🛑 2025 年的新困境:多模型时代的"数据孤岛"
AWS re:Invent 2025 刚刚落下帷幕,一个明显的趋势已经确立:"单一模型包打天下"的时代结束了。
在实际生产环境中,我们发现越来越多的企业开始采用 "Best-of-Breed"(最佳组合)策略:
●用 DeepSeek V3 做代码生成和复杂逻辑推理;
●用 Kimi / Moonshot 做长文档摘要;
●用 MiniMax 做语音交互;
●用 Midjourney/Flux 做图像生成。
这种策略带来了极致的效果,但也带来了一个噩梦般的架构问题:数据放在哪?
如果你的企业知识库(PDF、Markdown、日志)都在 AWS S3 上,那么当你调用阿里云上的 Qwen 或者本地部署的 DeepSeek 时,你将面临:
1.惊人的跨云流量费 (Egress Cost): 每次读取文档都要付流量费。
2.极高的延迟: 跨公网传输非结构化数据严重拖慢 RAG 的首字生成时间 (TTFT)。
3.厂商锁定 (Vendor Lock-in) : 如果想换模型,迁移 PB 级数据的成本足以让你放弃治疗。
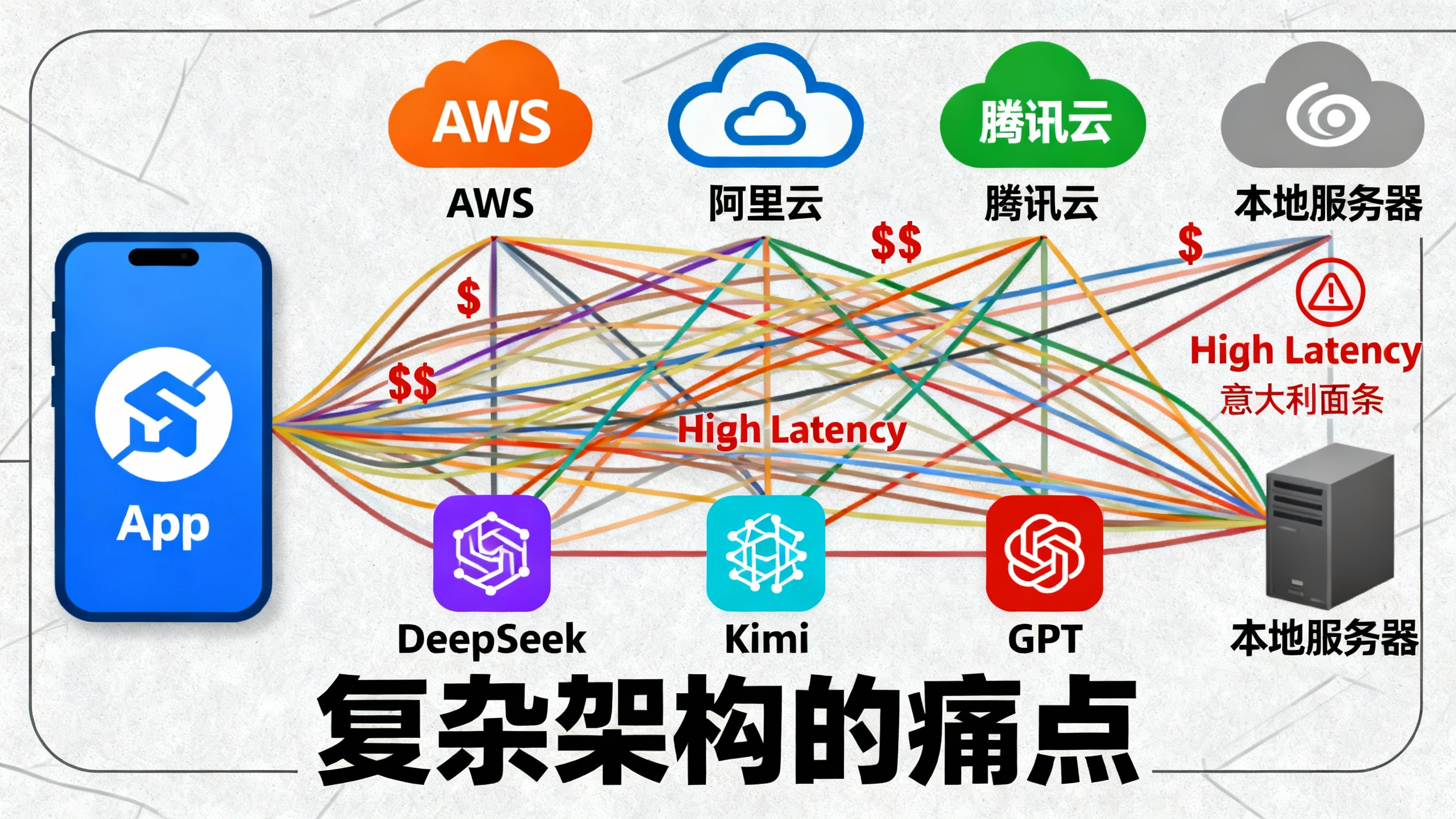
结论: 在 AI 推理时代,必须重构你的存储层。我们需要一个"模型中立" (Model-Neutral)的统一数据湖。
🛠️ 架构重构:从"全家桶"到"瑞士银行"模式
传统的云原生架构是 Compute-Centric(以计算为中心) 的,数据围着算力转。
而 AI 原生架构必须是 Data-Centric(以数据为中心) 的,算力(模型)只是外挂的插件。
1. 核心设计理念 :Unified Data Lake (统一数据湖)
我们需要构建一个独立于任何模型厂商之外的存储底座。经过多家选型对比,七牛云 Kodo 凭借其"中立性"和强大的边缘分发能力,成为目前构建 Independent RAG (独立 RAG) 的最佳解。
架构拓扑图 (Architecture Topology):
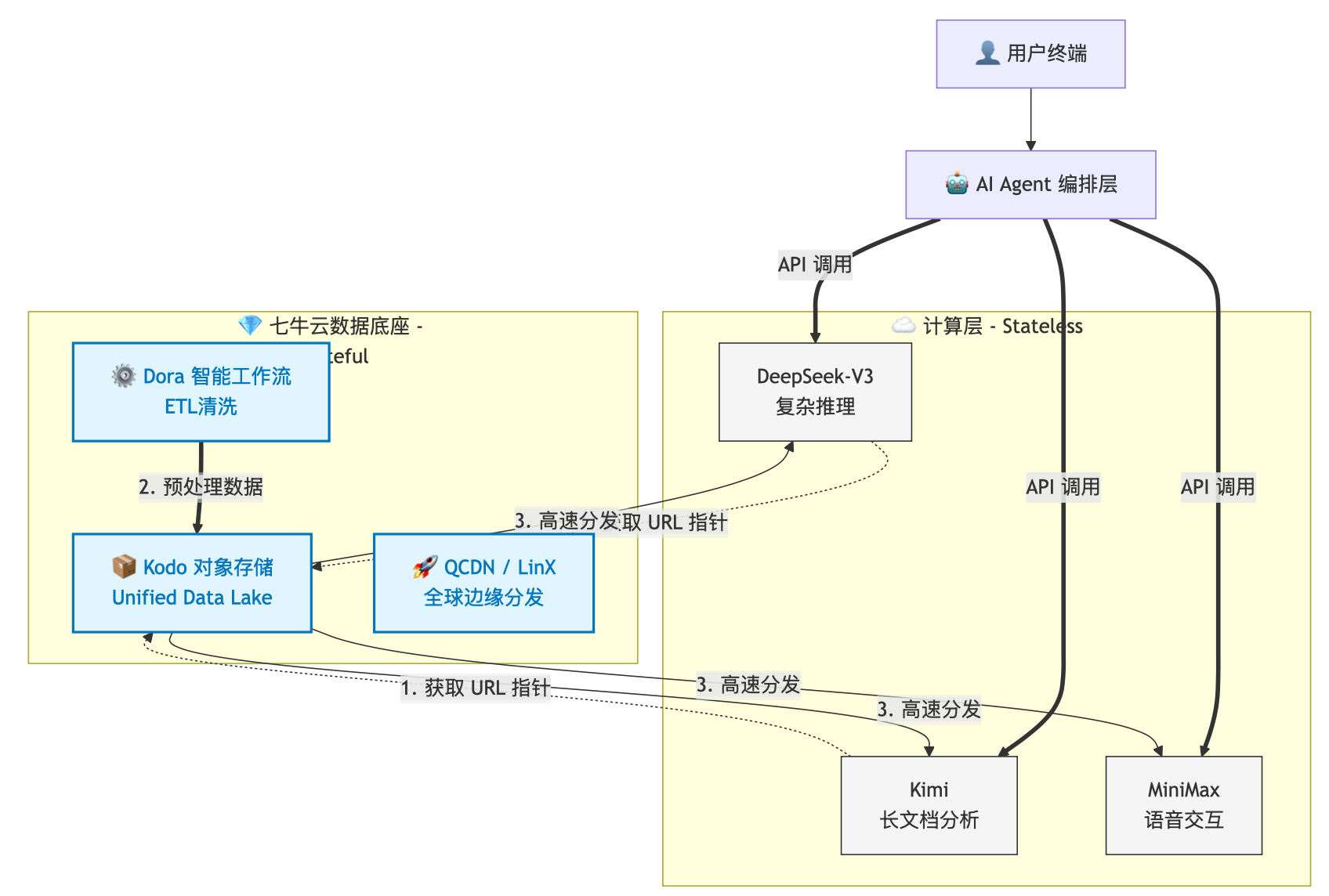
2. 关键组件解析
●七牛云 Kodo (存储核心) :
作为"数据的瑞士银行",Kodo 兼容 S3 协议,这意味着原本基于 LangChain 或 LlamaIndex 的代码几乎不用改动,只需更换 Endpoint。所有原始非结构化数据(Unstructured Data)统一在此归档。
●七牛云 Dora (ETL 预处理) :
