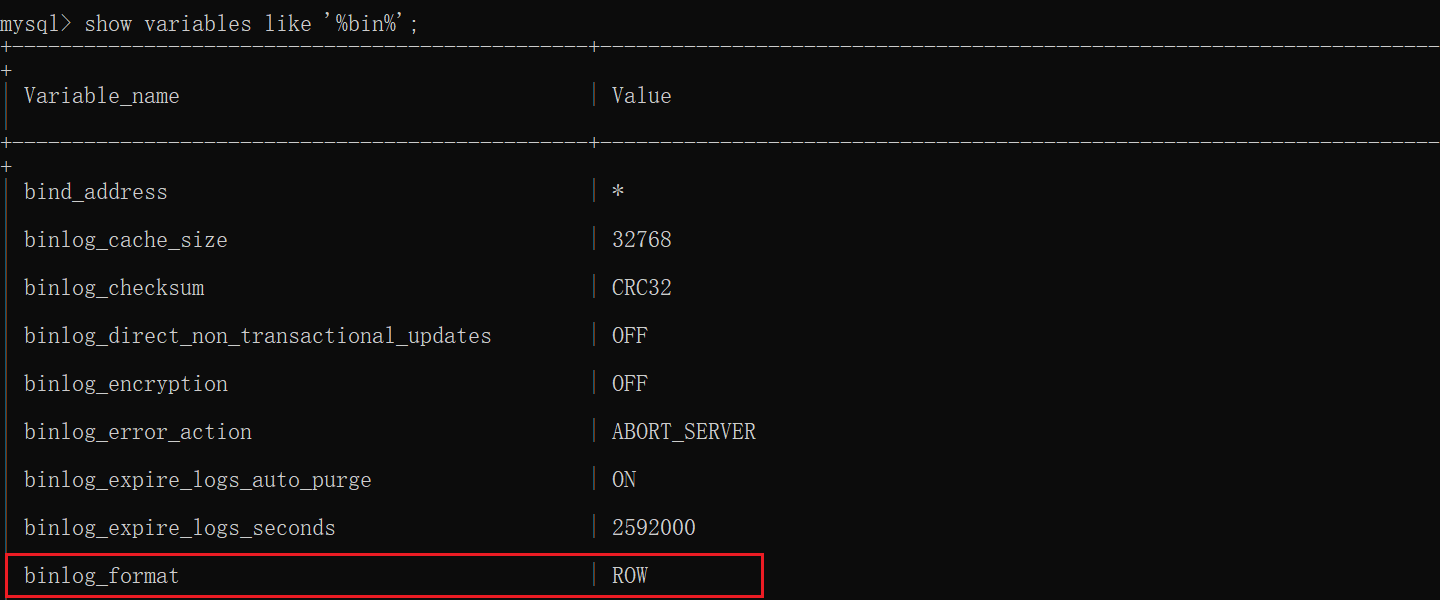
刷盘策略
MySQL binlog 缓存、操作系统缓存和磁盘中二进制日志文件的关系,如图所示:
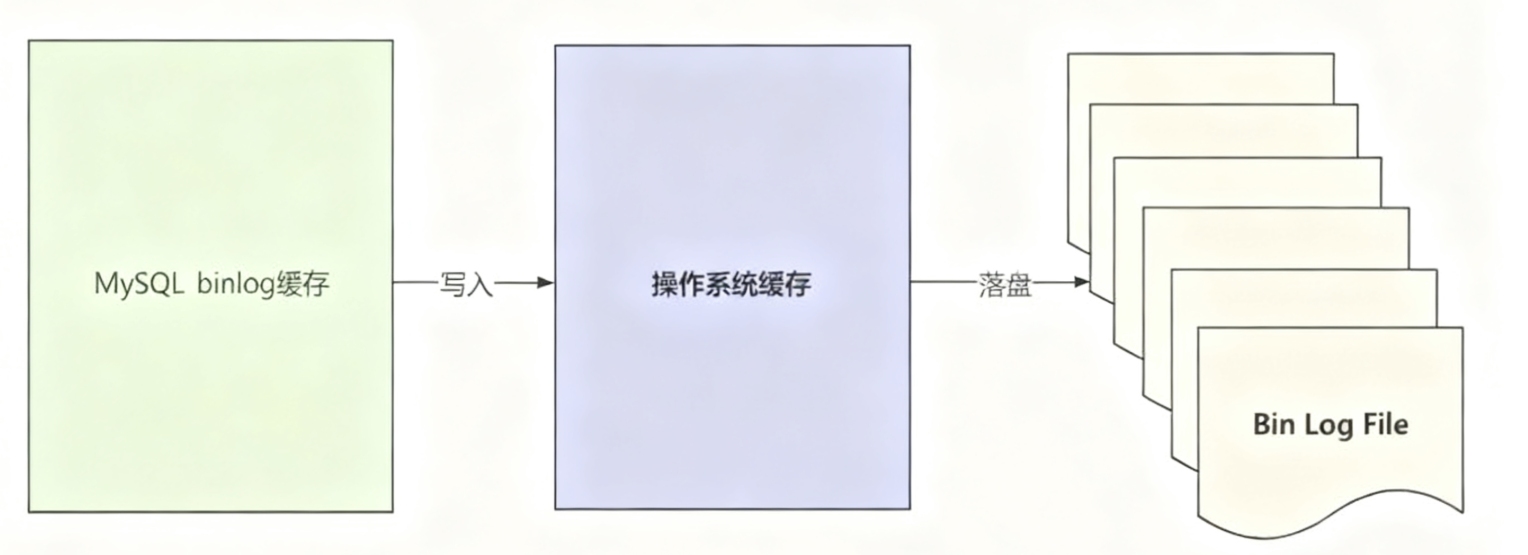
二进制日志的刷盘策略可以通过 sync_binlog 系统变量设置,设置规则如下:
|---------------|-------------------------------------------------------------------------------------|
| sync_binlog=0 | MySQL不控制binlog的刷新,由操作系统控制刷新时机,性能最好,风险最大,MySQL崩溃则MySQL binlog缓存中所有binlog信息都会丢失 |
| sync_binlog=1 | 每次提交事务,MySQL刷新binlog完成落盘,最安全但是性能损耗最大 |
| sync_binlog=N | 可以设置成一个非0和1的正整数,表示每提交N个事务刷新一次Binlog,需要根据当前的业务场景经过测试设置一个合理的值,这个设置牺牲一定的一致性,但可以提高一定的性能 |
在生产环境对数据一致要求高的场景里推荐使用 sync_binlog=1 (每次提交事务都刷新)。
常用操作
sql
-- 查看binlog是否开启
show variables like '%log_bin%';
select @@log_bin;
-- 查看binlog的路径
select @@log_bin_basename;
-- 查看binlog的格式
select @@binlog_format;
-- 查看是落盘策略
select @@sync_binlog;
-- 刷新所有⽇志
flush logs;
-- 刷新⼆进制⽇志
flush binary logs;
-- 查看当前服务器使⽤的binlog⽂件及⼤⼩
show binary logs;
-- 查看最新的binlog⽂件名和postion
show master status;
-- 查看binlog中的事件
show binlog events [IN 'log_name'] [FROM pos] [LIMIT row_count];
show binlog events in 'binlog.000051' from 676 limit 3;
-- 重置⼆进⾏⽇志⽂件和索引⽂件为初始状态
reset master;
-- 删除指定⽇志⽂件之前的所有⽇志⽂件并更新索引
purge binary logs to 'binlog.000010';
-- 删除指定时间之前的所有⽇志⽂件并更新索引
purge binary logs before '2024-05-02 22:56:26'
-- 查看服务器ID
select @@server_id;3.mysqlbinlog 工具
用来解析二进制日志的使用工具,可以能过ls /usr/bin/mysql* 查看:

windows 中在bin目录下也能找到:
mysqlbinlog 有如下常用选项,可以在命令行中指定,也可以在选项文件中通过 mysqlbinlog 和 client 组进行指定:
|-------------------------------|-----------------------------------------------------------------------------------------|
| 选项 | 说明 |
| --base64-output | --base64-output=value 把BINLOG中的事件用base-64进行编码,value的取值在之后有特殊说明 |
| --database | 只查看指定数据库的日志 |
| --no-defaults | 不读取选项文件 |
| --offset, -o | --offset=N,-o N 跳过日志中的前N条记录 |
| --raw | mysqlbinlog 以原始二进制格式写入事件,默认是文本格式 |
| --read-from-remote-server, -R | --read-from-remote-server=file_name , -R 读取远程MySQL服务器的二进制日志,而不是读取本地,要求远程服务器正在运行 |
| --require-row-format | 基于行格式的二进制日志记录格式 |
| --result-file, -r | --result-file=name, -r name 输出的目标文件 |
| --server-id | 仅显示指定服务器ID创建的事件 |
| --skip-gtids | 输出转储文件时不包含二进制日志文件中的gtid |
| --start-datetime | --start-datetime=datetime 从等于或晚于datetime的第一个事件开始读取日志,支持 DATETIME 和 TIMESTAMP 类型 |
| --stop-datetime | --stop-datetime=datetime 在等于或晚于datetime的第一个事件结束,支持 DATETIME 和 TIMESTAMP 类型 |
| --start-position, -j | --start-position=N , -j N 开始读取日志的位置, position 等于或大于N之后的任何事件 |
| --stop-position | --stop-position=N 在日志位置N处停止解码 |
| --stop-never | 保持与服务器的连接 |
| --verbose, -v | 重新构建行事件并将其显示为已注释的SQL语句,并在适用的情况下显示表分区信息 |
语法
bash
mysqlbinlog [options] log_file ...例如要显示名为 binlog.000010 二进制日志文件的内容,可以适用以下命令:
bash
mysqlbinlog --no-defaults binlog.000010数据恢复
这里适用一个示例来展示数据恢复。
首先我们要创建一个数据库,然后创建一张表再执行一些增删改语句。
sql
-- 建库
drop database if exists testdb;
create database testdb character set utf8mb4 collate utf8mb4_0900_ai_ci;
use testdb;
-- 建表
create table t1 (
id bigint not null,
name varchar(20) not null
);
-- 写⼊
insert into t1 (id, name) values (101, 'user101');
insert into t1 (id, name) values (102, 'user102');
insert into t1 (id, name) values (103, 'user103');
insert into t1 (id, name) values (104, 'user104');
insert into t1 (id, name) values (105, 'user105');
insert into t1 (id, name) values (106, 'user106');
-- 更新
update t1 set name = 'kaka101' where id = 101;
update t1 set name = 'makk102' where id = 102;
update t1 set name = 'wokk103' where id = 103;
-- 删除
delete from t1 where id = 104;
delete from t1 where id = 105;
delete from t1 where id = 106;使用这个命令来查看我们刚刚执行的sql语句:
bash
mysqlbinlog --no-defaults --database=testdb binlog.000001 | less上面这个语句是加密的,无法显示具体的sql语句,使用这个可以查看解密后的:
bash
mysqlbinlog --no-defaults --database=testdb --base64-output=decode-rows -v binlog.000001 | less
这个时候将数据库删除,我们的目标是利用二进制文件对这个数据库进行恢复。
1)方法一:找到恢复的起始位置,直接通过二进制日志进行恢复
bash
mysqlbinlog --no-defaults --skip-gtids=true --start-position=234 --stop-position=4387 binlog.000001 | mysql -uroot -p -h127.0.0.1 -P3306先要找到要恢复的起始位置和最终位置
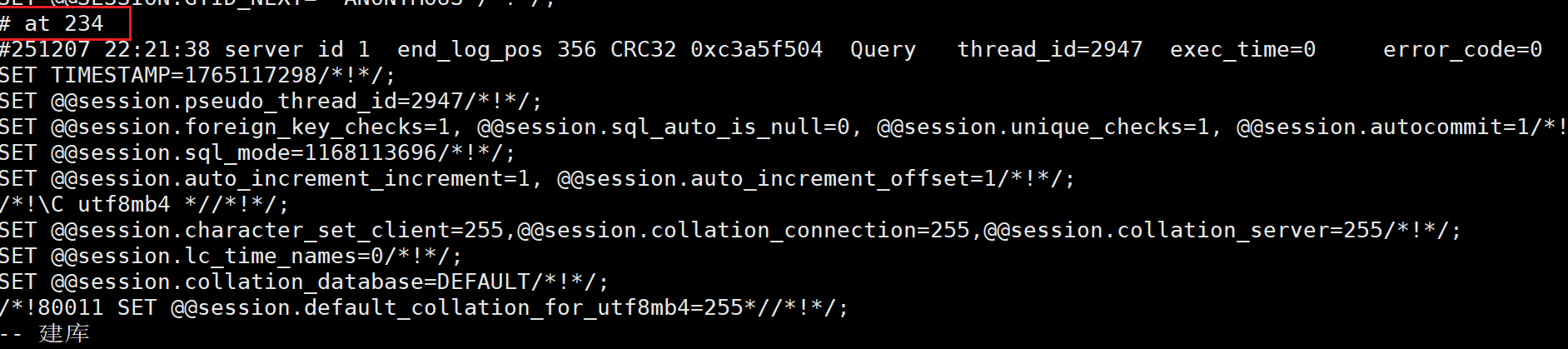

然后执行上面的命令即可。
2)方法二:导出二进制日志到 .sql 文件
bash
mysqlbinlog --no-defaults --skip-gtids=true --start-position=234 --stop-position=4470 binlog.000001 > testdb.sql在MySQL客户端导入 .sql 文件:
bash
source /var/lib/mysql/testdb.sql二.数据库备份
1.介绍
数据库备份是数据管理和维护中的一个重要步骤,具体的作用如下:
|-------|-------------------------------------------------|
| 数据恢复 | 在硬件故障、软件错误、数据损坏或人为失误的情况下,备份可以帮助快速恢复数据,减少业务中断的影响 |
| 灾难恢复 | 在发生自然灾害或其他灾难性事件时,备份可以确保数据不会丢失 |
