
这是一个毫无复习章法的笔记,反正还有10天,瞎吉尔看吧,这19页大提纲给我干没脾气了
第1章 大数据技术概述
1.请阐述大数据的基本处理流程。
(课本P2第二段)数据采集、存储和管理、处理与分析。结果呈现等环节
2.请阐述大数据的计算模式及对应代表性产品。
(课本P2表1-2)
| 大数据计算模式 | 代表性产品 |
|---|---|
| 批处理计算 | MapReduce、Spark等 |
| 流计算 | Flink、Storm、Spark Streaming、S4等 |
| 图计算 | Pregel、GraphX、Giraph等 |
| 查询分析计算 | Dremel、Hive、Cassandra等 |
3.请列举Hadoop生态系统的各个组件及其功能。
(课本P4图1-1)

4.分布式文件系统HDFS的名称节点和数据节点的功能分别是什么?
(课本P4第二段)名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问;数据节点负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除及复制等操作。
5.请阐述MapReduce的基本设计思想。
(课本P5第四段)计算向数据靠拢
6.YARN的主要功能是什么?使用YARN可以带来哪些好处?
(课本P5第五段)YARN是负责集群资源调度管理的框架;可以有效提高集群的利用率,避免数据集跨集群移动,降低企业运维成本。
7.请阐述Hadoop生态系统中HBase与其他部分的关系。
(课本P6图1-5)

8.数据仓库Hive的主要功能是什么?
(课本P5第三段)可对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析。
9.Hadoop主要有哪些缺陷?相比之下,Spark具有哪些优势?
(课本P6 1.2.2.2)
表达能力有限、磁盘I/O开销大、延迟该;更灵活、迭代运算效率更高、基于DAG的任务调度执行机制
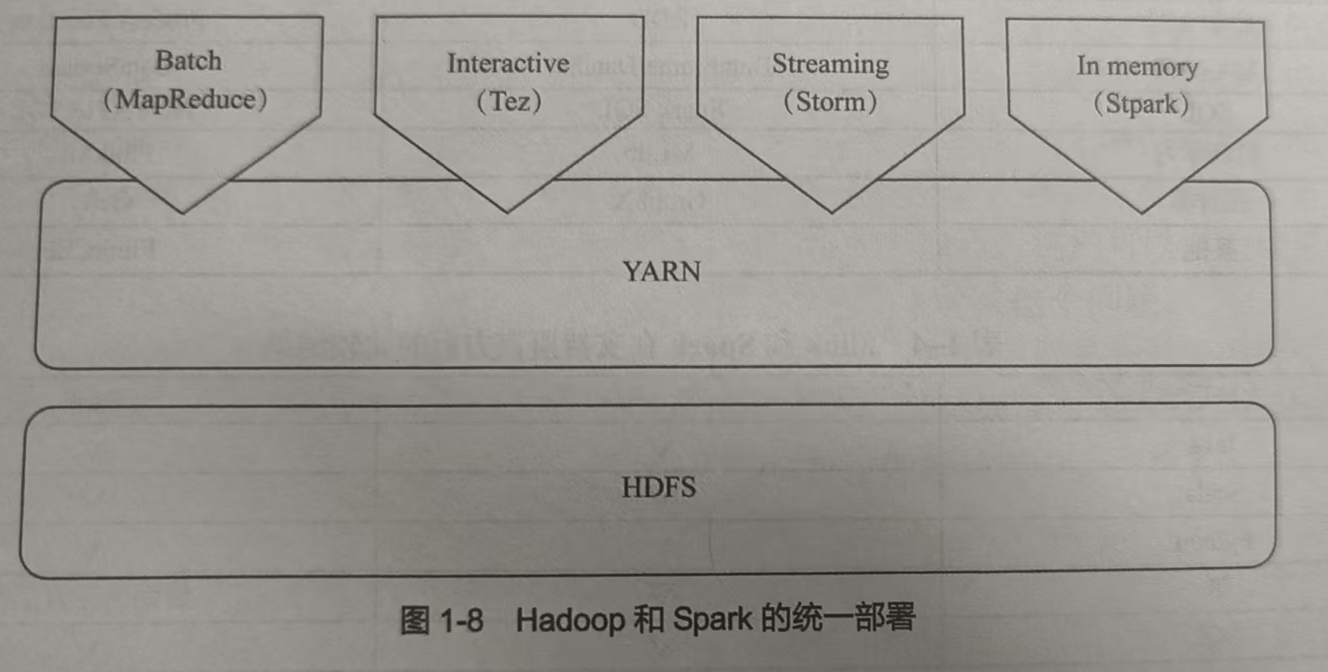
10.如何实现Spark与Hadoop的统一部署?
