1、思想简介
集成学习: (Ensemble Learning)集成学习是机器学习的一种范式,它的主要思想是使用多个弱学习器来构建一个整体泛化性更强的最终学习器来完成任务,它认为集体的智慧比单个的个体更加的准确、鲁棒。参与组合的模型又叫弱学习器或者基学习器。
集成学习思想分为bagging思想和boosting思想。
2、Bagging

bagging思想是使用有放回抽取样本(bootstrap抽样)给每个学习器,并行的训练多个弱学习器,最终的预测结果采用各个弱学习器平权投票的方式。
对于分类问题,也即少数服从多数,对于回归问题就是计算每个弱学习器预测结果的均值。
bagging思想适用于多个模型方差过大的情况,但不使用模型偏差过大一致性的情况。
2.1、随机森林

bagging代表性的算法是随机森林,API是
RandomForestClassifier()
参数:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
n_estimators |
int |
100 |
随机森林中的树的数量。更多的树通常能提高准确性,但会增加计算时间。 |
criterion |
str |
'gini' |
用于衡量分裂质量的函数,可以选择 'gini'(基尼不纯度)或 'entropy'(信息增益)。 |
max_depth |
int 或 None |
None |
每棵树的最大深度,控制树的复杂度,避免过拟合。 |
min_samples_split |
int 或 float |
2 |
分裂一个节点所需的最小样本数。可以用于控制树的复杂度,防止过拟合。 |
min_samples_leaf |
int 或 float |
1 |
每个叶节点的最小样本数。增加此值可避免过拟合。 |
max_features |
int, float, str, None |
'auto' |
每次分裂时考虑的最大特征数。可以是整数(指定特征数)、浮动值(指定比例)、'auto'(默认)等。 |
bootstrap |
bool |
True |
是否使用自助法(bootstrap sampling)进行抽样。如果为 True,则进行有放回的抽样。 |
oob_score |
bool |
False |
是否使用袋外样本(Out-of-Bag samples)评估模型性能。仅在 bootstrap=True 时有效。 |
n_jobs |
int |
None |
并行计算的作业数。设置为 -1 使用所有CPU核心。 |
random_state |
int, RandomState, None |
None |
随机数生成器的种子,确保结果的可重现性。 |
class_weight |
dict, 'balanced', None |
None |
类别权重,可以平衡类别不均衡的问题。 |
verbose |
int |
0 |
控制训练时的输出信息级别。1为输出进度,更多值输出更多调试信息。 |
max_samples |
int 或 float |
None |
每棵树训练时使用的最大样本数,能加速训练并减少过拟合。 |
warm_start |
bool |
False |
是否启用暖启动,允许在已有模型的基础上添加更多的树。 |
min_impurity_decrease |
float |
0.0 |
控制节点分裂的条件,只有当不纯度减少超过该值时,才会进行分裂。 |
min_weight_fraction_leaf |
float |
0.0 |
每个叶子节点最小权重比例。可以用于处理样本权重不均衡的情况。 |
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
综上:弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果。
3、Boosting
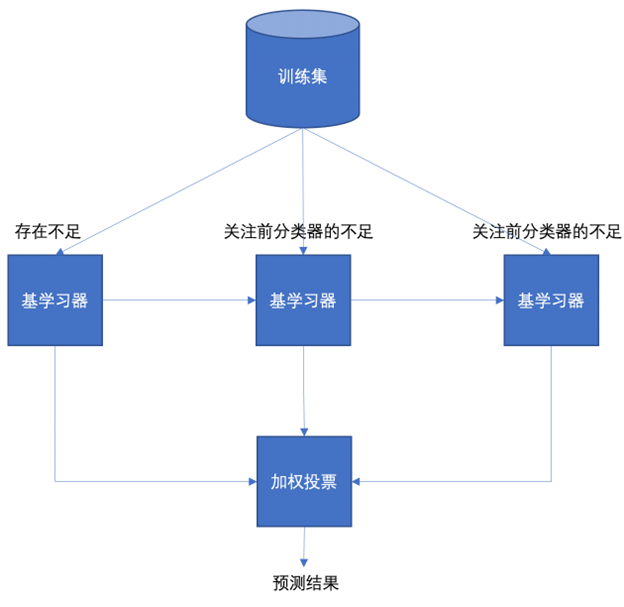
boosting思想是串行的训练多个弱学习器(决策树桩),每个学习器重点关注上一个学习器不足的地方,最后采用加权投票的方式计算最终的输出结果。
Boosting的知识点:
1、适用于多个偏差很大的模型提升。
2、在Boosting中,下一个学习器对上一个学习器的"经验"学习来自于样本权重,也即通过样本权重调整来传递经验。
3、Boosting思想通常使用浅层决策树(1-2层),这种被称为决策树桩。
4、在Boosting中样本的权重不会直接影响到最终投票结果,最终投票权重是每个弱分类器的权重αt。
boosting代表算法是AdaBoost、GBDT、XGBoost等。
3.1、AdaBoost
AdaBoost核心思想是通过逐步的提升被上一次学习器分类错误的样本权重,后来的学习器会不断的关注这些错误点。
随着学习器的不断增加,Adaboost最终的分类器在训练集上的错误将会越来越小。Adaboost最终的结果是每个学习器结果的加权和,以符号位决定结果。步骤大致是首先初始化每个样本的权重,来训练第一个弱学习器,计算错误率,通过错误率计算第一个学习器的权重,通过第一个模型的权重计算归一化的样本权重,再由这些计算更新后的样本权重,重复此步骤直到达到算法限制条件。
Adaboost的API是
AdaBoostClassifier(base_estimator=mytree, n_estimators=500, learning_rate=0.1, random_state=0)
参数:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
base_estimator |
estimator |
DecisionTreeClassifier(max_depth=1) |
基础分类器,默认使用决策树(深度为1),可以指定为其他模型,例如 mytree。 |
n_estimators |
int |
50 |
弱分类器的数量,即 AdaBoost 迭代训练的次数。更多的弱分类器可能会提升准确性,但计算成本也更高。 |
learning_rate |
float |
1.0 |
学习率,控制每个弱分类器在组合中的权重,较小的学习率会让每个分类器贡献更少,需要更多迭代。 |
random_state |
int, RandomState, None |
None |
随机数种子,用于确保每次训练结果一致。设置 random_state=0 可确保实验可重复。 |
算法步骤描述:
- 初始化样本权重,来训练第1个弱学习器。找最小的错误率计算模型权重,再更新模数据权重。
- 根据更新的数据集权重,来训练第2个弱学习器,再找最小的错误率计算模型权重,再更新模数据权重。
- 依次重复第2步,训练n个弱学习器。组合起来进行预测。结果大于0为正类、结果小于0为负类。
这里附上博主写的详细的AdaBoost步骤,供大家参考学习: (字丑勿喷✌)


附定理证明:

3.2、GBDT
梯度提升树 (Gradient Boosting Decision Tree)GBDT算法的思想是每次拟合上一个模型的残差,后面的模型只关注上一个模型的预测结果与观测结果之间的残差。通过迭代拟合残差(即真实观测值与当前模型预测值的差异),逐步提升模型精度。每一轮新模型的目标是拟合前一轮的残差,最终将所有弱学习器的预测结果叠加,形成强学习器。损失函数是真实值与预测值残差,最终的结果是各个学习器结果相加。
注意,梯度提升树(GBDT)的本质:不是直接拟合残差,而是用损失函数的负梯度作为残差的近似(从公式中可以看出,当损失函数为平方误差时,负梯度恰好等于残差)。

API:
GradientBoostingClassifier()
参数:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
loss |
str |
'deviance' |
损失函数,用于优化目标。'deviance' 对应对数损失(Log-Loss),'exponential' 对应指数损失。 |
learning_rate |
float |
0.1 |
学习率,用于缩小每个弱学习器的贡献。较小的学习率需要更多的弱学习器来达到相同效果。 |
n_estimators |
int |
100 |
弱分类器的数量,即模型的迭代次数。更多的分类器可能提升模型的准确性,但也增加计算复杂度。 |
subsample |
float |
1.0 |
用于每次训练的样本比例。subsample < 1.0 可以用来引入随机性,减少过拟合。 |
criterion |
str |
'friedman_mse' |
划分质量的度量标准。'friedman_mse' 和 'mse' 都用于回归问题,'mae' 用于处理异常值敏感的情况。 |
min_samples_split |
int or float |
2 |
每个节点拆分时所需的最小样本数。可以设置为浮动值,表示样本比例。 |
min_samples_leaf |
int or float |
1 |
叶节点上样本的最小数量。设置更大值可以防止过拟合。 |
max_depth |
int |
3 |
树的最大深度。限制树的深度有助于防止过拟合。 |
min_impurity_decrease |
float |
0.0 |
对于一个节点,划分所需的最小不纯度减少值。 |
max_features |
int, float, str, None |
None |
用于每次划分时考虑的特征数量。可以指定为整数、浮动值或 'auto', 'sqrt', 'log2'。 |
max_leaf_nodes |
int or None |
None |
最大叶节点数。限制叶节点数有助于提高训练速度,并防止过拟合。 |
min_weight_fraction_leaf |
float |
0.0 |
叶节点的最小权重分数。这个值用于处理具有不同权重的样本数据。 |
warm_start |
bool |
False |
是否使用上一轮训练的结果作为初始化,从而加速训练。设置为 True 可以在增加 n_estimators 时保留现有树。 |
validation_fraction |
float |
0.1 |
用于在训练过程中验证模型的样本比例。 |
n_iter_no_change |
int |
10 |
如果验证集上的性能在连续 n_iter_no_change 次迭代中没有改进,则停止训练。 |
tol |
float |
1e-4 |
用于判断停止训练的容忍度,基于验证集上的性能变化。 |
random_state |
int, RandomState, None |
None |
随机种子,用于确保每次训练结果一致。 |
verbose |
int |
0 |
是否显示训练过程的详细信息。verbose=1 显示进度,verbose=2 显示每个提升的详细输出。 |
n_jobs |
int |
1 |
并行运行的作业数。可以设置为 -1,使用所有可用的CPU。 |
步骤
1 初始化弱学习器(目标值的均值作为预测值)
2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度
3 直到达到指定的学习器个数
4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出

3.3、XGBoost
极端梯度提升树,核心构建思想围绕梯度提升框架展开,通过集成弱学习器(决策树)、优化目标函数和正则化控制实现高效、高精度的模型训练。
它的思想是在GBDT上增加了一个正则化项,这个正则化项是树复杂度控制,以此来提高模型的泛化性。
这个正则化项公式:
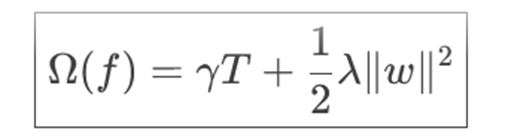

完整的目标函数为:
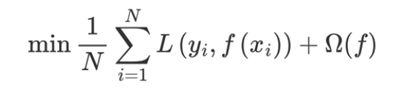
目标函数化简推导:



最终我们模型构建的标准为:
根据计算的gain值,对树中的每个叶子结点尝试进行分裂,计算分裂前 - 分裂后的分数:
- 如果gain > 0,则分裂之后树的损失更小,会考虑此次分裂
- 如果gain< 0,说明分裂后的分数比分裂前的分数大,此时不建议分裂
当触发以下条件时停止分裂:
- 达到最大深度
- 叶子结点数量低于某个阈值
- 所有的结点在分裂不能降低损失
等等...
API:
XGBClassifier(n_estimators, max_depth, learning_rate, objective)
参数:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
n_estimators |
int |
100 |
弱分类器的数量,即模型的迭代次数。更多的分类器可以提高模型的准确性,但也增加计算复杂度。 |
max_depth |
int |
6 |
树的最大深度,控制每棵树的复杂度,避免过拟合。较大的值可能导致过拟合,较小的值可能导致欠拟合。 |
learning_rate |
float |
0.3 |
学习率,控制每个弱分类器的贡献大小。较小的学习率通常需要更多的树来达到相同的效果。 |
objective |
str |
'binary:logistic' |
目标函数,用于确定模型的优化目标。常见的目标函数包括:'binary:logistic'(二分类),'multi:softmax'(多分类),'reg:squarederror'(回归)。 |
booster |
str |
'gbtree' |
基础模型类型,可以选择 'gbtree'(树模型),'gblinear'(线性模型),'dart'(DART提升树)。 |
eval_metric |
str |
'logloss' |
用于评估模型性能的度量标准。常见的评估标准有:'logloss'(对数损失)、'error'(分类错误率)。 |
gamma |
float |
0 |
控制树的分裂。较大的值会使树的分裂更严格,从而控制过拟合。 |
subsample |
float |
1.0 |
控制每棵树的训练样本比例。设置小于1的值会增加模型的随机性,减少过拟合。 |
colsample_bytree |
float |
1.0 |
每棵树构建时的特征子样本比率,控制特征选择的随机性。 |
colsample_bylevel |
float |
1.0 |
控制每个树层使用的特征子样本比率。 |
colsample_bynode |
float |
1.0 |
每个节点构建时使用的特征子样本比率。 |
lambda |
float |
1 |
L2正则化参数,控制过拟合。增加此值可以增加正则化,从而降低模型复杂度。 |
alpha |
float |
0 |
L1正则化参数,控制过拟合。增加此值可以增加正则化,从而降低模型复杂度。 |
scale_pos_weight |
float |
1 |
控制正负样本不平衡的权重,常用于处理类别不均衡问题。 止在高类别不平衡数据集上的数值不稳定,通常设为较小值。 |
tree_method |
str |
'auto' |
树的构建方法。可选 auto, exact, approx, hist, gpu_hist,gpu_hist 用于GPU加速。 |
grow_policy |
str |
'depthwise' |
控制树的生长策略,'depthwise' 每次按深度生长,'lossguide' 按损失减少来生长树。 |
min_child_weight |
float |
1 |
最小样本权重和,控制树的复杂度。值越大,模型越简单。 |
max_bin |
int |
256 |
每棵树构建时使用的最大特征数量。增加此值会提高精度,但也增加计算成本。 |
n_jobs |
int |
1 |
并行计算的线程数,设置为 -1 使用所有核心。 |
random_state |
int, RandomState, None |
None |
随机数种子,用于确保每次训练结果一致。 |
verbose |
int |
0 |
是否输出训练过程的详细信息,设置为 1 会显示进度条。 |
early_stopping_rounds |
int |
None |
如果在指定的轮数内验证集的评估指标没有改进,则停止训练。 |
4、Bagging思想和Boosting思想对比

代码示例:
随机森林:
python
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve
df = pd.read_csv('../Day05_DecisionTree/train.csv')
x = df[["Pclass","Age","Sex"]]
y = df["Survived"]
x = x.copy()
x["Age"] = x["Age"].fillna(x['Age'].mean(), inplace=True)
x = pd.get_dummies(x, drop_first=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6, stratify=y)
ssm = StandardScaler()
x_train = ssm.fit_transform(x_train)
x_test = ssm.transform(x_test)
rf = RandomForestClassifier(n_estimators=100, criterion='gini', bootstrap=True)
rf.fit(x_train, y_train)
y_pred = rf.predict(x_test)
accuracy_score(y_test, y_pred)
roc_curve()GBDT:
python
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
df = pd.read_csv('./data/train.csv')
x = df[['Pclass','Age','Sex']]
y = df["Survived"]
x = x.copy()
x['Age'] = x['Age'].fillna(x['Age'].mean())
x = pd.get_dummies(x, drop_first=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6, stratify=y)
ssm = StandardScaler()
x_train = ssm.fit_transform(x_train)
x_test = ssm.transform(x_test)
gbdt = GradientBoostingClassifier(loss='log_loss', n_estimators=100)
gbdt.fit(x_train, y_train)
y_pred = gbdt.predict(x_test)
acs = accuracy_score(y_test, y_pred)
print(f"准确率:{acs}")XGBoost:
python
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from xgboost import XGBClassifier
df = pd.read_csv('./data/红酒品质分类.csv')
x = df.iloc[:, :-1]
y = df.iloc[:, -1]
y = y - 3
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6, stratify=y)
ss = StandardScaler()
new_x_train = ss.fit_transform(x_train)
new_x_test = ss.transform(x_test)
model = XGBClassifier(objective="multi:softmax",eval_metric='merror',num_class=5)
model.fit(new_x_train, y_train)
y_pred = model.predict(new_x_test)
score = accuracy_score(y_test, y_pred)
print(score)
print(y_pred)