(1)索引概述
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查询算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。

索引的优点:
提高数据检索的效率,降低数据库的IO成本,通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
索引的劣势:
索引列也是要占用空间的,索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE时,效率也降低。
(2)索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:
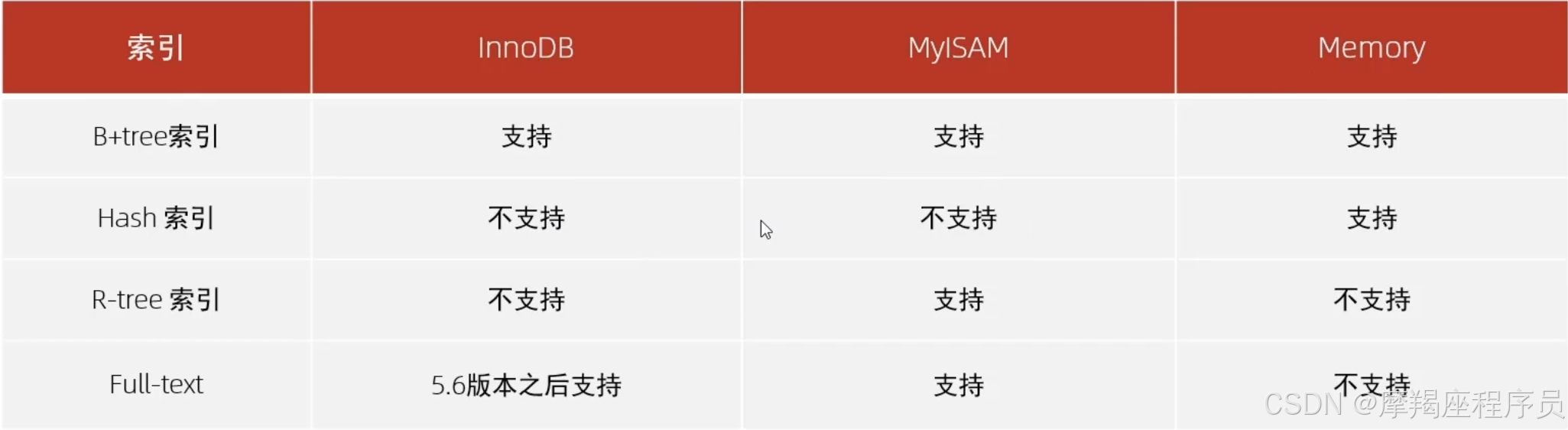
B+Tree索引:最常见的索引类型,大部分引擎都支持B+Tree索引
Hash索引:底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询
R-tree(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。
Full-text(全文索引):是一种通过建立倒排索引,快速匹配文档的方式。

二叉树缺点:顺序插入时,会形成一个链表,查询性能大大降低,大数据量情况下,层级较深,检索速度慢;
红黑树:大数据量情况下,层级较深,检索速度慢。
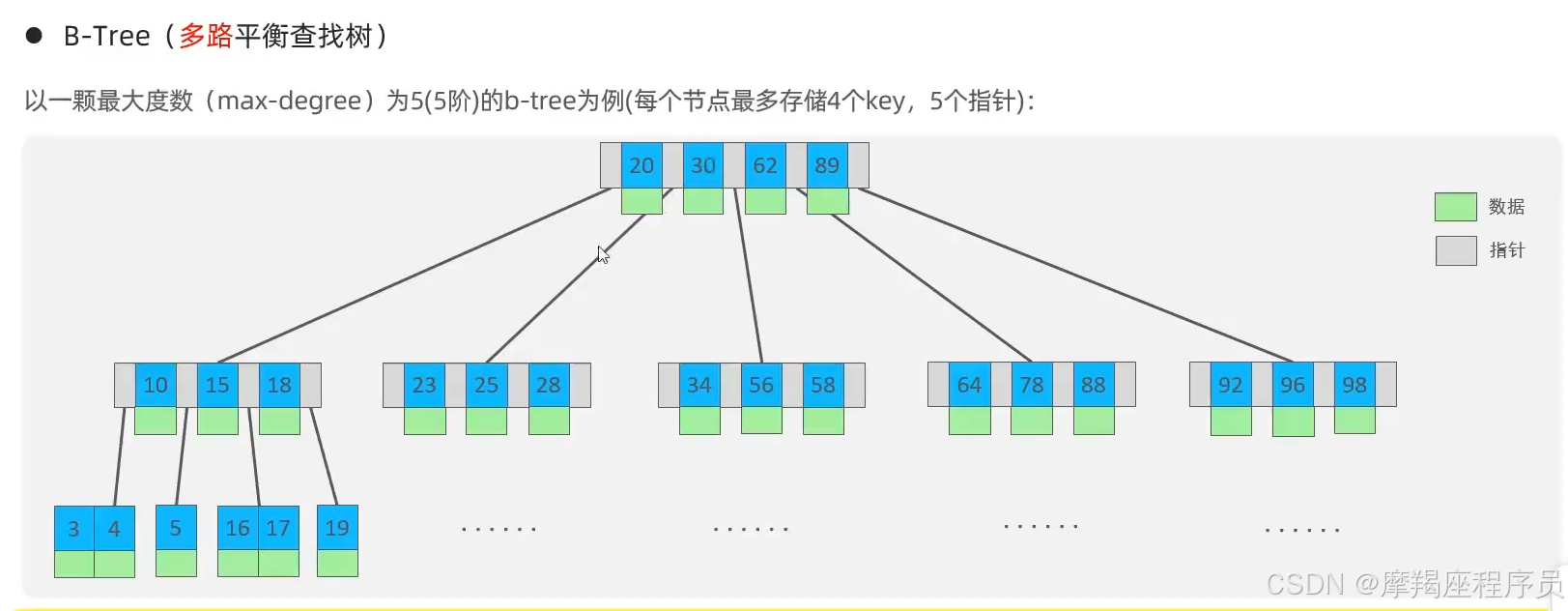
B-Tree(多路平衡查找树):以一颗最大度数(max-degree)为5(5阶)的B-Tree为例(每个节点最多存储4个key,5个指针)
B-Tree的演变过程
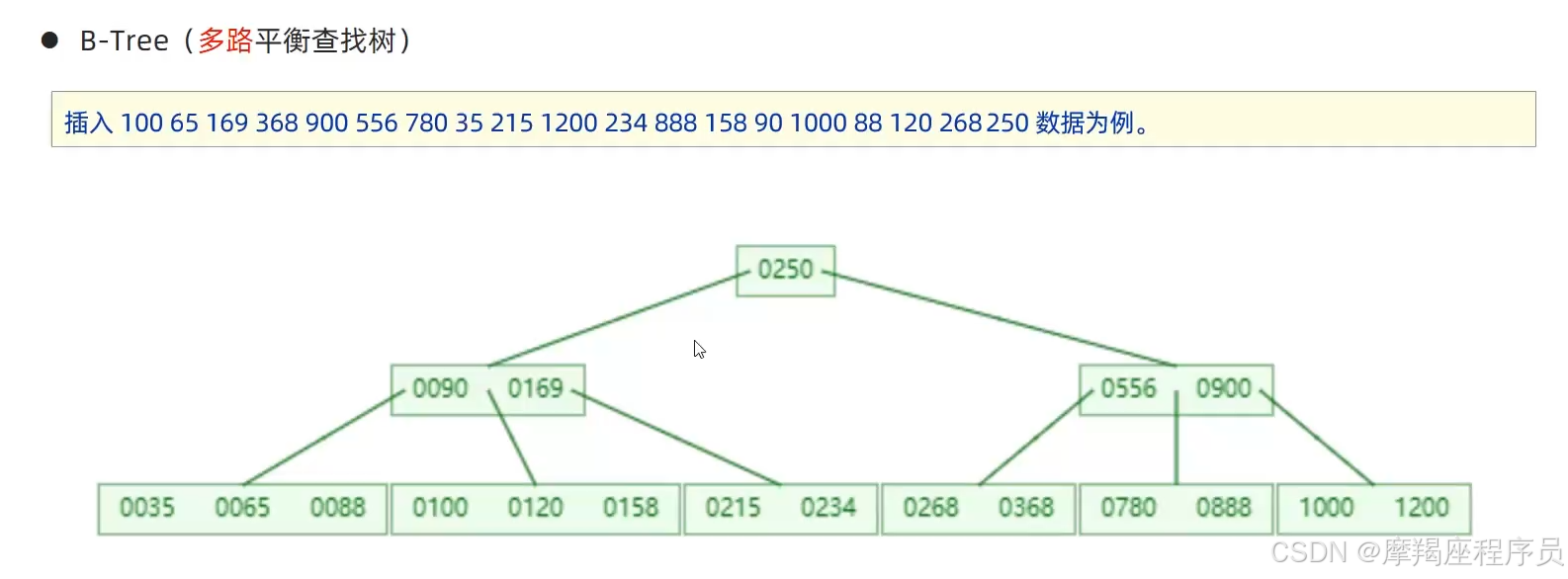
B-Tree的演变过程: https://www.cs.usfca.edu/~galles/visualization/BTree.html
