量化前言
随着人工智能大模型的迅速演进,模型参数规模呈指数级增长,主流模型已从最初的百万级、亿级扩展到数十亿乃至千亿级。虽然模型规模的扩大显著提升了模型的理解与生成能力,但也带来了更高的计算成本、更大的存储开销以及部署的巨大压力。
在常规实现中,大模型的参数与中间计算通常采用 FP32 或 FP16 等浮点数精度来表示。浮点精度具有较高的表达能力,但其存储空间大、运算能耗高,对计算硬件(如 GPU、NPU)的带宽和算力提出了极高要求。当模型规模达到十亿级以上时,仅权重存储就可能需要数10GB,推理过程中频繁的访存更容易使系统陷入带宽瓶颈,导致推理速度受限、能耗显著增加。
在此背景下,如何在保持模型性能的前提下降低模型的计算与存储成本,成为大模型工程实践中的核心议题。**模型量化(Model Quantization)**应运而生,成为当前工业界和学术界最重要的模型压缩与加速技术之一。
量化的核心思想是:
用低比特的定点整数去近似原始的高比特浮点数,通过适当的量化策略在精度损失可控的前提下,显著降低模型体积与推理成本。
量化不仅可以将模型的存储占用减少 2~8 倍,还能结合硬件的整数算子显著提升推理吞吐量与能效,因而成为大模型在云端与边缘设备部署过程中广泛采用的关键技术手段。
为什么要量化
进行模型量化的根本原因可以概括为三点:
- 让模型更轻:减小体积,降低存储和加载开销;
- 让推理更快:缓解带宽瓶颈,利用硬件整数算子加速计算;
- 让部署更划算:在有限的硬件资源下,支持更多模型实例和更多用户。
以下继续详细的展开。
量化可以减小模型体积,降低存储和加载开销
量化通过用更少的比特表示参数,可以显著压缩模型大小。
- 例如:将权重从 16 位(FP16)压缩到 8 位(INT8),理论上模型体积可减少约 50%;
- 如果是从 FP16 压到 INT4,仅权重部分的体积最多可以缩小到原来的 1/4。
体积变小的直接好处是:
- 模型可以存放在更多类型的设备上(包括显存较小的 GPU/NPU 或本地服务器);
- 模型加载时间更短,服务启动更快,滚动升级也更方便。
量化可以提升推理性能,缓解带宽和算力瓶颈
在大模型推理中,很多时候真正拖慢速度的不是算力,而是带宽:
- 每次前向传播要从显存 / HBM / NPU 内存中读取大量权重;
- 权重越大,访存越频繁,带宽越容易成为瓶颈。
量化后:
- 单次需要读取的权重数据量变小,同样带宽下可以承载更多计算;
- 很多硬件(GPU/NPU)对 INT8/INT4 乘加有专门的加速指令,矩阵运算本身也会变快;
- 在实际工程中,常能获得 1.5~4 倍不等的推理加速(视模型规模、位宽与硬件而定)。
量化可以降低推理成本,提升并发与利用率
对于云端服务或社区平台而言,成本往往和以下因素直接相关:
- 单模型占用的显存 / NPU 资源;
- 每秒可处理的请求数(QPS);
- 能耗与设备折旧。
量化之后:
- 同一块 NPU/GPU 上可以同时部署更多个模型实例 ,或者同一个模型允许更高的并发会话数;
- 单请求的推理时间下降,可以服务更多用户 → 单位时间摊薄成本;
- 整体能耗下降,有利于长期运行的商业化服务。
对一个需要服务大量用户的大模型社区来说,量化意味着:
用同样的硬件支持更多用户,用更低的成本支撑同样的体验。
什么是量化
模型量化(Quantization)本质是:用更低比特的整数去近似原始的高精度浮点数,以减少模型的存储和计算成本,同时尽可能保持模型性能。
量化的核心思想:把"高精度数字"替换为"更轻的数字"
在深度学习中,权重和激活通常用 FP32/FP16 浮点表示。量化的核心,就是将这些浮点值映射到低比特整数(例如 INT8、INT4),再按照 scale 和 zero-point 还原为近似值。
这样做的目标是:让同一组参数用更少的空间表示,并降低计算量。
在实际大模型中,量化可以作用在不同类型的张量上,常见的包括:
- 权重量化(Weights) :
对模型的参数矩阵做低比特表示,是当前大模型最核心、最常用的量化对象。 - 中间激活量化(Activations) :
对前向计算过程中的中间输出进行量化,用于进一步降低带宽与算力开销。 - KV Cache 量化(KV Cache) :
对注意力机制中的 Key / Value 缓存进行量化,属于激活量化的一种,但在长上下文大模型中影响巨大,通常会单独作为一个重要方向讨论。 - 其他张量量化 :
如输入/输出 embedding、logits 等,也可以根据需求进行量化以进一步节省存储或带宽。
从概念上看,权重以外的这些对象都可以视为"广义的激活",但在工程上我们会对 KV Cache 等关键部分做更细粒度的区分与优化。
量化的实现方式:PTQ 与 QAT
训练后量化(PTQ)
-
不需要训练;
-
直接对浮点模型进行量化;
-
成本低,是当前大模型最广泛使用的方式(W8、W4 等)。
量化感知训练(QAT)
-
在训练中模拟量化误差,让模型适应低比特表达;
-
精度更好,但训练成本高。
本次量化实操的目标,是带领大家在真实的昇腾 NPU 环境中使用华为的配套工具msmodelslim,完整走一遍从"浮点大模型 → 量化模型 → 推理验证"的工程化流程。我们选用当前主流的大语言模型作为示例,通过训练后量化(PTQ)的方式,将模型压缩为更轻、更快、部署成本更低的版本。
本次我们量化实操介绍
本次实操的核心任务:完成一次完整的 W8A8 量化流程
在本次课程中,我们将以 W8A8(权重 8bit,激活 8bit)量化 为主要范式,演示以下内容:
- 准备环境与基础模型
- 在魔乐社区创建带昇腾 NPU 的运行空间;
- 配置必要的软件环境(CANN、msModelSlim、vLLM-Ascend 等);
- 下载待量化的浮点模型作为基线。
- 编写量化配置并执行 PTQ 量化
- 编写量化配置文件(如指定权重/激活位宽、分组粒度、禁用量化的敏感层等);
- 使用 msModelSlim 对模型进行一键量化;
- 生成量化后的权重文件与量化描述文件。
- 加载量化模型并启动推理服务
- 使用 vLLM-Ascend 或相关推理框架启动量化后的模型服务;
- 通过简单请求验证模型输出是否正常;
- 确认量化权重已被推理框架正确使用。
- 进行量化精度与性能评估
- 使用如 ais_bench 的评估工具运行标准数据集;
- 对比量化前后的精度、推理速度与显存占用;
- 分析量化对模型效果和性能的影响。
本次实操的最终目标与预期收获
完成整个实操后,大家将能够:
- 理解 W8A8 量化的基本流程与注意事项;
- 掌握如何使用 msModelSlim 对大模型进行工程化量化;
- 能够在昇腾 NPU 上加载并运行量化模型;
- 学会对量化模型做性能与精度评估;
- 初步具备将大模型投入生产部署的能力。
换句话说,本次实操不仅让大家"知道什么叫量化",更让大家"真正动手完成一次量化工程",为后续更低比特(如 W4、混合精度)量化打下基础。
环境准备
本次量化的实践是在魔乐社区上,所以我们需要按照魔乐社区上已有的环境进行量化,在开始量化前我们需要在魔乐社区上配置好环境。在魔乐社区选择合适的镜像创建体验空间,注意选择NPU算力资源,基础镜像选择vllm:openeuler-python3.9-cann8.2.RC1-openmind1.0.0,接入SDK选择Application,许可证选择的是apache-2.0。
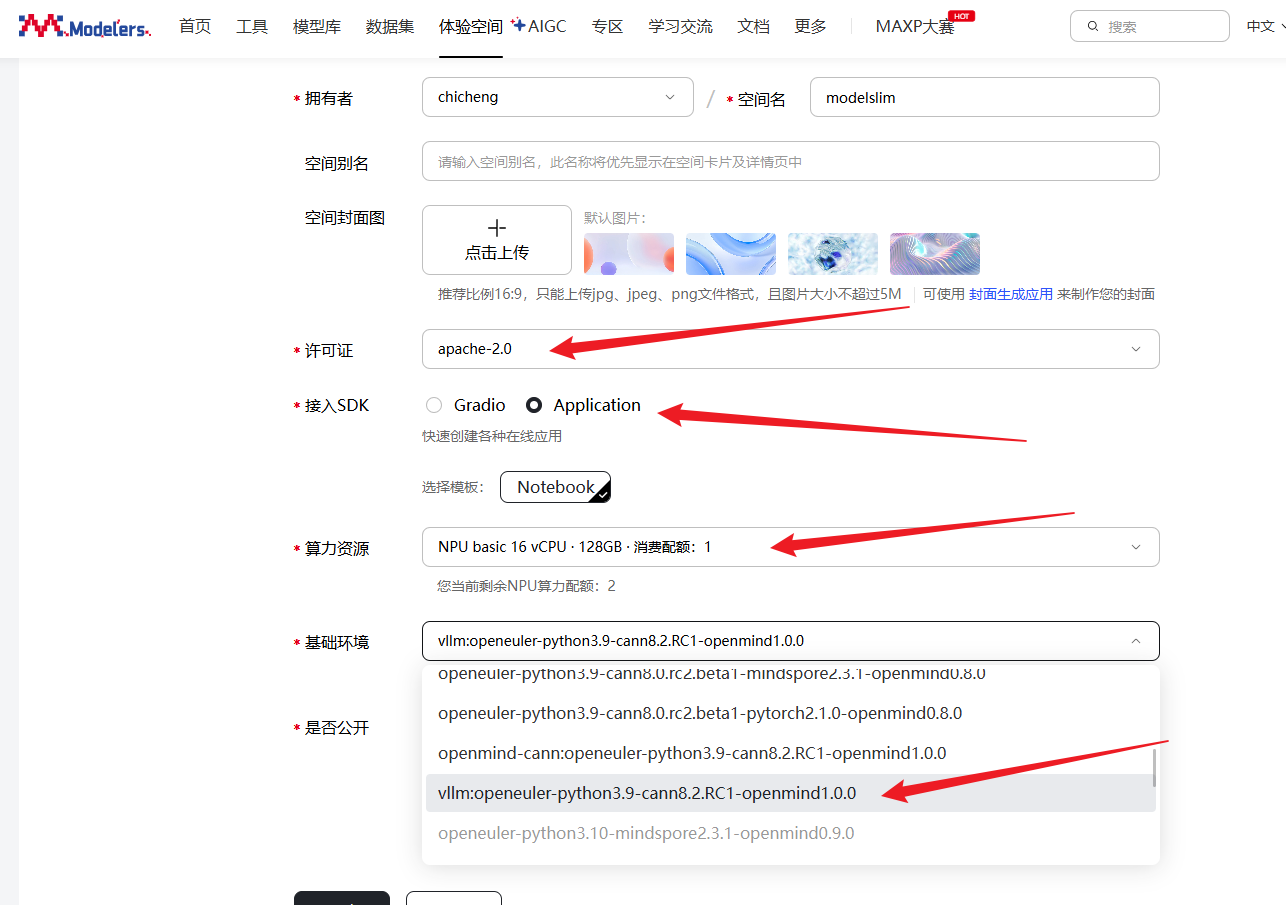
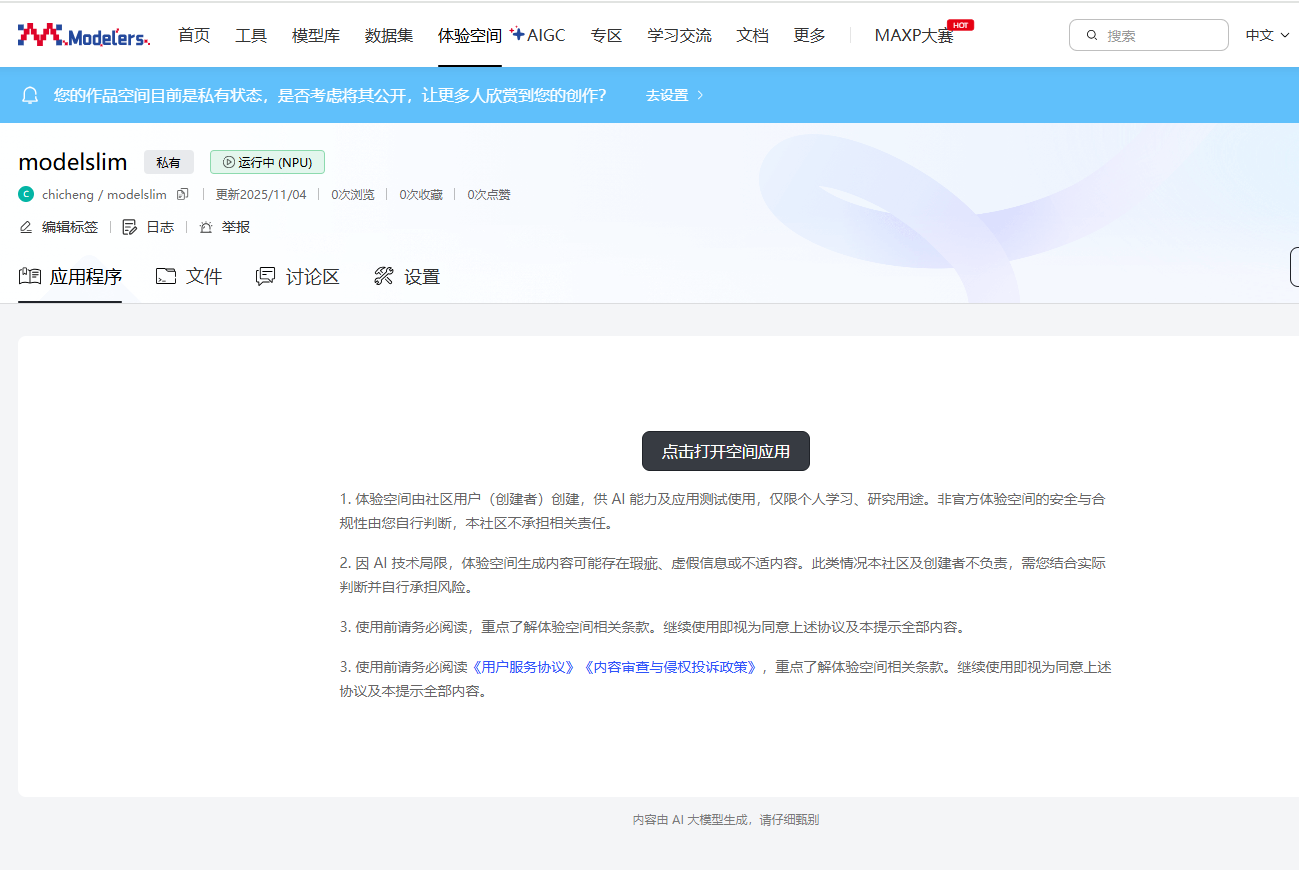
配置完体验空间后,等待镜像容器构建完成并启动后,在应用程序界面点击打开空间应用,输入界面提示的令牌即可进入jupyter lab。
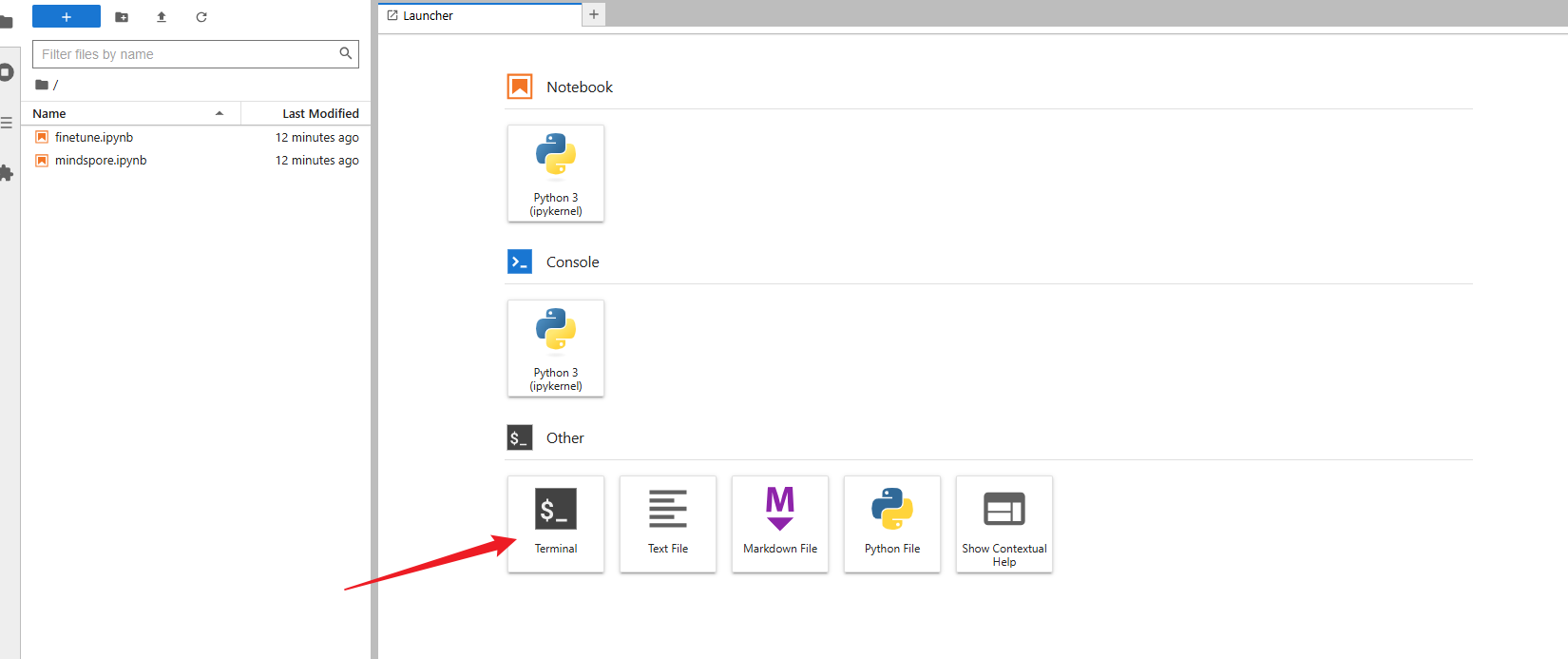
我们在jupyter lab中新建一个终端,除了文件上传下载操作,后续其他所有操作均在终端中进行。
设置当前软件终端的开发环境,注意每一次开新的终端都需要配置一次开会环境,也就是运行一下的内容:
shell
#设置昇腾AI处理器的基础开发环境
source ~/Ascend/ascend-toolkit/set_env.sh
#设置ASD-SIP环境
source ~/Ascend/nnal/asdsip/set_env.sh
#设置ATB环境
source ~/Ascend/nnal/atb/set_env.sh大模型量化
msModelslim工具介绍
本次我们使用的量化工具是msModelSlim,全称MindStudio ModelSlim,昇腾模型压缩工具。
昇腾模型压缩工具,一个以加速为目标、压缩为技术、昇腾为根本的亲和压缩工具。包含量化和压缩等一系列推理优化技术,旨在加速大语言稠密模型、MoE模型、多模态理解模型、多模态生成模型等。
昇腾AI模型开发用户可以灵活调用Python API接口,适配算法和模型,完成精度性能调优,并支持导出不同格式模型,通过MindIE、vLLM Ascend等推理框架在昇腾AI处理器上运行。
安装ModelSlim
我们可以将以下命令在终端执行,就可以安装好msmodelslim了
shell
# 安装msmodelslim
git clone https://gitcode.com/Ascend/msit.git
cd msit/msmodelslim
bash install.sh
pip install accelerate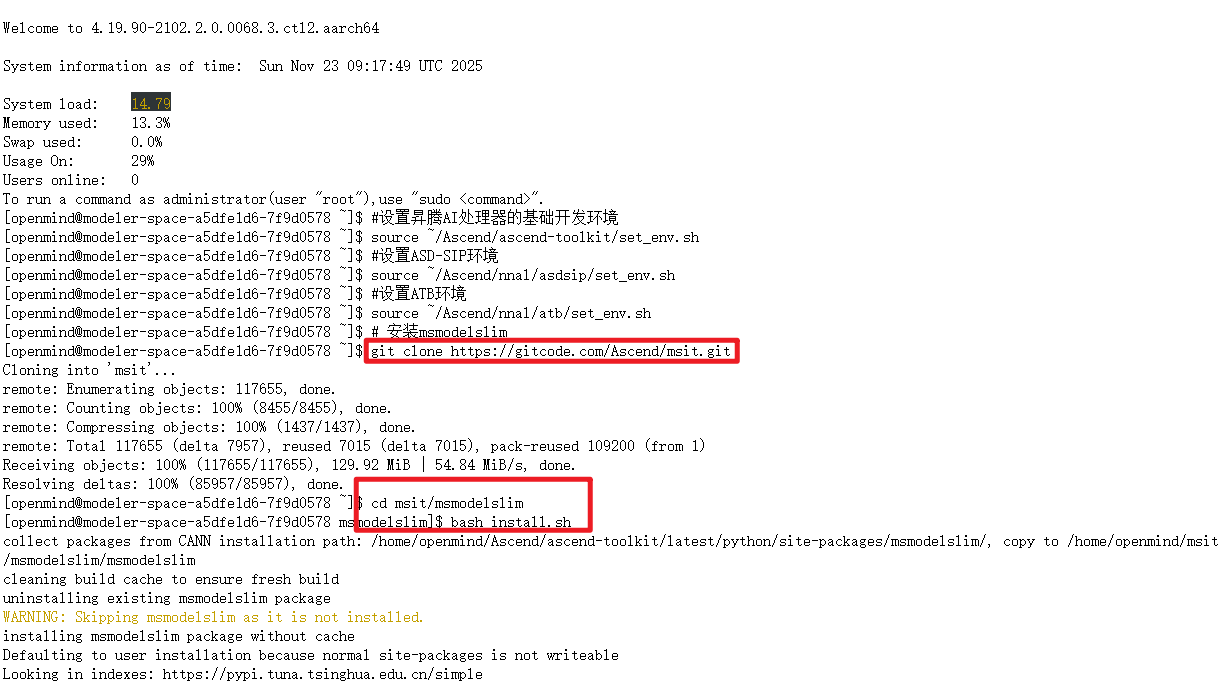
现在完成之后,我们cd回到根目录下。
模型下载
因为我们现在的这个空间是没有模型的,所以我们需要去下载模型,本次实践为了演示能快速出效果我们这里选择的是8B的模型,接下来我们进行模型的下载,魔乐社区提供两种下载模型的方式供大家选择,以下是两种模型下载方式的介绍。
使用git下载模型
这里我们使用git命令拉取,可以直接拉取完整的模型
shell
# 首先保证已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://modelers.cn/MindSDK/Qwen3-8B.git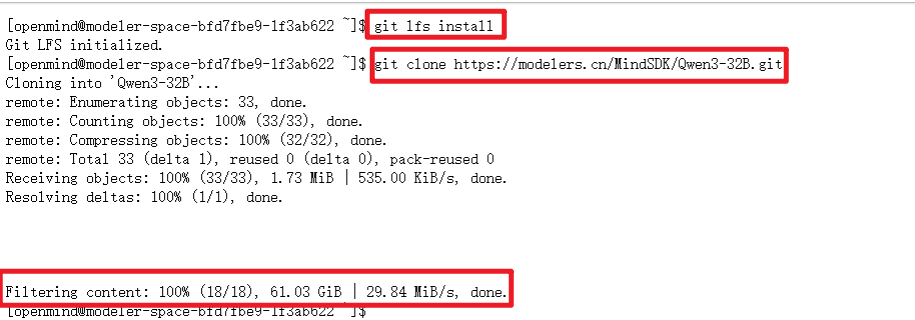
这里我下载的是Qwen3-8B,大家也可以量化其他的模型,更多的模型可以在魔乐社区模型库下载
使用openmind_hub下载模型
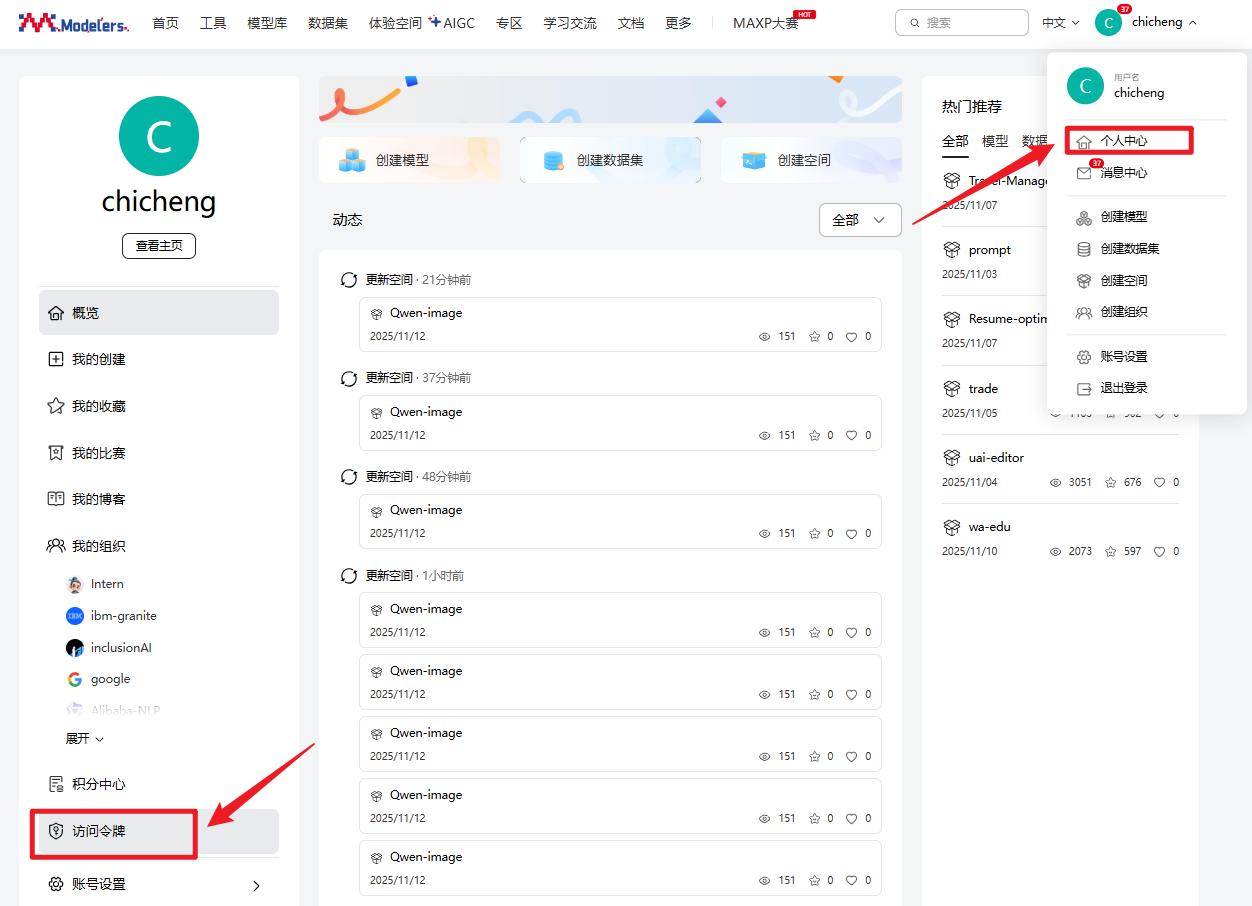
除了上面使用git下载模型外,我们魔乐社区还提供了使用openmind_hub下载模型,使用openmind_hub下载模型前,我们得先获取访问令牌,接下来我带大家获取访问令牌
1.在魔乐社区的个人中心,找到访问令牌
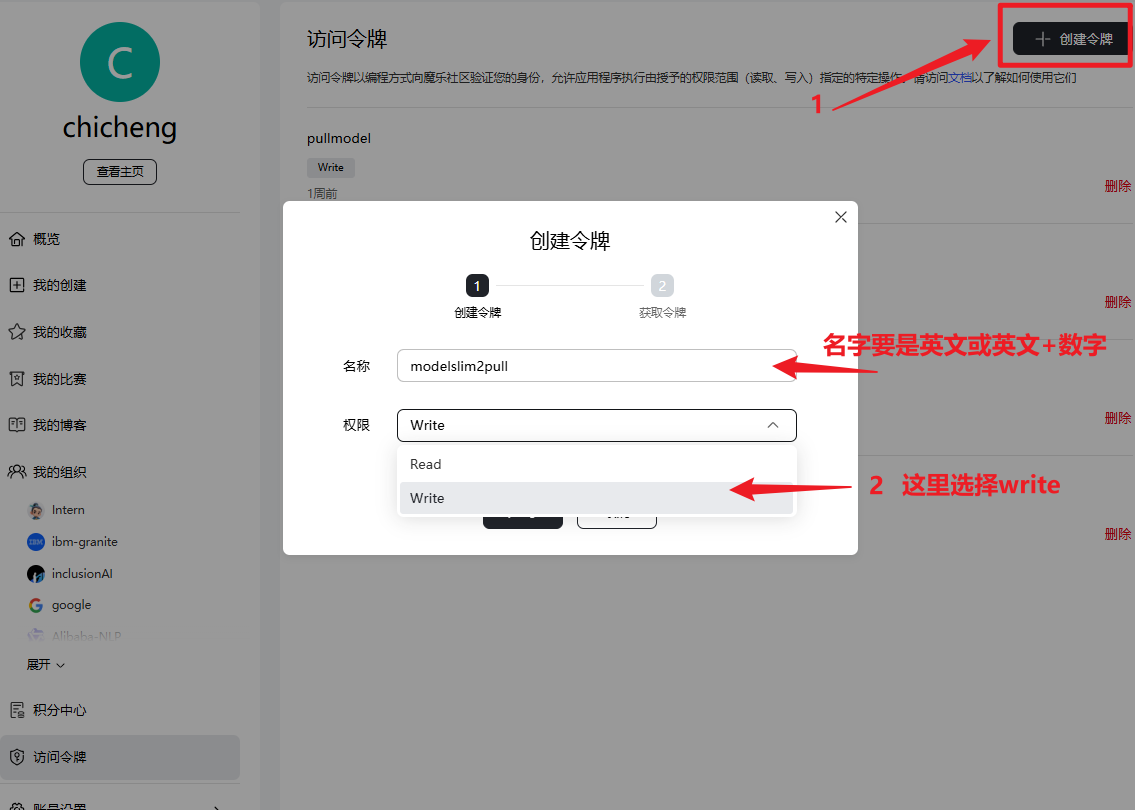
2.然后点击访问令牌,再点击创建令牌,选择在write这样后续我们还可以用这个令牌上传模型
3.然后我们就可以拿到一串加密字符串,复制保存下来,然后使用vim命令创建一个modelpull.py文件
shell
vim modelpull.py将下面的内容复制进去
python
from openmind_hub import snapshot_download
snapshot_download(
repo_id="AI-Research/Qwen3-8B",
token="38b22bf5599bf6b264f589bbe7ac8784ab7c48c9",# 这里需要输入自己的访问令牌,
repo_type="model",
local_dir=r"/home/openmind/MindSDK/Qwen3-8B",#指定下载的地址
)在运行这个代码之前我们需要先安装openmind_hub这个库
shell
pip install openmind_hub然后我们就可以运行代码了
shell
python modelpull.py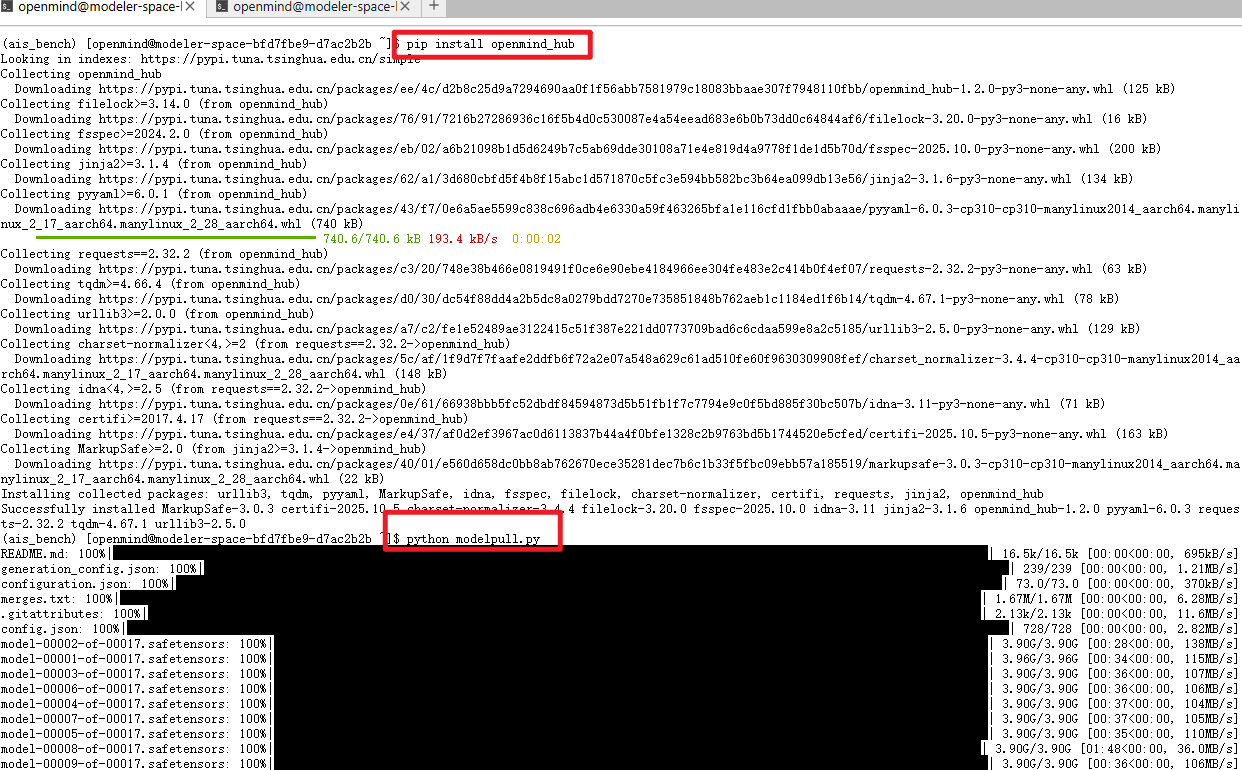
模型量化
拉取完模型后,我们就需要开始着手准备量化的所需要的yaml文件,这里我们使用的是msmodelslim的一键量化功能,所以我们只需要准备好yaml文件就可以了,我们新建yaml配置文件
shell
vim quant.yaml在文件中编写以下内容,然后保存退出
yaml
# API版本标识
apiversion: modelslim_v1
# 元数据信息
metadata:
# 配置唯一标识
config_id: qwen3-8b-dense-w8a8c8
# 量化后模型的评分(精度保持度)
score: 90
# 适用的模型类型
verified_model_types:
- Qwen3-8B
# 量化配置标签
label:
w_bit: 8 # 权重位宽为8bit
a_bit: 8 # 激活值位宽为8bit
is_sparse: False # 非稀疏量化
kv_cache: False # 不量化KV缓存
# 量化处理规范
spec:
# 量化处理流程步骤
process:
# 第一步:迭代平滑处理(Iterative SmoothQuant)
- type: "iter_smooth" # 使用迭代平滑量化方法
alpha: 0.5 # 平滑系数,平衡激活值和权重的量化难度
scale_min: 1e-5 # 缩放因子最小值,防止除零错误
symmetric: True # 使用对称量化(零点为0)
# 启用子图类型,对特定计算模式进行优化
enable_subgraph_type:
- 'norm-linear' # 层归一化后接线性层
- 'linear-linear' # 线性层串联
- 'ov' # 输出-值投影模式
- 'up-down' # 上投影-下投影模式
include:
- "*" # 包含所有层
# 第二步:线性量化
- type: "linear_quant" # 标准的线性量化
# 量化配置
qconfig:
# 激活值量化配置
act:
scope: "per_token" # 按token级别进行量化(动态量化)
dtype: "int8" # 数据类型为int8
symmetric: True # 对称量化
method: "minmax" # 使用最小-最大值方法确定量化范围
# 权重量化配置
weight:
scope: "per_channel" # 按通道级别进行量化(静态量化)
dtype: "int8" # 数据类型为int8
symmetric: True # 对称量化
method: "minmax" # 使用最小-最大值方法确定量化范围
# 包含范围
include: [ "*" ] # 默认包含所有层
# 排除列表:这些层的mlp.down_proj不进行量化
exclude:
- 'model.layers.1.mlp.down_proj' # 第1层的下投影层
- 'model.layers.2.mlp.down_proj' # 第2层的下投影层
- 'model.layers.6.mlp.down_proj' # 第6层的下投影层
- 'model.layers.7.mlp.down_proj' # 第7层的下投影层
- 'model.layers.11.mlp.down_proj' # 第11层的下投影层
- 'model.layers.43.mlp.down_proj' # 第43层的下投影层
- 'model.layers.44.mlp.down_proj' # 第44层的下投影层
- 'model.layers.45.mlp.down_proj' # 第45层的下投影层
- 'model.layers.62.mlp.down_proj' # 第62层的下投影层
# 保存配置
save:
- type: "ascendv1_saver" # 使用Ascend格式保存器
part_file_size: 4 # 分片文件大小,单位可能是GB量化需要准备的文件准备完毕之后,我们就可以执行一键量化的操作了
shell
msmodelslim quant \
--model_path /home/openmind/Qwen3-8B \
--save_path /home/openmind/Qwen3-8B-w8a8 \
--device npu \
--model_type Qwen3-8B \
--config_path ./quant.yaml \
--trust_remote_code True
# model_path后面跟着的是你需要量化的模型的地址,save_path是量化后模型要保存的位置,device是选择设备(显卡类型),model_type是指模型名称,config_path是指量化配置文件的地址,trust_remote_code是指信任并运行远程代码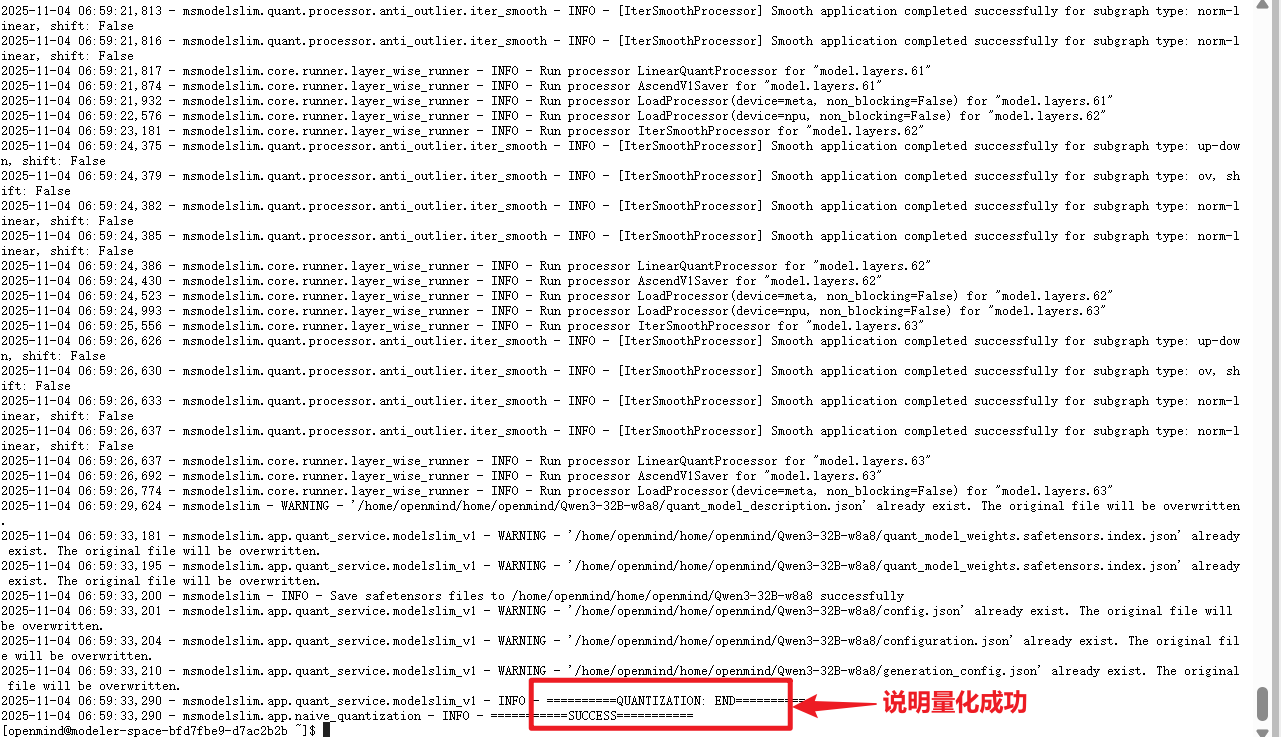
测量精度
拉起量化模型
我们通常使用vllm/mindie-service等拉起量化模型的服务后,使用客户端(curl/ais_bench)进行测评,将以下命令输入终端进行拉起。
shell
vllm serve --model=/home/openmind/Qwen3-8B-w8a8 --served-model-name qwen3 --trust-remote-code -tp 1 -dp 1 --quantization ascend --port 9000 --max-model-len 39500 --max-num-batched-tokens 39500 --additional_config='{"ascend_scheduler_config":{"enable": true}}' --gpu-memory-utilization 0.90命令的介绍:
python
"""
vllm serve: 启动vLLM高性能推理服务
--model: 模型文件在服务器上的存储路径
--served-model-name: 服务暴露的模型标识符,用于API调用
--trust-remote-code: 信任并加载模型自定义代码的安全选项
-tp: 张量并行度,控制模型在多个NPU/GPU间的切分方式
-dp: 数据并行度,控制请求在多个设备间的分发
--quantization: 量化方法指定,此处使用昇腾专用量化
--port: 网络服务端口号,客户端通过此端口连接
--max-model-len: 模型能处理的最大单序列长度
--max-num-batched-tokens: 批处理时token总数上限
--additional_config: 硬件特定的高级配置选项
--gpu-memory-utilization: 设备内存使用率阈值,避免内存溢出
"""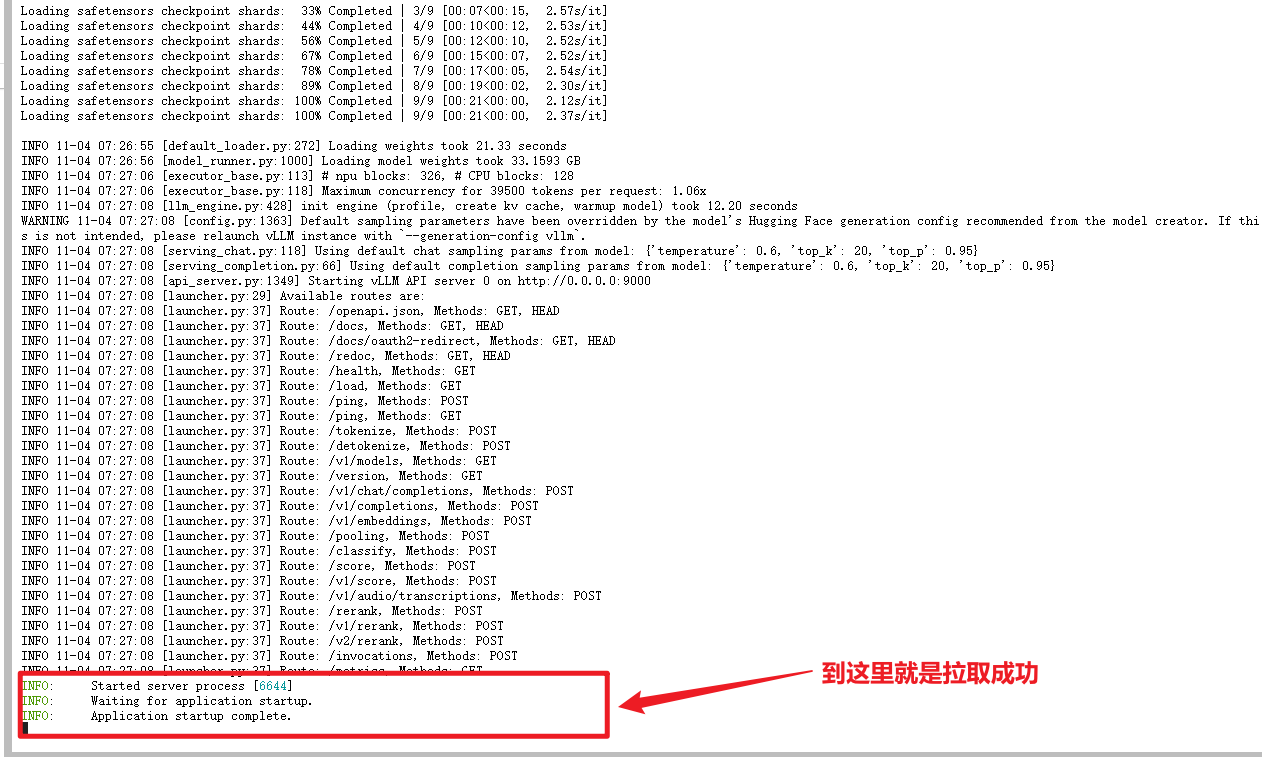
可以首先进行一次单论对话测试,快速检查量化模型是否存在乱码。
shell
curl http://localhost:9000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "qwen3", "messages": [{"role": "user", "content": "你好"}], "temperature": 0.7, "max_tokens": 50, "top_p": 0.9, "stream": false}'注:localhost:9000是服务化所指定的监听地址,需要和服务化拉起时的--port以及--host参数对应(未指定--host参数则默认为localhost)。

精度测量
我们量化完之后需要进行量化后模型的精度测量,本次实践在测评的时候使用的是ais_bench测量。ais_bench测量工具不支持python3.9及以下,需要安装miniconda,并在python3.10环境下安装。
环境准备
首先我们需要清除当前shell会话中的PYTHONPATH环境变量,清除它可以避免与CANN、MindSpore等框架的预配置环境冲突。
shell
#清除当前shell会话中的PYTHONPATH环境变量
unset PYTHONPATH注意这个命令操作只影响当前终端会话,重新打开终端或新会话会恢复原来的PYTHONPATH设置,需要重新再执行一次。
执行完以上命令之后我们就可以安装miniconda,创建python3.10环境
shell
# 安装miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
bash Miniconda3-latest-Linux-aarch64.sh
conda config --set auto_activate_base false
bash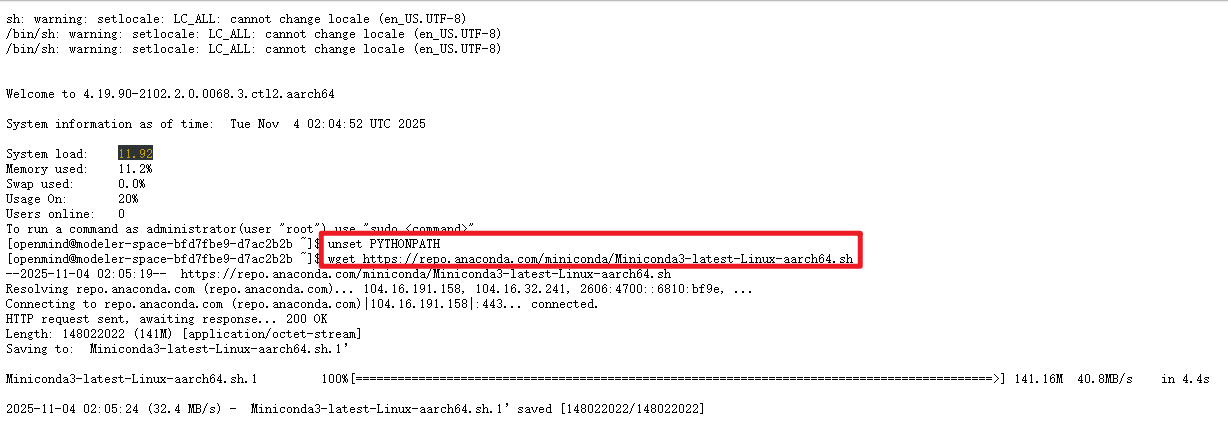
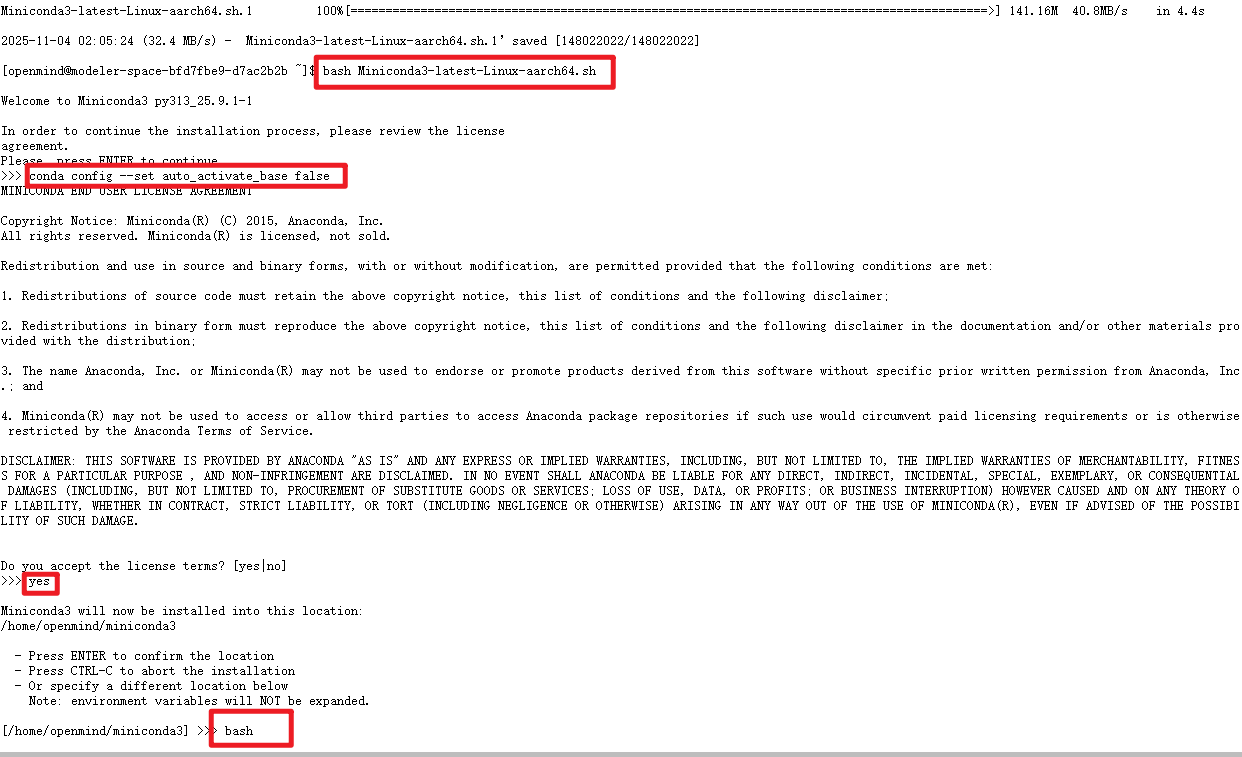
shell
#加载conda配置
source ~/.bashrc
# 接受main通道的条款
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
# 接受r通道的条款
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
# 创建python3.10环境
conda create --name ais_bench python=3.10 -y
conda activate ais_bench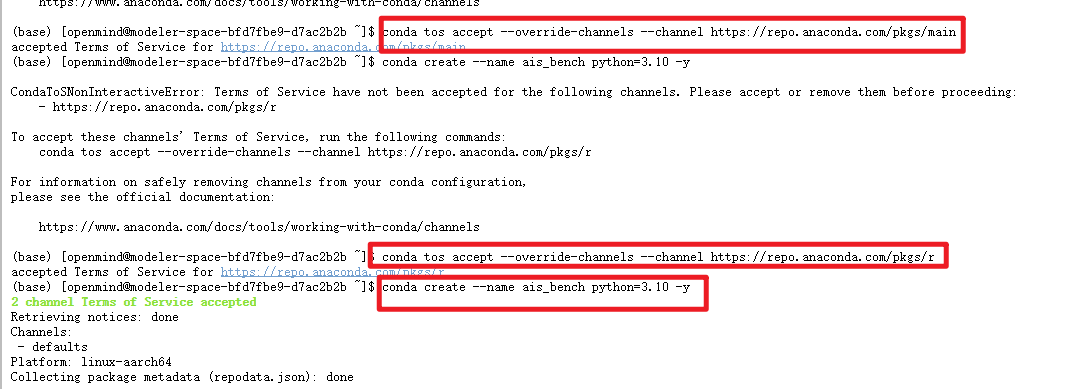
工具下载和数据集下载
环境准备完毕之后,我们就可以安装ais_bench测量工具了,执行以下命令进行安装
shell
git clone https://gitee.com/aisbench/benchmark.git
cd benchmark/
pip3 install -e ./ --use-pep517安装完毕之后,我们直接在benchmark下运行以下命令,下载需要测量的数据集
shell
cd ais_bench/datasets
mkdir aime/
cd aime/
wget http://opencompass.oss-cn-shanghai.aliyuncs.com/datasets/data/aime.zip
python3 -c "import zipfile; zipfile.ZipFile('aime.zip').extractall()"
rm aime.zip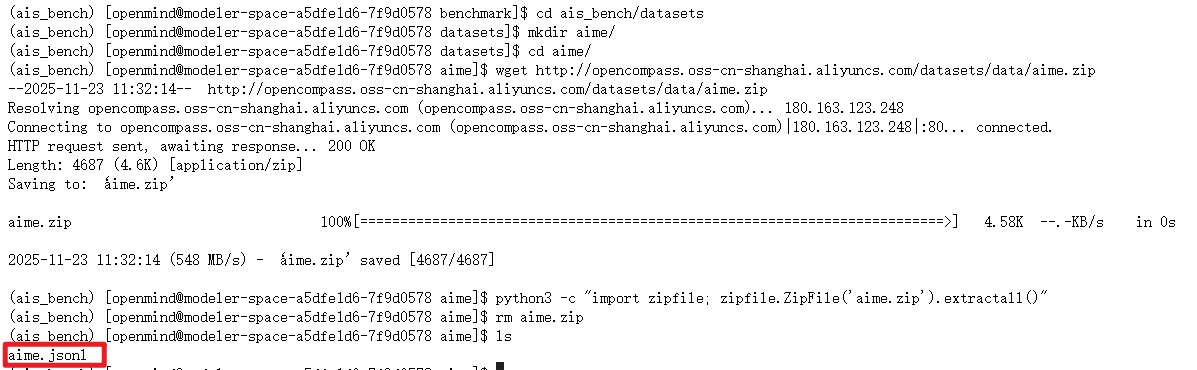
ls后有显示以下的aime.jsonl文件,就说明已经下载成功。我们可以vim进去看看内容

滑动到最后可以知道一共是30个题目,但是如果30个都跑的话,时间太长我们这里为了显示,只取3题进行测量,大家可以全部都跑通。
json
{"index": 0, "origin_prompt": "\nEvery morning, Aya does a $9$ kilometer walk, and then finishes at the coffee shop. One day, she walks at $s$ kilometers per hour, and the walk takes $4$ hours, including $t$ minutes at the coffee shop. Another morning, she walks at $s+2$ kilometers per hour, and the walk takes $2$ hours and $24$ minutes, including $t$ minutes at the coffee shop. This morning, if she walks at $s+\\frac12$ kilometers per hour, how many minutes will the walk take, including the $t$ minutes at the coffee shop?\n", "gold_answer": "204", "source": "aime2024"}
{"index": 1, "origin_prompt": "\nReal numbers $x$ and $y$ with $x,y>1$ satisfy $\\log_x(y^x)=\\log_y(x^{4y})=10.$ What is the value of $xy$?\n", "gold_answer": "25", "source": "aime2024"}
{"index": 2, "origin_prompt": "\nAlice and Bob play the following game. A stack of $n$ tokens lies before them. The players take turns with Alice going first. On each turn, the player removes $1$ token or $4$ tokens from the stack. The player who removes the last token wins. Find the number of positive integers $n$ less than or equal to $2024$ such that there is a strategy that guarantees that Bob wins, regardless of Alice's moves.\n", "gold_answer": "809", "source": "aime2024"}
我们下载完数据集后就可以cd到根目录了。
测量精度
在使用测量的数据集前我们需要修改测评的配置,ais_bench命令使用--models参数指定测评配置,其中包括了模型名称(model)、监听地址(host_ip/host_port)、最大上下文长度(max_out_len)、批处理大小(batch_size)、采样策略(generation_kwargs)等配置项。
一般我们使用vllm_api_general_chat进行测评,该配置所对应的配置文件可以通过以下路径直接配置,在终端输入以下命令:
shell
vim benchmark/ais_bench/benchmark/configs/models/vllm_api/vllm_api_general_chat.py更改文件中编写的内容,替换成以下内容,并且esc------>:wq(冒号是英文的)保存退出
shell
from ais_bench.benchmark.models import VLLMCustomAPIChat
from ais_bench.benchmark.utils.model_postprocessors import extract_non_reasoning_content
models = [
dict(
attr="service",
type=VLLMCustomAPIChat,
abbr='vllm-api-general-chat',
path="",
model="qwen3",
request_rate = 0,
retry = 2,
host_ip = "localhost",
host_port = 9000,
max_out_len = 32768,
batch_size=16,
trust_remote_code=False,
generation_kwargs = dict(
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
),
pred_postprocessor=dict(type=extract_non_reasoning_content)
)
]之后运行以下命令进行测量:
shell
ais_bench --models vllm_api_general_chat --datasets aime2024_gen_0_shot_chat_prompt --summarizer example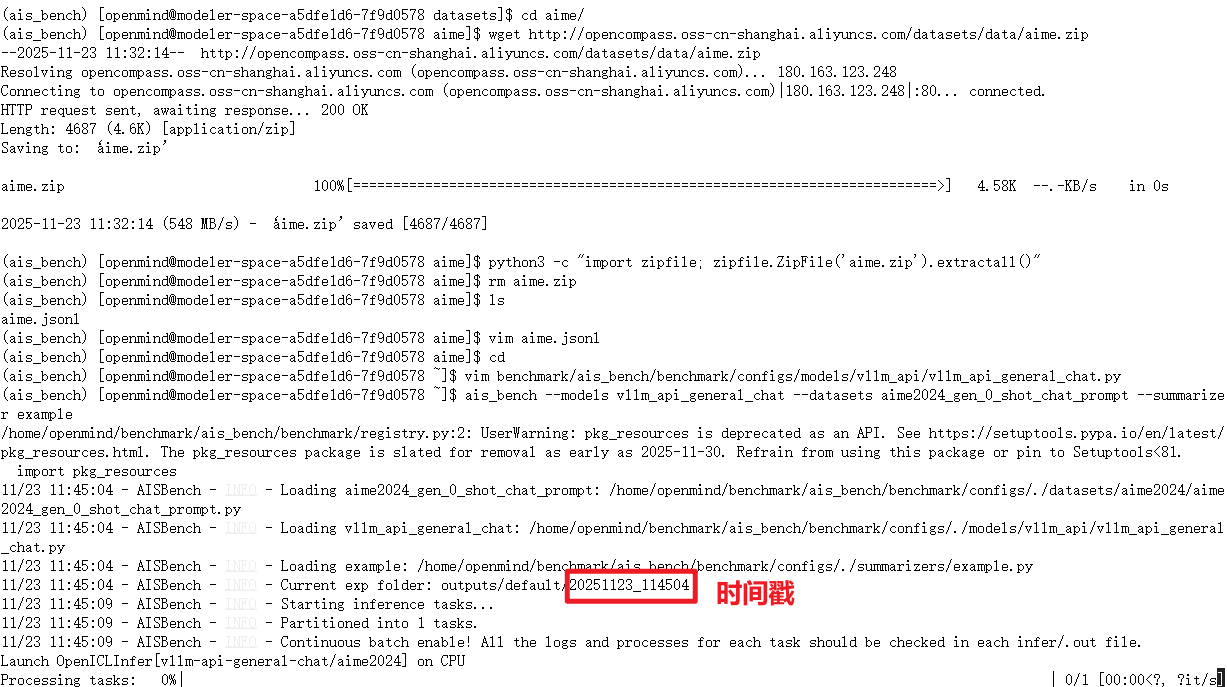
可以另起一个终端,查看测评日志文件,注意命令中的替换时间戳。(20251103_133922就是时间戳)
shell
tail outputs/default/20251123_115530/logs/infer/vllm-api-general-chat/aime2024.out
``
最终的准确率等结果会直接输出在运行测评命令的终端打屏中。