目录
- 简单概括
- ChatTime:统一多模态时间序列基础模型研究总结
-
- 一、研究背景与问题
- 二、核心创新:ChatTime模型设计
-
- [1. 核心理念](#1. 核心理念)
- [2. 模型架构(图1)](#2. 模型架构(图1))
- [3. 训练流程](#3. 训练流程)
- 三、实验设计与结果
-
- [1. 实验设置](#1. 实验设置)
- [2. 零样本时间序列预测(ZSTSF)](#2. 零样本时间序列预测(ZSTSF))
- [3. 上下文引导时间序列预测(CGTSF)](#3. 上下文引导时间序列预测(CGTSF))
- [4. 时间序列问答(TSQA)](#4. 时间序列问答(TSQA))
- [5. 消融实验(图2)](#5. 消融实验(图2))
- 四、数据集贡献
- 五、结论与未来展望
-
- [1. 结论](#1. 结论)
- [2. 未来方向](#2. 未来方向)
- 六、关键对比与优势(表1)
简单概括
人类专家通常会整合数值和文本多模态信息来分析时间序列。然而,大多数传统的深度学习预测模型仅依赖单模态的数值数据 ,在单个数据集上使用固定长度的窗口进行训练和预测,无法适应不同的场景。性能强大的预训练大型语言模型为时间序列分析带来了新的机遇。但现有的方法要么训练效率低下,要么无法处理文本信息,要么缺乏零样本预测能力 。在本文中,我们创新性地将时间序列建模为一种"外语 ",并构建了ChatTime------一个用于时间序列和文本处理 的统一框架。作为一款即开即用的多模态时间序列基础模型,ChatTime具备零样本预测能力,并支持时间序列和文本的双模态输入/输出 。我们设计了一系列实验,以验证ChatTime在多个任务和场景中的卓越性能,并创建了四个多模态数据集来填补数据空白。实验结果证明了ChatTime的潜力和实用性。
论文:ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
作者:hengsen Wang1* Qi Qi1* Jingyu Wang1 2
Haifeng Sun1 Zirui Zhuang1 Jinming Wu1 Lei Zhang3 Jianxin Liao1
单位: 北京邮电大学 ,鹏城实验室 ,中国联合网络通信股份有限公司
代码:https://github.com/ForestsKing/ChatTime请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
关注微信公众号 ,获取更多资讯

ChatTime:统一多模态时间序列基础模型研究总结
一、研究背景与问题
- 时间序列分析现状:时间序列数据在金融、交通、能源等多领域至关重要,但传统深度学习预测模型存在局限------仅依赖单模态数值数据,采用固定长度窗口在单一数据集上训练预测,无法适应不同场景;且当前单模态方法性能接近饱和,简单线性模型常能媲美复杂模型。
- 现有LLM相关方法缺陷:预训练大语言模型(LLM)为时间序列分析带来新可能,但现有方法存在不足:部分从 scratch 训练效率低且无法处理文本信息;部分整合LLM权重但需针对每个数据集重新微调,无零样本预测能力,且不能输出文本,难以应对时间序列问答、总结等场景。
- 研究目标:构建支持零样本推理、可处理时间序列与文本双模态输入输出的多模态时间序列基础模型。
