文章根据沉浸式翻译技专家陈琦在 Databend Meeup 上海站分享总结和思考构建。 通过本次活动也让我初步去理解 AI 长记忆体的实现及用途。 陈琦分享属于一个比较硬核的技术分享,所以在回顾这个 PPT 时,我在陈琦分享的思路的基础上长了一些案例,来帮助读者更容易理解这个实践。
沉浸式翻译(Immersive Translate),作为 AI 翻译领域的头部产品,拥有近千万用户。在 Databend Meeup 上海站沉浸式翻译团队透露他们启起阶段是自我搭建一个HTAP库用于承接业务及数据分析,但面临运维和成本比较高的问题,特别是数据量越来越大,SSD 成本增加明显,陈琦作为开源社区的重度参与者也是早期关注到 Databend, 在和 Databend 团队沟通后,利用 Vector + Databend Task 构建数据摄入链路,整个用时3天实现从 HTAP 迁移到 Databend Cloud 上面,利用 Databend 按付费用,存算分离架构。大大降低了存储和计算成本。

沉浸式翻译在 Databend 上也实现业务从起步到千万级用户,活跃百万的平滑过渡。 当前沉浸式翻译也在进一步往 AI 方面: 低成本构建 AI 长记忆体的实践。接下来我们通过 Databend Meetup 上海站沉浸式翻译技术专家陈琦的分享进行一个回顾和系统化总结。
挑战:记忆系统的" 不可能三角 "
沉浸式翻译团队在构建记忆系统时,面临着三个相互制约的核心难题:

-
连续性 (Continuity) :用户期望 Agent 能记住 3 个月甚至更久之前的对话细节,而非仅限于当前的 Context Window。
-
成本 (Cost) :在 2C 免费模式下,将海量历史数据全部存入昂贵的向量数据库,成本将是不可承受之重。
-
复杂性 (Complexity) :记忆不仅仅是文本,还包含了用户的偏好(JSON)、知识图谱(Relational)以及多模态数据。
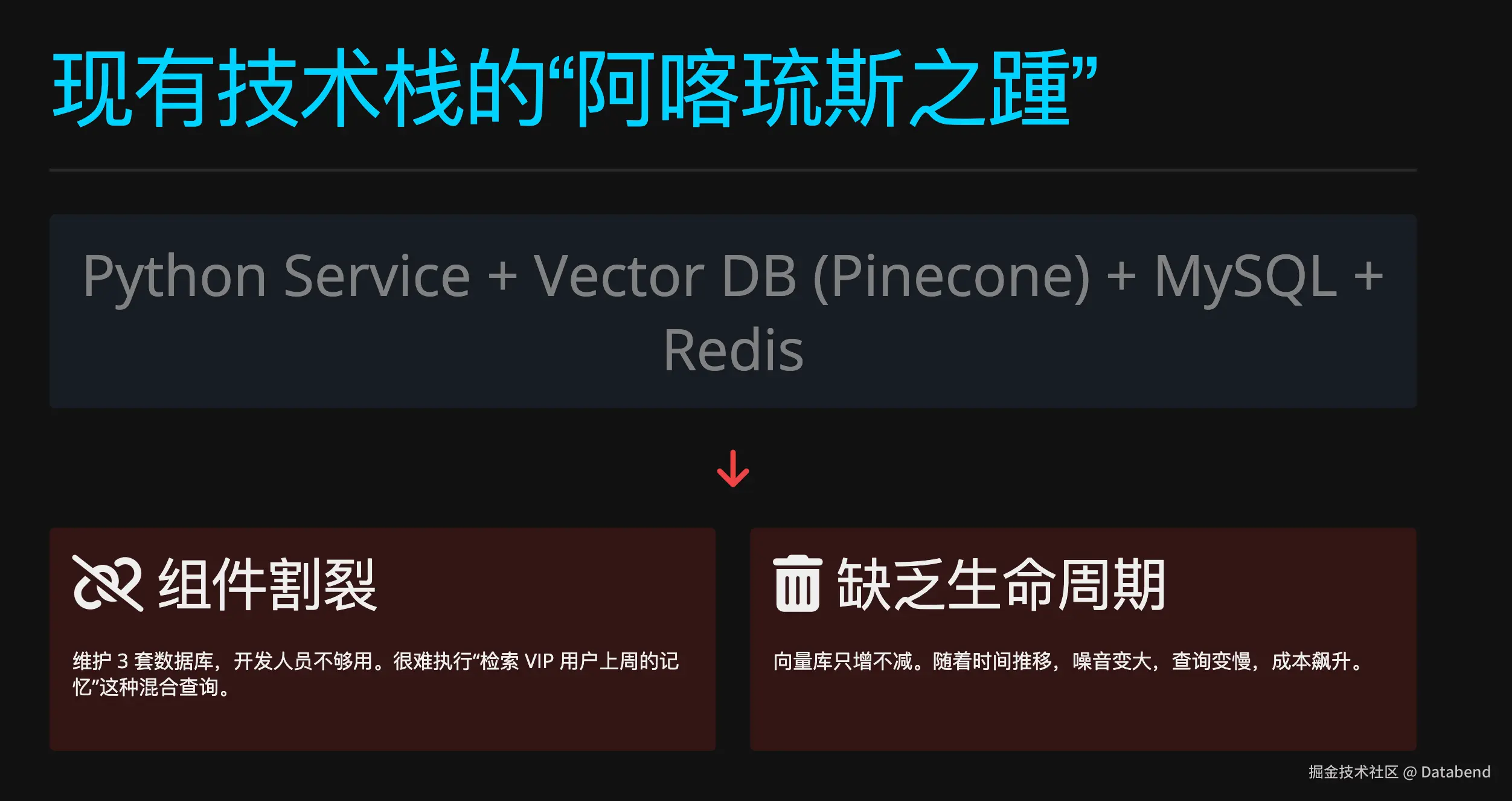
原有的技术栈采用了 "Python Service + Vector DB (Pinecone) + MySQL + Redis" 的组合。这种割裂的架构导致了维护成本高昂(需要维护 3 套数据库),且难以执行混合查询(例如"检索 VIP 用户上周的记忆")。此外,缺乏生命周期管理导致向量库只增不减,随着时间推移,噪音变大,查询变慢,成本飙升。
架构选型:为何选择 Databend?

面对上述挑战,沉浸式翻译团队选择了 Databend 作为其核心记忆存储与计算引擎。Databend 独特的架构优势完美契合了 MemOS 对成本、性能和复杂度的严苛要求:
-
