目录
[5.1 定义](#5.1 定义)
[5.2 组成](#5.2 组成)
[5.3 方法区内存溢出](#5.3 方法区内存溢出)
[5.4 运行时常量池](#5.4 运行时常量池)
[5.5 StringTable(串池)](#5.5 StringTable(串池))
[5.6 StringTable特性](#5.6 StringTable特性)
[5.7 StringTable位置](#5.7 StringTable位置)
[5.8 StringTable垃圾回收](#5.8 StringTable垃圾回收)
[5.9 StringTable性能调优](#5.9 StringTable性能调优)
[6.1 定义](#6.1 定义)
[6.2 基本使用](#6.2 基本使用)
[6.3 内存溢出(OOM)](#6.3 内存溢出(OOM))
[6.4 释放原理(重点)](#6.4 释放原理(重点))
[6.5 禁用显式回收对直接内存影响](#6.5 禁用显式回收对直接内存影响)
[1.1 引用计数法](#1.1 引用计数法)
[1.2 可达性分析算法](#1.2 可达性分析算法)
[1.3 五种引用](#1.3 五种引用)
[4.1 串行](#4.1 串行)
[4.2 吞吐量优先](#4.2 吞吐量优先)
[4.3 响应时间优先](#4.3 响应时间优先)
[4.4 G1](#4.4 G1)
[(2)Young Collection(年轻代收集)](#(2)Young Collection(年轻代收集))
[(3)Young Collection + CM(并发标记)](#(3)Young Collection + CM(并发标记))
[(4)Mixed Collection(混合收集)](#(4)Mixed Collection(混合收集))
[(5) FUll GC](#(5) FUll GC)
[(6)Young GC(跨代引用)](#(6)Young GC(跨代引用))
[① 为什么会有"跨代引用"](#① 为什么会有“跨代引用”)
[② 卡表(Card Table)------"老年代→新生代"的 粗粒度地图](#② 卡表(Card Table)——“老年代→新生代”的 粗粒度地图)
[③ 后置写屏障(Post-Write Barrier)+ 脏卡队列](#③ 后置写屏障(Post-Write Barrier)+ 脏卡队列)
[④ Remembered Set(RSet)------"卡表→Region"的 精确定位](#④ Remembered Set(RSet)——“卡表→Region”的 精确定位)
[⑤ Young GC 时的工作流程(结合图)](#⑤ Young GC 时的工作流程(结合图))
[① 问题背景:并发标记时对象图还在变](#① 问题背景:并发标记时对象图还在变)
[② SATB(Snapshot-At-The-Beginning) 思路](#② SATB(Snapshot-At-The-Beginning) 思路)
[③ 预写屏障(Pre-Write Barrier)(底层实现)](#③ 预写屏障(Pre-Write Barrier)(底层实现))
[④ SATB 标记队列(SATB Mark Queue)→ 全局队列](#④ SATB 标记队列(SATB Mark Queue)→ 全局队列)
[⑤ 时间线(配合图)](#⑤ 时间线(配合图))
[(9)JDK 8u40 并发标记类卸载](#(9)JDK 8u40 并发标记类卸载)
[(10)JDK 8u60 回收巨型对象](#(10)JDK 8u60 回收巨型对象)
一.JVM内存结构
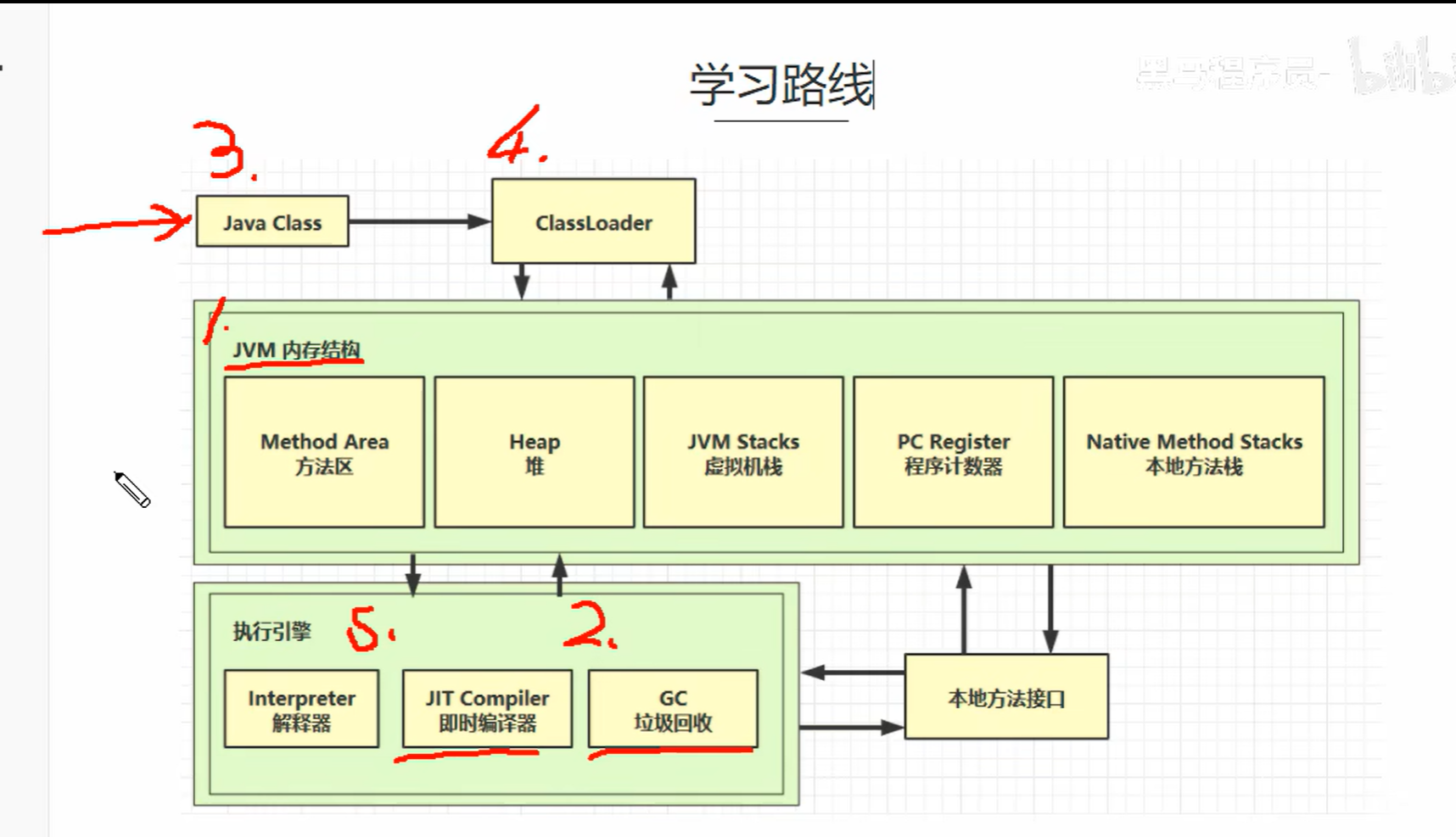
| 区域 | 线程私有? | 说明 | 生命周期 |
|---|---|---|---|
| PC 寄存器(Program Counter) | ✅ | 当前字节码行号 | 与线程同生同灭 |
| Java 虚拟机栈(Java Stack) | ✅ | 局部变量、操作数栈、方法出口 | 与线程同生同灭 |
| 本地方法栈(Native Method Stack) | ✅ | JNI native 方法用的 C 栈 | 与线程同生同灭 |
| 堆(Heap) | ❌ | 所有对象实例、数组 | JVM 启动到退出 |
| 方法区(Metaspace / PermGen) | ❌ | 类元数据、常量池、静态变量 | JVM 启动到退出 |
| 直接内存(Direct Memory) | ❌ | ByteBuffer.allocateDirect、NIO 映射 | JVM 启动到退出 |

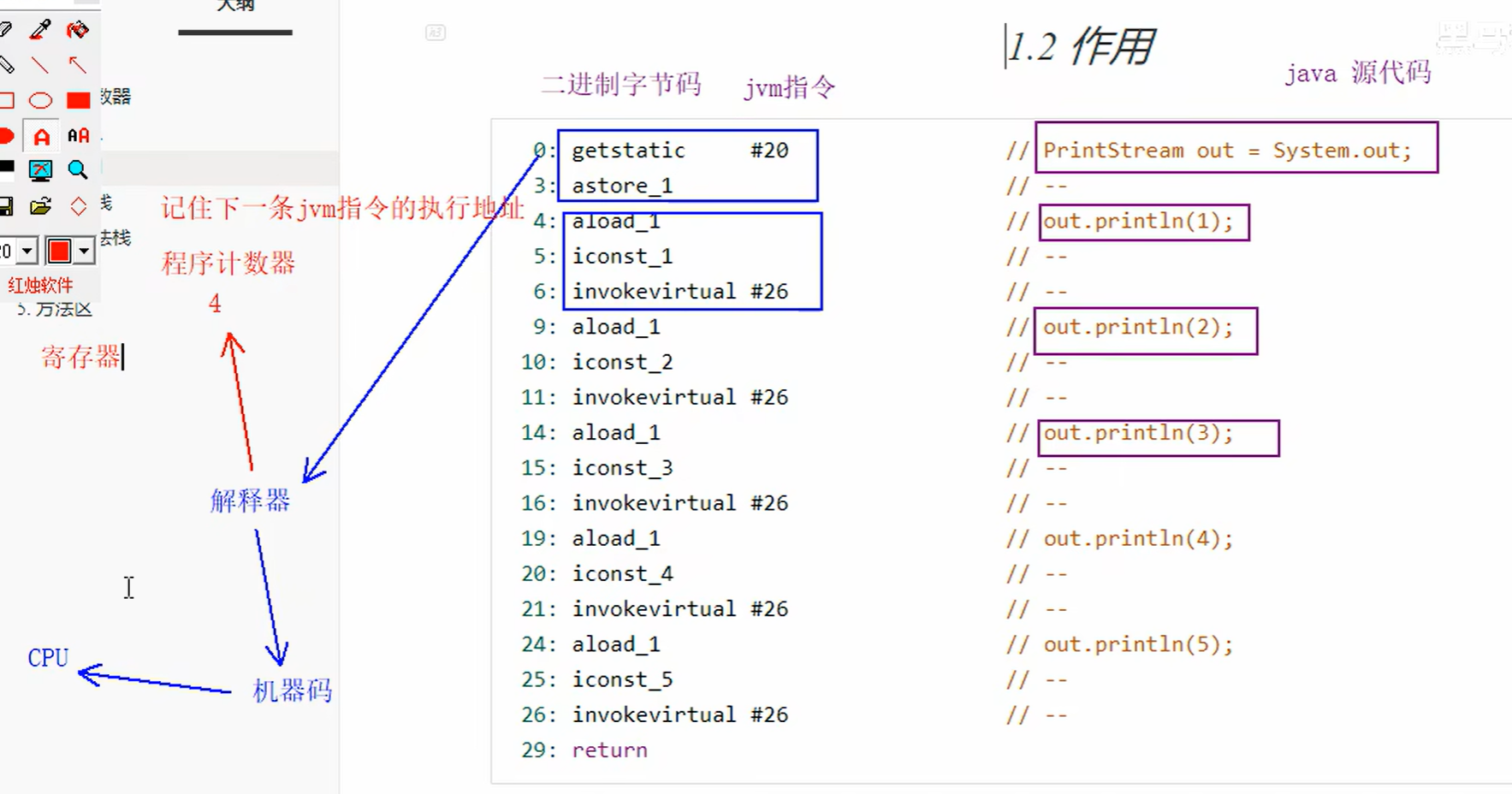
1.程序计数器
定义
作用
2.虚拟机栈
2.1定义

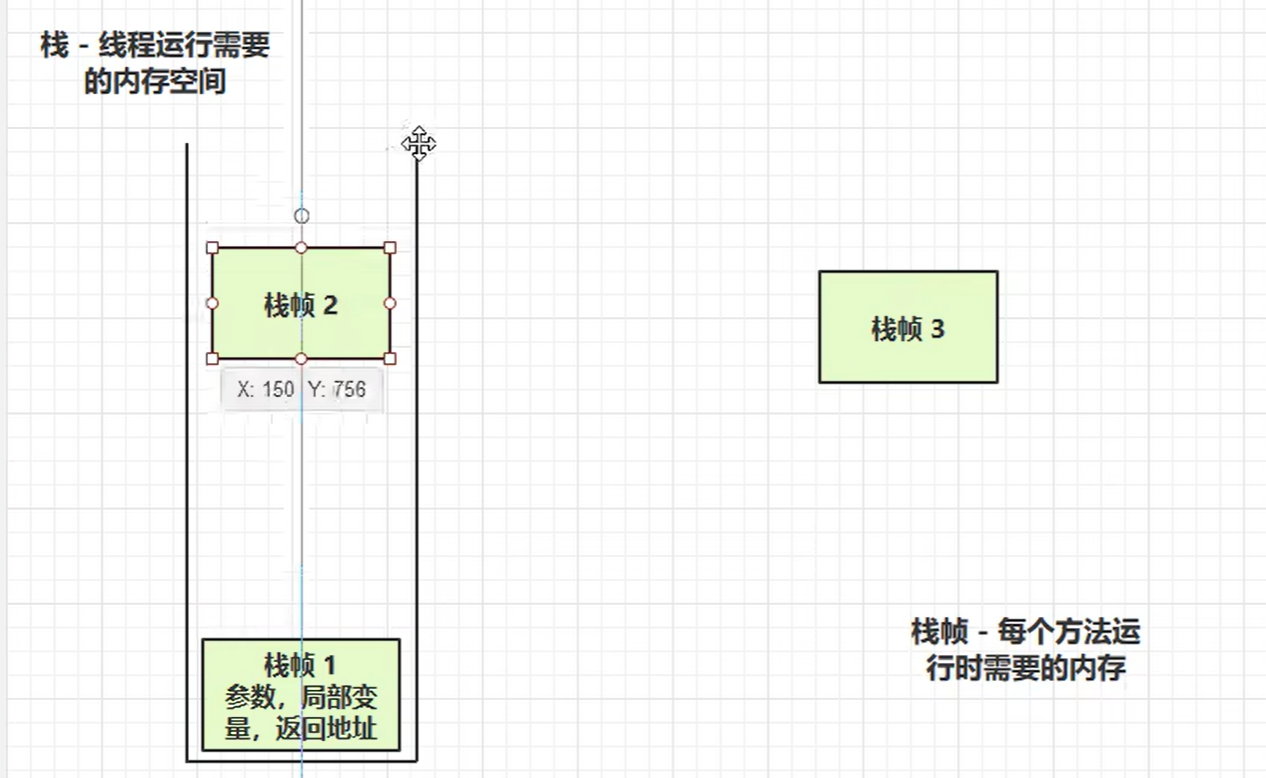
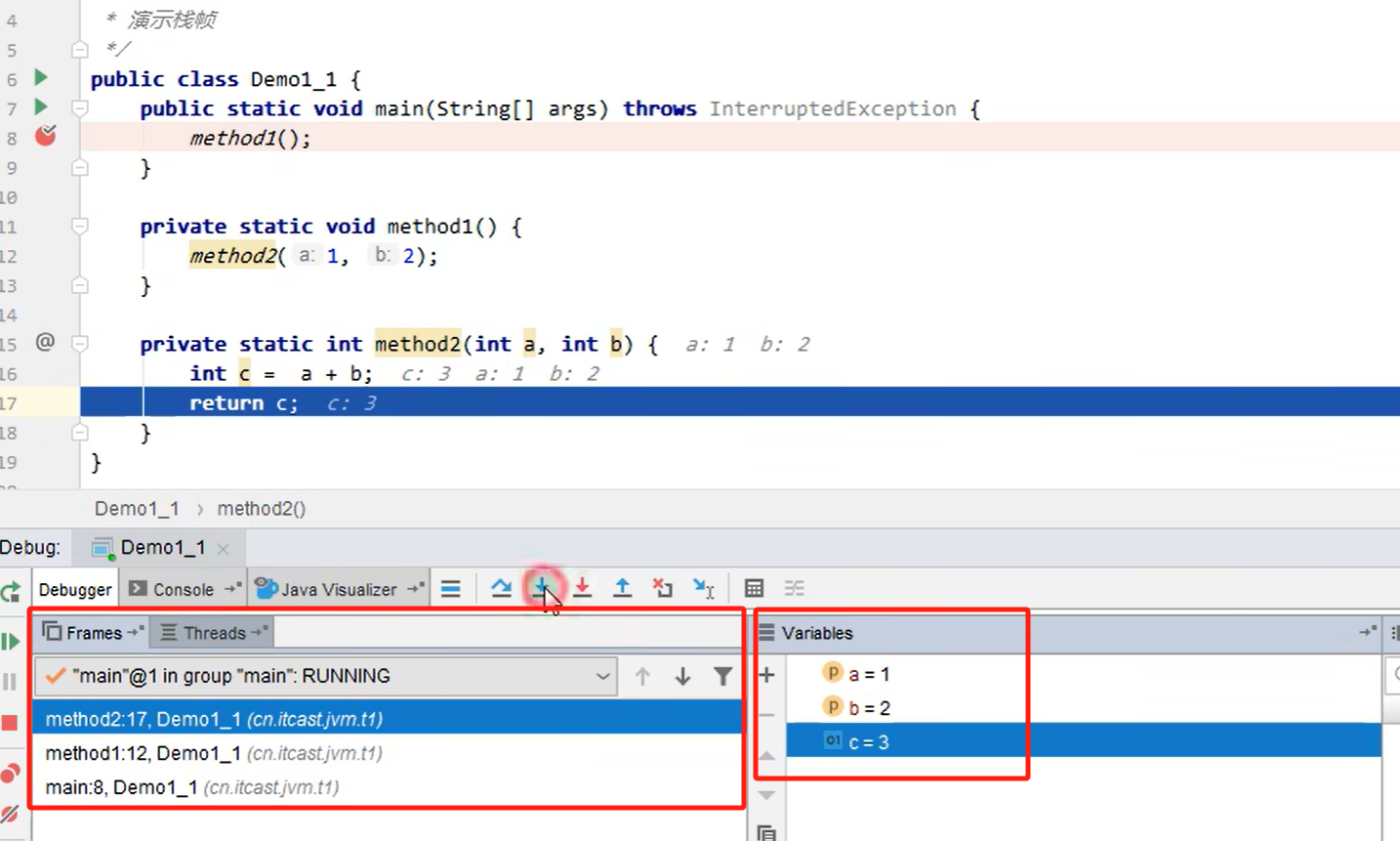
栈顶部的栈帧就是活动栈帧
2.2问题辨析(线程安全)

垃圾回收不涉及栈内存: 栈帧(方法调用的内存块)随方法调用而创建,随方法结束而自动销毁(由编译器预设的字节码指令控制,无需GC干预)。
栈内存分配不是越大越好: 栈内存是"线程私有的、一次性全额申请、生命周期同线程、永不归还"的内存 。它不像堆那样"按需分配、GC 回收",所以给得越大,只是白白预占、浪费、甚至直接创不出线程。
2.3栈内存溢出

2.4线程运行判断

3.本地方法栈

4.堆

堆内存溢出
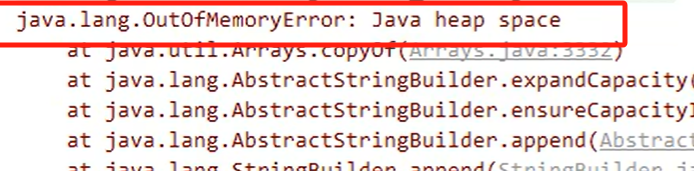
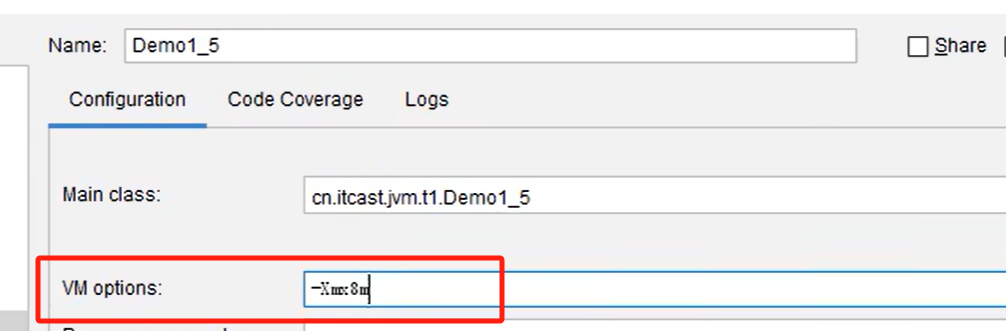
可通过设置较小的堆内存加速问题的排查
堆内存诊断

5.方法区
5.1 定义
方法区域是 JVM 中的一个逻辑内存区域,用于存储每个类的相关结构,例如运行时常量池、字段和方法数据、方法和构造函数的代码,以及类执行所需的其他元数据。
5.2 组成
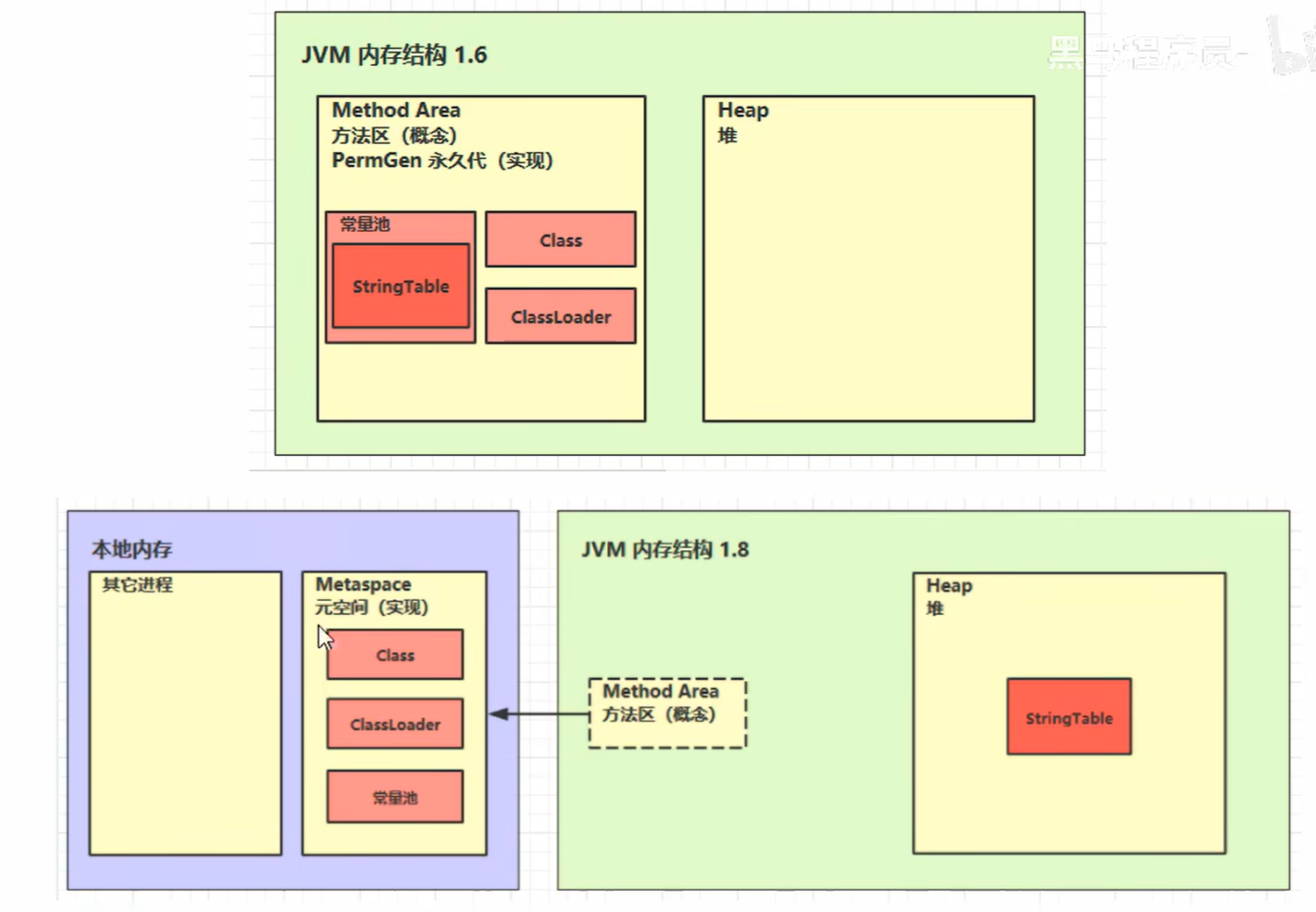

5.3 方法区内存溢出
方法区(Java 8 以后叫 Metaspace )存的是"类的元数据"------类名、字段、方法、字节码、常量池、注解、JIT 编译后的机器码等。
"方法区内存溢出" 就是这片区域被撑爆,JVM 无法再加载/扩展类信息,于是抛出:
-
Java 7 及之前:
java.lang.OutOfMemoryError: PermGen space永久代空间 -
Java 8 及之后:
java.lang.OutOfMemoryError: Metaspace元空间
场景 典型触发方式 观察指标 1. 动态类过多 多次 Class.forName、反射、代理、JSON/Bean 拷贝库(CGLIB、Objenesis、Javassist)、Groovy/Scala/Kotlin 脚本引擎、JSP 热加载加载类数( jstat -loader)持续上升,GC 不下降2. 热部署 / 热替换 Tomcat、Spring Boot DevTools、OSGi、Arthas retransform,旧 ClassLoader 应该被回收却还被引用 类加载器+类实例双重泄漏 3. 巨型常量池 代码里写了几万个 String s = "xxx"或static final String,或 MyBatis 拼接 SQL 用++拼出大量不同字面量常量池占 Metaspace 70 % 以上 4. JIT 代码缓存过大 -XX:ReservedCodeCacheSize太小,或大量 lambda/invokedynamic 生成巨量机器码Code Cache接近上限5. 框架 Bug 早期 Hibernate、Spring CGLIB 重复生成代理类未复用 同一接口出现 UserService$$EnhancerBySpringCGLIB$$a3c4d5f2几百次
5.4 运行时常量池

5.5 StringTable(串池)
5.6 StringTable特性

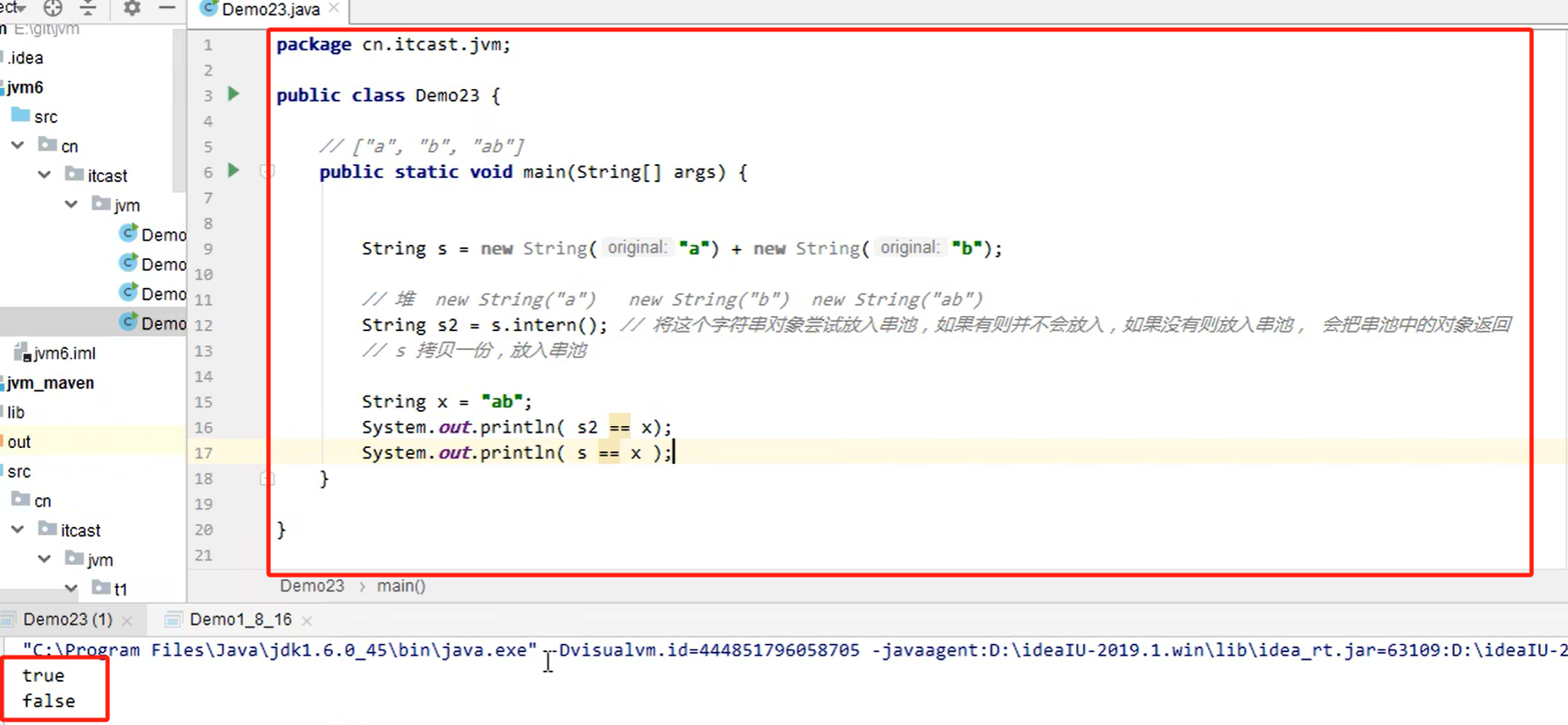
第一行:
读取到常量加入串池"a","b"
new了对象加入堆new String("a") new String("b") new String("ab")
s="ab"来自堆中
第二行:
s2=s.intern由于串池中没有"ab",将堆中"ab"加入串池并返回给s2(1.8版本)
String x="ab"由于串池中已经存在"ab"所以直接取串池中的
s2==x 为ture s==x为ture
(1.6版本)s.intern在串池没有的情况下,会拷贝一个加入串池并返回
此时s2为串池中拷贝的,x取出串池中拷贝的"ab"与s不同
s2==x ture s==x false
5.7 StringTable位置
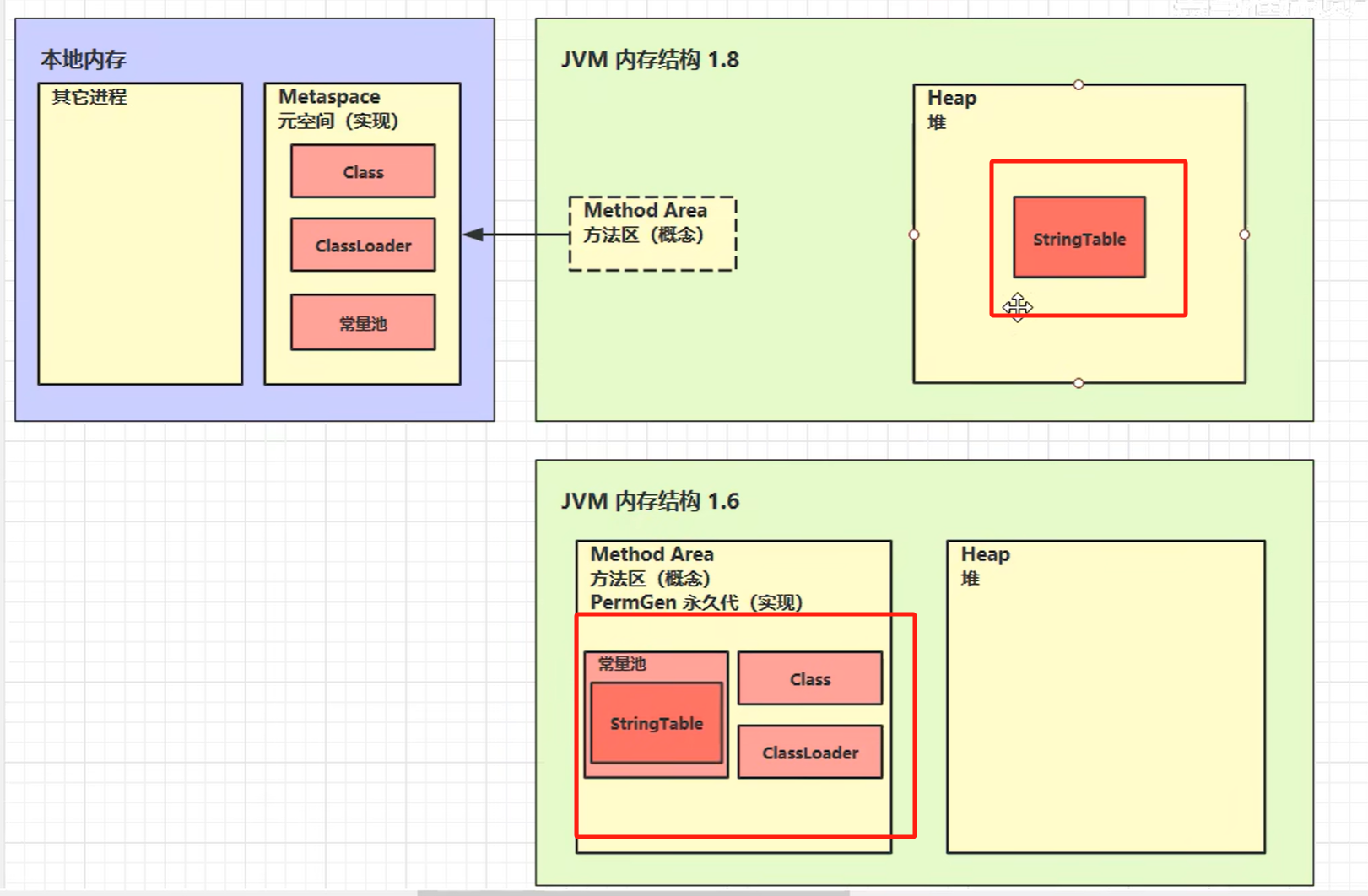
5.8 StringTable垃圾回收
| 版本 | 所在区域 | 触发 GC 类型 | 说明 |
|---|---|---|---|
| JDK≤6 | PermGen(永久代) | Full GC | 老年代或永久代不足时才触发,回收频率极低,容易堆积无用字符串。 |
| JDK≥7 | Java 堆 | Young GC / Full GC | 只要 Minor GC 发生就可能清理,回收及时性大幅提高。 |

