关于认识,和优化idea开发
一直想抽时间,彻底梳理一下idea这个开发工具。
要理解idea,就不能只理解idea,要理解他要处理的问题。
我们一般给idea的定义就是一个代码编辑器,我觉得这个定义太肤浅了。
完整的概念应该是,为写代码的时候提供整套生命周期机制的工具。
要理解idea,就要理解我们在写代码的时候,一共要做哪些事情、所谓idea只是帮助我们完成这些要做的事情,提供了一系列的机制来处理这些要做的事情,idea只是辅助,提供了一个可视化操作平台,来帮助我们完成代码编写,这个是地位和定义。。
要理解idea,如果只理解它提供的ui界面,就是错误的,
我们要去想这个设计的初衷是什么,是为了解决什么问题。要有一套知识体系去概括这套问题。这个是核心,其他的就是一些不重要的边角料设计,提升开发效率。核心还是要聚焦这个解决的问题。
我们就以一个一个最小开发的demo,来认识idea
这里要简述一下,认识这些软件,一定要动态的在解决问题的时候去认识。
这里先定义一下软件
所谓的软件,就是人和电脑交互的载体,他提供了一系列机制,让我们轻松的完成一些事情。首先自己要清楚,自己要干什么,然后,借助软件提供的机制,只要带点按钮就可以达到目的。
所以用软件的难点,不在于看ui和点击按钮,而是要理解自己要做的事情和软件提供什么方面的机制。来利用。
我们这里现在只研究项目运行和配置的,以一个单体的springboot为例。
我们写代码,要在本地运行,它真实的过程是什么样子的呢。
新手在idea配置的时候,应该没有遇到这个老是报错的问题。
项目的代码是首先交给idea交给,maven,然后去进行编译,然后给到jdk,jdk利用它内部的jvm在windows,或者linux环境下运行。
今天就带你展示一下idea的风采。
这里不讲基础的下载,配置环境变量,使用idea之类的、
直接按照流程来。
1.把文件夹在idea上打开,并且让idea认识问价夹里的文件
在这个文件打开以后,我们要让idea去识别这个每个文件是什么类型,idea会给我们做高光展示。做这个通常是idea里面有不止.java类型的文件,如在这里插入代码片果是.jsp类型的文件。等等也能让idea识别。
在这一步,我们要做两件事情。
1.让idea认识这个是个maven项目,让pom加载。
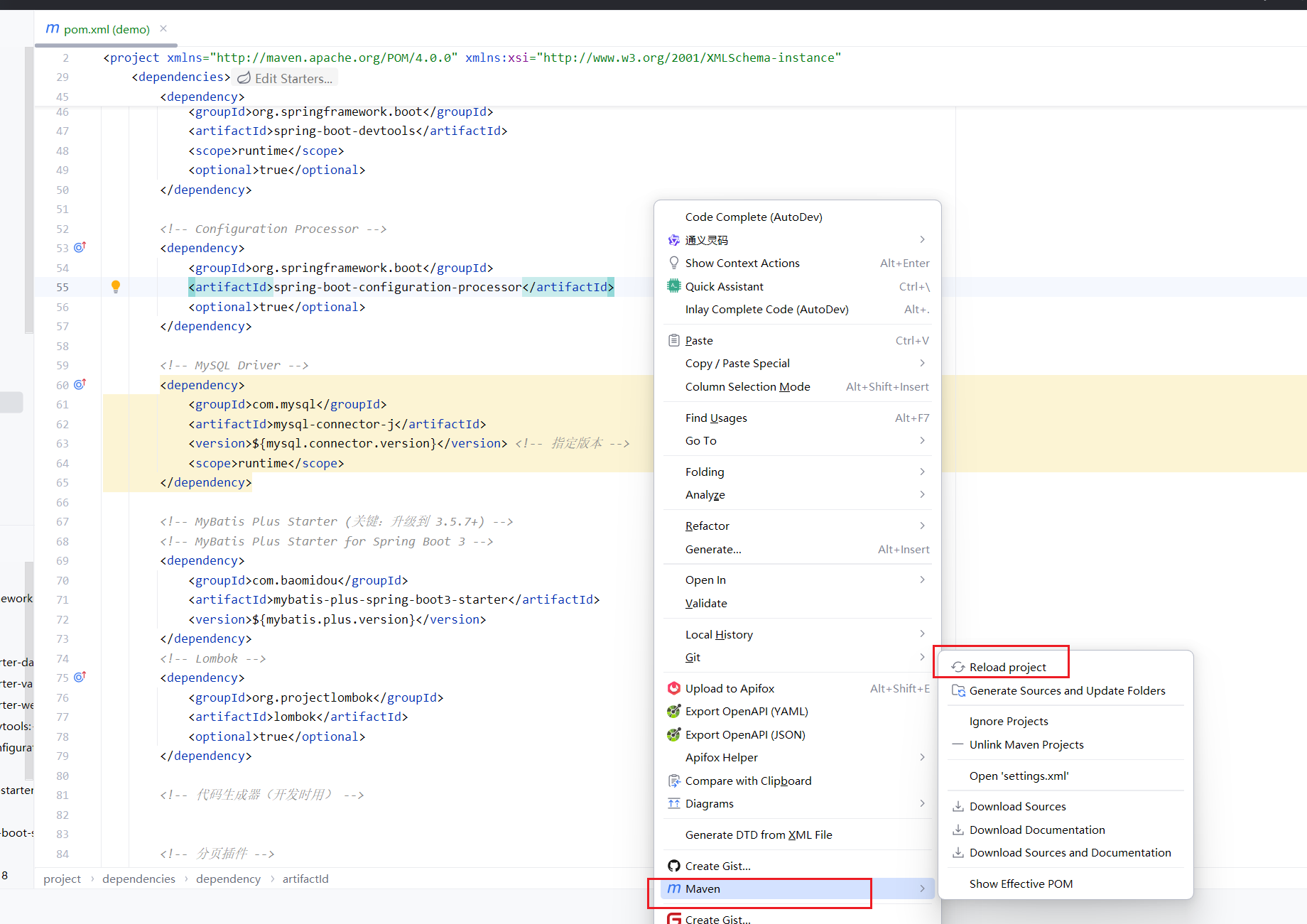
2.做好对应的文件夹的分析
2.配置项目的编译阶段。
什么是编译。就是把java文件变成class文件,
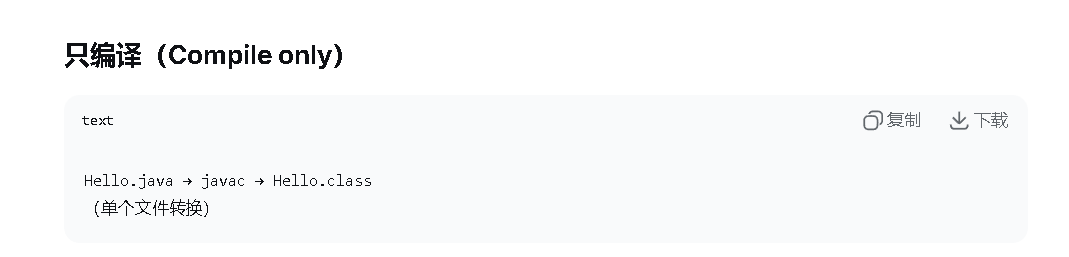
我们为什么要管这个编译阶段,以及这个编译阶段要管什么内容。
