1、数据库索引基础
1.1 什么是索引?
数据库索引的原理:
- 索引是一个排序的列表,存储着值和对应数据的物理地址
- 就像图书目录一样,通过索引可以快速定位数据,无需扫描整个表
- 类似C语言链表的指针机制,直接指向数据存储位置
核心概念
- 作用:加快查询速度,类似书本目录
- 本质:表中一列或多列值的排序方法
- 目的:快速定位数据行,提高查询效率
- 就像图书目录一样,通过索引可以快速定位数据,无需扫描整个表
- 类似C语言链表的指针机制,直接指向数据存储位置
核心概念
- 作用:加快查询速度,类似书本目录
- 本质:表中一列或多列值的排序方法
- 目的:快速定位数据行,提高查询效率
1.2 索引的作用与效果
生活案例:手机通讯录
当您要在手机通讯录中找"张三"的电话号码:
无索引的情况:
- 需要从A开始,一个一个名字往下找
- 如果通讯录有1000个人,可能要找500次
有索引的情况:
- 按姓名字母排序的通讯录,直接定位到Z开头的"张三"
- 可能只需要查找20-30
数据库索引的实际效果
- 小表(<300行):索引效果不明显
- 大表(>3000行):查询速度提升可达成千上万倍
- 典型场景:从全表扫描到快速定位
1.3 索引的优缺点分析
优点
- 大幅提升查询速度
- 减少数据库IO操作
- 降低排序成本
- 保证数据唯一性(唯一索引)
- 加快表间连接速度 也可以多表查询 建立索引 就是为了加快表之间进行查询(读比写多)
缺点
- 存储空间占用:索引文件需要额外磁盘空间
- MyISAM引擎:索引文件和数据文件分离
- InnoDB引擎:表数据文件本身就是索引文件
- 写入性能影响:插入、修改、删除数据时,索引也需要更新
2、索引创建原则与策略
2.1 什么时候应该创建索引?
必须创建索引的场景
1.主键和外键
- 主键:唯一性标识,自动创建索引
- 外键:关联查询,快速定位两张表学生学习表信息表
2. 大表(>300行)
- 超过300行的表建议创建索引
- 小表索引效果不明显,反而影响写入性能
3. 频繁查询的字段
- 经常出现在WHERE子句中的字段
- 用户名、手机号、邮箱等常用查询字段
4. 连接字段
- 经常用于表连接的字段订单表下单表
- 如用户表和订单表的user_id
不适合创建索引的场景
1. 唯一性很差的字段
- 如性别字段(只有"男"、"女"两个值)
- 状态字段(如"启用"、"禁用")
2. 更新频繁的字段
- 如最后登录时间字段
- 在线状态字段
3. 大文本字段
- BLOB、CLOB类型字段
- 文章内容、长文本描述
2.2 索引选择原则
索引优化原则
- 选择性强:字段值的重复度低
- 查询频繁:经常用于WHERE条件
- 数据量适中:不能太小(效果不明显),不能太大(占用空间过多)
- 小字段优先:整型比字符串更高效
3、索引类型详解
3.1 普通索引(INDEX)
**用途:**最基础的索引类型,没有唯一性限制
3.1.1 直接创建索引
CREATE INDEX 索引名 ON 表名 (列名[(length)]);
#(列名(length)):length是可选项。如果忽略 length 的值,则使用整个列的值作为索引。如果指定使 用列前的 length 个字符来创建索引,这样有利于减小索引文件的大小。
#索引名建议以"_index"结尾。
3.1.2 修改表方式创建
ALTER TABLE 表名 ADD INDEX 索引名 (列名);
3.1.3 创建表的时候指定索引
CREATE TABLE 表名 ( 字段1 数据类型,字段2 数据类型[,...],INDEX 索引名 (列名));
3.2 唯一索引(UNIQUE)
用途: 与普通索引类似,但区别是唯一索引列的每个值都唯一 。唯一索引允许有空值(注意和主键不同)。如果是用组合索引创建,则列值的组合必须唯一。添加唯一键将自动创建唯一索引。
3.2.1 直接创建唯一索引
CREATE UNIQUE INDEX 索引名ON表名(列名);
3.2.2 修改表方式创建
ALTER TABLE 表名 ADD UNIQUE 索引名 (列名);
3.2.3 创建表的时候指定
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型[,...],UNIQUE 索引名 (列名));
3.3 主键索引(PRIMARY KEY)
特点:
- 一个表只能有一个主键
- 不允许空值
- 自动创建唯一索引
- 性能最优的索引类型
3.3.1 创建表的时候指定
CREATETABLE表名 ([...],PRIMARY KEY (列名));
3.3.2 修改表方式创建
ALTER TABLE 表名 ADD PRIMARY KEY (列名);
3.4 组合索引(复合索引)
最左前缀原则:
组合索引(复合索引)是基于多个字段 创建的索引(如 INDEX idx_abc (a, b, c)),而「最左前缀原则」是组合索引生效的核心规则:MySQL 在匹配索引时,会从索引的最左侧字段开始,依次匹配连续的字段;如果跳过左侧字段直接匹配右侧字段,索引会失效。
CREATETABLE表名 (列名1 数据类型,列名2 数据类型,列名3 数据类型,INDEX 索引名 (列名1,列名2, 列名3));
3.5 全文索引(FULLTEXT)
3.5.1 直接创建索引
CREATE FULLTEXT INDEX 索引名ON表名 (列名);
3.5.2 修改表方式创建
ALTER TABLE 表名 ADD FULLTEXT 索引名 (列名);
3.5.3 创建表的时候指定索引
CREATE TABLE 表名 (字段1 数据类型[,...],FULLTEXT 索引名 (列名));
3.5.4 使用全文索引查询
SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('查询内容');
注意事项:
- MySQL 5.6+支持InnoDB引擎
- 适用于CHAR、VARCHAR、TEXT类型文本
- 每个表只能有一个全文索引
4、索引的查看与维护
4.1 查看索引信息
命令格式

索引信息字段说明
|--------------|---------------|----------|
| 字段名 | 含义 | 示例 |
| Table | 表名 | users |
| Key_name | 索引名 | idx_name |
| Column_name | 索引列名 | name |
| Seq_in_index | 列在索引中的顺序 | 1 |
| Non_unique | 是否唯一(0=是,1=否) | 1 |
| Null | 是否允许NULL | YES |
| Index_type | 索引类型 | BTREE |
4.2 删除索引

一致性的含义:
- 事务前后数据总量保持不变
- 数据库的完整性约束不被破坏
- 数据从一个一致状态转换到另一个一致状态
5.2.3I - 隔离性(Isolation)
隔离性的含义:
- 并发执行的事务相互隔离
- 每个事务有独立的数据空间
- 避免脏读、不可重复读、幻读等问题
5.2.4 D - 持久性(Durability)
持久性的含义:
- 事务一旦提交,对数据库的改变是永久的 即
- 使系统故障也不会丢失
- 通过日志机制保证数据的持久性
5.3 事务控制语句扩展
- BEGIN 或 START TRANSACTION:显式地开启一个事务。
- COMMIT 或 COMMIT WORK:提交事务,并使已对数据库进行的所有修改变为永久性的。 ROLLBACK 或 ROLLBACK WORK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
- SAVEPOINT S1:使用 SAVEPOINT 允许在事务中创建一个回滚点,一个事务中可以有多个SAVEPOINT;"S1"代表回滚点名称。
- ROLLBACK TO SAVEPOINT S1:把事务回滚到标记点。
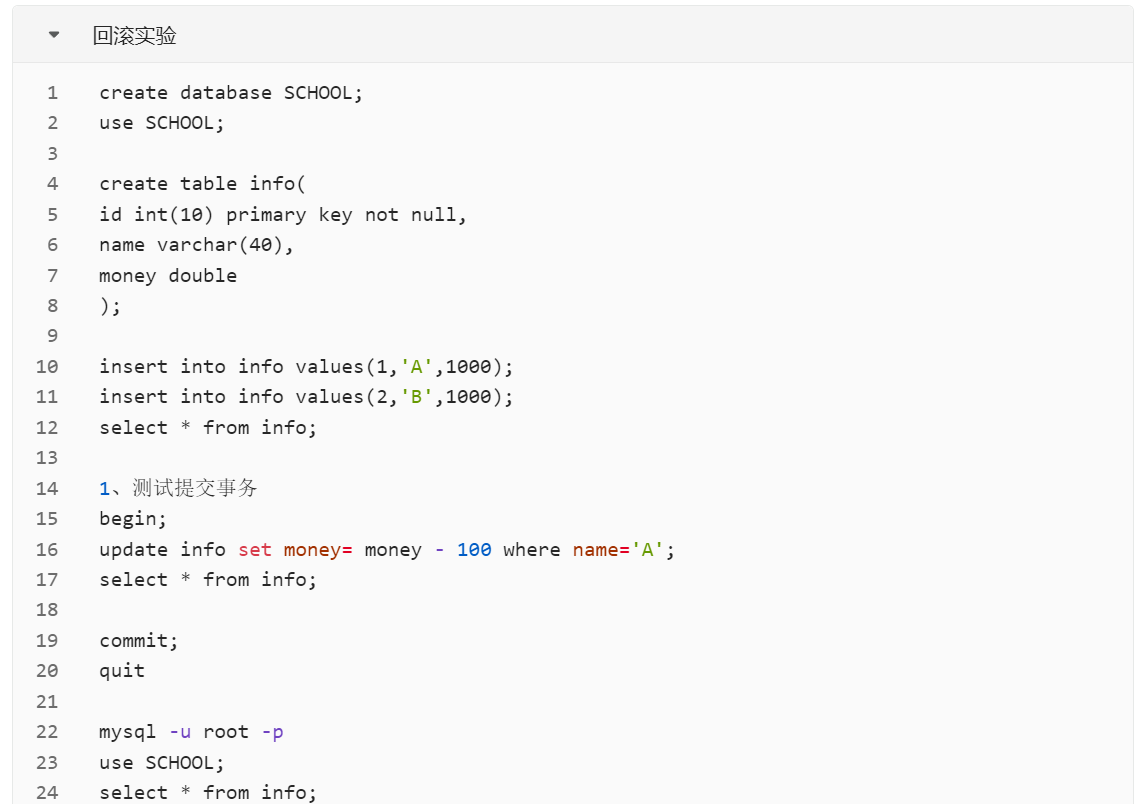


如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback|commit;当前事务才算结束。
当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。 如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin; commit|rollback; 都是独立的事务

6、总结


事务关键的一点:一致性,要么都成功,要么都失败,保存在自己的回滚日志中 对于事务过程中,我们可以对每一步sql进行savepoint打标机,为了方便回顾 提交事务:commit rollback