| 数据完整性 | 定期备份有助于保持数据的完整性和一致性,确保数据的准确性和可靠性 |
| 数据迁移 | 在系统升级或迁移到新的数据库平台时,备份可以确保数据的平滑过渡 |
| 审计和报告 | 备份可以用于审计目的,提供历史数据以供分析和报告 |
| 测试和开发 | 备份可以用来创建开发和测试环境,而不需要复制整个生产数据库 |
2.分类
|------|----------------|
| 逻辑备份 | 生成SQL语句 |
| 物理备份 | 复制数据库所有文件 |
| 冷备份 | 备份时数据库完全关闭 |
| 热备份 | 备份时数据库正常运行 |
| 温备份 | 备份时部分可用或处于只读模式 |
| 全量备份 | 备份所有数据 |
| 增量备份 | 自上次备份之后的变更 |
| 差异备份 | 上次全量备份之后的变更 |
三.Mysqldump工具
1.介绍
mysqldump客户端程序可以执行逻辑备份 并生成一组SQL语句 ,其中包含原始数据库和表的定义以及表中的数据,以便实现对数据库的简单备份或复制。mysqldump命令可以生成CSV、或XML格式的文件。
|--------|-----------------------------------------------------------------------|
| 简单灵活 | 是一个命令行工具,使用相对简单不需要复杂的配置,提供了各种选项和参数,可以按需备份数据库的结构和数据,包括表结构、数据、触发器、存储过程等 |
| 跨平台支持 | 使用于多个操作系统,包括 Windows、Linux 和 Mac 等 |
| 兼容性好 | SQL 文件是纯文本格式,易于编辑和传输,支持几乎所有的 MySQL版本 |
| 易于恢复 | 导出的 SQL 文件可以直接用于恢复数据库,通过简单的命令即可重新导入数据 |
| 数据恢复缓慢 | 由于恢复时是将备份产生的 SQL 语句逐条执行,对于大型数据库、高频率备份和快速恢复等需求不太合适 |
| 无增量备份 | 不支持增量备份,每次备份都需要导出整个数据库 |
应用场景:
|---------------------------|
| 数据库版本升级 |
| 只备份表结构或小于10GB以下的数据库 |
| 跨数据库类型迁移,比如MySQL升级到Oracle |
| 云平台之间的迁移,比如阿里云迁移到腾讯云 |
2.语法
mysqldump的方法通常有以下使用,可以转储一个或多个表或数据库:
sql
# 导出
mysqldump [options] > dump.sql
# 导⼊
mysql [options] < backup-file.sqlmysqldump有如下常用选项,可以在命令行中指定,也可以在选项文件中通过 mysqldump 和 client 组进行指定:
|------------------------|-----------------------------------------------------------|
| 选项 | 说明 |
| --add-drop-database | 在每个 CREATE DATABASE 语句之前添加 DROP DATABASE 语句 |
| --add-drop-table | 在每个 CREATE TABLE 语句之前添加 DROP TABLE 语句 |
| --add-drop-trigger | 在每个 CREATE TRIGGER 语句之前添加 DROP TRIGGER 语句 |
| --add-locks | 用 LOCK TABLES 和 UNLOCK TABLES 语句包裹每个表转储 |
| --all-databases,-A | 转储所有数据库中的所有表 |
| --databases,-B | --databases=db_name 多个数据库名用空格隔开将参数解释为数据库名称并转储所有的表 |
| --comments,-i | 添加注释到转储文件 |
| --complete-insert,-c | 使用包含列名的完整INSERT语句 |
| --events,-E | 从转储数据库中转储事件 |
| --extended-insert,-e | 使用多行 INSERT 语法 |
| --flush-logs,-F | 在开始转储前刷新日志 |
| --force,-f | 转储期间发送了SQL错误,也要继续 |
| --ignore-table | --ignore-table=db_name.table_name 多个表用空格隔开不转储给定的表 |
| --lock-all-tables,-x | 锁定所有数据库中的所有表 |
| --lock-tables,-l | 在转储之前锁定指定要转储的表 |
| --no-autocommit | 将每个转储表的 INSERT 语句包含在 SET autocommit = 0 和 COMMIT 语句中 |
| --no-create-db,-n | 不要生成 CREATE DATABASE 语句 |
| --no-create-info,-t | 不要为每个转储的表生成 CREATE TABLE 语句 |
| --no-data,-d | 不转储表内容 |
| --routines | 在输出中转储数据库的存储过程和函数 |
| --skip-add-drop-table | 在每个 CREATE TABLE 语句之前不添加 DROP TABLE 语句 |
| --skip-add-locks | 不要添加锁 |
| --skip-comments | 转储文件中不添加注释 |
| --skip-triggers | 不转储触发器 |
| --tables | --tables=table_name 多个表名用空格隔开在选项之后的所有名称参数都被视为表名 |
| --triggers | 转储每个表中的触发器 |
注意事项:
|-------------------------------------------------------------------------------|
| 转储 表(视图、触发器)时必须要有 SELECT (SHOW VIEW、TRIGGER )权限 |
| 如果没有使用 --single-transaction (--no-tablespaces)选项时必须要有 LOCK TABLES (PROCESS)权限 |
| 重新导入转储文件时,也需要有相应的权限 |
| 由于mysqldump是逐行转储数据,所以不适用于大数据量的转储与导入,一般适用于50G以下的数据备份,50G以上适用物理备份 |
| 默认不备份 INFORMATION_SCHEMA , performance_schema , sys ,需要备份时显示指定 |
| mysqldump是单线程,数据量大时备份时间长,在备份过程中会对非事务表( MyISAM )长时间锁定,可能会对业务造成影响 |
| 备份结果是SQL形式,数据恢复时间也相对较长,大概是备份时间的5-10倍 |
3.备份数据
导出SQL语句:
bash
# 导出本地testdb数据库中的所有数据到磁盘
mysqldump -uroot -p -h127.0.0.1 -P3306 -B testdb > /backup/mysql/dump.sql
# 备份⽂件按当前时间命名
mysqldump -uroot -p -h127.0.0.1 -P3306 -B testdb > /backup/mysql/`date +%Y%m%d`.sql
恢复数据:
1)方式一:在命令行通过mysql客户工具直接恢复
bash
mysql -uroot -p < /backup/mysql/dump.sql
2) 方式二:登录mysql客户端导入SQL文件
bash
mysql -uroot -p导入SQL文件:
sql
source /backup/mysql/dump.sql
执行流程
1)连接数据库
2)查看需要备份的数据库和表
3)对所有表加 read lock
4)循环查看每个备份表的结构和数据,直到备份完成
5)释放所有表上的 read lock
产生问题
上述的备份流程在备份之前会对所有表进行加锁,也就意味着,在备份完成之前,正常业务产生的相关插入、删除、trnucate操作都在处于锁等待状态,会对业务造成严重的影响,不建议在生成环境使用。
同时由于备份过程中会产生数据不一致问题:数据可能已经改变,但是这些改变尚未提交,因此备份可能包含未提交的事务中的数据更改。如果备份期间发生了事务回滚,备份中可能包含已经删除或修改了的数据,这些数据在恢复后可能不存在。如果备份期间有新的数据插入,那么这些新数据可能不会被备份。
解决问题
解决备份过程数据不一致的方法是使用 --single-transaction 选项,确保备份在事务内运行,保证备份期间的数据一致性,避免上述不一致性问题。这通常通过在备份开始时启动一个事务来保证,而不阻止其他事务对数据的修改,执行流程如下:
|-------------------------------------------------------------------------------------------------------------------------------|
| 1. Connect 建立数据库连接 |
| 2. FLUSH TABLES 关闭实例上所有打开的表,为下一步做准备,因为当前可能有大事务正在执行 |
| 3. FLUSH TABLES WITH READ LOCK 为所有表加全局读锁,关闭实例上所有打开的表,实例上所有DML和DDL被阻塞,并阻止其他事务COMMIT |
| 4. SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 设置事务的隔离级别为可重复读,确定备份的事务内任何时候读取的数据都相同(通过MVCC保证) |
| 5. START TRANSACTION 开启⼀个事务用于备份,加 --single-transaction 选项时生效 |
| 6. SHOW MASTER STATUS 获取备份实例的POS信息并写入日志,加 --source-data 选项时生效,当前POS之后的记录可用于增量备份 |