由于java这语言,是不断进化的java8,java17。
首先要下载足够高版本的jdk软件,才有java语言版本这么一说。
所谓的jdk,其实就是java运行环境的软件,它里面有jvm、还要让操作系统适应jdk,所以前期做一系列配置。
我们只有下载了足够高版本的jdk才能使用高级语法,所以首先我们这里解决编译期遇到的问题。
每次进化都会有新语法。
我们在idea里配置这个语言版本,他就能检查到错误,如果你在jdk8的环境下,使用java17的语言,就会报错。
配置整体项目的环境,我们这里要确定3个东西
1.对整个project。要使用什么版本的jdk,以及项目要什么什么语言
2.对于具体模块,要使用什么版本,以及具体语言
来做一个解释为什么需要配置这个
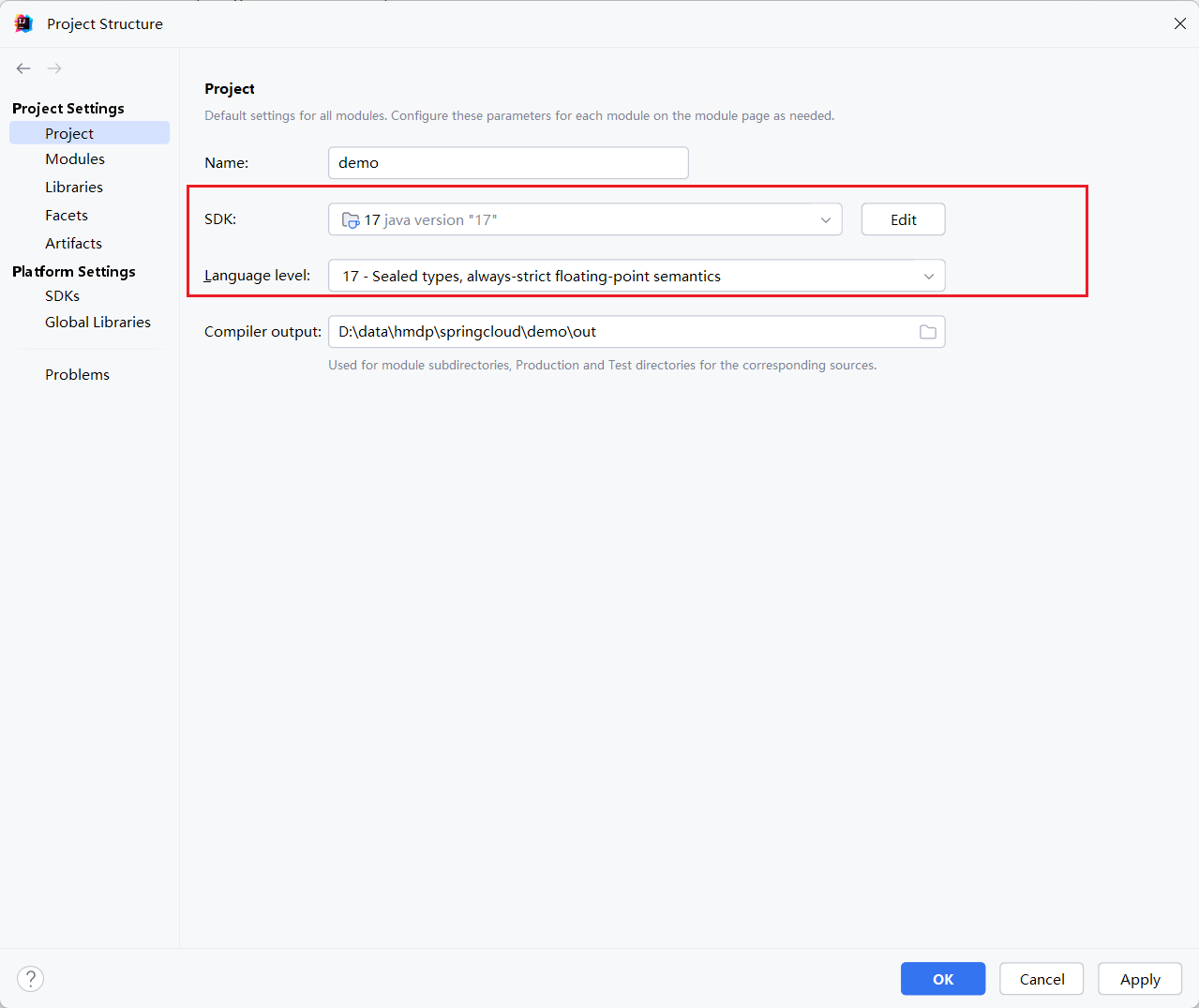
这个是多模块的,单体的就不展示了。
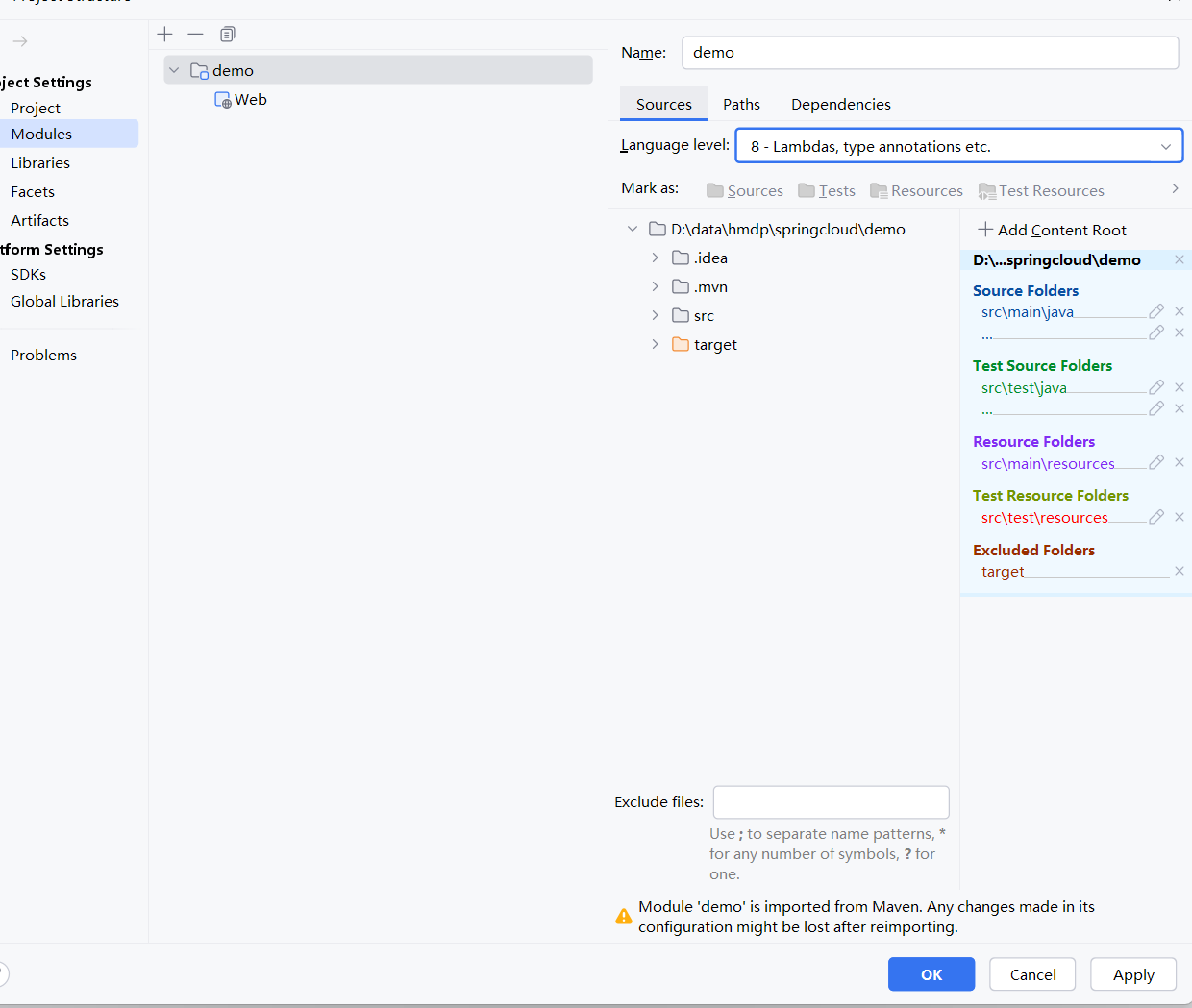
这个是一个配置的领域,还有一个idea提供的关于编译期的配置大全,让deepseek解释了一下。
我这里先做一个大致的介绍:
这个是idea提供给我们,项目在jvm上编译的时候,可以配置的东西。
我们可以决定什么文件,进入到jvm里进行编译,什么不进入
对于java compile 可以选择,项目编译运行的时候的语言版本,和开发中idea的版本不同
