在上一篇中,我们通过百万级测试数据的写入解决了后端数据库的性能验证问题。但在软件研发的另一端------前端与 UI 交互层,开发人员面临着完全不同的痛点。
你是否经历过这样的尴尬时刻:
-
后端接口还没写好,前端页面全是"暂无数据",老板过来验收时显得界面空空荡荡。
-
表格组件在只有几条测试数据时很漂亮,一上线遇到"超长文本"就排版错乱,内容溢出屏幕。
-
分页组件在数据少时是隐藏的,导致没发现分页逻辑有 Bug,上线后翻页报错。
对于前端开发、测试以及 UI 设计师来说,可能需要的数据不是"多",而是"杂"和"满"。我们需要能够触发 UI 边界情况(Edge Cases) 的高保真数据。
本文将分享如何利用 SQLynx 的数据生成功能,快速填充"有意义"的 UI 测试数据,让你在后端接口 Ready 之前,就能完成前端适配。
01 场景准备:
假设我们正在开发一个 CMS(内容管理系统)的文章列表页,对应的数据库表结构如下:
CREATE TABLE `t_articles` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL COMMENT '文章标题',
`summary` varchar(1000) NOT NULL COMMENT '文章摘要',
`views` int(11) NOT NULL DEFAULT '0' COMMENT '阅读数',
`is_published` int(11) NOT NULL DEFAULT '0' COMMENT '0-草稿, 1-发布',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;我们的目标是:通过构造特殊数据,测试前端列表的自适应能力、文本截断逻辑以及数字格式化显示。
02 构造"破坏性"数据
在 SQLynx 中右键点击 t_articles 表,选择 "生成测试数据"。这次我们的配置策略不再是追求"快",而是追求"破坏性"的数据。
1. 测试布局崩坏:长文本生成
我们来生成长文本,测试冗长标题下UI是否仍然符合预期。
-
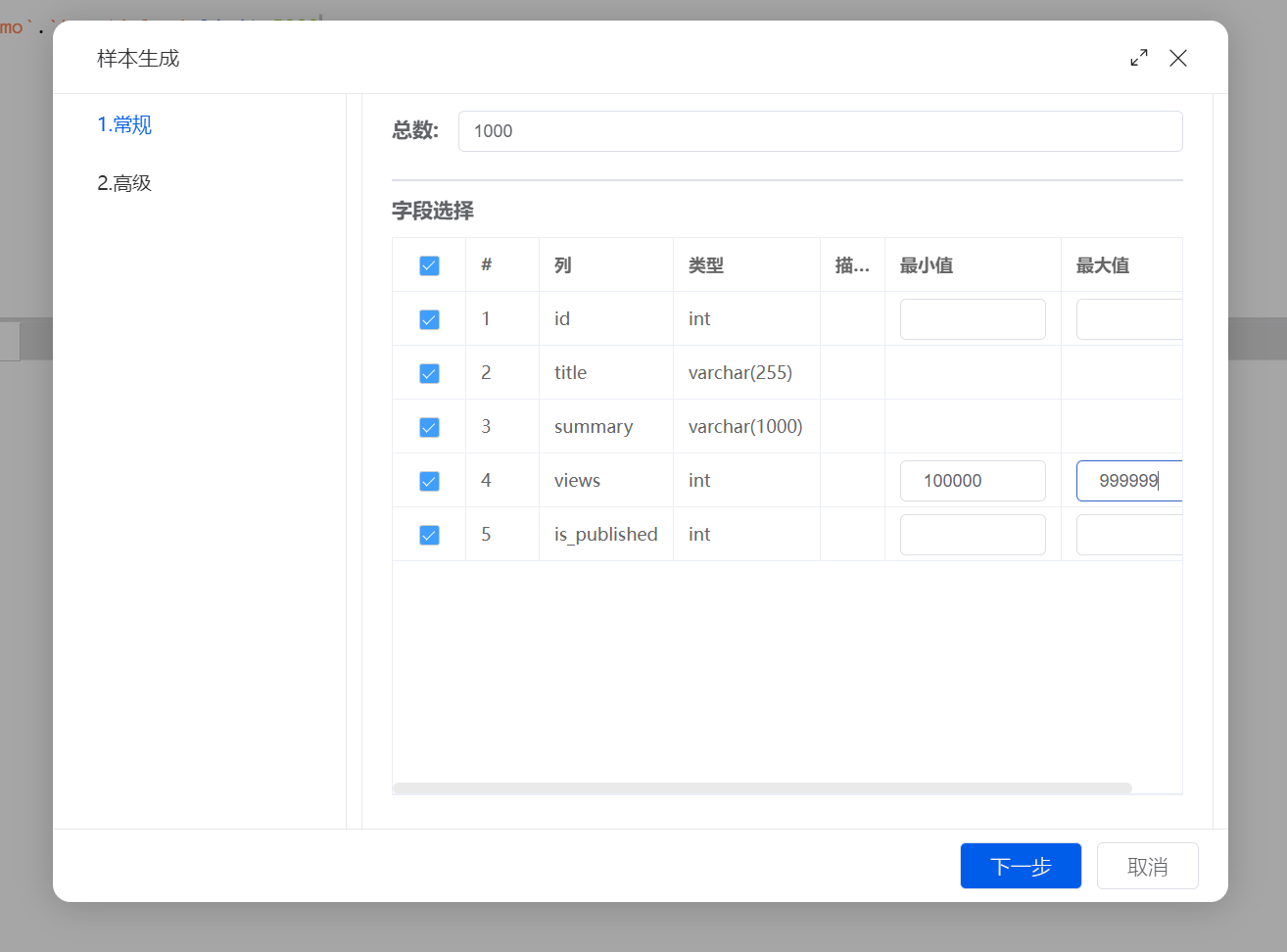
title字段配置:-
生成模式: 选择 "随机字符串"。
-
长度范围: 设置为 255(或根据实际设计的标题可容纳最高数值)。
-
前端验收点: 观察页面上的标题是否正确换行?或者是否超出一行后显示省略号(...)?
-
-
summary字段配置:-
生成模式: 选择 "随机字符串"。
-
长度范围: 设置为 1000(或根据实际设计的标题可容纳最高数值)。
-
前端验收点: 测试摘要区域的高度是否自适应,会不会把底部的按钮挤出屏幕。
-
2. 测试数值格式化:极端数字
阅读数 views 字段,当数字很大时,检查是否会显示异常或撑破列宽。
-
views字段配置:-
生成模式: 选择 "随机整数"。
-
范围设置: 100000 - 999999。
-
前端验收点:
-
数字是否进行了千分位格式化(如
1,000,000)? -
超大数字是否进行了缩写处理(如
100k或10w+)?
-
-
03 模式选择:清空与重置
与后端压测不同,前端调试往往需要反复重置环境。比如第一轮测试"无数据"状态,第二轮测试"满数据"状态。
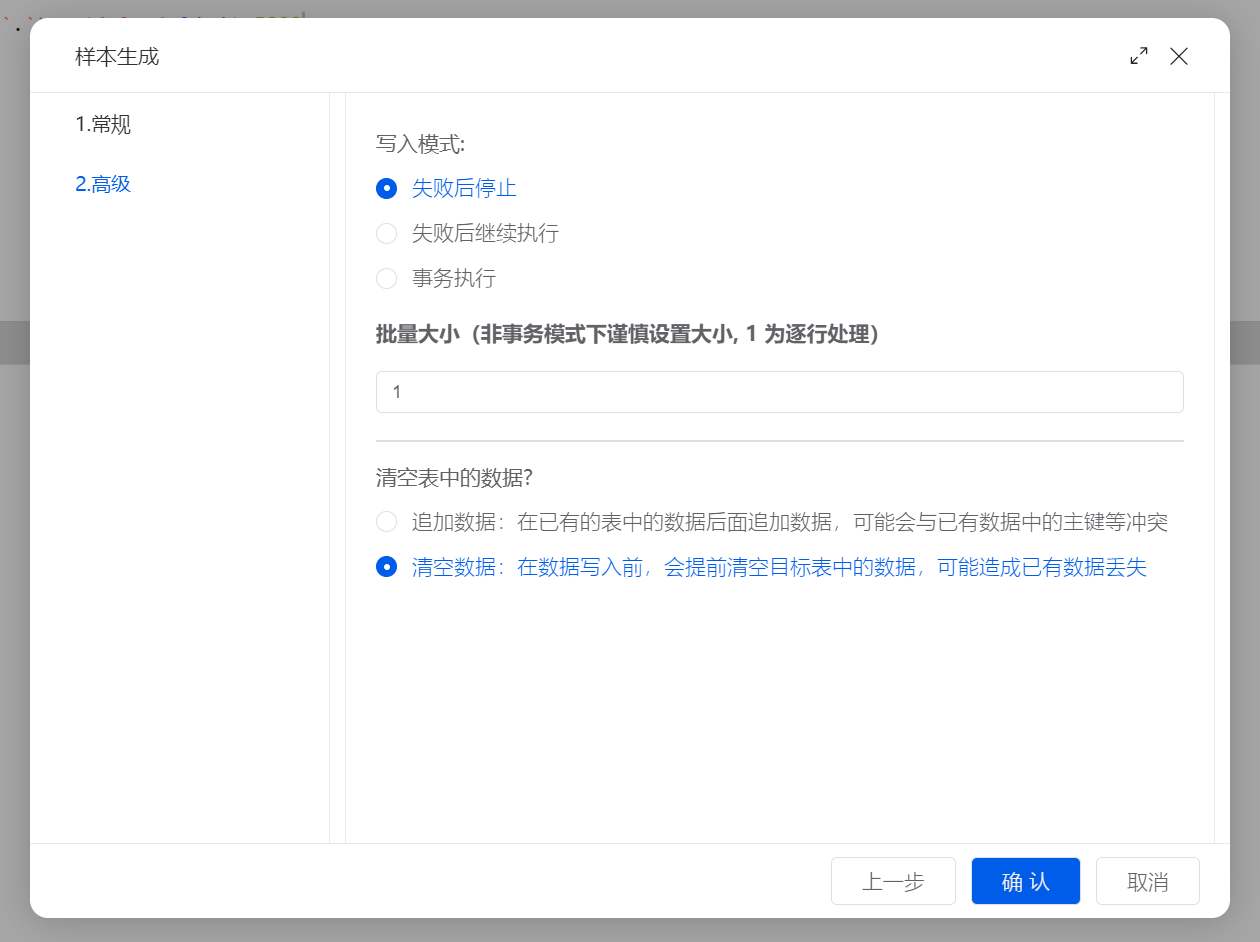
在 SQLynx 的写入策略中,建议灵活使用 "清空数据" 模式:
-
清空数据(Truncate): 勾选此项。每次生成前,工具会先清空表。
-
生成数量:
-
设置 0 条 -> 验证"空状态"占位图是否显示。
-
设置 12 条(假设每页 10 条) -> 验证分页条是否出现,第二页是否正常加载。
-
04 总结
前端开发的质量,很大程度上取决于测试数据的丰富度。
利用SQL工具的数据生成功能,通过几分钟的简单配置,无需耗费时间写脚本,就可以很快在本地构造出大量测试数据,以供我们使用。