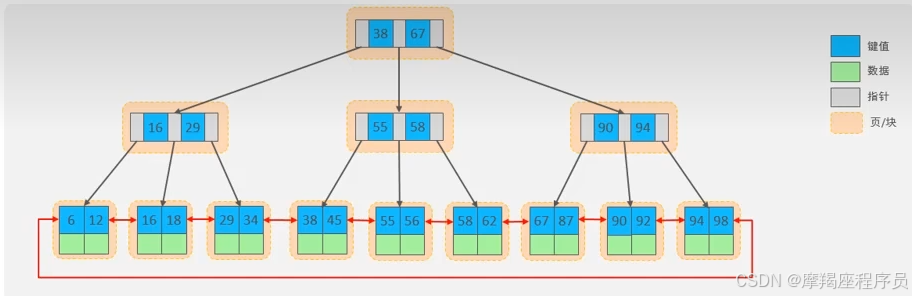
B+Tree:所有的元素都会存放在叶子节点;叶子节点形成一个单向链表;非叶子节点只起到索引的作用。
以一颗最大度数(max-degree)为4(4阶)的B+Tree为例
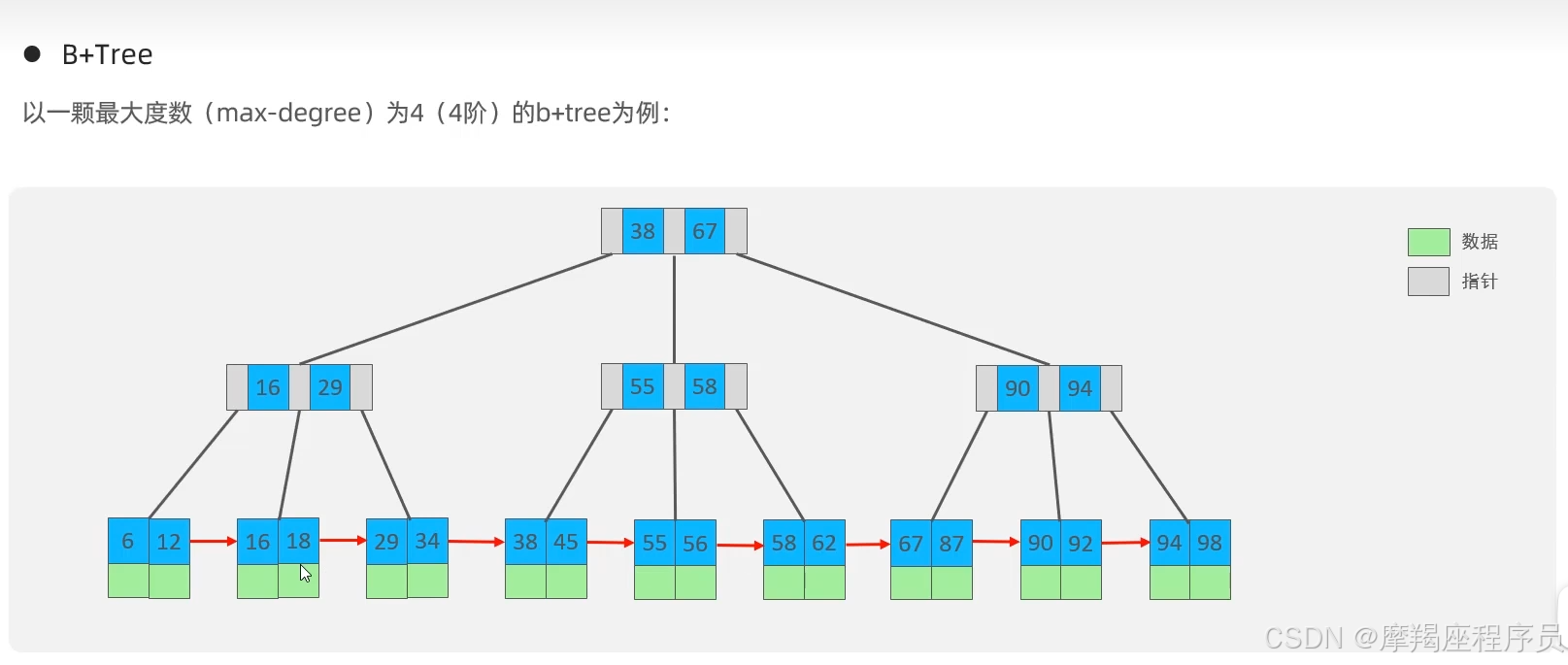
MySQL的B+Tree结构
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
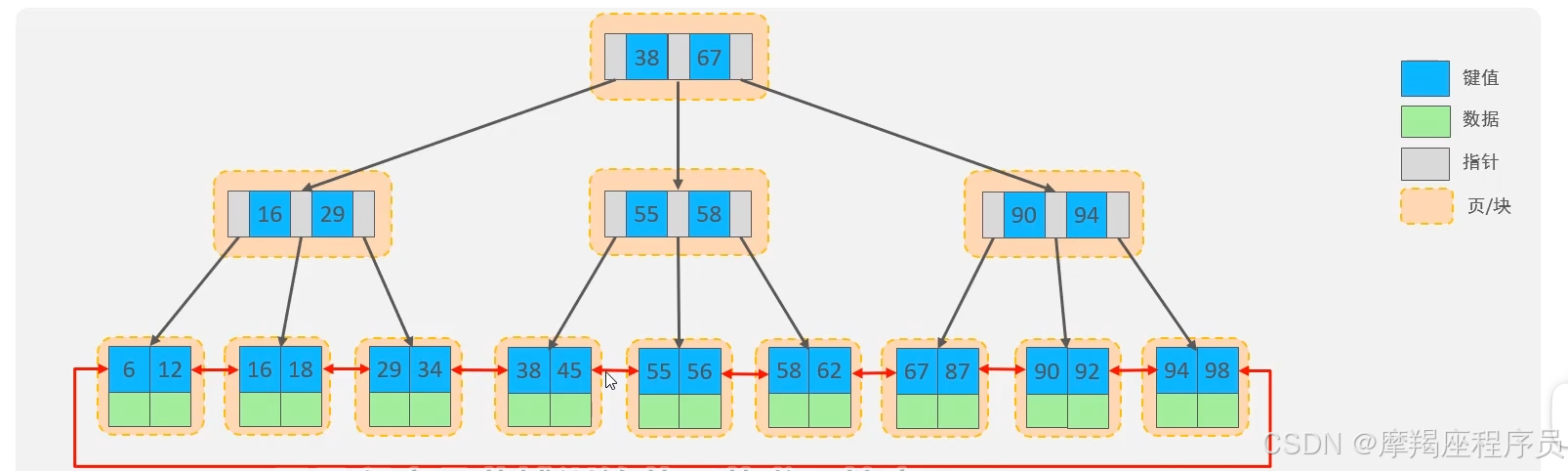
MySQL中,页的默认大小时16KB。
为什么InnoDB存储引擎选择使用B+Tree索引结构
(a)相对于二叉树,层级更少,搜索效率高;
(b)对于B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,