5.9 StringTable性能调优
# 启动参数
-XX:StringTableSize=200003 # 桶数放大 3 倍
-XX:+PrintStringTableStatistics # 事后对账
-Xms4g -Xmx4g -XX:+UseG1GC # 保持 GC 轻快
# 代码模板
private static final Interner<String> POOL = WeakInterners.create();
String key = POOL.intern(raw); // 高重复但可丢弃用弱引用池口诀总结
"先监控、再桶数、后代码,GC 友好并发怕。"
只要 桶数 > 1.5 × 预计条目数 、不乱 intern() 、GC 健康 ,StringTable 就能一直保持 O(1) 的查询速度。
6.直接内存
6.1 定义
直接内存(Direct Memory)是 JVM 堆外 的一块内存区域,不在 Java 堆里 ,由操作系统直接分配和释放,Java 代码通过 sun.misc.Unsafe 或 java.nio.ByteBuffer.allocateDirect() 访问。
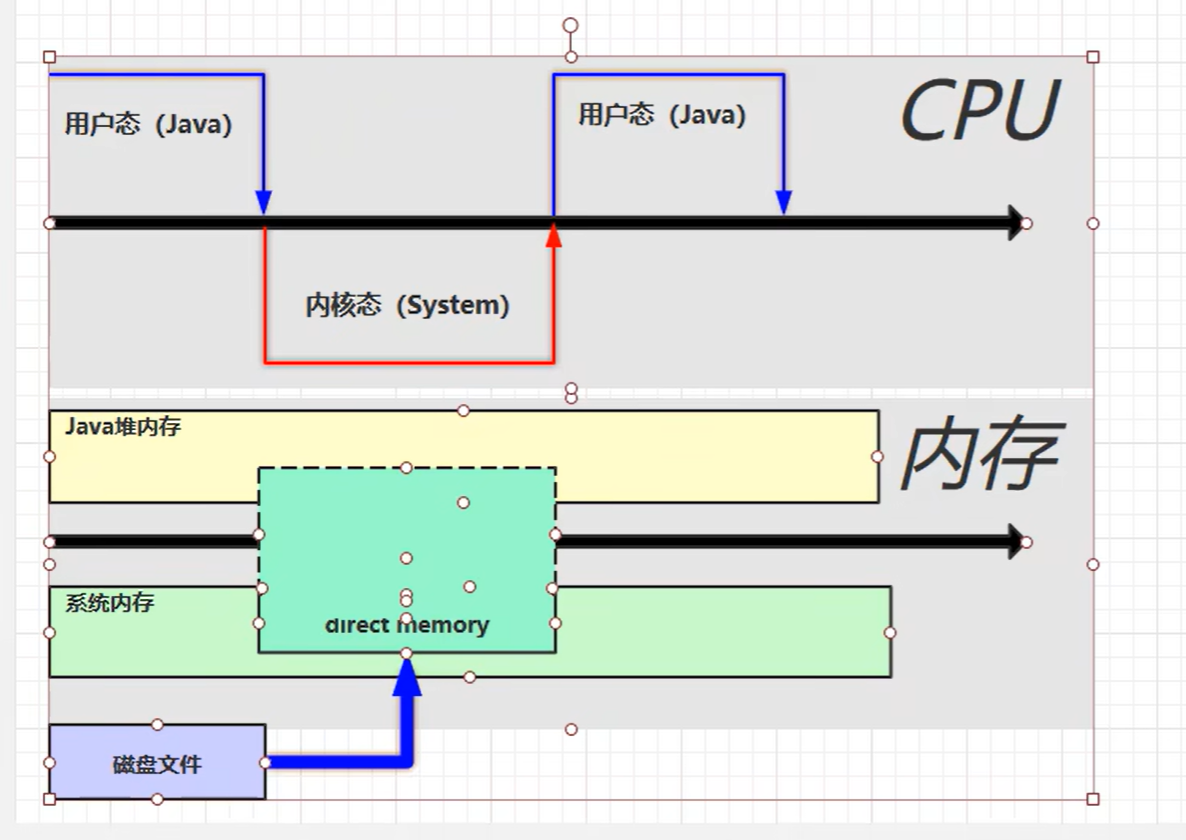
6.2 基本使用
最典型入口:
ByteBuffer.allocateDirect(size)→ 返回DirectByteBuffer对象。背后实现:
通过**
Unsafe.allocateMemory** 向操作系统malloc申请一块堆外 内存,地址存在address字段。使用场景:
NIO、Netty、Kafka、RocketMQ、G1 的巨型对象、零拷贝、JNI 库(TensorFlow、OpenCV)等。
优势:
不受
-Xmx限制,只在 MaxDirectMemorySize(默认 ≈ 堆大小)以内。省去一次 堆内↔堆外 拷贝,IO 性能高。
减轻 GC 压力(逻辑上不在 GC 堆)。
6.3 内存溢出(OOM)
异常信号:
java.lang.OutOfMemoryError: Direct buffer memory触发条件:
已分配量 ≥ MaxDirectMemorySize;
或 物理内存 + swap 被耗尽。
定位三板斧:
①
jmap -dump→ MAT / YourKit 看 DirectBuffer 对象个数;② NMT(Native Memory Tracking)
jcmd VM.native_memory summary;③
-XX:MaxDirectMemorySize=size调大做对比实验。常见代码级泄漏:
只
allocateDirect不release(Netty 未Unpooled.release);使用
FileChannel.map()反复映射文件,忘记unmap();JNI 库内部
malloc不报 JVM 账目。
6.4 释放原理(重点)

