系列前言
注,langchain 更新速度很快,本文所有案例都经过试验,在 2025年12月可用!
这是「写给小白学 AI」系列的第 5 篇文章,这个系列专门为刚接触人工智能的前端开发者和编程新手打造。如果你错过了之前的精彩内容,可以在这里补课:
- 打包票!前端和小白一定能明白的人工智能基础概念
- 不易懂你打我!写给前端和小白的 大模型(ChatGPT) 工作基本原理!
- 前端角度学 AI - 15 分钟入门 Python
- Prompt 还能哄女朋友!你真的知道如何问 ai 问题吗?
学习提示:为了让不同技术背景的同学都能跟上节奏,本文的代码示例会同时提供 Python 和 Node.js 版本,你可以选择自己熟悉的语言来实践。
一定要明白 ai agent 跟传统应用的区别
我们假设要开发一个对话机器人的应用。
对于传统对话机器人开发:核心在于后端业务逻辑、数据库设计、API 接口等技术栈。
而对于 AI Agent 对话机器人开发:核心变成了如何与大模型对话、如何优化提示词、如何管理对话流程。
核心在于 ai agent 中,大模型是驱动这个程序核心,这也是为什么说 ai 改变了传统应用的开发模式,也正式了解到这个概念,我才明白,ai 应用开发跟传统应用开发的根本区别。
从理论到实践:为什么你需要一个 AI 开发框架
经过前面几篇基础知识的铺垫,现在终于要进入激动人心的实战阶段了!但在真正开始动手构建 AI Agent 之前,我们需要先解决一个关键问题:
工欲善其事,必先利其器
在传统开发中,不同的编程语言都有自己的"神器":
- Java 开发者会用 Spring 框架
- Go 程序员会选择 Gin 框架
- Python 开发者青睐 Django/Flask
那么在 AI 应用开发领域,什么是我们的"趁手兵器"呢?
目前 AI Agent 开发框架中最耀眼的一颗星,毫无疑问就是 LangChain。今天,就让我们一起来揭开它的神秘面纱!
环境准备
javascript 环境,对于我们前端来说无需多言,python 环境需要稍微费点力气。
首先建议使用包管理工具,例如 node.js 有 nvm ,我选择使用 miniconda 管理 python 版本。(你也可以放弃使用 python, 下面的案例是 node.js 和 python 都有)。
你可以网上搜索,我是 mac 系统,我参考的这篇文章:zhuanlan.zhihu.com/p/476670331
安装好之后,切记,要激活新的 python 环境,也就是对于 node.js 来说要切换到对应的 node.js 版本,这样后续才能使用这个版本。
创建新环境,myenv 是你的环境名字,python=3.13 是代表你喜欢切换的 python 版本
ini
conda create -n myenv python=3.13激活新环境,myenv 代表上面我们创建的环境名字
conda activate myenv安装依赖,使用原生python 自带的 pip 命令即可
pip 包名xx安装之后,如何确认你安装完成呢,可以使用以下命令,查看所有安装的包
conda listLangChain 是什么?一个生动比喻告诉你答案
我们再用一个例子,来说明 LangChain 为什么是 ai agent 开发中必不可少的内容。
没有 LangChain 时,调用不同的大模型可能需要这样:
以下是调用 OpenAI 的 python 代码,node.js 代码在后面
python
# 调用 OpenAI
import openai
openai.api_key = "your-key"
response = openai.ChatCompletion.create(...)
# 调用 Claude
import anthropic
client = anthropic.Anthropic(api_key="your-key")
response = client.messages.create(...)
# 每个API都不一样,学习成本高!我们把上面 python 的示例换为 node.js
javascript
import OpenAI from 'openai';
// 初始化客户端
const openai = new OpenAI({
apiKey: 'your-openai-api-key',
});
// 调用 ChatGPT
async function callOpenAI() {
try {
const completion = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hello!" }
],
temperature: 0.7,
});
console.log(completion.choices[0].message.content);
return completion;
} catch (error) {
console.error('Error calling OpenAI:', error);
}
}
// 调用 Claude
import Anthropic from '@anthropic-ai/sdk';
// 初始化客户端
const anthropic = new Anthropic({
apiKey: 'your-anthropic-api-key',
});
async function callClaude() {xxx}
// 调用函数
callClaude();而你使用 langChain 后:
python
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
# 统一的使用方式
openai_llm = ChatOpenAI(model="gpt-4")
claude_llm = ChatAnthropic(model="claude-3")
# 调用方式完全一致!
response1 = openai_llm.invoke("你好")
response2 = claude_llm.invoke("Hello")node.js 版本
javascript
import { ChatOpenAI } from "@langchain/openai";
import { ChatAnthropic } from "@langchain/anthropic";
import 'dotenv/config'; // 确保已安装 dotenv: npm install dotenv
// 注:import 'dotenv/config';作用是自动从项目根目录的 `.env` 文件中读取环境变量
// 例如 .env 文件中有配置 OPENAI_API_KEY = xxx, 那么我们就可以用 process.env.OPENAI_API_KEY 获取到值
// 统一的使用方式
const openai_llm = new ChatOpenAI({
modelName: "gpt-4",
temperature: 0.7,
apiKey: process.env.OPENAI_API_KEY, // 从环境变量读取
});
const claude_llm = new ChatAnthropic({
modelName: "claude-3-opus-20240229", // Claude 需要具体版本
temperature: 0.7,
apiKey: process.env.ANTHROPIC_API_KEY, // 从环境变量读取
});
// 调用方式完全一致!
async function callModels() {
try {
// 单个调用
const response1 = await openai_llm.invoke("你好");
const response2 = await claude_llm.invoke("Hello");
console.log("GPT-4 回复:", response1.content);
console.log("Claude 3 回复:", response2.content);
return { response1, response2 };
} catch (error) {
console.error("调用模型时出错:", error);
throw error;
}
}
// 调用函数
callModels();看到区别了吗?LangChain 就像是一个万能翻译器,无论底层用的是哪个大模型,都为你提供统一的 API 接口。
注意这些案例,你需要充值才能调用,我是充值了 deepseek 10 元用来练习,调用方式跟 openai,一直,我先给大家展示一下deepseek用langchain的调用方式:
python
# 要安装对应的包 langchain langchain-openai
from langchain_openai import ChatOpenAI
api_key = "xxx" # 自己去生成 api_key
openai_llm = ChatOpenAI(
model_name="deepseek-chat",
temperature=0,
api_key=api_key,
base_url="https://api.deepseek.com",
)
response1 = openai_llm.invoke("你好")
print("Response 1:", response1)js 版本, 注意下载 @langchain/core,@langchain/openai 包。
javascript
import { ChatOpenAI } from "@langchain/openai";
const apiKey = "sk-xx";
const llm = new ChatOpenAI({
model: "deepseek-chat",
temperature: 0,
apiKey,
configuration: {
baseURL: "https://api.deepseek.com",
},
// other params...
});
const run = async () => {
try {
const response = await llm.invoke([
{
role: "user",
content: "I love programming.",
},
]);
console.log("response:", response);
} catch (error) {
console.error("Error:", error);
}
};
run();拆解 LangChain:名字里藏着什么秘密?
Lang + Chain = 语言模型 + 链式调用
这个名字精准地描述了它的核心思想:
- Lang:代表大语言模型(Large Language Model)
- Chain:代表将不同组件像链条一样连接起来
合起来就是:通过链式架构将大模型能力连接到实际应用中。
前端开发者的福音
好消息是,LangChain 原生支持 TypeScript!这意味着前端开发者可以用自己熟悉的 JavaScript/TypeScript 来构建 AI 应用。不过现实情况是,AI 领域的主流语言仍然是 Python,所以本文会以 Python 为主进行讲解。
不用担心:即使你现在对 Python 不熟悉,跟着示例一步步来,遇到不懂的地方随时问 AI 助手(比如我😊),多看多练自然就掌握了。
LangChain 还解决了哪些大模型的问题
大模型虽然强大,但也有一些"与生俱来"的局限性:
1. 信息过时问题
"今天北京的天气怎么样?"
大模型很可能会告诉你它不知道,因为它的训练数据截止到某个特定日期。这种时效性强的问题,单纯的大模型很难给出准确答案。
2. 无法联网
"帮我查一下特斯拉最新的股价"
大模型不能实时访问互联网(虽然有些模型后期增加了联网功能,但这通常是基于 LangChain 等技术实现的扩展)。
3. 私有知识盲区
"我们公司的产品定价策略是什么?"
大模型没有学习过你公司的内部文档,自然无法回答这类问题。
4. 无法调用外部服务
"帮我订一张明天去上海的机票"
大模型本身没有订票能力,它需要调用第三方的机票预订 API。
LangChain 如何解决这些问题?
针对上述问题,LangChain 提供了完整的解决方案:
解决方案矩阵
| 大模型的问题 | LangChain 的解决方案 | 实际应用场景 |
|---|---|---|
| 信息过时 | 实时数据检索 | 新闻查询、股票价格、天气信息 |
| 无法联网 | 网络搜索工具 | 最新资讯、实时数据获取 |
| 私有知识盲区 | 文档加载与向量检索 | 企业内部知识库、专业文档问答 |
| 不能调用 API | 工具调用集成 | 订票、支付、查询等实际业务 |
统一的多模型支持
LangChain 支持几乎所有主流大模型:
- OpenAI GPT 系列
- Anthropic Claude 系列
- Google Gemini
- 开源模型(Llama、Qwen等)
而且调用方式完全统一,让你可以轻松切换或同时使用多个模型。
关于可视化平台的思考
有些同学可能会问:"现在不是有 Coze、Dify 这类可视化 AI 应用搭建平台吗?为什么还要学编程去做大模型应用?"
这个问题问得很好!作为前端开发者,你一定很清楚低代码/无代码平台的优缺点:
可视化平台的优势
- 上手快,无需编码
- 快速原型验证
- 适合简单场景
可视化平台的局限
- 定制化能力有限
- 复杂逻辑实现困难
- 难以集成到现有系统
- 性能和扩展性受限
就像你不会只用低代码平台来做复杂的前端项目一样,在需要深度定制和复杂集成的 AI 应用场景中,掌握 LangChain 这样的编程框架是必不可少的。
讲完 langchain 是什么了,接下来我们了解下 ai agent 开发我们常见遇到的 4 个场景,帮助我们了解到后续开发 ai agent 可能遇到的架构是什么。
ai agent 开发常见的 4 个场景
纯Prompt场景
纯Prompt场景是最基础、最直接的AI应用方式,就像使用搜索引擎一样简单:你输入问题(Prompt),AI直接返回答案。示意图如下:

使用 langChain 示例代码, node.js (大家测试,为了方便,可以用我们之前的 deepseek 版本,毕竟是练习 api 而已) :
javascript
// 纯Prompt场景的简单实现
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
modelName: "gpt-4",
temperature: 0.7,
});
// 直接调用
const response = await llm.invoke("帮我写一首关于春天的诗");
console.log(response.content);python版本:
python
# 安装依赖:pip install langchain-openai
from langchain_openai import ChatOpenAI
import os
# 纯Prompt场景的简单实现
llm = ChatOpenAI(
model="gpt-4", # Python中参数名是model,不是modelName
temperature=0.7,
api_key=os.getenv("OPENAI_API_KEY") # 从环境变量读取
)
# 直接调用
response = llm.invoke("帮我写一首关于春天的诗")
print(response.content)剩下的场景,后续在 langchain 的各个模块介绍中,会写案例。
场景二:Agent + Function Call
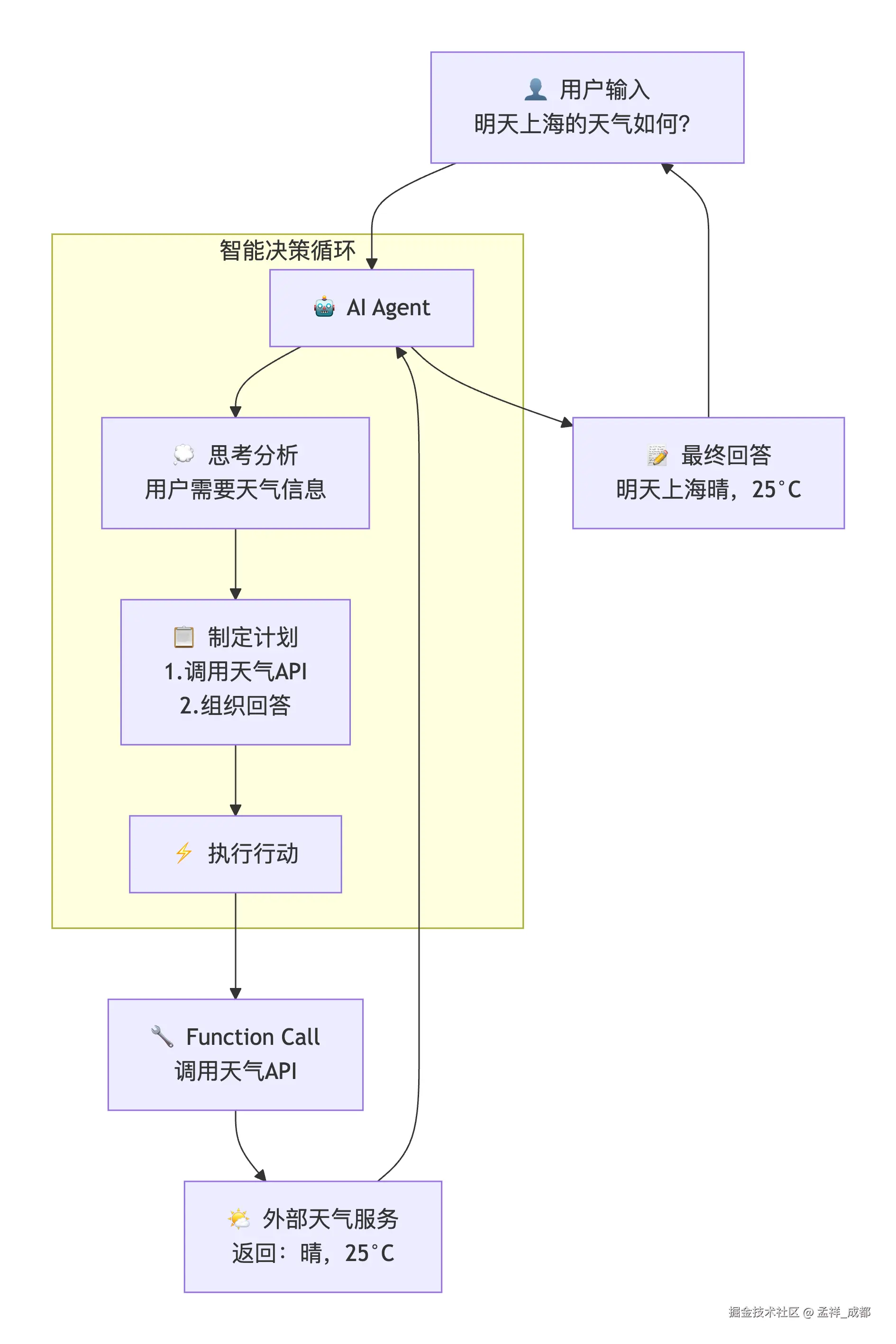
什么是Agent + Function Call?
Agent 是能够自主规划、决策和执行的智能体,Function Call让AI能够调用外部工具和API,真正"动手做事"。
简单举例,我们查询天气时,ai 肯定不知道当天天气是什么,此时,ai 可以调用一个函数,这个函数是我们后端自己写的,当问及查询天气的时候,就让大模型调我们的查询天气 api,然后将结果给大模型,最后大模型返回给用户。
场景三:RAG(检索增强生成)
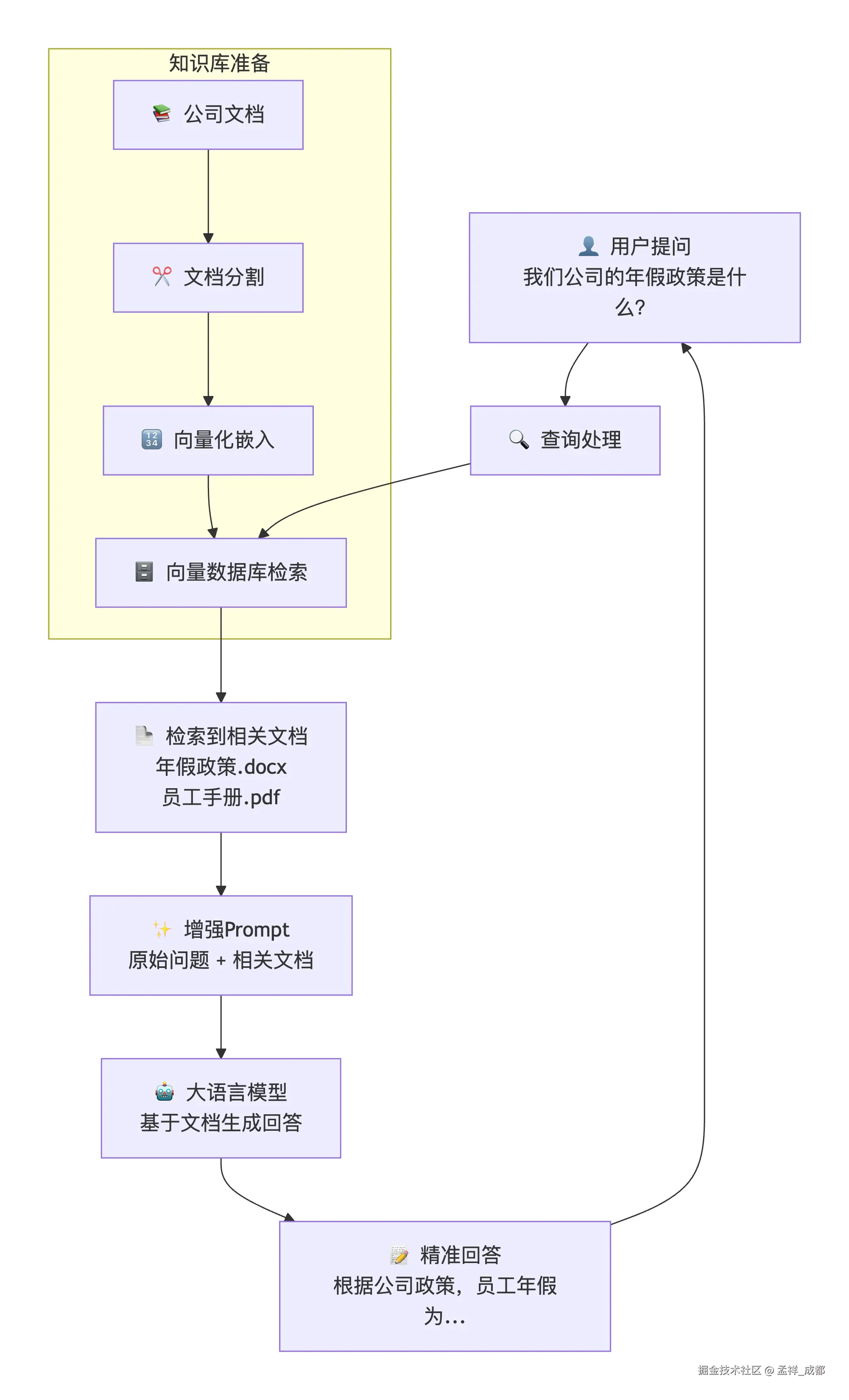
简单来说,比如你们要做一个公司内部文档的 ai agent,当你问这个 ai agent 问题的时候,很多问题都是跟公司内部信息有关,这个大模型肯定是不知道的,所以我们提前把公司各种资料转化为大模型认识的格式(向量),保存在数据库中,当大模型回答有关公司问题的时候,先去我们的数据库差相关内容,然后找到相关信息,再把之前用户提问的问题增强一下。
增强是指,把从向量数据库搜索的一些资料也附带在问题中,最终大模型基于这些资料和用户的问题回答。
场景四:Fine-tuning(微调训练)
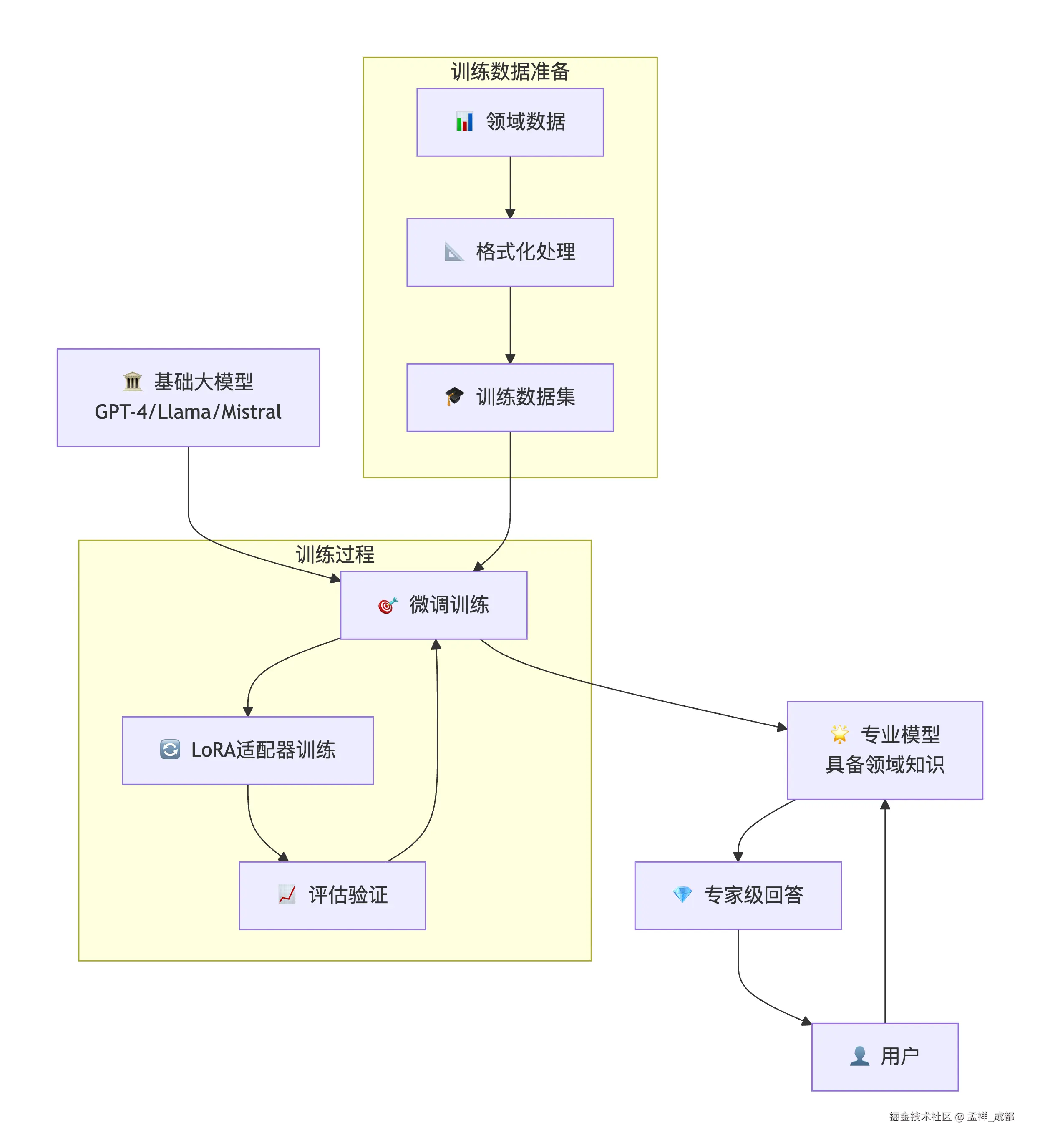
微调也很好理解,之前 rag 是把我们公司数据库里的信息附带着给大模型,让大模型知道一些背景信息,而微调,是直接把数据库里的资料给大模型训练,让大模型学习到。
最后用户问问题的时候,就不需要 rag 的模式,还去我们本地的数据库搜索了,直接就能回答跟公司相关的问题了。这就是微调!
其实目前实现 ai agent 大部分就是上面四种类型 + 在可视化平台拖拉拽的方式。这对于大家理解如果开发 ai agent 涉及到的应用原理很有帮助!
欢迎加入交流群
接下来 ai agent 部分,我们会继续介绍 langchain 的各个模块和基本使用。一起加油!
同时欢迎大家访问我的 headless(无样式) 组件库项目,欢迎一起交流!
欢迎到我们的交流群一起交流各种前端技术,同时欢迎访问我的 headless 组件库,同时感谢你的 star: