Hadoop生态体系:
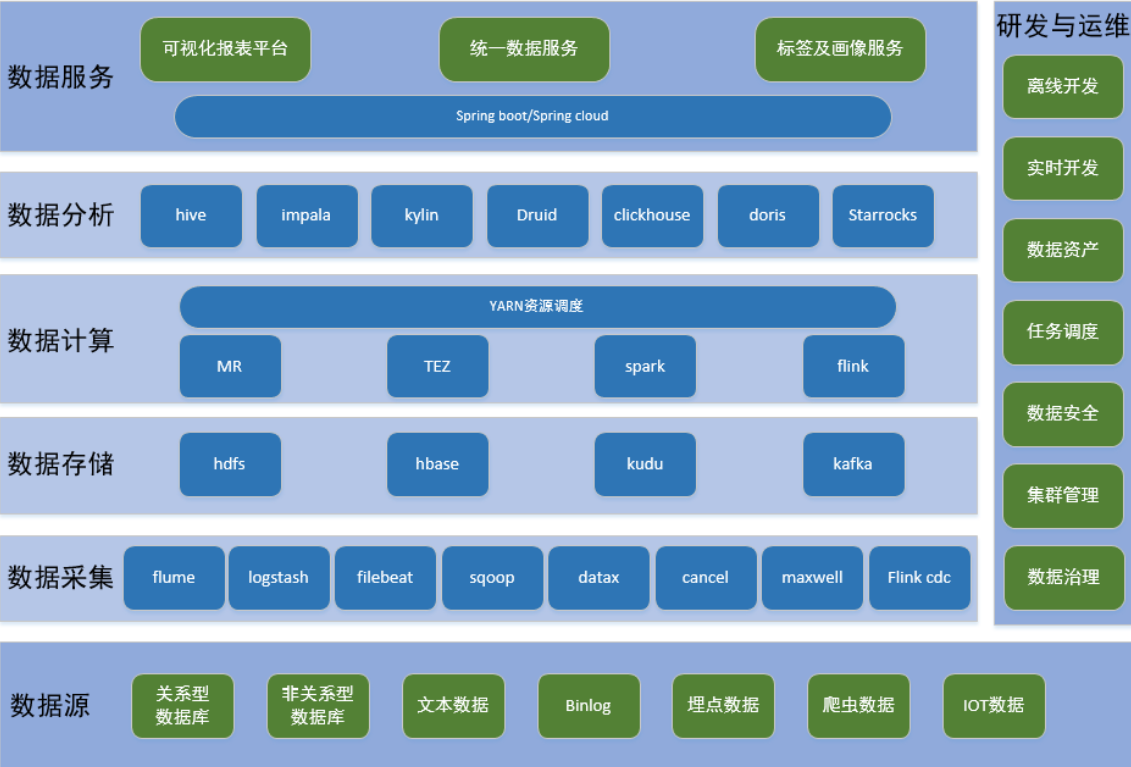
Hadoop
HDFS读写流程
读 
写 
MapReduce原理及其执行过程

shuffle归结为reduce阶段,map到reduce数据分发的过程叫做shuffle.shuffle是把我们map中的数据分发到reduce中去的一个过程.
YARN资源调度过程

ResourceManager
整个集群只有一个,负责集群资源的统一管理和调度,处理客户端请求,启动监控ApplicationMaster,监控NodeManager,资源分配与调度
NodeManager
整个集群存在多个,负责单节点资源管理与使用,处理来自ResourceManager的命令,处理来自ApplicationMaster的命令
ApplicationMaster
每一个应用有一个,负责应用程序的管理,数据切分,申请资源,任务监控,任务容错
Container
对任务环境的抽象
Hive
常见优化方案:
列裁剪
**读数据时只读查询所需需要的列--**hive.optimize.cp=true(默认值为真)
分区裁剪
**在查询过程中减少不必要分区的查询--**hive.optimize.pruner=true(默认值为真)
Join
在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。 因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。所以对于同一个 key 来说,对应的 value 值小的放前,大的放后,这便是"小表放前"原则。 若一条语句中有多个 Join,依据 Join 的条件相同与否,有不同的处理方法。
MapJoin
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。(hive.join.emit.interval = 1000 ,hive.mapjoin.size.key = 10000 ,hive.mapjoin.cache.numrows = 10000)
Group By
- Map端部分聚合
事实上并不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
- 有数据倾斜时进行负载均衡
此处需要设定 hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
- 是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
- 是否合并Reduce 端输出文件:hive.merge.mapredfiles=false(默认值为假)
- 合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
Spark
Spark任务调度机制
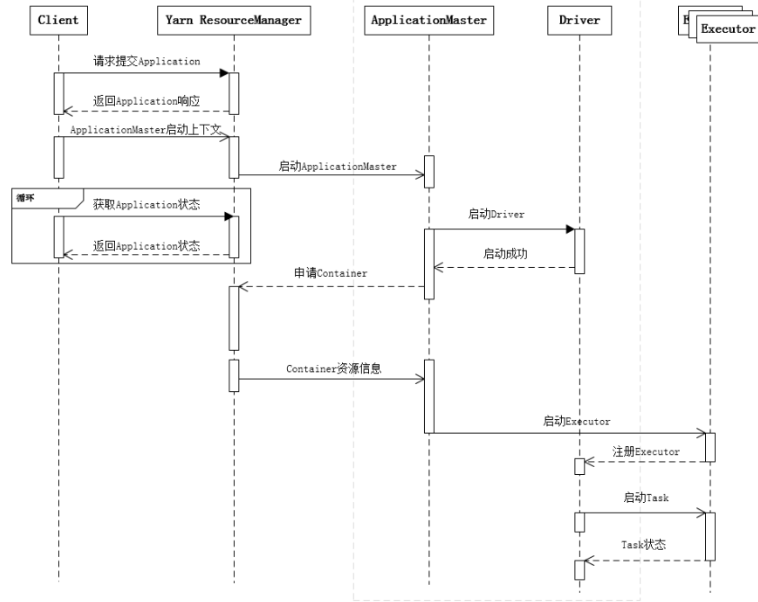
提交一个 Spark 应用程序,首先通过 Client 向 ResourceManager 请求启动一个
Application,同时检查是否有足够的资源满足 Application 的需求,如果资源条件满
足,则准备 ApplicationMaster 的启动上下文,交给 ResourceManager,并循环监控
Application 状态。
当提交的资源队列中有资源时,ResourceManager 会在某个 NodeManager 上启
动 ApplicationMaster 进程,ApplicationMaster 会单独启动 Driver 后台线程,当 Driver
启动后,ApplicationMaster 会通过本地的 RPC 连接 Driver,并开始向 ResourceManager
申请 Container 资源运行 Executor 进程(一个 Executor 对应与一个 Container),当
ResourceManager 返回 Container 资源,ApplicationMaster 则在对应的 Container 上启
动 Executor。
Driver 线程主要是初始化 SparkContext 对象,准备运行所需的上下文,然后一
方面保持与 ApplicationMaster 的 RPC 连接,通过 ApplicationMaster 申请资源,另一
方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲 Executor 上。
当 ResourceManager 向 ApplicationMaster 返 回 Container 资源时,
ApplicationMaster 就尝试在对应的 Container 上启动 Executor 进程,Executor 进程起
来后,会向 Driver 反向注册,注册成功后保持与 Driver 的心跳,同时等待 Driver
分发任务,当分发的任务执行完毕后,将任务状态上报给 Driver。
从上述时序图可知,Client 只负责提交 Application 并监控 Application 的状态。
对于 Spark 的任务调度主要是集中在两个方面: 资源申请和任务分发,其主要是通
过 ApplicationMaster、Driver 以及 Executor 之间来完成。
Spark常见数据倾斜优化方案
调整并行度分散同一个Task的不同Key
适用场景:大量不同的Key被分配到了相同的Task造成该Task数据量过大。
方案:Spark在做Shuffle时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的Key对应的数据被分配到了同一个Task上,造成该Task所处理的数据远大于其它Task,从而造成数据倾斜。如果调整Shuffle时的并行度,使得原本被分配到同一Task的不同Key发配到不同Task上处理,则可降低原Task所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。
自定义Partitioner
适用场景:大量不同的Key被分配到了相同的Task造成该Task数据量过大。
方案:使用自定义的Partitioner(默认为HashPartitioner),将原本被分配到同一个Task的不同Key分配到不同Task。
.groupByKey(new Partitioner() {
@Override
public int numPartitions() {
return 12;
}
@Override
public int getPartition(Object key) {
int id = Integer.parseInt(key.toString());
if(id >= 9500000 && id <= 9500084 && ((id - 9500000) % 12) == 0) {
return (id - 9500000) / 12;
} else {
return id % 12;
}
}
})
将Reduce side Join转变为Map side Join
适用场景:参与Join的一边数据集足够小,可被加载进Driver并通过Broadcast方法广播到各个Executor中。
方案:在Java/Scala代码中将小数据集数据拉取到Driver,然后通过broadcast方案将小数据集的数据广播到各Executor。或者在使用SQL前,将broadcast的阈值调整得足够多,从而使用broadcast生效。进而将Reduce侧Join替换为Map侧Join
为skew的key增加随机前/后缀
适用场景:两张表都比较大,无法使用Map则Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀
方案:将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join并去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
大表随机添加N种随机前缀,小表扩大N倍
适用场景:一个数据集存在的倾斜Key比较多,另外一个数据集数据分布比较均匀。
方案:如果出现数据倾斜的Key比较多,上一种方法将这些大量的倾斜Key分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍)