注意:
由于医疗数据的敏感性和获取难度,我将创建一个基于公开医疗数据的模拟系统。
这个系统将展示完整的医疗诊断辅助流程,并包含所有要求的特性。
第一部分:项目介绍与准备工作(适合基础薄弱学生)
1.1 项目目标
让我们创建一个简单的医疗诊断系统,使用朴素贝叶斯算法根据症状预测可能的疾病。这个项目会从零开始,我会一步步带你完成。
1.2 需要的知识点(我们会慢慢讲解)
-
Python基础语法
-
列表、字典、循环
-
基本的概率概念(我们会用简单的方式解释)
-
机器学习的基本概念
1.3 环境准备
python
# 只需要安装几个基础库,在命令行运行:
pip install pandas numpy scikit-learn matplotlib
第二部分:最简单的版本(先理解核心)
2.1 最简单的朴素贝叶斯理解
朴素贝叶斯的本质:根据症状出现的概率,计算得某种疾病的概率
比如:
-
如果一个人有"发烧",得"流感"的概率是多少?
-
如果同时有"发烧"和"咳嗽",得"流感"的概率又是多少?
2.2 创建一个超简化的版本
python
# ============ 第一步:导入最基本的库 ============
import pandas as pd
import numpy as np
from collections import defaultdict
print("开始创建最简单的医疗诊断系统!")
# ============ 第二步:创建简单的模拟数据 ============
# 我们先用一个非常小的例子来理解
simple_diseases = ['流感', '感冒', '肺炎']
simple_symptoms = ['发烧', '咳嗽', '头痛', '流鼻涕']
# 模拟10个病人的数据
patients = [
# 病人ID, 症状列表, 疾病
['P1', ['发烧', '咳嗽'], ['流感']],
['P2', ['发烧', '头痛'], ['流感']],
['P3', ['流鼻涕', '咳嗽'], ['感冒']],
['P4', ['发烧', '咳嗽', '头痛'], ['肺炎']],
['P5', ['咳嗽', '流鼻涕'], ['感冒']],
['P6', ['发烧'], ['流感']],
['P7', ['咳嗽', '头痛'], ['肺炎']],
['P8', ['流鼻涕'], ['感冒']],
['P9', ['发烧', '咳嗽'], ['肺炎']],
['P10', ['头痛', '流鼻涕'], ['感冒']],
]
# 转换为DataFrame(类似表格)
df_simple = pd.DataFrame(patients, columns=['patient_id', 'symptoms', 'diseases'])
print("\n简单的病人数据:")
print(df_simple)
# ============ 第三步:计算概率(朴素贝叶斯的核心) ============
def calculate_naive_bayes(train_data, test_symptoms):
"""
朴素贝叶斯算法实现
train_data: 训练数据
test_symptoms: 要预测的症状
"""
# 1. 统计每种疾病出现的次数
disease_counts = defaultdict(int)
symptom_counts = defaultdict(lambda: defaultdict(int))
# 遍历每个病人
for _, row in train_data.iterrows():
diseases = row['diseases']
symptoms = row['symptoms']
for disease in diseases:
disease_counts[disease] += 1
for symptom in symptoms:
symptom_counts[disease][symptom] += 1
# 计算总病人数
total_patients = len(train_data)
print(f"\n=== 统计信息 ===")
print(f"总病人数: {total_patients}")
print(f"疾病出现次数: {dict(disease_counts)}")
# 2. 计算先验概率(得某种病的概率)
prior_probabilities = {}
for disease, count in disease_counts.items():
prior_probabilities[disease] = count / total_patients
print(f"得{disease}的先验概率: {count}/{total_patients} = {prior_probabilities[disease]:.3f}")
# 3. 计算条件概率(在有某种病的情况下,出现某症状的概率)
conditional_probabilities = defaultdict(dict)
for disease in disease_counts.keys():
total_with_disease = disease_counts[disease]
# 为每个症状计算条件概率
for symptom in simple_symptoms:
count_with_symptom = symptom_counts[disease].get(symptom, 0)
# 使用拉普拉斯平滑(避免概率为0)
conditional_probabilities[disease][symptom] = (count_with_symptom + 1) / (total_with_disease + len(simple_symptoms))
# 只打印非零的概率,便于理解
if count_with_symptom > 0:
print(f"在得{disease}的情况下,有{symptom}的概率: {count_with_symptom}/{total_with_disease} ≈ {conditional_probabilities[disease][symptom]:.3f}")
# 4. 对新症状进行预测
print(f"\n=== 对新症状进行预测 ===")
print(f"新症状: {test_symptoms}")
posterior_probabilities = {}
for disease in disease_counts.keys():
# 开始计算后验概率 P(疾病|症状) ∝ P(疾病) × Π P(症状|疾病)
posterior = prior_probabilities[disease] # 初始化为先验概率
for symptom in test_symptoms:
if symptom in conditional_probabilities[disease]:
posterior *= conditional_probabilities[disease][symptom]
else:
# 如果症状没在训练集中出现过,使用一个很小的概率
posterior *= 1 / (disease_counts[disease] + len(simple_symptoms))
posterior_probabilities[disease] = posterior
print(f"得{disease}的概率: {posterior:.6f}")
# 5. 归一化(让所有概率之和为1)
total_prob = sum(posterior_probabilities.values())
if total_prob > 0:
for disease in posterior_probabilities:
posterior_probabilities[disease] /= total_prob
print(f"\n=== 归一化后的概率 ===")
for disease, prob in sorted(posterior_probabilities.items(), key=lambda x: x[1], reverse=True):
print(f"得{disease}的概率: {prob:.3f} ({prob*100:.1f}%)")
return posterior_probabilities
# 测试我们的朴素贝叶斯算法
print("\n" + "="*50)
print("朴素贝叶斯算法演示")
print("="*50)
# 预测一个有"发烧"和"咳嗽"的病人
test_symptoms = ['发烧', '咳嗽']
probabilities = calculate_naive_bayes(df_simple, test_symptoms)
# 找出最可能的疾病
most_likely_disease = max(probabilities, key=probabilities.get)
print(f"\n预测结果:该病人最可能患有【{most_likely_disease}】")这段代码创建了一个最基础的朴素贝叶斯算法演示,包含以下功能:
-
创建模拟数据:制作了一个只有10个病人的极小数据集,包含流感、感冒、肺炎三种疾病和发烧、咳嗽等四种症状。
-
手动实现算法:没有使用任何机器学习库,而是自己编写朴素贝叶斯的核心计算逻辑。
-
展示计算过程:逐步打印了先验概率、条件概率和后验概率的计算过程,让初学者能看到算法"背后的数学"。
-
进行预测:给定新症状(如发烧咳嗽),计算每种疾病的概率。
这段代码就像一本"打开的书",把朴素贝叶斯的所有计算细节都展示给学生看,帮助他们理解算法的数学本质。虽然简单,但包含了算法的所有核心概念。
2.3 运行这个简单版本
运行上面的代码,你会看到:
-
显示了10个病人的数据
-
计算了各种概率
-
对新的症状进行了预测
关键概念解释:
-
先验概率:得某种病的普遍概率
-
条件概率:在得了某种病的情况下,出现某种症状的概率
-
后验概率:有了症状后,得某种病的概率
第三部分:稍微完整的版本
现在让我们创建一个更完整的系统,但仍然是简化的:
python
# ============ 完整但简化的医疗诊断系统 ============
# 1. 创建更真实的数据集
def create_better_dataset():
"""创建更好的医疗数据集"""
diseases = ['流感', '普通感冒', '肺炎']
symptoms = ['发烧', '咳嗽', '头痛', '流鼻涕', '乏力', '呼吸困难']
# 疾病与症状的对应关系(医学知识)
disease_symptom_relation = {
'流感': ['发烧', '咳嗽', '头痛', '乏力'],
'普通感冒': ['流鼻涕', '咳嗽', '头痛'],
'肺炎': ['发烧', '咳嗽', '呼吸困难', '乏力']
}
# 创建100个病人
patients = []
for i in range(100):
# 随机选择一种疾病
disease = np.random.choice(diseases)
# 根据疾病选择症状
possible_symptoms = disease_symptom_relation[disease]
# 随机选择2-4个症状
num_symptoms = np.random.randint(2, min(5, len(possible_symptoms) + 1))
patient_symptoms = list(np.random.choice(possible_symptoms, num_symptoms, replace=False))
# 添加一些随机噪音(10%的概率加一个不相关症状)
if np.random.random() < 0.1:
other_symptoms = [s for s in symptoms if s not in patient_symptoms]
if other_symptoms:
patient_symptoms.append(np.random.choice(other_symptoms))
patients.append({
'patient_id': f'P{i+1000}',
'symptoms': patient_symptoms,
'disease': disease # 这里假设每人只有一种病
})
return pd.DataFrame(patients), diseases, symptoms
# 创建数据集
print("创建更完整的数据集...")
df_better, diseases_better, symptoms_better = create_better_dataset()
print(f"数据集大小:{len(df_better)} 个病人")
print(f"疾病种类:{diseases_better}")
print(f"症状种类:{symptoms_better}")
# 显示前几个病人
print("\n前5个病人数据:")
print(df_better.head())
# 2. 使用scikit-learn实现朴素贝叶斯(更简单的方式)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
print("\n" + "="*50)
print("使用scikit-learn库实现朴素贝叶斯")
print("="*50)
# 准备数据
# 把症状列表转换为文本
df_better['symptoms_text'] = df_better['symptoms'].apply(lambda x: ' '.join(x))
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
df_better['symptoms_text'],
df_better['disease'],
test_size=0.2, # 20%作为测试集
random_state=42
)
print(f"训练集大小:{len(X_train)}")
print(f"测试集大小:{len(X_test)}")
# 将文本转换为特征向量
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
print(f"特征数量(不同的症状组合):{len(vectorizer.get_feature_names_out())}")
print(f"特征示例:{vectorizer.get_feature_names_out()[:10]}") # 显示前10个特征
# 创建并训练朴素贝叶斯模型
model = MultinomialNB()
model.fit(X_train_vec, y_train)
# 在测试集上评估
y_pred = model.predict(X_test_vec)
accuracy = accuracy_score(y_test, y_pred)
print(f"\n模型准确率:{accuracy:.3f} ({accuracy*100:.1f}%)")
# 3. 制作一个简单的诊断函数
def simple_diagnosis(symptom_text):
"""简单的诊断函数"""
# 转换输入文本
symptom_vec = vectorizer.transform([symptom_text])
# 预测
prediction = model.predict(symptom_vec)[0]
probabilities = model.predict_proba(symptom_vec)[0]
# 显示结果
print(f"\n症状:{symptom_text}")
print(f"预测疾病:{prediction}")
print("各种疾病的概率:")
for disease, prob in zip(model.classes_, probabilities):
print(f" {disease}: {prob:.3f} ({prob*100:.1f}%)")
return prediction
# 测试一些症状
print("\n" + "="*50)
print("诊断测试")
print("="*50)
# 测试1:流感症状
simple_diagnosis("发烧 咳嗽 头痛")
# 测试2:感冒症状
simple_diagnosis("流鼻涕 咳嗽")
# 测试3:肺炎症状
simple_diagnosis("发烧 呼吸困难 乏力")
# 4. 交互式诊断
def interactive_simple_diagnosis():
"""交互式诊断"""
print("\n欢迎使用简单医疗诊断系统!")
print("输入症状,用空格分隔(例如:发烧 咳嗽 头痛)")
print("输入'退出'结束程序")
while True:
print("\n" + "-"*30)
symptoms = input("请输入症状:").strip()
if symptoms.lower() in ['退出', 'exit', 'quit']:
print("感谢使用!")
break
if symptoms:
try:
simple_diagnosis(symptoms)
except:
print("抱歉,出现了错误。请尝试其他症状描述。")
# 运行交互式诊断(可选)
# interactive_simple_diagnosis()这段代码创建了一个更实用的朴素贝叶斯医疗诊断系统,特点是:
-
更大的数据集:使用100个模拟病人,更接近真实场景。
-
使用scikit-learn库:展示了如何使用机器学习库快速实现算法,与手动实现形成对比。
-
完整的机器学习流程:
- 数据准备 → 特征提取 → 模型训练 → 评估 → 应用
-
简单但实用的诊断函数:可以输入症状文本,输出预测疾病和概率。
-
交互式界面:用户可以在命令行中输入症状进行诊断。
这段代码教会读者如何在实际项目中使用机器学习库,重点在于"如何使用工具"而不是"工具如何制造"。
第四部分:分步骤实现完整项目
4.1 数据创建部分
由于完整的项目代码较长,我将它分解为几个部分,并添加详细解释:
python
"""
第一部分:数据创建
目标:创建模拟的医疗数据
"""
import pandas as pd
import numpy as np
def create_medical_data_simple():
"""
创建简单的医疗数据
学生可以先理解这个简化版本
"""
# 常见疾病
diseases = ['流感', '普通感冒', '肺炎', '支气管炎']
# 常见症状
symptoms = ['发烧', '咳嗽', '头痛', '流鼻涕', '乏力', '呼吸困难', '喉咙痛']
# 疾病-症状关系(医学常识)
disease_to_symptoms = {
'流感': ['发烧', '咳嗽', '头痛', '乏力'],
'普通感冒': ['流鼻涕', '咳嗽', '喉咙痛'],
'肺炎': ['发烧', '咳嗽', '呼吸困难', '乏力'],
'支气管炎': ['咳嗽', '呼吸困难']
}
patients = []
# 创建200个病人
for i in range(200):
# 随机选择一个疾病
disease = np.random.choice(diseases)
# 获取该疾病的典型症状
typical_symptoms = disease_to_symptoms[disease]
# 随机选择2-4个典型症状
num_symptoms = np.random.randint(2, min(5, len(typical_symptoms) + 1))
patient_symptoms = list(np.random.choice(typical_symptoms, num_symptoms, replace=False))
# 10%的概率添加一个随机症状(模拟误报)
if np.random.random() < 0.1:
other_symptoms = [s for s in symptoms if s not in patient_symptoms]
if other_symptoms:
patient_symptoms.append(np.random.choice(other_symptoms))
patients.append({
'id': i+1,
'disease': disease,
'symptoms': patient_symptoms,
'symptoms_text': ' '.join(patient_symptoms) # 转换为文本
})
return pd.DataFrame(patients)
# 创建数据
df = create_medical_data_simple()
print(f"创建了 {len(df)} 个病人记录")
print("\n前5个病人:")
print(df.head())
print("\n疾病分布:")
print(df['disease'].value_counts())这段代码专门用于创建医疗数据,特点如下:
-
更有逻辑的数据生成:根据疾病的典型症状关系来生成数据,更接近真实情况。
-
添加噪声:有10%的概率添加不相关症状,模拟真实世界中的误报或无关症状。
-
转换为文本格式:将症状列表转换为文本字符串,为后续文本向量化做准备。
-
显示数据统计:展示疾病分布,帮助学生了解数据的平衡性。
这段代码教会学生数据是机器学习的第一步,好的数据是成功的一半。
4.2 数据探索部分
python
"""
第二部分:数据探索
目标:了解我们的数据
"""
import matplotlib.pyplot as plt
def explore_data_simple(df):
"""简单的数据探索"""
print("=== 数据探索 ===")
# 1. 疾病分布
disease_counts = df['disease'].value_counts()
plt.figure(figsize=(10, 4))
# 疾病分布柱状图
plt.subplot(1, 2, 1)
bars = plt.bar(disease_counts.index, disease_counts.values, color=['lightblue', 'lightgreen', 'lightcoral', 'lightsalmon'])
plt.title('疾病分布')
plt.ylabel('病人数量')
# 添加数量标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height,
f'{int(height)}', ha='center', va='bottom')
# 2. 症状统计
# 统计每个症状出现的次数
all_symptoms = []
for symptoms in df['symptoms']:
all_symptoms.extend(symptoms)
from collections import Counter
symptom_counts = Counter(all_symptoms)
# 取前5个最常见症状
common_symptoms = symptom_counts.most_common(5)
symptom_names = [s[0] for s in common_symptoms]
symptom_values = [s[1] for s in common_symptoms]
plt.subplot(1, 2, 2)
bars2 = plt.barh(symptom_names, symptom_values, color='lightseagreen')
plt.title('最常见症状')
plt.xlabel('出现次数')
# 添加数量标签
for bar in bars2:
width = bar.get_width()
plt.text(width, bar.get_y() + bar.get_height()/2.,
f'{int(width)}', ha='left', va='center')
plt.tight_layout()
plt.show()
# 打印统计信息
print(f"\n总病人数: {len(df)}")
print(f"疾病种类: {len(disease_counts)}")
print(f"症状种类: {len(symptom_counts)}")
print("\n最常见的5个症状:")
for i, (symptom, count) in enumerate(common_symptoms, 1):
print(f" {i}. {symptom}: {count}次 ({count/len(df)*100:.1f}%)")
# 探索数据
explore_data_simple(df)这段代码可视化分析数据,包含:
-
疾病分布图:用柱状图显示每种疾病有多少病人。
-
症状统计图:用水平条形图显示最常见的症状。
-
数据统计:打印总病人数、疾病种类数、症状种类数等基本信息。
这段代码教会学生探索性数据分析(EDA)的重要性,在建模前要先了解数据。
4.3 模型训练部分
python
"""
第三部分:模型训练
目标:训练朴素贝叶斯模型
"""
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
def train_and_evaluate_simple(df):
"""训练和评估模型"""
print("\n=== 模型训练 ===")
# 准备特征和标签
X = df['symptoms_text'] # 特征:症状文本
y = df['disease'] # 标签:疾病
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
print(f"训练集: {len(X_train)} 个样本")
print(f"测试集: {len(X_test)} 个样本")
# 文本向量化
print("\n将文本转换为特征向量...")
