一张日落照片的困境:为什么传统数据库"读不懂"它?
想象一下,你刚刚拍了一张绝美的日落山景照片------层峦叠嶂的山峰轮廓,天空被染成橙红色,云层像燃烧的火焰。你想把它存进数据库,以后方便检索。
如果用传统的关系型数据库,我们能存什么呢?
-
图片的二进制数据(就是那一堆计算机能读懂的0和1)
-
基本元数据:文件格式(JPG)、创建日期(2025年12月9日)、文件大小(3.2MB)
-
手动标签:日落、风景、橙色、山脉
看起来挺完整的,对吧?但问题来了:
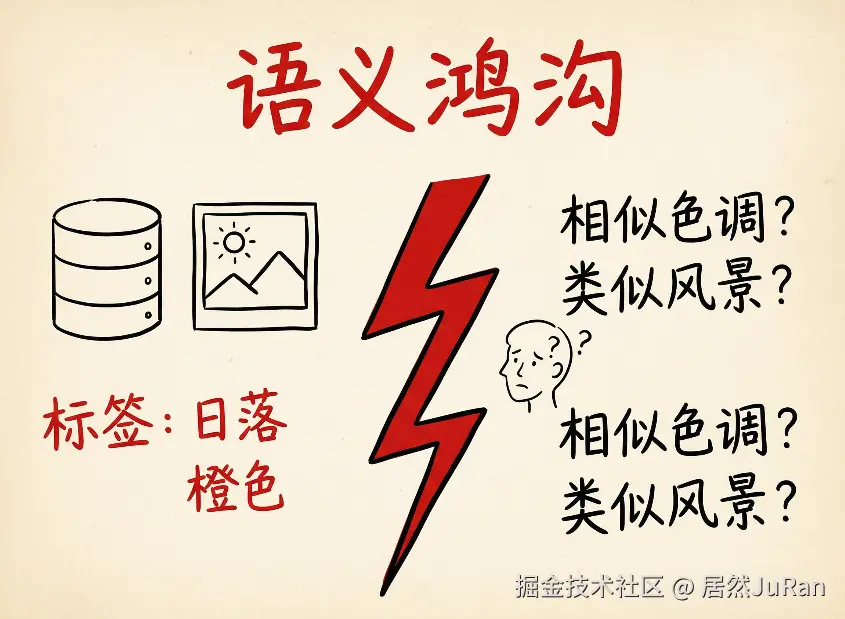
当你想搜索"颜色相似的图片 "时,怎么办?当你想找"背景有山的风景照"时,怎么办?传统数据库只会机械地匹配关键词------你搜"橙色",它就只能找标签里有"橙色"的图片。但如果另一张照片的标签是"暖色调"或"golden hour",即使它们在视觉上极其相似,数据库也认不出来。
这就是所谓的"语义鸿沟"------计算机存储数据的方式,和人类理解数据的方式,存在巨大的鸿沟。
语义鸿沟:机器看到的只是冰冷的标签
我们再来看看传统数据库的局限性到底在哪里。
假设你在公司的内容管理系统里存了几千张照片,每张都有这样的结构化字段:
plaintext
图片ID: 12345
文件名: sunset_mountain.jpg
标签: [日落, 风景, 橙色, 山脉]
拍摄日期: 2025-12-09当你执行一个SQL查询:SELECT * WHERE tags CONTAINS '橙色',数据库会老老实实地把所有标签里有"橙色"的图片找出来。但它完全不理解:
-
这张照片的整体氛围是宁静还是壮丽?
-
它和另一张海边日落在色调上是否相似?
-
如果我想要"类似的暖色系风景照",它该推荐什么?
传统数据库就像一个只会按标签分类的图书管理员------你说"找标签是'橙色'的书",他能做到;但你说"找感觉相似的书",他就懵了。
向量数据库:给数据装上"语义坐标"
向量数据库的出现,就是为了填补这条鸿沟。
它的核心思路是:不要把照片只存成"二进制+标签",而是把它转化成一串数字数组 ,这就是所谓的向量嵌入(Vector Embedding)。
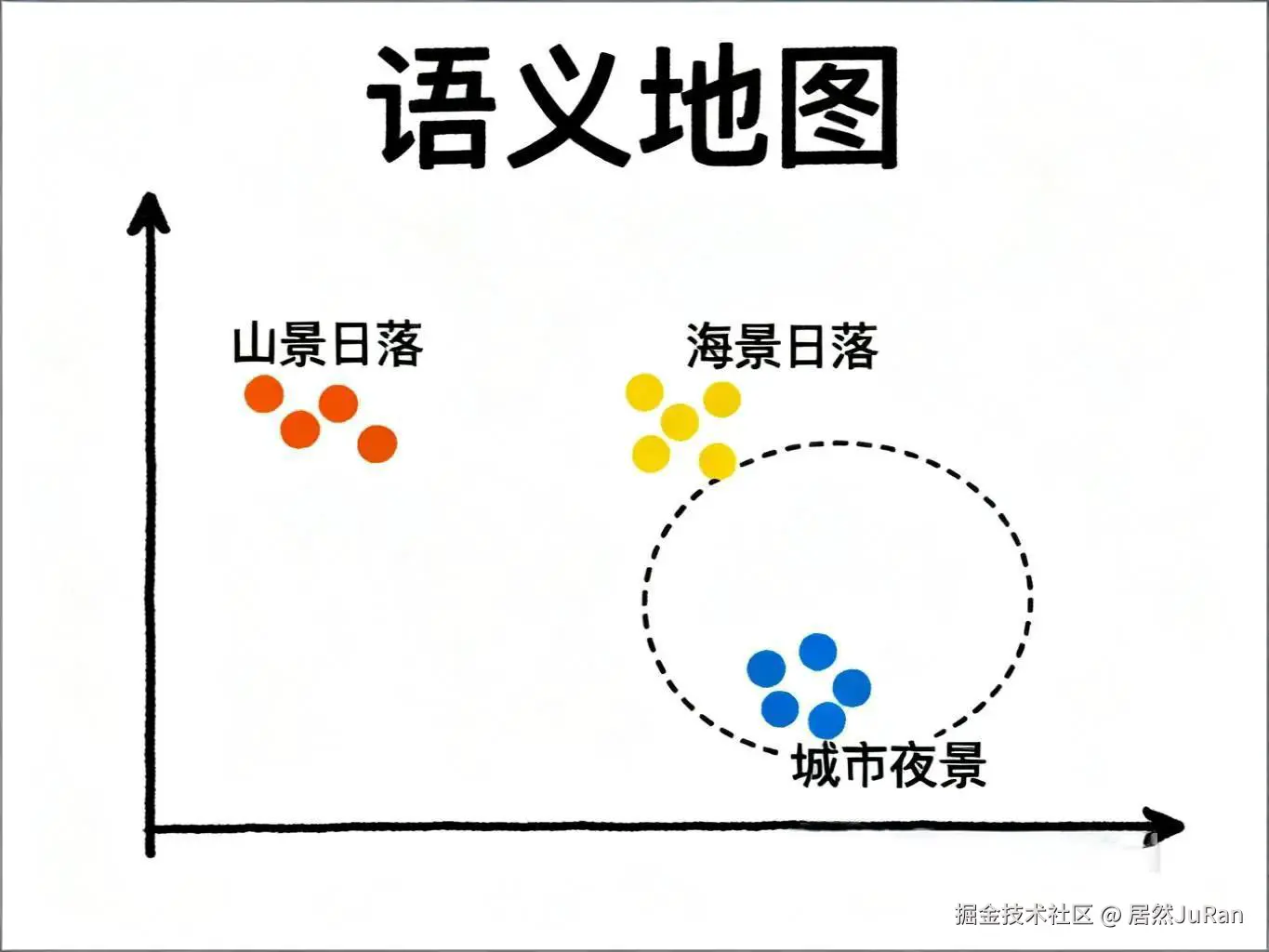
听起来很抽象?让我们用"语义地图"来理解:
想象有一张巨大的地图,每张照片都是地图上的一个点。相似的照片会靠得很近,不相似的照片会离得很远。比如:
-
所有"日落山景"的照片会聚在一起形成一个区域
-
所有"海边日落"的照片会聚在另一个区域(但因为都是日落,所以这两个区域不会离太远)
-
而"城市夜景"的照片,就会在地图的另一端
这样一来,当你想找"和这张山景照片相似的图片"时,系统只需要在地图上找距离这个点最近的其他点就行了------这就是向量数据库的相似性搜索!
而且,向量数据库不只能存图片,还能存各种非结构化数据:
-
文本文档:文章、评论、对话记录
-
音频文件:音乐、播客、语音记录
-
视频片段:短视频、电影片段
只要能转化成向量嵌入,就能存进向量数据库,然后用"语义相似度"来检索。
向量嵌入的"魔法":一串数字如何捕捉语义?
那么,这些神奇的向量嵌入到底长什么样?
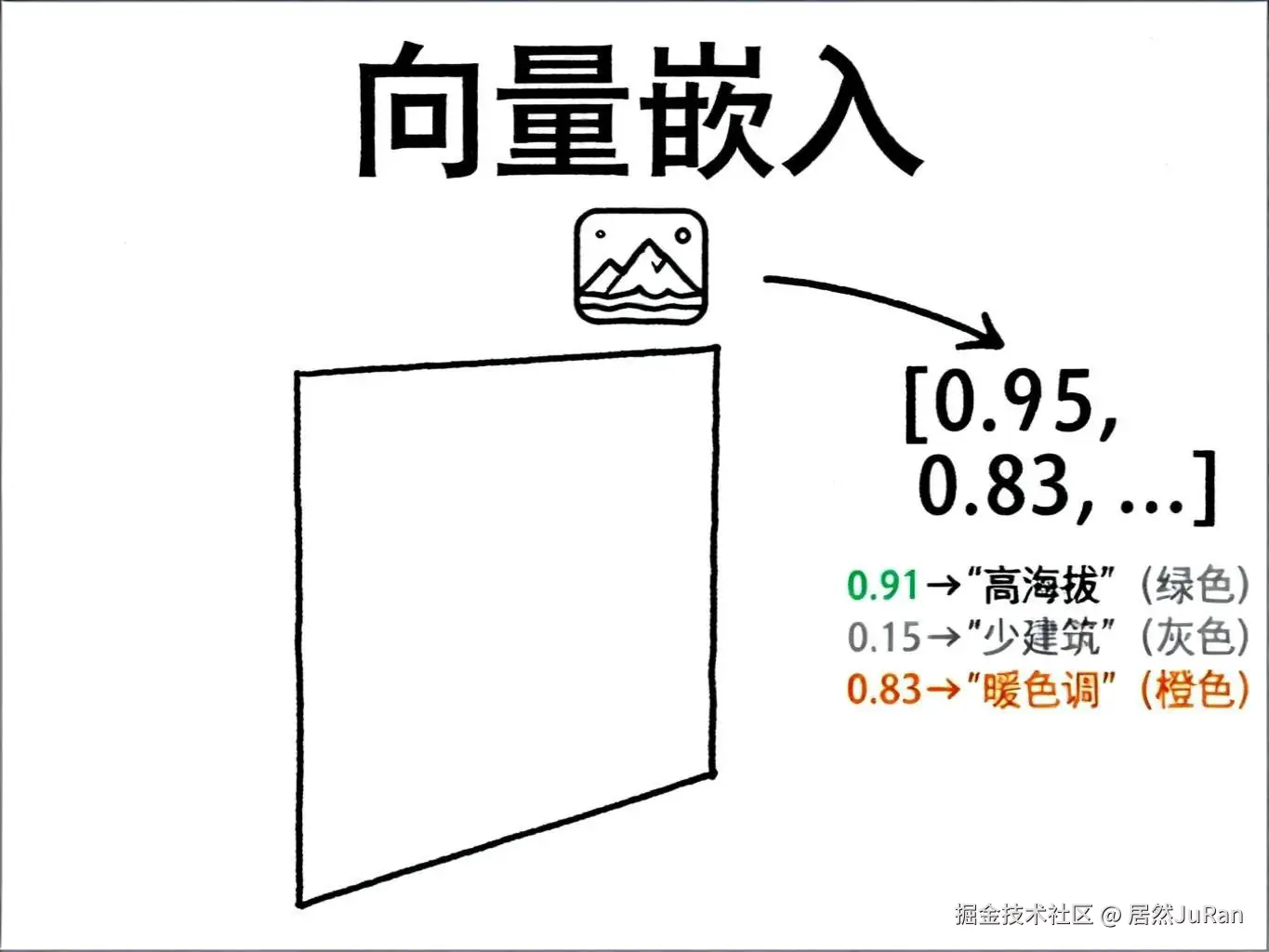
它本质上是一组数字,每个数字代表某种"特征强度"。
我们还是用那张日落山景照片举例(简化版,实际情况更复杂):
plaintext
山景照片的向量嵌入:
[0.91, 0.15, 0.83, ...]这三个数字分别代表:
-
0.91(第一维度):显著的海拔变化 → 这是山脉!
-
0.15(第二维度):很少的城市元素 → 没什么建筑物
-
0.83(第三维度):强烈的暖色调 → 日落的橙红色
现在我们换一张海边日落照片,它的向量嵌入可能是:
plaintext
海景照片的向量嵌入:
[0.12, 0.08, 0.89, ...]注意到了吗?
-
第一维度差异很大(0.91 vs 0.12):山有起伏,海滩平坦
-
第三维度非常接近(0.83 vs 0.89):都是暖色调的日落!
当我们计算这两个向量的"距离"时,会发现它们在某些维度上很相似 (都是日落),但在另一些维度上有差异(地形不同)。这就是向量如何捕捉"相似但不完全相同"的语义关系。
当然,真实的向量嵌入远比这复杂------它们通常有数百甚至数千个维度,每个维度都在捕捉某种抽象特征。而且,这些维度往往不像我们例子里这么容易解释,更多时候是模型在训练中"自己学会"的抽象表达。
向量嵌入是如何"炼成"的?
既然向量嵌入这么神奇,它们是怎么生成的?
答案是:专门的嵌入模型,通过在海量数据上训练得来的。
不同类型的数据,有不同的"专家模型":
-
图像:CLIP(能理解图像内容的模型)
-
文本:GloVe(能理解词语语义的模型)
-
音频:Wav2vec(能理解声音特征的模型)
这些模型的工作方式很相似:
从简单到复杂的"层层提炼"
当一张照片被送进CLIP模型时,它会经过多个处理层:
-
早期层:识别基础特征 → 检测边缘、颜色块、纹理
-
中间层:识别局部元素 → 识别出"这是山"、"这是云"
-
深层:理解整体语义 → "这是一张宁静的山景日落照片"
最终,模型会从最深的那一层提取出一个高维向量,这个向量就浓缩了整张照片的"语义精华"。
文本也是类似的过程:
-
早期层:识别单词 → "sunset"、"mountain"、"beautiful"
-
中间层:理解短语 → "beautiful sunset"
-
深层:理解语境和情感 → "这是一段赞美自然景色的描述"
这种"层层抽象"的过程,让模型能够捕捉到数据的深层含义,而不只是表面的关键词。
百万级向量的搜索挑战:向量索引来救场
现在我们有了向量数据库,里面存了几百万张照片的向量嵌入。当你想找"和这张日落照片相似的图片"时,系统要怎么做?
最笨的办法:把你的查询向量和数据库里的每一个向量都比较一遍,找出距离最近的。
但这太慢了!如果每个向量有1000个维度,数据库里有100万个向量,你需要做10亿次浮点数运算。这对于实时查询来说完全不可接受。
近似最近邻(ANN):用"接近正确"换取"极快速度"
向量索引 技术的核心思路是:我不需要找到绝对最接近 的向量,只要找到非常接近的向量就够了。
这就像你问"附近有没有咖啡馆",导航软件不需要把全城的咖啡馆都扫描一遍,只要看看你周围1公里内有哪些就行了------这就是**近似最近邻(Approximate Nearest Neighbor, ANN)**算法的思路。
常见的索引方法有:
1. HNSW(分层可导航小世界)
想象一个多层的高速公路网络:
-
顶层:只有几个主要城市的连接(快速定位大致区域)
-
中层:连接更多的城镇(缩小范围)
-
底层:连接所有的小村庄(精确定位)
搜索时,你先在顶层快速跳到目标区域,再逐层下沉到精确位置。
2. IVF(倒排文件索引)
把向量空间划分成很多"簇"(就像把地图分成几百个网格),每次搜索时只在最相关的几个簇里找,而不是全局搜索。
这些索引方法牺牲了一点点准确性 (可能错过了0.01%更接近的结果),但换来了数百倍的速度提升------从几秒钟变成几毫秒。

向量数据库的"杀手级应用":RAG系统
说了这么多,向量数据库最火的应用场景是什么?答案是:RAG(检索增强生成)系统。
简单来说,就是给AI助手(比如ChatGPT)装上一个"知识库",让它能引用最新、最准确的信息来回答问题。
工作流程是这样的:
-
存储阶段:把公司的文档、产品手册、历史记录等等,全部切成小块,转化成向量嵌入,存进向量数据库。
-
检索阶段:当用户问"我们公司去年Q4的营收增长率是多少?"时,系统会把这个问题也转成向量,然后在数据库里找最相关的文档片段。
-
生成阶段:把找到的相关信息和用户问题一起喂给大语言模型,让它基于"证据"生成回答,而不是瞎编。
这样一来,AI的回答就有了"依据",不再只是凭训练数据"猜"答案。
这也是为什么现在几乎所有的企业AI助手、智能客服、知识库问答系统,背后都在用向量数据库的原因。
写在最后:向量数据库的双重魔力
回到文章开头的那张日落山景照片。
在传统数据库里,它只是一串二进制数据加几个标签------冰冷、刻板、缺乏"理解"。
但在向量数据库里,它变成了一个在高维空间中的坐标点------它知道自己和其他照片的"语义距离",它能被"相似性"检索到,它成了一个真正"可被理解"的数据对象。
向量数据库的魔力,就在于它给了非结构化数据两种能力:
-
存储能力:把复杂的、难以量化的语义信息,压缩成数学向量
-
检索能力:快速、准确地找到语义相似的内容
这不仅改变了我们管理照片、文档、音频的方式,更重要的是,它让AI能够真正"理解"和"使用"人类的知识------这正是下一代智能应用的基石。
下次当你在某个AI助手里问问题,它秒速给你找到了相关资料;或者在图片库里搜索"类似这张照片的图片",系统精准地推荐了你想要的内容------背后可能就有一个向量数据库在默默工作。