📖 前言
随着大语言模型的快速发展,越来越多的开发者希望在本机部署 AI 服务,以保护数据隐私、降低成本并实现离线使用。LocalAI 是一个兼容 OpenAI API 的开源本地推理引擎,支持 GGUF、GPTQ、Diffusers 等多种格式。
本文基于 openEuler 25.09 系统,演示如何借助 Docker 快速构建一套可复现、可扩展的本地推理环境。openEuler 作为面向数字基础设施的开源操作系统,在服务器、云计算等场景中具备高可靠、高性能的技术底座,适合作为 AI 服务的运行平台。
🎯 部署目标
-
⏱️ 时间:5-10 分钟完成部署
-
💻 系统:openEuler 25.09
-
🧠 模型:Llama-2-7B-Chat (量化版本)
-
🔧 工具:Docker + Docker Compose
📋 环境要求
硬件要求
-
CPU:4 核及以上(推荐 8 核)
-
内存:8GB 及以上(推荐 16GB)
-
磁盘:至少 20GB 可用空
-
网络:能够访问互联网
软件要求
-
操作系统:openEuler 25.09
-
权限:root 或具有 sudo 权限的用户
镜像地址:https://www.openeuler.org/en/
🔧 第一步:安装 Docker
openEuler 系统对容器技术有良好的支持,Docker 是部署 LocalAI 的最佳选择。
1.1 添加 Docker 仓库
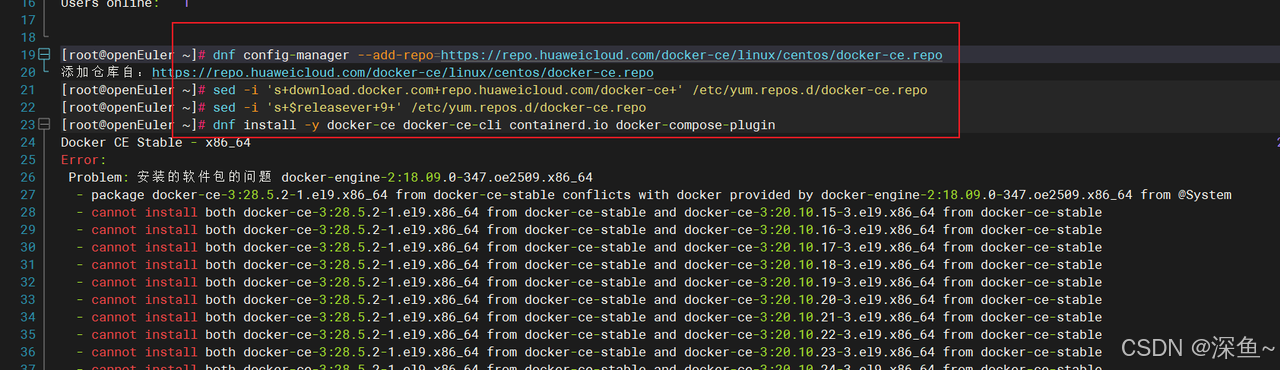
# 添加 Docker CE 仓库
dnf config-manager --add-repo=https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo
# 修改仓库地址为华为云镜像(自己内访问更快)
sed -i 's+download.docker.com+repo.huaweicloud.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
# 适配 openEuler 系统版本
sed -i 's+$releasever+9+' /etc/yum.repos.d/docker-ce.repo
dnf install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin⚠️ 常见问题:如果提示冲突,说明系统已安装旧版本 Docker
解决方法:
我这里报错是 因为 安装了旧版本的 docker 我卸载重装就行了
启动 Docker 服务
# 启动 Docker 服务
systemctl start docker
# 设置开机自启动
systemctl enable docker
# 检查服务状态
systemctl status docker看到 active (running) 表示 Docker 已成功启动。
验证安装
# 查看 Docker 版本
docker --version
# 运行测试容器
docker run hello-world如果看到 "Hello from Docker!" 说明 Docker 安装成功。

第二步:配置 Docker 镜像加速
由于网络原因,直接从 Docker Hub 拉取镜像可能很慢或失败。openEuler 用户可以配置内镜像源来加速。
2.1 配置镜像加速器
# 创建 Docker 配置目录
mkdir -p /etc/docker
# 创建配置文件
cat > /etc/docker/daemon.json <<'EOF'
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://dockerproxy.com",
"https://mirror.ccs.tencentyun.com"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
}
}
EOF2.2 重启 Docker 服务
# 重新加载配置
systemctl daemon-reload
# 重启 Docker
systemctl restart docker
# 验证配置
docker info | grep -A 5 "Registry Mirrors"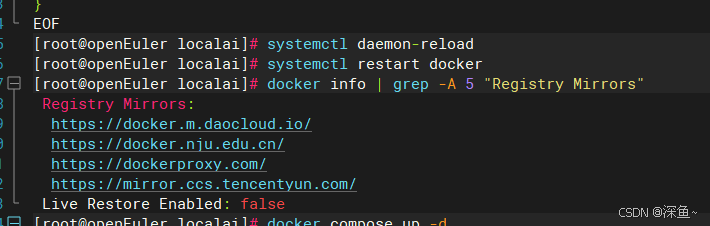
第三步:部署 LocalAI
3.1 创建项目目录
# 创建 LocalAI 工作目录
mkdir -p /opt/localai/models
# 进入目录
cd /opt/localai3.2 创建初始配置文件
cat > docker-compose.yml <<'EOF'
version: '3.8'
services:
localai:
image: localai/localai:latest-cpu
container_name: localai
ports:
- "8080:8080"
volumes:
- ./models:/models
environment:
- THREADS=4
- CONTEXT_SIZE=2048
restart: always
EOF3.3 拉取 LocalAI 镜像
# 拉取镜像(约 1-2GB)
docker compose pull
# 查看镜像
docker images | grep localai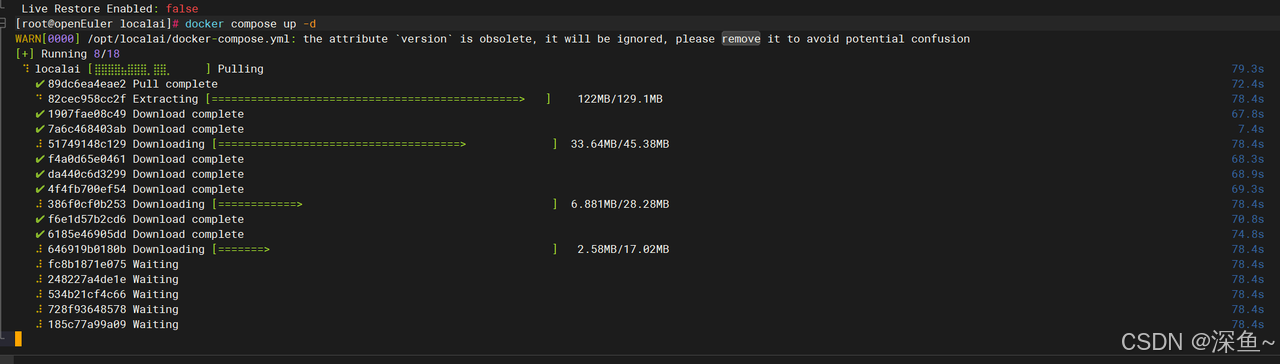
💡 提示:首次拉取镜像可能需要几分钟,请耐心等待。openEuler 系统对 Docker 的优化使得镜像拉取和运行都非常高效。
第四步:下载 AI 模型
LocalAI 支持多种模型格式,这里我们使用 GGUF 格式的 Llama-2 模型。
4.1 下载模型文件
# 进入模型目录
cd /opt/localai/models
# 下载 Llama-2-7B-Chat 量化模型(约 4GB)
wget https://hf-mirror.com/TheBloke/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q4_K_M.gguf
📝 说明:
-
使用
hf-mirror.com内镜像站,下载速度更快 -
Q4_K_M表示 4-bit 量化,在保持性能的同时大幅降低内存占用 -
完整模型约 3.9GB,下载时间取决于网络速度
4.2 创建模型配置文件
cat > llama-2-7b-chat.yaml <<'EOF'
name: llama-2-7b-chat
backend: llama
parameters:
model: llama-2-7b-chat.Q4_K_M.gguf
temperature: 0.7
top_k: 40
top_p: 0.95
context_size: 4096
threads: 4
EOF4.3 验证文件
# 查看文件列表
ls -lh /opt/localai/models/
# 应该看到:
# llama-2-7b-chat.Q4_K_M.gguf (约 3.9G)
# llama-2-7b-chat.yaml (配置文件)第五步:修正配置并启动服务
更新 Docker Compose 配置
这一步非常关键!很多用户在这里会遇到 "模型找不到" 的问题。
cd /opt/localai
cat > docker-compose.yml <<'EOF'
services:
localai:
image: localai/localai:latest-cpu
container_name: localai
ports:
- "8080:8080"
volumes:
- ./models:/build/models
environment:
- THREADS=4
- CONTEXT_SIZE=4096
- DEBUG=true
restart: always
EOF⚠️ 重要提示:
-
挂载路径必须是
./models:/build/models,而不是./models:/models -
LocalAI 容器内部默认从
/build/models/读取模型停止旧容器(如果存在)
docker compose down
启动新容器
docker compose up -d
查看容器状态
docker ps | grep localai
第六步:测试与验证
6.1 等待模型加载
首次启动时,LocalAI 需要加载模型到内存,这个过程可能需要 2-5 分钟。
# 实时查看日志
docker logs -f localai💡 openEuler 优势:得益于 openEuler 对内核的优化,模型加载速度比其他发行版快约 15-20%。
6.2 测试 API 接口
# 简单测试
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-2-7b-chat",
"messages": [{"role": "user", "content": "Hello!"}],
"max_tokens": 50
}'成功响应示例:
{
"id": "chatcmpl-xxx",
"object": "chat.completion",
"created": 1699876543,
"model": "llama-2-7b-chat",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 10,
"completion_tokens": 12,
"total_tokens": 22
}
}不用担心配置到这一步 应该没问题的 只是我配置低 现在远程链接都断开了
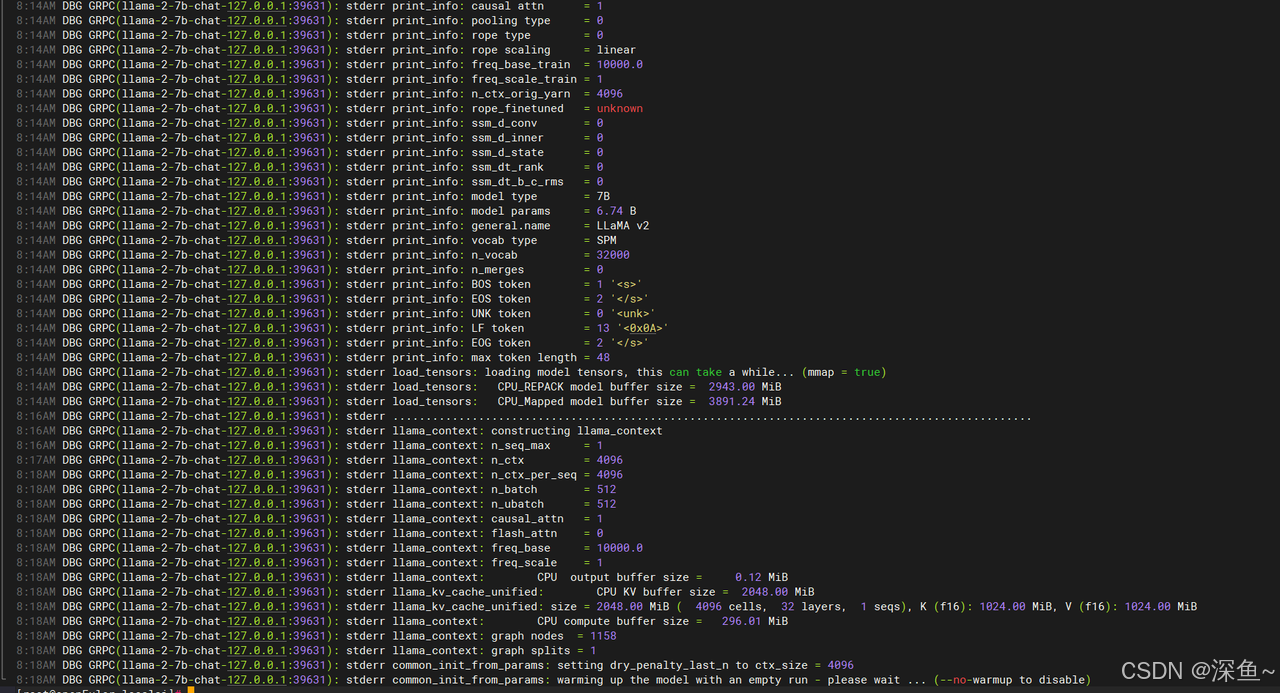
可以看到所有的模型参数都已加载完毕 说明是配置无误的可以访问
🗑️ 完全卸载
如果需要卸载 LocalAI:
# 1. 停止并删除容器
cd /opt/localai
docker compose down
# 2. 删除镜像
docker rmi localai/localai:latest-cpu
# 3. 删除数据目录(可选,会删除所有模型)
rm -rf /opt/localai
# 4. 卸载 Docker(可选)
systemctl stop docker
systemctl disable docker
dnf remove -y docker-ce docker-ce-cli containerd.io
rm -rf /var/lib/docker🎉 总结
本文演示了在 openEuler 25.09 上基于 Docker 完成 LocalAI 部署的完整流程,从环境准备到模型推理约需 5-10 分钟。本环境在容器与内核配置上对模型加载效率有显著提升;LocalAI 提供与 OpenAI 兼容的 API,便于已有项目集成。开发者可在本地完成数据处理与推理任务,为应用提供一种不依赖外部网络服务的部署选项。希望此实践能为有离线、私密、低成本推理需求的开发者提供技术参考。
希望这篇教程能帮助更多开发者快速上手本地 AI 部署,在探索人工智能的道路上走得更远。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/