在日常开发中,我们写 JavaScript 代码时几乎不需要关心内存分配、回收这些底层细节。但你是否曾好奇过:
- 为什么
let a = 1; let b = a; a = 2后,b还是 1? - 为什么对象赋值后修改一个会影响另一个?
- 闭包到底是怎么"记住"外部变量的?
- JS 是如何做到"不用手动释放内存"的?
今天,我们就结合 V8 引擎的实现原理,深入浅出地聊聊 JavaScript 的内存机制与执行模型,揭开这些常见现象背后的真相。
一、JS 是什么语言?动态弱类型 ≠ 不严谨
先来看一段代码:
ini
var bar;
console.log(typeof bar); // "undefined"
bar = 12;
console.log(typeof bar); // "number"
bar = "极客时间";
console.log(typeof bar); // "string"
bar = true;
console.log(typeof bar); // "boolean"
bar = null;
console.log(typeof bar); // "object" ← JS 的历史性 bug!
bar = {name: "极客时间"};
console.log(typeof bar); // "object"这段代码展示了 JavaScript 的两个关键特性:
- 动态类型:变量类型在运行时确定,无需提前声明。
- 弱类型 :不同类型之间可以隐式转换(如
true == 1)。
但这并不意味着 JS "不严谨"。恰恰相反,它的设计让开发者更聚焦于逻辑而非类型系统。而这一切的背后,离不开一套精密的 内存管理机制。
二、内存分两块:栈 vs 堆
JavaScript 引擎(如 V8)将内存分为两类:
| 内存区域 | 存储内容 | 特点 |
|---|---|---|
| 栈内存(Stack) | 简单数据类型(Number, String, Boolean, undefined, Symbol, BigInt) | 快速分配/释放,连续空间,大小固定 |
| 堆内存(Heap) | 复杂数据类型(Object, Array, Function 等) | 空间大但分配/回收慢,不连续 |
✅ 示例 1:基本类型 ------ 栈内存中的独立拷贝
ini
function foo() {
var a = 1;
var b = a; // 拷贝值
a = 2;
console.log(a); // 2
console.log(b); // 1 ← 不受影响
}因为 a 和 b 都是基本类型,它们各自在栈中拥有独立的存储空间。赋值是值拷贝,互不影响。
✅ 示例 2:引用类型 ------ 堆内存中的共享指针
css
function foo() {
var a = { name: "极客时间" };
var b = a; // 拷贝的是"引用"(指针)
a.name = '极客帮';
console.log(a); // { name: "极客帮" }
console.log(b); // { name: "极客帮" } ← 被同步修改!
}这里 a 和 b 在栈中只保存了指向堆中同一个对象的引用地址。修改对象内容,所有引用都会看到变化。
💡 关键理解:JS 中没有"对象变量",只有"对象引用"。
三、执行上下文与调用栈:程序运行的舞台
每当 JS 执行一段代码,引擎会创建一个 执行上下文(Execution Context) ,包含:
- 变量环境(Variable Environment) :存放
var、函数声明等 - 词法环境(Lexical Environment) :存放
let、const、块级作用域等 - this 绑定
- outer 引用:指向外层作用域(用于构建作用域链)
这些上下文被压入 调用栈(Call Stack) ------ 一个 LIFO(后进先出)的结构。
📌 为什么用栈?
因为函数调用频繁,栈的"压入/弹出"操作极快,且内存连续,适合快速切换上下文。
一旦函数执行完毕,其上下文从栈顶弹出,栈内变量(基本类型)瞬间释放 ;而堆中的对象,只有当没有任何引用指向它时,才会被垃圾回收器(GC)慢慢清理。
四、闭包:自由变量的"时光胶囊"
闭包是 JS 最强大也最易误解的特性之一。看下面这个经典例子:
javascript
function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())闭包是如何工作的?
- 编译阶段 :V8 扫描
foo内部函数,发现getName/setName引用了myName。 - 判断闭包:只要有内部函数引用了外部变量,就判定存在闭包。
- 创建 closure 对象 :在堆内存 中创建一个
closure(foo)对象,专门保存被引用的自由变量(如myName)。 - 内部函数绑定 :
getName和setName的[[Scope]]指向这个closure(foo)。
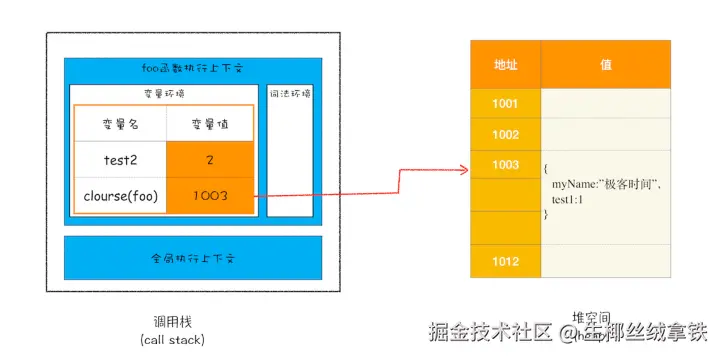
🔥 核心突破 :
闭包的本质,是把本该随栈销毁的变量,提升到堆中长期保存,并通过作用域链维持访问能力。
这解释了为什么即使 foo() 执行完毕,返回的函数仍能读写 myName ------ 它们共享同一个堆中的闭包环境。
五、对比 C 语言:JS 为何不用手动管理内存?
看看 C 代码:
ini
int main() {
int a = 1;
char* b = "极客时间";
bool c = true;
c = a; // 隐式转换(危险!)
return 0;
}C/C++ 需要手动 malloc / free,稍有不慎就会内存泄漏或野指针。而 JS:
- 自动分配:声明变量时自动决定放栈 or 堆
- 自动回收:通过引用计数 + 标记清除算法回收无用对象
- 开发者无感:你只需关注逻辑,引擎处理一切
当然,这也带来性能权衡:堆操作比栈慢,GC 可能造成卡顿。但对大多数 Web 应用来说,这是值得的抽象。
六、总结:一张图看懂 JS 内存模型

- 栈:轻量、快速、自动释放
- 堆:重量、灵活、GC 回收
- 闭包:通过堆保存自由变量,打破栈的生命周期限制
七、结语
理解 JavaScript 的内存机制,不仅能写出更健壮的代码,还能在面试中脱颖而出。真正的高手,既会写业务,也懂底层原理。