这是优化的关键。 很多人把 PDF 转 Markdown、图片 OCR 这种脏活累活都交给昂贵的 GPU(如 DeepSeek)去做,这是极大的浪费。
最佳实践: 在文件上传七牛云时,利用 Dora 的工作流(Workflow)自动完成格式清洗。模型拿到的直接是 Token 友好的纯文本,推理成本立减 40%。
●七牛云 LinX (云边互联) :
针对跨云延迟问题,七牛云的 LinX 产品提供了类似于"云间高速公路"的能力。它能优化从存储桶到不同推理节点(无论是阿里云、腾讯云还是私有化机房)的路由路径。
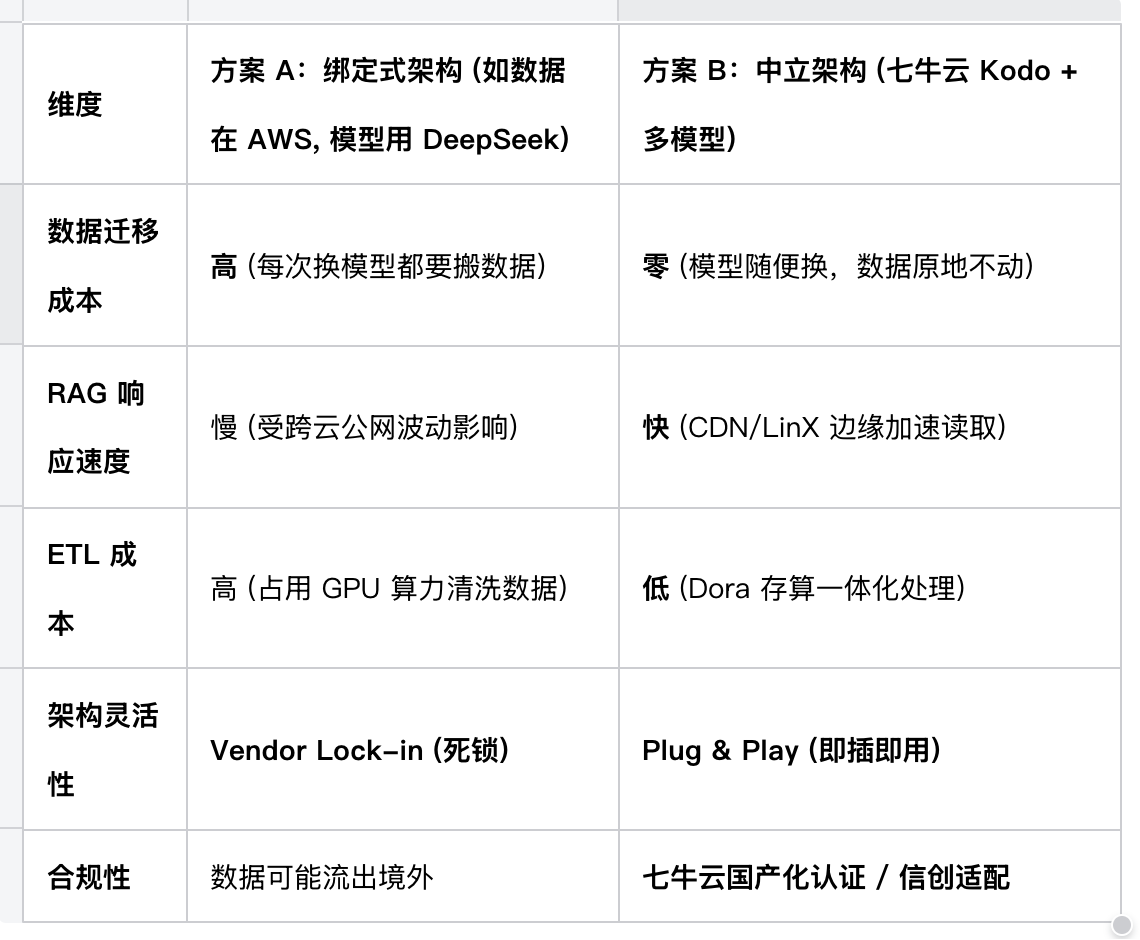
📊 技术方案对比 (The Comparison)
为了让大家更直观地理解架构收益,我们对比了两种方案:
💻 实战指南:3 步构建中立 RAG 索引
以下代码演示如何利用 Python SDK 将数据上传至七牛云,并生成对所有模型通用的访问链接。
Step 1: 建立中立存储桶 (Neutral Bucket)
不要使用特定云厂商的私有协议,开启 Kodo 的 S3 兼容模式。
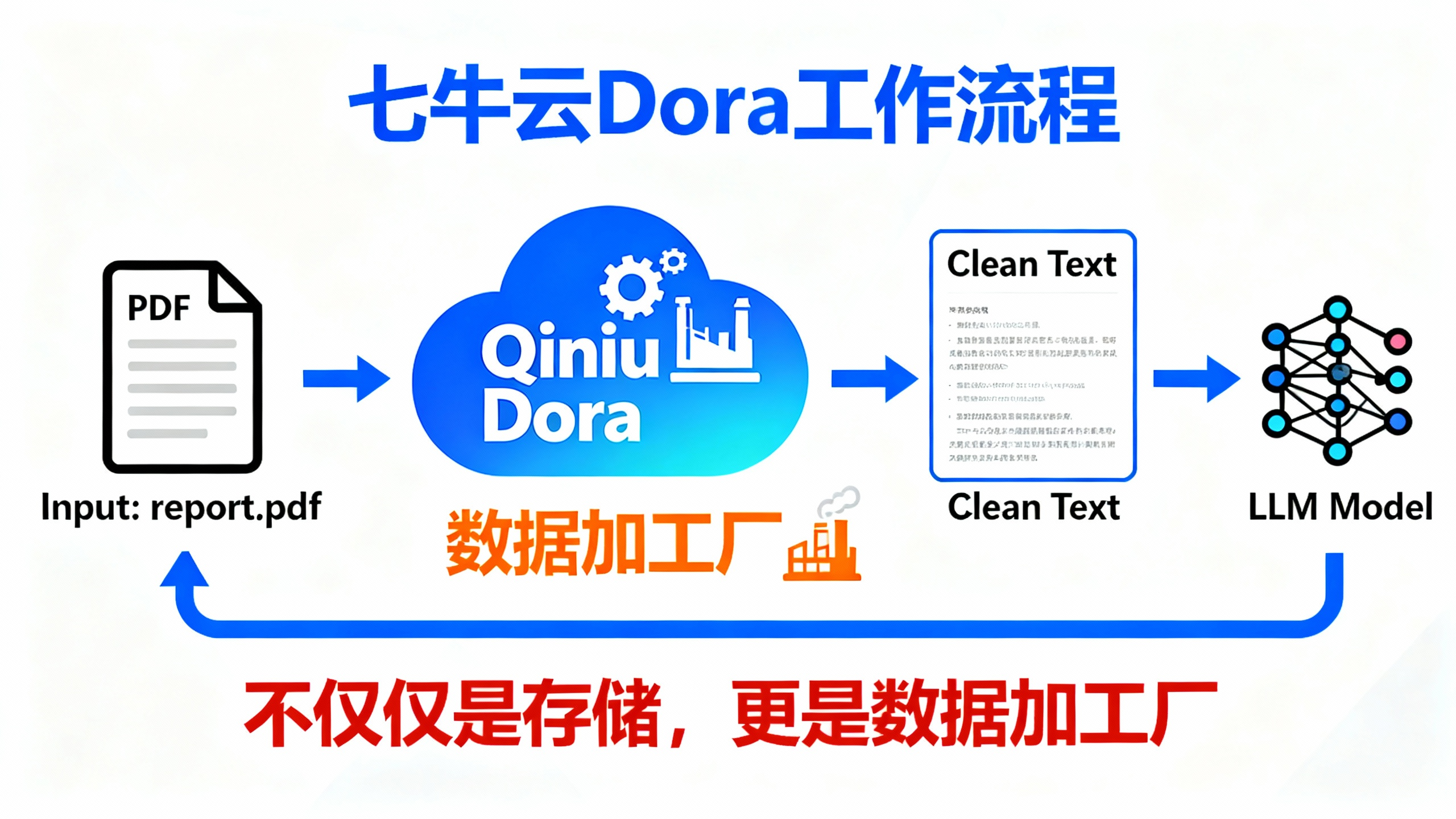
