TL;DR
- 2025 年 DeepSeek 提出的新模型 DeepSeek-V3.2,DeepSeek-V3.2 在多项推理基准上与 Kimi-k2-thinking 和 GPT-5 达到相近性能。同时,高算力版本 DeepSeek-V3.2-Speciale 的性能超越 GPT-5 ,并展现出与 Gemini-3.0-Pro 相当的推理能力,在 2025 年国际数学奥林匹克(IMO) 与 国际信息学奥林匹克(IOI) 中均达到了金牌水平。
Paper name
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Paper Reading Note
Paper URL:
Project URL:
- https://huggingface.co/deepseek-ai/DeepSeek-V3.2,提出了 DeepSeek 稀疏注意力机制(DSA),
Introduction
背景
- 虽然开源社区(MiniMax, 2025;MoonShot, 2025;Qwen, 2025;智谱AI, 2025)持续取得进展,但闭源商业模型(Anthropic, 2025b;DeepMind, 2025a;OpenAI, 2025)的性能提升轨迹呈现出明显更陡峭的增长趋势。结果是,二者并未趋同,反而在复杂任务上的差距不断拉大,闭源系统表现出愈发突出的优势。
- 本文识别出限制开源模型处理复杂任务的三大关键缺陷:
- 首先,在架构上,对 vanilla attention 的高度依赖严重制约了长序列场景中的计算效率。这一低效性既阻碍可扩展部署,也妨碍高质量的后训练过程。
- 其次,在资源分配方面,开源模型在后训练阶段投入的算力普遍不足,从而限制了其在高难度任务中的性能。
- 最后,在 AI agents 场景中,开源模型在泛化能力和指令遵循能力方面显著落后于闭源模型,因此在真实部署中效果欠佳。
本文方案
提出了 DeepSeek-V3.2,这是一款兼具高计算效率 与卓越推理与智能体能力的模型。DeepSeek-V3.2 的核心技术突破包括:
-
DeepSeek 稀疏注意力机制(DSA) :
引入了 DSA,这是一种高效的注意力机制,能够在显著降低计算复杂度 的同时,保持模型在超长上下文场景下的性能。
-
可扩展的强化学习框架 :
通过构建稳健的强化学习协议并扩大后训练计算规模,DeepSeek-V3.2 的表现可与 GPT-5 相媲美 。值得注意的是,高算力版本 DeepSeek-V3.2-Speciale 的性能超越 GPT-5 ,并展现出与 Gemini-3.0-Pro 相当的推理能力,在 2025 年国际数学奥林匹克(IMO) 与 国际信息学奥林匹克(IOI) 中均达到了金牌水平。
-
大规模智能体任务合成流水线 :
为将推理能力融入工具使用场景,我们开发了一套全新的数据合成流水线,可系统性、规模化地产生训练数据。该方法支持可扩展的智能体后训练,并在复杂、交互式环境中显著提升模型的泛化能力与指令遵循的稳健性。
- DeepSeek-V3.2 在多项推理基准上与 Kimi-k2-thinking 和 GPT-5 达到相近性能。此外,DeepSeek-V3.2 显著提升了开源模型的智能体能力,在 EvalSys (2025)、Li et al. (2025)、Luo et al. (2025) 提出的长尾智能体任务中表现优异。作为一种高度成本效率的智能体方案,DeepSeek-V3.2 在大幅降低成本的前提下,有效缩小了开源模型与前沿闭源模型之间的性能差距。
- 值得注意的是,为了推动开源模型在推理领域达到新高度,我们放宽了序列长度限制,开发了 DeepSeek-V3.2-Speciale。其性能已与领先的闭源系统 Gemini-3.0-Pro(DeepMind, 2025b) 达到同一水平,并在 IOI 2025、ICPC 世界总决赛 2025、IMO 2025、CMO 2025 中均展现出金牌级表现。
Methods
2. DeepSeek-V3.2 架构
2.1 DeepSeek 稀疏注意力
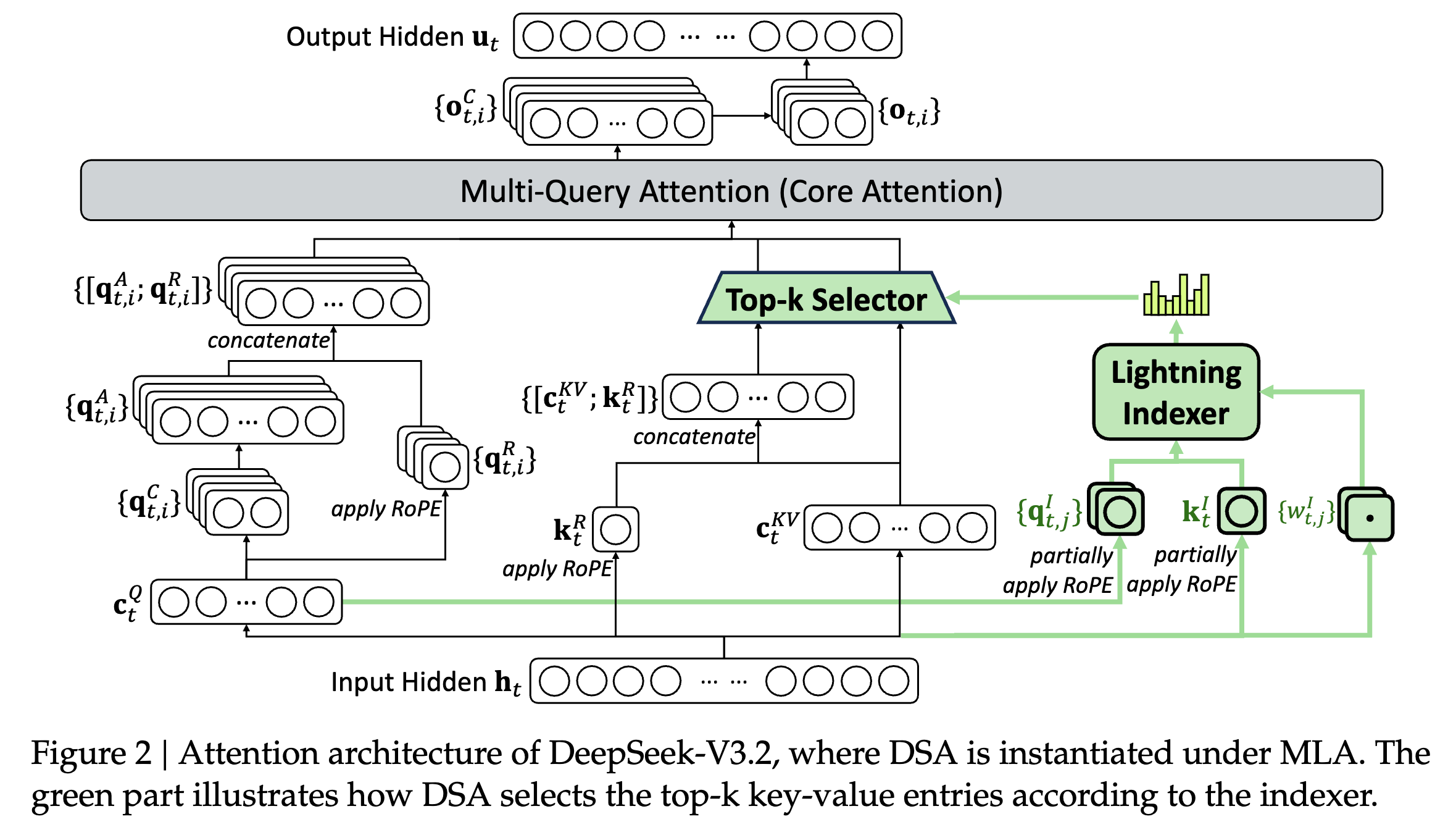
DeepSeek-V3.2 采用与 DeepSeek-V3.2-Exp 完全相同的架构。与上一代版本 DeepSeek-V3.1 的最终版 DeepSeek-V3.1-Terminus 相比,DeepSeek-V3.2 在架构上的唯一改动 ,就是在持续训练(continued training)的过程中引入了 DeepSeek Sparse Attention(DSA)。
DSA 原型(Prototype of DSA)
DSA 的原型主要由两个组件构成:
- lightning indexer(闪电索引器)
- fine-grained token selection mechanism(细粒度 token 选择机制)
Lightning indexer 计算查询 token ht∈Rdh_t \in \mathbb{R}^dht∈Rd 与其之前的某个 token hs∈Rdh_s \in \mathbb{R}^dhs∈Rd 之间的索引分数 It,sI_{t,s}It,s,用于决定该查询 token 要选择哪些历史 token:
It,s=∑j=1HIwt,jI⋅ReLU(qt,jI⋅ksI),(1) I_{t,s} = \sum_{j=1}^{H_I} w^I_{t,j} \cdot \text{ReLU}\big(q^I_{t,j} \cdot k^I_s\big), \tag{1} It,s=j=1∑HIwt,jI⋅ReLU(qt,jI⋅ksI),(1)
其中,HIH_IHI 表示 indexer head 的数量;
qt,jI∈RdIq^I_{t,j} \in \mathbb{R}^{d_I}qt,jI∈RdI 和 wt,jI∈Rw^I_{t,j} \in \mathbb{R}wt,jI∈R 由查询 token hth_tht 映射而来;
而 ksI∈RdIk^I_s \in \mathbb{R}^{d_I}ksI∈RdI 则由前序 token hsh_shs 映射而来。
我们选择 ReLU 作为激活函数,主要是出于吞吐量(throughput)的考虑。鉴于 lightning indexer 只包含少量的 heads,且可以用 FP8 来实现,其计算效率非常可观。
在为每个查询 token hth_tht 得到索引分数集合 It,s{I_{t,s}}It,s 之后,我们的细粒度 token 选择机制会仅检索对应于 Top-k 索引分数 的那些 key-value 条目 cs{c_s}cs。随后,通过在查询 token hth_tht 与这些稀疏选取的 key-value 条目 cs{c_s}cs 之间应用注意力机制,得到注意力输出 utu_tut:
ut=Attn(ht,{cs∣It,s∈Top-k(It,:)}).(2) u_t = \text{Attn}\Big(h_t, \{c_s \mid I_{t,s} \in \text{Top-k}(I_{t,:})\}\Big). \tag{2} ut=Attn(ht,{cs∣It,s∈Top-k(It,:)}).(2)
在 MLA 框架下实例化 DSA(Instantiate DSA Under MLA)
出于从 DeepSeek-V3.1-Terminus 持续训练(continued training)的考虑,我们在 DeepSeek-V3.2 中基于 MLA(Multi-Head Latent Attention,DeepSeek-AI, 2024)来实例化 DSA。
在 kernel 实现层面,为了获得较高的计算效率,每一个 key-value 条目都必须能够被多个 query 共享(Yuan et al., 2025)。因此,我们在 MLA 的 MQA 模式(Multi-Query Attention,Shazeer, 2019)下实现 DSA:在这种设置中,每个 latent 向量(即 MLA 中的 key-value 条目)会在同一个查询 token 的所有 query heads 之间共享。
基于 MLA 的 DSA 架构如图 2 所示。我们同时提供了 DeepSeek-V3.2 的开源实现,用于对这些细节做出明确说明。
2.1.1 持续预训练(Continued Pre-Training)
基于已扩展到 128K 上下文长度的 DeepSeek-V3.1-Terminus 基础检查点,我们进行持续预训练(continued pre-training),随后开展后训练(post-training),从而构建 DeepSeek-V3.2。DeepSeek-V3.2 的持续预训练由两个阶段组成。对于这两个阶段,训练数据的分布均与用于 DeepSeek-V3.1-Terminus 的 128K 长上下文扩展数据完全一致。
Dense Warm-up 阶段
我们首先进行一个短暂的 warm-up 阶段,用于初始化 lightning indexer。在该阶段中:
- 注意力仍保持稠密(dense attention)
- 除 lightning indexer 外的所有模型参数全部冻结
为了使 indexer 的输出与主注意力分布对齐,对于第 (t) 个 query token,我们首先对主注意力在所有 attention heads 上求和,并沿序列维度进行 L1 归一化,得到目标分布:
pt,:∈Rt. p_{t,:} \in \mathbb{R}^t. pt,:∈Rt.
基于 pt,:p_{t,:}pt,:,我们设定 indexer 的训练目标为 KL 散度损失:
LI=∑tDKL(pt,:∣∣Softmax(It,:)).(3) L_I = \sum_t \text{DKL}\left(p_{t,:} || \text{Softmax}(I_{t,:})\right). \tag{3} LI=t∑DKL(pt,:∣∣Softmax(It,:)).(3)
Warm-up 配置如下:
- 学习率:10−310^{-3}10−3
- 训练步数:1000
- 每步包含 16 条 128K tokens 的序列
- 总 token 数:2.1B
Sparse Training 阶段
在 indexer warm-up 之后,我们引入 细粒度 token 选择机制,并优化所有模型参数,使模型适应 DSA 的稀疏模式。
在此阶段,我们仍然将 indexer 输出与主注意力分布对齐,但只在 被选择的 token 集合 上进行:
St=s∣It,s∈Top-k(It,:). S_t = { s \mid I_{t,s} \in \text{Top-k}(I_{t,:}) }. St=s∣It,s∈Top-k(It,:).
损失函数为:
LI=∑tDKL!(pt,St;∣;Softmax(It,St)).(4) L_I = \sum_t \text{DKL}!\left(p_{t,S_t} ; |; \text{Softmax}(I_{t,S_t})\right). \tag{4} LI=t∑DKL!(pt,St;∣;Softmax(It,St)).(4)
需要特别指出的是:
- 我们将 indexer 的输入从计算图中 detach,以便独立优化
- indexer 仅 通过 LIL_ILI 获得训练信号
- 主模型 LMLMLM 仅根据语言建模损失进行优化
Sparse 阶段配置如下:
- 学习率:7.3×10−67.3\times 10^{-6}7.3×10−6
- 每个 query token 选择 2048 个 key-value tokens
- 训练步数:15000
- 每步包含 480 条 128K tokens 的序列
- 总 token 数:943.7B
2.2 性能一致性评估(Parity Evaluation)
标准基准测试(Standard Benchmark)
在 2025 年 9 月,我们在一系列覆盖多种能力的基准上评估 DeepSeek-V3.2-Exp,并与 DeepSeek-V3.1-Terminus 对比,结果显示其性能相近。
虽然 DeepSeek-V3.2-Exp 在长序列场景显著提升了计算效率,但在短上下文与长上下文任务中,其性能相较 DeepSeek-V3.1-Terminus 未出现明显下降。
人类偏好评估(Human Preference)
由于直接的人类偏好评估容易受到偏差影响,我们使用 ChatbotArena 作为间接框架来估计用户偏好。
- DeepSeek-V3.1-Terminus 与 DeepSeek-V3.2-Exp 采用完全一致的后训练策略
- 2025 年 11 月 10 日的 Elo 评分显示二者表现非常接近
这表明尽管 V3.2-Exp 引入了稀疏注意力,但新模型的用户偏好表现与上一代保持一致。
长上下文评估(Long Context Eval)
DeepSeek-V3.2-Exp 发布后,多组独立团队使用未公开的新测试集进行了长上下文评估。
- 在典型基准 AA-LCR 中,DeepSeek-V3.2-Exp 在 reasoning 模式下 比 V3.1-Terminus 高 4 分
- 在 Fiction.liveBench 中,各项指标均稳定超越 V3.1-Terminus
这些证据表明:V3.2-Exp 的基础模型在长上下文任务上没有退化
2.3 推理成本(Inference Costs)
DSA 将主模型注意力的核心复杂度从 O(L2)O(L^2)O(L2) 降低为 O(Lk)O(Lk)O(Lk)
其中 k≪Lk \ll Lk≪L 为选取的 token 数量。
尽管 lightning indexer 本身仍然是 O(L2)O(L^2)O(L2),但与 DeepSeek-V3.1-Terminus 中的 MLA 相比,其计算需求显著更低。
结合优化实现,DSA 在长上下文场景中带来了显著的端到端加速。
图 3 展示了 DeepSeek-V3.1-Terminus 与 DeepSeek-V3.2 在序列不同位置的 token 成本差异。该成本基于在 H800 GPU (租金为每 GPU 每小时 2 美元)上实际部署服务的基准测试所得。
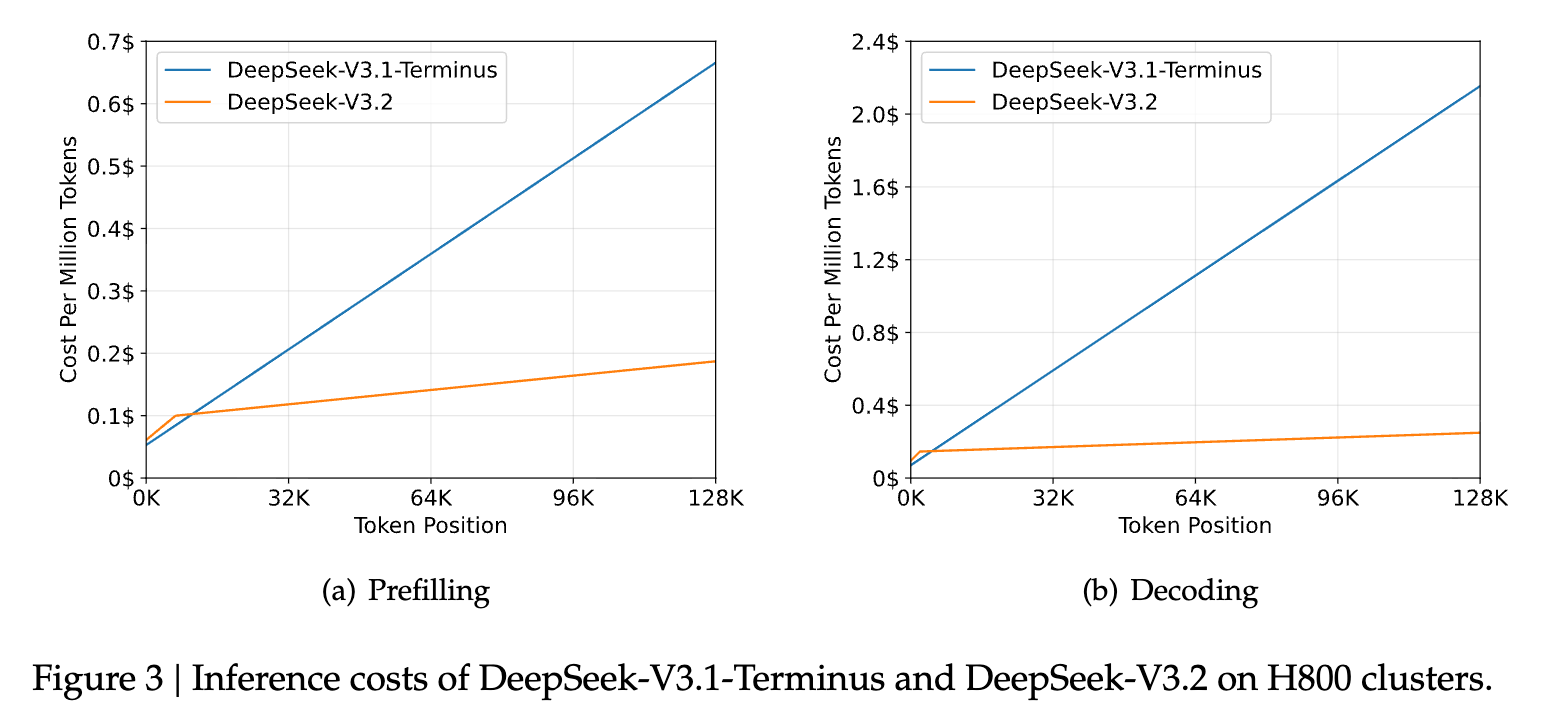
对于短序列 prefilling,我们特别实现了一个 masked MHA 模式 来模拟 DSA,以在短上下文条件下获得更高效率。
3. 后训练(Post-Training)
在持续预训练结束后,我们进一步执行后训练,以得到最终的 DeepSeek-V3.2。DeepSeek-V3.2 的后训练仍采用与稀疏持续预训练阶段相同的稀疏注意力方式。对于 DeepSeek-V3.2,我们保留了与 DeepSeek-V3.2-Exp 完全一致的后训练流程,其中包括 专家蒸馏(specialist distillation) 与 混合强化学习训练(mixed RL training)。
专家蒸馏(Specialist Distillation)
针对每项任务,我们首先开发专门的模型,这些专家模型仅专注于特定领域,且全部基于相同的 DeepSeek-V3.2 预训练基座进行微调。除了写作任务和通用问答,我们的框架涵盖六个专业领域:
- 数学
- 编程
- 通用逻辑推理
- 通用智能体任务
- 智能体代码生成(agentic coding)
- 智能体搜索(agentic search)
所有这些领域均支持 思维模式(thinking mode) 与 非思维模式(non-thinking mode)。
每个专家均使用大规模 RL 计算进行训练。此外,我们采用不同模型为两类任务生成数据:
- 长链条推理(思维模式)
- 直接回答(非思维模式)
在专家模型训练完成后,我们利用它们生成领域特定的数据用于最终检查点。实验表明:
在蒸馏数据上训练的模型,其性能仅略低于专家模型本身,并可通过后续 RL 完全弥补差距。
混合 RL 训练(Mixed RL Training)
对于 DeepSeek-V3.2,我们继续采用 Group Relative Policy Optimization(GRPO)(DeepSeek-AI, 2025;Shao et al., 2024)作为强化学习训练算法。
与 DeepSeek-V3.2-Exp 一样,我们将 推理、智能体训练、人类对齐三者合并到同一个 RL 阶段中。这种方法有效平衡不同领域的性能,并避免多阶段训练中常见的灾难性遗忘问题。
奖励策略包括:
- 推理与智能体任务:基于规则的结果奖励、长度惩罚、语言一致性奖励
- 通用任务:使用生成式奖励模型,每个 prompt 具有独立评分准则(rubrics)
DeepSeek-V3.2 与 DeepSeek-V3.2-Speciale
DeepSeek-V3.2 整合来自专家模型蒸馏的推理、智能体与人类对齐数据,通过数千步持续 RL 训练,得到最终检查点。
为了探索延长链式思维能力的上限,我们开发了实验性变体 DeepSeek-V3.2-Speciale:
- 仅使用推理数据进行训练
- RL 训练中降低长度惩罚
- 融入 DeepSeekMath-V2(Shao et al., 2025)的数据集与奖励方法
- 专门增强数学证明能力
3.1 GRPO 的扩展训练(Scaling GRPO)
首先回顾 GRPO 的优化目标。
GRPO 在每个问题 qqq 上,从旧策略 πold\pi_{\text{old}}πold 采样的一组回答 o1,...,oG{o_1, \ldots, o_G}o1,...,oG 上优化策略模型 πθ\pi_\thetaπθ,其目标函数为:
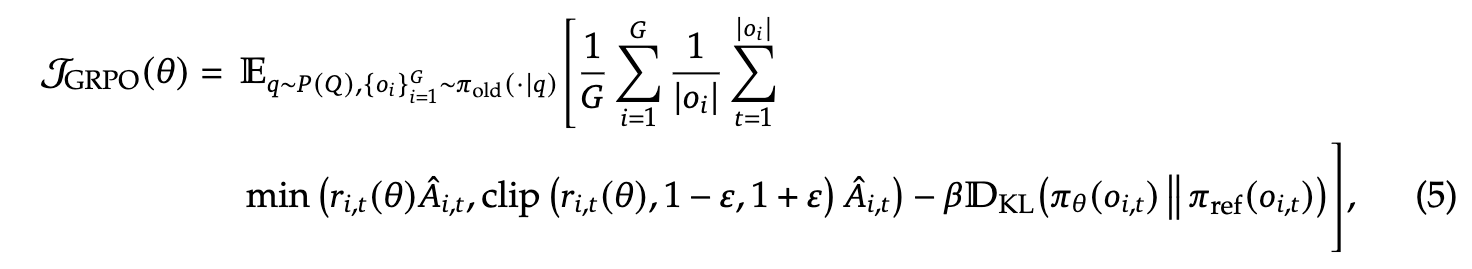
其中
ri,t(θ)=πθ(oi,t∣q,oi,<t)πold(oi,t∣q,oi,<t)(6) r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} \mid q, o_{i,<t})} {\pi_{\text{old}}(o_{i,t} \mid q, o_{i,<t})} \tag{6} ri,t(θ)=πold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)(6)
为重要性采样比率。
- (\varepsilon), (\beta) 分别控制 clipping 范围与 KL 强度
- (\hat{A}_{i,t}) 是优势项,通过组内奖励归一化计算
对于每个输出 (o_i),奖励模型给定结果奖励 (R_i),并计算:
A^i,t=Ri−mean(R). \hat{A}_{i,t} = R_i - \text{mean}(R). A^i,t=Ri−mean(R).
3.1.1 无偏 KL 估计(Unbiased KL Estimate)
由于 oi,to_{i,t}oi,t 来自旧策略 πold\pi_{\text{old}}πold,我们对 K3 估计器(Schulman, 2020)进行修正,使其通过重要性采样比率得到无偏估计:
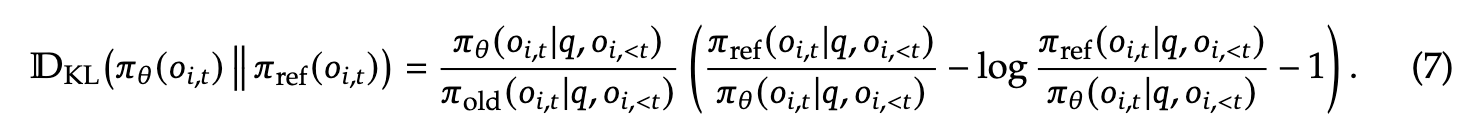
修正结果:
- KL 的梯度变为无偏,有助于稳定收敛
- 避免原 K3 在 (\pi_\theta \ll \pi_{\text{ref}}) 时梯度爆炸的问题
不同领域对 KL 正则强度敏感性不同,例如数学任务在弱 KL 或无 KL 时性能反而更好。
3.1.2 离策略序列掩码(Off-Policy Sequence Masking)
为了提高效率,我们通常先生成大批 rollout 数据,再拆成多个 mini-batch 执行多步更新。这自然引入离策略性。此外,高性能推理框架与训练框架之间的实现差异也加剧离策略问题。
为稳定训练,我们对产生显著策略偏移的样本进行掩码:
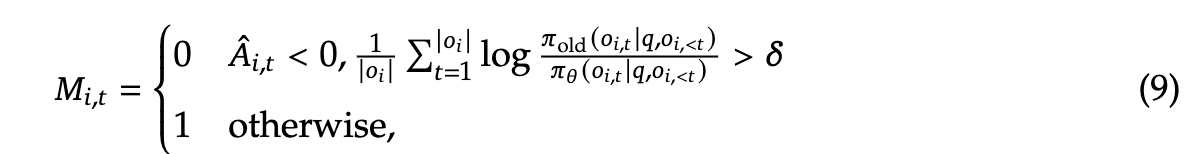
新的 GRPO 目标变为:
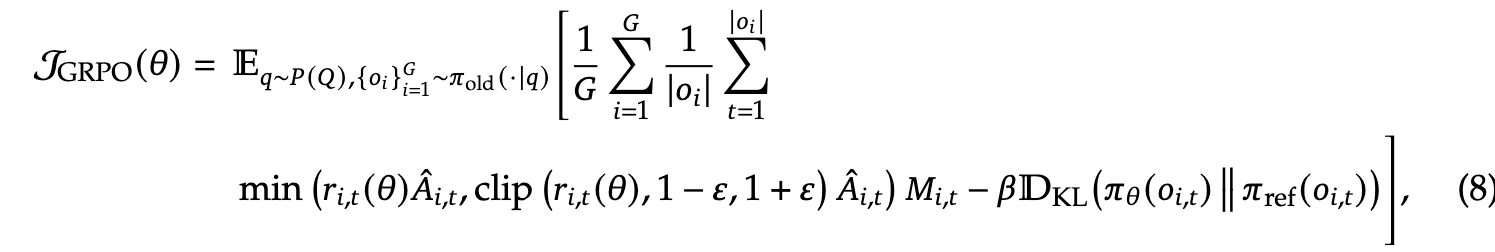
要点:
- 仅 mask 负优势(negative advantage) 样本
- 原因:模型最能从自身错误中学习,但高度离策略的负样本会损害训练
实践中,该操作显著提升了不稳定训练场景的稳定性。
3.1.3 保持路由(Keep Routing)
MoE 的专家选择在推理与训练框架中可能不同,从而造成路由不一致。这会导致:
- 激活参数空间突变
- 加剧离策略问题
- 造成训练不稳定
解决方案:
记录推理时的专家路由,并在训练时强制使用相同路由。
这在 DeepSeek-V3-0324 中已被采用,是稳定 MoE RL 的关键。
3.1.4 保持采样掩码(Keep Sampling Mask)
top-p / top-k 采样虽能提高输出质量,但会改变动作空间,从而:
- 破坏重要性采样前提
- 导致训练不稳定
解决方案:
将旧策略采样时的截断掩码同步应用于新策略。
经验表明:
- top-p + Keep Sampling Mask
- 能有效保持 RL 训练的语言一致性
3.2 工具使用中的思维能力(Thinking in Tool-Use)
3.2.1 思维上下文管理(Thinking Context Management)
DeepSeek-R1 已经证明,引入思维过程可以显著提升模型解决复杂问题的能力。基于这一洞察,我们尝试将思维能力整合到工具调用(tool-calling)场景中。
我们观察到,若直接沿用 DeepSeek-R1 的策略------在第二轮消息到来时丢弃推理内容------会带来严重的 token 低效性。因为这会迫使模型在每次工具调用后,都必须重新推理整个问题。
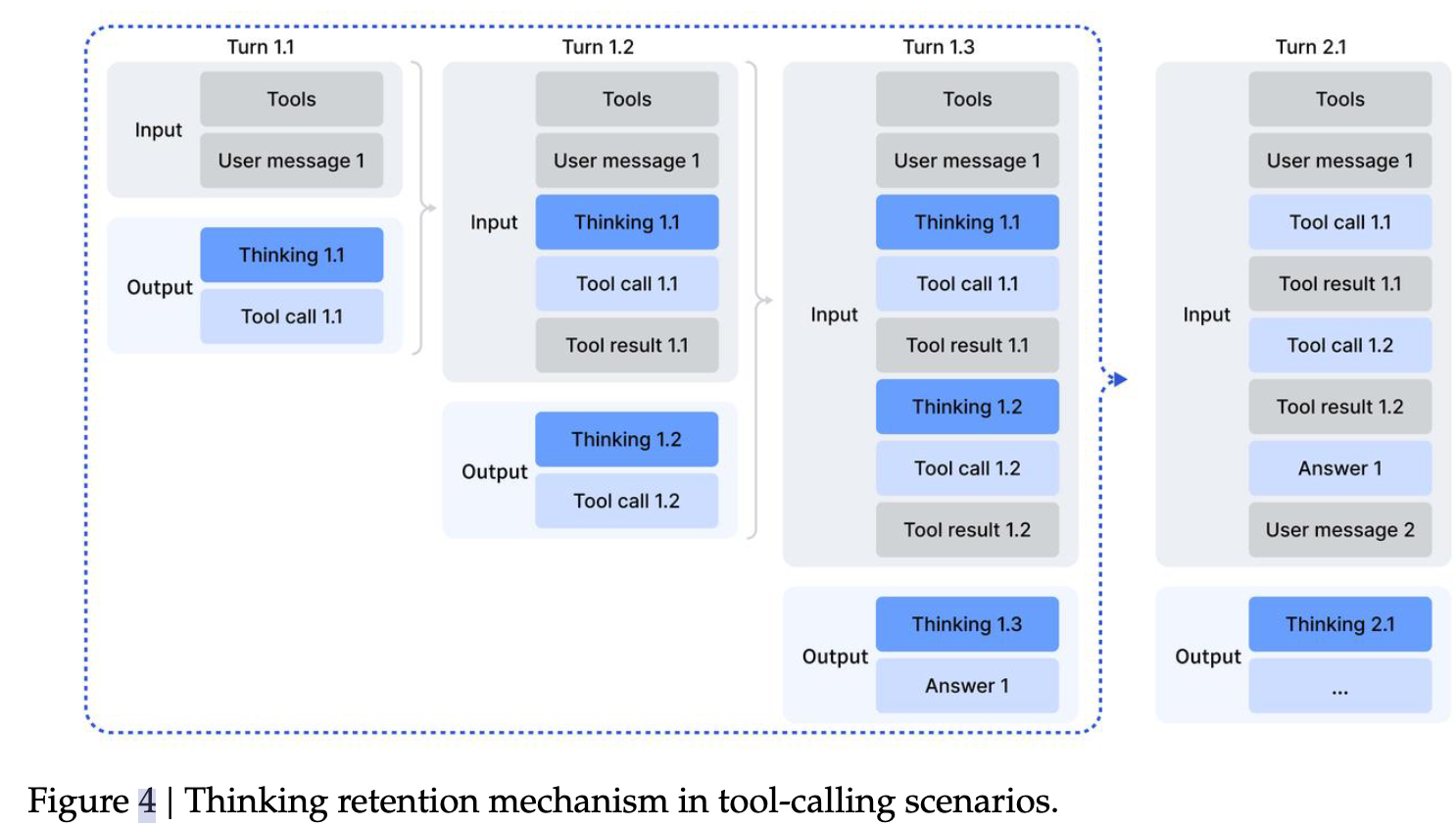
为缓解这一问题,我们开发了一种专门用于工具调用的上下文管理策略,如图 4 所示:
-
只有当新的用户消息出现时,历史推理内容才会被丢弃。
若追加的仅是工具相关消息(例如工具输出),推理内容会在整个交互过程中被保留。
-
当推理轨迹被清除时,工具调用的历史记录及其结果仍然保留在上下文中。
值得注意的是,一些智能体框架(例如 Roo Code 或 Terminus)通过用户消息来模拟工具交互。由于其上下文结构与上述策略不同,这些框架未必能充分受益于我们的"推理持久化"机制。因此,我们建议在此类框架中使用 非思维模型(non-thinking models) 以获得最佳性能。
3.2.2 冷启动(Cold-Start)
在已有如下两类数据的前提下:
- 带推理过程的非智能体数据(reasoning data)
- 不带推理过程的智能体数据(agentic data)
一种简单的整合方式是通过精心设计的 prompt。
我们认为:模型在已有能力基础上,可以很好地遵循明确指示,因此能够通过 prompting 自然地将工具执行整合进推理过程。
为展示冷启动机制如何运行,我们对训练数据进行抽样,如附录表 6--8 所示:
-
表 6:推理数据示例
使用系统提示明确要求模型在最终答案前进行推理,并通过
<think></think>标签标记推理路径。

-
表 7:非推理智能体数据示例
系统提示中包含工具调用相关指导。

-
表 8:我们设计的系统提示
指示模型在推理过程中融入多次工具调用。

通过此方式,即使模型在工具使用过程中的推理模式尚不稳定,它也能 偶尔生成符合预期的轨迹,成为后续 RL 阶段训练的基础。
3.2.3 大规模智能体任务(Large-Scale Agentic Tasks)
多样化的 RL 任务对于增强模型稳健性至关重要。
对于搜索、代码工程与代码解释等任务,我们使用真实的工具环境,例如:
- Web 搜索 API
- 编程环境
- Jupyter Notebook
这些 RL 环境是真实的,但其 prompt 来自互联网或合成,而非真实用户输入。
对于其他任务,我们构建完全合成的环境与 prompt。
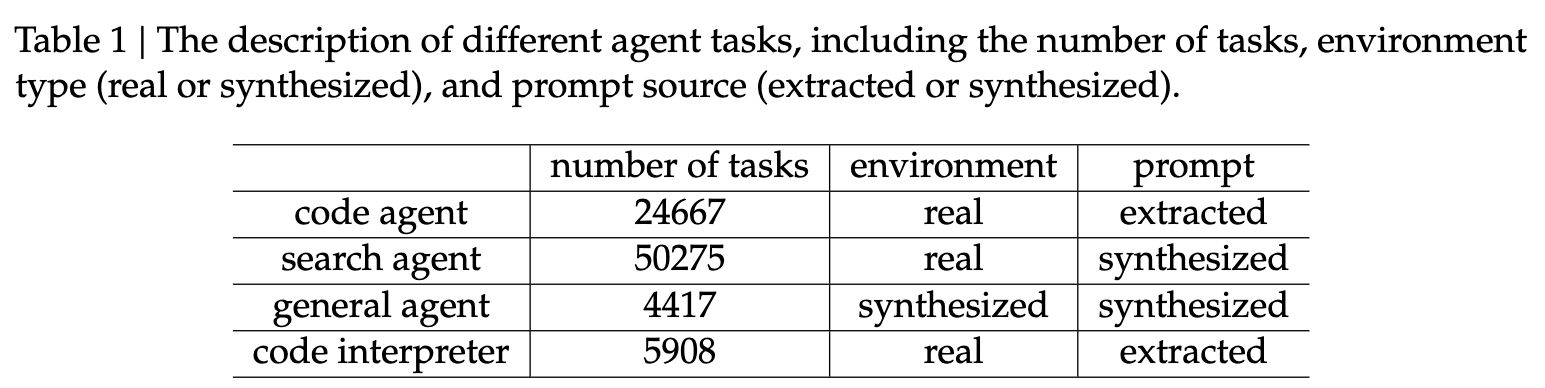
我们使用的智能体任务如表 1 所述。
搜索智能体(Search Agent)
我们基于 DeepSeek-V3.2 构建多智能体管线,生成多样且高质量的训练数据。流程如下:
-
从大规模网页语料中采样不同领域的长尾实体
-
问题构造智能体利用搜索工具进行探索(具有可配置的深度与广度),并整合为 QA 样本
-
多个回答生成智能体(不同 checkpoint、系统提示等配置)为每个 QA 对生成多样回答
-
具有搜索能力的验证智能体通过多轮验证,筛选条件为:
- 标准答案正确
- 所有候选答案均可被验证为错误
生成的数据跨越多个语言、领域与难度。
此外,我们从已有的 helpful RL 数据集中筛选可被搜索工具显著提升质量的样本,进行增补。
我们为多个维度构建详细的评价标准(rubrics),并使用生成式奖励模型计算奖励。这一混合方法同时优化事实可靠性与实用帮助度。
代码智能体(Code Agent)
我们从 GitHub 挖掘了数百万 issue--PR 配对构建大规模可执行环境,并进行严格过滤以确保质量:
- 每条数据需包含合理的问题描述
- 对应的 gold patch
- 可验证的 test patch
然后利用 DeepSeek-V3.2 驱动的自动环境搭建智能体完成环境构建,包括:
- 包安装
- 依赖处理
- 测试执行
测试输出采用标准 JUnit 格式,确保跨语言统一解析。
当且仅当:
- 应用 gold patch 后 F2P(false-to-pass)测试数 > 0
- P2F(pass-to-fail)测试数 = 0
环境被视为构建成功。
最终我们构建了数万个可重复环境,覆盖:
- Python
- Java
- JavaScript
- TypeScript
- C
- C++
- Go
- PHP
代码解释智能体(Code Interpreter Agent)
我们使用 Jupyter Notebook 作为代码解释器来解决复杂推理任务。
为此,我们准备了跨数学、逻辑、数据科学等领域的多种问题,这些问题要求模型必须通过代码执行才能得到答案。
通用智能体(General Agent)
为扩大 RL 中的环境与任务规模,我们使用自动环境生成智能体构建了 1,827 个任务环境。这些任务:
- 难解,但易于验证
- 具有自动化评估机制
任务生成流程如下:
-
给定任务类别(如旅行规划)与带搜索工具的 bash sandbox
- 智能体使用工具生成或检索相关数据,并存储至数据库
-
智能体合成任务特定工具(函数形式)
-
智能体构造任务解决方案与验证函数(Python 实现)
限制条件:
- 解决方案 只能调用工具函数或逻辑计算
- 不能调用其他函数或直接访问数据库
- 需通过验证函数验证
若无法通过,智能体修改方案或验证函数
-
智能体逐步增加任务难度,并在必要时扩展工具集
最终得到成千上万个 <environment, tools, task, verifier> 元组。
我们使用 DeepSeek-V3.2 在此数据集上执行 RL,并保留所有 pass@100 > 0 的实例,共计:
- 1,827 个环境
- 4,417 个任务
文中附带一个行程规划任务示例:
任务空间组合极大、难以搜索,但验证一个候选方案是否满足条件则相对简单。

Experiments
4.1 主要结果(Main Results)
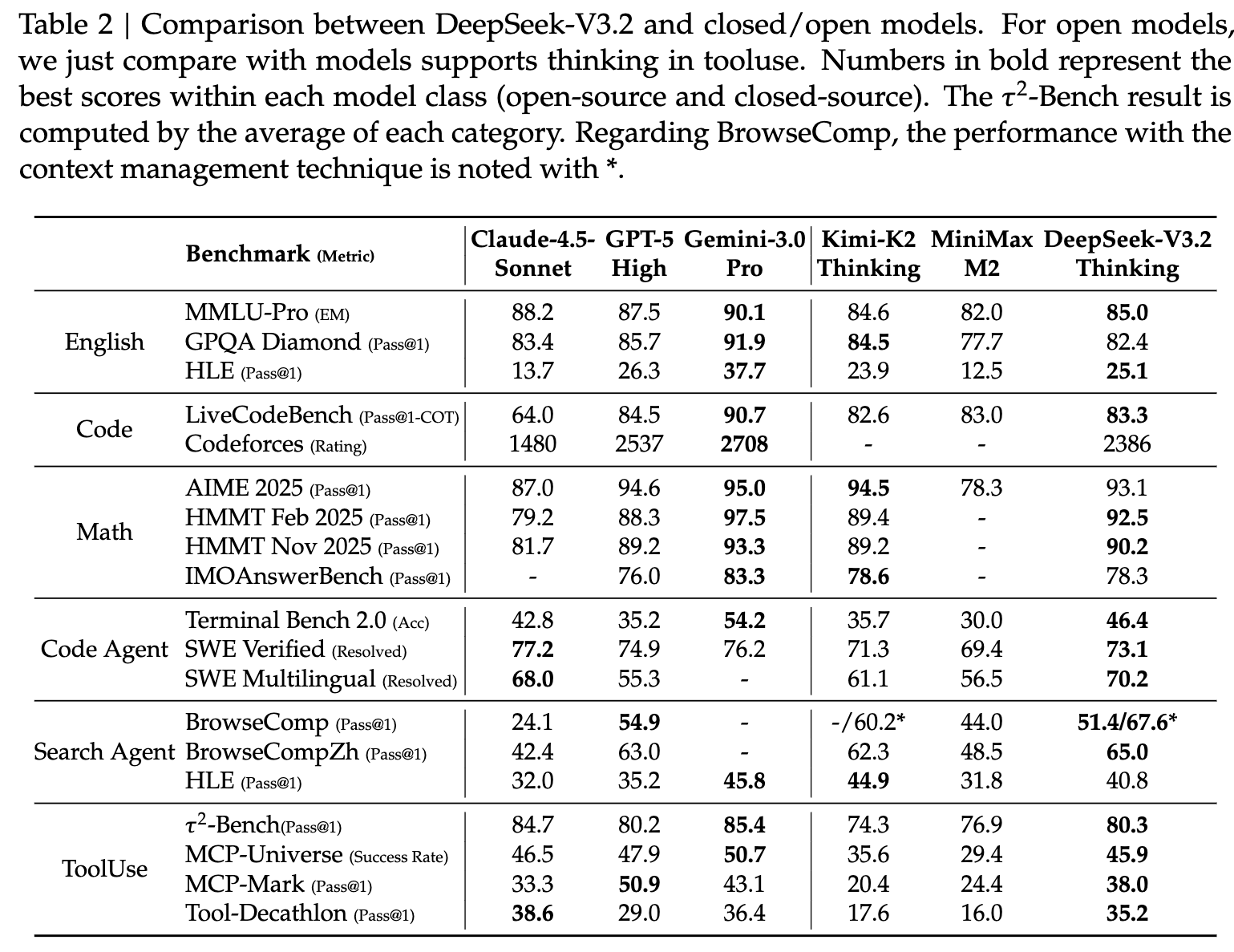
我们在以下基准上对模型进行评估:
- MMLU-Pro(Wang et al., 2024)
- GPQA Diamond(Rein et al., 2023)
- HLE(Human Last Exam)Text-only(Phan et al., 2025)
- LiveCodeBench(2024.08--2025.04)
- Codeforces
- Aider-Polyglot
- AIME 2025
- HMMT Feb 2025 / Nov 2025(Balunović et al., 2025)
- IMOAnswerBench(Luong et al., 2025)
- Terminal Bench 2.0
- SWE-Verified(OpenAI, 2024b)
- SWE Multilingual(Yang et al., 2025)
- BrowseComp(Wei et al., 2025)
- BrowseCompZh(Zhou et al., 2025)
- τ²-bench(Barres et al., 2025)
- MCP-Universe(Luo et al., 2025)
- MCP-Mark(EvalSys, 2025)
- Tool-Decathlon(Li et al., 2025)
在工具使用(tool-use)基准中,我们以标准函数调用格式进行评估,模型设置为 thinking mode。对于 MCP-Universe 与 MCP-Mark,我们使用内部环境进行评测,因为搜索环境和 Playwright 环境可能与官方略有不同。
我们将 temperature 设置为 1.0,上下文窗口设置为 128K tokens。
对于数学类任务(AIME、HMMT、IMOAnswerBench、HLE),我们使用以下模板进行评测:
{question}
Please reason step by step, and put your final answer within \boxed{}.在 HLE 的评估中,我们还使用官方模板对 DeepSeek-V3.2-Thinking 进行测试,得分为 23.9。
与竞品模型的对比表现
- DeepSeek-V3.2 的推理能力接近 GPT-5-high,但略弱于 Gemini-3.0-Pro。
- 与 K2-Thinking 相比,DeepSeek-V3.2 在 输出 token 明显更少的情况下取得了可比性能 (见表 3)。
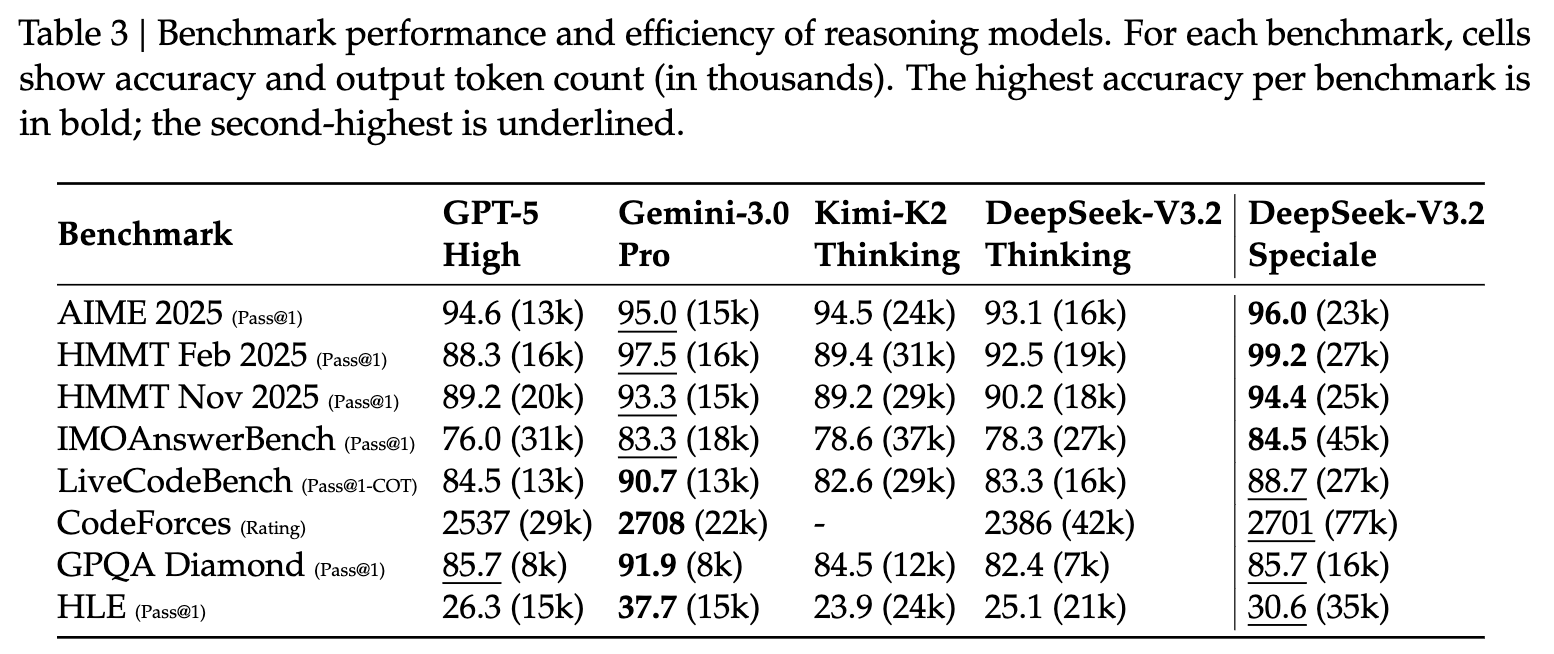
性能提升主要来自:
- 加大 RL 训练计算预算
- RL 训练时间的显著延长(已超过预训练成本的 10%)
我们观察到:随着 RL 预算进一步增加,模型推理表现持续提升。
我们推测:若继续增加训练算力,推理能力仍可进一步增强。
值得注意的是:
当前 DeepSeek-V3.2 的结果受到 长度约束奖励模型(length constraint reward model)的限制。移除该约束后,模型性能进一步提升,详见第 4.2 节。
代码智能体任务表现
DeepSeek-V3.2 在 SWE-bench Verified 与 Terminal Bench 2.0 上明显优于所有开源 LLM,展示出其在真实代码工作流中的潜力。
Terminal Bench 2.0
由于我们的 "思维模式上下文管理策略" 暂时不兼容 Terminus 框架,因此:
- 使用 Claude Code 框架 得到得分 46.4
- 在 Terminus 的 非思维模式 下评测,则得分 39.3
SWE-bench Verified
- 主结果来自我们的内部评测框架
- 使用 Claude Code、RooCode 以及非思维模式得到的结果一致,介于 72--74 之间,表现稳定
搜索智能体任务表现
我们使用商业搜索 API 进行评测。
由于 DeepSeek-V3.2 的最大上下文长度为 128K,测试集中约 20% 以上用例超过该长度。
为此,我们采用 上下文管理策略 来计算最终得分。
作为参考:
- 若不使用该策略,得分为 51.4
进一步细节见第 4.4 节。
工具使用基准(tool-use benchmarks)表现
DeepSeek-V3.2 已大幅缩小开源模型与闭源模型的差距,但仍落后于最新的前沿模型(frontier models)。
τ²-bench
我们让模型本身作为用户智能体,最终获得:
- 航空(Airline):63.8
- 零售(Retail):81.1
- 电信(Telecom):96.2
MCP 系列基准
我们使用函数调用格式,将工具输出放入 tool 角色消息(而非 user)。
测试中发现:
- DeepSeek-V3.2 经常进行 冗余自我验证
- 导致生成过长轨迹
- 从而在某些任务(如 MCP-Mark GitHub、Playwright)频繁触发 上下文超限(context overflow)
这现象拖累了最终成绩。
然而:
- 通过引入上下文管理策略,可显著改善该问题
- 我们将其视作未来工作方向及用户在实践中需要考虑的因素
尽管如此,DeepSeek-V3.2 仍显著优于所有现存开源模型。
特别是:
这些评测环境与工具从未作为 RL 训练数据出现 ,模型仍能大幅提升,说明 DeepSeek-V3.2 能将推理策略泛化至域外(out-of-domain) 智能体任务。
4.2 DeepSeek-V3.2-Speciale 的结果
表 3 显示,DeepSeek-V3.2-Speciale 通过使用更多的推理 tokens 获得了更优的性能,在多个基准上超越了当前最先进的 Gemini-3.0-Pro。值得注意的是,如表 4 所示,该通用模型在未经过专项训练的情况下,就在 2025 年国际信息学奥林匹克竞赛(IOI)和 ICPC 世界总决赛(ICPC WF)中达到了金牌水平。此外,通过结合 Shao 等人(2025)的方法,该模型在复杂证明任务中表现出色,在 2025 年国际数学奥林匹克(IMO)和中国数学奥林匹克(CMO)中达到了金牌线。
然而,DeepSeek-V3.2-Speciale 的 token 效率仍显著低于 Gemini-3.0-Pro。为了降低部署成本与延迟,我们在官方版本 DeepSeek-V3.2 的训练过程中施加了更严格的 token 约束,以优化性能与成本之间的权衡。我们认为,token 效率仍是未来需要重点研究的方向。
4.3 合成智能体任务
在本节中,我们通过消融实验研究合成智能体任务的作用,重点关注两个问题。其一,合成任务对于强化学习是否具有足够的挑战性?其二,这些合成任务的泛化能力如何,即它们能否迁移到不同的下游任务或真实环境中?
为回答第一个问题,我们从通用的合成智能体任务中随机抽取 50 个实例,分别评估用于生成这些任务的模型以及前沿闭源 LLM。如表 5 所示,DeepSeek-V3.2-Exp 的准确率仅为 12%,而前沿闭源模型的最高准确率也只有 62%。这些结果表明,合成数据中包含的智能体任务对 DeepSeek-V3.2-Exp 和闭源模型而言都具有相当挑战性。

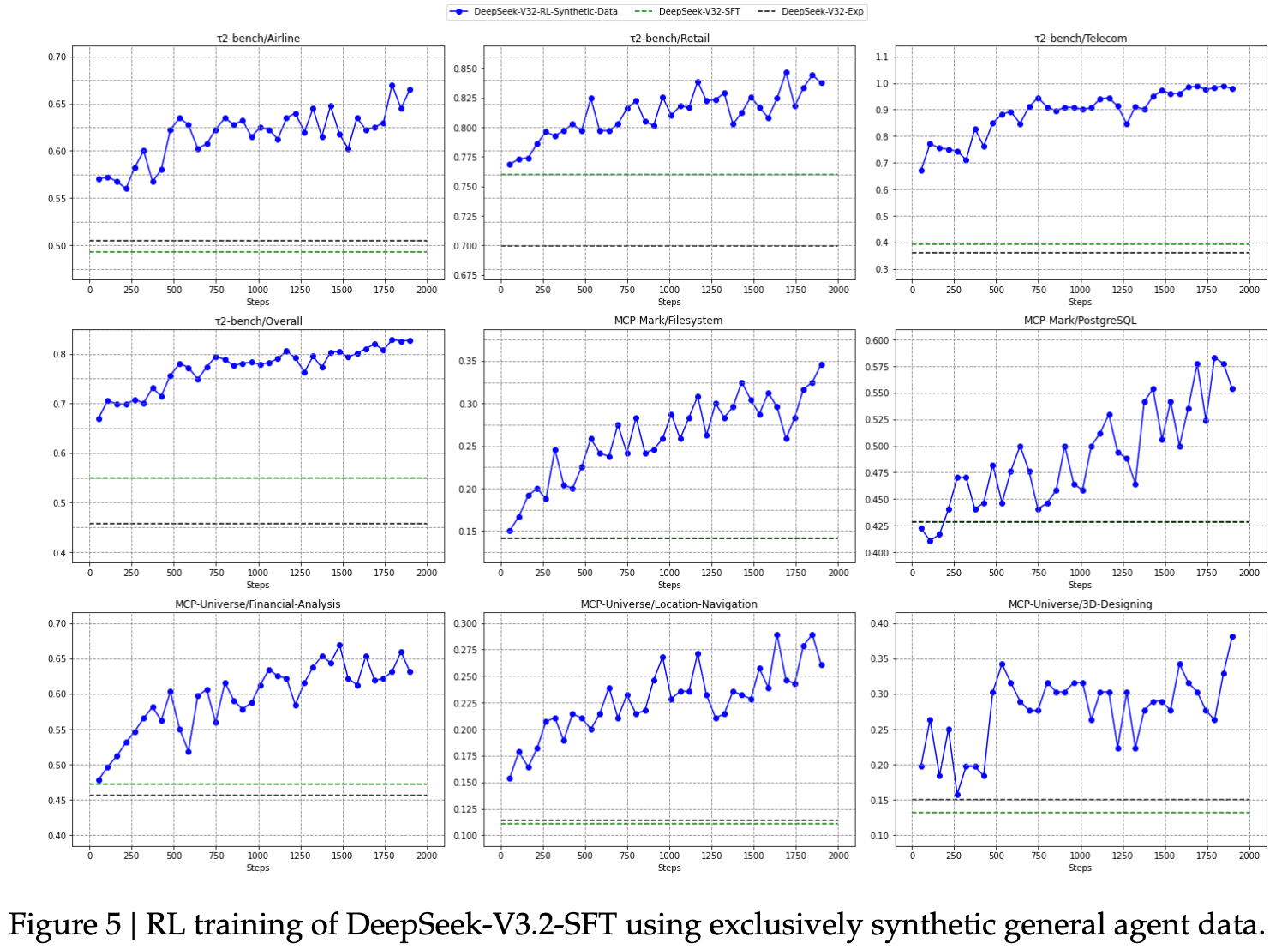
为研究基于合成数据的 RL 能否泛化到不同任务或真实环境,我们将 RL 应用于 DeepSeek-V3.2 的 SFT 检查点(记为 DeepSeek-V3.2-SFT)。为排除长链式推理(long CoT)及其他 RL 数据的影响,我们仅在非思维模式下对合成智能体任务进行 RL 训练。随后,我们将模型与 DeepSeek-V3.2-SFT 和 DeepSeek-V3.2-Exp 进行比较,其中 DeepSeek-V3.2-Exp 只在搜索和代码环境中进行 RL 训练。
如图 5 所示,大规模的合成数据 RL 在 Tau2Bench、MCP-Mark 和 MCP-Universe 基准上相较 DeepSeek-V3.2-SFT 带来了显著提升。相比之下,将 RL 限制在代码与搜索场景中并不能改善这些基准上的表现,进一步凸显了合成数据的潜力。
4.4 搜索智能体的上下文管理
即使具备如 128k 的扩展上下文窗口,在以搜索为核心的智能体工作流中,模型仍常因达到最大长度限制而导致推理过程被过早截断。这一瓶颈抑制了测试时计算(test-time compute)潜力的充分发挥。
为解决此问题,我们提出了一种上下文管理方法,当 token 使用量超过上下文窗口长度的 80% 时,通过简单策略在测试阶段扩展 token 预算。这些策略包括:
- Summary:对溢出的轨迹进行总结,然后重新启动 rollout;
- Discard-75%:丢弃轨迹中最早的 75% 工具调用历史,以释放上下文空间;
- Discard-all:丢弃所有先前的工具调用历史,重置上下文(类似于 Anthropic (2025a) 提出的新上下文工具)。
作为对照,我们还实现了一个并行扩展基线 Parallel-fewest-step,即采样 N 条独立轨迹并选取其中步骤最少的一条。
我们在 BrowseComp 基准(Wei et al., 2025)上评估了这些策略。
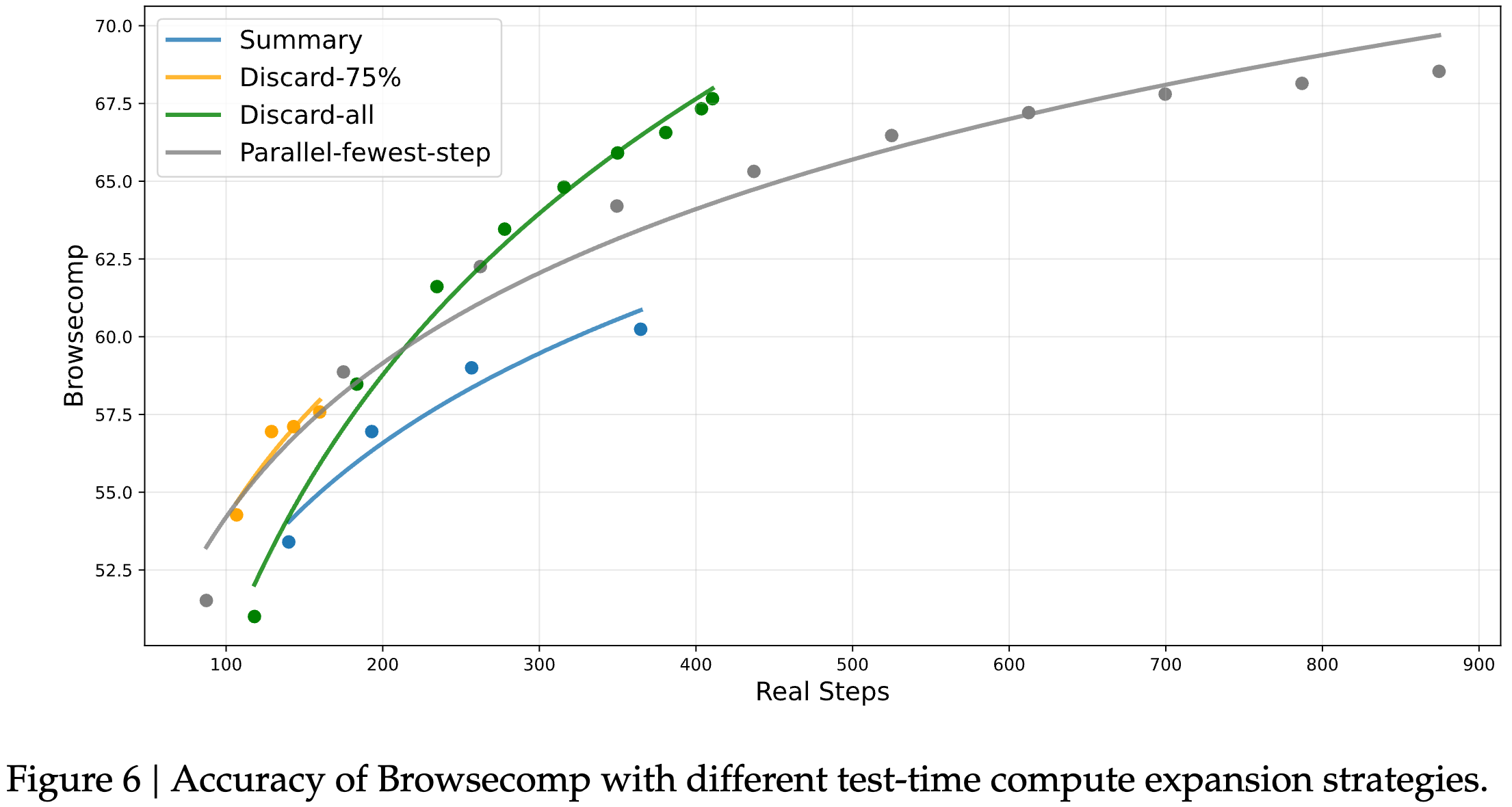
如图 6 所示,在不同的计算预算下,上下文管理通过允许模型扩展测试时计算量而带来显著性能提升,为模型执行更多步骤提供空间。例如:
- Summary 将平均执行步数扩展至 364,性能最高可提高至 60.2,但整体效率较低;
- Discard-all 尽管极为简单,却在效率与可扩展性上表现良好,以显著更少的步骤取得了 67.6 的得分,与并行扩展方法相当。
综上,测试时计算可以通过 串行方式(上下文管理) 或 并行方式 进行扩展,两者都能有效提升模型的任务求解能力。然而,不同策略的效率与可扩展性存在差异,因此在基准测试中需要考虑实际计算成本。
同时,如何在串行与并行扩展之间找到最优组合,使效率与可扩展性同时最大化,仍是未来的重要研究方向。
Conclusion
- 通过引入 DSA,在不牺牲长上下文性能的前提下解决了关键的计算复杂度问题
- 凭借增加的计算预算,DeepSeek-V3.2 在推理基准上实现了与 GPT-5 相当的表现
- 大规模智能体任务合成流水线的整合显著提升了工具使用能力
- 与 Gemini-3.0-Pro 这种前沿闭源模型比,DeepSeek-V3.2 仍存在一定局限性。目前差距可能的原因有
- 训练 FLOPs 不足,DeepSeek-V3.2 的世界知识广度仍落后于领先的商业模型
- token 效率仍是一项挑战;DeepSeek-V3.2 往往需要更长的生成轨迹(即更多 token)才能达到类似 Gemini-3.0-Pro 的输出质量