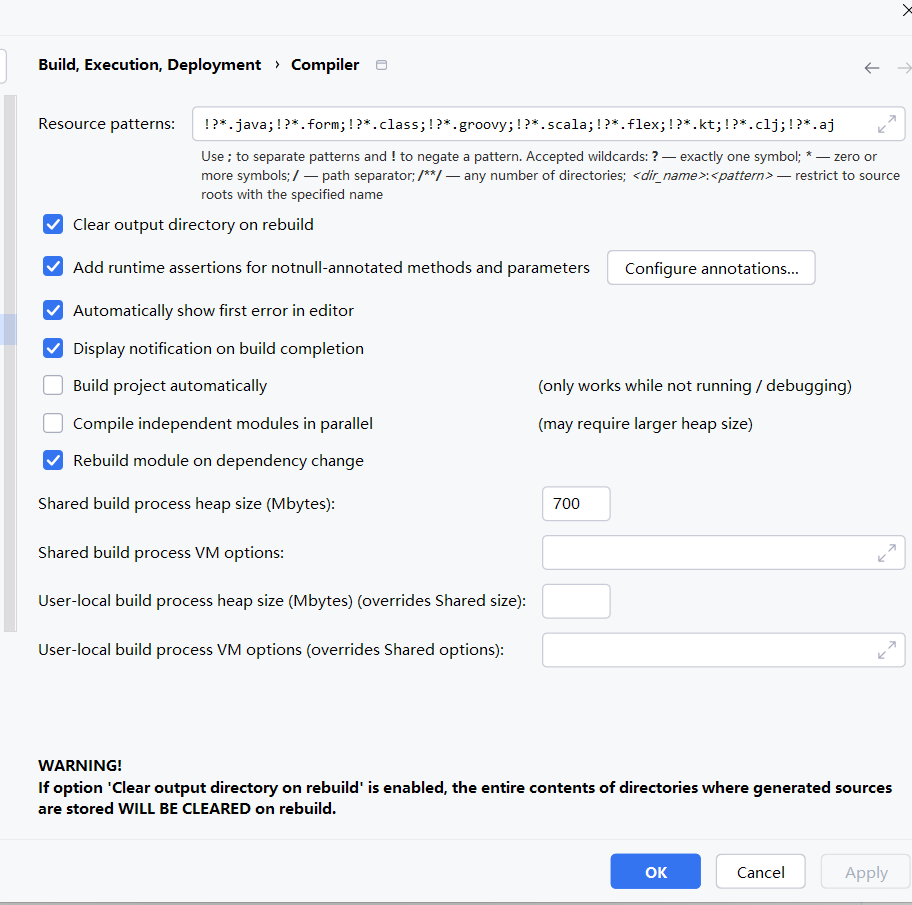
这是 IntelliJ IDEA 的编译器全局设置面板,主要用于控制项目的编译行为和性能。每个选项都针对特定的编译场景或问题。下面我为你详细解释每个部分的作用和解决的问题:
🛠 一、资源模式匹配(Resource patterns)
text
.java; .form;.class; .groovy;.scala; .flex;.kt; .clj;*.aj
作用:定义哪些文件类型会被编译器识别为"源文件"并进行编译处理。
解决问题:
确保编译器正确处理多种语言(Java、Groovy、Kotlin、Scala等)。
排除不需要编译的文件(如.txt、.md)。
🧹 二、清理输出目录(Clear output directory on rebuild)
作用:在"重建(Rebuild)"时自动清理输出目录(如out/、target/classes/)。
解决问题:
避免残留的旧.class文件导致类冲突或版本不一致。
警告:如果启用了此选项,生成的源码目录(如 Lombok 生成的代码)也会被清理,可能导致编译错误。
🔍 三、空值检查断言(Add runtime assertions for notnull-annotated...)