这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量
数据,只能增加树的高度,导致性能降低。
(c)相对Hash索引,B+Tree支持范围匹配和顺序操作。
(3)索引分类
主键索引:针对于表中主键创建的索引,默认自动创建,只能有一个;关键字:PRIMARY
唯一索引:避免同一个表中某数据列中的值重复,可以有多个;关键字:UNIQUE
常规索引:快速定位特定数据,可以有多个;
全文索引:全文索引查找的是文本中的关键词,而不是比较索引中的值,可以有多个。 关键字:FULLTEXT
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
聚集索引(Clustered Index)将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。必须有,而且只有一个。
二级索引(Secondary Index)将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键。可以存在多个。
聚集索引的选取规则:
(a)如果存在主键,主键索引就是聚集索引。
(b)如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
(c)如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
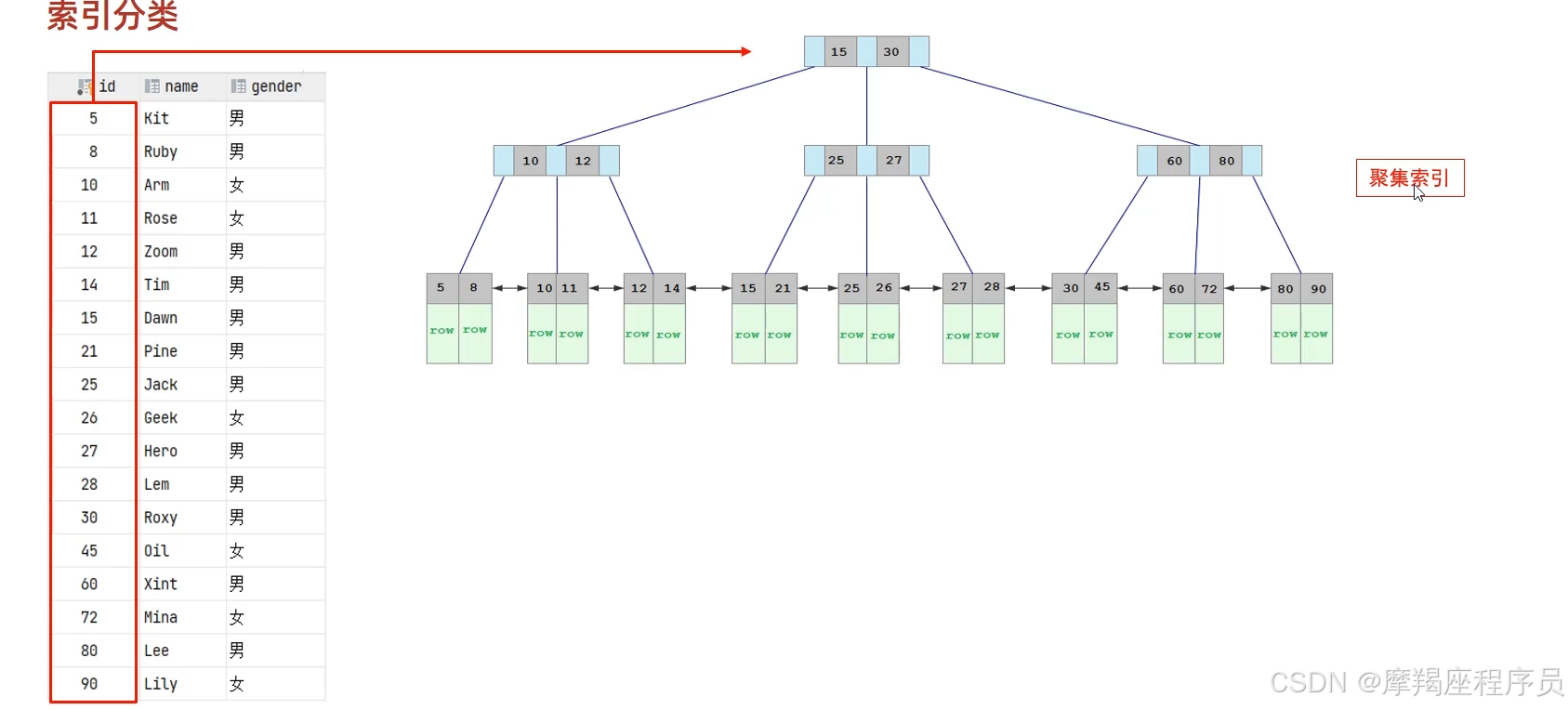
聚集索引的叶子节点保存的是行数据。
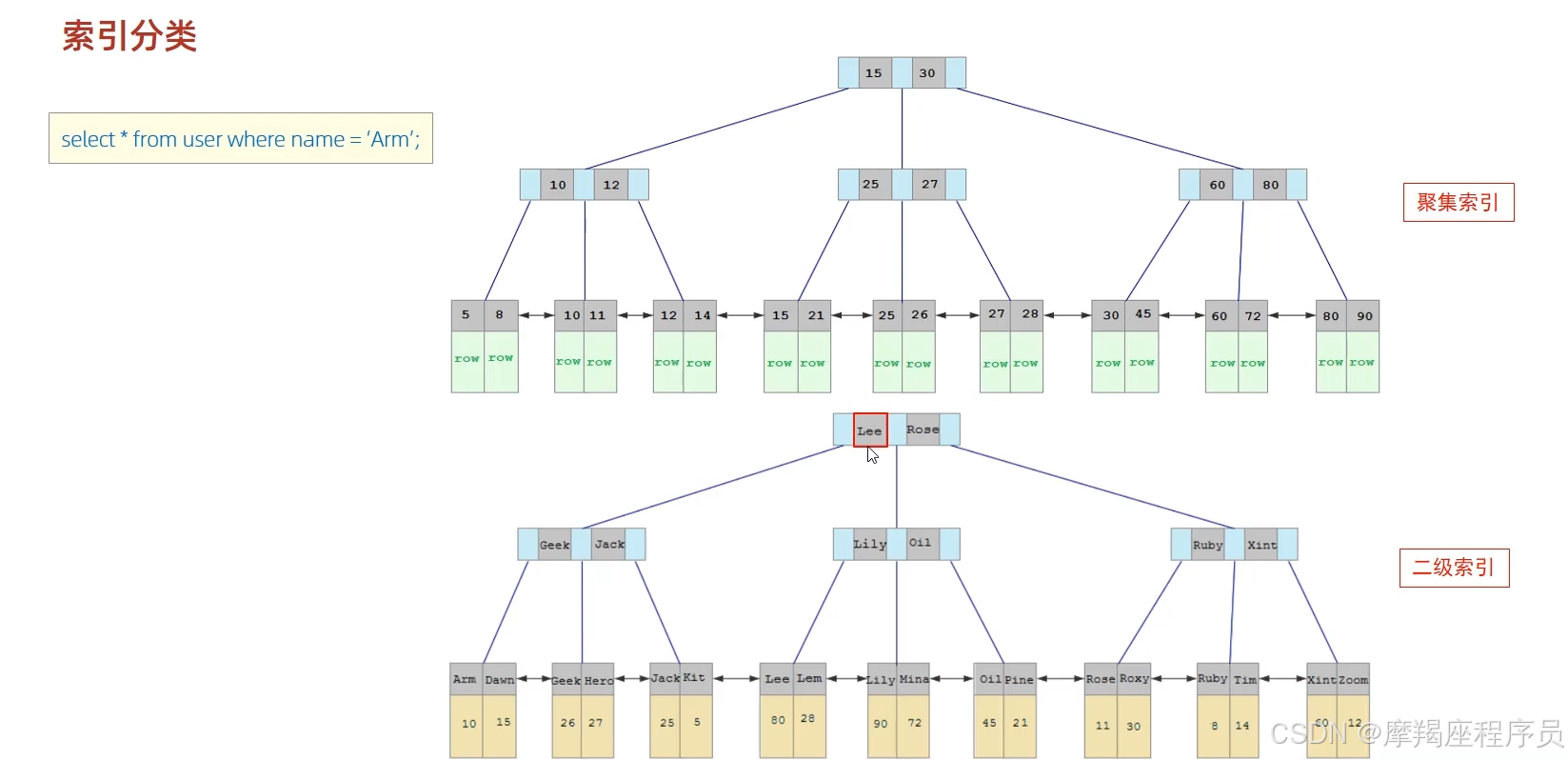
(a)以下SQL语句,哪个执行效率高
select * from user where id=10;
select * from user where name='Arm';
备注 id为主键,name字段创建的有索引;
(b)InnoDB主键索引的B+Tree高度为多高呢?
假设:一行数据大小为1k,一页中可以存储16行这样的数据,InnoDB的指针占用6个字节的空间,主键即使为bigint,占用字节数为8。
假设高度为2:
n*8+(n+1)*6=16*1024, 算出n约为1170; 所以有1171个指针;
可以存储的行数为: 1171 * 16 = 18736;
假设高度为3:
可以存储的行数为: 1171 * 1171 * 16 = 21939856
(4)索引语法
创建索引:
CREATE UNIQUE \| FULLTEXT INDEX index_name ON table_name(index_col_name, ...);
查看索引:
SHOW INDEX FROM table_name;
删除索引:
DROP INDEX index_name ON table_name;
表tb_user结构及数据如下:
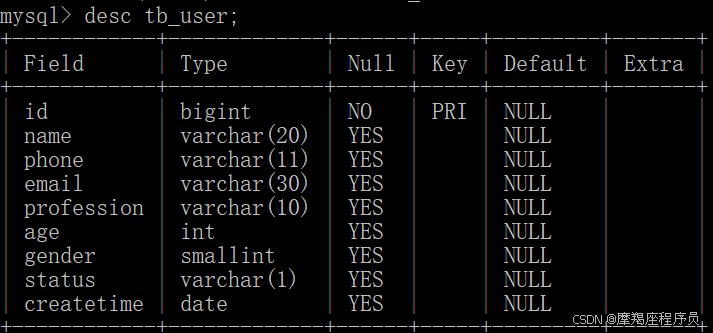
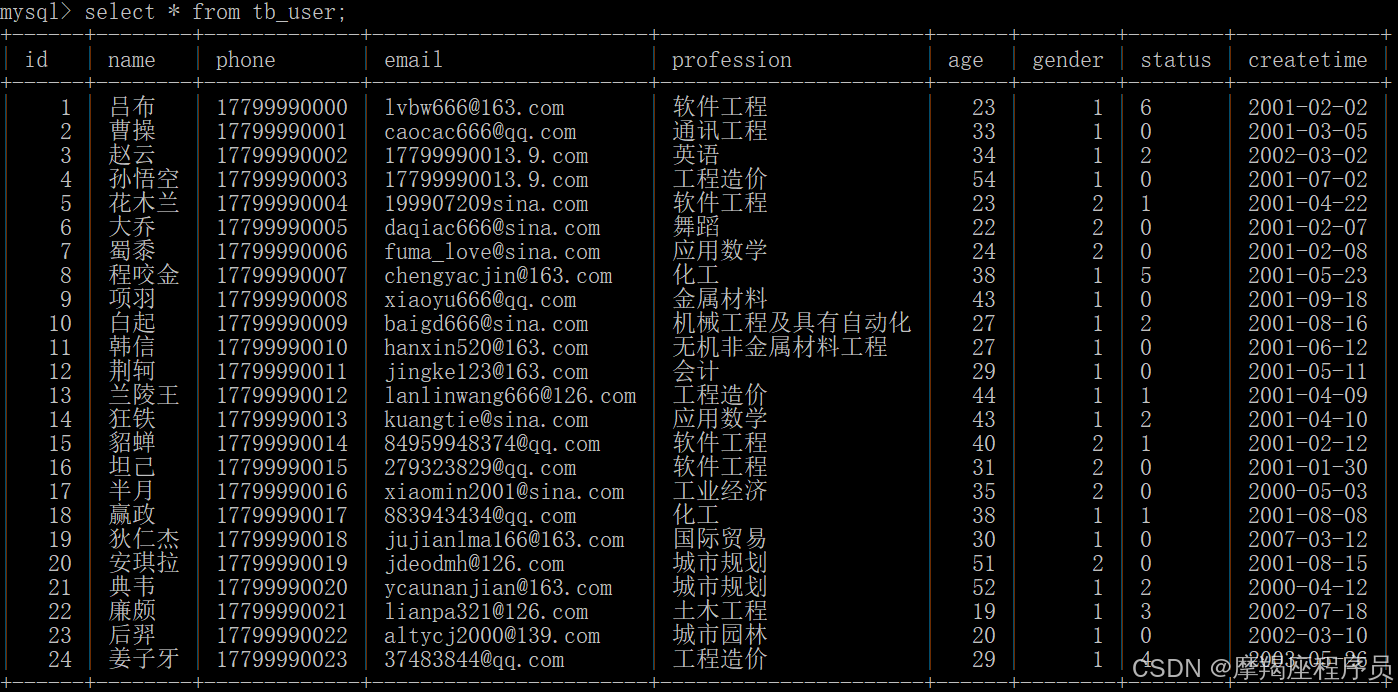
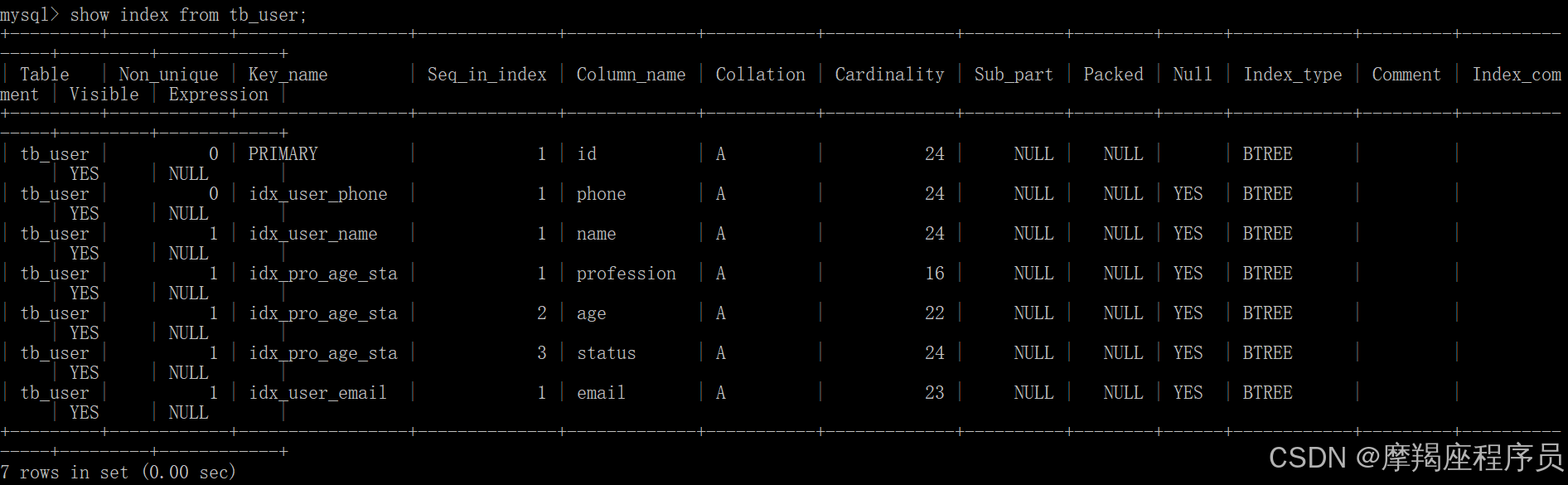
当前表中的索引:
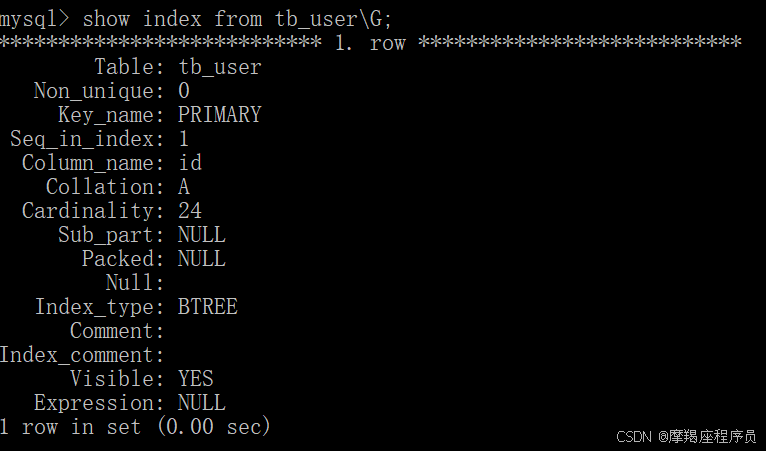
- name字段为姓名字段,该字段的值可能会重复,为该字段创建索引。
create index idex_user_name on tb_user(name);

创建之后,查看表中的索引:show index from tb_user;

- phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引。