All-in-One (多模态统一) :Databend 支持 Vector(记忆)、Table(业务)和 JSON(偏好)在同一个引擎中处理,打破了数据孤岛。
-
Serverless (零运维) :存算分离架构,按需付费,完美契合"小步快跑"的小团队模式。
-
Programmability (可编程性) :不仅仅是存储,更是计算引擎。通过 SQL + UDF + Task,可以灵活地实现复杂的业务逻辑。
-
Dynamic JSON (动态 JSON 加速) :记忆的元数据(Tags、Status、Time)往往是动态变化的。Databend 支持直接存储 JSON 数据并建立倒排索引加速查找,无需频繁变更表结构(Schema Evolution),即可实现毫秒级的多维过滤,这对于
ai_query获取精准上下文至关重要。
核心架构设计:MemOS

沉浸式翻译构建了名为 MemOS 的统一记忆架构,利用 Databend 的特性实现了高效的存储与检索。
1. MemNodes:记忆实体与性能优化
MemNodes 表存储了记忆的核心载荷(文本与向量)以及元数据(JSON)。为了解决混合查询的性能问题,他们利用了 Databend 的 Computed Column (计算列) 和 Cluster Key ( 聚簇索引 ) 。
-
计算列 (Computed Column) :用于高频、固定 的过滤场景。直接从 JSON
meta字段中提取lifecycle_state等关键字段建立物理列,使得数据库在过滤时无需解析整个 JSON,极大提升了查询速度。 -
聚簇索引 (Cluster Key) :通过
CLUSTER BY (user_id, lifecycle_state),强制让同一个用户的活跃记忆在物理存储上相邻。这意味着查询特定用户记忆时,数据库只需读取极少量的文件块,显著降低了 I/O 开销。 -
全文索引 (Inverted Index) :用于动态、长尾 的标签查询。为了应对 Schema 不固定的元数据查询,MemOS 为
meta(JSON) 和content建立了倒排索引。这意味着开发者可以随意增加新的 Tag 或属性,并立即使用QUERY函数进行高效过滤(如meta.topic:food),而无需重建索引或修改表结构。
sql
CREATE TABLE MemNodes (
node_id VARCHAR NOT NULL,
user_id VARCHAR NOT NULL,
content VARCHAR,
embedding VECTOR(1024),
meta VARIANT,
created_at TIMESTAMP DEFAULT NOW(),
-- 物理存储的计算列,加速 JSON 字段过滤
topic VARCHAR AS (meta:topic::VARCHAR) STORED,