分配对象 vs 分配内存:
JVM 端 :
DirectByteBuffer实例(很小)仍在 Java 堆,受 GC 管理。OS 端 :真正的堆外页由
malloc/mmap完成,GC 不负责。两种回收路径:
显式 :
((DirectBuffer) buf).cleaner().clean()→Unsafe.freeMemory(address)立即归还 OS。依赖 GC(默认):
对象进入老年代 → Full GC 或
System.gc()触发 →Cleaner(PhantomReference)钩子执行 → 调用freeMemory。因此「堆越慢,直接内存越晚释放」。
关键源码:
jdk/internal/misc/Unsafe.allocateMemory
java.nio.DirectByteBuffer.Deallocator.run()
6.5 禁用显式回收对直接内存影响
参数:
-XX:+DisableExplicitGC(生产常用,防代码里频繁System.gc())。副作用:
直接内存的 Cleaner 钩子仍会被 Full GC 触发 ,但 Young GC 不再处理。
若应用从不触发老年代收集 (对象很快死亡或晋升阈值高),堆外内存可能长时间得不到释放,看起来就像"泄漏"。
官方建议:
开启
-XX:+DisableExplicitGC时,主动定期触发 Full GC 或 手动 clean;或者使用 Netty-4 的
-Dio.netty.maxDirectMemory=0让 Netty 自己管理计数并强制 clean;JDK 17+ 的 Foreign Memory API (
MemorySegment) 已支持 scoped 释放,无需依赖 GC。
二.垃圾回收
1.如何判断对象可以回收
1.1 引用计数法
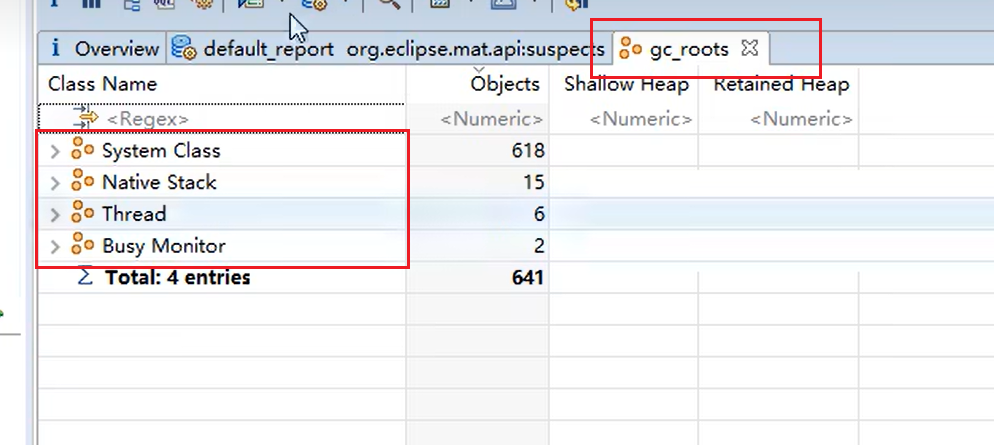
1.2 可达性分析算法
JVM 进行垃圾回收时,并不会一次性遍历整个堆,而是从这些 Roots 出发,标记所有仍然存活的对象 ;从 Roots 无法到达的对象,就被判定为"已死",可以回收。
MAT 中的名称 对应 JVM 内部概念 为什么能成为 Root System Class 由 Bootstrap/Extension 类加载器 加载的类(如 java.lang.*)这些类永远不会被卸载,其静态字段引用的对象始终存活。 Co Native Stack JNI 本地方法栈中的引用 本地 C/C++ 代码可能通过 JNI 访问 Java 对象,JVM 必须保证它们存活。 Thread 正在执行的 Java 线程 每个线程的 栈帧局部变量表 里的引用都是活的。 Busy Monitor 被 synchronized 加锁的对象(Monitor 入口集) 同步块还没退出,锁对象必须存活,否则解锁时会崩溃。
1.3 五种引用
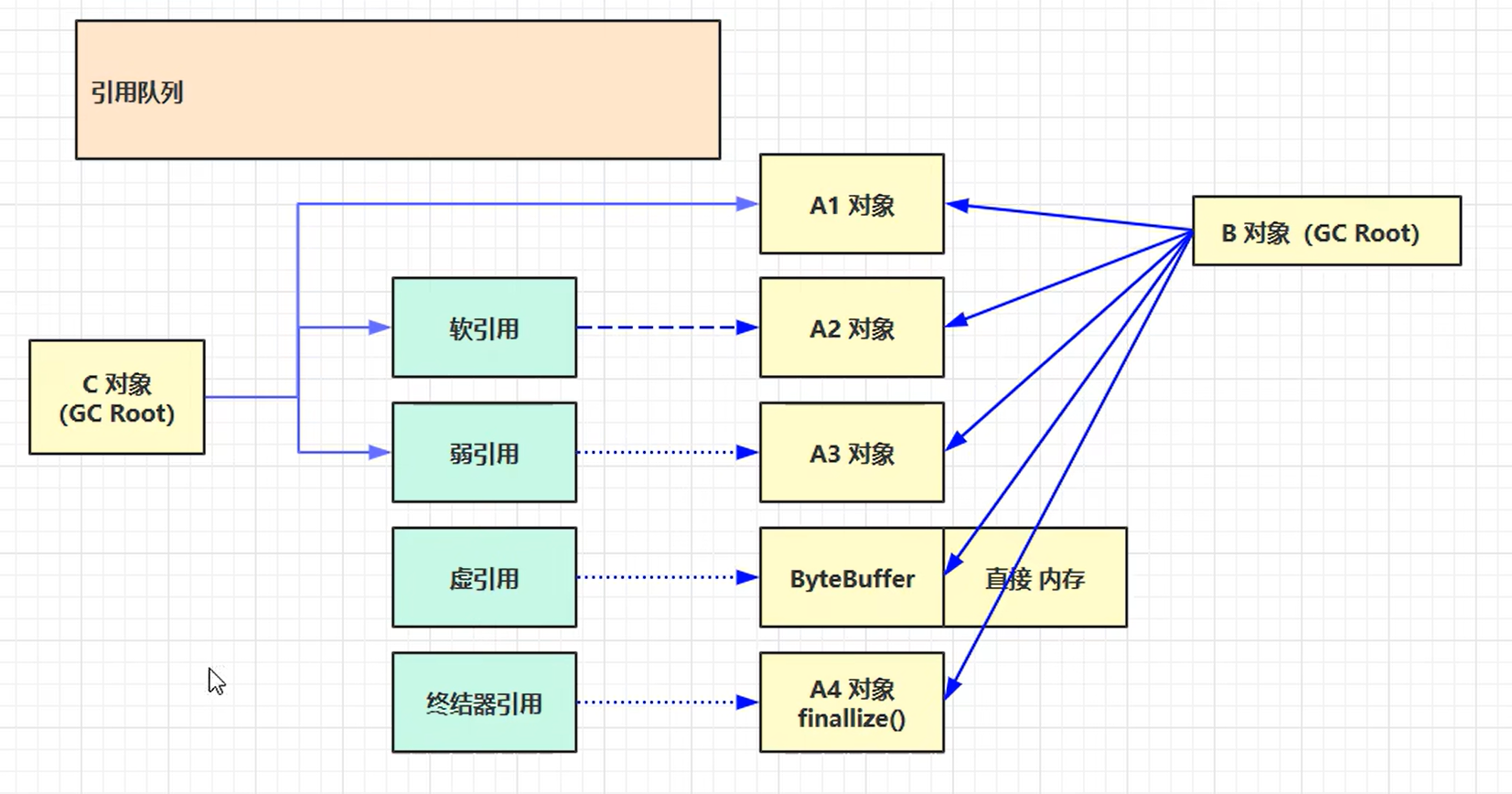
| 引用类型 | 类 | 回收时机 | 与队列配合 | 典型场景 |
|---|---|---|---|---|
| 强引 用 Strong | Object o = new Object() |
永远不会被 GC | 无 | 日常代码 |
| 软引用 Soft | SoftReference<Object>(obj) |
内存不足时(OOM 前) | 可以带队列,用于 缓存清理通知 | Guava 内存缓存、图片缓存 |
| 弱引用 Weak | WeakReference<Object>(obj) |
下一次 GC 无论内存够不够 | 必带队列 ,用于 清理通知 | ThreadLocalMap 的 key、WeakHashMap |
| 虚引用 Phantom | PhantomReference<Object>(obj, queue) |
对象已被回收后 (get() 永远 null) | 必须带队列 ,用于 回收后置动作 | DirectByteBuffer 堆外内存释放(Cleaner) |
| 终引用 Finalizer | (仅内部 FinalizerReference) |
第一次不可达 → 加入 Finalizer 队列 → 执行 finalize() → 再次 GC 才回收 | JVM 内部队列,开发者无感知 | 兼容历史 Object.finalize(),性能差,已废弃 |
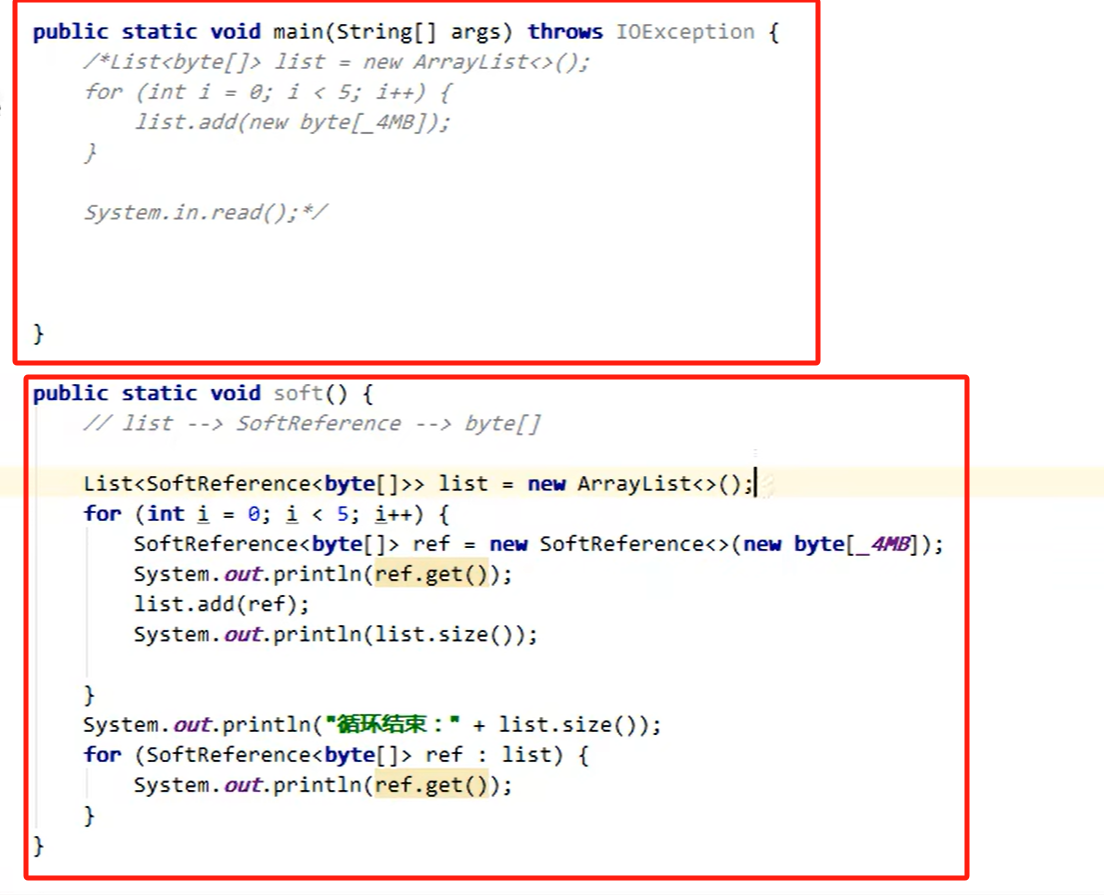
**方法1:**当List与byte 为强引用时,内存溢出不会执行GC垃圾回收。
方法2:当List强引用一个软引用对象,而软引用对象再引用byte 时,当内存不足时(OOM 前)执行GC
引用队列 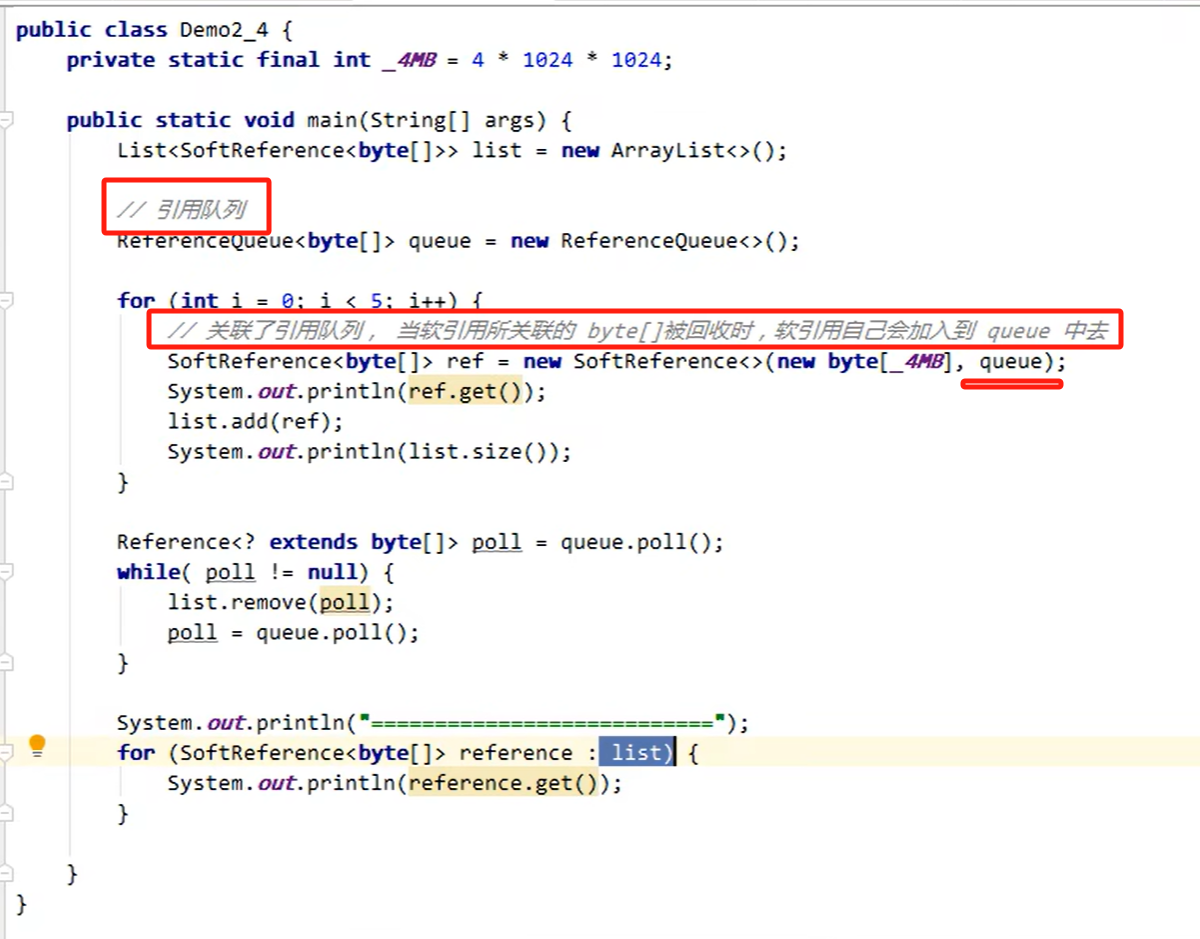
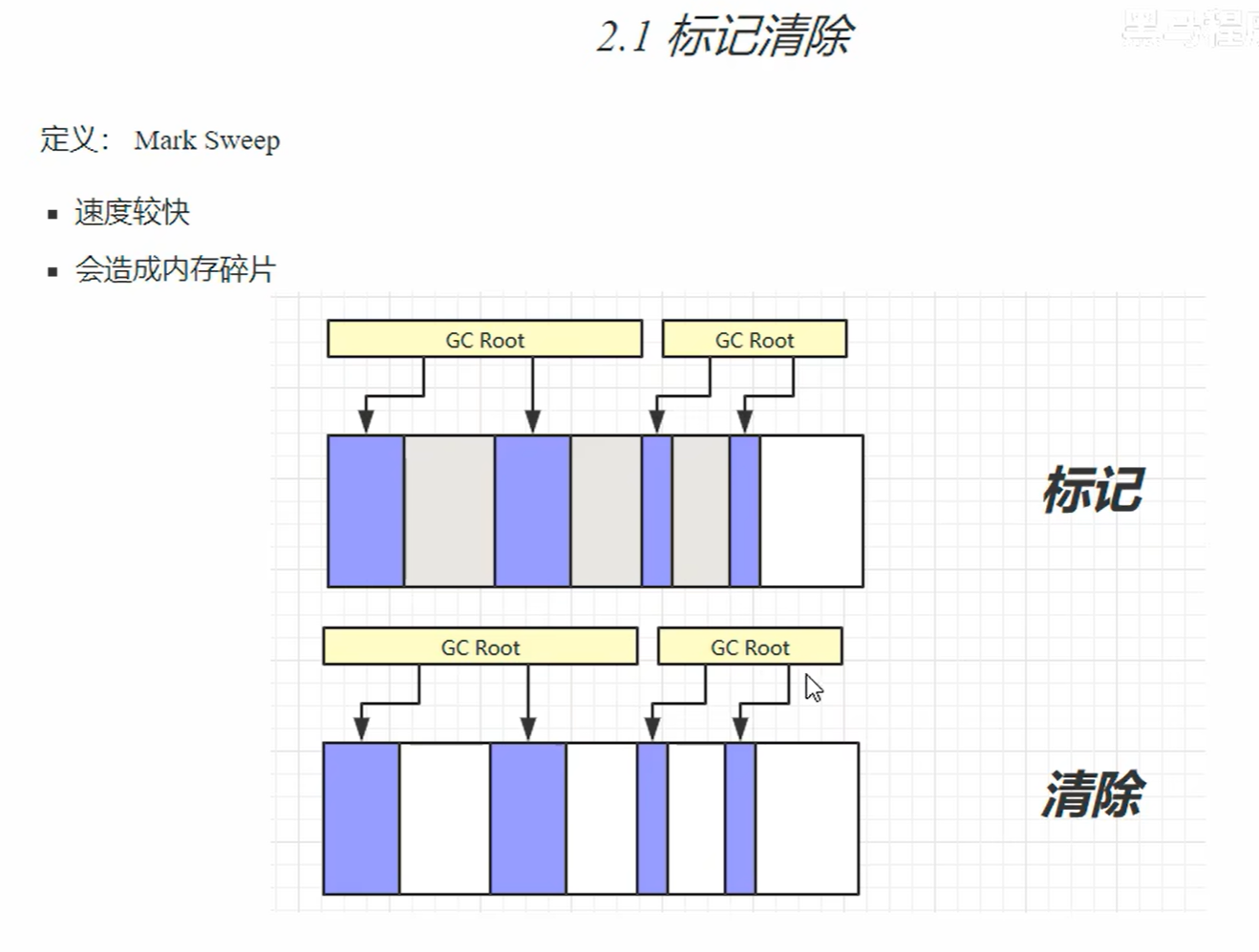
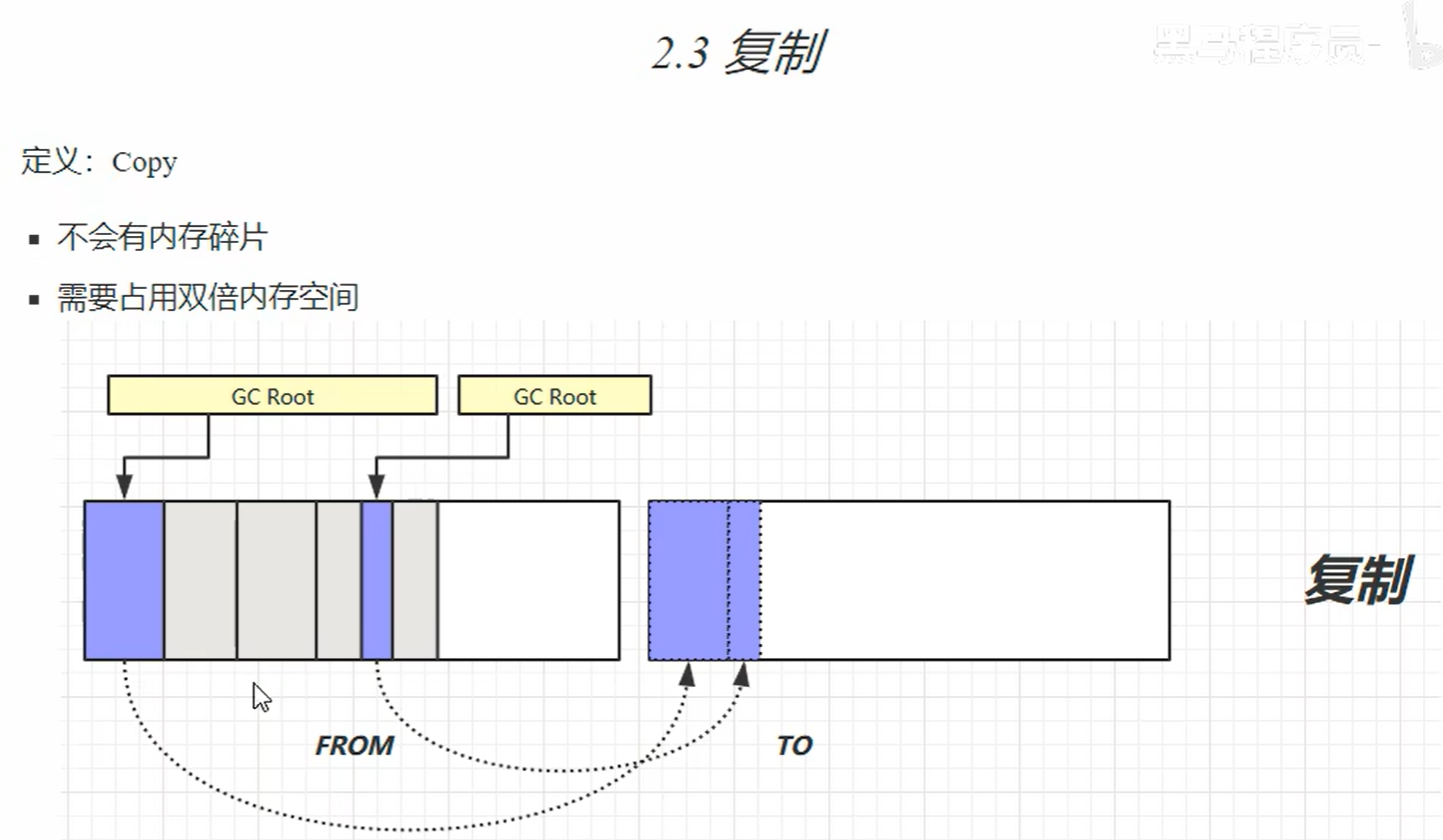
2.垃圾回收算法

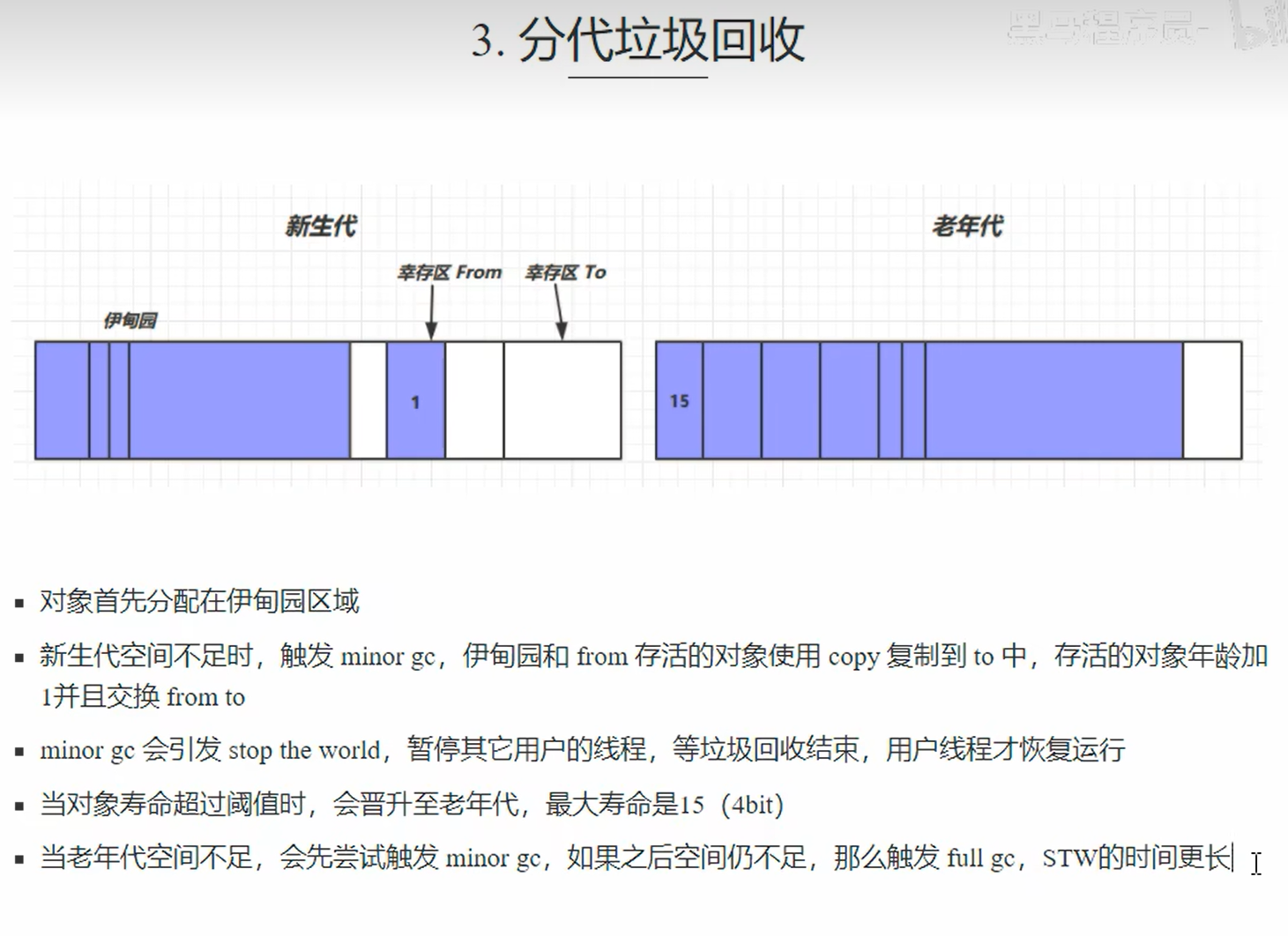
3.分代垃圾回收

4.垃圾回收器
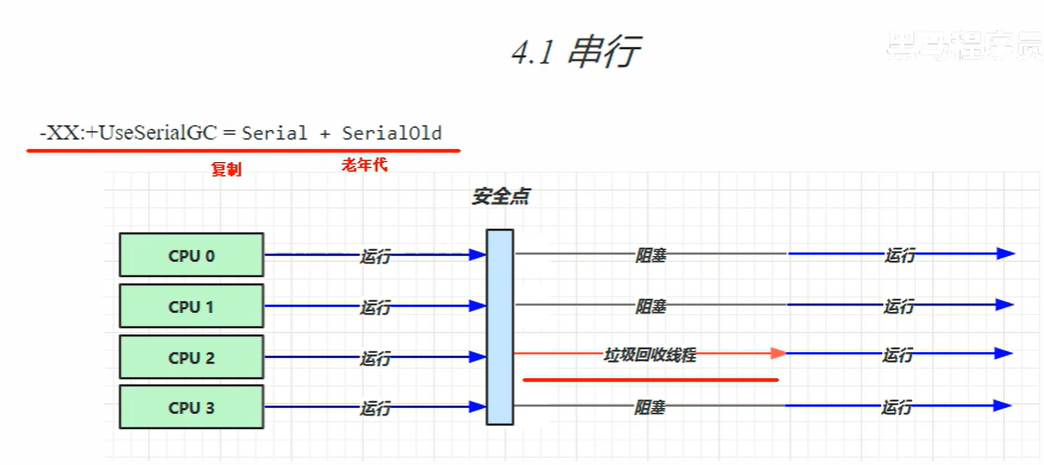
4.1 串行
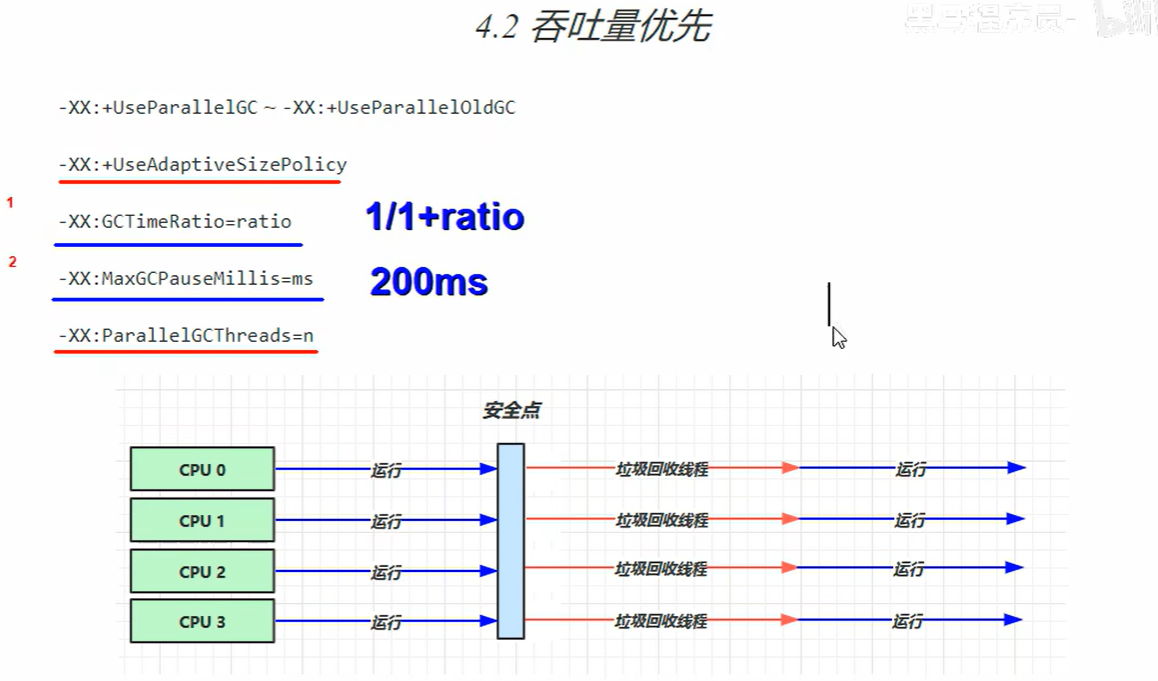
4.2 吞吐量优先
| 参数 | 含义 | 示例值 |
|---|---|---|
-XX:+UseParallelGC |
新生代用 Parallel Scavenge(并行复制) | 默认即开启 |
-XX:+UseParallelOldGC |
老年代用 Parallel Old(并行标记-整理) | 与上面配对 |
-XX:+UseAdaptiveSizePolicy |
自动调整新生代大小、Survivor 比例等,以达到目标停顿/吞吐量 | 默认开启 |
-XX:GCTimeRatio=ratio |
设定 吞吐量目标 :1 / (1 + ratio) 的时间用于 GC,默认 99 → 允许 1% 时间做 GC |
99 |
-XX:MaxGCPauseMillis=ms |
最大停顿时间目标(毫秒),软目标,JVM 会尽量缩小新生代来缩短停顿 | 200 |
-XX:ParallelGCThreads=n |
GC 线程数,默认 = CPU 核心数,可手动减少避免抢占业务线程 | n |
吞吐量和停顿时间为相反的目标。
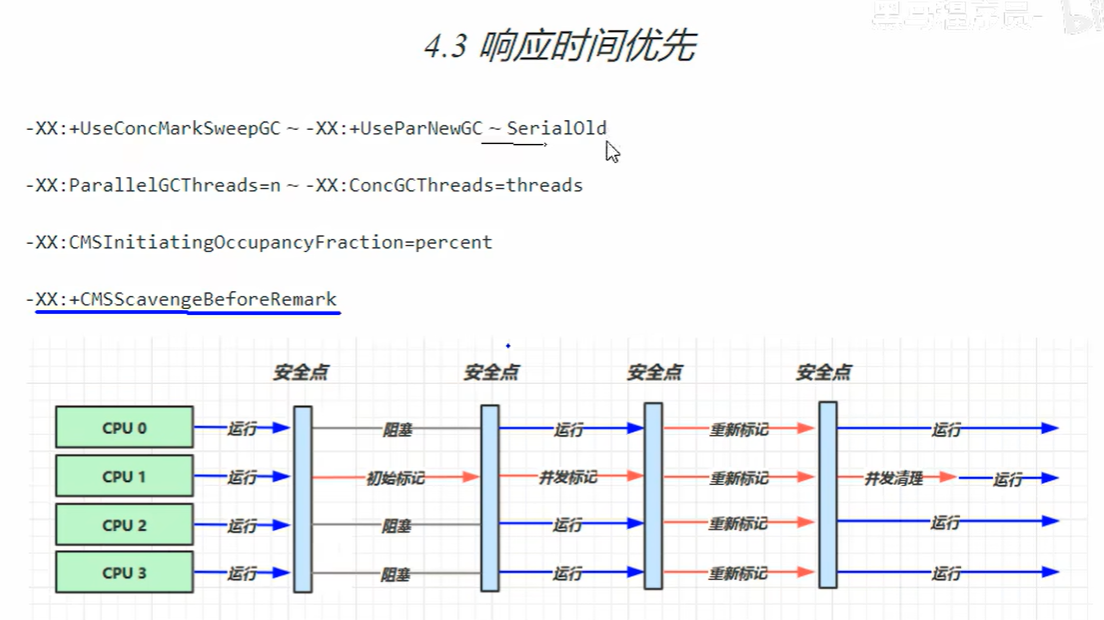
4.3 响应时间优先
| 参数 | 作用 |
|---|---|
-XX:+UseConcMarkSweepGC |
开启 CMS 老年代收集器(JDK 8 默认即启用) |
-XX:+UseParNewGC |
新生代配套使用 ParNew(并行复制,只有它支持 CMS) |
-XX:ParallelGCThreads=n |
STW 阶段(初始标记、重新标记)的并行线程数 |
-XX:ConcGCThreads=threads |
并发阶段 (并发标记、并发清理)的线程数,一般设为 (n+3)/4 |
-XX:CMSInitiatingOccupancyFraction=percent |
老年代使用率 ≥ percent% 时启动 CMS GC,默认 68 |
-XX:+CMSScavengeBeforeRemark |
在"重新标记"前先做一次 Young GC,减少跨代引用扫描量 |
初始标记(Initial Mark)
Stop-The-World(图里 CPU0~3 短暂阻塞)
只标记 GC Roots 直接关联的对象,耗时极短。
并发标记(Concurrent Mark)
与应用线程并发执行(CPU 继续跑业务)
从 Roots 出发,标记 所有可达对象。
重新标记(Remark)
第二次 STW(图里 CPU0/2/3 再次短暂阻塞)
修正并发阶段因用户线程运行而产生的 变动。
并发清理(Concurrent Sweep)
与应用线程并发执行
回收 标记为垃圾的对象,不产生压缩,因此有碎片。
✅ 优点
大部分 GC 工作与业务并发,停顿时间极短(通常 < 200 ms)。
适合 Web/API、交互式应用 等对响应时间敏感的场景。
❌ 缺点
内存碎片 + 浮动垃圾(并发清理时用户线程仍在分配)。
JDK 9 已废弃,JDK 14 移除;官方推荐 G1 或 ZGC 替代。
一句话记忆
"CMS = ** Initial STW → 并发标记 → Remark STW → 并发清理 **;
参数控线程数、触发阈值、预清理 ;
停顿短,但碎片多,已过时。"
4.4 G1

(1)G1回收阶段
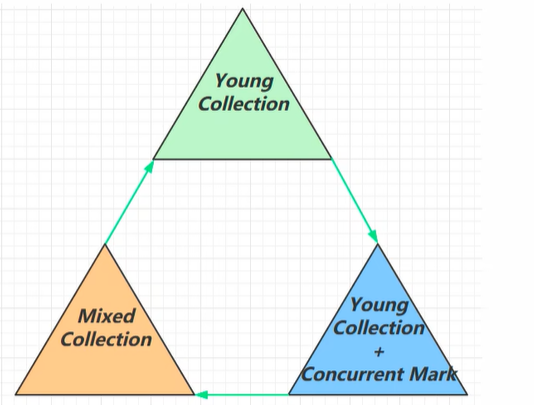
(2)Young Collection**(年轻代收集)**
-
Stop-The-World ,但极短(毫秒级)。
-
并行复制 Eden + Survivor → 新 Survivor / Old Region。
-
完成后 Eden Region 被清空,存活对象年龄 +1。
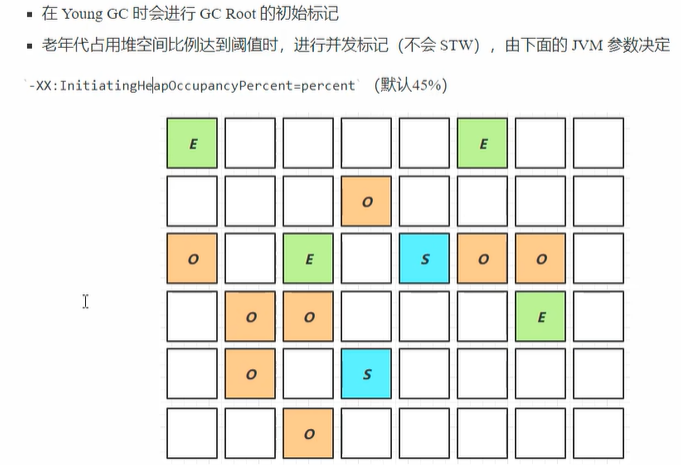
(3)Young Collection + CM(并发标记)
-
与应用线程并发执行,无停顿。
-
从 GC Roots 出发,三色标记 整个堆,记录每个 Region 的存活比例。
-
子阶段:
-
初始标记(STW,极短)
-
根区域扫描
-
并发标记
-
最终标记(STW,修正并发期间变动)
-
-
目的:选出"垃圾最多"的 Old Region ,为下一步 Mixed GC 做准备。
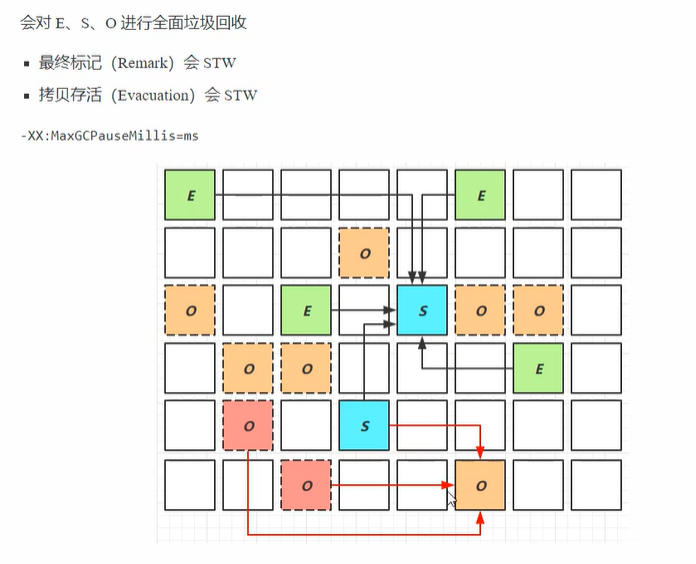
(4)Mixed Collection(混合收集)
-
Stop-The-World ,但只回收垃圾最多的部分 Old Region + 全部 Young Region。
-
用户可设 停顿目标 (
-XX:MaxGCPauseMillis),G1 根据历史成本动态挑选 Region 数量,保证在目标时间内完成。 -
连续多次 Mixed 直到 Old Region 垃圾占比 < G1MixedGCLiveThreshold 或 Mixed 次数上限。
(5)FUll GC

| 收集器 | 新生代算法 | Minor GC 停顿时长 | 老年代算法 | Full GC 停顿时长 | 特点 |
|---|---|---|---|---|---|
| Serial | Serial | 长(单线程) | Serial Old | 长(单线程) | 简单,小堆 |
| Parallel | ParNew | 短(多线程) | Parallel Old | 较长(多线程) | 吞吐量优先 |
| CMS | ParNew | 短 | Concurrent Mark-Sweep | 两次极短 STW + 并发清理 | 响应优先,碎片 |
| G1 | Parallel Region | 可预测短 | Region-Based Mixed | 可预测短(只收垃圾最多 Region) | 大堆、低停顿 |
(6)Young GC(跨代引用)
"卡表 + 脏卡 + 后置写屏障" = G1 在 Young GC 时快速找到 老年代→新生代 的引用,避免全堆扫描。
① 为什么会有"跨代引用"
Young GC 只收 Eden/Survivor,但
老年代对象可能持有新生代对象的引用 (图里箭头),如果 Young GC 时不扫描"老年代 → 新生代"的引用 ,就会出现 "存活对象被误回收" ,导致 数据丢失甚至 JVM 崩溃。。
若不做记录,就必须 扫描整个老年代 才能确定存活 → 代价太大。
② 卡表(Card Table)------"老年代→新生代"的 粗粒度地图
-
把 整个堆 划分成 512 字节的 卡片(Card);
-
每个卡片对应 1 字节 的 卡表项:
-
0 = 干净(无跨代引用)
-
1 = 脏(Dirty)(可能持有新生代引用)
-
③ 后置写屏障(Post-Write Barrier)+ 脏卡队列
当 应用线程 修改字段时,JVM 插入一段 极小汇编代码:
; 伪汇编
cmp rdi, young_start
jb skip ; 如果写入目标是老年代,继续
mov byte [card_table + addr>>9], 1 ; 把对应卡标记为脏
skip:-
写入 老年代→新生代 引用 → 当前卡被标记为 脏;
-
为了 不阻塞应用线程 ,真正的"脏卡"先放进 Dirty Card Queue ,由 并发 refinement 线程 异步处理。
④ Remembered Set(RSet)------"卡表→Region"的 精确定位
-
每个 Region 维护一个 RSet (HashMap 结构):
Key = 其他 Region 的起始地址
Value = 这些 Region 中 **哪些卡** 指向我 -
Young GC 时 只扫描 RSet 记录的脏卡 → 瞬间得到 跨代引用集合,无需全堆扫描。
⑤ Young GC 时的工作流程(结合图)
-
Root Scan → 扫描线程栈、JNI 等 固定根;
-
Scan RSet → 只遍历 脏卡里的对象 ,找到 老→新引用;
-
Copy & Update → 把存活对象复制到 Survivor/Old,并 更新指针;
-
Clear Dirty Card → 当前 Region 的脏卡清零,等待下次写入。
一句话记忆
"写操作 → 写屏障 → 脏卡 → RSet → Young GC 只扫脏卡 ",
"卡表是地图,RSet是坐标,写屏障是 GPS 更新器"。
(7)Remark
这是 CMS / G1 在 "Remark"(最终标记)阶段 用来 修正并发标记期间被改动的引用 的核心机制:
"预写屏障 + SATB 标记队列" 保证 "并发标记快照" 的完整性。① 问题背景:并发标记时对象图还在变
并发标记阶段 应用线程仍在运行,字段随时被改写。
若不做记录,新产生的跨代引用 或 存活对象被误标为垃圾 就会漏标 → 漂浮垃圾 甚至 误回收。
② SATB(Snapshot-At-The-Beginning) 思路
在 并发标记开始那一刻 拍一张快照 S。
只要当时快照里是活的,就必须被标记为活(即使后面变成垃圾也无所谓)。
新分配的对象 默认 黑色 (存活),旧对象的引用字段被删除/修改 时才需要记录。
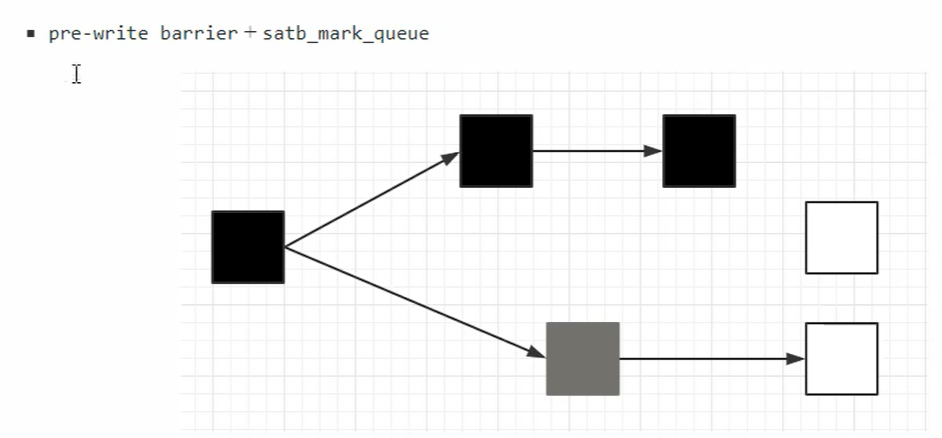
③ 预写屏障(Pre-Write Barrier)(底层实现)
位置 :在 应用线程 的 putfield/putstatic/A*STORE 指令前插入一段 极小汇编(几乎无性能损耗):
; 伪汇编 oldValue = [field] ; 先读旧值 if oldValue != null satb_enqueue(oldValue) ; 把旧值压入 SATB 队列 [field] = newValue ; 再写新值
写前 先把 旧引用 记录下来(不是新引用)。
记录内容:旧目标对象地址 → 压入 线程私有的 SATB 标记队列(SATB Mark Queue)。
④ SATB 标记队列(SATB Mark Queue)→ 全局队列
每个应用线程一个 本地 SATB 队列(无锁,极快)。
队列满后 批量刷新到全局 SATB 队列。
Remark 阶段 只需 扫描全局队列里的对象 ,就能 把"被删掉"的引用重新标记为存活 ,保证 快照 S 的完整性。
⑤ 时间线(配合图)
并发标记开始 → 生成快照 S。
应用线程 A 执行 :
obj.f = newObj(原 f 指向 X)→ 预写屏障记录 X → X 进入 SATB 队列。
Remark 阶段 → 扫描 SATB 队列 → 把 X 重新标记为活。
结果 :X 不会被 Young GC/Mixed GC 误回收 ;浮动垃圾 最多留到下次。
一句话记忆
"预写屏障 = 写前拍照 ,SATB 队列 = 照片底片 ,Remark = 把底片洗出来 ,保证并发标记不漏活对象。"
(8)JDK8u20字符串去重
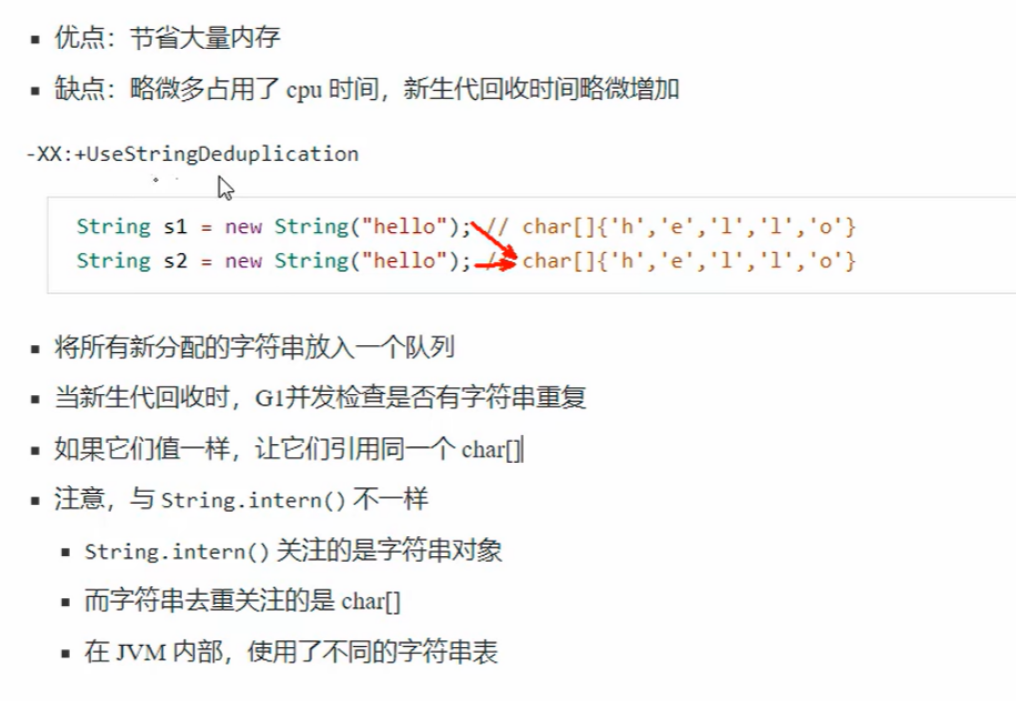
(9)JDK 8u40 并发标记类卸载

(10)JDK 8u60 回收巨型对象

(11)JDK9并发标记起始时间的调整