create unique index idx_user_phone on tb_user(phone);

查看创建的索引 show index from tb_user;
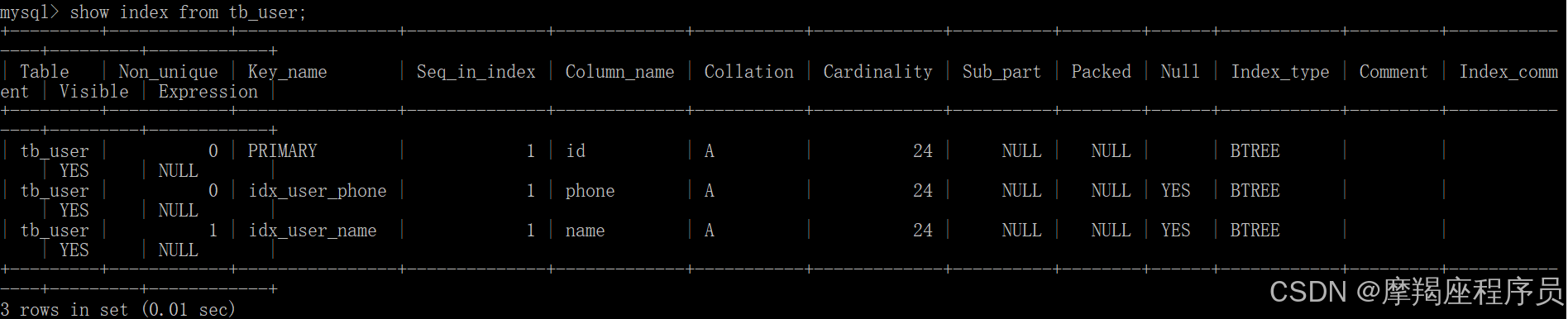
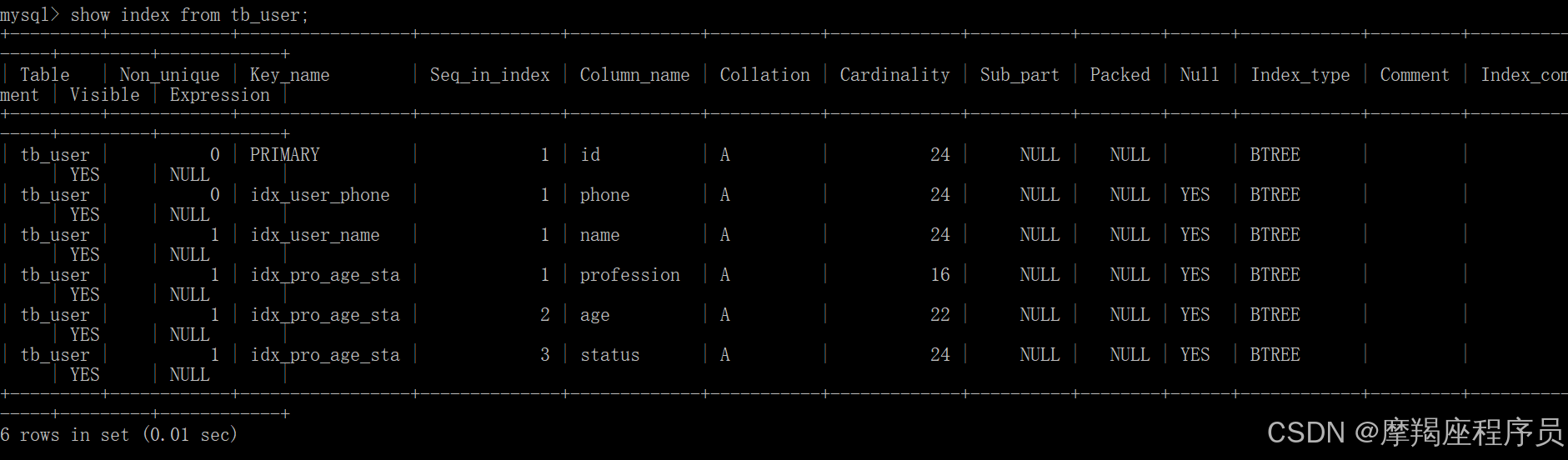
- 为profession、age、status创建联合索引。
create index idx_pro_age_sta on tb_user(profession, age, status);

查看创建就的索引: show index from tb_user;
- 为email建立合适的索引来提升查询效率。
create index idx_user_email on tb_user(email);

查看创建的索引: show index from tb_user;