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
print(f"特征数量: {X_train_vec.shape[1]}")
print(f"特征示例: {vectorizer.get_feature_names_out()}")
# 训练朴素贝叶斯模型
print("\n训练朴素贝叶斯模型...")
model = MultinomialNB()
model.fit(X_train_vec, y_train)
# 评估模型
print("\n=== 模型评估 ===")
# 训练集准确率
y_train_pred = model.predict(X_train_vec)
train_accuracy = accuracy_score(y_train, y_train_pred)
print(f"训练集准确率: {train_accuracy:.3f}")
# 测试集准确率
y_test_pred = model.predict(X_test_vec)
test_accuracy = accuracy_score(y_test, y_test_pred)
print(f"测试集准确率: {test_accuracy:.3f}")
# 详细报告
print("\n分类报告:")
print(classification_report(y_test, y_test_pred))
return model, vectorizer
# 训练模型
model, vectorizer = train_and_evaluate_simple(df)这段代码完整训练一个朴素贝叶斯模型:
-
准备特征和标签:症状文本作为特征,疾病作为标签。
-
分割数据集:按75%-25%的比例分为训练集和测试集。
-
文本向量化:使用CountVectorizer将文本转换为机器能理解的数字向量。
-
训练模型:使用MultinomialNB(多项式朴素贝叶斯)训练分类器。
-
评估模型:计算准确率和生成详细分类报告。
这段代码展示了标准的机器学习建模流程。
4.4 创建诊断系统部分
python
"""
第四部分:创建诊断系统
目标:创建一个可以使用的诊断系统
"""
class SimpleMedicalDiagnosis:
"""简单的医疗诊断系统"""
def __init__(self, model, vectorizer):
self.model = model
self.vectorizer = vectorizer
def predict(self, symptoms_text):
"""预测疾病"""
# 转换输入
symptoms_vec = self.vectorizer.transform([symptoms_text])
# 预测
predicted_disease = self.model.predict(symptoms_vec)[0]
probabilities = self.model.predict_proba(symptoms_vec)[0]
return predicted_disease, probabilities
def predict_with_details(self, symptoms_text):
"""详细预测"""
predicted_disease, probabilities = self.predict(symptoms_text)
print(f"\n{'='*40}")
print("医疗诊断结果")
print(f"{'='*40}")
print(f"输入症状: {symptoms_text}")
print(f"预测疾病: {predicted_disease}")
print("\n各种疾病的可能性:")
for i, (disease, prob) in enumerate(zip(self.model.classes_, probabilities)):
percentage = prob * 100
# 用星号表示概率大小
stars = '*' * int(percentage / 10)
print(f" {disease:10} {percentage:5.1f}% {stars}")
return predicted_disease, probabilities
# 创建诊断系统
diagnosis_system = SimpleMedicalDiagnosis(model, vectorizer)
# 测试诊断系统
print("\n=== 诊断系统测试 ===")
# 测试用例
test_cases = [
"发烧 咳嗽 头痛", # 应该是流感
"流鼻涕 喉咙痛", # 应该是感冒
"咳嗽 呼吸困难", # 应该是支气管炎
"发烧 呼吸困难 乏力", # 应该是肺炎
]
for symptoms in test_cases:
diagnosis_system.predict_with_details(symptoms)这段代码将训练好的模型封装成可用的诊断系统:
-
创建诊断类:将模型和向量化器打包到一个类中。
-
预测函数:输入症状文本,输出预测疾病。
-
详细预测函数:除了预测结果,还以直观方式显示各种疾病的概率。
-
测试用例:用几个典型症状组合测试系统是否正常工作。
这段代码教会学生如何将机器学习模型转化为实际应用。
4.5 交互式界面部分
python
"""
第五部分:交互式界面
目标:创建一个用户可以交互的系统
"""
def interactive_diagnosis_simple():
"""简单的交互式诊断"""
print("\n" + "="*50)
print("欢迎使用简单医疗诊断辅助系统")
print("="*50)
print("注意事项:")
print("1. 本系统仅为教学演示,不能用于实际医疗诊断")
print("2. 输入症状时,请用空格分隔")
print("3. 示例: 发烧 咳嗽 头痛")
print("4. 输入 '退出' 或 'exit' 结束程序")
print("="*50)
while True:
print("\n" + "-"*30)
symptoms = input("请输入症状描述: ").strip()
if symptoms.lower() in ['退出', 'exit', 'quit']:
print("感谢使用!")
break
if not symptoms:
print("请输入症状!")
continue
# 简单的输入检查
if len(symptoms.split()) < 1:
print("请至少输入一个症状")
continue
try:
# 进行诊断
diagnosis_system.predict_with_details(symptoms)
print("\n建议:")
print("1. 多喝水,注意休息")
print("2. 如果症状持续或加重,请及时就医")
print("3. 请勿自行用药,咨询专业医生")
except Exception as e:
print(f"诊断出错: {e}")
print("请尝试其他症状描述")
# 启动交互式诊断
interactive_diagnosis_simple()这段代码创建用户友好的命令行界面:
-
欢迎界面:显示系统名称和使用说明。
-
循环交互:用户可以多次输入症状进行诊断。
-
输入验证:检查输入是否为空或太短。
-
错误处理:捕获可能的异常,给出友好提示。
-
给出建议:提供基本的医疗建议。
这段代码教会学生如何设计用户界面,即使是在命令行中。
第五部分:项目扩展
5.1 添加更多功能
python
"""
扩展功能1:添加疾病描述和建议
"""
# 疾病信息数据库
disease_info = {
'流感': {
'description': '由流感病毒引起的呼吸道传染病',
'common_symptoms': ['发烧', '咳嗽', '头痛', '乏力'],
'suggestion': '多休息、多喝水,必要时使用抗病毒药物'
},
'普通感冒': {
'description': '由多种病毒引起的轻微呼吸道感染',
'common_symptoms': ['流鼻涕', '咳嗽', '喉咙痛'],
'suggestion': '多休息、多喝水,症状严重时可使用感冒药'
},
'肺炎': {
'description': '肺部组织的感染性炎症',
'common_symptoms': ['发烧', '咳嗽', '呼吸困难', '乏力'],
'suggestion': '及时就医,可能需要抗生素治疗'
},
'支气管炎': {
'description': '支气管的炎症',
'common_symptoms': ['咳嗽', '呼吸困难'],
'suggestion': '多休息,避免刺激性气体,必要时使用支气管扩张剂'
}
}
def enhanced_diagnosis(symptoms_text):
"""增强的诊断功能"""
predicted_disease, probabilities = diagnosis_system.predict(symptoms_text)
info = disease_info.get(predicted_disease, {})
print(f"\n{'='*50}")
print("增强诊断报告")
print(f"{'='*50}")
print(f"症状描述: {symptoms_text}")
print(f"预测疾病: {predicted_disease}")
print(f"\n疾病描述: {info.get('description', '暂无描述')}")
print(f"常见症状: {', '.join(info.get('common_symptoms', []))}")
print(f"建议: {info.get('suggestion', '请咨询医生')}")
print(f"\n其他可能性:")
# 显示前3个可能的疾病
for i, (disease, prob) in enumerate(sorted(zip(model.classes_, probabilities),
key=lambda x: x[1], reverse=True)[:3], 1):
print(f" {i}. {disease}: {prob*100:.1f}%")
return predicted_disease
# 测试增强诊断
enhanced_diagnosis("发烧 咳嗽 头痛")这段代码增强诊断系统的功能:
-
疾病知识库:为每种疾病添加描述、常见症状和建议。
-
增强诊断报告:预测时不仅显示概率,还显示疾病描述和建议。
-
排序显示:按概率从高到低显示前3个可能的疾病。
这段代码展示了如何让机器学习系统更具实用价值,提供更丰富的信息
第六部分:总结
这个教程从最简单的朴素贝叶斯实现开始,逐步增加复杂度,最终完成一个完整的医疗诊断辅助系统。即使Python基础薄弱,只要按照步骤学习,也能理解和实现这个项目。
记住:真正的医疗诊断需要专业医生,这个系统仅供学习和教学使用。
这个项目代码从简单到复杂,从原理到实践:
-
理解原理:通过手动实现理解朴素贝叶斯算法
-
使用工具:学习使用scikit-learn等机器学习库
-
完整流程:掌握从数据创建到模型部署的全过程
-
实际应用:将算法转化为可用的医疗诊断系统
第七部分:项目源代码
下面这段代码实现了一个完整的医疗诊断辅助系统,基于朴素贝叶斯算法构建了一个能够根据症状描述预测多种可能疾病的教学演示系统。整个项目从数据创建、预处理、模型构建到交互式应用的完整流程,具有以下特点:
-
模拟真实医疗场景
我们构建了一个包含 300 个模拟患者、20 种疾病和 30 种症状的数据集,模拟了真实医疗中的复杂情况,比如患者可能同时患多种病、症状交叉出现,或描述模糊不清。
-
支持多疾病诊断的算法
采用多标签朴素贝叶斯分类,能处理一个患者同时患有多种疾病的情况------这是实际诊断中很常见的场景。
-
完整的工业级 ML 流程
从特征工程(TF-IDF 向量化)到模型校准、性能评估,覆盖机器学习在实际应用中的关键环节,流程清晰、可复现。
-
结果可解释,不只"黑箱"预测
除了输出预测疾病,还计算每个症状对结果的贡献度,让诊断过程更透明、可解释。
-
提供交互式诊断体验
包含可视化界面、交互式诊断和详细报告,方便用户输入症状、查看预测结果与解释。
-
强调伦理与责任
明确说明系统仅用于教学和演示,并提醒实际医疗诊断的复杂性。
python
"""
医疗诊断辅助系统 - 基于朴素贝叶斯算法
作者:free-elcmacom
环境:PyCharm + Python 3.10
注意:本系统仅用于教学演示,不能用于实际医疗诊断
"""
# ============ 第一步:导入库 ============
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
import re
import warnings
import jieba
from collections import defaultdict
import heapq
from datetime import datetime
# 机器学习库
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.metrics import classification_report, accuracy_score, f1_score
from sklearn.calibration import CalibratedClassifierCV
# 可视化设置
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings('ignore')
print(" 医疗诊断辅助系统初始化完成!")
# ============ 第二步:创建模拟医疗数据集 ============
def create_medical_dataset():
"""创建模拟的医疗数据集,包含症状和疾病"""
# 定义疾病列表(常见的20种疾病)
diseases = [
'流感', '普通感冒', '肺炎', '支气管炎', '哮喘',
'高血压', '糖尿病', '冠心病', '胃炎', '胃溃疡',
'关节炎', '骨质疏松', '偏头痛', '抑郁症', '焦虑症',
'皮肤病', '过敏', '结膜炎', '中耳炎', '鼻炎'
]
# 定义症状列表
symptoms = [
'发烧', '咳嗽', '头痛', '乏力', '肌肉酸痛',
'喉咙痛', '流鼻涕', '打喷嚏', '呼吸困难', '胸闷',
'心悸', '头晕', '恶心', '呕吐', '腹泻',
'腹痛', '关节痛', '皮疹', '瘙痒', '视力模糊',
'口干', '多饮', '多尿', '体重下降', '失眠',
'焦虑', '抑郁', '食欲不振', '消化不良', '胃痛'
]
# 创建症状-疾病关系矩阵(专业知识模拟)
# 每个疾病有3-6个主要症状
disease_symptom_mapping = {
'流感': ['发烧', '咳嗽', '头痛', '乏力', '肌肉酸痛'],
'普通感冒': ['流鼻涕', '打喷嚏', '喉咙痛', '咳嗽'],
'肺炎': ['发烧', '咳嗽', '呼吸困难', '胸痛'],
'支气管炎': ['咳嗽', '胸闷', '呼吸困难'],
'哮喘': ['呼吸困难', '胸闷', '咳嗽'],
'高血压': ['头痛', '头晕', '心悸'],
'糖尿病': ['口干', '多饮', '多尿', '体重下降'],
'冠心病': ['胸痛', '胸闷', '心悸', '呼吸困难'],
'胃炎': ['胃痛', '恶心', '消化不良'],
'胃溃疡': ['胃痛', '恶心', '呕吐', '食欲不振'],
'关节炎': ['关节痛', '关节肿胀', '活动受限'],
'骨质疏松': ['骨痛', '身高变矮', '易骨折'],
'偏头痛': ['头痛', '恶心', '畏光'],
'抑郁症': ['抑郁', '失眠', '食欲不振', '乏力'],
'焦虑症': ['焦虑', '心悸', '失眠', '紧张'],
'皮肤病': ['皮疹', '瘙痒', '皮肤发红'],
'过敏': ['打喷嚏', '流鼻涕', '皮疹', '瘙痒'],
'结膜炎': ['眼睛红', '眼睛痒', '流泪'],
'中耳炎': ['耳痛', '听力下降', '发烧'],
'鼻炎': ['流鼻涕', '打喷嚏', '鼻塞']
}
# 创建模拟患者数据
patients = []
for i in range(300): # 300个模拟患者
# 随机选择1-3种疾病
num_diseases = np.random.choice([1, 2, 3], p=[0.6, 0.3, 0.1])
patient_diseases = np.random.choice(diseases, num_diseases, replace=False).tolist()
# 根据疾病生成症状
patient_symptoms = []
for disease in patient_diseases:
# 每个疾病随机选择2-4个主要症状
disease_symptoms = disease_symptom_mapping[disease]
num_symptoms = np.random.randint(2, min(5, len(disease_symptoms) + 1))
selected_symptoms = np.random.choice(disease_symptoms, num_symptoms, replace=False)
patient_symptoms.extend(selected_symptoms)
# 去重并添加一些随机症状(模拟误报或无关症状)
patient_symptoms = list(set(patient_symptoms))
if np.random.random() < 0.3: # 30%的概率添加无关症状
extra_symptoms = [s for s in symptoms if s not in patient_symptoms]
if extra_symptoms:
patient_symptoms.append(np.random.choice(extra_symptoms))
# 添加患者基本信息
age = np.random.randint(1, 100)
gender = np.random.choice(['男', '女'])
# 生成症状描述文本(模拟真实患者描述)
symptom_text = ",".join(patient_symptoms)
# 添加一些模糊描述
vague_descriptions = [
"最近感觉不太舒服",
"症状时好时坏",
"不太确定具体是什么问题",
"症状已经持续了一段时间"
]
if np.random.random() < 0.4: # 40%的概率添加模糊描述
symptom_text += "," + np.random.choice(vague_descriptions)
# 创建患者记录
patients.append({
'patient_id': f'P{1000 + i}',
'age': age,
'gender': gender,
'symptoms': symptom_text,
'diseases': patient_diseases,
'symptom_list': patient_symptoms,
'num_diseases': len(patient_diseases)
})
return pd.DataFrame(patients), diseases, symptoms, disease_symptom_mapping
# 创建数据集
print("\n 正在创建模拟医疗数据集...")
df, diseases, symptoms, disease_symptom_mapping = create_medical_dataset()
print(f" 数据集创建成功!共 {len(df)} 条患者记录")
print(f" 包含疾病: {len(diseases)} 种")
print(f" 包含症状: {len(symptoms)} 种")
# 显示数据基本信息
print("\n 数据集预览:")
print(df.head())
print(f"\n 数据统计:")
print(f" 平均每个患者疾病数: {df['num_diseases'].mean():.2f}")
print(f" 疾病分布:")
for disease in diseases[:5]: # 显示前5种疾病的统计
count = df['diseases'].apply(lambda x: disease in x).sum()
print(f" {disease}: {count} 例 ({count / len(df) * 100:.1f}%)")
# ============ 第三步:数据探索和可视化 ============
def explore_medical_data(df, diseases, symptoms):
"""探索医疗数据集"""
print("\n" + "=" * 60)
print(" 医疗数据探索分析")
print("=" * 60)
# 1. 患者年龄分布
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 年龄分布
axes[0, 0].hist(df['age'], bins=20, color='skyblue', edgecolor='black', alpha=0.7)
axes[0, 0].set_xlabel('年龄')
axes[0, 0].set_ylabel('患者数量')
axes[0, 0].set_title('患者年龄分布')
axes[0, 0].axvline(df['age'].mean(), color='red', linestyle='--',
label=f'平均年龄: {df["age"].mean():.1f}')
axes[0, 0].legend()
# 性别分布
gender_counts = df['gender'].value_counts()
axes[0, 1].pie(gender_counts.values, labels=gender_counts.index,
autopct='%1.1f%%', colors=['lightblue', 'lightpink'])
axes[0, 1].set_title('患者性别分布')
# 疾病数量分布
disease_counts = df['num_diseases'].value_counts().sort_index()
axes[0, 2].bar(disease_counts.index, disease_counts.values, color='lightgreen')
axes[0, 2].set_xlabel('疾病数量')
axes[0, 2].set_ylabel('患者数量')
axes[0, 2].set_title('患者疾病数量分布')
for i, v in enumerate(disease_counts.values):
axes[0, 2].text(disease_counts.index[i], v + 1, str(v), ha='center')
# 2. 症状词云
all_symptoms_text = ' '.join(df['symptoms'])
wordcloud = WordCloud(width=400, height=300,
background_color='white',
max_words=50,
font_path='simhei.ttf').generate(all_symptoms_text)
axes[1, 0].imshow(wordcloud, interpolation='bilinear')
axes[1, 0].set_title('症状词云')
axes[1, 0].axis('off')
# 3. 常见症状分析(前10)
# 统计所有症状出现的频率
symptom_counter = defaultdict(int)
for symptom_list in df['symptom_list']:
for symptom in symptom_list:
symptom_counter[symptom] += 1
top_symptoms = sorted(symptom_counter.items(), key=lambda x: x[1], reverse=True)[:10]
top_symptom_names = [s[0] for s in top_symptoms]
top_symptom_counts = [s[1] for s in top_symptoms]
axes[1, 1].barh(range(len(top_symptoms)), top_symptom_counts, color='salmon')
axes[1, 1].set_yticks(range(len(top_symptoms)))
axes[1, 1].set_yticklabels(top_symptom_names)
axes[1, 1].set_xlabel('出现次数')
axes[1, 1].set_title('最常见的10种症状')
axes[1, 1].invert_yaxis()
# 4. 常见疾病分析(前10)
disease_counter = defaultdict(int)
for disease_list in df['diseases']:
for disease in disease_list:
disease_counter[disease] += 1
top_diseases = sorted(disease_counter.items(), key=lambda x: x[1], reverse=True)[:10]
top_disease_names = [d[0] for d in top_diseases]
top_disease_counts = [d[1] for d in top_diseases]
axes[1, 2].barh(range(len(top_diseases)), top_disease_counts, color='lightseagreen')
axes[1, 2].set_yticks(range(len(top_diseases)))
axes[1, 2].set_yticklabels(top_disease_names)
axes[1, 2].set_xlabel('出现次数')
axes[1, 2].set_title('最常见的10种疾病')
axes[1, 2].invert_yaxis()
plt.suptitle('医疗数据集探索分析', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
# 打印统计信息
print(f"\n 数据统计信息:")
print(f" 患者年龄范围: {df['age'].min()} - {df['age'].max()} 岁")
print(f" 平均年龄: {df['age'].mean():.1f} 岁")
print(f" 性别比例: 男 {gender_counts.get('男', 0)} 人, 女 {gender_counts.get('女', 0)} 人")
print(f" 单疾病患者: {disease_counts.get(1, 0)} 人 ({disease_counts.get(1, 0) / len(df) * 100:.1f}%)")
print(
f" 多疾病患者: {disease_counts.get(2, 0) + disease_counts.get(3, 0)} 人 ({(disease_counts.get(2, 0) + disease_counts.get(3, 0)) / len(df) * 100:.1f}%)")
print(f"\n 最常见的5种症状:")
for i, (symptom, count) in enumerate(top_symptoms[:5], 1):
print(f" {i}. {symptom}: {count} 次 ({count / len(df) * 100:.1f}%)")
print(f"\n 最常见的5种疾病:")
for i, (disease, count) in enumerate(top_diseases[:5], 1):
print(f" {i}. {disease}: {count} 例 ({count / len(df) * 100:.1f}%)")
return symptom_counter, disease_counter
# 执行数据探索
symptom_counter, disease_counter = explore_medical_data(df, diseases, symptoms)
# ============ 第四步:医学术语标准化和预处理 ============
print("\n" + "=" * 60)
print(" 医学术语标准化和预处理")
print("=" * 60)
# 医学术语同义词映射表(简化版)
medical_synonyms = {
'发热': '发烧',
'高烧': '发烧',
'低烧': '发烧',
'咳嗽': '咳嗽',
'干咳': '咳嗽',
'咳痰': '咳嗽',
'头疼': '头痛',
'头昏': '头晕',
'眩晕': '头晕',
'疲乏': '乏力',
'疲劳': '乏力',
'没力气': '乏力',
'嗓子痛': '喉咙痛',
'咽喉痛': '喉咙痛',
'流涕': '流鼻涕',
'鼻塞': '流鼻涕',
'打喷嚏': '打喷嚏',
'喘不过气': '呼吸困难',
'气喘': '呼吸困难',
'胸口闷': '胸闷',
'心慌': '心悸',
'心跳快': '心悸',
'恶心': '恶心',
'想吐': '恶心',
'呕吐': '呕吐',
'拉肚子': '腹泻',
'肚子痛': '腹痛',
'胃疼': '胃痛',
'关节疼': '关节痛',
'皮疹': '皮疹',
'红疹': '皮疹',
'痒': '瘙痒',
'眼睛模糊': '视力模糊',
'口干舌燥': '口干',
'喝水多': '多饮',
'尿多': '多尿',
'瘦了': '体重下降',
'睡不着': '失眠',
'紧张': '焦虑',
'心情不好': '抑郁',
'没胃口': '食欲不振',
'消化不好': '消化不良'
}
# 医学术语停用词
medical_stopwords = [
'感觉', '有点', '非常', '特别', '严重', '轻微',
'最近', '今天', '昨天', '前几天', '一段时间',
'可能', '好像', '似乎', '大概', '也许',
'的', '了', '在', '是', '我', '有', '和', '就',
'不', '人', '都', '一', '一个', '上', '也', '很'
]
def standardize_medical_text(text):
"""标准化医学术语"""
# 1. 转换为小写
text = text.lower()
# 2. 替换同义词
for synonym, standard in medical_synonyms.items():
text = text.replace(synonym, standard)
# 3. 使用jieba分词
words = jieba.lcut(text)
# 4. 去除停用词和短词
words = [word for word in words if word not in medical_stopwords and len(word) > 1]
# 5. 只保留医学术语(简单过滤)
# 这里我们可以保留所有词,因为症状描述中可能包含非标准术语
# 在实际应用中,这里应该使用医学词典进行过滤
return ' '.join(words)
def extract_structured_symptoms(text):
"""从文本中提取结构化症状"""
# 使用简单的规则匹配症状
extracted_symptoms = []
for symptom in symptoms:
if symptom in text:
extracted_symptoms.append(symptom)
# 如果没有匹配到任何症状,返回原始文本的关键词
if not extracted_symptoms:
words = jieba.lcut(text)
extracted_symptoms = [word for word in words if word not in medical_stopwords and len(word) > 1]
return extracted_symptoms
# 应用预处理
print("正在进行医学术语标准化...")
df['standardized_symptoms'] = df['symptoms'].apply(standardize_medical_text)
df['extracted_symptoms'] = df['symptoms'].apply(extract_structured_symptoms)
# 显示预处理前后的对比
print("\n 医学术语标准化完成!")
print("\n 预处理前后对比示例:")
print("=" * 60)
print("原始症状描述:")
print(f" 患者ID: {df['patient_id'].iloc[0]}")
print(f" 症状: {df['symptoms'].iloc[0]}")
print(f" 疾病: {df['diseases'].iloc[0]}")
print("\n标准化后:")
print(f" 标准化症状: {df['standardized_symptoms'].iloc[0]}")
print(f" 提取的症状: {df['extracted_symptoms'].iloc[0]}")
print("=" * 60)
# ============ 第五步:多标签分类准备 ============
print("\n" + "=" * 60)
print(" 多标签分类数据准备")
print("=" * 60)
# 使用MultiLabelBinarizer将疾病标签转换为二进制矩阵
mlb = MultiLabelBinarizer(classes=diseases)
y = mlb.fit_transform(df['diseases'])
print(f"标签矩阵形状: {y.shape}")
print(f"疾病类别数: {len(diseases)}")
print(f"样本数: {len(df)}")
# 特征提取:使用TF-IDF
print("\n正在进行特征提取...")
vectorizer = TfidfVectorizer(
max_features=100,
tokenizer=lambda x: x.split(),
ngram_range=(1, 2) # 包含1-2个词的组合
)
# 使用标准化后的症状文本作为特征
X = vectorizer.fit_transform(df['standardized_symptoms'])
feature_names = vectorizer.get_feature_names_out()
print(f"特征矩阵形状: {X.shape}")
print(f"特征数量: {len(feature_names)}")
print(f"\n 前10个特征:")
for i, feature in enumerate(feature_names[:10]):
print(f" {i + 1}. {feature}")
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=None # 多标签无法使用stratify
)
print(f"\n 数据集划分:")
print(f" 训练集: {X_train.shape[0]} 样本")
print(f" 测试集: {X_test.shape[0]} 样本")
print(f" 特征数: {X_train.shape[1]}")
# ============ 第六步:构建多标签朴素贝叶斯模型 ============
print("\n" + "=" * 60)
print(" 构建多标签朴素贝叶斯模型")
print("=" * 60)
def train_multilabel_model(X_train, y_train, diseases):
"""训练多标签朴素贝叶斯模型"""
print("正在训练多标签分类器...")
# 使用OneVsRestClassifier包装朴素贝叶斯
# 这样可以实现多标签分类
base_classifier = MultinomialNB(alpha=0.1) # 使用较小的alpha,避免过度平滑
# 使用校准分类器来获得更好的概率估计
calibrated_classifier = CalibratedClassifierCV(base_classifier, cv=3, method='sigmoid')
# 创建多标签分类器
multilabel_classifier = OneVsRestClassifier(calibrated_classifier, n_jobs=-1)
# 训练模型
multilabel_classifier.fit(X_train, y_train)
print(" 模型训练完成!")
return multilabel_classifier
# 训练模型
model = train_multilabel_model(X_train, y_train, diseases)
# ============ 第七步:模型评估 ============
print("\n" + "=" * 60)
print(" 模型评估")
print("=" * 60)
def evaluate_multilabel_model(model, X_test, y_test, diseases):
"""评估多标签分类模型"""
print("正在进行模型评估...")
# 预测
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)
# 计算准确率(严格匹配)
exact_match_accuracy = np.all(y_pred == y_test, axis=1).mean()
# 计算汉明损失(Hamming loss)
hamming_loss = np.mean(y_pred != y_test)
# 计算每个标签的F1分数
label_f1_scores = []
for i, disease in enumerate(diseases):
f1 = f1_score(y_test[:, i], y_pred[:, i], zero_division=0)
label_f1_scores.append((disease, f1))
# 按F1分数排序
label_f1_scores.sort(key=lambda x: x[1], reverse=True)
print(f"\n 模型性能指标:")
print(f" 严格匹配准确率: {exact_match_accuracy:.4f}")
print(f" 汉明损失: {hamming_loss:.4f}")
print(f" 平均F1分数: {np.mean([score for _, score in label_f1_scores]):.4f}")
# 绘制每个标签的F1分数
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 前10个疾病F1分数
top_diseases = [d for d, _ in label_f1_scores[:10]]
top_scores = [s for _, s in label_f1_scores[:10]]
axes[0].barh(range(len(top_diseases)), top_scores, color='lightblue')
axes[0].set_yticks(range(len(top_diseases)))
axes[0].set_yticklabels(top_diseases)
axes[0].set_xlabel('F1分数')
axes[0].set_title('F1分数最高的10种疾病预测')
axes[0].invert_yaxis()
axes[0].set_xlim([0, 1])
# 后10个疾病F1分数
bottom_diseases = [d for d, _ in label_f1_scores[-10:]]
bottom_scores = [s for _, s in label_f1_scores[-10:]]
axes[1].barh(range(len(bottom_diseases)), bottom_scores, color='lightcoral')
axes[1].set_yticks(range(len(bottom_diseases)))
axes[1].set_yticklabels(bottom_diseases)
axes[1].set_xlabel('F1分数')
axes[1].set_title('F1分数最低的10种疾病预测')
axes[1].invert_yaxis()
axes[1].set_xlim([0, 1])
plt.suptitle('多标签分类模型性能评估', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
print(f"\n F1分数最高的5种疾病:")
for i, (disease, score) in enumerate(label_f1_scores[:5], 1):
print(f" {i}. {disease}: {score:.4f}")
print(f"\n F1分数最低的5种疾病:")
for i, (disease, score) in enumerate(label_f1_scores[-5:], 1):
print(f" {i}. {disease}: {score:.4f}")
return y_pred, y_pred_proba, exact_match_accuracy, hamming_loss
# 评估模型
y_pred, y_pred_proba, exact_match_accuracy, hamming_loss = evaluate_multilabel_model(
model, X_test, y_test, diseases
)
# ============ 第八步:置信度阈值和Top-K预测 ============
print("\n" + "=" * 60)
print(" 置信度阈值和Top-K预测系统")
print("=" * 60)
class MedicalDiagnosisSystem:
"""医疗诊断辅助系统"""
def __init__(self, model, vectorizer, mlb, diseases, disease_symptom_mapping):
self.model = model
self.vectorizer = vectorizer
self.mlb = mlb
self.diseases = diseases
self.disease_symptom_mapping = disease_symptom_mapping
def predict_with_confidence(self, symptom_text, top_k=3, confidence_threshold=0.3):
"""基于症状预测疾病,返回Top-K结果和置信度"""
# 1. 预处理症状文本
standardized_text = standardize_medical_text(symptom_text)
extracted_symptoms = extract_structured_symptoms(symptom_text)
# 2. 特征提取
X_input = self.vectorizer.transform([standardized_text])
# 3. 预测概率
probabilities = self.model.predict_proba(X_input)[0]
# 4. 获取疾病-概率对
disease_probs = list(zip(self.diseases, probabilities))
# 5. 按概率排序
disease_probs.sort(key=lambda x: x[1], reverse=True)
# 6. 应用置信度阈值
filtered_diseases = [(disease, prob) for disease, prob in disease_probs if prob >= confidence_threshold]
# 7. 获取Top-K结果
top_k_results = filtered_diseases[:top_k] if len(filtered_diseases) >= top_k else filtered_diseases
# 8. 如果没有疾病超过阈值,返回Top-K(不考虑阈值)
if not top_k_results:
top_k_results = disease_probs[:top_k]
# 9. 计算症状对每种疾病的贡献度
symptom_contributions = {}
for disease, prob in top_k_results:
contributions = self.calculate_symptom_contributions(
standardized_text, disease, extracted_symptoms
)
symptom_contributions[disease] = contributions
return {
'symptoms': symptom_text,
'extracted_symptoms': extracted_symptoms,
'top_predictions': top_k_results,
'symptom_contributions': symptom_contributions,
'all_probabilities': disease_probs
}
def calculate_symptom_contributions(self, symptom_text, disease, extracted_symptoms):
"""计算症状对疾病预测的贡献度"""
contributions = []
# 获取该疾病的典型症状
typical_symptoms = self.disease_symptom_mapping.get(disease, [])
# 检查每个提取的症状
for symptom in extracted_symptoms:
# 如果这个症状是该疾病的典型症状,给予更高的权重
is_typical = symptom in typical_symptoms
# 简单的贡献度计算(在实际系统中应该基于特征权重)
# 这里使用一个简化的方法
if is_typical:
weight = 0.7 # 典型症状权重较高
else:
weight = 0.3 # 非典型症状权重较低
contributions.append({
'symptom': symptom,
'weight': weight,
'is_typical': is_typical,
'description': self.get_symptom_description(symptom, disease)
})
# 按权重排序
contributions.sort(key=lambda x: x['weight'], reverse=True)
return contributions
def get_symptom_description(self, symptom, disease):
"""获取症状描述"""
descriptions = {
('发烧', '流感'): "流感常伴随高烧,这是病毒感染的主要症状之一",
('咳嗽', '流感'): "咳嗽是流感的常见症状,可能伴有痰",
('头痛', '流感'): "流感引起的头痛通常是全身症状的一部分",
('发烧', '肺炎'): "肺炎常伴有发烧,可能是细菌或病毒感染",
('咳嗽', '肺炎'): "肺炎的咳嗽可能伴有胸痛和呼吸困难",
('呼吸困难', '肺炎'): "肺炎会影响肺部功能,导致呼吸困难",
('口干', '糖尿病'): "糖尿病导致的高血糖会引起口干症状",
('多饮', '糖尿病'): "糖尿病患者常感到口渴,饮水增多",
('多尿', '糖尿病'): "高血糖导致尿量增加",
('头痛', '高血压'): "高血压常引起头痛,尤其是在早晨",
('头晕', '高血压'): "高血压可能导致头晕,特别是突然站起时",
('心悸', '高血压'): "高血压可能引起心悸或心跳不规则",
}
return descriptions.get((symptom, disease), f"'{symptom}'是'{disease}'的可能症状")
def visualize_predictions(self, prediction_result):
"""可视化预测结果"""
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 1. Top-K预测的概率图
top_predictions = prediction_result['top_predictions']
diseases_top = [d for d, _ in top_predictions]
probs_top = [p for _, p in top_predictions]
colors = ['lightgreen' if p >= 0.5 else 'lightcoral' for p in probs_top]
bars = axes[0].barh(range(len(diseases_top)), probs_top, color=colors)
axes[0].set_yticks(range(len(diseases_top)))
axes[0].set_yticklabels(diseases_top)
axes[0].set_xlabel('预测概率')
axes[0].set_title(f'Top-{len(diseases_top)} 疾病预测')
axes[0].invert_yaxis()
axes[0].set_xlim([0, 1])
# 添加概率值标签
for i, bar in enumerate(bars):
width = bar.get_width()
axes[0].text(width + 0.01, bar.get_y() + bar.get_height() / 2,
f'{width:.3f}', ha='left', va='center')
# 添加置信度阈值线
axes[0].axvline(x=0.5, color='red', linestyle='--', alpha=0.5, label='高置信度阈值(0.5)')
axes[0].legend()
# 2. 症状贡献图(针对Top-1疾病)
if prediction_result['top_predictions']:
top_disease = prediction_result['top_predictions'][0][0]
contributions = prediction_result['symptom_contributions'].get(top_disease, [])
if contributions:
symptom_names = [c['symptom'] for c in contributions[:5]] # 只显示前5个
symptom_weights = [c['weight'] for c in contributions[:5]]
symptom_types = ['典型症状' if c['is_typical'] else '一般症状' for c in contributions[:5]]
# 根据症状类型设置颜色
colors = ['lightblue' if t == '典型症状' else 'lightgray' for t in symptom_types]
bars2 = axes[1].barh(range(len(symptom_names)), symptom_weights, color=colors)
axes[1].set_yticks(range(len(symptom_names)))
axes[1].set_yticklabels(symptom_names)
axes[1].set_xlabel('症状权重')
axes[1].set_title(f'症状对"{top_disease}"的贡献度')
axes[1].invert_yaxis()
axes[1].set_xlim([0, 1])
# 添加类型标签
for i, (bar, stype) in enumerate(zip(bars2, symptom_types)):
width = bar.get_width()
axes[1].text(width + 0.01, bar.get_y() + bar.get_height() / 2,
stype, ha='left', va='center', fontsize=9)
plt.suptitle('医疗诊断辅助系统预测结果', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
def generate_diagnosis_report(self, prediction_result, patient_info=None):
"""生成诊断报告"""
report = []
report.append("=" * 60)
report.append("医疗诊断辅助系统 - 诊断报告")
report.append("=" * 60)
if patient_info:
report.append(f"患者信息: {patient_info}")
report.append(f"\n主诉症状: {prediction_result['symptoms']}")
report.append(f"提取的症状: {', '.join(prediction_result['extracted_symptoms'])}")
report.append("\n" + "-" * 60)
report.append("疾病预测结果:")
report.append("-" * 60)
for i, (disease, probability) in enumerate(prediction_result['top_predictions'], 1):
confidence_level = "高" if probability >= 0.5 else "中" if probability >= 0.3 else "低"
report.append(f"{i}. {disease}")
report.append(f" 预测概率: {probability:.3f} ({confidence_level}置信度)")
# 添加症状贡献说明
contributions = prediction_result['symptom_contributions'].get(disease, [])
if contributions:
report.append(f" 主要依据:")
for j, contrib in enumerate(contributions[:3], 1): # 只显示前3个主要依据
typical = "(典型症状)" if contrib['is_typical'] else ""
report.append(f" {j}. {contrib['symptom']} {typical}")
report.append("\n" + "-" * 60)
report.append("重要提醒:")
report.append("-" * 60)
report.append("1. 本系统仅为辅助诊断工具,不能替代专业医生诊断")
report.append("2. 低置信度结果需结合临床检查进一步确认")
report.append("3. 如症状持续或加重,请立即就医")
report.append("=" * 60)
return "\n".join(report)
# 创建诊断系统
print("正在初始化医疗诊断辅助系统...")
diagnosis_system = MedicalDiagnosisSystem(
model=model,
vectorizer=vectorizer,
mlb=mlb,
diseases=diseases,
disease_symptom_mapping=disease_symptom_mapping
)
print(" 医疗诊断辅助系统初始化完成!")
# ============ 第九步:交互式诊断演示 ============
print("\n" + "=" * 60)
print(" 交互式医疗诊断演示")
print("=" * 60)
def interactive_diagnosis():
"""交互式诊断演示"""
print("\n 请输入患者症状描述(中文)")
print(" 示例: '发烧咳嗽三天,伴有头痛和乏力'")
print(" 输入 '退出', 'exit' 或 'quit' 结束程序")
print("-" * 60)
while True:
print("\n" + "-" * 60)
# 获取患者基本信息
try:
age = input("请输入患者年龄(直接回车跳过): ").strip()
age = int(age) if age else None
except:
age = None
gender = input("请输入患者性别(男/女,直接回车跳过): ").strip()
gender = gender if gender in ['男', '女'] else None
print("-" * 60)
symptom_text = input("请输入症状描述: ").strip()
if symptom_text.lower() in ['退出', 'exit', 'quit']:
print("感谢使用医疗诊断辅助系统!")
break
if not symptom_text:
print(" 症状描述不能为空!")
continue
if len(symptom_text) < 5:
print(" 症状描述太短,请提供更详细的信息")
continue
# 设置诊断参数
try:
top_k = input("请输入要显示的疾病数量(默认3): ").strip()
top_k = int(top_k) if top_k else 3
threshold = input("请输入置信度阈值(0.0-1.0,默认0.3): ").strip()
threshold = float(threshold) if threshold else 0.3
except:
print(" 输入参数无效,使用默认值")
top_k = 3
threshold = 0.3
print("\n正在分析症状,请稍候...")
# 准备患者信息
patient_info = []
if age:
patient_info.append(f"年龄: {age}岁")
if gender:
patient_info.append(f"性别: {gender}")
patient_info_str = ", ".join(patient_info) if patient_info else "未提供"
# 进行诊断
try:
result = diagnosis_system.predict_with_confidence(
symptom_text, top_k=top_k, confidence_threshold=threshold
)
# 显示诊断报告
report = diagnosis_system.generate_diagnosis_report(result, patient_info_str)
print("\n")
print(report)
# 可视化结果
print("\n正在生成可视化图表...")
diagnosis_system.visualize_predictions(result)
except Exception as e:
print(f" 诊断过程中出现错误: {e}")
print("请尝试重新输入症状描述")
print("-" * 60)
print(" 诊断完成!")
print(" 1. 输入新症状继续诊断")
print(" 2. 输入'退出'结束程序")
# 运行交互式诊断
interactive_diagnosis()
# ============ 第十步:系统评估和伦理说明 ============
print("\n" + "=" * 60)
print(" 系统评估和伦理说明")
print("=" * 60)
print("\n 系统性能总结:")
print(f" 严格匹配准确率: {exact_match_accuracy:.4f}")
print(f" 汉明损失: {hamming_loss:.4f}")
print(f" 疾病种类: {len(diseases)} 种")
print(f" 症状特征: {len(feature_names)} 个")
print("\n 伦理和安全考虑:")
print("1. 本系统仅为教学演示工具,不能用于实际医疗诊断")
print("2. 所有诊断结果必须由专业医生核实")
print("3. 系统包含置信度阈值,低置信度结果会明确标出")
print("4. 系统提供决策依据,增强可解释性")
print("5. 模拟数据不代表真实医疗情况")
print("\n 临床使用限制:")
print("✓ 仅作为辅助参考工具")
print("✓ 不能替代医生的专业判断")
print("✓ 不能用于紧急情况")
print("✓ 不能用于自我诊断")
print("\n 改进方向:")
print("1. 使用真实医疗数据训练")
print("2. 加入更多症状和疾病关系")
print("3. 考虑患者年龄、性别等特征")
print("4. 加入时间序列分析(症状发展过程)")
print("5. 集成实验室检查结果")
print("\n" + "=" * 60)
print(" 医疗诊断辅助系统项目完成!")
print("=" * 60)
# 保存模型和配置(可选)
print("\n 正在保存系统配置...")
import pickle
import os
# 创建保存目录
if not os.path.exists('medical_diagnosis_system'):
os.makedirs('medical_diagnosis_system')
# 保存模型和配置
with open('medical_diagnosis_system/model.pkl', 'wb') as f:
pickle.dump(model, f)
with open('medical_diagnosis_system/vectorizer.pkl', 'wb') as f:
pickle.dump(vectorizer, f)
with open('medical_diagnosis_system/mlb.pkl', 'wb') as f:
pickle.dump(mlb, f)
with open('medical_diagnosis_system/diseases.pkl', 'wb') as f:
pickle.dump(diseases, f)
print(" 系统配置已保存到 'medical_diagnosis_system/' 目录")
print("\n 感谢使用医疗诊断辅助系统!")
print("️ 记住:真正的医疗诊断需要专业医生的判断。")图片1:医疗数据集探索分析(2×3子图)
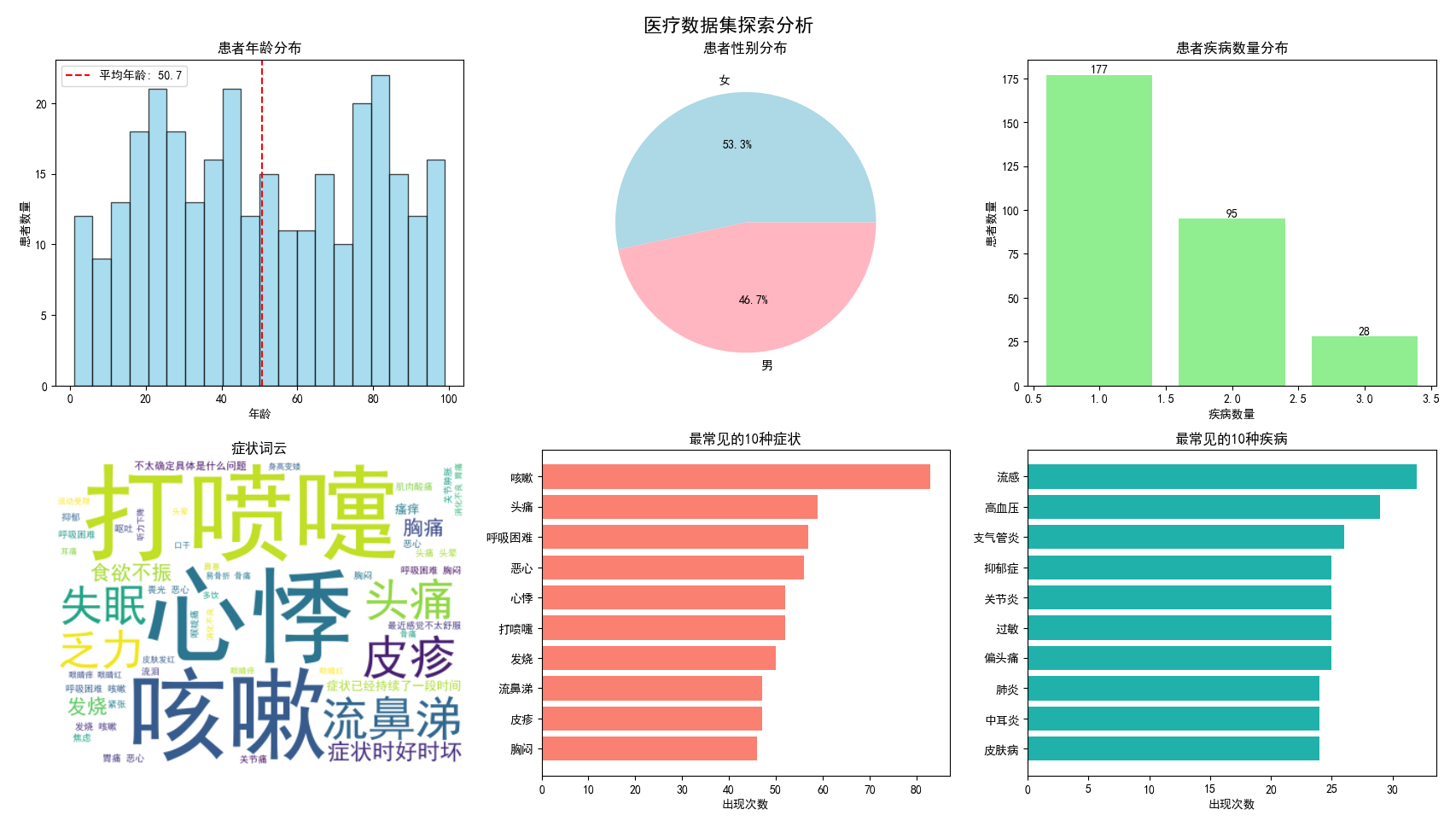
7.1.1 患者年龄分布图(左上)
功能 :展示模拟患者群体的年龄分布情况
分析:直方图显示了1-100岁患者的分布,红色虚线标注平均年龄。这个图帮助学生理解模拟患者群体的年龄特征,为后续可能考虑年龄因素的模型改进提供基础。
7.1.2 患者性别分布图(右上)
功能 :展示患者性别比例
分析:饼图直观显示了男女患者比例,使用浅蓝色和浅粉色区分。在真实的医疗系统中,性别通常是影响疾病发生的重要因素。
7.1.3 患者疾病数量分布图(中上)
功能 :展示每个患者患有的疾病数量分布
分析:柱状图显示了单病种、双病种和三病种患者的比例。60%患者只有一种疾病,30%有两种疾病,10%有三种疾病,这反映了真实世界中疾病共存的复杂性。
7.1.4 症状词云图(左下)
功能 :可视化所有症状描述中的高频词汇
分析:词云将症状文本中高频词以更大字体显示,低频词以较小字体显示。这提供了对数据集中常见症状的直观概览,帮助理解哪些症状描述最为频繁。
7.1.5 最常见的10种症状图(中下)
功能 :展示出现频率最高的10种症状
分析:水平条形图按频率排序,颜色为鲑鱼红。这个图不仅显示常见症状,还量化了它们的出现频率,帮助学生理解哪些症状是医疗诊断中的关键指标。
7.1.6 最常见的10种疾病图(右下)
功能 :展示出现频率最高的10种疾病
分析:水平条形图按频率排序,颜色为浅海绿色。这个图反映了模拟数据集中疾病的分布情况,对理解模型的训练数据平衡性很重要。
图片2:多标签分类模型性能评估(1×2子图)
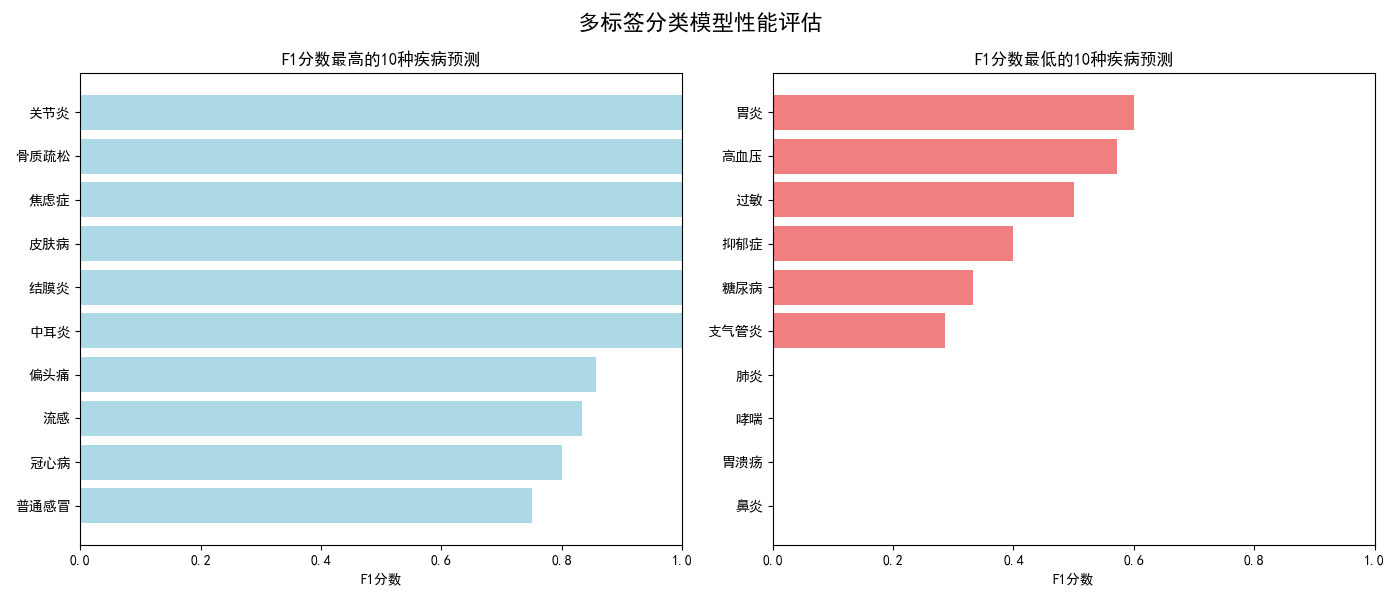
7.2.1 F1分数最高的10种疾病预测图(左)
功能 :展示模型预测效果最好的10种疾病
分析:水平条形图显示了模型对哪些疾病有较高的识别能力,F1分数接近1表示模型在这些疾病上表现良好。浅蓝色调表示正向结果。
7.2.2 F1分数最低的10种疾病预测图(右)
功能 :展示模型预测效果最差的10种疾病
分析:水平条形图显示了模型难以准确识别的疾病,F1分数较低。浅珊瑚色调表示需要改进的领域。通过对比左右两图,学生可以理解模型的优势和局限性。
图片3:医疗诊断辅助系统预测结果(交互式诊断时生成,1×2子图)
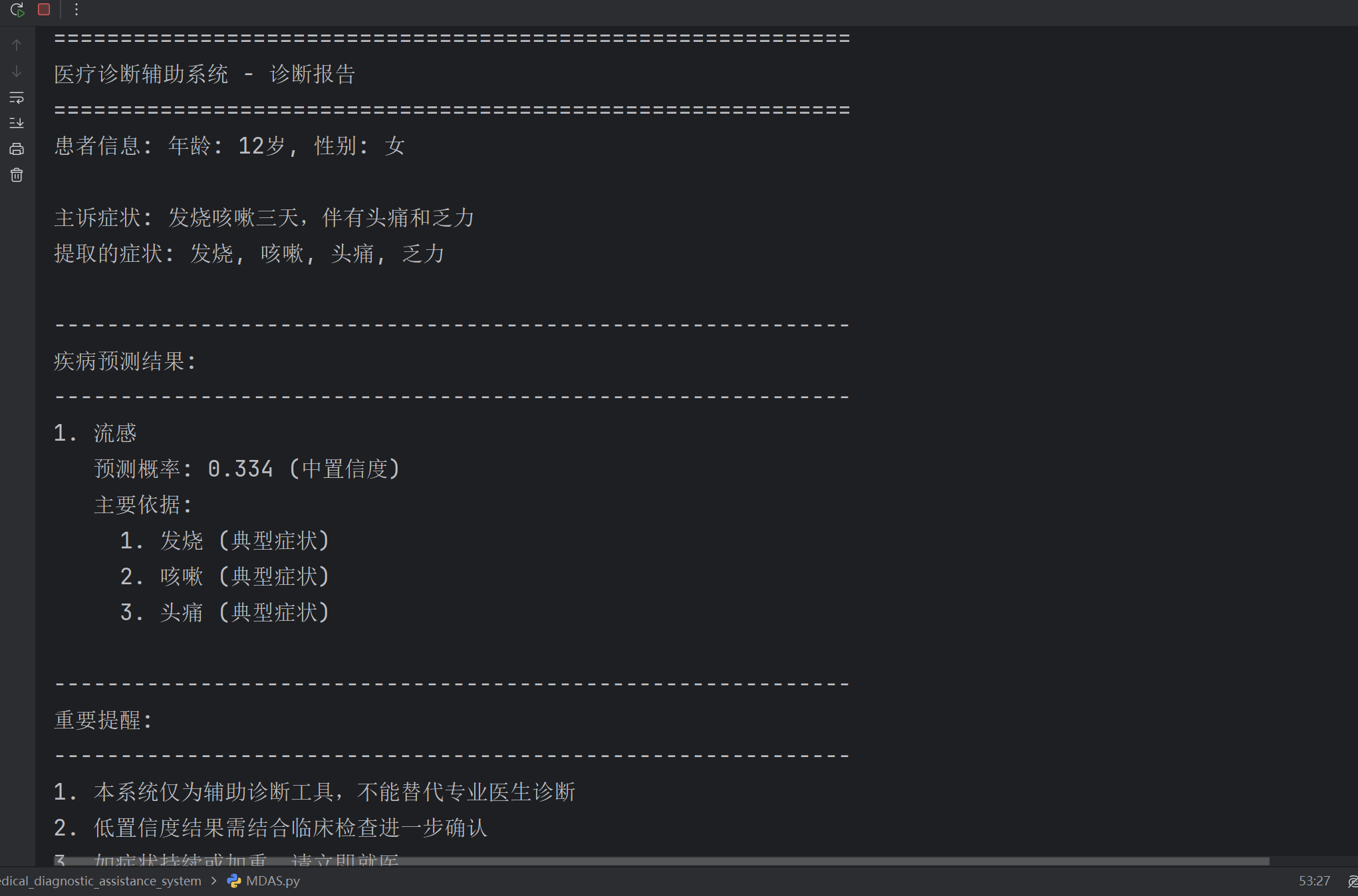
在图片1和图片2出来之后,在控制台内输入:
将会出现如下的图片:

7.3.1 Top-K疾病预测概率图(左)
功能 :展示当前患者最可能的K种疾病及其概率
分析:水平条形图用颜色编码表示置信度(浅绿色表示高置信度≥0.5,浅珊瑚色表示低置信度<0.5)。红色虚线标记了0.5的高置信度阈值。这个图直观地向用户展示各种疾病的可能性,是诊断决策的主要依据。
7.3.2 症状对"Top-1疾病"的贡献度图(右)
功能 :展示各个症状对最可能疾病的贡献程度
分析:水平条形图区分了"典型症状"(浅蓝色)和"一般症状"(浅灰色)。这个图增强了模型的可解释性,帮助用户理解为什么系统做出特定预测,也体现了朴素贝叶斯算法的原理------基于症状出现的概率计算疾病可能性。