| 7. UNLOCK TABLES 释放全局读锁,实例上所有DML和DDL正常运行 |
| 8. SELECT /*!40001 SQL_NO_CACHE */ * FROM `t1` 通过SELECT语句获取数据并备份,由于此时已经释放了全局读锁,所以除了INNODB表利用MVCC保持一致性以外,其他存储引擎表不一定能保证一致性 |
| 9. COMMIT 备份完成后提交事务,实例上所有DDL正常运行 |
4.完整示例
在对数据库进行完全备份前,需要收集数据库相关信息,如:存储引擎、字符集等,确保备份内容完整。
sql
-- 查看数据库和表信息
SELECT
table_schema,
table_name,
table_collation,
ENGINE,
table_rows
FROM
information_schema.TABLES
WHERE
table_schema NOT IN ( 'information_schema', 'sys', 'mysql','performance_schema' );
-- 查看是否存在存储过程
SELECT count(*) FROM information_schema.routines;
-- 查看是否存在触发器、调度事件
SELECT count(*) FROM information_schema.TRIGGERS;
-- 查看是否存在调度事件
SELECT count(*) FROM information_schema.EVENTS;
-- 查看字符集
show variables like 'character%';
-- 查看数据库连接超时时间
show variables like 'wait_timeout%'; -- 默认8⼩时
-- 查看交互式连接超时时间
show variables like 'interactive_timeout'; -- 默认8⼩时
-- 查看数据包大小限制,,建议128M或256M
show variables like 'max_allowed_packet'; -- # 防止包过大而失败,默认64MB,最大1GB
-- 查看事务是否自动提交
show variables like 'autocommit'; -- 必须开启生产环境单库备份
bash
mysqldump -ubackup_user -p -h127.0.0.1 -P3306 \
-B testdb --default-character-set=utf8mb4 \
--single-transaction --source-data=2 \
--triggers --events --routines \
--set-gtid-purged=off > /backup/mysql/`date +%Y%m%d`_0.sql单表多表备份
在数据库后面加上 --tables 表1 表2
bash
mysqldump -ubackup_user -p -h127.0.0.1 -P3306 \
-B testdb --tables class student \
--default-character-set=utf8mb4 \
--single-transaction --source-data=2 \
--triggers --events --routines \
--set-gtid-purged=off > /backup/mysql/dump2.sql按条件备份
--where='id<3' : 备份条件,如果备份多张表,备份的所有表中必须都包含条件中的列名,类型不匹配不会报错
bash
mysqldump -ubackup_user -p -h127.0.0.1 -P3306 \
-B testdb --tables class student --default-character-set=utf8mb4 \
--single-transaction --source-data=2 \
--triggers --events --routines --set-gtid-purged=off \
--where='id<3' > /backup/mysql/dump3.sql导出表结构
--no-data,-d: 不转储数据
bash
mysqldump -ubackup_user -p -h127.0.0.1 -P3306 \
-B testdb -d --default-character-set=utf8mb4 \
--single-transaction --source-data=2 \
--triggers --events --routines \
--set-gtid-purged=off > /backup/mysql/dump4.sql只备份数据
bash
mysqldump -ubackup_user -p -h127.0.0.1 -P3306 \
--databases testdb --hex-blob --no-create-db --no-create-info \
--default-character-set=utf8mb4 \
--single-transaction --source-data=2 \
--triggers --events --routines \
--set-gtid-purged=off --flush-logs > /backup/mysql/dump5.sql数据导入
1)方式一:在命令行通过mysql客户工具直接恢复
bash
mysql -uroot -p < /backup/mysql/dump.sql2)方式二:登录mysql客户端导入SQL文件
bash
msyql -uroot -p
sql
source /backup/mysql/dump.sql3)方式三:流式导入
bash
mysqldump -ubackup_user -p123456 -h本地IP -P3306 \
-B testdb --default-character-set=utf8mb4 \
--single-transaction --source-data=2 \
--triggers --events --routines \
--set-gtid-purged=off | mysql -uroot -p123456 -h远程主机IP -P3306四.SQL语句导出导入
1.介绍
MySQL中可以通过SQL语句把查询出来的数据导出到服务器的文件中,也可以从导出文件加载数据到指定的数据库和表,同时提供了一个导入工具方便在命令行中完成导入操作。
特点:
|--------------------|
| 根据查询结果导出,定制性强,操作方便 |
| 高效读取文本数据到指定的表 |
| 可以灵活定制,适合异构迁移 |
使用场景:
|---------------------|
| 简单的数据备份和数据迁移 |
| 将数据导出到外部应用程序进行进一步处理 |
2.语法
导出
sql
-- 完整语法
SELECT
select_expr [, select_expr] ...
FROM table_references
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}
export_options:
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]简单示例:
sql
SELECT * FROM db_name.tbl_name into outfile 'file_name';注意:该文件将在服务器主机上创建,必须具有 file 权限才能使用此语法。file_name不能是一个已经存在的文件。
导入
sql
-- 完整语法
LOAD DATA
[LOW_PRIORITY | CONCURRENT] [LOCAL]
INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}]
[(col_name_or_user_var
[, col_name_or_user_var] ...)]简单示例:
sql
LOAD DATA infile 'file_name' into table tbl_name;常用关键字
|----------------------|-----------------------------------------------------------------------------------|
| 关键字 | 描述 |
| LOW_PRIORITY | LOAD DATA语句的执行可能会被阻塞,直到没有其他客户端读取表中的数据为止。只对只支持表级锁的存储引擎有效,比如MyISAM |
| CONCURRENT | 满足并发插入条件的MyISAM表(即表中不包含空闲块),其他线程可以在执行LOAD data时从表中检索数据,会对性能有影响 |
| REPLACE | 当插入的数据行与表中现唯一字段重复时则替换表中的数据,的新行将替换现有行 |
| IGNORE | 当插入的数据行与表中现唯一字段重复时则忽略 |
| LOCAL | 指定该关键字表示文件位于客户端的机器上,文件由客户端读取并通过网络发送到MySQL服务器;如果不指定该关键字则表明文件在MySQL服务器,由MySQL服务器去读取 |
| CHARACTER SET | 指定字符集,如果不指定则使用 character_set_database 变量对应的字符集 |
| FIELDS TERMINATED BY | 字段的分隔符,默认为 '\t' |
| FIELDS ENCLOSED BY | 字段的包裹符, 默认为 ' ' |
| FIELDS ESCAPED BY | 字段值的转义字符,默认为 '\\' |
| IGNORE | 忽略开头N行 |
| LINES TERMINATED BY | 行分隔符,默认为 '\n' |
| LINES STARTING BY | 忽略指定的前缀,若指定该值为'xxx'',则MySQL会自动去掉xxx及其前面的字符 |
3.mysqlimport
由 LOAD DATA INFILE SQL语句的工具化,由 SELECT INTO OUTFILE 导出的文件,也可以通过 mysqlimport 导入。
bash
mysqlimport -uroot -pPassword [--local] dbname filename.txt [OPTION]|---------------------------------|-----------|
| 选项 | 说明 |
| -local | 从指定路径加载文件 |
| --fields-terminated-by | 字段的分隔符 |
| --fields-optionally-enclosed-by | 字段的包裹符 |
| --fields-escaped-by | 字段值的转义字符 |
| --lines-terminated-by | 行分隔符 |
| --ignore-lines | 忽略开头N行 |
4.完整示例
执行导出操作:
sql
-- 查看全局只读参数secure_file_priv的值(允许导出的目录)
show variables like 'secure_file_priv';
-- 导出到授权的路径下
select * from t1 into outfile '/var/lib/mysql-files/student.txt';
执行导入操作:
sql
load data infile '/var/lib/mysql-files/t1.txt' into table t1;五.物理备份工具------Xtrabackup
1.介绍
Xtrabackup是由Percona公司开发的一款用于MySQL数据库的物理热备份 工具,开源免费。它是MySQL社区唯一款开源物理热备份工具,深受用户喜爱,是MySQL开源社区的主流备份工具之一。官网:Percona XtraBackup for MySQL - Top MySQL Backup Solution
使用 Xtrabackup 进行备份,是对数据目录进行物理拷贝,把数据目录所有的内容复制到备份目录中。
特点:
|-------------|--------------------------------------------------------------|
| 备份类型 | 支持全量备份 和增量备份 |
| 快速可靠 | 使用物理备份,备份速度快且可靠,同时会对备份的数据进行自动校验,确保备份数据的完整性,恢复过程相对简单 |
| 性能影响小 | 在备份过程中,Xtrabackup对数据库的性能影响较小,不会增加太多的性能压力 |
| 压缩和加密 | 支持备份压缩和加密,可以节约磁盘空间和网络带宽,同时会对备份的数据进行自动校验,确保备份数据的完整性 |
| 支持多种数据库 | XtraBackup 支持 MySQL、Percona Server 和 MariaDB,是目前较为受欢迎的主流备份工具 |
应用场景:
|-------------|---------------------------------------------------------------------------|
| 大型数据库备份 | 适合处理大型数据库的备份需求,可以节省存储空间和备份时间 |
| 高可用环境 | 可以在不影响数据库服务的情况下进行在线热备份,适用于高可用环境的备份需求 |
| 全量和增量备份 | 需要定期进行增量备份以节省存储空间和备份时间的场景 |
| 全量和增量恢复 | 可以进行全量恢复和增量恢复,甚至可以进行部分恢复和时间点恢复 |
| 非阻塞备份 | XtraBackup 支持对 InnoDB 和 XtraDB 存储引擎的数据库进行非阻塞备份,这对于要求不影响线上服务的数据备份和恢复场景非常适合 |
2.全量备份
备份
bash
# 指定参数
xtrabackup --defaults-file=/etc/mysql/my.cnf \
--host=localhost --port=3306 --user=backup_user --password=123456 \
--use-memory=1G --parallel=2 \
--backup --target-dir=/backup/mysql/full此时查看备份目录,发现生产了新的文件:
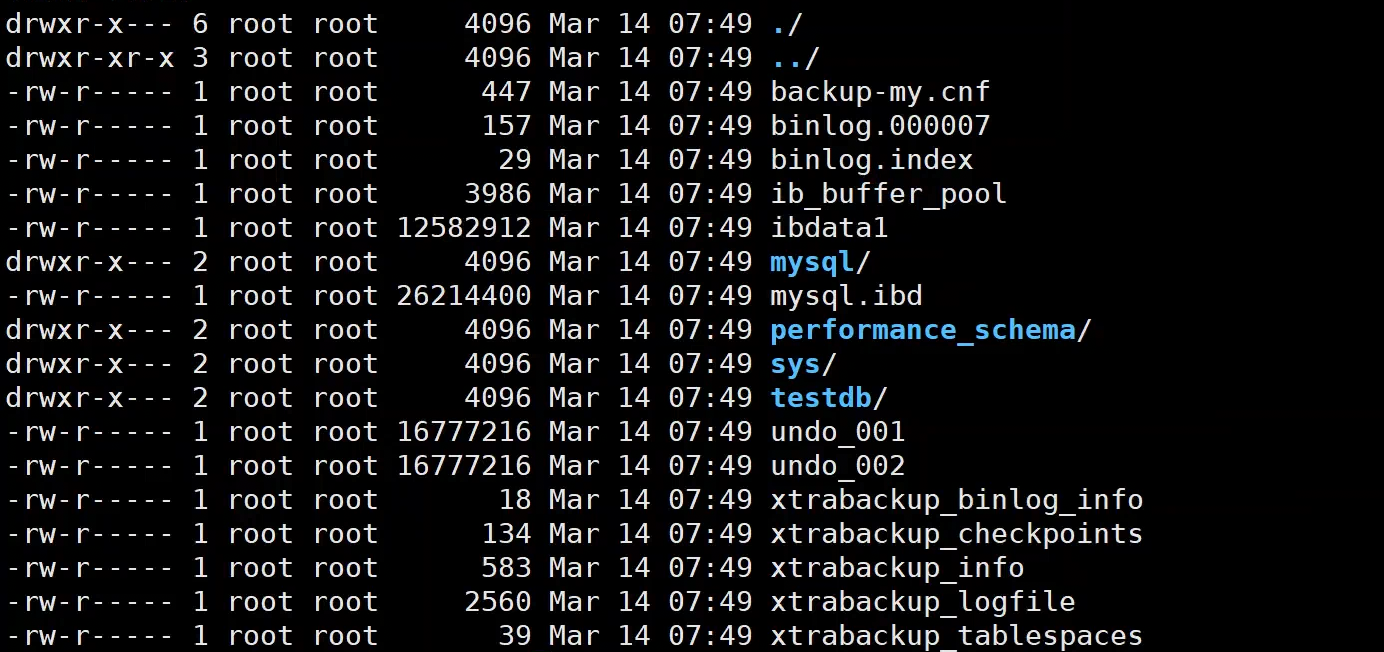
备份目录下生成的主要文件:
|----------------------------|-----------------------------|
| xtrabackup_binlog_info | 记录备份时binlog日志和POS信息 |
| xtrabackup_checkpoints | 备份类型和备份LSN信息,增量备份时依赖文件中的LSN |
| xtrabackup_info | 备份信息 |
恢复
首先要确保 /etc/mysql/my.cnf 已配置好,就是恢复时的数据目录一定要与选项文件中的配置的数据目录相同。