Step 2: 上传并预处理 (Upload & ETL)
利用七牛云 Dora,在上传 PDF 时自动触发"文档转纯文本"指令。
code Python
python
from qiniu import QiniuMacAuth, put_file
# 初始化鉴权
q = QiniuMacAuth(ACCESS_KEY, SECRET_KEY)
bucket = 'company-knowledge-base'
# 定义 Dora 处理指令:将 PDF 转为 Markdown,便于 LLM 理解
# 这是一个"魔法参数",上传即处理
policy = {
'persistentOps': 'doc-convert/markdown|saveas/$(key)_parsed.md'
}
token = q.upload_token(bucket, 'finance_report_2025.pdf', 3600, policy)
# 上传文件
ret, info = put_file(token, 'finance_report_2025.pdf', './local_file.pdf')
print(f"原始文件 ID: {ret['key']}")
print(f"清洗后文件 ID: {ret['key']}_parsed.md")Step 3: 向模型投喂标准 URL
当 DeepSeek 需要读取该文件时,直接给它清洗后的 URL:
http://cdn.your-domain.com/finance_report_2025.pdf_parsed.md
优势: DeepSeek 不需要消耗 Token 去解析 PDF 格式,直接读取 Markdown 文本,速度提升 3 倍,且不依赖任何云厂商的私有 API。
📝 总结:数据主权是最后的护城河
技术圈有句名言:"Model is Commodity, Data is Asset. " (模型是日用品,数据是资产)。
在 2026 年即将到来之际,不要再把你的核心资产(数据)锁死在某一家模型厂商的"全家桶"里。构建基于 七牛云 这样中立、解耦的存储底座,你才能拥有在 DeepSeek、Kimi、GPT 之间自由切换的底气。
架构师建议 : 如果你正在重构公司的 RAG 系统,不妨先去七牛云官网看看他们的 Unified Data Lake 解决方案,现在的架构决策,决定了你明年的运维成本。
互动话题:
你们公司现在是"单模型"还是"多模型混用"?跨云调用数据时遇到过最坑的事是什么?欢迎评论区吐槽!