作用:为带有 @NotNull 注解的方法和参数在运行时自动插入空值检查断言。
解决问题:
提前暴露空指针异常,便于调试。
配合 @NotNull 注解(如 javax.annotation.Nonnull 或 Lombok)使用。
📢 四、自动显示第一个错误(Automatically show first error in editor)
作用:编译失败后自动在编辑器中定位到第一个错误。
解决问题:快速跳转到编译错误处,提高调试效率。
🔔 五、构建完成通知(Display notification on build completion)
作用:编译完成后显示系统通知。
解决问题:在长时间编译时,无需盯着进度条,可继续其他工作。
🔄 六、自动构建项目(Build project automatically)
作用:在文件保存时自动触发增量编译。
解决问题:
实时反馈编译错误。
限制:在运行或调试时自动构建会被禁用,避免干扰。
⚡ 七、并行编译模块(Compile independent modules in parallel)
作用:同时编译多个独立的模块(如 Maven 多模块项目)。
解决问题:
提升大型项目的编译速度。
注意:可能需要增加堆内存(-Xmx)。
🔗 八、依赖变化时重建模块(Rebuild module on dependency change)
作用:当模块的依赖发生变化时,自动重新编译该模块。
解决问题:确保依赖更新后,当前模块也能同步更新。
🧠 九、构建进程堆内存设置(Shared build process heap size)
作用:为编译进程分配堆内存(默认为 700 MB)。
解决问题:
避免编译大型项目时因内存不足而失败。
用户本地设置:允许覆盖全局设置,适应不同开发者的机器性能。
⚙ 十、VM 选项(Shared build process VM options)
作用:为编译进程设置 JVM 参数(如 -XX:+UseG1GC)。
解决问题:
优化垃圾回收策略。
启用调试参数等。
💡 总结:这个面板主要解决以下问题
编译性能优化(并行编译、内存设置)。
编译准确性(清理输出目录、依赖感知重建)。
开发者体验(错误定位、通知、自动构建)。
多语言支持(Java、Kotlin、Scala等)。
代码质量辅助(运行时空值检查)。
如果你遇到 编译慢、内存不足、旧文件残留、空指针问题定位困难等情况,可以来这里调整相应设置。
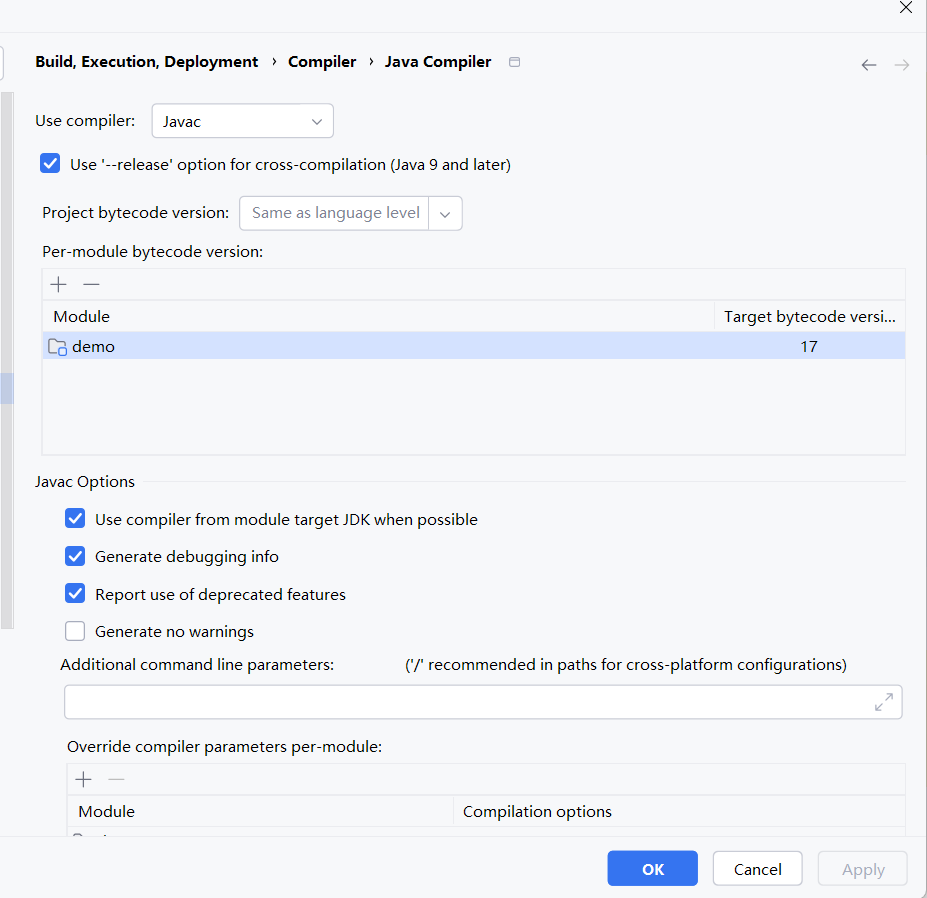
这是 IntelliJ IDEA 中 Java 编译器的详细配置面板,专门用于控制 Java 编译的细节行为。下面为你逐一解释每个选项的作用和解决的问题:
🔧 一、编译器选择(Use compiler)
选项:Javac(默认)、Eclipse、Ajc(AspectJ)等。
作用:选择使用哪个 Java 编译器。
解决问题:
Javac:标准 Oracle/OpenJDK 编译器。
Eclipse:Eclipse 的 ECJ 编译器,有时兼容性更好。
Ajc:用于 AspectJ 面向切面编程。
🔄 二、跨编译-release选项(Use "-release" option for cross-compilation)
作用:Java 9+ 的 -release 参数确保编译时只使用指定版本的API。
解决问题:
避免因使用高版本JDK编译低版本目标时,不小心用了新API而导致运行时错误。
比旧的 -source 和 -target 参数更严格可靠。
📦 三、项目字节码版本(Project bytecode version)
Same as language level:字节码版本与项目语言级别一致。
Per-module bytecode version:可为不同模块设置不同的目标字节码版本。
解决问题:
确保生成的 .class 文件能在指定JVM版本上运行。
多模块项目中,不同模块可能需要兼容不同JVM版本。
⚙ 四、Javac 选项(Javac Options)
- Use compiler from module target JDK when possible
作用:尽量使用模块指定的JDK中的编译器。
解决问题:多模块项目中使用不同JDK版本时,确保每个模块用正确的编译器。
- Generate debugging info
作用:在字节码中包含调试信息(如行号、局部变量名)。
解决问题:支持断点调试、堆栈跟踪显示行号。
- Report use of deprecated features
作用:报告使用了已弃用(@Deprecated)的API。
解决问题:提醒开发者更新代码,避免使用即将移除的API。
- Generate no warnings
作用:抑制所有编译警告。
解决问题:让编译输出更干净(但可能隐藏潜在问题)。
- Additional command line parameters
作用:添加额外的 javac 命令行参数。
示例参数:
-parameters:保留方法参数名(用于反射)。
-Xlint:unchecked:启用未检查转换警告。
解决问题:实现标准选项不支持的编译需求。
- Override compiler parameters per-module
作用:为特定模块覆盖全局编译参数。
解决问题:多模块项目中,某个模块可能需要特殊编译选项。
🎯 这个面板主要解决的问题
版本兼容性问题
确保代码在目标JVM版本上正常运行。
避免跨JDK版本编译时的API不兼容。
调试支持
生成调试信息便于开发和问题排查。
代码质量
报告弃用API使用,推动代码现代化。
多模块项目管理
不同模块可以使用不同的JDK版本和编译选项。
高级编译需求
通过额外参数实现特定优化或检查。
💡 使用场景示例
项目需要兼容 Java 8:设置字节码版本为8,启用-release选项。
调试时看不到变量名:确保勾选"Generate debugging info"。
多模块项目中一个模块用Java 17,其他用Java 11:使用"Per-module bytecode version"分别设置。
想看到所有编译警告:取消"Generate no warnings",并在附加参数中添加-Xlint:all。
这个面板让你能精细控制Java编译过程,解决版本兼容性、调试、代码质量等关键问题。
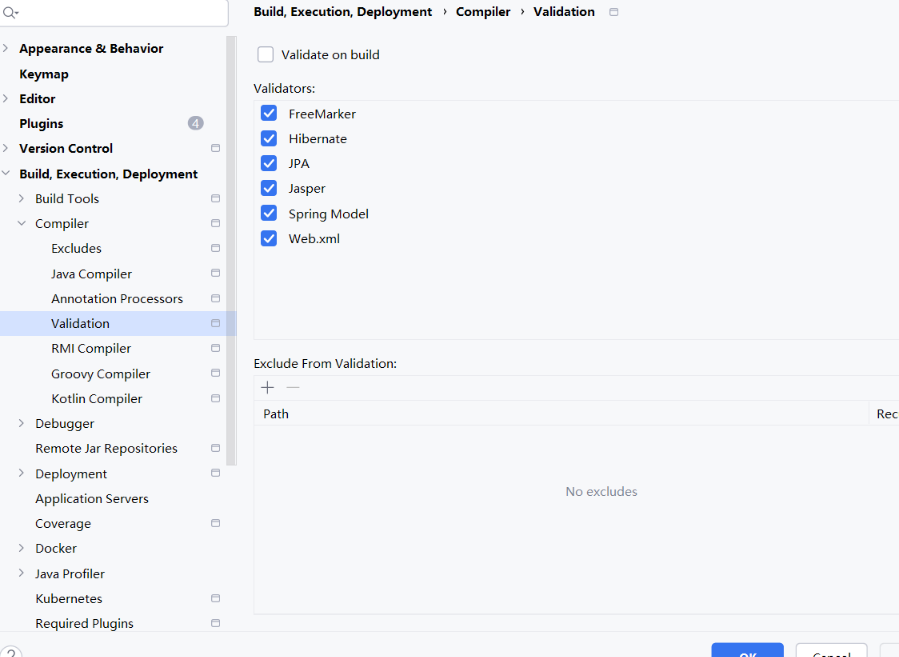
这是 IntelliJ IDEA 的验证(Validation)配置界面,主要用于在编译时对特定类型的文件进行静态验证。让我为你详细解释:
🎯 验证(Validation)的作用
验证是指在编译过程中,IDE 会对特定文件类型(如配置文件、模板文件)进行语法和语义检查,确保它们格式正确、配置合理。
📋 面板各部分解释
- Validate on build(构建时验证)
作用:勾选后,在编译项目时会自动运行下面的各种验证器。
解决问题:在编译阶段就发现配置文件错误,而不是等到运行时才崩溃。
- 可用的验证器列表
FreeMarker:验证 .ftl 模板文件语法。
Hibernate:验证 Hibernate 配置文件和映射文件。
JPA:验证 JPA 持久化配置。
Jasper:验证 JasperReports 报表文件。
Spring Model:验证 Spring 配置文件(如 applicationContext.xml)。
Web.xml:验证 Web 应用部署描述符。
- Exclude From Validation(排除验证)
作用:指定某些文件或目录不进行验证。
解决问题:
排除第三方库的配置文件。
排除自动生成但无需验证的文件。
排除还在开发中的文件。
🔍 为什么需要这个功能?
✅ 主要目的:
提前发现配置错误
例如:Spring XML 配置文件写错了 bean 名称。
例如:FreeMarker 模板语法错误。
避免运行时错误
在编译阶段就发现 Web.xml 配置错误,而不是部署到服务器后才报错。
提高开发效率
红色波浪线提示错误,立即修复。
避免"编译通过但运行失败"的尴尬情况。
💡 典型使用场景
场景1:Spring 项目开发
开启 Spring Model 验证。
当你在 applicationContext.xml 中引用了一个不存在的 bean 时,IDEA 会立即报错。
场景2:Web 应用开发
开启 Web.xml 验证。
确保 servlet 映射、过滤器配置正确。
场景3:模板引擎使用
开启 FreeMarker 验证。
模板文件中变量引用错误会立即提示。
场景4:需要排除验证
项目中有一个 test-config/ 目录,里面是各种测试配置文件,不想在编译时验证。
点击 + 添加排除路径。
⚠️ 注意事项
性能考虑:验证会消耗一定资源,如果项目很大,可能会影响编译速度。
误报情况:有些动态配置可能被误判为错误。
选择性开启:根据项目实际使用的技术栈开启相应的验证器即可。
🔧 建议设置
日常开发:建议开启相关验证器,能及早发现问题。
大型项目:如果编译变慢,可以关闭不常用的验证器。
排除规则:只排除真正不需要验证的文件,不要过度排除。
这个功能相当于为非 Java 代码(配置文件、模板等)提供了一个静态代码分析机制,是 IDEA 提供的重要质量保障工具之一。
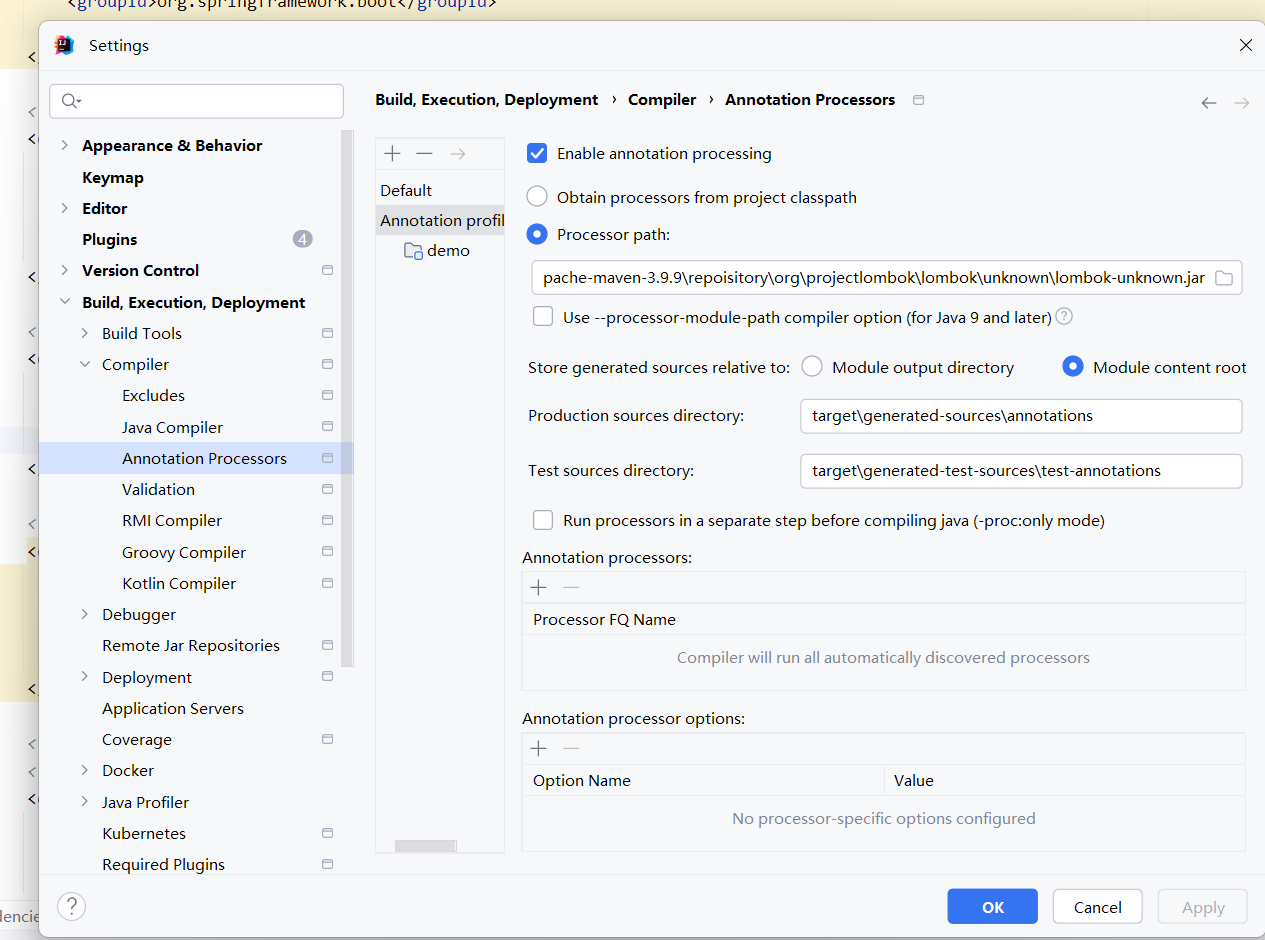
这是 IntelliJ IDEA 的注解处理器(Annotation Processors)配置界面,专门用于管理和配置 Java 注解处理器。这是现代 Java 开发中非常重要的一个功能。
🎯 注解处理器是什么?
注解处理器是在 Java 编译期间 运行的特殊程序,它们:
扫描源代码中的注解(如 @Getter、@Data、@Mapper 等)
根据注解生成额外的 Java 源代码、资源文件或其他内容
在编译时完成,不影响运行时性能
📋 面板各部分详细解释
-
Enable annotation processing(启用注解处理)
总开关:必须勾选才能使用注解处理器。
-
Obtain processors from project classpath
作用:从项目依赖中自动发现和加载注解处理器。
常见处理器:
Lombok(生成 getter/setter/构造器等)
MapStruct(生成对象映射代码)
QueryDSL(生成查询类)
JPA Metamodel(生成 JPA 元模型类)
- Processor path
作用:手动指定注解处理器的 JAR 包路径。
使用场景:当处理器不在 classpath 中时手动添加。
示例:图中显示的是 Lombok 的 JAR 包路径。
- Store generated sources relative to(生成文件的存储位置)
Module output directory:相对于模块输出目录
Module content root:相对于模块内容根目录
Production sources directory:生产代码生成目录
target/generated-sources/annotations(Maven 标准)
Test sources directory:测试代码生成目录
target/generated-test-sources/test-annotations
- Run processors in a separate step(单独运行处理器)
作用:先运行注解处理器生成代码,再编译所有代码。
解决问题:解决处理器之间的依赖问题。
- Annotation processors(指定使用的处理器)
作用:手动列出要使用的处理器全限定名。
默认:Compiler will run all automatically discovered processors
- Annotation processor options(处理器选项)
作用:为特定处理器传递参数。
示例:为 MapStruct 设置 mapstruct.defaultComponentModel=spring
🔍 为什么需要这个功能?
✅ 主要目的:
代码生成自动化
Lombok:自动生成 getter/setter/equals/hashCode 等
MapStruct:自动生成对象转换代码
避免手动编写重复代码
编译时检查
某些注解处理器会在编译时验证代码的正确性
例如:检查 @NonNull 参数的合法性
元编程支持
根据注解生成配置类、工厂类等
实现类似"编译时 AOP"的效果
💡 典型使用场景
场景1:使用 Lombok
java
@Data // 编译时自动生成 getter/setter/toString/equals/hashCode
public class User {
private String name;
private int age;
}
需要启用注解处理
处理器从 classpath 自动发现
场景2:使用 MapStruct
java
@Mapper
public interface UserMapper {
UserDto toDto(User user);
}
编译时生成 UserMapperImpl 实现类
可能需要在选项中配置组件模型
场景3:自定义注解处理器
开发自己的注解处理器
需要在列表中手动添加处理器全限定名
⚠️ 常见问题与解决方案
问题1:Lombok 不生效
检查:确保启用了注解处理
检查:Lombok 依赖已正确添加
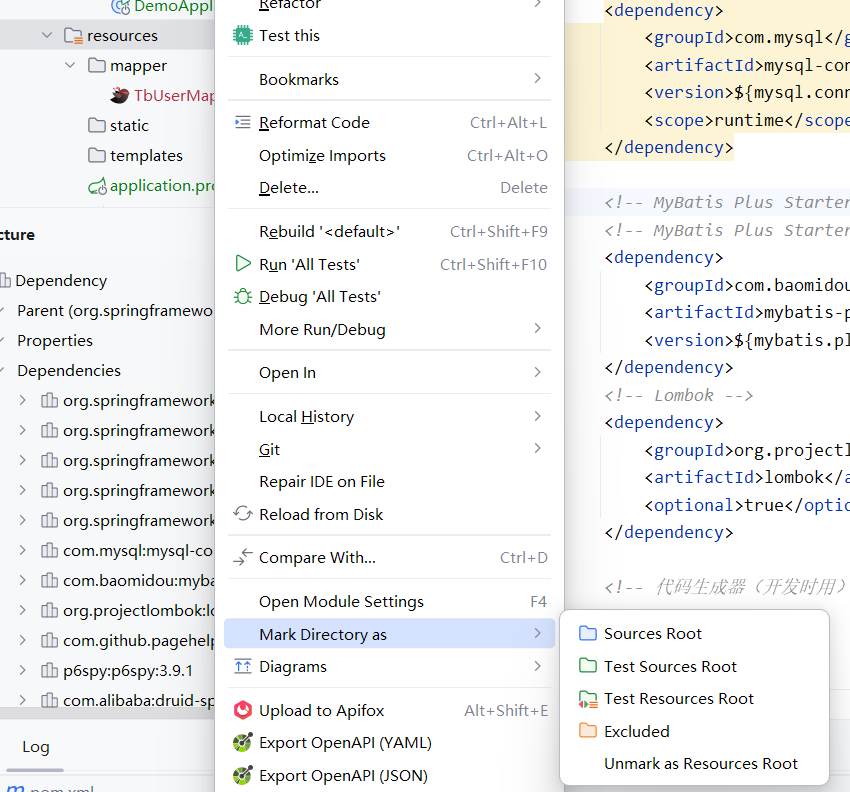
问题2:生成的源代码找不到
检查:生成目录是否正确配置
解决:将生成目录标记为"Sources Root"
问题3:多模块项目处理器冲突
解决:使用"Run processors in a separate step"
🔧 建议设置
新项目设置:
启用注解处理
使用"从 classpath 获取处理器"
使用 Maven 标准目录结构
多模块项目:
可能需要为每个模块单独配置
考虑使用"单独运行处理器"选项
性能优化:
只启用真正需要的处理器
避免不必要的处理器运行
🌟 重要提醒
注解处理器是编译期行为,它们:
不增加 运行时依赖
不降低 运行时性能
生成的是真实 Java 代码,可调试、可查看
这个功能让 Java 开发实现了 "约定优于配置" 和 "代码生成自动化",是现代 Java 框架(如 Spring Boot、Lombok、MapStruct)的核心支撑技术。
这个就是配置项目jdk,和java语言,以及在本地环境编译运行,的idea提供的机制,以及可视化的操作平台。所谓的可视化就是相对于命令行交互而言。
配置了这个,我们就知道,每个project,每个module在jvm里,在idea上是什么java语言。