(课本P9图1-8)
11.相对Spark而言,Flink在实现机制上有什么不同?
Flink全部当成流处理,Spark全部当成批处理
12.Beam的设计目标是什么?具有哪些优点?
(课本P11最后一段)目标是为开发者提供一个易于使用的、强大的数据并行处理模型,能够支持流处理和批处理,并兼容多个运行引擎;开源、统一。
第2章 Flink的设计与运行原理
1.请阐述传统数据处理架构的局限性。
(课本P16第一段)一旦发生问题影响严重,出现异常问题时难以保证系统yuxn
2.请阐述大数据Lambda架构的优点和局限性。
(课本P16第四段)系统构建工作更简单,一定程度上解决了不同计算类型的问题;平台复杂度高、运维成本高。
3.请阐述与传统数据处理架构和大数据Lambda架构相比,流处理架构具有什么优点。
(课本P17第三段)避免了传统数据处理架构中存在的"数据库不堪重负"的问题和大数据Lambda架构中存在的"多个框架难管理"的问题。
4.请举例说明Flink在企业中的应用场景。
- (课本P19 2.3.1.1)事件驱动型应用如反欺诈、异常检测、给予规则的报警、业务流程监控、Web应用。
- (课本P20 2.3.2.1)数据分析应用如电信网络质量监控、移动应用中的产品更新及试验评估分析、消费者技术中的实时数据即席分析。
- (课本P21 2.3.3.1)数据流水线应用如电子商务中的实时查询索引构建和持续ETL。
5.请阐述Flink核心组件栈包含哪些层以及每层具体包含哪些内容。
(课本P23图2-10)

6.请阐述Flink的JobManager和TaskManager具体有哪些功能。
(课本P24第一三段)JobManager负责整个Flink集群任务的调度以及资源的管理;TaskManager相当于整个集群的从节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。
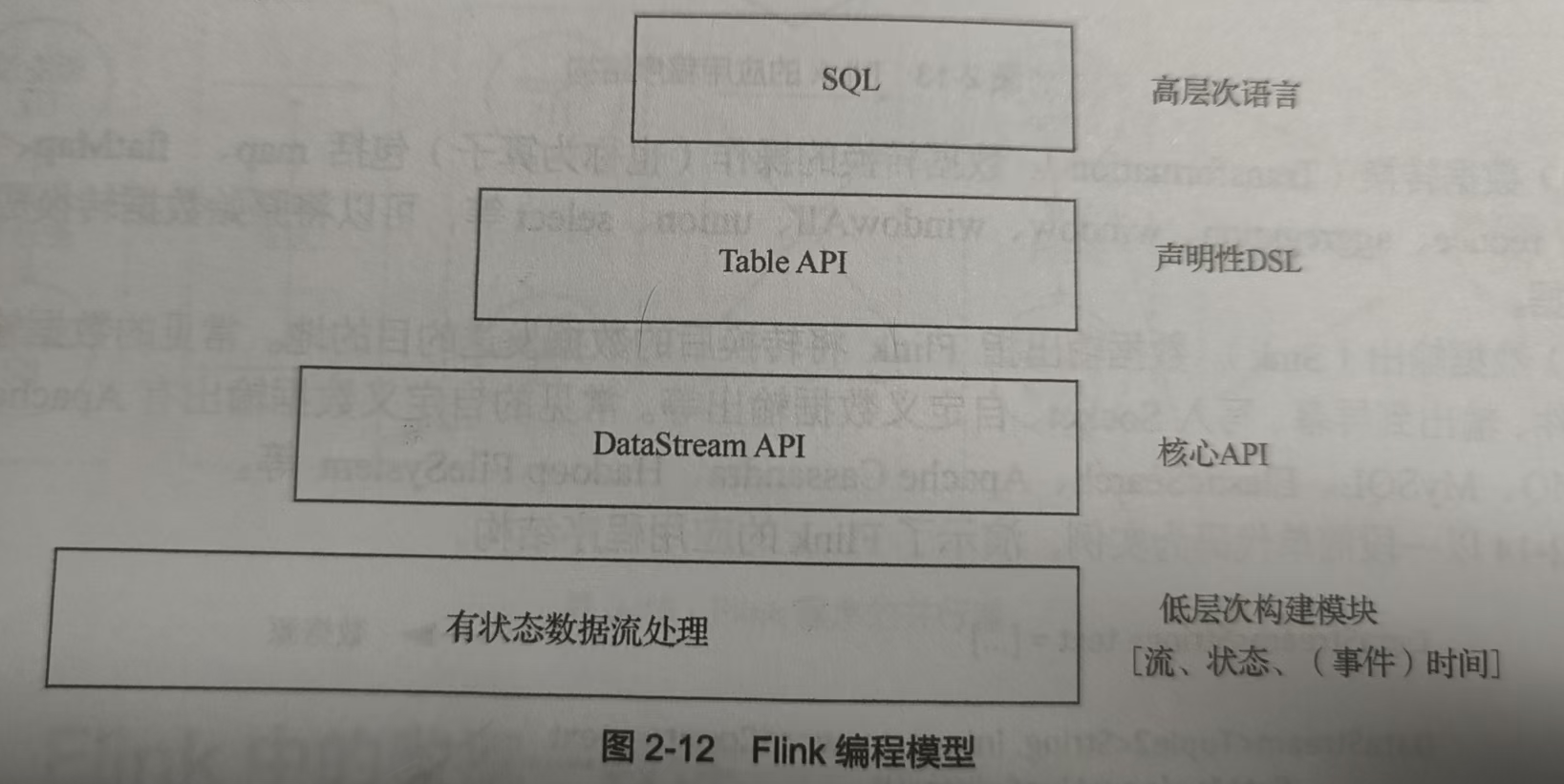
7.请阐述Flink编程模型的层次结构。
(课本P25图2-12)
8.请对Spark、Flink和Storm进行对比分析。
| 对比维度 | Storm | Flink | Spark |
|---|---|---|---|
| 核心定位 | 原生流处理(仅无界流) | 原生流处理(批流统一) | 原生批处理(微批流) |
| 处理模型 | 单事件驱动 | 事件驱动+Pipeline | 微批模拟 |
| 延迟级别 | 亚毫秒~毫秒级 | 毫秒级 | 秒级(依赖微批) |
| 吞吐量 | 低 | 高(兼顾延迟) | 高(批处理优化) |
| 时间语义 | 仅处理时间(基础版) | 处理/事件/摄入时间+Watermark | 1.6+支持事件时间(弱) |
| 状态管理 | 无原生(需第三方) | 原生Keyed/Operator State | 无原生(依赖缓存/外部) |
| 容错机制 | Acker机制 | 分布式快照(异步增量) | Lineage+全量Checkpoint |
| 容错语义 | At-Least-Once | 原生Exactly-Once | 默认At-Least-Once |
| 适用场景 | 超低延迟实时场景 | 低延迟+有状态流处理 | 批处理+近实时流处理 |
9.请阐述数据一致性的3种模式。
(课本P28 2.10.2)最多一次、至少一次、精确一次。
10.请阐述Flink的异步屏障快照机制。
(课本P28第八段)以低成本备份DAG或DCG计算作业的状态,这使得计算作业可以频繁进行快照并且不会对性能产生明显影响。
第3章 大数据实验环境搭建
1.请阐述Linux系统有哪些发行版本。
Debian、Ubuntu等等等等
2.请阐述Hadoop 1.0和Hadoop 2.0的主要区别是什么。
(课本P38第四段)Hadoop 2.0完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统。
3.请阐述为什么要在Linux系统中安装SSH。
(课本P39最后一段)省得输密码比较方便。
4.请阐述Hadoop的安装模式主要包含哪几种。
(课本P41 3.2.3)单机模式、伪分布式模式、分布式模式。
5.请阐述Hadoop伪分布式模式和分布式模式的主要区别是什么。
(课本P41 3.2.3)HDFS的名称节点和数据节点是否位于同一台机器上。
6.请阐述如何解决MySQL中存在的中文乱码问题。
(课本P57 3.3.4)修改配置文件/etc/mysql/mysql.conf.d/mysql.cnf在[mysqld]下面添加一行character_set_server=utf8
第4章 Flink环境搭建和使用方法
1.请阐述Flink的4种部署模式。
(课本P63章首语)Local模式、Standalone模式、YARN模式、Kubernetes模式。
2.请阐述Flink和Hadoop的关系。
(课本P63章首语)通常Hadoop中的HDFS和HBase等组件负责数据存储和管理,由Flink负责计算。
3.请阐述使用IDEA对程序进行编译和打包的基本方法。
(课本P69)在项目开发界面的右侧单击Maven按钮,在弹出的界面中双击package。打包成功以后,可以在项目开发界面左侧目录树的target子目录下找到两个jar文件。
4.请阐述如何安装Java环境。
(课本P75 4.5.2)每个节点都按照第三章说的操作安装一遍。
5.请阐述如何设置SSH无密码登录。
(课本P75 4.5.3)同上。
6.请阐述Flink集群环境搭建的基本过程。
(课本P74 4.5)配置集群基础、在集群中安装Java环境、设置SSH无密码登录、安装和配置Flink、启动和关闭Flink集群。
7.请阐述Flink包含哪些运行模式。
(课本P79 4.6)会话模式、单作业模式、应用模式。
第5章 DataStream API
1.请阐述Flink流处理程序的基本运行流程包括哪5个步骤。
(课本P90 5.1)创建执行环境、创建数据源、指定对接收的数据进行转换操作的逻辑、指定数据计算的输出结果方式、程序触发执行。
2.请蚴阐述Flink的窗口是如何划分的。
(课本P126 5.2)基于时间的窗口根据起始时间戳和终止时间戳来决定窗口的大小;基于数量的窗口根据固定的数量来决定窗口的大小。
3.请阐述Flink的3种时间及其具体含义。
(课本P127-128 5.3)事件时间是每个独立事件在设备上产生的时间;接入时间是数据进入Flink系统的时间;处理时间是数据在操作算子计算过程中获取到的所在主机时间。
4.请阐述分组数据流的窗口计算程序结构。
(课本P128 5.4.1)先使用KeyBy()函数把无限数据流拆分成逻辑分组的数据流,然后调用window()函数进行接口计算。
5.请阐述Flink提供了哪些常用的预定义窗口分配器。
(课本P129 5.4.2)滚动窗口、滑动窗口、会话窗口、全局窗口。
6.请阐述Flink提供了哪3种类型的窗口计算函数。
(课本P132 5.4.3)ReduceFunction、AggregateFunction、ProcessWindowFunction。
7.请阐述水位线的基本原理。
(课本P146 5.5.1)水位线是流处理中基于事件时间的逻辑标记,定义数据到达时间边界,平衡无序 / 延迟数据处理的完整性与实时性。
8.请阐述水位线的设置方法。
(课本P149 5.5.2)构建一个DataStream后,可以使用assignTimestampsAndWatermarks()方法来分配时间戳和水位线,调用该方法时,需要传入一个WatermarkStrategy对象,语法如下:
java
dataStream.assignTimestampsAndWatermarks(WatermarkStategy<T>)9.请阐述键控状态包括哪几种状态。
(课本P174 5.8.3)括值状态、列表状态、映射状态、归约状态、聚合状态。
10.请阐述处理函数的功能和作用。
(课本P183-184 5.9.1)ProcessFunction可以被认为是一种提供了对KeyedState和定时器访问的FlatMapFunction。每当输入流接收到一个事件时,就会调用此函数来处理。
第6章 Table API&SQL
1.请阐述基于TableAPI和SQL的数据处理应用程序主要包括哪几个步骤。
| 步骤 | 说明 |
|---|---|
| 1 | 初始化TableEnvironment,配置运行环境 |
| 2 | 注册数据源,接入待处理的数据 |
| 3 | 编写TableAPI/SQL语句实现数据处理逻辑 |
| 4 | 执行查询,生成处理后的结果表 |
| 5 | 将结果表写入目标存储(如数据库、文件) |
2.请阐述在批处理和流处理两种情形下TableEnvironment的创建方法。
批处理基于BatchExecutionEnvironment创建,或通过TableEnvironment.create(BatchTableEnvironmentSettings)构建;流处理基于StreamExecutionEnvironment创建,或通过TableEnvironment.create(StreamTableEnvironmentSettings)构建
3.请阐述在Flink中注册表有哪几种方式。
一是通过connect() API连接数据源,配置格式和模式后注册表;二是调用createTemporaryTable()创建临时表;三是执行CREATE TABLE格式的DDL语句直接注册;四是关联Hive等外部Catalog注册Catalog表。
4.请阐述Calcite执行SQL查询的主要步骤有哪些。
1.解析SQL生成抽象语法树;2.语义验证确保语法和逻辑合法;3.优化(逻辑+物理)生成最优执行计划;4.执行优化后的计划;5.返回查询结果。
5.TableAPI中的事件时间也是从输入事件中提取而来的,请阐述定义事件时间的方法有哪几种。
一是定义 Schema 时为字段指定 rowtime 属性,搭配水印策略;二是创建表的 DDL 中用 WATERMARK FOR 子句,从数据源字段提取事件时间并定义水印。
6.请阐述Table API有哪些不同类型的操作。
基础查询类(选择、过滤、投影等);聚合类(分组聚合、窗口聚合);连接类(内/外连接、等值连接等);集合类(并、交、差集);窗口类(时间/计数窗口);转换类(列重命名、类型转换)。
7.请阐述SQL有哪些不同类型的操作。
查询类(SELECT,含聚合、连接、窗口函数等);定义类(CREATE/ALTER/DROP,管理表/视图等);操作类(INSERT/UPDATE/DELETE,增删改数据);控制类(COMMIT/ROLLBACK,管控事务)。
8.根据处理的数据类型以及计算方式的不同,请阐述自定义函数分为哪几种类型。
(课本P253 6.6)标量函数、表值函数、聚合函数、表聚合函数。