memory_type VARCHAR AS (meta:type::VARCHAR) STORED,
lifecycle_state VARCHAR AS (meta:state::VARCHAR) STORED,
-- 全文检索索引,支持 MATCH/QUERY 函数
INVERTED INDEX idx_content (content),
INVERTED INDEX idx_meta (meta)
)
CLUSTER BY (user_id, lifecycle_state);场景示例:旧金山之旅 - 记忆存储
用户Bob正在使用沉浸式翻译插件浏览一篇关于旧金山美食的双语文章,他鼠标划词收藏了 "Sourdough Bread" (酸种面包) 及其例句。
ini-- 自动提取 Meta 中的 topic,加速查询 SELECT content FROM MemNodes WHERE user_id = 'Bob' AND topic = 'food' -- 命中计算列索引 AND lifecycle_state = 'activated';
- 效果 :Databend 自动提取
topic="food"。当 Bob 复习"食物"类词汇时,数据库直接利用物理索引跳过其他无关数据,毫秒级返回结果。
2. MemEdges:记忆图谱与推理
为了解决纯向量无法进行逻辑推理的问题,他们引入了 MemEdges 表来存储记忆之间的关系(如推理链、时序链)。这使得 Agent 能够理解"单词 A 是由场景 B 触发的"或"翻译 A 发生在浏览网页 B 时"。
sql
CREATE TABLE MemEdges (
source_id VARCHAR,
target_id VARCHAR,
-- 关系类型,如 'found_at', 'derived_from'
relation_type VARCHAR,
-- 关联强度 (0.0-1.0),用于在检索时过滤弱相关记忆
weight FLOAT,
created_at TIMESTAMP DEFAULT NOW()
);场景示例:旧金山之旅 - 关联记忆
- 记忆节点 A:单词 "Sourdough Bread"。
- 记忆节点 B:景点 "Fisherman's Wharf" (渔人码头) 的介绍页面。
sql-- 插入关联关系 INSERT INTO MemEdges (source_id, target_id, relation_type) VALUES ('node_sourdough', 'node_wharf', 'found_at');
- 效果:当 Bob 后来询问"渔人码头有什么好玩的?"时,Agent 不仅介绍景点,还能温馨提示:"别忘了你之前标记过的酸种面包就在那里哦!"
3. 混合检索策略:向量 + 全文 + 图谱
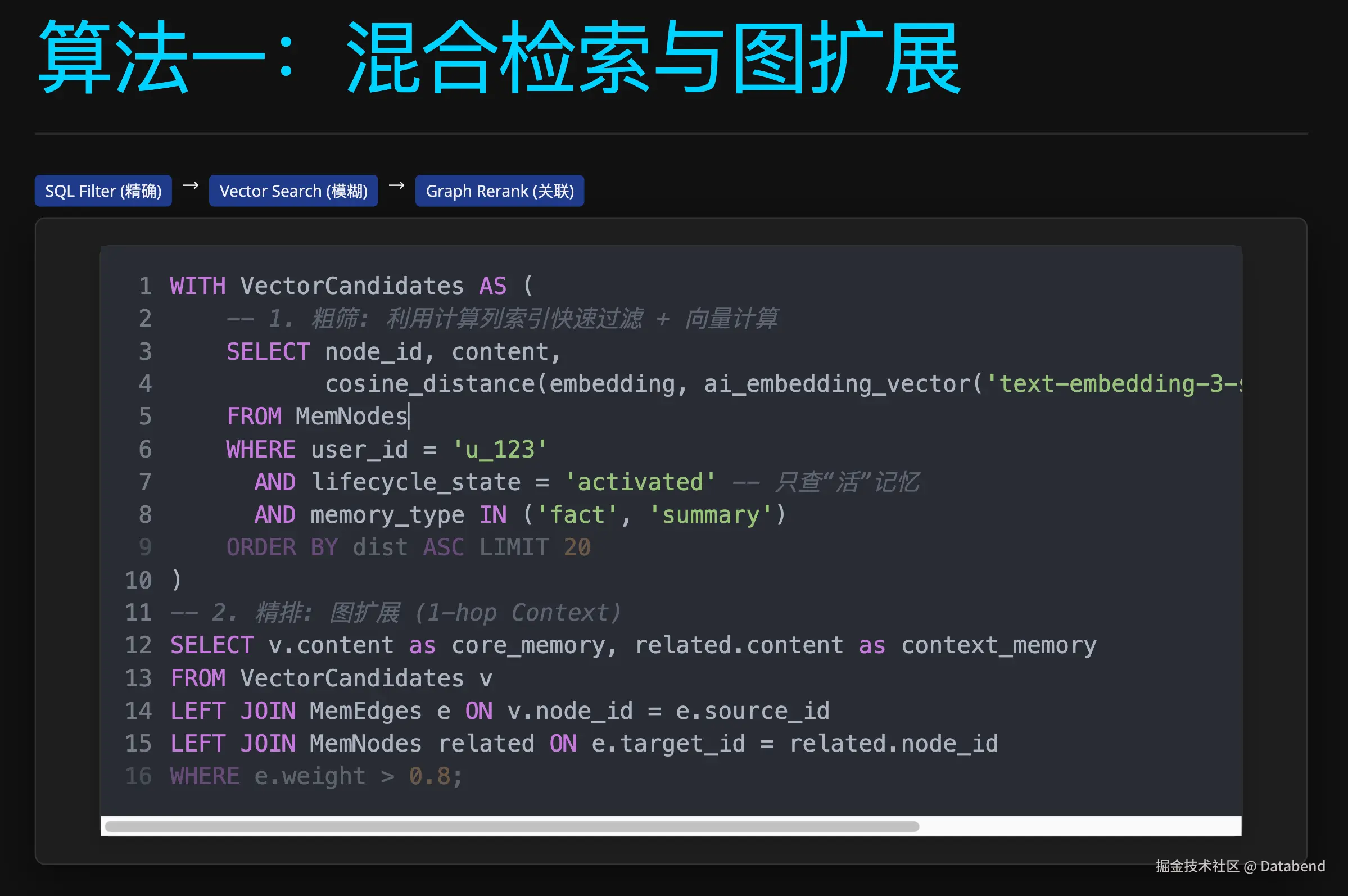
在实战中,单纯的向量检索往往难以处理精确匹配需求(如查找特定的专有名词或错误码)。MemOS 采用了工业界标准的混合检索 (Hybrid Search) 策略,结合了全文检索的"精确性"和向量检索的"语义泛化能力"。
-
全文检索 (Keyword Search) :利用 Databend 的
QUERY()函数进行倒排索引匹配,确保召回结果必须包含关键实体(如 "Sourdough"),解决向量检索偶尔出现的"幻觉"或不精确问题。 -
向量重排 (Semantic Rerank) :在命中关键词的候选集中,利用
cosine_distance计算语义相似度,将最符合语境的记忆排在前面。 -
图谱扩展 ( Graph Augmentation) :最后通过
MemEdges找到这些记忆的一跳关联,拼出上下文。
场景示例:旧金山之旅 - 混合查找
Bob 问:"我之前在哪家店吃的酸种面包?" (Where did I have that Sourdough bread?)
- 关键词提取 :
"Sourdough"- 语义向量 :
:user_query_embedding(包含"地点"、"吃"等语义)
vbnetWITH HybridCandidates AS ( SELECT node_id, content, -- 向量距离:衡量语义相似度 (越小越相似) cosine_distance(embedding, :user_query_embedding) AS semantic_dist FROM MemNodes WHERE user_id = 'Bob' AND lifecycle_state = 'activated' -- 全文检索:利用倒排索引强制匹配关键词,确保精确度 AND QUERY('content:"Sourdough"') ORDER BY semantic_dist ASC LIMIT 20 ) -- 图谱扩展:拼接一跳关联 (如地点、评论) SELECT core.content AS core_memory, related.content AS context_memory, related.meta:topic AS context_topic FROM HybridCandidates core LEFT JOIN MemEdges e ON core.node_id = e.source_id LEFT JOIN MemNodes related ON e.target_id = related.node_id WHERE e.weight > 0.8;
- 效果 :
QUERY保证了结果一定关于 "Sourdough"(不会歪楼到其他面包),而cosine_distance确保了关于"地点/店铺"的记忆排在前面(而不是关于酸种面包做法的记忆)。最后MemEdges补全了具体的店铺名称和地址。
4. Serverless ETL Pipeline:自动化生命周期管理
"只有会遗忘的系统,才拥有长期记忆。"
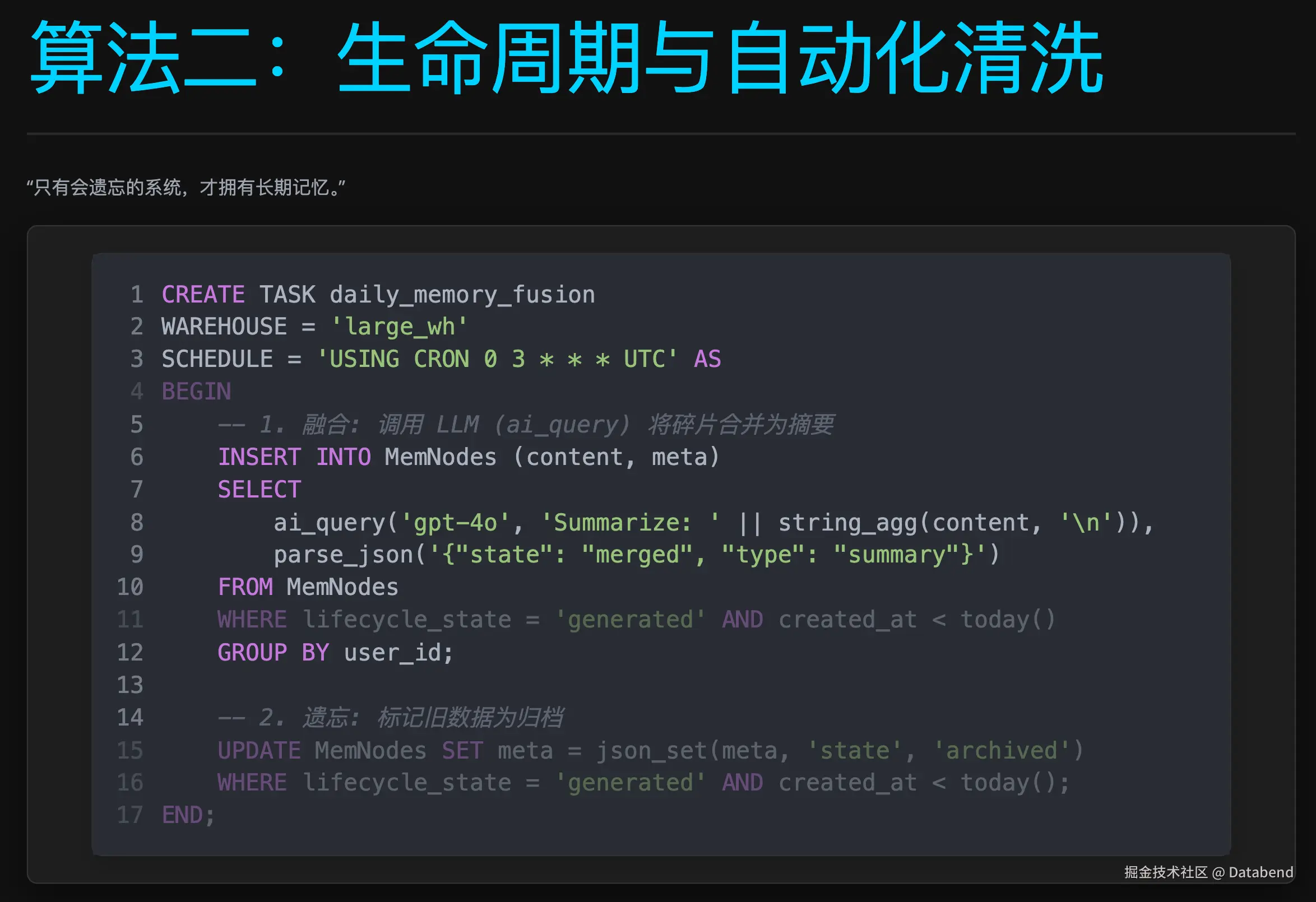
如何让有限的 Context Window 承载无限的对话历史? 这是所有 Agent 开发者面临的终极难题。简单的"先进先出"策略会丢失关键信息,而全量存储又面临成本和性能的双重压力。MemOS 需要一种机制,能够自动地将"即时对话"提炼为"长期记忆",实现记忆的优胜劣汰。
为此,他们利用 Databend 的 Task 构建了一套 Serverless ETL Pipeline。它允许开发者在数据库内部定义复杂的数据流转逻辑,将非结构化的对话流实时转化为结构化的记忆。
策略设计:滚动式记忆压缩 (Rolling Memory Compression)
为了解决 Context Window 限制,MemOS 采用了一种"滚动归纳"的策略,将记忆分为两层:
- 短期记忆 (Short-term) :最近 N 轮的原始对话,保留完整细节。
- 长期记忆 (Long-term) :由历史对话不断迭代生成的"摘要"。
当短期记忆积累到一定阈值(如 10 轮)时,系统会将"当前摘要"与"新增对话"合并,生成"新摘要",并将原始对话归档。这种机制确保了 Agent 始终持有最新的状态概览,而无需背负沉重的历史包袱。
技术实现:Stream + Task 的自动化闭环
假设对象均位于memdbschema,流水线分为三步走:
- 捕获 (Stream) :
chat_messages_stream实时捕获原始对话的增量写入。- 聚合 (Task 1) :
chat_ctx_collect监听流,将"当前轮次 - 水位 ≥ 10"的会话聚合到pending_chats表。- 摘要 (Task 2) :
chat_ctx_summarize监听pending_chats_stream,仅在确有待处理窗口时唤醒计算数仓,调用 LLM 生成摘要并推进水位线。
这样可以避免原始消息持续写入所带来的 7×24 唤醒,同时确保只对真正需要压缩的会话执行昂贵的 LLM 调用。
sql
-- Source:原始对话
CREATE TABLE memdb.chat_messages (
session_id STRING,
round_no UINT64,
content STRING,
created_at TIMESTAMP DEFAULT NOW()
);
-- Stream:原始对话增量
CREATE STREAM memdb.chat_messages_stream ON TABLE memdb.chat_messages APPEND_ONLY = TRUE;
-- Watermark:处理进度
CREATE TABLE memdb.chat_summary_watermark (
session_id STRING,
last_summarized_round UINT64 DEFAULT 0
);
-- Pending:Task 输入窗口
CREATE TABLE memdb.pending_chats (
session_id STRING,
content STRING,
new_rounds UINT64
);
-- Stream:待压缩窗口增量
CREATE STREAM memdb.pending_chats_stream ON TABLE memdb.pending_chats APPEND_ONLY = TRUE;
-- Sink:摘要结果
CREATE TABLE memdb.chat_summaries (
session_id STRING,
summary STRING,
created_at TIMESTAMP DEFAULT NOW()
);
-- Task 1:收集符合条件的会话窗口
CREATE TASK chat_ctx_collect
WAREHOUSE = 'collect_wh'
SCHEDULE = 1 MINUTE
WHEN STREAM_STATUS('memdb.chat_messages_stream') = TRUE
AS
INSERT INTO memdb.pending_chats (session_id, content, new_rounds)
SELECT
m.session_id,
string_agg(m.content, '\n' ORDER BY m.round_no) AS content,
max(m.round_no) AS new_rounds
FROM memdb.chat_messages AS m
LEFT JOIN memdb.chat_summary_watermark AS w
ON m.session_id = w.session_id
GROUP BY m.session_id
HAVING max(m.round_no) - COALESCE(w.last_summarized_round, 0) >= 10;
