分区选择策略
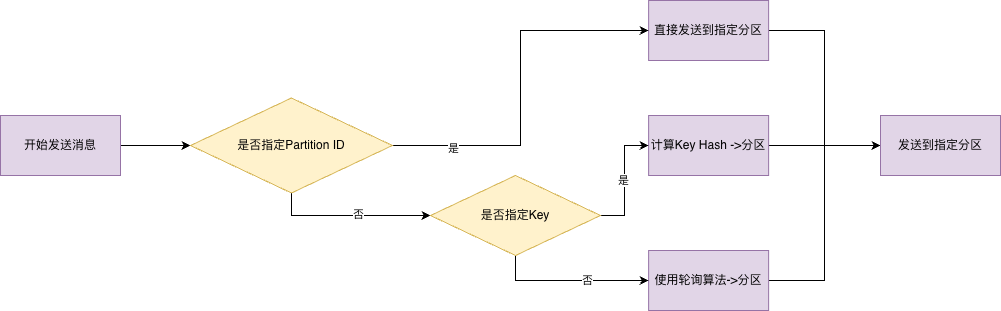
Kafka中生产者发送到Broker分区,分区选择策略分为四种。指定Partition ID、指定了Key和轮询算法和自定义分区策略。
指定Partition ID
拥有最高优先级的分区选择策略。即使指定了对应的Key,也会遵循Partition ID选择的策略。
java
ProducerRecord<String, String> record =
new ProducerRecord<>("my-topic", 2, "key", "value");
// 这条消息将直接发送到分区2,忽略Key值指定Key
未指定Partition ID,当使用Key去选择分区,就需要使用hash算法,确定目标分区。
java
ProducerRecord<String, String> record =
new ProducerRecord<>("my-topic", "user-123", "order data");
// 通过 hash("user-123") % 分区数 确定目标分区这里的Hash算法并不是Java的hashCode。而是使用了MurmurHash2的算法。让相同Key的消息总是发送到同一个分区,保证同一业务实体的消息有序性。
轮询算法
轮询算法是Kafka默认的策略。能够实现负载均衡,让消息能够均匀的分布到所有的分区,也能够最大化吞吐量,避免单个分区成为热点的问题。
java
ProducerRecord<String, String> record =
new ProducerRecord<>("my-topic", "value only");
// 使用round-robin轮询算法自定义分区策略
自定义分区策略一般来说只有特殊的业务才会使用的到。需要实现Partitioner到接口
java
// 实现Partitioner接口
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key,
byte[] keyBytes, Object value,
byte[] valueBytes, Cluster cluster) {
// 自定义分区逻辑
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 没有Key时使用轮询
return roundRobinPartition(topic, numPartitions);
} else {
// 有Key时使用自定义逻辑
return customHash(keyBytes) % numPartitions;
}
}
}流程图
核心配置参数
bootstrap.servers - 集群地址
java
# 格式:host1:port1,host2:port2,...
bootstrap.servers=localhost:9092,localhost:9093,localhost:9094最主要的作用:
生产者用于发现集群中所有的Broker的初始连接列表
只需要提供部分Broker地址,生产者会自动发现集群完整拓扑
建议至少提供多个Broker地址,避免单点故障的问题。
acks - 消息确认机制
acks消息确认机制分为三种模式。0、1和all/-1
acks = 0
从可靠性上,是三种模式中最低的,Leader写入缓存就返回,不等待任何确认。
从性能上,是三种模式中最高的,零等待以及最高的吞吐。
从适用场景上,适合日志收集,指标上报等可容忍数据丢失的场景。
acks = 1
从可靠性上,是三种模式中中等的,Leader写入成功(落盘)即返回
从性能上,是三种模式中较高的,需要等待Leader确认。
从适用场景上,适合大多数业务场景,平衡性能与可靠性。
acks = all/-1
从可靠性上,是三种模式中最高的,等待所有ISR副本同步成功。
从性能上,是三种模式中最低的,需要等待所有副本确认。
从适用场景上,适合金融交易、重要订单等要求强一致的场景。
retries 和 retry.backoff.ms - 重试机制
主要讲三个参数。retries、retry.backoff.ms和enable.idempotence
retries是指重试次数,默认是Integer.MAX_VALUE。我最常使用是3次
retry.backoff.ms是重试的间隔,默认是100ms。我最常使用的是1000ms
enable.idempotence是启用幂等性,避免重试导致消息重复问题。
PS:这里重试需要注意一下:
Kafka的重试是幂等的,当我们的enable.idempotence是true。
重试可能会导致消息顺序改变,需要max.in.flight.requests.per.connection=1来保证顺序
重试只对可恢复错误有效,比如说Leader选举和网络抖动
批处理优化参数
批处理优化参数也主要是三个。batch.size、linger.ms和buffer.memory。
batch.size
batch.size的默认值为16KB,它的作用是单个批次的最大字节数。
调优建议:根据消息的大小进行调整,太小,就增加了请求数,太大,就增加了延迟。
linger.ms
linger.ms的默认值为0ms,它的作用是批次在发送前的最大等待时间。增加这个值,能够提高吞吐,但是会增加延迟,一般来说都设置为5ms到100ms比较合理。
buffer.memory
buffer.memory到默认值是32MB,它的作用是生产者缓冲区的总内存大小。调优的时候建议根据监控缓冲区的使用情况,避免阻塞。
场景建议参数
当场景是高吞吐场景时
XML
batch.size=32768 # 32KB
linger.ms=20 # 等待20ms
buffer.memory=67108864 # 64MB当场景是低延时场景时
XML
batch.size=16384 # 16KB
linger.ms=0 # 立即发送
buffer.memory=33554432 # 32MB当缓冲区的使用率到达95%或超过这个数值的时候,需要考虑增加buffer.memory。