作者:来自 Elastic Aram Favela
了解 Elastic 的 InfoSec 团队如何在多集群 ECK 环境中实施 AutoOps,将集群性能调查时间从 30 多分钟减少到五分钟。
通过实时问题检测和可操作的建议来优化性能并降低成本,从而简化你的 Elasticsearch 运维。AutoOps 可用于 cloud 和 self-managed 部署。了解更多关于 AutoOps 的信息。
在 Elastic,InfoSec Security Engineering 团队负责部署和管理 InfoSec 的 ECK 集群。在 Elastic on Elastic 系列中,我们强调 InfoSec 作为 Customer Zero 的角色。通过运行最新的 stack 版本和功能,我们致力于提供实用建议,并展示我们如何运营。在本节中,我们介绍在多集群 Elastic Cloud on Kubernetes ( ECK )环境中安装 AutoOps,并强调它如何立即带来价值。
AutoOps for Elasticsearch 通过提供性能建议、资源使用洞察、实时问题检测和引导式修复来简化集群运维。随着 AutoOps for self-managed ( on-premises )集群的最新发布,我们迫不及待地将其部署,看看它如何帮助我们监控和维护大型多集群 ECK 环境的健康状况。
在 ECK 上安装 AutoOps
为了确保可扩展性和一致性,Security Engineering 团队致力于将所有基础设施作为代码( IaC )进行管理。遵循这种方式,我们创建了一个 Helm chart 来在整个 ECK 环境中部署 AutoOps agent。关于我们基础的 ECK 和 Helm 方法的更多信息,请参考本系列之前的博客文章。
AutoOps chart
markdown
`
1. cloud-connected-autoops/
2. ├─ chart.yaml
3. ├─ values.yaml
4. └─ templates/
5. └─ deployment.yaml
`AI写代码chart.yaml
markdown
`
1. apiVersion: v1
2. description: Autoops cloud connected Agent chart
3. name: cloud-connected-autoops
4. version: 0.1.0
`AI写代码values.yaml
go
`version: 9.2.0`AI写代码deployment.yaml
这来自官方的 AutoOps 仓库,不过我们将 image 版本模板化,以简化未来升级,并与现有自动化保持兼容:
arduino
`1. image: >-
2. docker.elastic.co/elastic-agent/elastic-otel-collector-wolfi:{{ .Values.version }}`AI写代码在定义好 AutoOps 的 Helm chart 之后,我们现在可以使用 Cloud Connect 在环境中安装 AutoOps。这个功能让我们能够在 self-managed 的 ECK 集群中使用 Elastic Cloud 服务,而无需安装和维护额外的基础设施。
文档列出了创建 Elastic Cloud Connect 账号以及为每个集群生成必要连接信息的步骤。基于我们的 ECK 环境,我们使用了 Kubernetes 安装方法。
配置好连接后,我们只需要在每个 ECK 集群的 values.yml 中添加一个简单的布尔标志,就能启用 Elastic Agent:
yaml
`
1. cloud-connected-autoops:
2. enabled: true
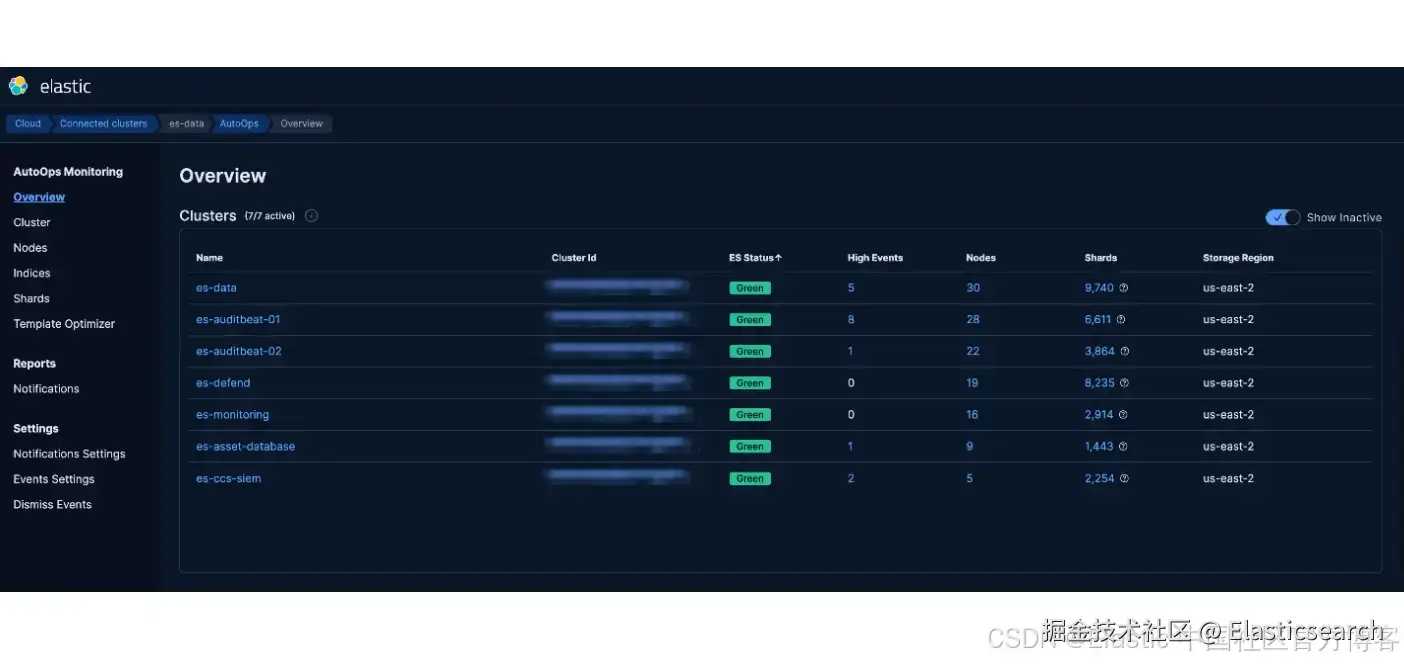
`AI写代码安装完成后,每个已连接的集群都会显示在 AutoOps 概览页面上:
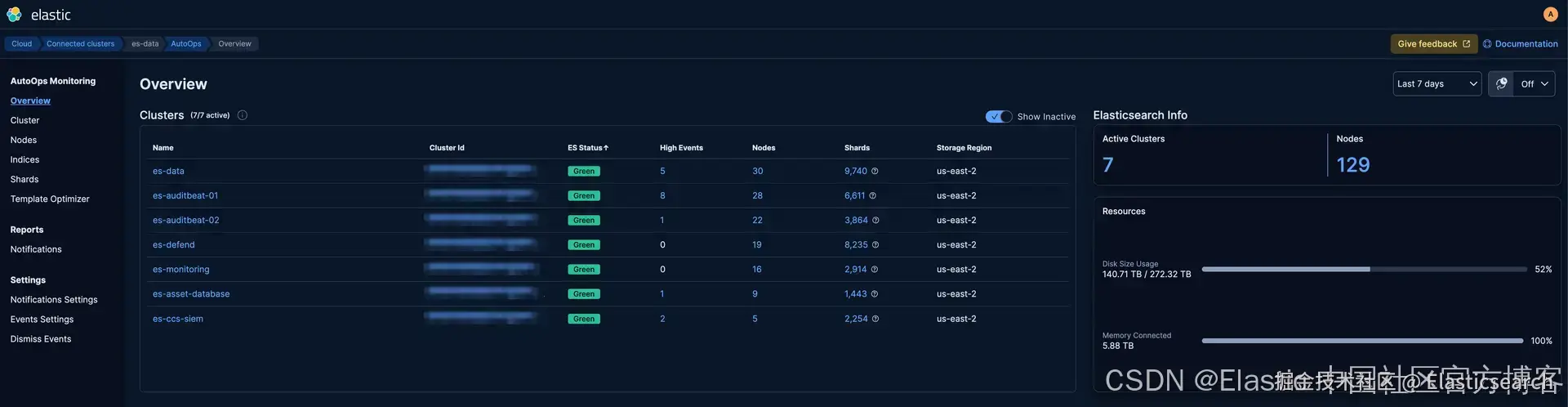
AutoOps 实际应用
我们目前使用 Stack Monitoring 来监控集群健康状况,并使用默认规则向我们发送告警。虽然我们计划在不久的将来迁移到 AutoOps 告警,但我们现有的告警仍依赖 Stack Monitoring。
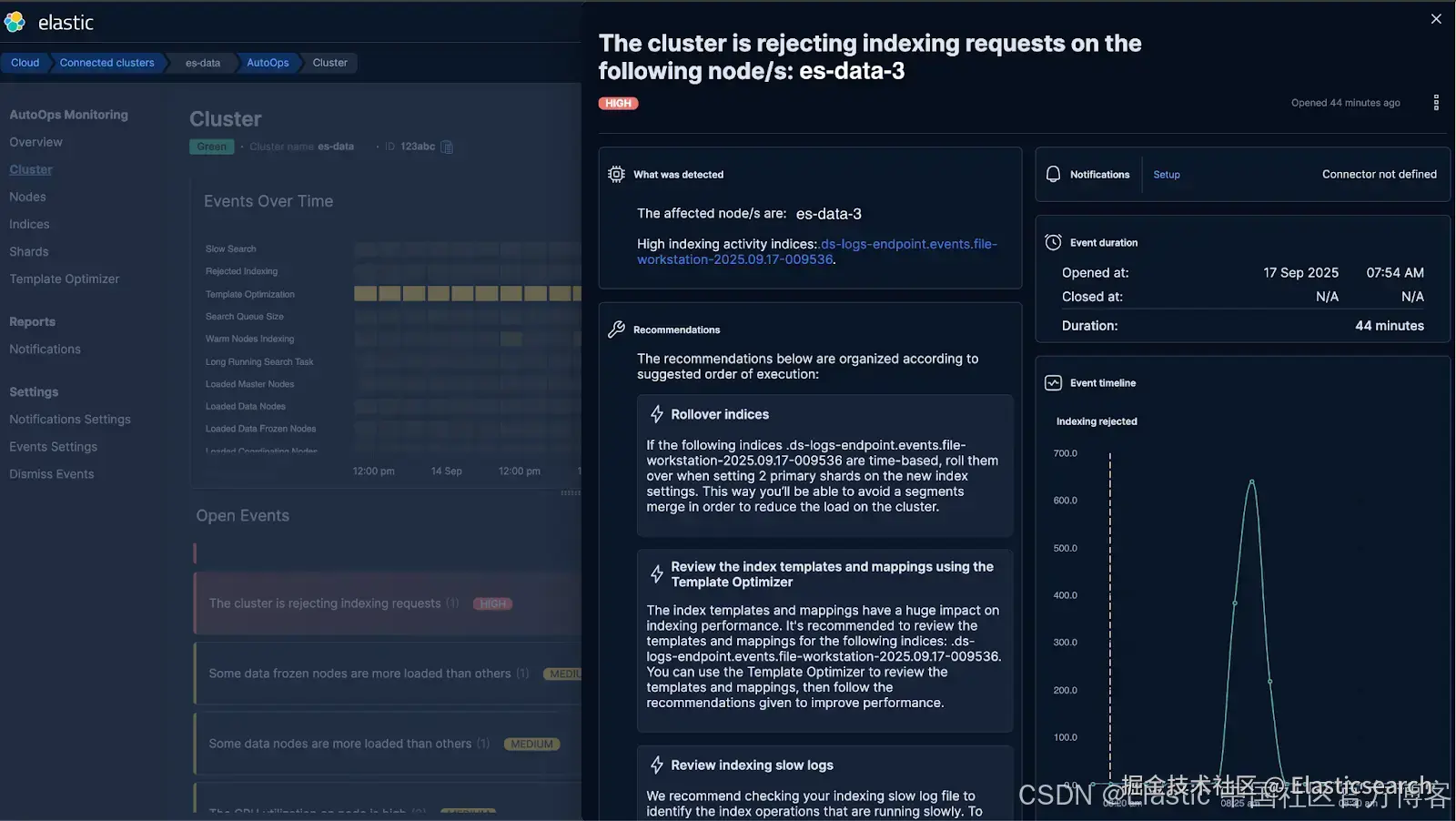
当我们在告警的 Slack 频道收到 thread pool write rejections 告警时,就有了测试 AutoOps 的机会:

在收到标准警报后,我们查看了 AutoOps 以获取更多上下文。AutoOps 标记了同样的问题,但提供了额外的关键细节,包括导致写入拒绝的确切索引:
接下来,我们导航到 shard Analyzer 页面,该页面可视化分片热点。可视化显示这个特定节点的写入速率最高,并管理两个写入索引。图表还显示其他节点的利用率较低:
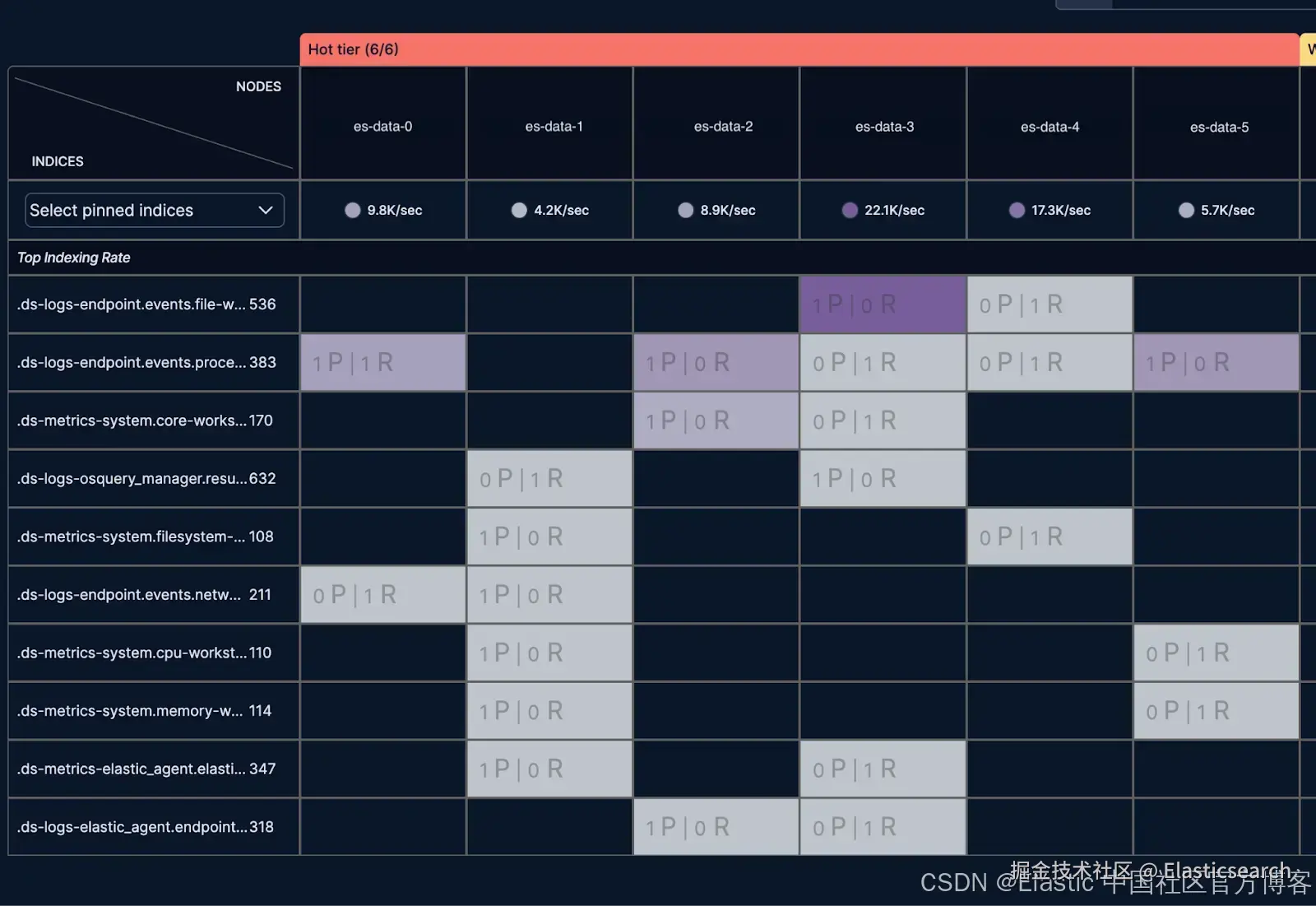
为减轻 es-data-3 的负载,我们使用 cluster reroute 命令将较小的写入索引移动到 es-data-5:
bash
`
1. POST /_cluster/reroute
2. {
3. "commands": [
4. {
5. "move": {
6. "index": ".ds-logs-osquery_manager.result-workstation-2025.09.15-000632",
7. "shard": 0,
8. "from_node": "es-data-3",
9. "to_node": "es-data-5"
10. }
11. }
12. ]
13. }
`AI写代码在执行 reroute 后,es-data-3 的写入线程池立即下降:
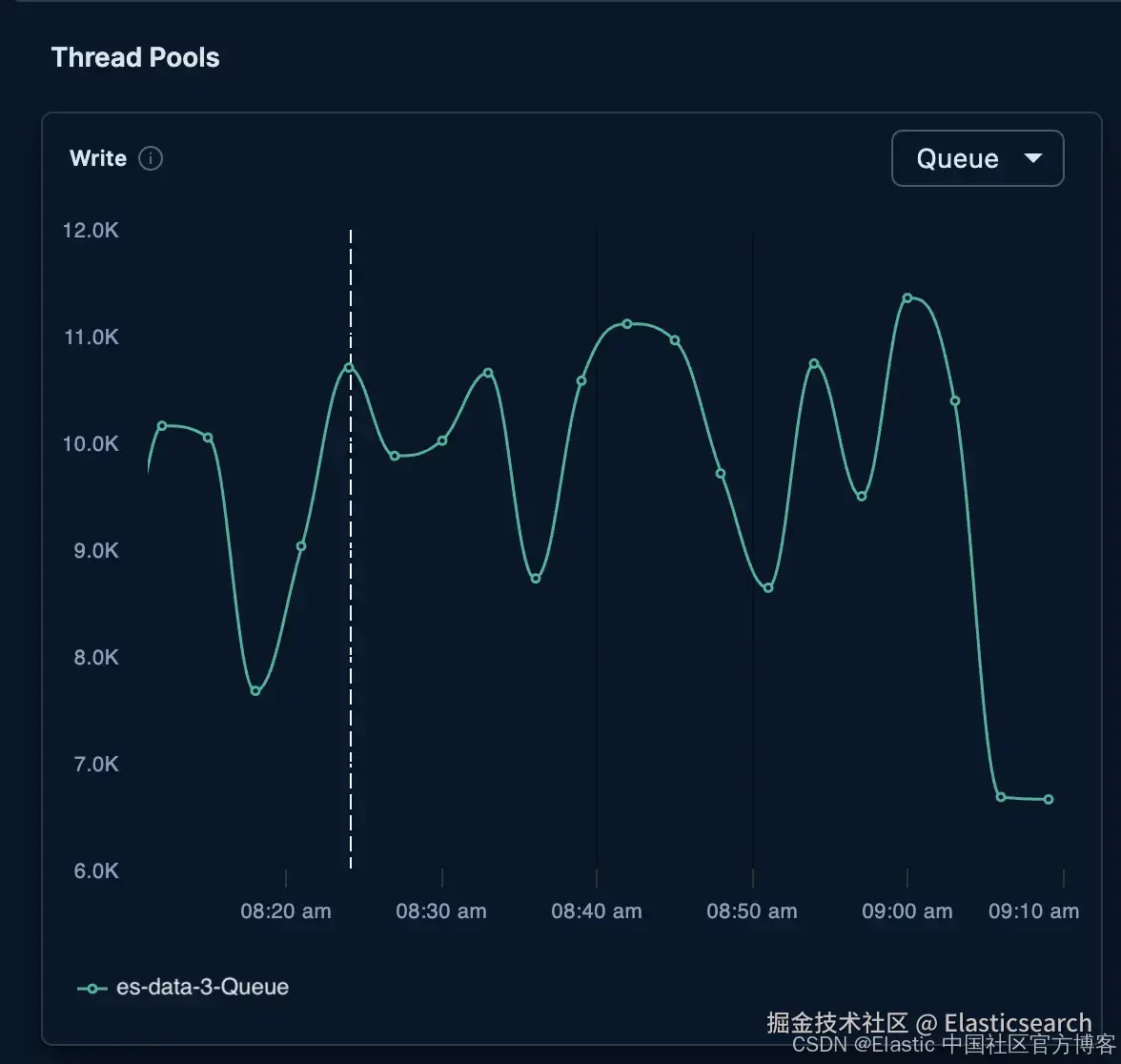
如果没有 AutoOps,调查 Elasticsearch 性能问题将需要手动查询各个节点的指标、分片分配和线程池,通常还需要多次调用时间点 API。AutoOps 将这些数据集中管理,实时持续收集,并可视化随时间变化的趋势。因此,我们能够在五分钟内调查并解决一个之前可能需要三十分钟或更长时间的问题。
虽然这个示例只是展示了 AutoOps 功能的一部分,但我们的实践经验表明,其详细的指标和可视化使得调查和解决 Elasticsearch 性能问题比以前更简单、更高效。
想了解更多关于自管理集群部署 AutoOps 的信息,请查看公告。