二、核心创新:ChatTime模型设计
1. 核心理念
将时间序列视为"外语",通过词汇扩展使预训练LLM能处理时间序列,无需从头训练或修改模型架构,实现时间序列与文本的统一处理。
2. 模型架构(图1)
- 关键修改:一是引入"黄色插件",支持时间序列实值与"外语"互转;二是扩展"灰色分词器"词汇表,容纳时间序列"外语"。
- 时间序列转"外语"流程 :
- 归一化:用min-max缩放将时间序列实值映射到-1至1范围,考虑预测序列可能超出历史序列范围,实际将历史序列缩放到-0.5至0.5,预留缓冲区间。
- 离散化:将-1至1区间均匀划分为10K个区间,每个缩放后的值映射到对应区间,以区间中心值作为离散值,并固定精度为4位。
- 构建"外语词汇":在离散值前后添加标记"###"形成"外语词汇"(如###0.2835###),同时添加"###Nan###"处理缺失值,大幅降低token消耗(表2)。
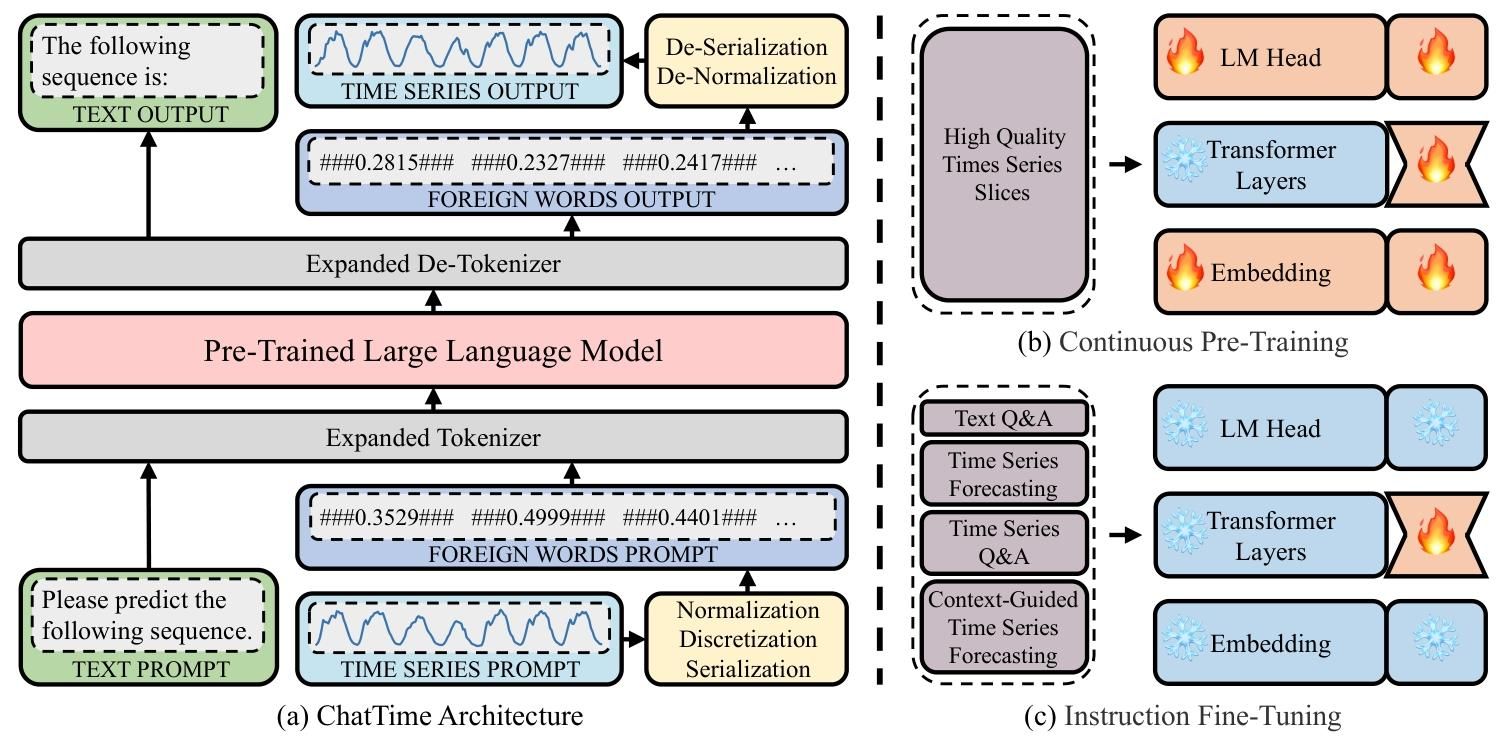
3. 训练流程
- 持续预训练(图1b) :
- 数据来源:从Monash和TFB两个开源时间序列库选取约100个子数据集,排除后续评估用数据集,通过滑动窗口(表3)生成切片,经K-means聚类筛选1M高质量切片。
- 训练任务:基于LLaMA-2-7B-Base模型,以自回归预测为任务进行预训练,得到ChatTime-1-7B-Base,同时训练嵌入层、输出头与Transformer层。
- 指令微调(图1c) :
- 数据与任务:用4类任务数据集(各25K样本,共100K)微调,包括文本问答(Alpaca数据集)、单模态时间序列预测(预训练阶段筛选的切片)、上下文引导预测(3个自建数据集)、时间序列问答(自建数据集)。
- 输出模型:仅微调Transformer层,得到最终模型ChatTime-1-7B-Chat。
三、实验设计与结果
1. 实验设置
- 硬件:单NVIDIA GeForce RTX 4090显卡,借助Unsloth工具实现训练。
- 参数:持续预训练与指令微调均用4位量化模型+LoRA(rank=8,alpha=16),批处理大小256(梯度累积32),预训练2轮(8K步),微调4轮(1.6K步)。
2. 零样本时间序列预测(ZSTSF)
- 数据集:8个真实基准数据集(4个ETT数据集+Electric、Exchange、Traffic、Weather),涵盖能源、金融、交通、气候4领域。
- 基线模型:分两类------单数据集固定窗口模型(DLinear、iTransformer、GPT4TS、TimeLLM);零样本基础模型(TimeGPT、Moirai、TimesFM、Chronos)。
- 结果(表4) :
- ChatTime仅用4%预训练数据,达到SOTA模型Chronos 99.9%的零样本预测精度。
- 相比单模态全样本模型,达到SOTA模型GPT4TS 90.9%的精度。
- 平均MAE为0.2515,平均排名4.4688,在零样本模型中表现优异。
3. 上下文引导时间序列预测(CGTSF)
- 数据集:自建3个多模态数据集------墨尔本太阳能发电(MSPG)、伦敦电力使用(LEU)、巴黎交通流量(PTF),包含时间序列与文本辅助信息(背景、天气、日期,无未来信息泄露)。
- 基线模型:在ZSTSF基线基础上增加TGForecaster(支持文本信息),并设置无文本输入的ChatTime-作为对比。
- 结果(表5) :
- ChatTime平均MAE 0.5884,平均排名2.5833,优于所有基线,包括数据集专用模型与零样本模型。
- ChatTime显著优于ChatTime-,证明文本上下文对预测的辅助作用;且超越TGForecaster,体现双模态融合优势。
4. 时间序列问答(TSQA)
- 数据集:基于4类时间序列特征(趋势、波动性、季节性、异常值),用KernelSynth生成变长问答数据集,排除微调用样本作为测试集。
- 基线模型:通用预训练LLM(GPT4、GPT3.5、GLM4、LLaMA3-70B)。
- 结果(表6) :
- ChatTime平均准确率0.7605,平均排名1.0,远超所有通用LLM(平均准确率最高的GPT4仅0.5567)。
- 在4类特征问答中均表现最优,证明其对时间序列特征的理解能力。
5. 消融实验(图2)
验证模型关键设计的必要性:
- 无自回归持续预训练(w/o AR):零样本推理能力大幅下降,虽在CGTSF和TSQA略有提升,但模型难以掌握时间序列基础特征。
- 无切片聚类(w/o CL):用随机采样的低质量切片,模型对时间序列理解不足,三类任务性能均下降,且易过拟合。
- 无文本问答微调(w/o TQA):模型推理能力受损,三类任务性能下降,尤其在多模态任务(CGTSF、TSQA)中更明显。
四、数据集贡献
为填补多模态时间序列数据空白,构建4个数据集:
- 上下文引导预测数据集(3个):MSPG(15分钟粒度,太阳能发电)、LEU(30分钟粒度,家庭用电)、PTF(1小时粒度,交通流量),均包含时间序列与对齐的文本辅助信息。
- 时间序列问答数据集:涵盖4类特征(趋势、波动性、季节性、异常值),每类特征3个类别,时间序列切片长度为64、128、256、512,共48000样本。
五、结论与未来展望
1. 结论
- 提出的ChatTime模型,通过将时间序列视为"外语",实现了零样本推理与双模态输入输出,在ZSTSF、CGTSF、TSQA三类任务中均表现优异。
- 大幅降低训练成本(训练token仅1B,表1),同时保留文本处理能力,相比现有模型更高效、通用。
- 构建的4个多模态数据集,为后续研究提供了重要资源。
2. 未来方向
- 利用更多数据与计算资源,进一步提升模型性能,探索模型饱和状态。
- 扩展适用任务范围,如时间序列异常检测、分类、总结等。
六、关键对比与优势(表1)
| 模型 | 零样本预测 | 缺失值支持 | 训练token | 可训练参数 |
|---|---|---|---|---|
| TimesFM | ✓ | ✗ | 3T | 200M |
| Moirai | ✓ | ✓ | 150B | 300M |
| TimeGPT | ✓ | ✓ | 100B | 未知 |
| MOMENT | ✗ | ✓ | 100B | 300M |
| Timer | ✗ | ✗ | 50B | 50M |
| Chronos | ✓ | ✓ | 25B | 700M |
| ChatTime | ✓ | ✓ | 1B | 350M |
ChatTime在训练成本(训练token仅1B)、功能完整性(零样本+缺失值支持+双模态)上综合优势显著。