目录
- 模拟一个100万条数据的环境
- [key *遍历一百万条数据要花费多久?](#key *遍历一百万条数据要花费多久?)
- [生产上限制key */flushdb/flushall等危险命令防止误删误用](#生产上限制key */flushdb/flushall等危险命令防止误删误用)
- [禁用keys *,我们要如何遍历呢?](#禁用keys *,我们要如何遍历呢?)
- BigKey
模拟一个100万条数据的环境
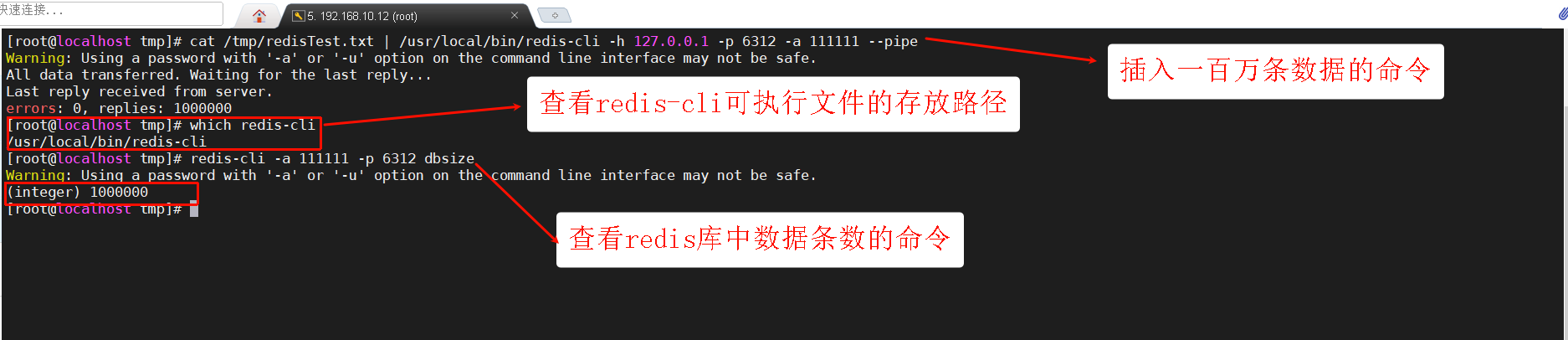
1.生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中
linux
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;2.通过redis提供的管道--pipe命令插入 10ow大批量数据
linux
#插入一百万条数据数据
cat /tmp/redisTest.txt | /usr/local/bin/redis-cli -h 127.0.0.1 -p 6312 -a 111111 --pipe
#查看redis-cli可执行文件的路径
which redis-cli
#查看redis库中数据的条数
redis-cli -a 111111 -p 6312 dbsize命令中的/usr/local/bin/redis-cli是redis的可执行文件路径,会存在不一样的情况,不清楚的可以用which redis-cli查看
新闻事故 :最近安全事故濒发啊:前几天发生了"某高级运维工程师的删库事件",今天又看到了PHP工程师在线执行了Redis危险命令导致某公司损失400万.
什么样的Redis命令 会有如此威力,造成如此大的损失?具体消息如下:
据云头条报道,某公司技术部发生2起本年度P0级特大事故,造成公司资金损失400万,原因如下:
由于PHP工程师直接操作上线redis,执行键keys *wxdb*cf8 这样的命令,导致redis锁住,导致CPU额升,引起所有支付链路卡住,等十几秒结束后,所有的请求流量全部挤压到了rds数据库中,使数据库产生了雪崩效应 ,发生了数据库客机事件。
该公司表示,如再犯类似事故,将直接开除,并表示之后会逐步收回运维部各项权限。看完这个消息后,我心又一惊,为什么这么低级的问题还在犯?为什么
线上的危险命令没有被禁用?
这事件报道出来
真是觉得很低级
且不说是哪家公司,发生这样的事故,不管是大公司还是小公司,我觉得都不应该,相关负责人应该引答辞职!
对Redis稍微有点使用经验的人都知道线上是不能执行keys*相关命令的,
虽然其模糊匹配功能使用非常方便也很强
数据量大会导致Redis锁住及CPU升,在生产环境建议禁用或者重命名!
key *遍历一百万条数据要花费多久?
刚好我们有一个库,直接执行

经过上图我们了解到,keys * 遍历一百万条数据要花二十多秒
这个指令没有 offset、limit 参数,是要一次性吐出所有满足条件的 key,由于 redis 是单线程的,其所有操作都是原子的,而 keys 算法是遍历算法,复杂度是 O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,所有读写Redis的其它的指令都会被延后甚至会超时报错,可能会引起缓存雪崩甚至数据库宕机。PS:offset:跳过多少条,可以理解从 第几条开始取。limit:最多取多少条
说白了,就是keys算法是遍历算法,复杂度表较高,且redis工作线程是单线程,在大数据量面前非常容易造成阻塞
清空一百万条数据要多久呢?
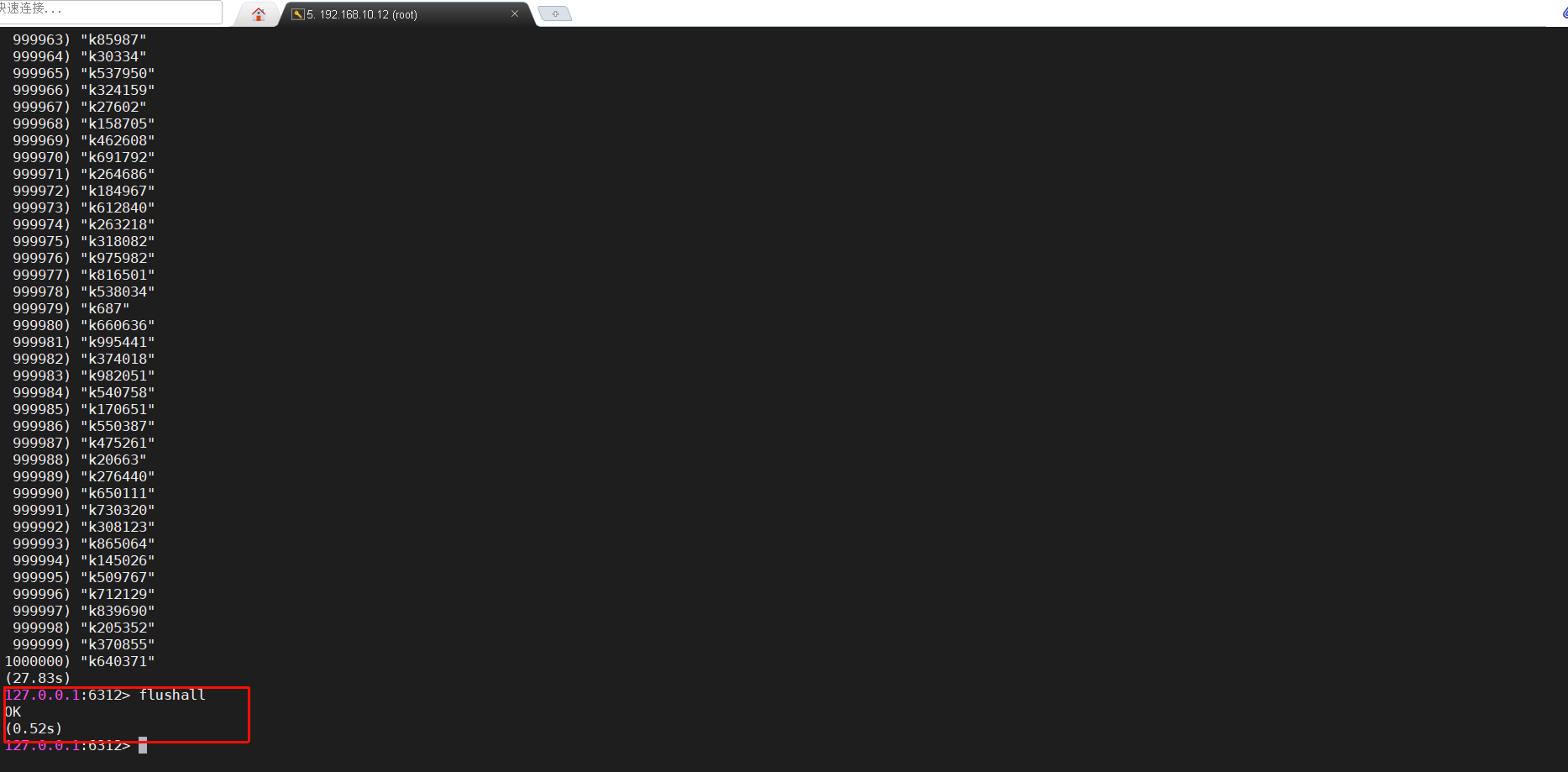
一秒不到,这些非常容易造成生产事故的命令,统统都是危险操作,得想个办法限制它们。
生产上限制key */flushdb/flushall等危险命令防止误删误用
想要禁用危险操作,我们只需要在配置文件中加入一个配置就好了。
配置:rename-command 禁用的指令 ""
linux
rename-command keys ""
rename-command flushdb ""
rename-command flusall ""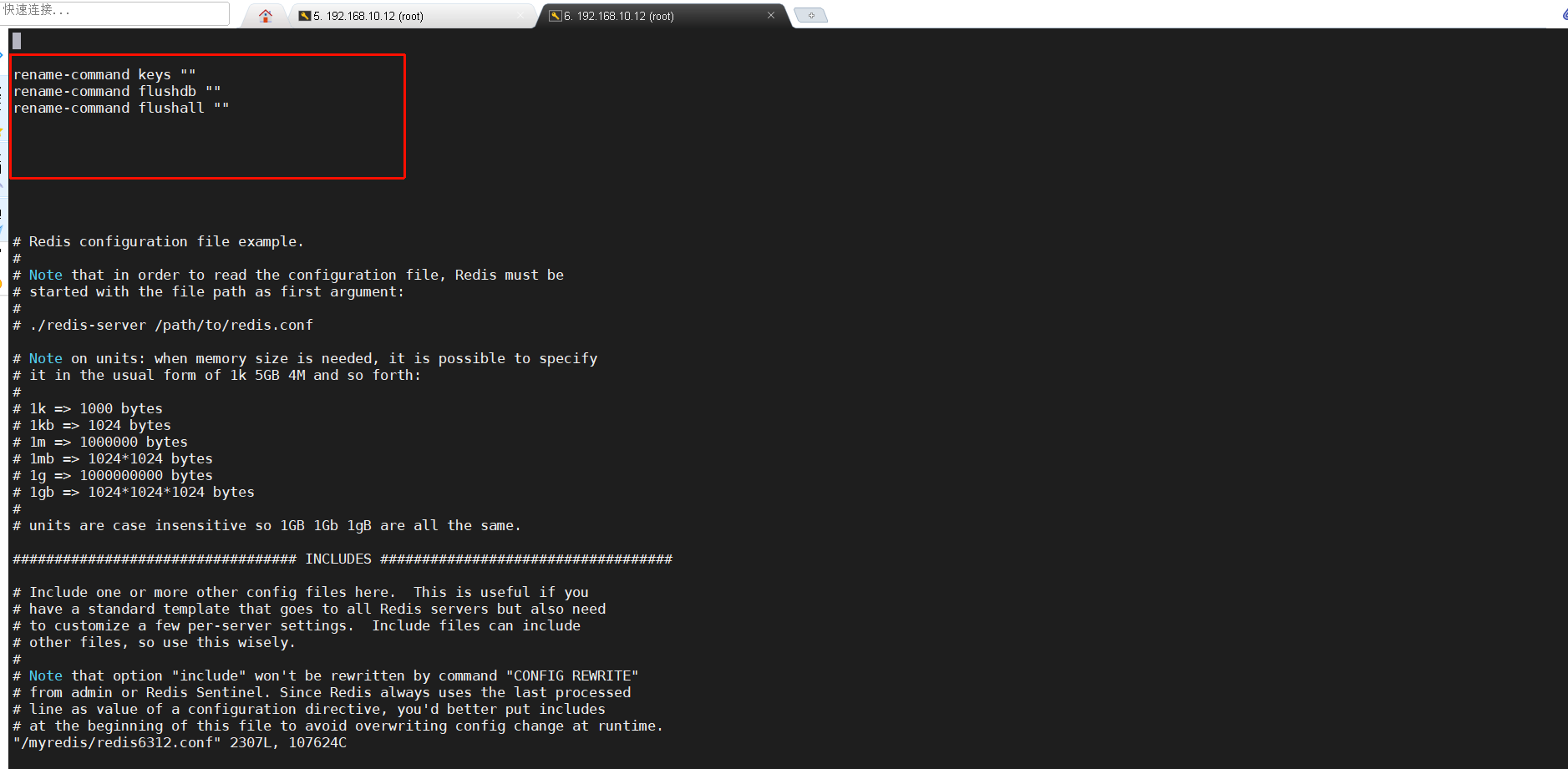
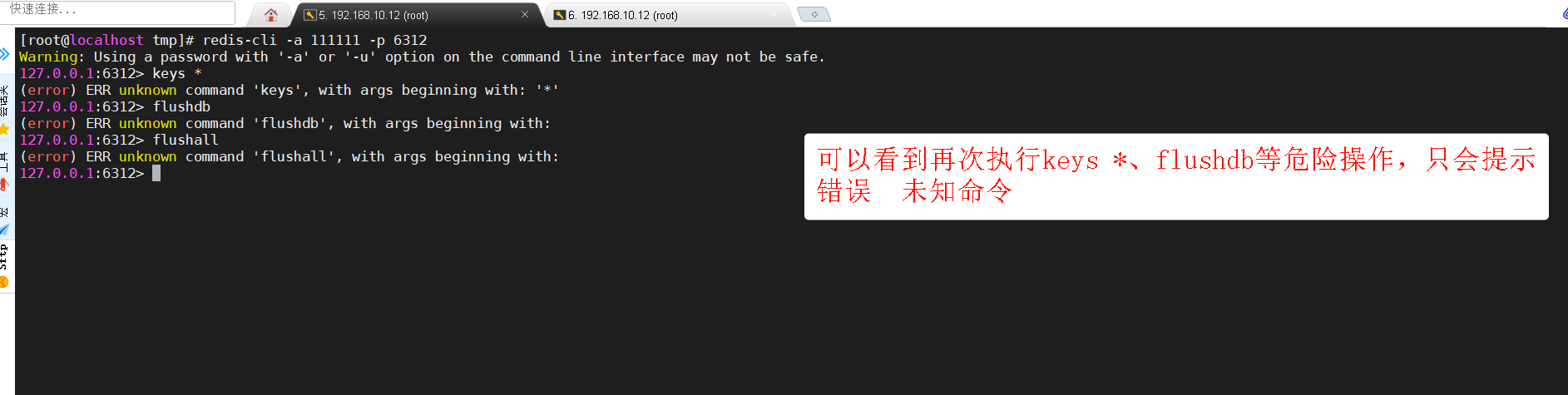
禁用keys *,我们要如何遍历呢?
SCAN
linux
SCAN cursor [MATCH pattern] [COUNT count]是Redis提供的非阻塞式全局键遍历命令,用于替代高危的 KEYS * 命令,核心是通过「游标迭代」的方式渐进式遍历 Redis 实例中的所有键,避免长时间阻塞主线程。
| 参数 | 是否必选 | 核心含义 | 通俗解释 |
|---|---|---|---|
| cursor | 是 | 遍历游标(整数),遍历的 "进度标记":1. 初始遍历用 0 作为游标;2. 每次执行返回新游标,用新游标继续遍历;3. 返回游标 0 表示遍历完成。 | 像看书的 "书签":- 游标 0 = 从第一页开始看;- 返回游标 150 = 下次从第 150 页继续;- 返回游标 0 = 整本书看完了。 |
| MATCH pattern | 否 | 模糊匹配规则,只返回符合规则的键名(支持 * 通配符)。 | 只找 "符合条件的键",比如 MATCH user:* 只遍历以 user: 开头的键。 |
| COUNT count | 否 | 遍历力度建议值(整数):1. 告诉 Redis"本次遍历尽量扫描 count 个哈希桶";2. 不保证返回 count 个键(最终数量由哈希桶分布 / 匹配规则决定);3. 默认值为 10。 |
告诉 Redis"每次尽量翻 count 页书",但最终找到的 "符合条件的内容" 可能多 / 少 / 为 0(比如翻 10 页没找到匹配的键,就返回空)。 |
核心特性(为什么比 KEYS 安全)
非阻塞:
- 不同于 KEYS * 一次性遍历所有键(O (n) 复杂度,千万级键会阻塞几十秒),SCAN 每次只遍历一小部分键,执行
耗时毫秒级,中间可穿插处理其他客户端的命令(如 GET/SET),不会导致 Redis 卡顿。 - 游标迭代:
遍历不是 "一次性完成",而是通过「游标」记录进度 ------ 第一次用 0 开始,后续用上次返回的游标继续,直到游标返回 0 才完成全量遍历。 - 结果非精准性:
- COUNT count 是 "建议值" 而非 "强制值":比如 COUNT 100 可能返回 80/120/0 个键(取决于哈希桶里的键数量、MATCH 筛选结果);
- 遍历过程中若有键新增 / 删除,可能出现 "重复扫" 或 "漏扫"(不保证绝对完整性,适合统计 / 清理场景,不适合强一致性场景)。
哈系桶:哈希桶是 Redis 用来分类存储键的最小单元,一个桶里可以放多个键(也可以空)。
使用示例(直观理解执行流程)
redis
# 第一步:初始遍历(游标0,匹配user:*,建议遍历100个哈希桶)
127.0.0.1:6379> SCAN 0 MATCH user:* COUNT 100
1) "150" # 返回新游标150(下次用这个游标)
2) 1) "user:101" # 本次匹配到的键列表
2) "user:102"
# 第二步:继续遍历(用游标150)
127.0.0.1:6379> SCAN 150 MATCH user:* COUNT 100
1) "320"
2) 1) "user:103"
# 最后一步:遍历完成(返回游标0)
127.0.0.1:6379> SCAN 320 MATCH user:* COUNT 100
1) "0" # 游标0 = 全量遍历完成
2) 1) "user:999"
#以上带条件筛选的遍历,无条件筛选直接使用,从游标0开始,遍历100个哈系桶
SCAN 0 COUNT 100scan只会遍历出key,而不会遍历出value,需要结合type key来获取键值对的类型,如果是Hash或者Set或者是Zset则分别需要用hscan、sscan、zscan指令来遍历。
遍历 Set → SSCAN;
遍历 Hash → HSCAN;
遍历 ZSet → ZSCAN;
使用方式和scan一模一样,只是scan是遍历库里所有key,而hscan、sscan、zscan遍历对应的集合。
sscan示例
linux
SSCAN set键名 游标 [MATCH pattern] [COUNT count]SSCAN 是 Redis 专为 Set(无序集合) 设计的非阻塞遍历命令**加粗样式**,用于渐进式遍历单个 Set 键内的所有元素(替代一次性遍历的 SMEMBERS,避免阻塞主线程),语法和 SCAN 一致:
基础场景:遍历小 Set 键(无筛选 / 指定 COUNT)
redis
# 1. 先插入测试数据
127.0.0.1:6379> SADD user_ids 101 102 103 104 105 201 202 203
(integer) 8
# 2. 初始遍历(游标0,无MATCH/COUNT,默认COUNT=10)
127.0.0.1:6379> SSCAN user_ids 0
1) "0" # 返回游标0 → 遍历完成(Set元素少,一次扫完)
2) 1) "101" # 本次返回的元素列表
2) "102"
3) "103"
4) "104"
5) "105"
6) "201"
7) "202"
8) "203"
# 3. 带MATCH筛选(只遍历以1开头的用户ID)
127.0.0.1:6379> SSCAN user_ids 0 MATCH 1*
1) "0"
2) 1) "101"
2) "102"
3) "103"
4) "104"
5) "105"
# 4. 带COUNT指定遍历力度(建议遍历20个哈希桶)
127.0.0.1:6379> SSCAN user_ids 0 COUNT 20
1) "0"
2) 1) "101"
2) "102"
3) "103"
4) "104"
5) "105"
6) "201"
7) "202"
8) "203"核心场景:遍历大 Set 键(渐进式游标迭代)
如果 Set 键有 1 万 + 元素,必须用「循环游标」遍历,避免一次性遍历阻塞 Redis:
redis
# 假设 Set 键 big_set 有 10000 个元素
# 第一步:初始遍历(游标0,COUNT=1000,建议遍历1000个哈希桶)
127.0.0.1:6379> SSCAN big_set 0 COUNT 1000
1) "5000" # 返回新游标5000 → 下次用这个游标继续
2) 1) "elem1" # 本次返回约1000个元素(实际数量由哈希桶分布决定)
2) "elem2"
...
# 第二步:继续遍历(用游标5000)
127.0.0.1:6379> SSCAN big_set 5000 COUNT 1000
1) "8000" # 新游标8000
2) 1) "elem1001"
2) "elem1002"
...
# 最后一步:遍历完成(返回游标0)
127.0.0.1:6379> SSCAN big_set 9900 COUNT 1000
1) "0" # 游标0 = 全量遍历完成
2) 1) "elem9999"
2) "elem10000"实战场景:筛选 + 分批遍历
遍历 Set 键 product_codes,只匹配以 PRO 开头的编码,每次遍历 50 个哈希桶:
redis
# 1. 插入测试数据
127.0.0.1:6379> SADD product_codes PRO1001 PRO1002 PRO2001 PRO2002 TEST3001 TEST3002
(integer) 6
# 2. 初始遍历(游标0,MATCH PRO*,COUNT=50)
127.0.0.1:6379> SSCAN product_codes 0 MATCH PRO* COUNT 50
1) "0"
2) 1) "PRO1001"
2) "PRO1002"
3) "PRO2001"
4) "PRO2002"zscan示例
linux
ZSCAN zset键名 游标 [MATCH pattern] [COUNT count]ZSCAN 是 Redis 专为 ZSet(有序集合) 设计的非阻塞遍历命令,用于渐进式遍历单个 ZSet 键内的「元素 + 分值」(替代一次性遍历的 ZRANGE/ZREVRANGE,避免阻塞主线程),语法如下:
redis
# 假设 ZSet 键 big_rank 有 10000 个元素(用户ID+积分)
# 第一步:初始遍历(游标0,COUNT=1000,建议遍历1000个哈希桶)
127.0.0.1:6379> ZSCAN big_rank 0 COUNT 1000
1) "5000" # 返回新游标5000 → 下次用这个游标继续
2) 1) "user101" # 元素1
2) "850" # 元素1的分值
3) "user102" # 元素2
4) "920" # 元素2的分值
... (约1000个元素+分值对,数量不绝对精准)
# 第二步:继续遍历(用游标5000)
127.0.0.1:6379> ZSCAN big_rank 5000 COUNT 1000
1) "8000" # 新游标8000
2) 1) "user1001"
2) "780"
3) "user1002"
4) "890"
...
# 最后一步:遍历完成(返回游标0)
127.0.0.1:6379> ZSCAN big_rank 9900 COUNT 1000
1) "0" # 游标0 = 全量遍历完成
2) 1) "user9999"
2) "999"
3) "user10000"
4) "1000"核心场景:遍历大 ZSet 键(渐进式游标迭代)
如果 ZSet 键有 1 万 + 元素(比如全站用户积分排名),必须用「循环游标」遍历,避免一次性遍历阻塞
redis
# 假设 ZSet 键 big_rank 有 10000 个元素(用户ID+积分)
# 第一步:初始遍历(游标0,COUNT=1000,建议遍历1000个哈希桶)
127.0.0.1:6379> ZSCAN big_rank 0 COUNT 1000
1) "5000" # 返回新游标5000 → 下次用这个游标继续
2) 1) "user101" # 元素1
2) "850" # 元素1的分值
3) "user102" # 元素2
4) "920" # 元素2的分值
... (约1000个元素+分值对,数量不绝对精准)
# 第二步:继续遍历(用游标5000)
127.0.0.1:6379> ZSCAN big_rank 5000 COUNT 1000
1) "8000" # 新游标8000
2) 1) "user1001"
2) "780"
3) "user1002"
4) "890"
...
# 最后一步:遍历完成(返回游标0)
127.0.0.1:6379> ZSCAN big_rank 9900 COUNT 1000
1) "0" # 游标0 = 全量遍历完成
2) 1) "user9999"
2) "999"
3) "user10000"
4) "1000"实战场景:筛选 + 分批遍历(业务常用)
遍历 ZSet 键 product_sales(商品 ID + 销量),只匹配以 PRO 开头的商品 ID,每次遍历 50 个哈希桶:
redis
# 1. 插入测试数据
127.0.0.1:6379> ZADD product_sales 5000 "PRO1001" 3000 "PRO1002" 8000 "PRO2001" 2000 "TEST3001"
(integer) 4
# 2. 初始遍历(游标0,MATCH PRO*,COUNT=50)
127.0.0.1:6379> ZSCAN product_sales 0 MATCH PRO* COUNT 50
1) "0"
2) 1) "PRO1001"
2) "5000"
3) "PRO1002"
4) "3000"
5) "PRO2001"
6) "8000"hscan示例
linux
HSCAN hash键名 游标 [MATCH 字段匹配规则] [COUNT 遍历建议数]HSCAN 是 Redis 专为 Hash(哈希表) 设计的非阻塞遍历命令,用于渐进式遍历单个 Hash 键内的「字段(field)+ 值(value)」(替代一次性遍历的 HGETALL,避免阻塞主线程),语法如下:
基础场景:遍历小 Hash 键(无筛选 / 指定 COUNT)
redis
# 1. 先插入测试数据(HSET 键 字段1 值1 字段2 值2 ...)
127.0.0.1:6379> HSET user:101 name "张三" age 28 gender "男" addr "北京市朝阳区" phone "13800138000" email "zhangsan@xxx.com"
(integer) 6
# 2. 初始遍历(游标0,无MATCH/COUNT,默认COUNT=10)
127.0.0.1:6379> HSCAN user:101 0
1) "0" # 返回游标0 → 遍历完成(Hash字段少,一次扫完)
2) 1) "name" # 字段1
2) "张三" # 字段1的值
3) "age" # 字段2
4) "28" # 字段2的值
5) "gender" # 字段3
6) "男" # 字段3的值
7) "addr" # 字段4
8) "北京市朝阳区" # 字段4的值
9) "phone" # 字段5
10) "13800138000" # 字段5的值
11) "email" # 字段6
12) "zhangsan@xxx.com" # 字段6的值
# 3. 带MATCH筛选(只遍历以a开头的字段)
127.0.0.1:6379> HSCAN user:101 0 MATCH a* COUNT 10
1) "0"
2) 1) "age"
2) "28"
3) "addr"
4) "北京市朝阳区"
# 4. 带COUNT指定遍历力度(建议遍历20个哈希桶)
127.0.0.1:6379> HSCAN user:101 0 COUNT 20
1) "0"
2) 1) "name" 2) "张三" 3) "age" 4) "28" 5) "gender" 6) "男" 7) "addr" 8) "北京市朝阳区" 9) "phone" 10) "13800138000" 11) "email" 12) "zhangsan@xxx.com"核心场景:遍历大 Hash 键(渐进式游标迭代)
redis
# 假设 Hash 键 big_product:1001 有 10000 个字段(属性名+属性值)
# 第一步:初始遍历(游标0,COUNT=1000,建议遍历1000个哈希桶)
127.0.0.1:6379> HSCAN big_product:1001 0 COUNT 1000
1) "5000" # 返回新游标5000 → 下次用这个游标继续
2) 1) "price" # 字段1
2) "999" # 字段1的值
3) "stock" # 字段2
4) "5000" # 字段2的值
... (约1000个字段+值对,数量不绝对精准)
# 第二步:继续遍历(用游标5000)
127.0.0.1:6379> HSCAN big_product:1001 5000 COUNT 1000
1) "8000" # 新游标8000
2) 1) "weight"
2) "1.5kg"
3) "size"
4) "XL"
...
# 最后一步:遍历完成(返回游标0)
127.0.0.1:6379> HSCAN big_product:1001 9900 COUNT 1000
1) "0" # 游标0 = 全量遍历完成
2) 1) "brand"
2) "小米"
3) "origin"
4) "中国"BigKey
多大算大?
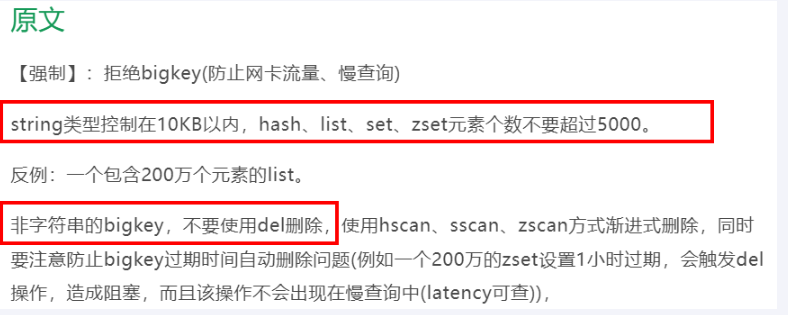
参考《阿里云Redis开发规范》
- string类型。value最大512MB但是value≥10KB就是bigkey
- list、hash、set和zset。 个数超过5000就是bigkey
为什么 BigKey 危险?(核心危害)
- 阻塞主线程:
- 一次性操作 BigKey(如 HGETALL/SMEMBERS/LRANGE 0 -1)会占用 Redis 主线程大量时间,导致其他命令(如 GET/SET)等待,业务超时;
- 删除 BigKey(如 DEL bigkey)时,Redis 需释放大量内存,可能造成秒级阻塞,引发服务雪崩。
- 内存碎片 / 集群倾斜:
- BigKey 会导致 Redis 实例内存占用不均(集群中某节点内存占比 80%,其他仅 20%);
- 频繁修改 BigKey 易产生内存碎片,降低内存利用率。
- 网络阻塞:
- 读取 BigKey 会产生大量网络流量,占用带宽,甚至导致客户端连接超时。
如何产生的?
BigKey 不是 "突然出现" 的,而是业务设计缺陷 + 不合理的使用习惯 + 缺乏监控 共同导致的,以下是最常见的产生场景和底层原因,结合真实案例更易理解:
一、核心原因 1:业务设计阶段的 "懒规划"(最主要)
| 典型场景 | 具体行为 | 最终结果 |
|---|---|---|
| 消息队列设计 | 用单个 List 存储所有业务的消息,不做拆分 | List 积压 10 万 + 元素,成为 BigKey |
| 全量数据存储 | 用单个 Hash 存储所有用户的属性(如 all_users),字段随用户量增长 | Hash 字段数突破 10 万,内存占用超 100MB |
| 大文本存储 | 用单个 String 存储商品详情页 HTML、图片 Base64 编码、日志全量内容 | String 大小从几 KB 涨到几十 MB |
| 无分片的集合存储 | 用单个 Set/ZSet 存储全平台用户 ID、商品 ID,不按维度分片 | Set/ZSet 元素数超 100 万,操作阻塞 |
真实案例:某社交产品用 user:follow:10001(ZSet)存储单个大 V 的粉丝 ID,粉丝量破千万后,该 ZSet 元素数达 120 万,内存占用 80MB,执行 ZSCAN 单次耗时超 50ms,触发客户端超时。
二、核心原因 2:数据写入时的 "无节制"
业务运行中持续向单键写入数据,但未设置 "过期 / 清理机制",导致数据无限累积。
| 典型场景 | 具体行为 | 最终结果 |
|---|---|---|
| 日志 / 监控数据堆积 | 用单个 List/String 存储全量系统日志,只写不删 | String 大小每天涨 10MB,一周后达 70MB |
| 缓存全量榜单 | 用 ZSet 存储全站商品销量榜,每天新增数据但不清理历史数据 | ZSet 元素数从 1 万涨到 50 万 |
| 未限流的接口缓存 | 把高并发接口的全量返回结果(如包含 1000 条商品的列表)直接缓存为单个 String | String 大小达 500KB,高频读取时等同于 BigKey |
真实案例:某电商平台缓存 "首页商品列表" 为单个 String(包含 200 个商品详情),大小 800KB,秒杀期间单秒读取 200 次,带宽占用超 1Gbps,引发网络阻塞。
三、核心原因 3:不合理的 Redis 命令使用
误用命令导致单键数据量异常增长,或把 "小键" 间接变成 "BigKey"。
| 典型行为 | 问题本质 | 最终结果 |
|---|---|---|
| 用 LPUSH 向 List 批量写入海量数据(一次 1 万条) | 单批次写入量过大,List 瞬间成为 BigKey | List 元素数骤增,后续 LRANGE 操作阻塞 |
| 用 HSET 循环向单个 Hash 写入字段(无分片) | 字段数随循环次数线性增长 | Hash 字段数突破阈值,HGETALL 超时 |
| 把多个小值拼接成一个 String 存储(如用逗号分隔 1000 个 ID) | 人为把多个小数据合并为单键 | String 大小超标,拆分 / 读取成本高 |
四、核心原因 4:缺乏监控和预警机制
未对 Redis 键的大小 / 元素数做监控,导致 BigKey 持续增长直到引发故障。
- 无监控:不知道哪些键是 BigKey、大小增长趋势如何;
- 无预警:未设置 "键大小≥50KB / 元素数≥5000" 的告警,错过治理时机;
- 无治理流程:即使发现 BigKey,也无拆分 / 清理方案,任其恶化。
如何发现?
redis-cli --bigkeys
linux
redis-cli --bigkeys -i 0.1 -a 密码 -p 端口 是 Redis 官方提供的BigKey 检测工具,核心作用是扫描 Redis 实例中所有键,统计不同类型键的「最大键 / 平均大小」,帮你快速定位 BigKey。
| 参数 | 是否必须 | 含义 |
|---|---|---|
| --bigkeys | 是 | 核心参数:启动 BigKey 扫描模式(非阻塞,基于 SCAN 遍历) |
| -i | 否 | 扫描限速:每执行 100 次 SCAN 指令,休眠 0.1 秒(生产必加!避免 SCAN 密集执行导致 ops 飙升) |
ops(Operations Per Second):Redis 每秒处理的命令数,是衡量 Redis 负载的核心指标;
假设 Redis 实例有 10 万个键,--bigkeys 每次 SCAN 扫 100 个哈希桶,总共需要执行 1000 次 SCAN指令:
- 无 -i 0.1:1000 次 SCAN 连续执行,耗时 10 秒 → Redis 每秒要处理 100 次 SCAN 指令,ops 从日常 1000 飙升到 1100,若业务高峰期,可能导致业务命令(GET/SET)延迟增加;
- 加 -i 0.1:每 100 次 SCAN 休眠 0.1 秒 → 1000 次 SCAN 会休眠 10 次(1000/100=10),总休眠 1 秒,扫描总耗时变成 11 秒 → SCAN 指令被 "匀速" 执行,ops 始终平稳,业务无感知。扫描速度变慢 ↔ Redis 性能(ops)更稳定。
本质是 "慢扫换稳定"。
示例
redis
# 执行命令(生产环境建议加 -i 0.1)
redis-cli --bigkeys -a 111111 -i 0.1
# 核心输出(关键部分)
# 1. 扫描进度提示
Scanning the entire keyspace to find biggest keys as well as
average sizes per key type. You can use -i 0.1 to sleep 0.1 sec per 100 SCAN commands to reduce server load.
# 2. 各类型 BigKey 结果
[00.00%] Biggest string key: "big_str" (size: 1048576 bytes) # 最大String(1MB)
[00.00%] Biggest list key: "big_list" (elements: 15000) # 最大List(1.5万元素)
[00.00%] Biggest hash key: "big_hash" (fields: 20000) # 最大Hash(2万字段)
[00.00%] Biggest set key: "big_set" (members: 18000) # 最大Set(1.8万元素)
[00.00%] Biggest zset key: "big_zset" (members: 25000) # 最大ZSet(2.5万元素)
# 3. 整体统计(核心参考)
-------- summary -------
Sampled 10000 keys in the keyspace!
Total key length in bytes is 123456 (avg len 12.35)
Biggest string key: big_str (1048576 bytes)
Biggest list key: big_list (15000 items)
Biggest hash key: big_hash (20000 fields)
Biggest set key: big_set (18000 members)
Biggest zset key: big_zset (25000 members)
1) String keys: 5000 (50.00%)
Average size: 1024 bytes (1.00 KB) # String平均大小
2) List keys: 1000 (10.00%)
Average size: 1500 items # List平均元素数
3) Hash keys: 2000 (20.00%)
Average size: 2000 fields # Hash平均字段数
4) Set keys: 1500 (15.00%)
Average size: 1800 members # Set平均元素数
5) ZSet keys: 500 (5.00%)
Average size: 2500 members # ZSet平均元素数局限性
- 只统计 "最大键",不直接标记 "是否为 BigKey"(需结合业务阈值判断);
- 遍历过程中若有键新增 / 删除,可能漏扫(适合定期巡检,不适合实时检测);
redis-cli --bigkeys -a 111111是快速定位 BigKey 的官方工具,核心输出「各类型最大键 + 平均大小」;
memory usage
MEMORY USAGE 是 Redis 用于精准查询单个键占用内存大小的核心命令,能帮你定位隐藏的 BigKey(比如看似小的键实际占用大量内存),弥补 --bigkeys 只统计 "最大键" 的不足。
linux
MEMORY USAGE key [SAMPLES count]返回值不仅是 "数据本身的大小",还包含 Redis 键的元数据(如类型、过期时间、哈希桶等),更贴近实际内存占用;
| 参数 | 必选 | 含义 |
|---|---|---|
| key | 是 | 要查询的 Redis 键名(如 user:101、big_str) |
| SAMPLES count | 否 | 仅对 Hash/Set/ZSet 生效:抽样统计元素内存(默认 5 个样本),count 越大越精准(如 SAMPLES 100)。就是从指定key的集合中随机抽指定个数的元素(默认是5个)进行估算整个集合占多大内存。 |
查询 String 键(最精准)示例
String 类型无抽样,直接返回实际占用内存(字节):
redis
# 查询 big_str 键的内存占用
127.0.0.1:6379> MEMORY USAGE big_str
(integer) 1048576 # 结果:1048576 字节 = 1MB查询 Hash/Set/ZSet 键(支持抽样)示例
集合类型默认抽样统计,样本数越多结果越准(适合大集合):
redis
# 查询 big_hash 键的内存占用(默认 5 个样本)
127.0.0.1:6379> MEMORY USAGE big_hash
(integer) 5242880 # 约 5MB
# 精准查询(100 个样本,耗时略增但结果更准)
127.0.0.1:6379> MEMORY USAGE big_hash SAMPLES 100
(integer) 5250000 # 精准值:约 5.25MB查询 List 键示例
redis
127.0.0.1:6379> MEMORY USAGE big_list
(integer) 3145728 # 约 3MB对比两种方式
| 工具 | 优势 | 劣势 |
|---|---|---|
| redis-cli --bigkeys | 一键扫描全量键,速度快 | 仅统计 "最大键",无精准内存值 |
| MEMORY USAGE | 精准查询单个键内存 | 需遍历键,批量检测需写脚本 |
如何删除?
删除非字符串类型的 BigKey 时,要 "分批删" 而非 "一次性删";同时要避免让 BigKey 自动过期(过期会触发隐性的一次性删除,导致 Redis 阻塞),本质是防止删除操作占用 Redis 主线程,引发业务卡顿。
为什么要防止 BigKey 过期时间自动删除?
过期自动删除的 "隐性坑":当给 BigKey 设置过期时间(比如 EXPIRE zset_big 3600),到期后 Redis 会自动执行 DEL zset_big------ 这个 DEL 操作和手动执行一样,会一次性删除所有元素,导致阻塞。
更坑的是:
- 这个自动 DEL 操作不会出现在 Redis 慢查询日志(慢查询只记录客户端发送的命令);
- 只能通过 latency 命令(如 latency latest)查到突发的延迟峰值,
排查难度大。
如何避免BigKey过期自动删除
- 方案 1:不给 BigKey 设过期时间,改用 "手动渐进式删除"(上面的 SCAN + 分批删);
- 方案 2:若必须设过期,先把 BigKey 拆成多个小键(比如 200 万 ZSet 拆成 20 个 10 万元素的 ZSet),每个小键设过期,即使自动删除也只阻塞极短时间;
- 方案 3 :(Redis 4.0+):开启 lazy-free(
惰性释放)配置,让 BigKey 删除时的内存释放操作在后台线程执行,不阻塞主线程:
开启惰性释放
redis
# 开启惰性删除(永久生效需改 redis.conf)
127.0.0.1:6379> CONFIG SET lazyfree-lazy-expire yes
127.0.0.1:6379> CONFIG SET lazyfree-lazy-del yes永久生效修改配置文件配置

手动删除大Key
String 类型(特殊:无需分批,DEL 直接删)示例
String 类型即使是 BigKey(如 10MB),DEL 命令耗时也极短(毫秒级),无需渐进式删除,直接删即可:(实在害怕用unlink异步删除)
redis
# String BigKey 直接删除(无阻塞风险)
127.0.0.1:6379> DEL big_string
(integer) 1 # 删除成功List 类型(LPOP/RPOP 分批弹出删除)示例
List 是线性结构,用 LPOP/RPOP 批量弹出元素(每次 100 个),直到 List 为空:
redis
# 循环执行以下命令,直到返回空(可写脚本/客户端循环)
127.0.0.1:6379> LPOP big_list 100 # 每次从头部弹出100个元素
# 返回:1) "elem1" 2) "elem2" ... (最多100个)
# 重复执行,直到返回 (nil),表示List已空
# 最后删除空键(可选,List为空后Redis会自动回收,DEL耗时极短)
127.0.0.1:6379> DEL big_list
(integer) 1代码删除
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisException;
public class RedisBigKeyUtils {
/**
* 渐进式删除List类型BigKey(批量截断,最高效方式)
* @param host Redis主机
* @param port Redis端口
* @param password Redis密码(无则传null)
* @param bigListKey 要删除的List BigKey
*/
public void delBigList(String host, int port, String password, String bigListKey) {
Jedis jedis = null;
try {
// 1. 初始化Redis连接
jedis = new Jedis(host, port);
if (password != null && !password.trim().isEmpty()) {
jedis.auth(password);
}
// 2. 每次截断100个元素(核心逻辑:ltrim保留 [left, end],设为100则删除前100个)
int batchSize = 100;
long remainingLen; // 实时剩余元素数
while ((remainingLen = jedis.llen(bigListKey)) > 0) {
// 若剩余元素不足100,取剩余数量作为截断点
int left = Math.min(batchSize, (int) remainingLen);
// ltrim(key, left, -1):保留第left个到最后一个元素(等价删除前left个元素)
// 注:Redis List索引从0开始,ltrim(100, -1) 即删除前100个元素
jedis.ltrim(bigListKey, left, -1); // -1 表示最后一个元素,避免依赖动态llen
}
// 3. 可选:删除空List键(元素删完后Redis自动回收,可省略)
// Redis4.0+推荐用unlink(惰性删除)替代del,减少阻塞
if (jedis.exists(bigListKey)) {
// jedis.del(bigListKey); // 同步删除
jedis.unlink(bigListKey); // 惰性删除(推荐)
}
System.out.println("List BigKey " + bigListKey + " 渐进式删除完成");
} catch (JedisException e) {
// 捕获Redis异常,保证程序健壮性
System.err.println("删除List BigKey失败:" + e.getMessage());
throw e; // 按需选择是否抛出,让上层感知
} finally {
// 4. 关闭连接,避免连接泄露
if (jedis != null) {
jedis.close();
}
}
}
// 测试方法
public static void main(String[] args) {
RedisBigKeyUtils utils = new RedisBigKeyUtils();
utils.delBigList("127.0.0.1", 6379, "your_password", "big_list_key");
}
}Set 类型(SSCAN + SREM 分批删除)
用 SSCAN 遍历部分元素,再用 SREM 批量删除:
redis
# 步骤1:初始化游标为0
127.0.0.1:6379> SET cursor 0
# 步骤2:循环执行(核心逻辑)
# 2.1 用SSCAN遍历100个元素
127.0.0.1:6379> SSCAN big_set $(GET cursor) COUNT 100
1) "12345" # 新游标,更新到cursor变量
2) 1) "elem1" 2) "elem2" ... (100个元素)
# 2.2 更新游标
127.0.0.1:6379> SET cursor 12345
# 2.3 批量删除遍历到的元素(元素列表作为SREM参数)
127.0.0.1:6379> SREM big_set elem1 elem2 ... (100个元素)
(integer) 100 # 删除成功的数量
# 步骤3:重复步骤2,直到SSCAN返回游标0且元素列表为空
# 步骤4:删除空键
127.0.0.1:6379> DEL big_set
(integer) 1代码删除
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanParams;
import redis.clients.jedis.ScanResult;
import redis.clients.jedis.exceptions.JedisException;
import java.util.List;
public class RedisBigKeyUtils {
/**
* 渐进式删除Set类型BigKey(分批扫描+批量删除元素)
* @param host Redis主机
* @param port Redis端口
* @param password Redis密码(无则传null)
* @param bigSetKey 要删除的Set BigKey
*/
public void delBigSet(String host, int port, String password, String bigSetKey) {
Jedis jedis = null;
try {
// 1. 初始化Redis连接
jedis = new Jedis(host, port);
if (password != null && !password.trim().isEmpty()) {
jedis.auth(password);
}
// 2. 配置扫描参数:每次扫描100个元素
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
// 3. 循环扫描+批量删除元素
do {
ScanResult<String> scanResult = jedis.sscan(bigSetKey, cursor, scanParams);
List<String> memberList = scanResult.getResult();
if (memberList != null && !memberList.isEmpty()) {
// 核心优化:批量删除元素(一次命令删多个,减少网络开销)
String[] members = memberList.toArray(new String[0]);
jedis.srem(bigSetKey, members);
}
// 更新游标(必须在循环末尾,避免游标错位)
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor)); // 游标为0时终止循环
// 4. 可选:删除空Set键(元素删完后Redis自动回收,可省略)
// Redis4.0+推荐用unlink(惰性删除)替代del,避免阻塞
if (jedis.exists(bigSetKey)) {
// jedis.del(bigSetKey); // 同步删除
jedis.unlink(bigSetKey); // 惰性删除(推荐)
}
System.out.println("Set BigKey " + bigSetKey + " 渐进式删除完成");
} catch (JedisException e) {
// 捕获Redis异常,保证程序健壮性
System.err.println("删除Set BigKey失败:" + e.getMessage());
throw e; // 按需选择是否抛出,让上层感知
} finally {
// 5. 关闭连接,避免连接泄露
if (jedis != null) {
jedis.close();
}
}
}
// 测试方法
public static void main(String[] args) {
RedisBigKeyUtils utils = new RedisBigKeyUtils();
utils.delBigSet("127.0.0.1", 6379, "your_password", "big_set_key");
}
}ZSet 类型(ZSCAN + ZREM 分批删除)
用 ZSCAN 遍历元素(返回「元素 + 分值」),提取元素名后用 ZREM 批量删除:
redis
# 步骤1:初始化游标为0
127.0.0.1:6379> SET cursor 0
# 步骤2:循环执行
# 2.1 用ZSCAN遍历100个元素(返回元素+分值成对列表)
127.0.0.1:6379> ZSCAN big_zset $(GET cursor) COUNT 100
1) "67890" # 新游标
2) 1) "elem1" 2) "100" 3) "elem2" 4) "99" ... (100个元素+分值)
# 2.2 提取元素名(elem1、elem2...,忽略分值),更新游标
127.0.0.1:6379> SET cursor 67890
# 2.3 批量删除元素
127.0.0.1:6379> ZREM big_zset elem1 elem2 ... (100个元素)
(integer) 100
# 步骤3:重复步骤2,直到游标返回0且无元素
# 步骤4:删除空键
127.0.0.1:6379> DEL big_zset
(integer) 1代码删除
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanParams;
import redis.clients.jedis.ScanResult;
import redis.clients.jedis.Tuple;
import redis.clients.jedis.exceptions.JedisException;
import java.util.List;
import java.util.stream.Collectors;
public class RedisBigKeyUtils {
/**
* 渐进式删除ZSet类型BigKey(分批扫描+批量删除元素)
* @param host Redis主机
* @param port Redis端口
* @param password Redis密码(无则传null)
* @param bigZsetKey 要删除的ZSet BigKey
*/
public void delBigZset(String host, int port, String password, String bigZsetKey) {
Jedis jedis = null;
try {
// 1. 初始化Redis连接
jedis = new Jedis(host, port);
if (password != null && !password.trim().isEmpty()) {
jedis.auth(password);
}
// 2. 配置扫描参数:每次扫描100个元素(含分值)
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
// 3. 循环扫描+批量删除元素
do {
// 修复:传scanParams实例而非类名
ScanResult<Tuple> scanResult = jedis.zscan(bigZsetKey, cursor, scanParams);
List<Tuple> tupleList = scanResult.getResult();
if (tupleList != null && !tupleList.isEmpty()) {
// 核心优化:提取所有元素名,批量删除(1次命令搞定)
String[] elements = tupleList.stream()
.map(Tuple::getElement) // 提取ZSet元素名(忽略分值)
.toArray(String[]::new);
jedis.zrem(bigZsetKey, elements);
}
// 修复:游标更新移到循环末尾,避免错位
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor)); // 修复:终止条件为数字0,非字母o
// 4. 可选:删除空ZSet键(元素删完后Redis自动回收,可省略)
// Redis4.0+推荐用unlink(惰性删除)替代del,减少阻塞
if (jedis.exists(bigZsetKey)) {
// jedis.del(bigZsetKey); // 同步删除
jedis.unlink(bigZsetKey); // 惰性删除(推荐)
}
System.out.println("ZSet BigKey " + bigZsetKey + " 渐进式删除完成");
} catch (JedisException e) {
// 捕获Redis异常,保证程序健壮性
System.err.println("删除ZSet BigKey失败:" + e.getMessage());
throw e; // 按需选择是否抛出,让上层感知
} finally {
// 5. 关闭连接,避免连接泄露
if (jedis != null) {
jedis.close();
}
}
}
// 测试方法
public static void main(String[] args) {
RedisBigKeyUtils utils = new RedisBigKeyUtils();
utils.delBigZset("127.0.0.1", 6379, "your_password", "big_zset_key");
}
}Hash 类型(HSCAN + HDEL 分批删除)
用 HSCAN 遍历字段,再用 HDEL 批量删除字段:
redis
# 步骤1:初始化游标为0
127.0.0.1:6379> SET cursor 0
# 步骤2:循环执行
# 2.1 用HSCAN遍历100个字段(返回字段+值成对列表)
127.0.0.1:6379> HSCAN big_hash $(GET cursor) COUNT 100
1) "78901" # 新游标
2) 1) "field1" 2) "val1" 3) "field2" 4) "val2" ... (100个字段+值)
# 2.2 提取字段名(field1、field2...,忽略值),更新游标
127.0.0.1:6379> SET cursor 78901
# 2.3 批量删除字段
127.0.0.1:6379> HDEL big_hash field1 field2 ... (100个字段)
(integer) 100
# 步骤3:重复步骤2,直到游标返回0且无字段
# 步骤4:删除空键
127.0.0.1:6379> DEL big_hash
(integer) 1代码删除
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanParams;
import redis.clients.jedis.ScanResult;
import redis.clients.jedis.exceptions.JedisException;
import java.util.*;
import java.util.Map.Entry;
public class RedisBigKeyUtils {
/**
* 渐进式删除Hash类型BigKey(分批扫描+批量删除字段)
* @param host Redis主机
* @param port Redis端口
* @param password Redis密码(无则传null)
* @param bigHashKey 要删除的Hash BigKey
*/
public void delBigHash(String host, int port, String password, String bigHashKey) {
Jedis jedis = null;
try {
// 1. 初始化Redis连接
jedis = new Jedis(host, port);
if (password != null && !password.trim().isEmpty()) {
jedis.auth(password);
}
// 2. 配置扫描参数:每次扫描100个字段
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
// 3. 循环扫描+批量删除字段
do {
ScanResult<Entry<String, String>> scanResult = jedis.hscan(bigHashKey, cursor, scanParams);
// 获取本次扫描的字段列表
List<Entry<String, String>> entryList = scanResult.getResult();
if (entryList != null && !entryList.isEmpty()) {
// 提取所有字段名,批量删除(核心优化:一次命令删多个字段)
String[] fields = entryList.stream()
.map(Entry::getKey)
.toArray(String[]::new);
jedis.hdel(bigHashKey, fields);
}
// 更新游标(必须在循环末尾,否则会无限循环)
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor)); // 游标为0时终止(数字0,非字母o)
// 4. 可选:删除空Hash键(字段删完后,Redis会自动回收,可省略)
// 若开启惰性释放,建议用unlink替代del
if (jedis.exists(bigHashKey)) {
// jedis.del(bigHashKey); // 同步删除
jedis.unlink(bigHashKey); // 惰性删除(Redis4.0+推荐)
}
System.out.println("Hash BigKey " + bigHashKey + " 渐进式删除完成");
} catch (JedisException e) {
// 捕获Redis异常,避免程序崩溃
System.err.println("删除Hash BigKey失败:" + e.getMessage());
throw e; // 按需选择是否抛出,让上层感知
} finally {
// 5. 关闭连接,避免连接泄露
if (jedis != null) {
jedis.close();
}
}
}
// 测试方法
public static void main(String[] args) {
RedisBigKeyUtils utils = new RedisBigKeyUtils();
utils.delBigHash("127.0.0.1", 6379, "your_password", "big_hash_key");
}
}