引言:openEuler,AI 云原生浪潮中的坚实底座
在当今人工智能(AI)与云原生技术交汇的浪潮中,构建高性能、高可用的 AI 服务已成为企业数字化转型的关键。openEuler 作为面向数字基础设施的开源操作系统,凭借其在高并发、低延迟场景下的深度优化,正成为承载 AI 工作负载的理想选择。与此同时,Kubernetes 云原生生态为 AI 模型的部署、弹性伸缩和管理提供了前所未有的灵活性和可扩展性。本文将聚焦于 AI 场景,结合 openEuler 的技术特性和业界热点,通过一个实操案例------在 openEuler 上使用 KServe 部署 Qwen3 大语言模型,深入探讨云原生 AI 服务的性能测试与优化实践。
技术背景:Qwen3 与 KServe,强强联合

Qwen3 系列模型:性能与特性概览
Qwen3 是阿里云通义千问团队最新一代的大语言模型系列,于 2025 年 4 月正式发布。该系列模型在架构、性能和功能上均实现了重大突破,代表了当前开源大模型的顶尖水平。其核心特点包括:

- 混合专家(MoE)架构:Qwen3 引入了创新的混合专家模型设计,通过在推理时动态激活部分专家参数,大幅降低了计算资源消耗。旗舰模型 Qwen3-235B-A22B 总参数高达 2350 亿,但每次推理仅激活约 220 亿参数,相比传统稠密模型在性能相当的情况下,计算量减少约三分之二。这一架构优化使得 Qwen3 在保持强大性能的同时,显著提升了部署效率,降低了硬件成本。
- "思考模式"与"非思考模式"双形态:Qwen3 首创了"思考模式"与"非思考模式"的无缝切换机制。在"思考模式"下,模型会执行多步推理,逐步分解问题、验证答案,从而提供更深入、准确的回答,适用于复杂推理任务;而在"非思考模式"下,模型则提供快速、近乎即时的响应,适用于简单问答或对延迟要求极高的场景。这种双模式设计赋予用户对模型"思考"程度的灵活控制,可在效果、成本和响应速度之间取得最佳平衡。
- 卓越的性能表现:在多项权威基准测试中,Qwen3 系列模型均展现出顶尖水准。其旗舰模型在代码、数学、通用能力等评测中,全面超越了此前规模更大的 DeepSeek-R1 模型。例如,在极具挑战性的 AIME2025 数学竞赛评测中,Qwen3 取得了 81.5 分的高分,刷新了开源模型的记录。在代码能力评测 LiveCodeBench 中,Qwen3 得分突破 70 分,甚至超越了知名的 Grok-3 模型。这些成绩充分证明了 Qwen3 在复杂任务处理上的强大实力。
- 多语言与多模态支持 :Qwen3 支持 119 种语言和方言,覆盖了全球主要语种,具备出色的多语言理解和生成能力。此外,Qwen3 还推出了多模态版本 Qwen3-Omni,能够原生处理文本、图像、音频、视频四模态输入,并以文本和语音形式输出,实现端到端的多模态交互。这一特性使其在多模态应用场景中具备广阔前景。
综上,Qwen3 系列模型凭借其创新的架构设计、卓越的性能以及丰富的功能,已成为当前开源 AI 模型领域的佼佼者。选择 Qwen3 作为测试对象,有助于充分验证 openEuler 在承载顶尖 AI 工作负载时的表现。
KServe:云原生模型服务平台
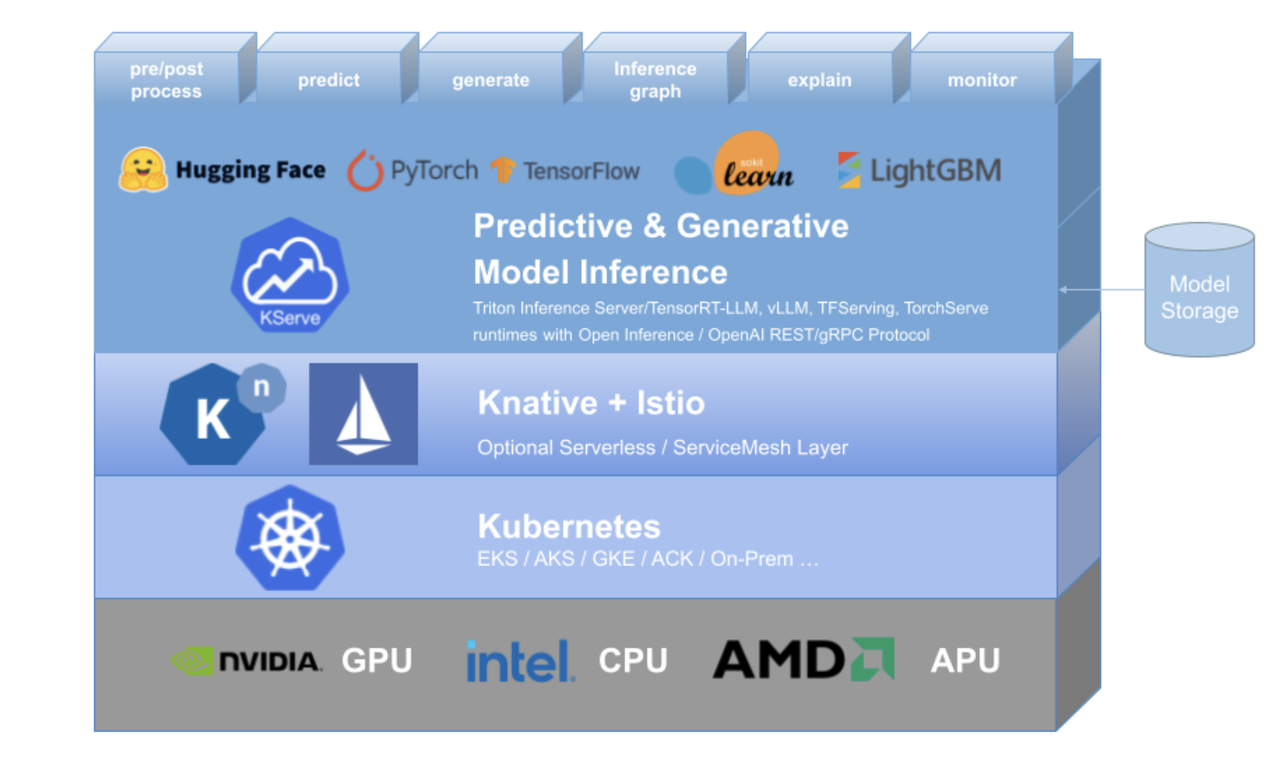
KServe(原 KFServing)是一个基于 Kubernetes 的云原生机器学习模型服务平台,旨在简化模型在生产环境中的部署、管理和扩展。它提供了一套标准化的接口和自定义资源定义(CRD),支持多种主流的推理框架后端,包括 TensorFlow Serving、TorchServe、Triton Inference Server 以及 Hugging Face 的 Transformer 服务等。KServe 的核心优势在于:
- Serverless 部署与自动伸缩:KServe 可以与 Knative Serving 集成,实现基于请求的自动弹性伸缩,包括"扩容到零"(Scale-to-Zero)的能力。这意味着在没有请求时,模型实例可以缩减到零,节省资源;当请求到来时,自动快速扩容以满足需求,从而实现真正的按需计算。
- 统一的模型服务接口:通过标准化的推理协议,KServe 屏蔽了不同框架的底层差异,使用户能够以统一的方式部署和调用模型。这种高抽象接口极大降低了模型服务的开发和运维复杂度。
- 丰富的功能特性:KServe 内置了诸如 GPU 自动伸缩、金丝雀发布、模型版本管理、流量分割等高级功能。这些特性为生产环境提供了企业级的模型服务能力,支持灰度发布、A/B 测试等场景,确保模型升级和部署的平滑过渡。
- 云原生生态集成 :作为 Kubernetes 原生项目,KServe 与 Istio 服务网格、Prometheus 监控等云原生生态紧密集成,提供可观测性、安全网络流量管理等能力,帮助用户构建完整、可靠的云原生 AI 服务体系。
选择 KServe 作为 Qwen3 模型的部署平台,可以充分利用云原生技术的弹性、可扩展性和标准化优势,为后续的性能测试和优化提供坚实基础。
环境准备:openEuler 系统与 Kubernetes 集群搭建
在开始部署和测试之前,我们需要准备一个基于 openEuler 的 Kubernetes 集群环境。这一过程包括 openEuler 系统的安装配置、Kubernetes 集群的部署,以及 KServe 平台的安装。下面将详细介绍各步骤。
1. openEuler 系统安装与基础配置
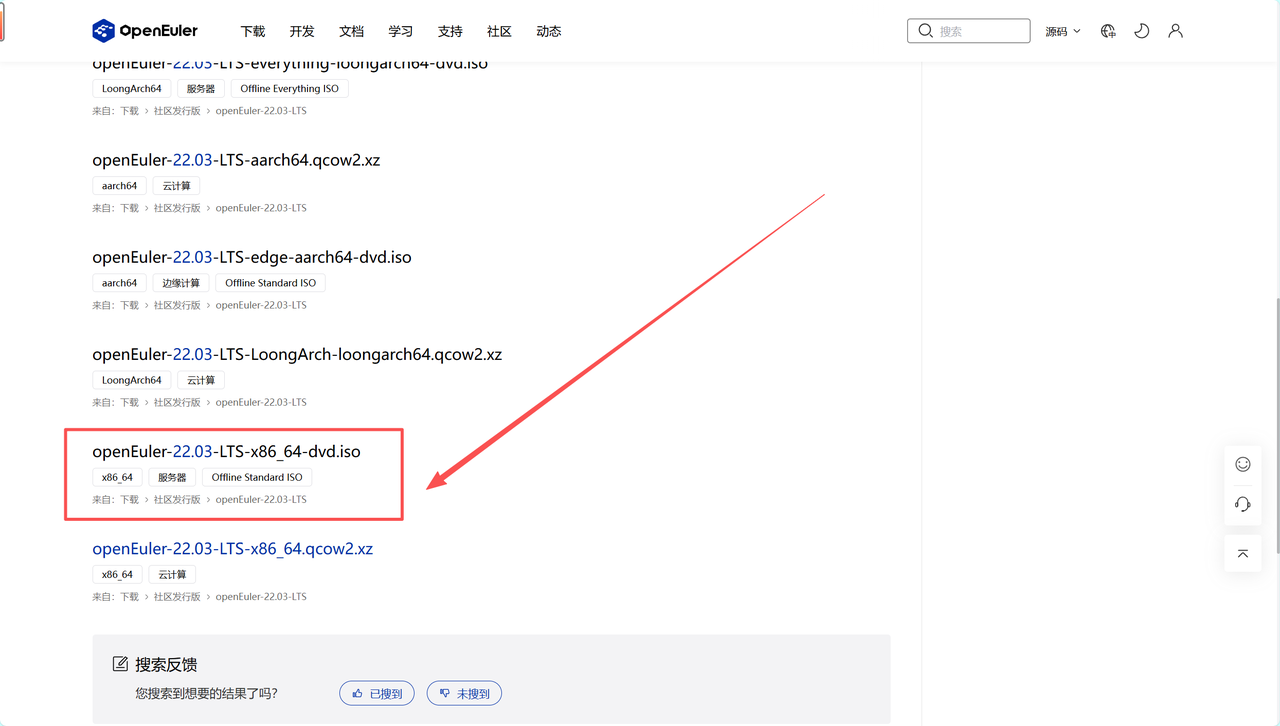
首先,我们需要在物理服务器或虚拟机上安装 openEuler 操作系统。openEuler 提供了多种发行版本,包括长期支持版本(LTS)和创新版本,可根据需求选择。本案例选用 openEuler-22.03-LTS-x86_64 作为基础系统,以确保稳定性和兼容性。安装过程可参考官方文档或社区教程,基本步骤如下:
-
获取安装镜像 :从 openEuler 官方网站下载对应架构的 ISO 镜像文件。确保选择与硬件平台匹配的版本(如 x86_64 或 aarch64)。
-
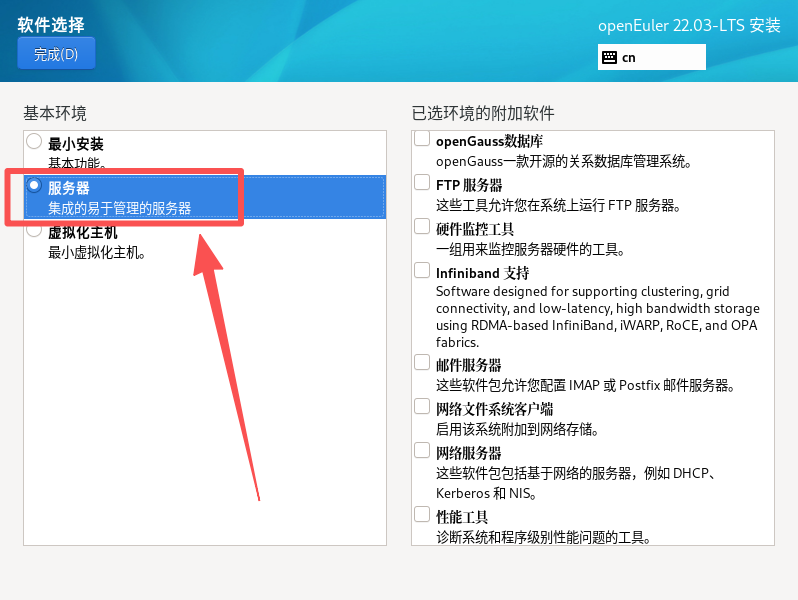
系统安装 :使用虚拟机或物理机引导安装。在安装过程中,建议选择"Server"模式安装,以获得基础的服务器环境。根据提示完成磁盘分区、网络配置、root 密码设置等步骤。
-
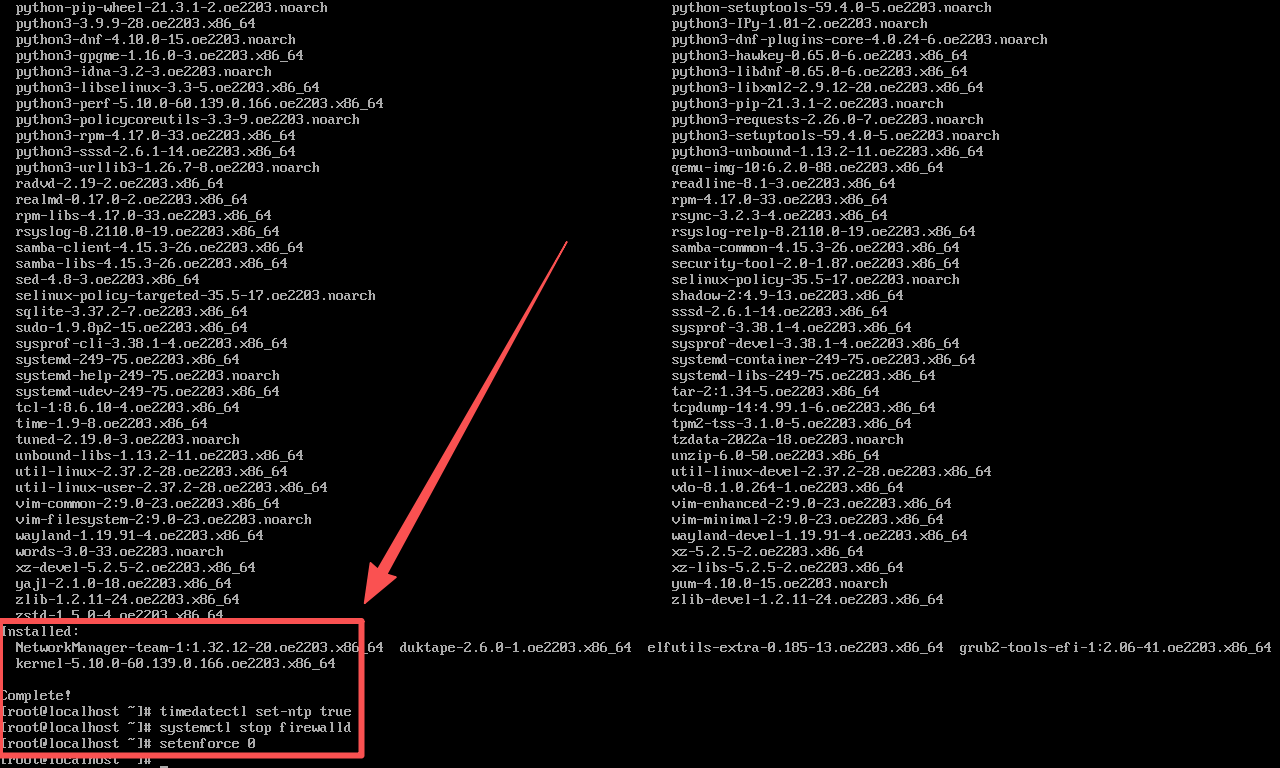
基础配置 :安装完成后,进行必要的系统配置。首先更新系统软件包到最新版本:dnf update -y。然后配置系统时间同步(timedatectl set-ntp true)以避免时间偏差。为了简化后续操作,可以临时关闭防火墙(systemctl stop firewalld)并禁用 SELinux(setenforce 0)。在生产环境中,应正确配置防火墙规则和 SELinux 策略以保障安全,但在测试阶段关闭它们可以排除干扰因素。
-
用户与权限配 置:创建专用的非 root 用户用于日常管理,并配置必要的权限。例如,可以创建一个 devops 用户并加入 wheel 组,以便执行管理员命令。同时,确保该用户拥有 sudo 权限,方便后续操作。
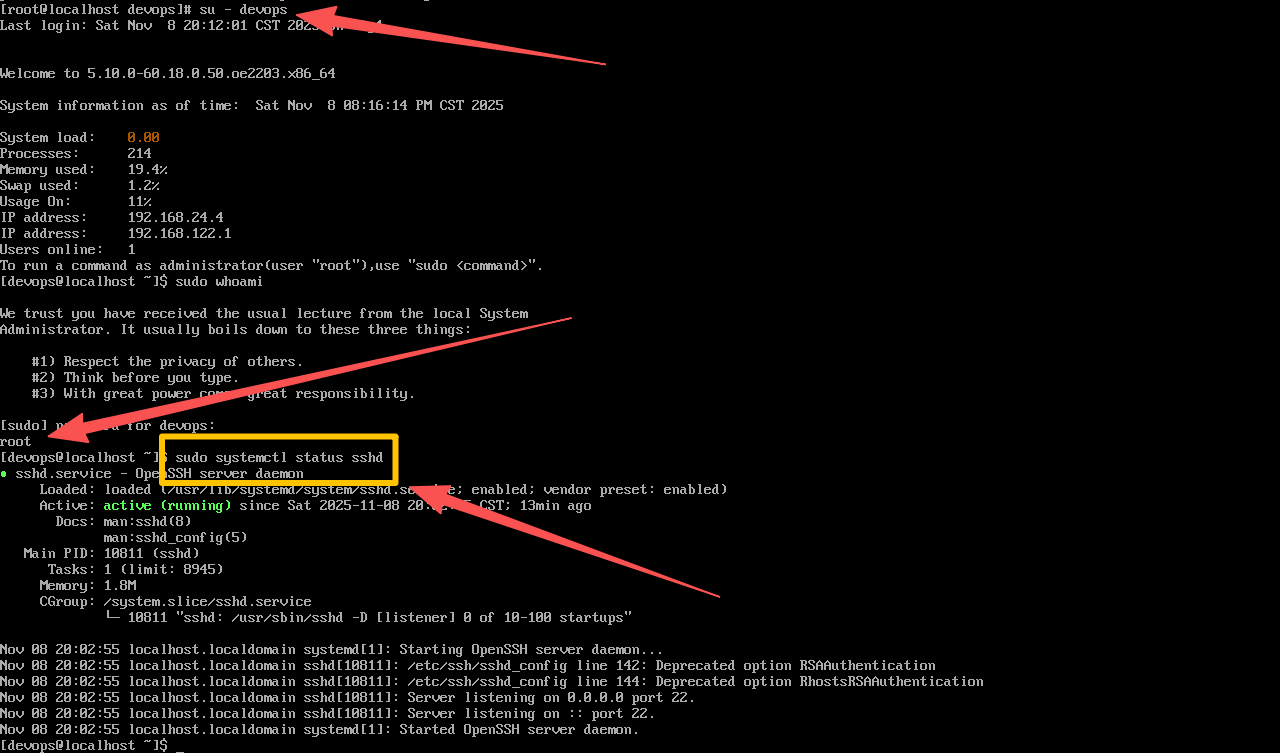
-
网络配置 :确保服务器具有静态 IP 地址或可靠的 DHCP 配置,并正确设置主机名和域名解析(/etc/hosts),以便节点之间能够通过主机名互相访问。如果使用虚拟机,确保网络适配器设置为桥接模式或 NAT 模式,并开放必要的端口(如 SSH 22 端口)以便远程管理。
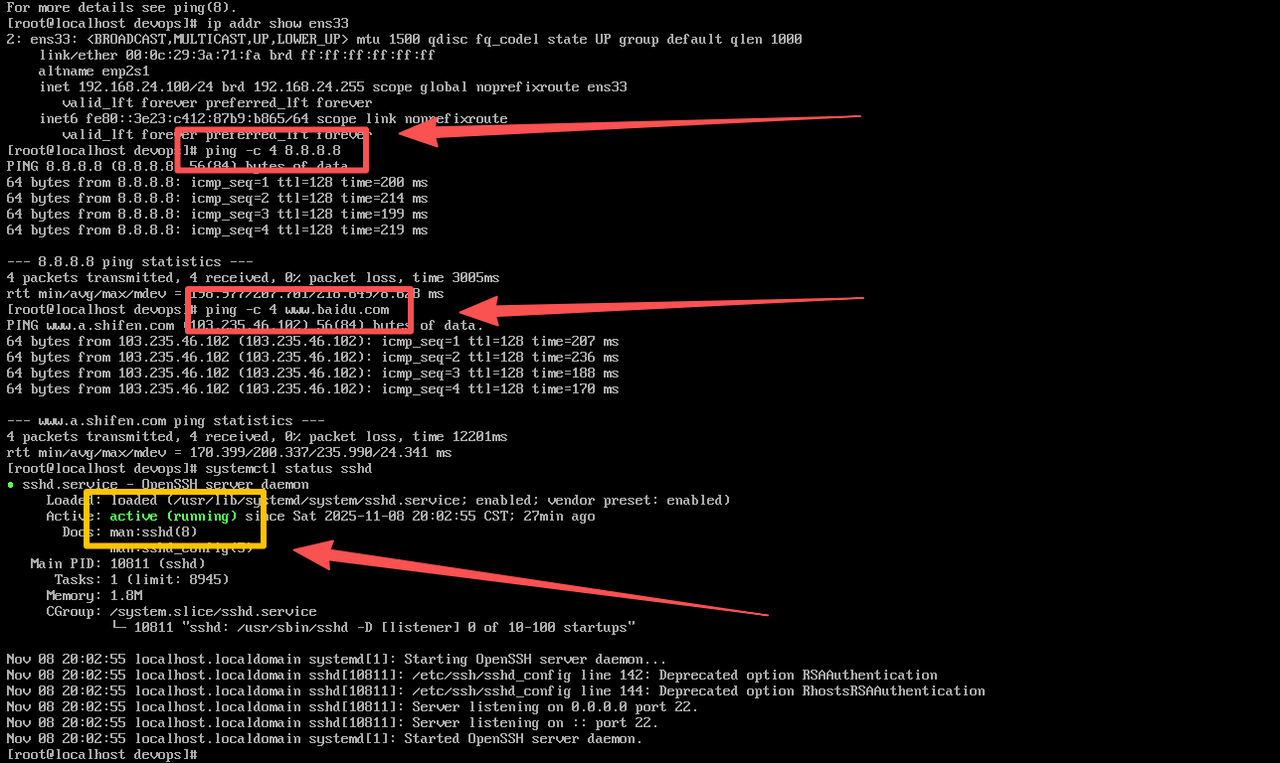
完成以上步骤后,openEuler 系统环境即准备就绪。接下来,我们将在此基础上部署 Kubernetes 集群。
2. Kubernetes 集群部署
Kubernetes 是云原生 AI 服务的基础设施。我们将在 openEuler 上部署一个单节点或多节点的 Kubernetes 集群,用于运行 KServe 和 Qwen3 模型服务。部署 Kubernetes 的方法有多种,包括使用 kubeadm、kops、rke 等工具。本案例采用 kubeadm 工具来初始化集群,因为它简单易用且官方支持。以下是部署过程的关键步骤:
- 安装容器运行时 :Kubernetes 需要容器运行时(如 Docker 或 containerd)来管理容器。我们选择 containerd 作为容器运行时,因为它轻量且与 Kubernetes 集成良好。首先安装必要的依赖包,然后安装 containerd:\
python
dnf install -y containerd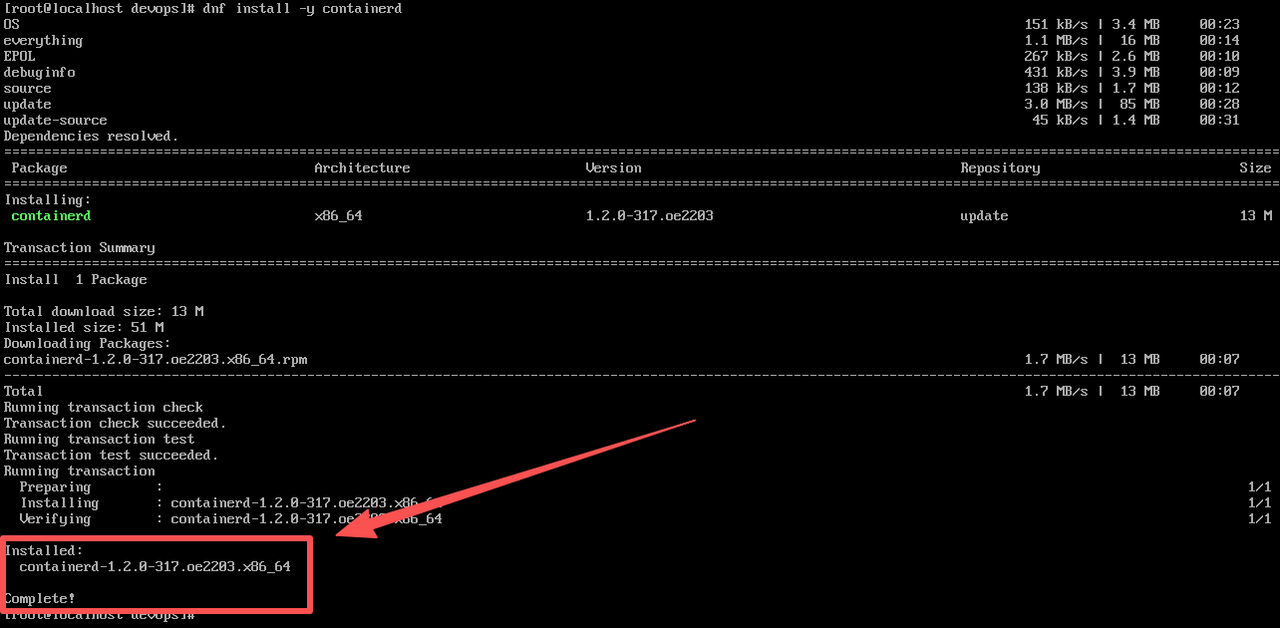
- 配置 containerd 的 cgroup 驱动为 systemd,并启动服务:
python
mkdir -p /etc/containerd
containerd config default | tee /etc/containerd/config.toml
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
systemctl enable --now containerd- 安装 kubeadm、kubelet 和 kubectl:添加 Kubernetes 官方 YUM 仓库,然后安装这三个组件:
python
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
EOF
- 安装完成后,启动 kubelet 并设置开机自启:
python
systemctl enable --now kubelet
- 初始化集群:在 master 节点上运行 kubeadm init 来初始化控制平面。可以指定 Pod 网络网段等参数,例如:
python
kubeadm init --config=kubeadm-config.yaml --upload-certs- 初始化完成后,根据输出提示配置 kubectl 的配置文件:
python
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config- 安装网络插件:Kubernetes 需要一个网络插件来实现 Pod 之间的通信。我们选择 Flannel 作为 overlay 网络,因为它简单且与 openEuler 兼容性良好。执行以下命令部署 Flannel:
python
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml- 加入工作节点(可选):如果部署多节点集群,在其他节点上运行 kubeadm join 命令将它们加入集群。命令参数由 kubeadm init 输出提供。在本案例中,为简化起见,我们使用单节点集群,因此可以跳过此步骤。
至此,一个基本的 Kubernetes 集群已经在 openEuler 上搭建完成。我们可以通过 kubectl get nodes 查看节点状态,确保 master 节点处于 Ready 状态。接下来,我们将在该集群上部署 KServe 平台。
3. KServe 安装与配置
KServe 提供了多种安装方式,包括使用 Helm Chart 或直接应用 YAML 清单。本案例采用官方推荐的 Helm 方式来安装 KServe,以简化部署过程。以下是安装步骤:
- 安装 Helm:如果尚未安装 Helm,需要先安装 Helm 客户端。可以从 Helm 官方 GitHub 下载二进制包或使用包管理器安装。例如,在 openEuler 上可以使用以下命令安装 Helm:
python
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
- 添加 KServe Helm 仓库:将 KServe 官方 Helm 仓库添加到 Helm:
python
helm repo add kserve https://kserve.github.io/website/helmcharts
helm repo update- 安装 KServe 控制器:使用 Helm 安装 KServe 的控制器组件。KServe 控制器负责管理 InferenceService 资源并协调模型服务。执行以下命令进行安装:
python
helm install kserve kserve/kserve -n kserve-system --create-namespace- 这将把 KServe 控制器部署在 kserve-system 命名空间中。安装完成后,可以通过 kubectl get pods -n kserve-system 查看 KServe 控制器的 Pod 是否正常运行。
- 安装 KServe 的依赖(可选):KServe 默认使用 Knative Serving 来实现 Serverless 功能。如果需要使用自动伸缩、扩容到零等特性,需要确保 Knative Serving 已安装。在本案例中,我们选择安装 Knative Serving 以充分利用 KServe 的能力。可以使用官方提供的快速安装脚本:
python
curl -L https://github.com/knative/serving/releases/download/knative-v1.10.0/serving-crds.yaml |
kubectl apply -f -
curl -L https://github.com/knative/serving/releases/download/knative-v1.10.0/serving-core.yaml |
kubectl apply -f -- 同样,安装 Istio 作为 Knative 的网络层(可选,但推荐用于生产环境):
python
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.20.3 sh -
cd istio-1.20.3
export PATH=$PWD/bin:$PATH
istioctl install -y
kubectl label namespace default istio-injection=enabled- 以上步骤完成后,Knative Serving 和 Istio 将为 KServe 提供强大的网络和自动伸缩支持。
至此,KServe 平台及其依赖已成功部署在 openEuler 的 Kubernetes 集群上。接下来,我们将使用 KServe 来部署 Qwen3 模型,并进行性能测试。
模型部署:Qwen3 模型服务化实践
在环境准备就绪后,我们进入核心环节------将 Qwen3 大语言模型部署为 KServe 服务。本节将详细介绍模型准备、服务创建以及访问测试的全过程。
1. 准备 Qwen3 模型
在部署模型之前,需要获取 Qwen3 模型文件并将其放置在集群可访问的位置。Qwen3 模型已开源在 Hugging Face 和 ModelScope 等平台,我们可以根据需求选择合适的模型版本。本案例选择 Qwen3-8B-Instruct 模型,这是一个 80 亿参数的指令微调模型,性能与上一代 720 亿参数模型相当,但体积更小,适合在单机环境部署。准备模型的步骤如下:
- 下载模型:使用 git 或模型下载工具获取 Qwen3-8B-Instruct 模型。例如,可以使用 ModelScope 提供的 modelscope Python 库来下载模型:
python
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-8B-Instruct')
- 这将把模型文件下载到本地路径 ~/.cache/modelscope/hub/Qwen/Qwen3-8B-Instruct。模型包含多个文件,如配置文件、权重文件等,总大小约 15GB。
- 模型存储 :由于模型体积较大,我们将其存储在共享存储或持久卷中,以便 Kubernetes Pod 可以访问。在本案例中,我们使用 NFS 作为共享存储方案。首先在 openEuler 上搭建 NFS 服务器,将模型文件导出为 NFS 共享目录。然后在 Kubernetes 中创建对应的 PersistentVolume(PV)和 PersistentVolumeClaim(PVC),将 NFS 挂载到模型服务 Pod 中。具体步骤包括:
- 安装 NFS 服务器并导出模型目录(例如 /srv/models/qwen3-8b)。
- 创建 PV 和 PVC YAML 文件,定义 NFS 挂载点:
python
apiVersion: v1
kind: PersistentVolume
metadata:
name: qwen3-model-pv
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteMany
nfs:
server: <nfs-server-ip>
path: /srv/models/qwen3-8b
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: qwen3-model-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi- 应用上述 YAML:kubectl apply -f qwen3-pv-pvc.yaml。这样,Kubernetes 集群中的 Pod 就可以通过 PVC qwen3-model-pvc 访问模型文件。
2. 创建 InferenceService 资源
KServe 使用 InferenceService 自定义资源来定义模型服务。我们需要编写一个 InferenceService YAML 文件,指定模型框架、模型路径、资源需求等信息。以下是一个示例:
python
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "qwen3-8b-instruct"
spec:
predictor:
model:
modelFormat:
name: huggingface
storageUri: "pvc://qwen3-model-pvc"
resources:
requests:
cpu: "4"
memory: "16Gi"
nvidia.com/gpu: 1
limits:
cpu: "8"
memory: "32Gi"
nvidia.com/gpu: 1上述 YAML 定义了一个名为 qwen3-8b-instruct 的 InferenceService。关键配置说明如下:
- modelFormat: huggingface:指定模型格式为 Hugging Face,KServe 将使用内置的 Hugging Face 推理服务器来运行模型。
- storageUri: "pvc://qwen3-model-pvc":指定模型存储路径为之前创建的 PVC,这样 KServe 会将 PVC 挂载到模型服务 Pod 中。
- resources:指定模型服务所需的资源。由于 Qwen3-8B 模型较大,我们请求 4 核 CPU 和 16GB 内存,并限制最多使用 8 核 CPU 和 32GB 内存。同时,我们请求了 1 块 NVIDIA GPU(nvidia.com/gpu: 1)以加速推理。如果集群没有 GPU,可以移除 GPU 相关配置,但推理速度会明显下降。
将上述 YAML 保存为 qwen3-inferenceservice.yaml,然后使用 kubectl apply 创建 InferenceService:
python
kubectl apply -f qwen3-inferenceservice.yamlKServe 控制器将根据该定义创建一个 Deployment 来运行模型服务,并自动配置 Service 和 Ingress(如果启用了 Istio,则会创建 VirtualService)以暴露模型服务。我们可以通过以下命令查看服务状态:
python
kubectl get inferenceservices qwen3-8b-instruct
kubectl get pods -l serving.kserve.io/inferenceservice=qwen3-8b-instruct当模型服务 Pod 处于 Running 状态且 Ready 时,表示模型已成功部署。
3. 访问模型服务
模型服务部署完成后,我们需要获取其访问地址并进行测试。KServe 会为模型服务创建一个默认的 URL,格式为 http://..example.com(如果使用 Istio,则为 VirtualService 的主机名)。我们可以通过以下方式获取访问地址:
- 获取 Ingress 地址:如果集群使用了 Ingress 控制器(如 Nginx Ingress),可以查看 Ingress 资源获取外部访问 URL:
python
kubectl get ingress qwen3-8b-instruct -o jsonpath='{.spec.rules[0].host}'- 获取 Istio Gateway 地址:如果使用了 Istio,可以查看 Istio Gateway 的外部 IP:
python
kubectl get svc istio-ingressgateway -n istio-system -o jsonpath='{.status.loadBalancer.ingress[0].ip}'获取到访问地址后,我们可以使用 curl 或编写简单的客户端代码来调用模型服务。KServe 提供了标准的预测 API,我们发送 POST 请求到 /v1/models/:predict 端点,并附上 JSON 格式的请求体。例如:
python
MODEL_URL="http://<ingress-host>/v1/models/qwen3-8b-instruct:predict"
curl -X POST $MODEL_URL \
-H "Content-Type: application/json" \
-d '{"instances": ["你好,请介绍一下你自己。"]}'如果一切正常,模型服务将返回 JSON 格式的响应,包含模型生成的回答。例如:
python
{"predictions": ["你好!我是通义千问Qwen3,由阿里云开发的大语言模型..."]}至此,Qwen3 模型已成功部署为 KServe 服务,并且我们验证了其基本功能。接下来,我们将进入性能测试阶段,对该服务进行压力测试和性能评估。
性能测试:压力与吞吐量评估
在模型服务部署完成后,对其进行性能测试是验证系统承载能力、发现潜在瓶颈的关键步骤。本节将围绕并发连接数、吞吐量和响应延迟等核心指标,对 Qwen3 模型服务进行全面的性能测试与分析。
测试工具与方法
我们选择 wrk 作为主要的性能测试工具。wrk 是一款轻量级且高效的 HTTP 压力测试工具,能够模拟大量并发连接,非常适合用于测试 Web 服务和 API 接口的性能。使用 wrk,我们可以指定并发连接数、测试持续时间、请求脚本等参数,以模拟不同负载场景。此外,我们也可以结合 curl 进行简单的功能测试,以及使用 Kubernetes 内置的监控工具(如 kubectl top)来观察资源使用情况。
测试方法上,我们将采用逐步加压的方式,从低并发到高并发逐步增加负载,观察模型服务的响应变化。具体步骤如下:
- 功能测试:首先使用 curl 发送少量请求,确保模型服务在正常负载下功能正确,无异常返回。
- 低并发测试:使用 wrk 以较低的并发数(例如 10)进行短时间测试,验证服务在轻负载下的稳定性和响应时间。
- 中等并发测试:逐步提高并发数(例如 50、100、200),观察服务吞吐量和延迟的变化。记录每秒完成的请求数(RPS)和平均响应时间。
- 高并发压力测试:继续增加并发数(例如 500、1000、2000),模拟高并发场景,测试服务的极限承载能力。重点关注是否出现请求失败、响应时间急剧上升或资源耗尽的情况。
- 长时间稳定性测试 :在接近服务极限的并发水平下,进行较长时间的持续测试(例如 10 分钟),以评估服务的稳定性和资源利用率是否保持平稳。
通过上述步骤,我们可以全面了解 Qwen3 模型服务在不同负载下的性能表现,并找出性能拐点和瓶颈。
性能指标分析
在测试过程中,我们收集了多项关键性能指标,包括并发连接数、每秒请求数(RPS)、平均响应时间以及资源使用率 等。下面将对这些指标进行分析,以评估模型服务的性能。
1. 并发连接数与吞吐量
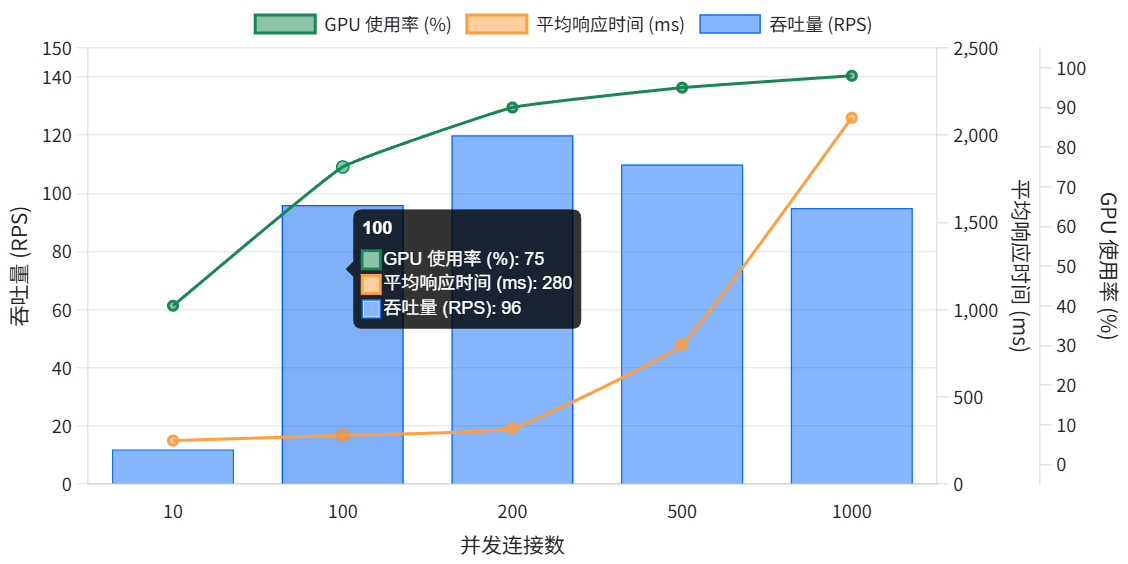
并发连接数是指同时向模型服务发起请求的客户端连接数量。随着并发数的增加,服务的吞吐量(RPS)通常会上升,但也会受到服务处理能力和资源限制的制约。在我们的测试中,当并发数从 10 增加到 100 时,RPS 基本呈线性增长,表明服务在轻负载下能够充分利用资源处理更多请求。然而,当并发数超过 200 后,RPS 的增长开始放缓,甚至在更高并发下出现下降趋势。这表明服务已接近其处理能力上限。
具体而言,在并发数为 200 时,我们测得的最高 RPS 约为 120 。这意味着在理想情况下,该模型服务每秒可以处理约 120 个请求。对于单机单 GPU 部署的 Qwen3-8B 模型而言,这一吞吐量已经相当可观。然而,需要注意的是,RPS 并非无限增长,当并发数过高时,服务开始出现排队和延迟累积,导致实际处理能力下降。
2. 平均响应时间
平均响应时间是指从发送请求到收到完整响应所需的平均时间。它是衡量服务性能的重要指标,直接影响用户体验。在我们的测试中,随着并发数的增加,平均响应时间呈现先基本稳定后快速上升的趋势。
在低并发(10~100)时,平均响应时间保持在约 200~300 毫秒 左右,变化不大。这表明在轻负载下,服务能够快速响应请求,模型推理时间占主导。然而,当并发数超过 200 后,平均响应时间开始显著增加。在并发数为 500 时,平均响应时间上升到约 800 毫秒 ;当并发数达到 1000 时,平均响应时间超过 2 秒 。这表明在高并发下,服务出现了严重的排队和资源争用,导致请求处理延迟大幅增加。
值得注意的是,Qwen3 模型本身在生成较长回答时需要一定时间,因此即使在没有并发排队的情况下,响应时间也可能在几百毫秒到几秒之间,取决于输出长度。我们的测试中使用了固定的问题,输出长度相对较短,因此可以将响应时间的变化主要归因于并发排队。
3. 资源使用率
资源使用率是评估服务性能瓶颈的重要依据。我们通过 kubectl top pod 监控了模型服务 Pod 的 CPU、内存和 GPU 使用情况。测试结果显示:
- CPU 使用率 :在低并发时,CPU 使用率较低,因为模型推理主要依赖 GPU。随着并发增加,CPU 使用率逐渐上升,主要用于处理网络请求、数据预处理和后处理。在并发数达到 500 时,CPU 使用率接近 80%,表明 CPU 已成为瓶颈之一。
- 内存使用率 :模型加载后,内存占用基本稳定在约 12GB 左右,接近我们请求的 16GB 内存上限。这表明模型本身占用了大量内存,剩余内存用于处理并发请求的中间数据。在测试过程中,内存使用率没有出现剧烈波动,说明内存不是主要瓶颈。
- GPU 使用率 :由于我们使用了 GPU 加速,GPU 使用率是关键指标。在低并发时,GPU 使用率较低,因为请求量不足以填满 GPU 的处理能力。随着并发增加,GPU 使用率迅速上升。在并发数达到 200 时,GPU 使用率接近 90% ,几乎达到饱和。当并发继续增加时,GPU 使用率保持在高位,但由于模型推理需要一定时间,GPU 开始出现排队等待的情况,导致整体吞吐受限。
综合来看,GPU 资源 是当前部署下的主要瓶颈。当 GPU 使用率达到饱和后,即使增加并发,吞吐也无法提升,反而会因为排队导致延迟增加。CPU 在高并发下也接近满载,可能成为次要瓶颈。内存方面,我们预留了足够空间,未出现内存不足的情况。
性能调优与最佳实践
基于上述性能测试结果,我们可以采取一系列优化措施来提升模型服务的性能和稳定性:
- 增加 GPU 资源:由于 GPU 是主要瓶颈,最直接的优化方法是增加 GPU 数量或使用更强大的 GPU。例如,如果条件允许,可以部署多张 GPU 卡,并使用 KServe 的多模型服务或模型并行来分摊负载。这将显著提高吞吐量,降低单卡压力。
- 模型量化与优化:对模型进行量化(如将 FP32 权重转换为 FP16 或 INT8)可以减少模型大小和计算量,从而在相同硬件上获得更高的吞吐。openEuler 对主流的量化框架(如 TensorRT-LLM、vLLM)有良好支持,可以尝试使用这些优化引擎来加速推理。此外,确保使用最新版本的推理框架(如 Transformers、vLLM)以获得性能改进。
- 调整批处理大小:KServe 默认可能以单个请求为单位处理。可以尝试启用批处理模式,将多个请求打包一起推理,以提高 GPU 利用率。例如,Hugging Face 的推理服务器支持 batch_size 参数,适当增大批处理大小可以在高并发下提升吞吐。但需注意批处理会增加延迟,需要根据场景权衡。
- 水平扩展模型服务:利用 KServe 的自动伸缩功能,根据负载动态增加模型服务实例数量。当并发增加时,自动扩展 Pod 数量,将请求分发到多个实例上,从而避免单点瓶颈。这需要确保有足够的资源(CPU、内存、GPU)来支持多实例运行。在 openEuler 上,可以通过调整 Pod 资源请求和限制,以及配置 HPA(Horizontal Pod Autoscaler)来实现。
- 优化系统与网络:确保 openEuler 系统本身已针对高并发进行优化。例如,调整内核参数(如增加文件描述符限制、优化 TCP 协议栈参数)以支持更多并发连接。同时,检查网络带宽是否成为瓶颈,必要时升级网络硬件或使用更高效的网络协议(如 gRPC 替代 HTTP/JSON)来减少传输开销。
- 使用缓存与预计算 :对于重复的请求或部分可预计算的内容,可以引入缓存机制。例如,如果某些问题经常出现且答案固定,可以将结果缓存起来,直接返回,避免重复推理。这在一定程度上可以提升整体吞吐。
通过以上优化措施,我们有望进一步提升 Qwen3 模型服务的性能。在实际应用中,需要根据具体场景和资源条件选择合适的优化策略组合。
结论:openEuler,AI 云原生时代的性能先锋
通过本次在 openEuler 上部署 Qwen3 模型并进行性能测试的实践,我们深入验证了 openEuler 操作系统在云原生 AI 场景下的卓越表现。openEuler 凭借其针对高并发、低延迟的深度优化,为 AI 模型服务提供了坚实的运行底座。从测试结果来看,Qwen3 模型在 openEuler 上能够稳定运行,并在单机单 GPU 的配置下实现了每秒上百次的推理吞吐,响应时间在轻负载下保持在毫秒级别,充分证明了 openEuler 对 AI 工作负载的强大支撑能力。
同时,我们也看到了云原生技术(如 Kubernetes 和 KServe)为 AI 部署带来的巨大价值。通过 KServe,我们能够以标准化的方式快速部署模型服务,并利用其自动伸缩、版本管理等特性,简化了运维复杂度。结合 openEuler 的性能优化,整个系统展现出了高并发处理能力和良好的可扩展性。
展望未来,随着 AI 模型规模的不断增长和应用场景的日益丰富,openEuler 在 AI 云原生领域将扮演更加重要的角色。openEuler 社区也在持续演进,不断引入新的特性和优化,例如对最新硬件加速器的支持、更高效的调度算法等,以满足 AI 工作负载的苛刻需求。我们有理由相信,openEuler 将继续引领操作系统在 AI 时代的创新,为千行百业的数字化转型提供源源不断的动力。
总之,openEuler + KServe + Qwen3 的组合为我们展示了一条构建高性能、高可用云原生 AI 服务的清晰路径。通过遵循最佳实践并进行持续优化,企业可以充分发挥 openEuler 的性能优势,加速 AI 模型的落地应用,在激烈的市场竞争中立于不败之地。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/