恢复之前可以把原来数据库的数据目录删掉,再创建一个同名的空目录。
1)停掉MySQL
bash
systemctl stop mysql2)处理目录
bash
# 移动或删除原来的数据⽬录
mv /var/lib/mysql /var/lib/mysql-old
# 创建数据⽬录同名的空⽬录
mkdir -p /var/lib/mysql3)进行数据准备和恢复
bash
# 准备
xtrabackup --prepare --target-dir=/backup/mysql/full
# 恢复数据
xtrabackup --defaults-file=/etc/mysql/my.cnf \
--copy-back --parallel=2 --target-dir=/backup/mysql/full
# 为恢复⽬录授权
chown -R mysql:mysql /var/lib/mysql
# 启动MySQL服务
systemctl start mysql3.增量备份
Xtrabackup 支持增量备份,备份时只复制自上次备份之后更改的所有数据。
在每次完全备份之间可以执行多次增量备份,例如每周进行一次完全备份,每天进行一次增量备
份,或者每天进行一次完全备份,每小时进行一次增量备份。
InnoDB存储引擎中的每个数据页都包含一个日志序列号(LSN),增量备份是通过查找上次备份之后的LSN对应的所有数据页,并对这些数据页进行增备。
备份
增量备份需要先进行一次完全备份,全备的过程与之前的一样
bash
# 全备
xtrabackup --defaults-file=/etc/mysql/my.cnf \
--host=localhost --port=3306 --user=backup_user --password=123456 \
--use-memory=1G --parallel=2 \
--backup --target-dir=/backup/mysql/full第一次增量备份,备份完修改一次数据库内的数据:
bash
# 为当前增量备份指定保存备份的⽬录,以及全量备份的⽬录
xtrabackup --host=localhost --port=3306 --user=backup_user --password=123456 \
--backup \
--target-dir=/backup/mysql/inc1 \
--incremental-basedir=/backup/mysql/full第二次增量备份:
bash
# 为当前增量备份指定保存备份的⽬录,以及上⼀次增备的⽬录
xtrabackup --host=localhost --port=3306 --user=backup_user --password=123456 \
--backup \
--target-dir=/backup/mysql/inc2 \
--incremental-basedir=/backup/mysql/inc1恢复
首先要确保 /etc/mysql/my.cnf 已配置好,就是恢复时的数据目录一定要与选项文件中的配置的数据目录相同。
恢复之前可以把原来数据库的数据目录删掉,再创建一个同名的空目录。
bash
# 停⽌MySQL服务
systemctl stop mysql
# 查看MySQL服务是否停⽌
systemctl status mysql
# 移动或删除原来的数据⽬录
mv /var/lib/mysql /var/lib/mysql-old
# 创建数据⽬录同名的空⽬录
mkdir -p /var/lib/mysql先进行数据准备再进行恢复,增量恢复准备需要加 --apply-log-only 选项,增量恢复是通过RedoLog进行重放事务完成数据恢复,这个选项用来跳过备份时还没有提交的事务;注意:最后一次增量在准备时不需要使用该选项。
bash
# 准备全量恢复
xtrabackup --prepare --apply-log-only --target-dir=/backup/mysql/full
# 准备第一次增量恢复
xtrabackup --prepare --apply-log-only --target-dir=/backup/mysql/full \
--incremental-dir=/backup/mysql/inc1
# 准备第二次增量恢复
xtrabackup --prepare --target-dir=/backup/mysql/full \
--incremental-dir=/backup/mysql/inc2
bash
# 恢复数据
xtrabackup --copy-back --parallel=2 --target-dir=/backup/mysql/full
# 为恢复⽬录授权
chown -R mysql:mysql /var/lib/mysql
# 启动MySQL服务
systemctl start mysql
# 查看MySQL服务
systemctl status mysql