计算机十万个为什么--数据库索引
大家好,欢迎来到最新一期的无限大博客。
突然发现自己对数据库相关的内容掌握不够扎实,于是就去学习了一下,顺便也将自己的理解写成了一篇博客。
希望这篇文章能对大家有所帮助
数据库索引:给数据仓库装个"智能导航系统" 🧭
想象一下,你走进一个占地 1000 平方米的超级图书馆 📚,里面塞满了几十万本书,却连个分类牌都没有。老板忽然喊你找一本《数据库从入门到放弃》,你是不是当场想表演一个原地消失术?😱
这就是没有索引的数据库 的日常!每次查询都像蒙眼找书,全表扫描就是那个被蒙住眼睛的倒霉蛋,只能一本本摸过去。而今天我们要聊的 数据库索引 ,就是给这个混乱图书馆装上的智能导航系统 🧭,让你秒变图书馆馆长,想找哪本书就找哪本书!
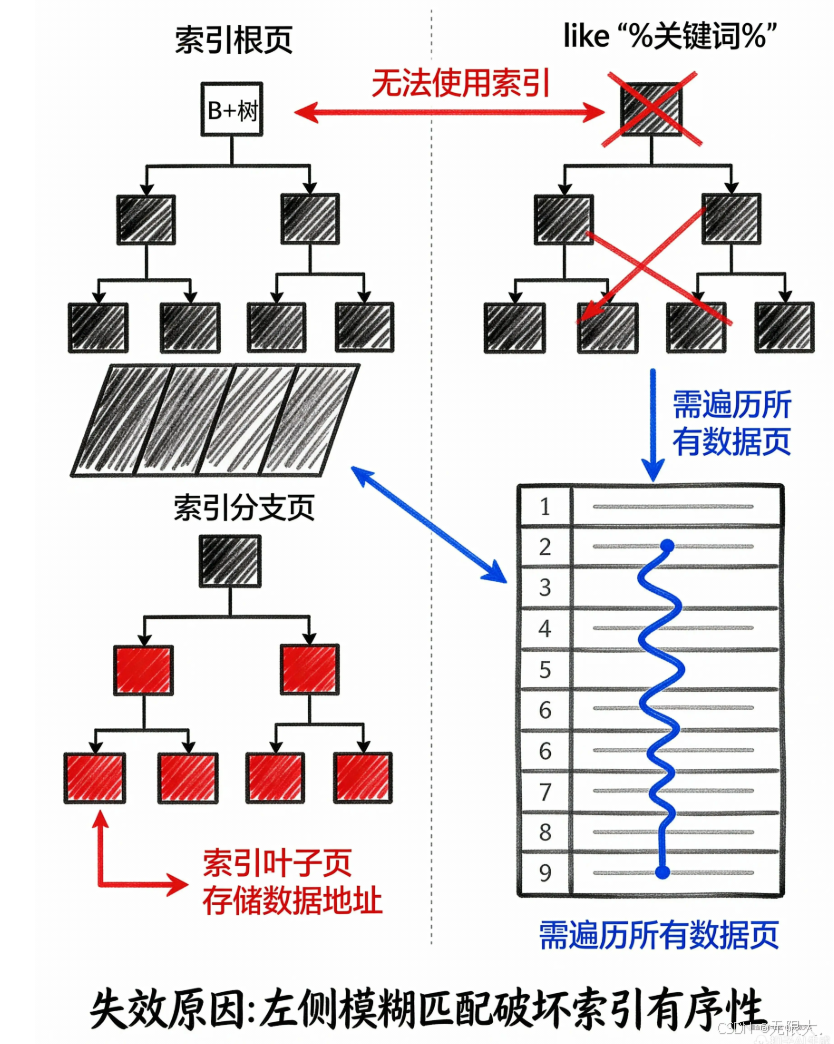
为什么"like '%关键词%'"会让索引当场罢工?
先看个灵魂拷问:下面两条 SQL,性能可能差 1000 倍!你猜哪个快?
sql
-- 语句 A
SELECT * FROM books WHERE title LIKE '数据库%';
-- 语句 B
SELECT * FROM books WHERE title LIKE '%数据库%';答案是语句 A 可能快到飞起,语句 B 可能慢到想砸键盘 !
