作者:路遥
点击此处,查看视频演示!
背景
在可观测性系统中,UModel 定义了统一的数据模型(Schema),UModel 查询专注于探索知识图谱元数据,而 Entity 查询则用于查询和检索具体的实体实例数据。Entity 查询基于 USearch 引擎,提供了强大的全文检索、精确查找、条件过滤等能力,支持跨域、跨实体类型的联合查询。
与 UModel 查询关注 Schema 定义不同,Entity 查询专注于运行时实体数据,帮助用户快速定位、检索和分析具体的实体实例,如服务实例、Pod 实例、主机实例等。
1.1 Entity 查询解决的问题
在实际的可观测性场景中,我们经常需要:
- 快速定位实体: 根据关键词、属性值快速找到相关实体
- 跨域检索: 在多个域(APM、K8s、云资源等)中联合搜索
- 精确查询: 根据已知的实体 ID 批量查询详细信息
- 条件过滤: 基于实体属性进行复杂的条件筛选
- 统计分析: 对实体数据进行聚合分析和计算
Entity 查询通过 USearch 引擎的统一接口,解决了传统多系统查询的痛点,提供了高效、灵活的实体检索能力。
1.2 三种查询类型的区别
在 EntityStore 中,存在三种不同类型的查询:
EntityStore 是 UModel 系统中的统一存储引擎,负责存储和管理可观测性领域的核心 Metadata 数据,包括 UModel 元数据、实体数据和实体关系数据。它为可观测性分析提供高性能的数据存储和查询能力。
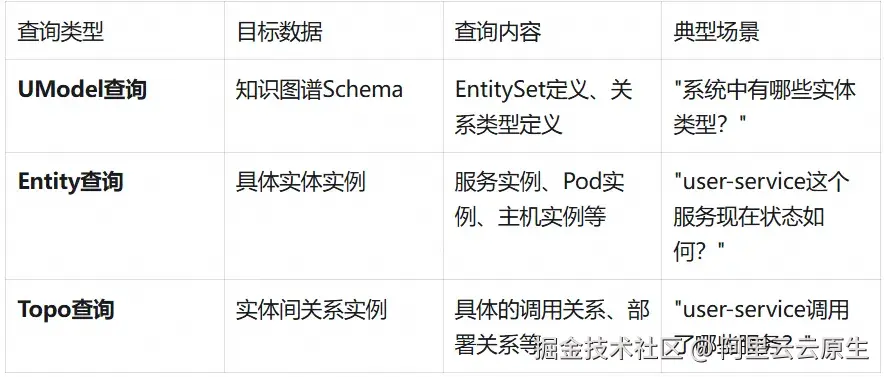
Entity 查询专注于实体实例数据,是日常运维和问题排查中最常用的查询方式。
Entity 查询介绍
2.1 数据模型
三层存储结构
USearch 采用分层存储结构,确保数据的逻辑隔离和高效查询:
- Workspace 层: 最顶层隔离单位,不同 workspace 之间完全隔离
- Domain 层: 域级别的分类,用于业务逻辑分组(如 apm、k8s、acs 等)
- EntityType 层: 具体的实体类型,包含实际的实体数据(如 apm.service、k8s.pod 等)
yaml
Workspace: my-observability
├── Domain: apm
│ ├── EntityType: apm.service
│ ├── EntityType: apm.host
│ └── EntityType: apm.instance
├── Domain: k8s
│ ├── EntityType: k8s.pod
│ ├── EntityType: k8s.node
│ └── EntityType: k8s.service
└── Domain: acs
├── EntityType: acs.ecs.instance
└── EntityType: acs.rds.instance数据存储特点
- 唯一性保证: 在同一 EntityType 下,
__entity_id__保证唯一性 - 列式存储: 支持多行多列的表结构数据,支持 SPL 进行统计分析
- 索引优化: 针对检索场景进行全文索引优化,支持多关键词检索和 Ranking 打分
- 时序支持: 支持基于时间范围的数据查询和过滤,支持回溯任意时刻的实体和关系状态
2.2 USearch 核心功能
检索能力
USearch 提供强大的全文检索能力,支持:
- 多类型联合检索: 跨多个 domain 和 entity_type 进行联合查询,统一打分排序
- 多关键词检索打分: 基于词权重、字段权重等信息计算相关性分数
- 智能分词: 自动分词和相关性打分,提高检索准确性
ini
-- 检索所有domain中包含"cart"的实体
.entity with(domain='*', name='*', query='cart') 扫描能力
除了检索模式,USearch 还支持扫描模式,读取原始数据后通过 SPL 进行更多的过滤和计算,适用于需要复杂数据处理的场景。
ini
-- 扫描apm域中香港区域的应用数量
.entity with(domain='apm', name='apm.service')
| where region_id = 'cn-hongkong'
| stats count = count() 2.3 查询语法
基础语法结构
ini
.entity with(
domain='domain_pattern', -- 域过滤模式
name='type_pattern', -- 类型过滤模式
query='search_query', -- 查询条件
topk=10, -- 返回条数
ids=['id1','id2','id3'] -- 精确ID查询
)参数详解
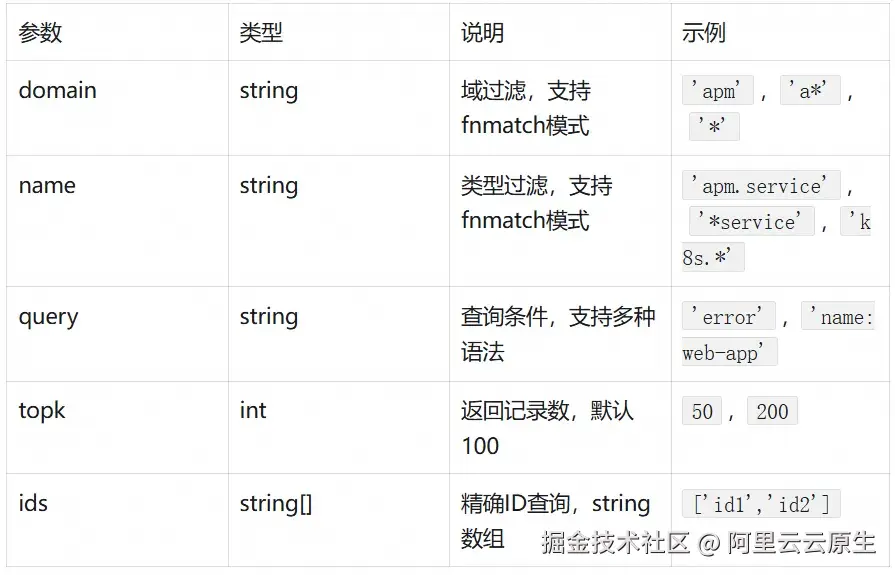
fnmatch 语法说明: 支持通配符匹配,如 * 匹配任意字符,? 匹配单个字符。参考 fnmatch 文档:docs.python.org/3/library/f...
域和类型过滤模式
sql
-- 匹配模式示例
.entity with(domain='ac*') -- ac开头的domain
.entity with(domain='a*c') -- a开头、c结尾的domain
.entity with(name='*instance') -- 以instance结尾的类型
.entity with(name='k8s.*') -- k8s域下的所有类型
.entity with(domain='*', name='*') -- 所有domain和类型查询模式详解
3.1 精确 ID 查询
当知道具体的实体 ID 时,使用 ids 参数进行精确查询:
ini
-- 查询特定ID的实体
.entity with(
domain='apm',
name='apm.service',
ids=['4567bd905a719d197df','973ad511dad2a3f70a']
)适用场景:
- 根据告警中的实体 ID 查询详细信息
- 验证特定实体的存在性和状态
- 批量查询已知 ID 的实体信息
3.2 全文检索模式
基础全文搜索
ini
-- 简单关键词搜索
.entity with(query='web application')
-- 多词OR关系(默认行为)
.entity with(query='kubernetes docker container')搜索特性:
- 多个词之间是 OR 关系,出现任意一个词即满足条件
- 搜索所有字段,包括系统字段和自定义字段
- 自动分词和相关性打分
短语搜索
对于通过符号连接(-)的词,必须在同一字段下完整匹配:
ini
-- 完整短语匹配
.entity with(query='opentelemetry.io/name-fraud-detection')
-- 普通搜索(命中任意一个词)
.entity with(query='opentelemetry.io/name cart')字段限定搜索
指定在特定字段中搜索:
ini
-- 在描述字段中搜索
.entity with(query='description:"error handling service"')
-- 在自定义属性中搜索
.entity with(query='cluster_name:production')
-- 在标签中搜索
.entity with(query='labels.team:backend')逻辑条件组合
支持 and、or、not 逻辑运算符:
ini
-- AND条件:同时满足两个条件
.entity with(query='service_name:web AND status:running')
-- OR条件:满足任一条件
.entity with(query='environment:prod OR environment:staging')
-- NOT条件:满足左侧、不满足右侧
.entity with(query='type:service NOT status:stopped')
-- 复杂组合
.entity with(query='(cluster:prod OR cluster:staging) AND NOT status:maintenance')特殊字符处理:
- 包含特殊字符(如 |、:)的查询必须用双引号包含
- 示例:
query='description:"ratio is 1:2"'
3.3 多类型联合检索
支持跨多个 domain 和 entity_type 进行联合查询,统一打分排序:
java
-- 检索所有domain中包含"cart"的实体
.entity with(domain='*', name='*', query='cart')
-- 检索所有domain中包含"service"的实体类型,属性中存在"production"的实体
.entity with(domain='*', name='*service*', query='production')
-- 检索特定domain下的多种实体类型,属性中存在"error"或"rate"的实体
.entity with(domain='apm', name='apm.*', query='error rate')3.4 结合 SPL 进行数据计算分析
无论检索模式还是扫描模式,都可以结合 SPL 进行更深入的数据计算:
sql
-- 检索apm域中在香港区域的不同语言的应用数量,按照应用数量降序排列
.entity with(domain='apm', name='apm.service')
| where region_id = 'cn-hongkong'
| stats count = count() by language
| project language, count
| sort count desc打分和排序机制
4.1 相关性打分
USearch 使用多因素综合打分算法:
- 词频权重: 关键词在文档中出现的频率
- 字段权重: 不同字段的重要性权重(如名称字段权重高于描述字段)
- 文档长度: 较短文档中的匹配通常得分更高
- 逆文档频率: 稀有词汇获得更高权重
4.2 排序规则
默认按相关性分数降序排列,分数相同时按时间戳排序:
sql
-- 默认相关性排序
.entity with(query='web service error', topk=20)
-- 结合SPL自定义排序
.entity with(query='kubernetes pod')
| sort __last_observed_time__ desc
| limit 50
-- 多字段排序
.entity with(domain='apm', name='apm.service')
| sort cluster asc, service_name ascEntity 查询具体应用场景
5.1 场景一:快速定位和检索实体
问题描述: 线上出现告警或需要查找特定实体时,需要快速定位相关实体实例。
解决方案: 根据场景选择不同的查询方式。
ini
-- 方式1:根据告警中的实体ID精确查询
.entity with(
domain='apm',
name='apm.service',
ids=['4567bd905a719d197df','973ad511dad2a3f70a']
)
-- 方式2:根据关键词全文检索
.entity with(query='user-service error', topk=10)
-- 方式3:字段限定精确查询
.entity with(query='service_name:user-service')
-- 方式4:通过标签查找特定团队的服务
.entity with(
domain='apm',
name='apm.service',
query='labels.team:backend AND labels.language:java AND status:running'
)效果: 快速获取问题实体的完整信息,包括状态、属性、标签等,支持多种查询方式满足不同场景需求。
5.2 场景二:跨域联合检索
问题描述: 需要在多个域(APM、K8s、云资源等)中搜索包含特定关键词的实体,避免在多系统间切换。
解决方案: 使用多类型联合检索。
ini
-- 在所有域中搜索包含"error"的实体
.entity with(domain='*', name='*', query='error', topk=50)
-- 检索特定前缀domain下的多种实体类型
.entity with(domain='apm*', name='*', query='error', topk=50)效果: 统一接口检索跨域实体,打破数据孤岛,提高查询效率。
5.3 场景三:条件过滤和数据分析
问题描述: 需要找出满足特定条件的实体,并进行统计分析,识别问题模式或进行数据洞察。
解决方案: 结合 SPL 进行条件过滤和聚合分析。
ini
-- 找出java语言的apm服务,按集群统计
.entity with(domain='apm', name='apm.service')
| where language='java'
| stats count=count() by cluster
-- 查询生产环境或预发环境中运行的服务
.entity with(query='(environment:prod OR environment:staging) AND status:running')
| stats count=count() by environment, cluster
-- 检索apm域中ARMS生产应用在不同区域的数量,按照应用数量降序排列
.entity with(domain='apm', query='environment:prod')
| where telemetry_client='ARMS'
| stats service_count = count() by service, region_id
| project region_id, service, service_count
| sort service_count desc效果: 快速识别问题实体,进行数据聚合分析,发现数据模式。
性能优化建议
6.1 使用精确匹配
字段限定查询比全文搜索更高效:
ini
-- ❌ 全文搜索(较慢)
.entity with(query='production')
-- ✅ 字段限定(更快)
.entity with(query='environment:production')6.2 避免前缀通配符
后缀通配符比前缀通配符性能更好:
ini
-- ❌ 前缀通配符(较慢)
.entity with(name='*service')
-- ✅ 后缀通配符(更快)
.entity with(name='service*')6.3 合理使用逻辑运算符
简单的 AND 条件比复杂的 OR 条件更高效:
ini
-- ✅ 简单AND条件
.entity with(query='status:running AND cluster:prod')
-- ⚠️ 复杂OR条件(性能较差)
.entity with(query='name:a OR name:b OR name:c OR name:d')6.4 合理设置 topk
根据实际需求设置 topk 值,避免返回过多不必要的数据:
ini
-- 只需要前10条结果
.entity with(query='error', topk=10)
-- 需要更多结果时再增加
.entity with(query='error', topk=100)总结
Entity 查询作为 EntityStore 中用于查询实体实例的核心接口,为可观测性场景提供了强大的检索和分析能力。通过 Entity 查询,用户可以:
- 快速定位: 通过关键词、ID、条件快速找到目标实体
- 跨域检索: 统一接口查询多个域的实体数据
- 精确查询: 支持字段限定、逻辑组合等精确查询方式
- 数据分析: 结合 SPL 进行复杂的数据过滤和统计分析
这些能力使得 Entity 查询成为日常运维、问题排查、数据分析等场景中不可或缺的工具,为可观测性数据的有效利用提供了坚实的基础。
点击此处查看视频演示。