-- Task 2:Serverless 自动调度(摘要 + 水位推进)
CREATE TASK chat_ctx_summarize
WAREHOUSE = 'summarize_wh'
SCHEDULE = 1 MINUTE
-- 仅当待压缩窗口出现增量时唤醒
WHEN STREAM_STATUS('memdb.pending_chats_stream') = TRUE
AS
BEGIN
-- Step A: 调用 LLM 生成摘要并写入 Sink 表
INSERT INTO memdb.chat_summaries (session_id, summary)
SELECT session_id, ai_query('...summarize...', content)
FROM memdb.pending_chats
WHERE new_rounds >= 10;
-- Step B: 推进水位线,标记已处理
MERGE INTO memdb.chat_summary_watermark AS target
USING memdb.pending_chats AS source
ON target.session_id = source.session_id
WHEN MATCHED THEN UPDATE SET last_summarized_round = source.new_rounds
WHEN NOT MATCHED THEN INSERT (session_id, last_summarized_round)
VALUES (source.session_id, source.new_rounds);
END;场景示例:旧金山之旅 - 语言特训
Bob 进行了 50 轮"模拟海关入境"练习,当pending_chats累积 10 轮未摘要的数据时,Task 被触发并把最近对话压缩成一条"入境问答上下文摘要",重点记录他在"行李违禁品"话题上的提问与回答、Agent 给出的提示以及 Bob 的反馈。下次练习时,Agent 直接引用这条长期记忆补齐上下文,避免重复确认背景信息。
总结展望

通过迁移到 Databend,沉浸式翻译不仅解决了成本与性能的难题,更构建了一套面向未来的现代化数据架构:

- 低成本: 存算分离,让海量的记忆存储成本趋近 S3 的存储成本
- 低运维: 利用 Databend Serverless Task 替代了复杂的 Airflow/Python 脚本,管理和开发都简化了许多。
- 高性能: cluster key 和 计算列解决了混合检索的题。
后续需要 Databend 一起在 AI 长记体方面一起协作的方向:
-
更丰富的 Vector 索引算法支持
-
在 AI 方向引入 GPU 加载能力
-
更加友好的 UDF 部署体验。目前团队在 UDF 方面也是重度的使用。
总的来说沉浸式翻译的实践证明,Databend 不仅是一个高性能的数仓,更是构建下一代 AI Native 应用的理想基础设施。 它帮助小团队轻松驾驭海量记忆,打造出真正懂用户的 AI 伴侣。
关于 Databend
Databend 是一款 100% Rust 构建、面向对象存储设计的新一代开源云原生数据仓库,统一支持 BI 分析、AI 向量、全文检索及地理空间分析等多模态能力。期待您的关注,一起打造新一代开源 AI + Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab...