文章目录
- 前言
- [第一章:C/C++ 内存分布详解](#第一章:C/C++ 内存分布详解)
-
- [1\. 内存分布全景图](#1. 内存分布全景图)
- [2\. 各区域详细剖析](#2. 各区域详细剖析)
-
- [2.1 内核空间](#2.1 内核空间)
- [2.2 栈区 (Stack)](#2.2 栈区 (Stack))
- [2.3 共享区 / 文件映射区](#2.3 共享区 / 文件映射区)
- [2.4 堆区 (Heap)](#2.4 堆区 (Heap))
- [2.5 数据段 (Data Segment)](#2.5 数据段 (Data Segment))
-
- [A. 已初始化数据段 (.data)](#A. 已初始化数据段 (.data))
- [B. 未初始化数据段 (.bss)](#B. 未初始化数据段 (.bss))
- [2.6 代码段 (Code Segment / Text Segment)](#2.6 代码段 (Code Segment / Text Segment))
- [3\. 深度对比:栈 (Stack) vs 堆 (Heap)](#3. 深度对比:栈 (Stack) vs 堆 (Heap))
- [4\. 实战代码解析](#4. 实战代码解析)
- 补充:cons声明的变量位置
-
- [1\. 局部 `const` 变量](#1. 局部
const变量) - [2\. 全局 `const` 变量](#2. 全局
const变量) - [3\. `static` 修饰的 `const`](#3.
static修饰的const) - [4\. 字符串字面量 (特殊)](#4. 字符串字面量 (特殊))
- [5\. 被编译器优化了 (常量折叠)](#5. 被编译器优化了 (常量折叠))
- 总结一张表
- [1\. 局部 `const` 变量](#1. 局部
- [第二章:C++ 内存管理详解](#第二章:C++ 内存管理详解)
-
- [1\. 内置类型的内存管理](#1. 内置类型的内存管理)
-
- [1.1 单个变量的申请与释放](#1.1 单个变量的申请与释放)
- [1.2 数组(多个变量)的申请与释放](#1.2 数组(多个变量)的申请与释放)
- [1.3 核心思考:内置类型混用 `delete` 和 `delete\[\]` 会怎样?](#1.3 核心思考:内置类型混用
delete和delete[]会怎样?)
- [2\. 自定义类型的内存管理](#2. 自定义类型的内存管理)
-
- [2.1 单个对象的申请与释放](#2.1 单个对象的申请与释放)
- [2.2 new初始化具体流程:](#2.2 new初始化具体流程:)
- [2.3 初始化方式](#2.3 初始化方式)
-
- [1\. 默认初始化:`new T` (无括号)](#1. 默认初始化:
new T(无括号)) - [2\. 值初始化:`new T()` (空括号)](#2. 值初始化:
new T()(空括号)) - [3\. 直接初始化:`new T(args)` (圆括号传参)](#3. 直接初始化:
new T(args)(圆括号传参)) - [4\. 列表初始化:`new T{args}` (花括号,C++11)](#4. 列表初始化:
new T{args}(花括号,C++11)) - [5\. 数组的初始化](#5. 数组的初始化)
- 快速一览表
- [1\. 默认初始化:`new T` (无括号)](#1. 默认初始化:
- [2.4 对象数组的申请与释放](#2.4 对象数组的申请与释放)
-
- [2.4.1 为什么必须要有默认构造函数?](#2.4.1 为什么必须要有默认构造函数?)
- [2.4.2 `delete\[\]` 的魔力:Cookie 机制](#2.4.2
delete[]的魔力:Cookie 机制)
- [补充:Cookie 机制只有在显示写析构情况下才开?](#补充:Cookie 机制只有在显示写析构情况下才开?)
-
- [1\. 核心规则:有没有析构函数是关键](#1. 核心规则:有没有析构函数是关键)
-
- [情况 A:内置类型(int, float)或 无自定义析构函数的结构体](#情况 A:内置类型(int, float)或 无自定义析构函数的结构体)
- [情况 B:有自定义析构函数的类](#情况 B:有自定义析构函数的类)
- [2\. Cookie开的字节数](#2. Cookie开的字节数)
- [3\. 代码验证:亲眼看看"地址偏移"](#3. 代码验证:亲眼看看“地址偏移”)
- [4\. 总结图解](#4. 总结图解)
- [3\. 总结与对比表](#3. 总结与对比表)
- [第四章:内存分配底层------operator new 与 operator delete](#第四章:内存分配底层——operator new 与 operator delete)
-
- [4.1 核心概念区分:Expression vs Function](#4.1 核心概念区分:Expression vs Function)
- [4.2 全局 operator new 与 operator delete](#4.2 全局 operator new 与 operator delete)
-
- [1\. 全局 operator new](#1. 全局 operator new)
- [2\. 全局 operator delete](#2. 全局 operator delete)
- [4.3 类专属重载](#4.3 类专属重载)
- [4.4 数组版本:operator new\[\] 与 operator delete\[\]](#4.4 数组版本:operator new[] 与 operator delete[])
- [4.5 Placement New (定位 new)](#4.5 Placement New (定位 new))
- [5.5 深入详解:定位 new (Placement New)](#5.5 深入详解:定位 new (Placement New))
-
- [1\. 核心定义与头文件](#1. 核心定义与头文件)
- [2\. 具体语法规则](#2. 具体语法规则)
- [3\. 标准使用流程 (SOP)](#3. 标准使用流程 (SOP))
-
- 第一步:准备"生肉" (Raw Memory)
- [第二步:调用 Placement New](#第二步:调用 Placement New)
- 第三步:使用对象
- 第四步:手动析构 (关键!)
- 第五步:释放"生肉" (如果有必要)
- [4\. 完整代码示例](#4. 完整代码示例)
- [5\. 常见陷阱与注意事项](#5. 常见陷阱与注意事项)
- [6\. 为什么要这么麻烦?(应用场景)](#6. 为什么要这么麻烦?(应用场景))
- [4.6 常见面试题与坑](#4.6 常见面试题与坑)
-
- [1\. `delete` 和 `free` 的区别?](#1.
delete和free的区别?) - [2\. 构造函数抛出异常会发生什么?](#2. 构造函数抛出异常会发生什么?)
- [1\. `delete` 和 `free` 的区别?](#1.
- 第四章总结
- [第五章:new 和 delete 的底层实现原理](#第五章:new 和 delete 的底层实现原理)
-
- [5.1 new 表达式的完全拆解](#5.1 new 表达式的完全拆解)
- [5.2 delete 表达式的完全拆解](#5.2 delete 表达式的完全拆解)
- [5.3 异常安全机制](#5.3 异常安全机制)
- 第五章总结
前言
本文介绍C和C++的内存管理相关内容
(【由浅入深】是一个系列文章,它记录了我个人作为一个小白,在学习c++技术开发方向计相关知识过程中的笔记,欢迎各位彭于晏刘亦菲从中指出我的错误并且与我共同学习进步,作为该系列的第三部曲-c++,大部分知识会根据本人所学和我的助手------通义,gimini等以及合并网络上所找到的相关资料进行核实编写,每一篇文章都可能会因为一些错误在后续时间增删改查,因为该系列会按照我在互联网中的学习笔记形式编写,我会使用绝大多数人使用的讲解顺序编写,所以基础框架和大部分内容案例会与他人一样,基础知识不会过于详细讲述)
第一章:C/C++ 内存分布详解
在 C/C++ 程序设计中,我们讨论的"内存"通常指的是虚拟地址空间(Virtual Address Space)。操作系统为每一个正在运行的进程提供了一个独立的、连续的虚拟地址空间。
以 32 位系统为例,寻址空间为 2 32 2^{32} 232,即 4GB。这 4GB 空间被严格划分为几个特定的区域,从低地址 到高地址依次分布。
1. 内存分布全景图
我们将内存划分为以下几个核心区域(按地址从低到高排列):
- 代码段 (Code Segment / Text Segment)
- 数据段 (Data Segment / Initialized Data)
- BSS 段 (BSS Segment / Uninitialized Data)
- 堆区 (Heap)
- 共享区/文件映射区 (Memory Mapping Segment)
- 栈区 (Stack)
- 内核空间 (Kernel Space)
text
内存地址 (Address) 内存区域 (Memory Segment)
================== =========================
0xFFFFFFFF (4GB) +-----------------------------------------+
| |
高地址 | 内核空间 | ⛔️ 用户代码不可访问
(High) | (Kernel Space) | (操作系统的地盘)
| |
0xC0000000 (3GB) +-----------------------------------------+ <--- 用户空间分界线
| |
| 栈区 | 📥 局部变量、函数参数
| (Stack) | (编译器自动管理)
| | |
| v |
| (向下生长) |
| |
| [文件映射区 / 共享库] | 📚 动态链接库(.so/.dll)
| (Memory Mapping Segment) |
| |
| (向上生长) |
| ^ |
| | |
| 堆区 | 🏗️ new/malloc 分配
| (Heap) | (程序员手动管理)
| |
+-----------------------------------------+
| 未初始化数据段 (.bss) | 📦 全局/静态变量 (无初值)
+-----------------------------------------+
| 已初始化数据段 (.data) | 📦 全局/静态变量 (有初值)
+-----------------------------------------+
| 代码段 | 📜 二进制指令
| (Text Segment) | 🔒 只读常量 ("hello")
+-----------------------------------------+
低地址 | 受保护/保留区 | ☠️ 空指针(nullptr)指向这里
(Low) | (Reserved) | (访问即崩溃)
0x00000000 +-----------------------------------------+ 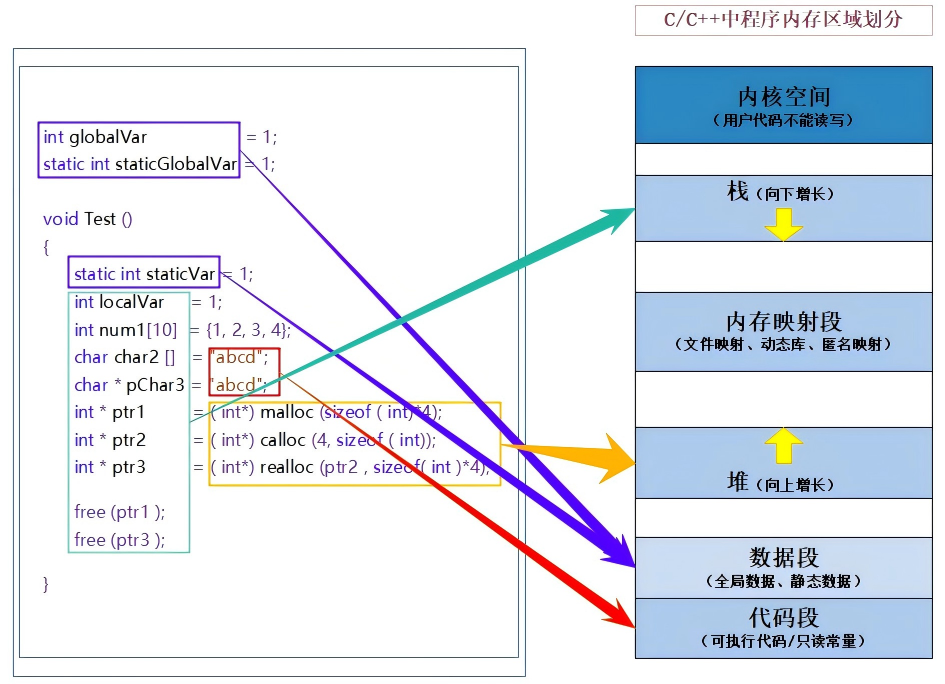
2. 各区域详细剖析
2.1 内核空间
- 位置:最高地址部分(在 32 位系统中,通常是顶部的 1GB)。
- 作用:也就是操作系统内核代码运行的地方。包含系统调用表、页表、内核栈等。
- 权限 :用户代码无法直接读写该区域。如果你尝试访问(例如空指针解引用通常指向低地址,但野指针可能指向这里),操作系统会抛出异常,导致程序崩溃。
2.2 栈区 (Stack)
- 位置 :用户空间的较高地址处,向下增长(向低地址方向延伸)。
- 存储内容 :
- 非静态局部变量:函数内部定义的普通变量。
- 函数参数:调用函数时传递的参数。
- 函数调用信息:栈帧(Stack Frame),包括返回地址、寄存器状态等。
- 管理方式 :自动管理。由编译器自动分配和释放。函数进入时压栈,函数退出时弹栈。
- 特点 :
- 效率极高 :基于 CPU 的
push/pop指令,分配内存仅仅是移动栈指针(ESP/RSP)。 - 空间有限 :栈的大小通常较小(Linux 下默认通常是 8MB,Windows 下默认 1MB)。这也是为什么递归过深 或在栈上开辟超大数组 会导致
Stack Overflow(栈溢出)。
- 效率极高 :基于 CPU 的
2.3 共享区 / 文件映射区
- 位置:位于堆和栈之间。
- 作用 :
- 加载动态链接库(.dll / .so)。
- 用于
mmap系统调用实现的共享内存。 - 高效的文件读写映射。
2.4 堆区 (Heap)
- 位置 :位于数据段之上,向上增长(向高地址方向延伸)。
- 存储内容 :程序运行期间动态分配 的内存。
- C 语言:
malloc,calloc,realloc - C++:
new
- C 语言:
- 管理方式 :手动管理 。必须由程序员显式释放(
free/delete),否则会导致内存泄漏 (Memory Leak)。 - 特点 :
- 空间巨大:受限于虚拟内存大小,可以申请很大的空间。
- 效率较低 :分配时需要在堆管理器中查找合适的空闲块,可能涉及系统调用,容易产生内存碎片。
2.5 数据段 (Data Segment)
这一区域通常包含两个部分,用于存储全局变量 和静态变量 (static) 。它们的生命周期是整个程序运行期间。
A. 已初始化数据段 (.data)
- 存储内容 :已初始化 且初值不为 0 的全局变量和静态变量。
- 示例 :
int g_val = 10;或static int s_val = 5;
B. 未初始化数据段 (.bss)
- 全称:Block Started by Symbol(历史遗留术语)。
- 存储内容 :未初始化 ,或初始化为 0 的全局变量和静态变量。
- 特点 :在可执行文件中,.bss 段不占用实际磁盘空间(只需要记录大小即可),程序加载运行时,操作系统会将这块内存清零。
- 示例 :
int g_val;(默认为0)
2.6 代码段 (Code Segment / Text Segment)
- 位置:最底层的用户空间地址。
- 存储内容 :
- 二进制代码:编译器生成的机器指令(函数的执行逻辑)。
- 只读常量 :例如字符串字面量
"Hello World",const修饰的全局变量(视编译器优化而定)。
- 权限 :只读 (Read-Only) 。防止程序在运行时意外修改指令。如果尝试修改字符串字面量(例如
char* p = "abc"; p[0] = 'x';),会触发段错误。
3. 深度对比:栈 (Stack) vs 堆 (Heap)
这是面试和实际开发中最核心的区别:
| 特性 | 栈 (Stack) | 堆 (Heap) |
|---|---|---|
| 分配方式 | 编译器自动分配释放 | 程序员手动分配释放 (new/delete) |
| 生长方向 | 向低地址生长 (Down) | 向高地址生长 (Up) |
| 空间大小 | 小 (MB 级别) | 大 (GB 级别,受虚存限制) |
| 分配效率 | 极高 (寄存器操作) | 较低 (算法查找,可能涉及系统调用) |
| 碎片问题 | 无 (先进后出) | 有 (频繁分配释放导致外部碎片) |
| 内容 | 局部变量、函数上下文 | 动态对象、大型数据结构 |
4. 实战代码解析
下面这段代码清晰地展示了变量在内存中的实际分布位置:
cpp
#include <stdio.h>
#include <stdlib.h> // 提供 malloc 和 free
// 1. 全局区 (Global/Static)
int g_val = 100; // .data (已初始化数据段)
int g_uninit_val; // .bss (未初始化数据段,自动清零)
static int s_val = 200; // .data (静态变量,生命周期伴随整个程序)
void func() {
// 2. 栈区 (Stack) -> 局部变量
int a = 10;
// 3. 堆区 (Heap) -> 动态分配
// 区别点:C语言使用 malloc 申请内存,返回 void* 需要强转
// 注意:ptr 这个指针变量本身在栈上,它存的值是堆内存的地址
int* ptr = (int*)malloc(sizeof(int));
if (ptr != NULL) {
*ptr = 30; // 给堆上的内存赋值
}
// 4. 代码段/常量区 (Text/RO Data)
// str_ptr 是一个局部指针(在栈上),指向常量区只读字符串 "Hello"
const char* str_ptr = "Hello";
// 【对比特例】栈上的字符数组
// str_arr 在栈上分配空间,并将 "World" 从常量区**拷贝**过来
// 所以这里的地址是栈地址,且内容可修改
char str_arr[] = "World";
// 5. 打印地址验证 (通常顺序:代码段 < 数据段 < 堆 < ... < 栈)
printf("=== 内存地址分布 (由低到高) ===\n");
printf("[代码段] 函数地址: %p\n", func);
printf("[常量区] 字符串字面量: %p (指向 \"Hello\")\n", str_ptr);
printf("[数据段] 全局变量 g_val: %p\n", &g_val);
printf("[数据段] 静态变量 s_val: %p\n", &s_val);
printf("[BSS段 ] 未初始化全局: %p\n", &g_uninit_val);
printf("[堆区 ] malloc分配: %p (ptr指向的实体)\n", ptr);
printf("\n--- 巨大跨度 (未映射区域) ---\n\n");
printf("[栈区 ] 局部变量 a: %p\n", &a);
printf("[栈区 ] 字符数组: %p (str_arr本身)\n", str_arr);
printf("[栈区 ] 指针变量 ptr: %p (ptr本身)\n", &ptr);
// 释放堆内存
free(ptr);
}
int main() {
func();
return 0;
}预期输出分析 (地址大小趋势)
运行上述代码,你通常会观察到地址数值的大小关系如下:
代码区 < 常量区 < 数据段 < 堆区 < ...巨大跨度... < 栈区
关键点解析
- 指针与实体的区别 :
int* ptr = (int*)malloc(sizeof(int));ptr是一个变量,存储在栈上。(int*)malloc(sizeof(int))分配的内存块,位于堆上。ptr内部存的值,就是堆上那块内存的地址。
- const char* :
const char* str = "abc";- 字符串
"abc"存储在代码段(常量区),它是只读的。 - 如果写成
char str[] = "abc";,那么"abc"会被拷贝到栈数组中,此时它是可修改的。(即"abc"本来是在常量区,但会被拷贝栈区中str所在位置)
- 字符串
补充:cons声明的变量位置
const不能决定存储位置。const 只是一个编译期的类型限定符(Type Qualifier),它主要约束代码层面的"不可修改性",而不能直接决定变量在内存中的物理存储位置。变量存储在哪里,主要由它的生命周期和作用域决定,而不是 const。
这个问题没有唯一的答案。const 只是给变量打上了一个"只读 "的标签,但它并不决定变量存在哪里。
决定变量存储位置的,依然是它的生命周期(是全局的还是局部的)。
下面是详细的分布情况:
1. 局部 const 变量
📍 位置:栈区 (Stack)
当你写在函数内部时:
c
void func() {
const int a = 10;
}- 本质 :它和普通的
int a = 10一模一样,都存储在栈上。 - 区别 :
const在这里只是给编译器 看的。编译器会帮你检查,如果你写了a = 20,编译时就会报错。 - 破解:因为在栈上(栈内存默认是可读写的),如果你用指针强制转换去改它,在 C 语言里往往能改成功(但这属于流氓行为)。
2. 全局 const 变量
📍 位置:常量区 (.rodata)
当你写在函数外部时:
c
const int g_a = 100;
int main() { ... }- 本质 :由于是全局的,且承诺不修改,编译器会将它放入只读数据段 (.rodata)。
- 区别 :这是操作系统/硬件层面 的保护。这块内存页被标记为
Read Only。 - 破解:如果你用指针强制去改它,程序会直接崩溃(Segmentation Fault),因为你试图写入受保护的内存。
3. static 修饰的 const
📍 位置:常量区 (.rodata)
无论是在函数内还是函数外:
c
void func() {
static const int b = 20;
}- 本质 :
static决定了它存在静态数据区,const决定了它是只读的。两者结合,通常会放进.rodata。
4. 字符串字面量 (特殊)
📍 位置:常量区 (.rodata)
c
const char* str = "Hello";- 注意这里有两个东西:
str指针变量本身 :如果是在函数里,它在栈上。"Hello"字符串实体 :这串字符存储在常量区。
5. 被编译器优化了 (常量折叠)
📍 位置:哪里都不在 (符号表/指令立即数)
c
const int WIDTH = 1920;
int x = WIDTH + 10;- 如果编译器发现你从未对
WIDTH取地址 (&WIDTH),它可能根本不会为WIDTH分配内存。 - 在生成的机器码里,
WIDTH直接被替换成了数字1920(立即数),嵌入在 CPU 的指令代码中。
总结一张表
| 你的代码写法 | 实际存储位置 | 物理属性 | 备注 |
|---|---|---|---|
void f() { const int a = 10; } |
栈 (Stack) | 可读写 | 编译器禁止你写,但内存本身没锁。 |
const int g_a = 10; (全局) |
常量区 (.rodata) | 只读 | 硬件保护,强行写会崩溃。 |
static const int s = 10; |
常量区 (.rodata) | 只读 | 同上。 |
"Hello World" (字符串) |
常量区 (.rodata) | 只读 | 试图修改会崩溃。 |
| (未取地址的简单常量) | 无 (寄存器/立即数) | 无 | 变成了指令的一部分。 |
第二章:C++ 内存管理详解
在上一章中,我们探讨了 C++ 内存分布的基础(栈、堆、数据段等)。在实际开发中,堆(Heap)内存的管理是最为复杂且容易出错的环节。
C++ 的 new 和 delete 操作符不仅仅是 C 语言中 malloc 和 free 的语法糖,它们承载了对象生命周期管理的核心职责。本章我们将把目光聚焦在"类型"上,对比内置类型与自定义类型在动态内存分配中的不同表现,特别是针对单个变量与数组的创建细节。
1. 内置类型的内存管理
内置类型主要指 int, char, double, float 以及指针等基础数据类型。对于这些类型,内存管理相对"纯粹",主要关注的是内存的分配与释放,不涉及复杂的构造与析构逻辑。
1.1 单个变量的申请与释放
对于单个内置类型变量,我们需要关注的是初始化问题。
cpp
void TestBuiltInSingle() {
// 1. 申请内存但不初始化
// 内存中的值是随机值(脏数据)
int* p1 = new int;
// 2. 申请内存并初始化
// 内存中的值为 10
int* p2 = new int(10);
// 3. 申请内存并进行默认初始化
// 内存中的值为 0
int* p3 = new int();
// 释放
delete p1;
delete p2;
delete p3;
}- 关键点 :
new int和new int()是有区别的。前者在堆上分配内存后不进行处理(随机值),后者会将内存清零。
1.2 数组(多个变量)的申请与释放
当我们需要动态创建一个内置类型的数组时:
cpp
void TestBuiltInArray() {
// 1. 申请 10 个 int 的数组,不初始化
// 此时 arr[0] ~ arr[9] 都是随机值
int* arr1 = new int[10];
// 2. 申请 10 个 int 的数组,并全部初始化为 0
int* arr2 = new int[10]();
// 3. (C++11) 列表初始化
// 前三个为 1, 2, 3,其余为 0
int* arr3 = new int[10]{1, 2, 3};
// 释放
// 严格遵循匹配原则,使用 delete[]
delete[] arr1;
delete[] arr2;
delete[] arr3;
}1.3 核心思考:内置类型混用 delete 和 delete[] 会怎样?
这是一个经典的面试题。对于内置类型 (如 int):
cpp
int* p = new int[10];
delete p; // 这样写会崩溃吗?- 结论 :在大多数现代编译器下,这通常不会崩溃,也不会造成明显的内存泄漏。
- 原因 :内置类型没有析构函数。当
delete p执行时,它只是释放了p指向的那块内存。因为不需要调用析构函数,编译器不需要知道数组具体的元素个数去遍历清理。 - 警示 :尽管可能不报错,但这属于Undefined Behavior (未定义行为) ,严禁在生产代码中使用。请始终坚持
new[]配对delete[]。
2. 自定义类型的内存管理
一旦涉及到类(Class),情况就发生了本质变化。new 不仅仅分配内存,还负责构造 ;delete 不仅仅释放内存,还负责析构。
假设我们要使用以下类:
cpp
class A {
public:
int _a;
A(int a = 0) : _a(a) {
std::cout << "A() Constructed: " << this << std::endl;
}
~A() {
std::cout << "~A() Destructed: " << this << std::endl;
}
};2.1 单个对象的申请与释放
cpp
void TestCustomSingle() {
// 1. 分配内存 -> 2. 调用构造函数
A* p = new A(10);
// 1. 调用析构函数 -> 2. 释放内存
delete p;
}- 底层动作 :
new A(10)等价于调用operator new分配sizeof(A)大小的字节,然后在该内存上调用A::A(10)。delete p等价于调用p->~A(),然后调用operator delete释放内存。
2.2 new初始化具体流程:
1. 直接初始化:new A(10) (主流)
流程: 堆内存分配 -> 匹配 A(int) -> 原地构造。
结论: 无临时对象,无拷贝。
2. 拷贝初始化:new A = 10 (少见)
这种写法看起来像是"先用 10 构造一个临时 A,再拷贝到堆上"。
C++17 之前:理论上确实存在"临时对象 + 移动构造/拷贝构造"的语义,但编译器通常会优化掉。
C++17 及以后:标准强制规定省略拷贝。此时 10 依然是被直接传递给堆上对象的构造函数。结果和第一种写法完全一样。
2.3 初始化方式
在使用 new 申请堆内存时,有没有括号 以及用什么括号,决定了对象里的成员变量是"随机值"还是"零值"。
主要分为以下几种方式,核心区别在于默认初始化(Default Initialization)与值初始化(Value Initialization)。
1. 默认初始化:new T (无括号)
这是最简单的写法,但对于没有构造函数的类型(如 int 或简单 struct),它也是最危险的。
- 语法 :
T* p = new T; - 行为 :
- 对于有显式构造函数的类:调用默认构造函数。
- 对于内置类型(POD) :不进行初始化。内存里原来是什么垃圾数据,现在就是什么。
cpp
struct A { int x; }; // 简单结构体(POD)
class B { public: B() { y = 10; } int y; }; // 有构造函数
A* p1 = new A; // p1->x 是随机值(垃圾值)!危险!
B* p2 = new B; // p2->y 是 10(调用了 B())
int* p3 = new int; // *p3 是随机值2. 值初始化:new T() (空括号)
加上空括号,表示你希望编译器帮你把内存"打扫干净"。
- 语法 :
T* p = new T(); - 行为 :
- 对于有显式构造函数的类:调用默认构造函数(效果同上)。
- 对于内置类型(POD) :进行零初始化(Zero Initialization)。内存会被清零。
cpp
A* p1 = new A(); // p1->x 必定是 0 (安全)
B* p2 = new B(); // p2->y 是 10 (同上)
int* p3 = new int(); // *p3 必定是 0总结 :如果你定义的类没有写构造函数,或者你在
newint/double,请务必加上(),否则你会得到随机值。
3. 直接初始化:new T(args) (圆括号传参)
这是最常见的带参构造方式。
- 语法 :
T* p = new T(a, b); - 行为 :直接寻找匹配参数列表
(a, b)的构造函数进行调用。
cpp
class C {
public:
C(int a) { val = a; }
int val;
};
C* p = new C(100); // 调用 C(int),val 为 1004. 列表初始化:new T{args} (花括号,C++11)
这是 C++11 引入的"统一初始化"语法,通常比圆括号更推荐。
- 语法 :
T* p = new T{a, b};(或空花括号new T{}等同于new T()) - 行为 :
- 优先匹配参数为
std::initializer_list的构造函数。 - 如果没有,则匹配普通构造函数。
- 对于聚合类(简单结构体):可以直接按顺序给成员赋值。
- 安全性 :禁止窄化转换 (Narrowing Conversion)。例如不允许把
double隐式转给int。
- 优先匹配参数为
cpp
struct Point { int x, y; };
Point* p1 = new Point{1, 2}; // C++11 特性:聚合初始化,x=1, y=2
// Point* p2 = new Point(1, 2); // 错误!旧语法不支持这样直接初始化结构体,除非你写了构造函数
int* p3 = new int{5}; // OK
// int* p4 = new int{5.5}; // 编译报错!花括号禁止数据截断(double->int)5. 数组的初始化
对于数组,规则也是类似的,括号决定了是否清零。
new T[N]:默认初始化。如果是int数组,里面全是随机值。new T[N]()或new T[N]{}:值初始化。如果是int数组,里面全是 0。new T[N]{a, b, c}:(C++11) 前几个元素用 a,b,c 初始化,剩下的元素补 0。
cpp
int* arr1 = new int[5]; // [随机, 随机, 随机, 随机, 随机]
int* arr2 = new int[5](); // [0, 0, 0, 0, 0]
int* arr3 = new int[5]{1,2};// [1, 2, 0, 0, 0]注意:new A3 = { 1, 2, 3 }; ❌ 错误 new 后面不能接 =
new 运算符被设计为直接在分配的内存上构造对象,不涉及"创建一个临时列表对象再拷贝过去"的概念。因此,它强制使用直接初始化的语法(即不带 = 的大括号)。
快速一览表
| 写法 | 对 class (有构造函数) |
对 struct / int (无构造函数) |
|---|---|---|
new T |
调用构造函数 | 随机值 (未初始化) ⚠️ |
new T() |
调用构造函数 | 清零 (Zero Init) ✅ |
new T(x) |
调用构造函数 T(x) |
初始化为 x |
new T{x} |
调用构造函数 / 聚合初始化 | 初始化为 x (禁止截断) |
建议: 除非你有极端的性能需求且确定后续会立马覆盖内存,否则对于简单类型(int, struct),习惯性加上 () 或 {} 是个好习惯。
2.4 对象数组的申请与释放
这是本章的重难点。
cpp
void TestCustomArray() {
// 申请包含 10 个 A 对象的数组
// 注意:这里必须要求 A 有默认构造函数!
A* arr = new A[10];
// 释放
delete[] arr;
}2.4.1 为什么必须要有默认构造函数?
当我们执行 new A[10] 时,编译器需要连续构造 10 个对象。编译器无法给这 10 个对象分别传递不同的参数,因此它默认调用无参构造函数 (或全缺省构造函数)。如果类 A 没有默认构造函数,代码将无法通过编译。
2.4.2 delete[] 的魔力:Cookie 机制
对于自定义类型,严禁 混用 delete 和 delete[]。
cpp
A* arr = new A[10];
delete arr; // 极度危险!!程序崩溃或未定义行为为什么 delete[] 知道要调用 10 次析构函数?
当编译器检测到你要 new 一个有析构函数 的自定义类型数组时,它会在分配的内存块头部多分配几个字节(通常是 4 字节或 8 字节),用来存储数组的元素个数 。这被称为 Cookie。
内存布局示意图:
text
[ Cookie (记录数量: 10) ] [ 对象 A[0] ] [ 对象 A[1] ] ... [ 对象 A[9] ]
^ ^
| |
真正分配的起始地址 返回给用户的指针 (arr)-
当你调用
delete[] arr时:- 系统会"向后看"(指针偏移),读取 Cookie 中的数字(比如 10)。
- 循环调用 10 次析构函数。
- 最后释放整块内存(包含 Cookie)。
-
如果你错误地调用
delete arr:- 系统认为这只是一个单个对象。
- 它只调用一次
arr[0]的析构函数(导致剩下 9 个对象资源泄漏)。 - 然后试图释放内存。但
free需要的是内存块的首地址 。由于arr跳过了 Cookie,传给free的地址是不对齐或错误的(不是真正的起始位置),直接导致**Heap Corruption(堆破坏)**或程序崩溃。
补充:Cookie 机制只有在显示写析构情况下才开?
Cookie(记录数组元素个数的额外空间)通常只在"类型拥有非平凡析构函数(就是编译器认为"这个对象死的时候,必须执行一些代码来善后"的情况。)" 时才会存在。 (人话:只有当类既没有显式析构函数,也没有包含带析构函数的成员变量时,才不会多开那 4 个字节。你显式定义了析构函数,哪怕函数体是空的,只要你写了,编译器就认为它是非平凡的。)
下面是详细的底层剖析:
1. 核心规则:有没有析构函数是关键
编译器决定是否"多开几个字节"来存数组长度(Cookie),依据是:delete[] 时是否需要循环调用析构函数。
情况 A:内置类型(int, float)或 无自定义析构函数的结构体
- 行为 :编译器不会多开空间存 Cookie。
- 原因 :因为没有析构函数需要调用。
delete[] p的任务仅仅是把这块内存归还给操作系统。内存分配器(如malloc的底层实现)本身就已经记录了这块内存块的大小(Size),所以 C++ 运行时不需要额外记录"里面有几个 int"。 - 结果 :
new int[10]请求多少内存,就分配多少(加上 malloc 自身的头部开销,但用户指针前没有 C++ 的 Cookie)。
情况 B:有自定义析构函数的类
- 行为 :编译器会在数组头部多开空间(Cookie)。
- 原因 :
delete[] p时,程序必须知道"我要调用多少次析构函数"。内存分配器只知道这块内存是 100 字节,但它不知道这代表 10 个对象还是 20 个对象。因此,C++ 必须自己找个地方把"对象的个数"记下来。 - 结果 :返回给你的指针,实际上是偏移过的。
2. Cookie开的字节数
在现代开发中:
- 32 位系统 (x86) :Cookie 通常是 4 字节 (
size_t的大小)。 - 64 位系统 (x64) :Cookie 通常是 8 字节(或者是为了内存对齐而更大的填充)。
此外,内存对齐(Alignment) 也会影响这个"多开的空间"具体看起来是多大。编译器为了保证对象的地址是高效对齐的(比如 16 字节对齐),可能会在 Cookie 和第一个对象之间填充 Padding。
3. 代码验证:亲眼看看"地址偏移"
我们可以通过打印指针地址来验证这个机制。
cpp
#include <iostream>
using namespace std;
// 类A:没有显式析构函数(编译器认为它是 Trivial 的)
class A {
public:
int _a;
A() : _a(0) {}
};
// 类B:有显式析构函数
class B {
public:
int _b;
B() : _b(0) {}
~B() { cout << "~B" << endl; } // 关键在于这个析构函数
};
int main() {
// ---- 测试 A (无析构) ----
A* pA = new A[10];
// 实际上分配的起始地址 vs 返回的地址
// 既然没有 Cookie,理论上 new 返回的地址就是内存块的起始地址
// 这里的验证比较隐晦,我们通常通过看 delete 的行为或者调试器的内存窗口来确认
// ---- 测试 B (有析构) ----
B* pB = new B[10];
// 我们做一个危险的实验来寻找 Cookie
// 获取 pB 之前的那个整数
size_t* cookie_ptr = (size_t*)pB;
cookie_ptr--; // 指针前移一位(在64位下前移8字节,32位下前移4字节)
cout << "B requested size: 10" << endl;
cout << "Value in Cookie: " << *cookie_ptr << endl; // 这里应该打印出 10
delete[] pA;
delete[] pB;
return 0;
}运行结果(在 64 位环境下):
text
B requested size: 10
Value in Cookie: 10你会发现,就在 pB 指针的前面(前移 8 字节),确实藏着一个数字 10。如果你对 pA 做同样的操作,前面通常是乱码或 malloc 的调试信息,而不是对象个数。
4. 总结图解
假设 32 位系统,new T[3]
-
T是int(无析构):text[ int ][ int ][ int ] ^ p (返回给用户的地址) -
T是MyClass(有析构):text[ 3 ][ MyObj ][ MyObj ][ MyObj ] ^ ^ | p (返回给用户的地址) | 真正的内存起始地址 (传给 free 的是这里)
这也是为什么有析构函数的数组混用 delete(而不是 delete[])会崩溃 的根本原因:delete p 以为 p 就是起始地址,直接把它传给 free,但实际上 p 是偏移过的,并非通过 malloc 分配出的首地址,导致堆损坏(Heap Corruption)。
3. 总结与对比表
为了方便记忆,我们将本章内容总结如下:
| 特性 | 内置类型 (int, double...) | 自定义类型 (Class/Struct) |
|---|---|---|
new T |
只分配内存,值为随机(除非 new T()) |
分配内存 + 调用 1 次构造函数 |
new T[N] |
分配 N * sizeof(T) 内存 |
分配内存 + 调用 N 次默认构造函数 |
delete ptr |
释放内存 | 调用 1 次析构函数 + 释放内存 |
delete[] ptr |
释放内存 | 调用 N 次析构函数 + 释放内存 |
| Cookie 机制 | 通常不需要(取决于编译器,无析构则不需要) | 必须有(用于记录 N,以便循环析构) |
| 混用后果 | new[] -> delete 通常无害但不规范 |
new[] -> delete 崩溃或内存泄漏 |
第四章:内存分配底层------operator new 与 operator delete
4.1 核心概念区分:Expression vs Function
首先必须厘清两个极其容易混淆的概念:
- new 表达式 (new expression) :
这是我们在代码里直接写的A* p = new A(10);。它是一个不可重载的关键字。 - operator new 函数 :
这是一个可以重载的函数,通常声明为void* operator new(size_t size)。它的唯一任务就是申请原始内存
它们的关系
当你写下 new A() 时,编译器实际上执行了以下逻辑(伪代码):
cpp
// 1. 调用 operator new 申请生肉(内存)
void* raw_mem = operator new(sizeof(A));
// 2. 在生肉上调用构造函数(烹饪)
call_constructor(raw_mem);
// 3. 返回指针
A* p = static_cast<A*>(raw_mem);这一章我们重点讨论的是第 1 步:那个负责"找系统要内存"的函数。
4.2 全局 operator new 与 operator delete
C++ 标准库提供了全局的默认实现。如果你不自己写,编译器就会用这些默认版本。
1. 全局 operator new
它的底层实现通常就是调用 C 语言的 malloc。
cpp
void* operator new(size_t size) {
if (size == 0) size = 1; // C++标准规定,申请0字节也要返回有效地址
while (true) {
// 尝试分配内存
void* ptr = malloc(size);
if (ptr) return ptr;
// 如果分配失败,尝试调用 new_handler 处理(比如释放一点缓存)
std::new_handler global_handler = std::get_new_handler();
if (global_handler) {
global_handler();
} else {
// 实在没办法了,抛出异常
throw std::bad_alloc();
}
}
}2. 全局 operator delete
它的底层实现通常就是调用 free。
cpp
void operator delete(void* ptr) noexcept {
if (ptr == nullptr) return; // 保证 delete 空指针是安全的
free(ptr);
}4.3 类专属重载
这是这一章的重头戏。你可以为一个特定的类重写这两个函数。
为什么要做这个?
- 性能优化 :针对特定大小的对象使用内存池,避免频繁调用系统的
malloc/free。 - 调试监控:统计某个类到底创建了多少个对象,有没有内存泄漏。
- 特殊内存:强制对象分配在共享内存或显存中。
语法规则
这两个函数在类中隐式是静态的 (static) ,写不写 static 关键字都可以。因为调用它们的时候,对象还没产生(或者即将销毁),所以无法依赖 this 指针。
完整示例:编写一个具有内存监控功能的类
cpp
#include <iostream>
#include <new>
class Data {
public:
int m_val;
Data(int v) : m_val(v) {
std::cout << " [Construct] Data constructed with " << v << std::endl;
}
~Data() {
std::cout << " [Destruct] Data destroyed" << std::endl;
}
// 重载 operator new
// 编译器会自动计算类的大小并传给 size
static void* operator new(size_t size) {
std::cout << "1. [operator new] Allocating " << size << " bytes" << std::endl;
// 这里我们可以自定义分配策略,简单起见我们调用全局的 new
return ::operator new(size);
}
// 重载 operator delete
static void operator delete(void* p) {
std::cout << "3. [operator delete] Freeing memory" << std::endl;
// 释放内存
::operator delete(p);
}
};
int main() {
std::cout << "=== Start ===" << std::endl;
// 触发 operator new -> 构造函数
Data* p = new Data(100);
std::cout << "=== Using Object ===" << std::endl;
// 触发 析构函数 -> operator delete
delete p;
std::cout << "=== End ===" << std::endl;
return 0;
}运行结果:
text
=== Start ===
1. [operator new] Allocating 4 bytes
[Construct] Data constructed with 100
=== Using Object ===
[Destruct] Data destroyed
3. [operator delete] Freeing memory
=== End ===4.4 数组版本:operator new\[\] 与 operator delete\[\]
当你使用 new Data[10] 时,调用的不是 operator new,而是 operator new[](Vector New)。
- operator new\[\]:负责申请"数组总大小 + 可能的额外空间(用于记录数组长度)"。
- operator delete\[\]:负责释放这块内存。
注意: 如果你重载了 operator new,通常也应该重载 operator new[],否则创建数组时会回退到使用全局的分配函数,导致你的内存池或监控失效。
cpp
static void* operator new[](size_t size) {
std::cout << "[Array new] Allocating " << size << " bytes" << std::endl;
return ::operator new(size);
}
static void operator delete[](void* p) {
std::cout << "[Array delete] Freeing array" << std::endl;
::operator delete(p);
}4.5 Placement New (定位 new)
通常我们在 C++ 中使用 new 时,是"申请内存"和"构造对象"一把抓。而 Placement New 允许我们将这两步完全分离。它的核心作用是:在已经分配好的内存块上,强行调用构造函数初始化对象。
5.5 深入详解:定位 new (Placement New)
1. 核心定义与头文件
普通 new 向操作系统申请空间,而 Placement New 只是在"借尸还魂"------利用已有的空间。
-
头文件 :必须包含
<new>cpp#include <new> -
底层实现 :
标准库中它的实现极其简单,就是一个"透传"函数,不做任何内存申请操作:cpp// C++ 标准库源码简化版 void* operator new(size_t, void* ptr) noexcept { return ptr; // 直接返回传入的地址 }
2. 具体语法规则
基本语法格式如下:
cpp
new (address) Type(arguments);- address : 一个指针,指向一块已经分配好的、足够容纳该对象的内存(通常是
void*或char*)。 - Type: 要构造的类型。
- arguments: 传递给构造函数的参数列表。
3. 标准使用流程 (SOP)
使用 Placement New 必须严格遵守 "五步走" 流程,任何一步出错都可能导致内存腐烂或崩溃。
第一步:准备"生肉" (Raw Memory)
你需要先有一块内存。来源可以是栈、堆(malloc/new char\[\])、或者特殊的硬件地址。
cpp
// 例子:在栈上准备一块缓冲区(也可以是堆)
char memory_pool[sizeof(Complex)]; 第二步:调用 Placement New
在这块内存上构建对象。
cpp
Complex* pc = new (memory_pool) Complex(1.5, 2.5);此时编译器做了什么?
- 调用
operator new(sizeof(Complex), memory_pool)-> 返回memory_pool地址。- 在这个地址上执行
Complex::Complex(1.5, 2.5)。- 将地址赋值给
pc。
第三步:使用对象
此时 pc 是一个指向有效对象的指针,可以正常使用。
cpp
std::cout << pc->real() << std::endl;第四步:手动析构 (关键!)
这是与普通 new 最大的不同。因为内存不是 Placement New 分配的,所以不能使用 delete pc。必须显式调用析构函数。
cpp
pc->~Complex(); // 必须手动调用!第五步:释放"生肉" (如果有必要)
如果第一步的内存是申请来的(比如用 malloc 或 new char[]),现在才轮到释放它。如果是在栈上(如本例),则无需处理。
4. 完整代码示例
cpp
#include <iostream>
#include <new> // 必须包含
#include <vector>
class User {
public:
int id;
User(int i) : id(i) { std::cout << "Construct User " << id << std::endl; }
~User() { std::cout << "Destruct User " << id << std::endl; }
};
int main() {
// 1. 准备一块足够大的内存(比如模拟内存池)
// 注意:这里分配的是 char 数组,不是 User 对象
char* buffer = new char[sizeof(User) * 2];
// 2. 使用 Placement New 在 buffer 的不同位置构造对象
User* u1 = new (buffer) User(1); // 在起始位置构造
User* u2 = new (buffer + sizeof(User)) User(2); // 在偏移位置构造
// 3. 使用对象
std::cout << "u1 id: " << u1->id << std::endl;
std::cout << "u2 id: " << u2->id << std::endl;
// 4. 析构对象(必须手动调用!)
// delete u1; // 错误!!!会导致 buffer 被释放,而 buffer 是 char数组,内存布局不同,会崩溃
u2->~User();
u1->~User();
// 5. 释放原始内存
delete[] buffer;
std::cout << "Raw memory freed." << std::endl;
return 0;
}5. 常见陷阱与注意事项
- 内存对齐 (Alignment) :
如果你提供的 buffer 地址没有对齐(例如int通常需要 4 字节对齐),在某些 CPU 架构上会导致崩溃或性能下降。C++11 提供了alignas和std::aligned_storage来辅助解决这个问题。 - 严禁使用 delete :
如果你对 Placement New 返回的指针调用delete,编译器会尝试释放这块内存。但如果这块内存是栈内存、静态区内存或者只是大内存块的一部分,程序就会崩溃。 - 覆盖风险 :
如果在同一个地址重复调用 Placement New 而没有先析构之前的对象,前一个对象持有的资源(如锁、文件句柄)将无法释放,导致资源泄漏。
6. 为什么要这么麻烦?(应用场景)
既然这么危险,为什么还要用?
- 构建内存池 (Memory Pool) :这是最高频的用法。一次性申请一大块内存(减少
malloc开销),然后用 Placement New 快速在池中切割分配对象。游戏引擎几乎都这么做。 - 共享内存 (Shared Memory):在进程间共享内存区域构建复杂的 C++ 对象。
- STL 容器底层 :
std::vector的push_back扩容时,需要在新内存上拷贝构造旧元素,底层就是用的 Placement New。
4.6 常见面试题与坑
1. delete 和 free 的区别?
free是 C 语言函数,只释放内存,不管析构。delete是 C++ 操作符,先调用析构函数 ,再调用 operator delete 释放内存。
2. 构造函数抛出异常会发生什么?
如果在 new Data() 的过程中,operator new 成功申请了内存,但随后的构造函数抛出了异常:
- C++ 运行时会自动捕获这个异常。
- 它会自动调用匹配的
operator delete归还刚才申请的内存(防止内存泄漏)。 - 然后继续向外层抛出异常。
这就是为什么重载new时通常也要重载delete,即使你不手动调用它,异常处理机制也可能调用它。
第四章总结
- 分工明确 :
operator new只管分地(分配字节),构造函数负责盖楼(初始化),new表达式是指挥官。 - 可定制 :通过在类中重载
operator new/delete,我们可以接管对象的内存管理权(内存池的核心原理)。 - 底层原理 :全局的
operator new基本等于malloc+ 异常处理。 - Placement New:是唯一一个不分配内存的 new,允许我们在指定的地址上"原地构造"对象。
第五章:new 和 delete 的底层实现原理
在第四章中,我们知道了 operator new 和 operator delete 只是类似于 malloc 和 free 的内存搬运工。
本章我们将揭开 C++ 编译器的面纱,看看当我们写下 new A() 这样简单的代码时,编译器在幕后到底生成了什么样的汇编逻辑。
5.1 new 表达式的完全拆解
当我们写出如下代码:
cpp
Complex* pc = new Complex(1, 2);编译器会将其翻译为大约如下的伪代码(注意:这是编译器内部视角的逻辑,普通 C++ 代码不能直接这样调用构造函数):
编译器背后的三步走:
-
内存分配 (Call operator new)
调用第四章讲过的函数来申请原始内存。
cppvoid* mem = operator new(sizeof(Complex)); -
类型转换 (Type Casting)
将
void*指针转换为目标类型的指针。cppComplex* pc = static_cast<Complex*>(mem); -
对象构造 (Call Constructor)
这是最关键的一步。编译器会在
pc指向的内存地址上,直接调用构造函数。在 C++ 层面这通常通过 Placement New 的机制实现。cpppc->Complex::Complex(1, 2); // 伪代码:只有编译器能这样直接调用构造函数
总结 :new 表达式 = operator new (买地) + Placement New (盖楼)。
5.2 delete 表达式的完全拆解
当我们执行:
cpp
delete pc;编译器的操作顺序正好与 new 相反:
编译器背后的两步走:
-
对象析构
首先调用析构函数,清理对象持有的资源(如关闭文件、释放对象内部的指针等)。此时内存本身还是有效的,只是对象逻辑上结束了。
cppif (pc != nullptr) { pc->~Complex(); } -
内存释放
调用库函数释放那块原始内存。
cppoperator delete(pc);
5.3 异常安全机制
如果在 new 的过程中,内存分配成功了,但是构造函数抛出了异常,会发生什么?
如果不做处理,这块刚申请的内存就会永久丢失(泄漏),因为指针还没有赋值给变量,用户无法手动 delete。
C++ 编译器为 new 表达式生成了类似这样的保护代码:
cpp
// 编译器的各种 try-catch 魔法
void* mem = operator new(sizeof(Complex));
try {
// 在 mem 上调用构造函数
new (mem) Complex(1, 2);
} catch (...) {
// 哎呀,构造函数抛异常了!
// 此时 mem 已经分配,必须收回
operator delete(mem);
// 继续向外抛出异常通知用户
throw;
}结论 :C++ 的 new 操作符是强异常安全的。如果构造失败,它保证负责清理掉已经申请的生肉。
第五章总结
- new 表达式 是一个组合拳:先调
operator new分配内存,再调构造函数初始化。 - delete 表达式 是逆向组合拳:先调析构函数清理逻辑,再调
operator delete释放内存。 - Cookie 机制 :
new[]数组时,编译器会在头部多分配空间记录元素个数。这是delete[]能够正确工作的关键。 - 生死攸关 :严禁
new[]和delete混用,否则会导致析构不全和指针地址错误(Crash)。 - 异常保护 :
new内部自带 try-catch,构造失败会自动回滚内存分配。