你有没有好奇过:ControlNet为什么能在不"废掉"Stable Diffusion(SD)预训练能力的前提下,精准控制图像生成?
答案藏在一个看似简单的组件里------零卷积(Zero Convolution)。它不是什么复杂的新结构,却是ControlNet"既听话又好用"的核心秘密。今天我们就拆解它的工作流程,看看这个"全零初始化的1×1卷积"到底有多聪明。
一、先搞懂:ControlNet为啥需要"零卷积"?
先回顾ControlNet的基础架构:
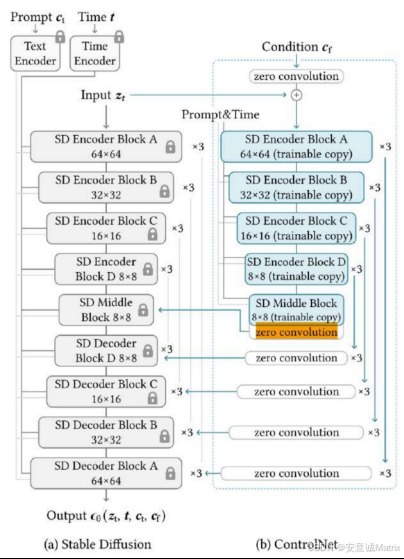
- 左侧是冻结的Stable Diffusion主分支(权重固定,保留预训练的生成能力);
- 右侧是可训练的ControlNet分支(负责学习"条件信号",比如边缘图、姿态图)。
要让这两个分支协同工作,得解决一个关键矛盾:
如何让ControlNet的"条件信号"注入SD,但训练初期不破坏SD的预训练效果?
零卷积就是为这个矛盾设计的"连接器"。
二、零卷积的工作流程:从"隐身"到"精准控制"
我们结合ControlNet的分支结构(示意图右侧),分3个阶段看零卷积的作用:
阶段1:初始化------"我先隐身,不打扰SD"
零卷积的核心初始化规则是:权重和偏置全设为0。
当ControlNet刚启动训练时:
- 条件信号(比如Canny边缘图)经过ControlNet分支的编码器后,会通过"零卷积"输出;
- 因为参数全零,零卷积的输出是全零特征图;
- 这个全零特征图会和SD主分支的对应特征图"相加融合"------加0等于没加,SD的预训练能力完全不受影响。
→ 效果:训练初期,ControlNet相当于"不存在",SD依然能生成高质量图像,避免了"新分支干扰预训练模型"的问题。
阶段2:训练------"悄悄学习,慢慢接管控制"
随着训练推进,零卷积的参数会逐步从0开始更新:
- ControlNet分支学习"条件信号→图像特征"的映射(比如"边缘图的线条→人物轮廓");
- 零卷积根据训练损失(比如生成图和真实图的差异)调整参数,让输出的特征图不再是全零;
- 调整后的特征图与SD主分支的特征融合,逐步把"条件信号的约束"注入生成流程。
→ 关键优势:渐进式学习
零卷积的参数从0开始微调,相当于"慢慢给ControlNet加权重"------既让它学会"按条件生成",又不会让SD忘记预训练的"绘画功底",避免了"灾难性遗忘"。
阶段3:推理------"精准融合,控制生成方向"
训练完成后,零卷积的参数已经固定,推理时的流程是:
- 输入条件信号(比如用户给的姿态图),经过ControlNet分支编码器处理;
- 零卷积将ControlNet的特征转换为"与SD主分支特征维度匹配"的格式(1×1卷积的作用是维度对齐);
- 零卷积的输出特征与SD主分支的对应特征"相加",让条件约束融入生成过程;
- 最终通过SD的解码器生成"符合条件信号"的图像(比如和输入姿态一致的人物)。
→ 效果:既保留SD的生成质量,又实现了"条件信号精准控制图像内容"的目标。
三、为什么是"零卷积",不是"普通卷积"?
如果用普通1×1卷积(随机初始化参数)代替零卷积,会发生什么?
- 训练初期,普通卷积的随机输出会"污染"SD主分支的特征,导致SD直接生成乱码;
- 必须重新微调SD主分支才能恢复质量,这会大幅增加训练成本,也失去了ControlNet"冻结SD权重"的优势。
零卷积的"全零初始化",本质是用最简单的方式实现了"预训练模型+新分支"的无痛融合。
四、总结:零卷积是ControlNet的"智慧妥协"
零卷积不是什么黑科技,却是ControlNet设计的"巧思":
- 它解决了"新控制分支如何兼容预训练扩散模型"的核心问题;
- 用"全零初始化+渐进式学习",平衡了"控制精度"和"生成质量"。
现在再看ControlNet的示意图,你应该能秒懂:那些标着"zero convolution"的模块,就是让ControlNet"既听话又好用"的隐形功臣。