原因就藏在那个小小的百分号里。
🌰 蒙眼找书现场还原
假设我们给 title 字段建了索引,就像图书馆按书名首字母排序的分类架。当你执行 LIKE '数据库%' 时,索引会开心地带你直奔 "数" 字区,从 "数据库入门" 找到 "数据库原理",一气呵成 🚀。
但如果写成 LIKE '%数据库%',相当于你告诉图书管理员:"我要找所有书名里包含'数据库'的书,但我不告诉你它在开头还是结尾"。这时候索引直接懵了 😵,因为它的排序规则是按首字母来的,现在关键词可能出现在任何位置,就像让你在所有书里找 "包含'的'字的书" 一样------索引完全帮不上忙!
全表扫描警告 ⚠️:数据库只能开启"蒙眼摸书"模式,逐行检查每条记录。如果表中有 100 万条数据,就像让你在 100 万本书里一本本翻开找,画面太美我不敢看 🥶。
避坑指南:3 个让索引失效的经典操作
| 错误写法 🔴 | 正确姿势 🟢 | 性能差距 |
|---|---|---|
| LIKE '%关键词%' | LIKE '关键词%' 或使用全文索引 | 可能差 100~1000 倍 |
| WHERE age + 1 = 25 | WHERE age = 24 | 索引直接失效 |
| WHERE SUBSTR(title, 3) = '数据库' | WHERE title LIKE '__数据库%' | 函数操作导致索引失效 |
B+树索引 vs 哈希索引:新华字典 vs 快递柜
现在你决定给图书馆装导航系统了,但市场上有两种方案:
- 方案 A :像《新华字典》那样的目录 📖(B+树索引)
- 方案 B :像快递柜那样的编号系统 📦(哈希索引)
到底选哪个?这得看你平时怎么找书!
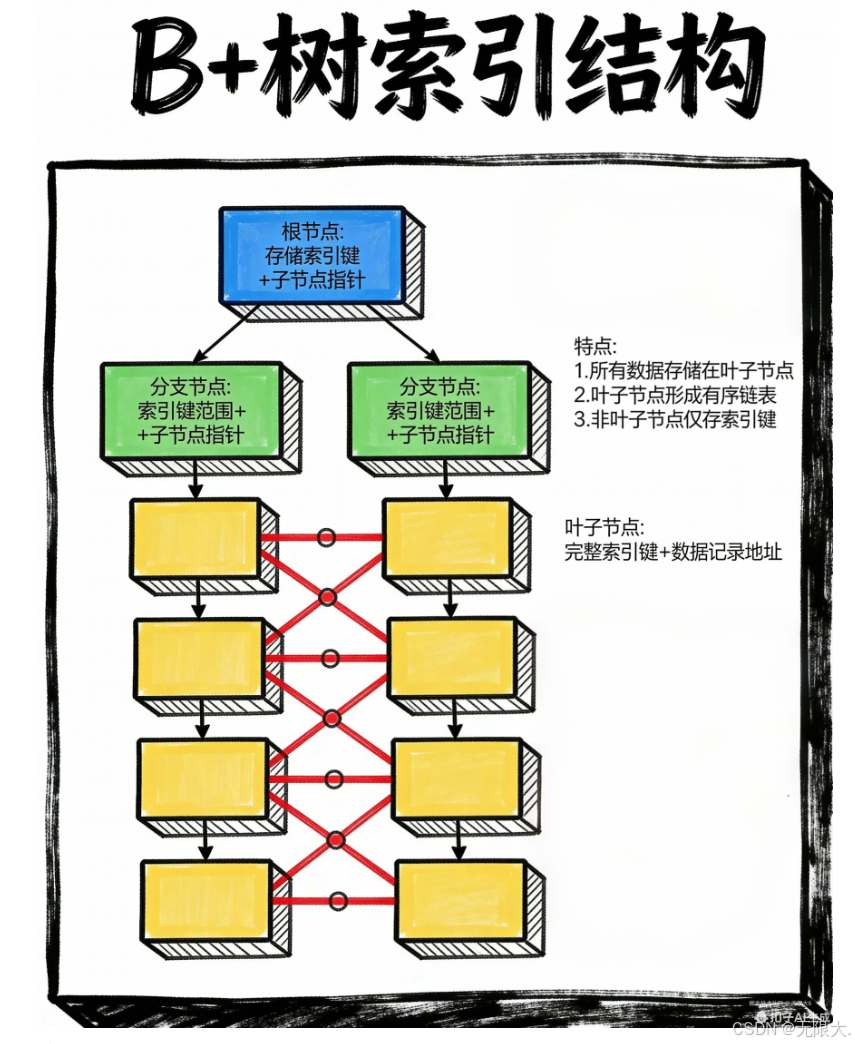
📖 B+树索引:新华字典的智慧
翻开你的新华字典,会发现它有两种目录:拼音索引和部首索引。B+树索引就像拼音索引,它把数据按顺序排好,并且只在叶子节点存储完整数据,中间节点都是"指路牌"。
1-100 101-200 1-50 51-100 101-150 151-200 链表指针 链表指针 链表指针 根节点 中间节点 中间节点 叶子节点: 1,3,5...50 叶子节点: 51,53...100 叶子节点: 101...150 叶子节点: 151...200
适用场景 :
- 范围查询(比如找 "价格在 10-50 元的书")📊
- 排序操作(比如 "按出版日期倒序排列")🔄
- 前缀匹配(比如 LIKE '数据库%')🎯
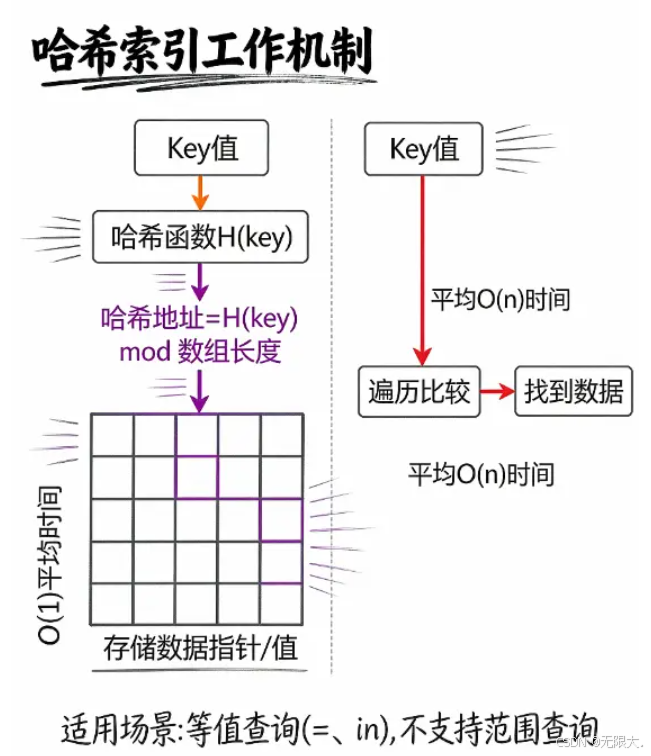
📦 哈希索引:快递柜的暴力美学
哈希索引就像快递柜,每个 key 都通过哈希函数计算出一个唯一编号,直接定位到存储位置。比如查询 id=100 的数据,哈希函数算出来是 8 号柜,直接拉开 8 号柜就能找到!
适用场景 :
- 等值查询(比如 WHERE id=100)⚡
- 键值对数据库(如 Redis)🚀
灵魂对比表格 👇
| 特性 | B+树索引 | 哈希索引 |
|---|---|---|
| 查找速度 | O(log n) 稳定 | O(1) 但有哈希冲突风险 |
| 范围查询 | ✅ 天生支持 | ❌ 完全不支持 |
| 排序 | ✅ 叶子节点链表天然有序 | ❌ 无序存储 |
| 内存占用 | 中等(可存磁盘) | 较高(通常内存存储) |
| 经典应用 | MySQL InnoDB 主键索引 | Redis、Memcached 键值存储 |
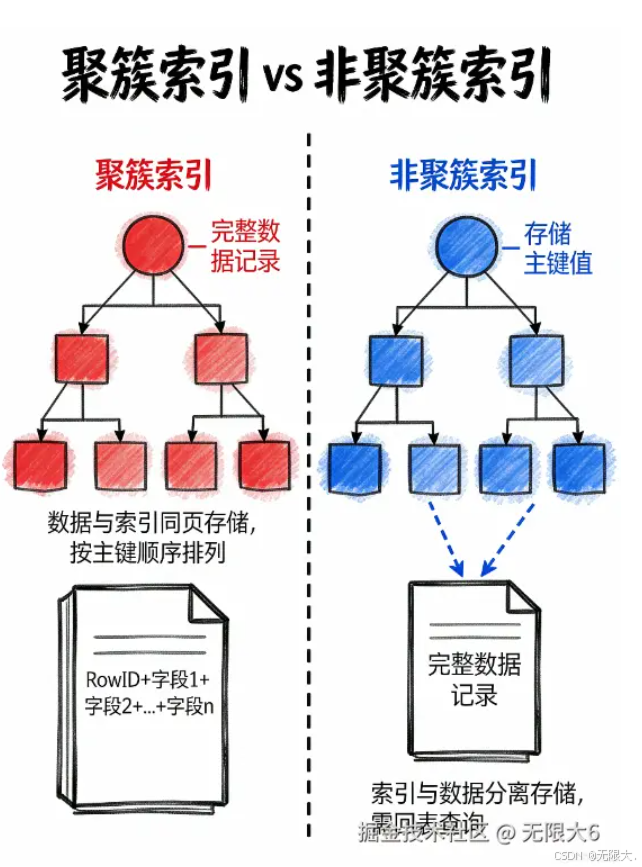
MySQL InnoDB 聚簇索引:叶子节点里藏着大秘密!
如果你用 MySQL 的 InnoDB 引擎,那你必须知道这个惊天大秘密 💣:
它的主键索引叶子节点直接存着整行数据!就像你查新华字典时,翻到 "数" 字不仅能看到拼音,还能直接把整页字典撕下来带走 📄。
聚簇索引 vs 非聚簇索引:冰箱 vs 储物柜
- 聚簇索引 (主键索引):就像家里的冰箱 🧊,门(索引)打开直接看到食物(数据),不用再跑一趟。
- 非聚簇索引 (二级索引):就像储物柜的标签 🏷️,上面写着"零食在冰箱第三层",你还得再去冰箱拿。
聚簇索引 B+树 根节点: 主键范围 1-1000 中间节点: 1-500 中间节点: 501-1000 叶子节点: 1-100, 包含整行数据 叶子节点: 101-200, 包含整行数据 ...更多叶子节点
实战:如何检测索引失效?
给大家分享一个我压箱底的索引失效检测 SQL 🕵️♂️,执行它就能知道查询有没有用到索引:
sql
EXPLAIN
SELECT * FROM books
WHERE title LIKE '%数据库%' -- 这个会失效
AND price > 50; -- 这个可能有效结果解读 👇:
-- 重点看 type 列:
-- ✅ ref/range/index:索引有用
-- ❌ ALL:全表扫描,索引失效!
避坑神技 ✨:如果必须用 %关键词% 模糊查询,可以考虑用 全文索引 :
sql
-- 创建全文索引
CREATE FULLTEXT INDEX idx_title_ft ON books(title);
-- 高效查询包含关键词的记录
SELECT * FROM books
WHERE MATCH(title) AGAINST('数据库' IN NATURAL LANGUAGE MODE);索引设计的三大灵魂拷问
- 是不是索引越多越好?
答:NO!索引像图书馆的分类架,太多了反而难找,而且每次增删改数据都要维护索引,就像每次新书入库都要重新贴标签 贴到崩溃。
- 主键为什么最好是自增 ID?
答:InnoDB 聚簇索引如果用随机 ID,会导致叶子节点频繁分裂,就像你整理好的书架忽然插进新书,整个架子都要重排 🗄️。
- 为什么不建议用 UUID 做主键?
答:UUID 是随机字符串,索引树会变成"歪脖子树" 🌳,查询效率暴跌!不信你试试给图书馆的书按 UUID 排序?
结语:索引不是银弹,但没有索引是真的完蛋
最后送大家一句我奶奶都能听懂的话:索引就像给自行车装变速器 🚲,平时通勤(简单查询)可能感觉不到,但遇到爬坡(复杂查询)时,有没有变速器直接是两个物种!
但记住,没有万能的索引设计,最好的实践是:用 EXPLAIN 分析 SQL,用监控工具观察慢查询,让数据告诉你答案 📊。
祝大家都能写出飞一般的 SQL,再也不用对着全表扫描掉头发!💇♂️💨
(如果觉得有用,记得点赞收藏哦~ 👇)