Debezium日常分享系列之:认识debezium operator、debezium server yaml格式、部署debezium server
- [debezium operator](#debezium operator)
- [使用 Debezium Operator 的主要好处](#使用 Debezium Operator 的主要好处)
- 两种主要的实现模式
- [部署debezium operator](#部署debezium operator)
- 声明式管理
- [debezium server yaml配置](#debezium server yaml配置)
- [部署debezium server yaml](#部署debezium server yaml)
- 核心架构与特点
debezium operator
- Debezium Operator 是一个运行在 Kubernetes 里的"自动化运维专家"。它的核心使命是:让在 K8s 中部署和管理 Debezium 连接器变得像管理一个原生 K8s 应用一样简单、声明式和自动化。
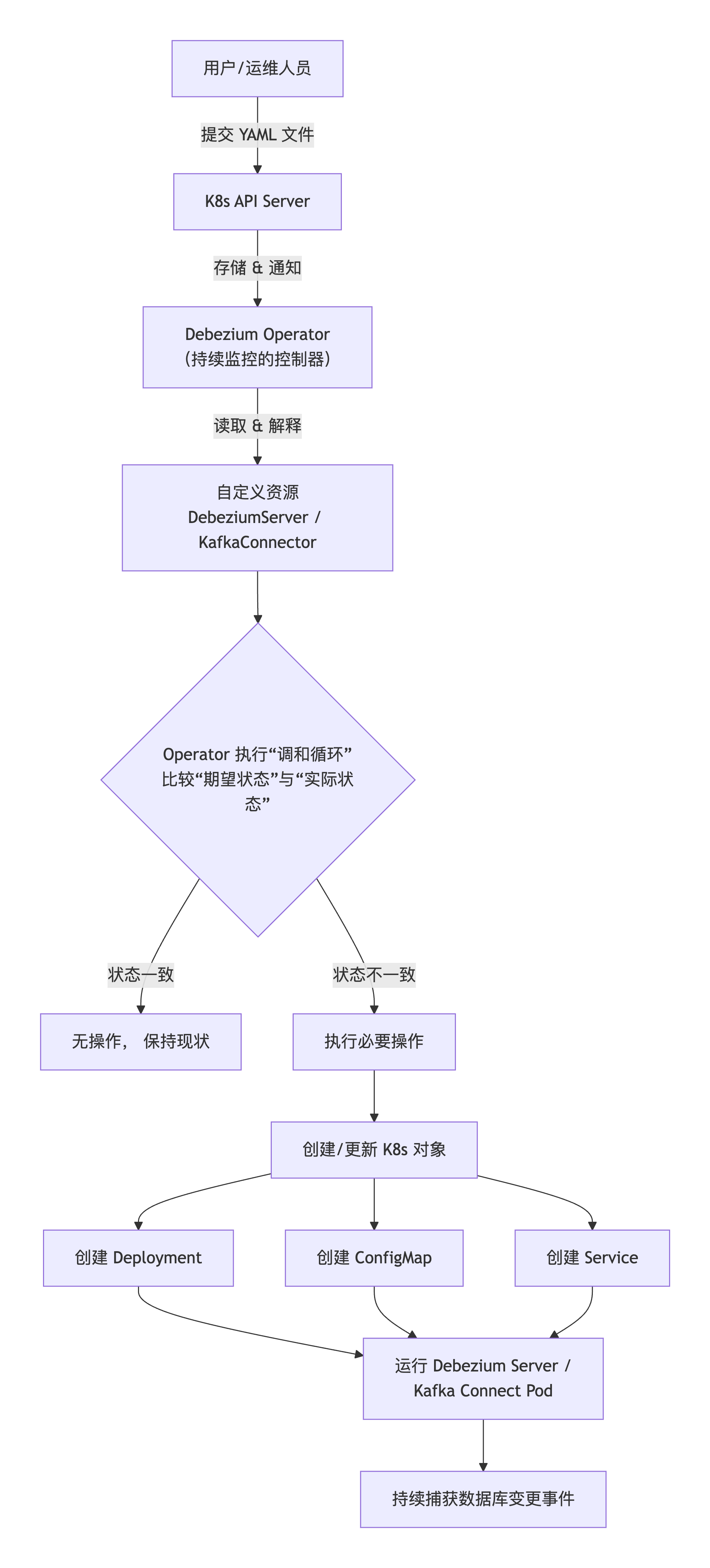
- 你编写了一个 server.yaml,其中 kind: DebeziumServer 就是这个 Operator 定义的一种自定义资源。这个文件描述了你"期望的状态":一个连接到特定 MySQL 和 Kafka 的 Debezium 实例。
- 你执行了 kubectl apply -f server.yaml。这个命令将你的"期望状态"提交给了 Kubernetes API 服务器。
- Debezium Operator 开始工作:
- 监听:Operator 的控制器(一个常驻程序)一直在监听DebeziumServer 资源的变化。
- 调和:它发现你创建了一个新的 DebeziumServer 资源,便读取其中的详细配置。
- 行动:它自动为你创建和管理一系列标准的 Kubernetes 对象,比如:
- Deployment/StatefulSet:来运行 Debezium Server 的 Pod。
- ConfigMap:把你的复杂配置注入到 Pod 中。
- Service:提供网络访问。
- Secret:安全地处理数据库密码等敏感信息。
- 你的 Debezium 连接器就运行起来了,并且后续如果你想修改配置,只需要更新同一个 server.yaml 文件并重新 apply,Operator 就会自动完成滚动更新等操作。
使用 Debezium Operator 的主要好处
- 声明式配置:你只需关心"想要什么"(YAML文件),而不是"如何做到"(手动执行一系列命令)。这大大简化了部署和变更流程。
- 全生命周期管理:Operator 不仅负责部署,还能处理升级、配置变更、故障恢复(如 Pod 崩溃后重启)等日常运维。
- 标准化与集成:它将 Debezium 的领域知识(如何配置连接器)封装成了 Kubernetes 的原生 API 对象,使 Debezium 能够无缝融入云原生的运维体系(如 GitOps、CI/CD)。
- 简化复杂配置:它帮你处理了在 K8s 中运行一个有状态、复杂配置的中间件服务的诸多细节。
两种主要的实现模式
目前主要有两种方式将 Debezium 运行在 Kubernetes 上,它们背后的"Operator"略有不同:
- 专用的 Debezium Operator:
- 管理资源:通常使用 DebeziumServer 这种自定义资源(就像你之前使用的 apiVersion: debezium.io/v1alpha1)。
- 特点:直接部署和管理独立的 Debezium Server 容器,相对轻量、直接。
- 通过 Kafka Operator(如 Strimzi)管理:
- 管理资源:使用 KafkaConnector 这种自定义资源。
- 特点:将 Debezium 作为 Kafka Connect 集群中的一个连接器插件来运行。这种方式更适合已经使用了 Strimzi 管理 Kafka 的复杂环境,可以复用 Kafka Connect 的资源管理和扩展能力。
总结:
- Debezium Operator 看作是你的 "Debezium-on-K8s 专属运维机器人"。它把你的配置文件翻译成 K8s 能执行的指令,并确保 Debezium 实例始终按你的描述去运行,从而把你从繁琐的部署和运维命令中解放出来,让你更专注于数据管道本身的逻辑。
部署debezium operator
bash
helm install my-debezium-operator debezium/debezium-operator --version 3.2.0-final -n debezium- 核心作用是 在Kubernetes集群中部署了一个"智能运维机器人"------Debezium Operator。
- 安装它本身并不会立即开始同步数据,但它提供了一种强大、自动化、云原生的方式来管理和运行Debezium数据同步任务。
声明式管理
| 特性 | Debezium Operator | 无 Debezium Operator |
|---|---|---|
| 部署方式 | 声明式。你只需提交一个YAML文件(如DebeziumServer或KafkaConnector),Operator自动创建和管理所有底层Kubernetes资源(Pod、Service、ConfigMap等)。 | 命令式/手动。需要自己编写并管理复杂的Deployment、Service、ConfigMap等多个YAML文件,步骤繁琐。 |
| 生命周期管理 | 自动化。Operator持续监控你定义的资源状态,确保实际运行状态与你的声明一致。如果Pod意外崩溃,它会自动重建。 | 手动。你需要自己监控Pod健康,手动处理故障恢复、配置更新和版本升级。 |
| 配置与更新 | 便捷。修改连接器配置只需更新YAML并重新apply,Operator会协调滚动更新,减少服务中断。 | 复杂且易出错。需要手动编辑多个配置,重启服务,并确保步骤正确。 |
| 高级功能 | 内建支持。开箱即用地支持监控指标暴露、安全配置、资源限制等,通过YAML即可启用。 | 自行集成。需要自己额外部署和配置监控组件、安全策略。 |
| 知识模型 | 领域驱动。你使用DebeziumServer或KafkaConnector这种"业务语言"来定义想要什么(同步哪个库),无需关心Kubernetes细节。 | 基础设施驱动。你需要精通Kubernetes的底层资源对象,用它们"组装"出一个Debezium服务。 |
debezium server yaml配置
这是一个用于在 Kubernetes 环境下部署 Debezium Server 的 YAML 配置文件。它使用了 DebeziumServer 这个自定义资源定义(CRD),通常与 Debezium Operator 配合使用,以实现声明式的部署和管理。
bash
apiVersion: debezium.io/v1alpha1
kind: DebeziumServer
metadata:
name: my-debezium-server
spec:
version: "3.2.0"
source:
class: io.debezium.connector.mysql.MySqlConnector
config:
database.hostname: mysql-server
database.port: 3306
database.user: debezium
database.password: secret
database.server.id: 184054
topic.prefix: mysql
database.include.list: inventory
offset:
type: kafka
config:
bootstrap.servers: kafka:9092
topic: debezium-offsets
schemaHistory:
type: kafka
config:
bootstrap.servers: kafka:9092
topic: debezium-schema-history
sink:
type: kafka
config:
bootstrap.servers: kafka:9092
format:
key:
type: json
value:
type: json
config:
schemas.enable: false
runtime:
jmx:
enabled: true
port: 1099
storage:
data:
type: persistent
claimName: debezium-data-pvc
metrics:
jmxExporter:
enabled: true
transforms:
- type: io.debezium.transforms.UnwrapFromEnvelope
config:
drop.tombstones: false
predicate: inventory-filter
negate: false
predicates:
inventory-filter:
type: org.apache.kafka.connect.transforms.predicates.TopicNameMatches
config:
pattern: "mysql.inventory.*"
quarkus:
config:
quarkus.log.level: INFO
quarkus.http.port: 8080| 配置模块 | 关键字段 | 说明 |
|---|---|---|
| 基础信息 | apiVersion, kind, metadata.name | 定义这是一个 debezium.io/v1alpha1 版本的 DebeziumServer 资源,实例名为 my-debezium-server。 |
| 核心版本 | spec.version | 指定部署的 Debezium Server 版本为 3.2.0。 |
| 数据源 | spec.source | 配置数据从哪里来。 |
| ↳ 连接器 | class: io.debezium...MySqlConnector | 使用 MySQL 连接器 捕获变更。 |
| ↳ 数据库配置 | database.hostname, user 等 | 连接 MySQL 服务器的基本信息。database.include.list: inventory 表示只捕获 inventory 库的变更。 |
| ↳ 偏移量存储 | offset.type: kafka | 关键配置:将消费位点(offset)存储在 Kafka 主题 (debezium-offsets) 中,而非本地文件。这确保了容错性和可恢复性。 |
| ↳ 模式历史存储 | schemaHistory.type: kafka | 关键配置:将表结构变更历史存储在另一个 Kafka 主题 (debezium-schema-history) 中。同样是为了持久化和集群化。 |
| 数据目标 | spec.sink | 配置变更数据写入到哪里。这里指定为 Kafka 集群 (kafka:9092)。 |
| 数据格式 | spec.format | 配置输出到 Kafka 的消息格式。键和值都使用 JSON,并且 schemas.enable: false 表示消息体不包含复杂的 schema 信息,更简洁。 |
| 运行时 | spec.runtime | 配置服务器运行时的特性。 |
| ↳ 监控 | jmx.enabled: true | 启用 JMX 监控,端口 1099,并启用 Exporter 方便 Prometheus 抓取。 |
| ↳ 存储 | storage.data.type: persistent | 为服务器运行时数据(如连接器插件、临时文件)配置持久化存储卷(PVC),重启后数据不丢失。 |
| 数据转换 | spec.transforms | 配置一个转换器,这里使用 UnwrapFromEnvelope 来"展开" Debezium 默认的复杂变更事件结构,只提取变更后的数据行。 |
| 条件谓词 | spec.predicates | 定义一个过滤器 (inventory-filter),配合 transforms 使用,确保只有匹配 mysql.inventory.* 主题的变更才会被上述转换器处理。 |
| 底层框架 | spec.quarkus | Debezium Server 基于 Quarkus 框架构建,这里设置了日志级别和 HTTP 服务端口。 |
部署debezium server yaml
bash
kubectl apply -f ./server.yaml -n debezium核心架构与特点
理解这个配置,可以抓住以下三个关键点:
- Server 模式与独立运行:你之前接触的 Flink CDC 是库模式,需要嵌入到 Flink 作业中。而这个配置定义的是 Debezium Server,它是一个独立运行的服务,作为 Kafka Connect 的单机替代品,直接将变更数据写入 Kafka。
- 状态外置存储:配置文件中最关键的部分是 offset 和 schemaHistory 都明确指定存储到 Kafka。这是一个生产级的最佳实践,它确保了即使 Debezium Server 实例全部重启或迁移,也能从 Kafka 中恢复准确的消费位点和表结构,实现完全无状态化和高可用部署。
- 云原生部署:通过 CRD 和 Operator 在 Kubernetes 中管理,配合持久化存储 (PVC) 和丰富的监控 (JMX),体现了标准的云原生应用部署和管理方式。
简单来说,这个 YAML 文件定义了一个高可用、易于监控、可将 MySQL 的 inventory 数据库变更以简洁 JSON 格式实时写入 Kafka 的独立数据同步服务。