一、前言
上一节已经将mp的基本核心用法讲到了,除此之外,mp还具备一些能够提高开发效率的扩展功能,下面将一一讲解。
二、代码生成工具
这个需要基于插件来实现,我使用的是官方推荐的MyBatisX,这个插件中具备代码生成器,可以允许对一个单表进行代码生成。
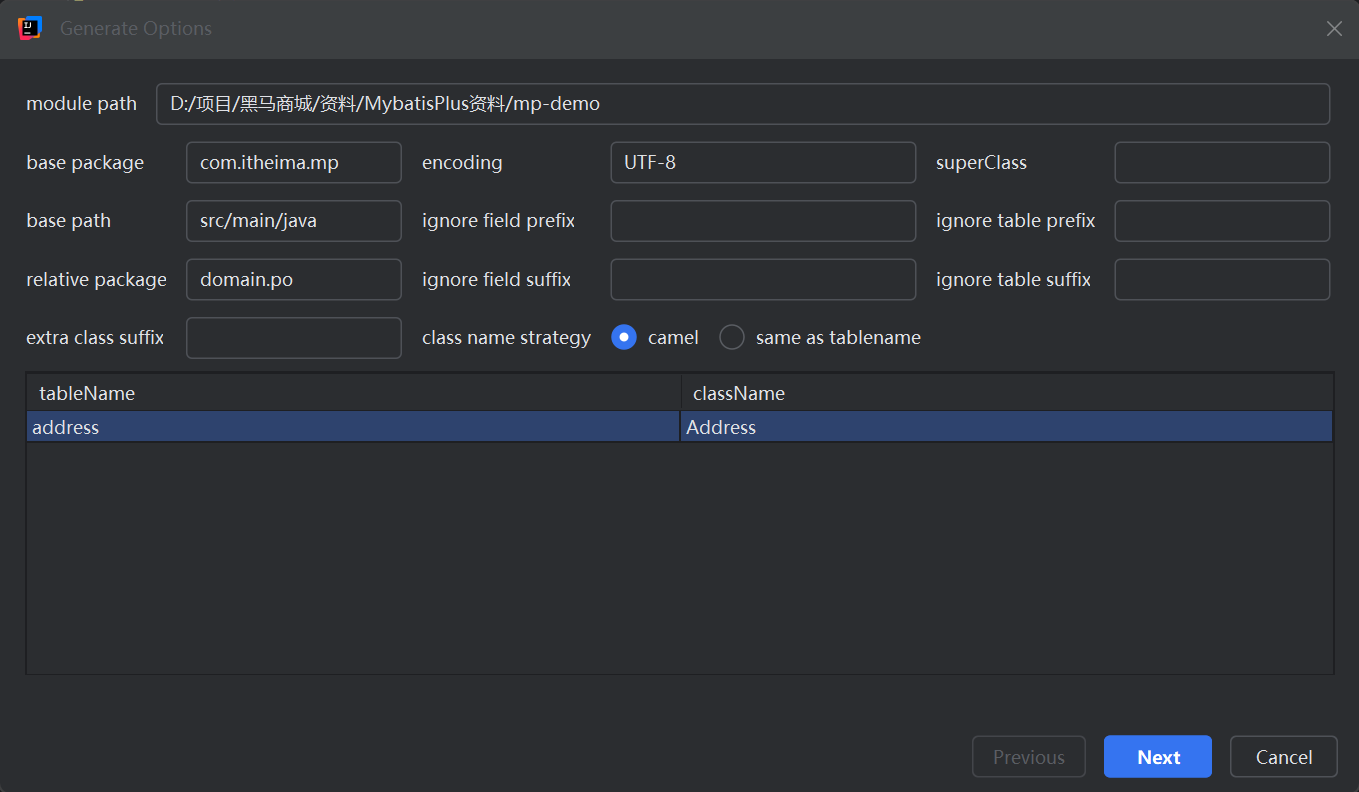
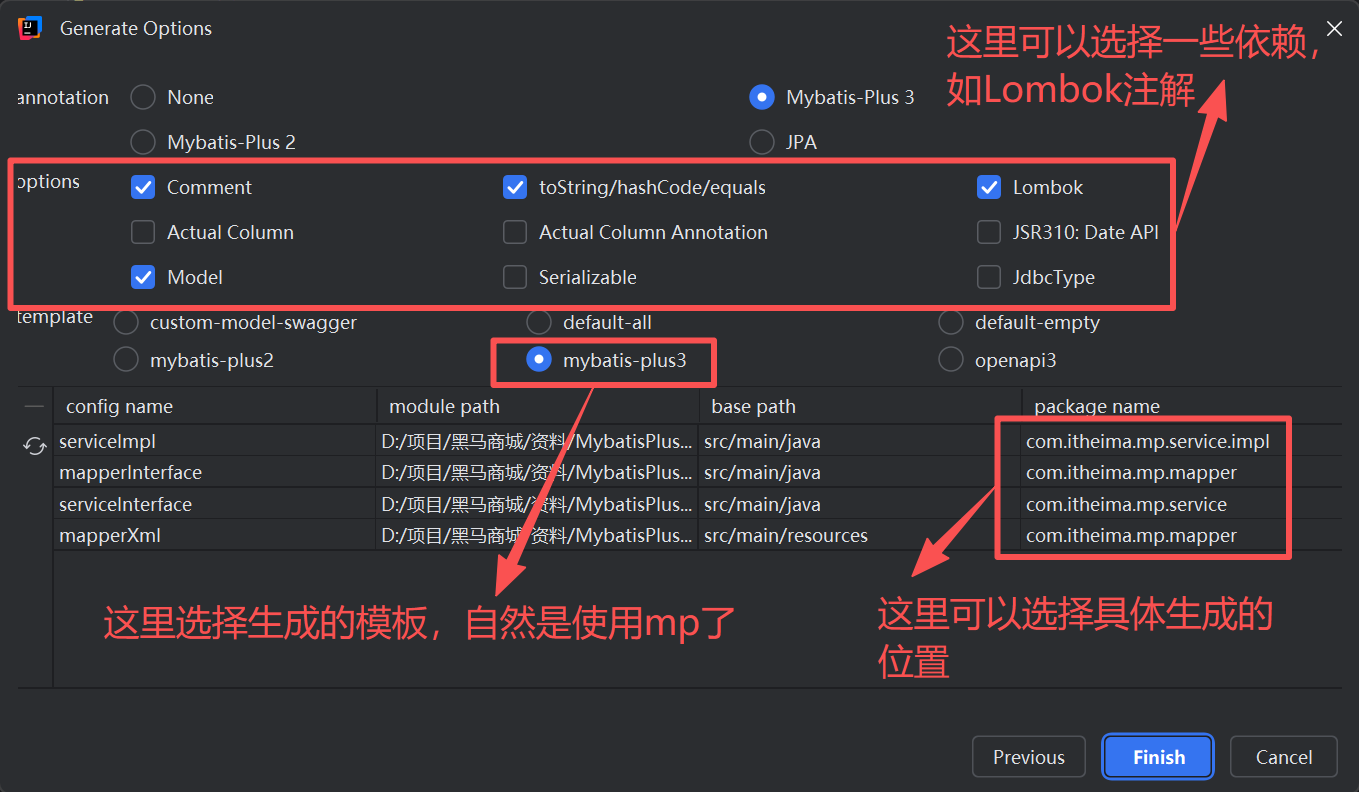
随后就会自动生成这些文件(里面是空的,业务代码当然需要自己去写,主要目的是简化IService的实现和实现类的继承):
三、Db静态工具
静态工具的功能主要在于可以直接操作表,在简单的多表查询中,可以无需注入Mapper,实现直接从表中查询数据,然后再拼接数据的功能。Db本身的方法和其他构造器的方法相同,所以没有什么学习成本,直接使用即可。
例如:
需求1:根据id查询用户和用户对应的所有地址:
java
@Override
public UserVO queryUserAndAddressById(Long id) {
//1.查询用户
User user = this.getById(id);
if (user == null || user.getStatus() == UserStatus.FROZEN) {
throw new RuntimeException("用户状态异常");
}
//2.查询地址
List<Address> addresses = Db.lambdaQuery(Address.class)
.eq(Address::getUserId, id)
.list();
//3.封装VO
UserVO userVO = BeanUtil.copyProperties(user, UserVO.class);
if (CollUtil.isNotEmpty(addresses)) {
userVO.setAddresses(BeanUtil.copyToList(addresses, AddressVO.class));
}
return userVO;
}这里就用Db根据userId条件查询地址集合,然后将集合拼接到userVO中去。
需求2:根据ids批量查询用户和用户对应的所有地址:
java
@Override
public List<UserVO> queryUserAndAddressByIds(List<Long> ids) {
//1.查询用户
List<User> users = listByIds(ids);
if (CollUtil.isEmpty(users)) {
return Collections.emptyList();
}
//2 查询地址
//2.1 获取用户id集合
List<Long> userIds = users.stream().map(User::getId).collect(Collectors.toList());
//2.2 根据用户id查询地址
List<Address> addresses = Db.lambdaQuery(Address.class).in(Address::getUserId, userIds).list();
//2.3 转换地址VO
List<AddressVO> addressVOList = BeanUtil.copyToList(addresses, AddressVO.class);
Map<Long, List<AddressVO>> addressMap = new HashMap<>(0);
//2.4 梳理地址集合,分类整理,相同用户的放入一个集合中
if (CollUtil.isNotEmpty(addressVOList)) {
addressMap = addressVOList.stream().collect(Collectors.groupingBy(AddressVO::getUserId));
}
//3.转换VO返回
List<UserVO> list = new ArrayList<>(users.size());
for (User user : users) {
//3.1 转换User的PO为VO
UserVO vo = BeanUtil.copyProperties(user, UserVO.class);
list.add(vo);
//3.2 转换地址VO
vo.setAddresses(addressMap.get(user.getId()));
}
return list;
}四、处理器
先展示一下我们的User类:
java
@Data
@TableName(value = "user", autoResultMap = true)
public class User {
/**
* 用户id
*/
@TableId(type = IdType.AUTO)//标记自增长,如果这里不标记id就是默认雪花算法
private Long id;
/**
* 用户名
*/
@TableField("`username`")//这里只是使用了转义字符,当表中的字段名和成员变量名不同(或者没有遵循驼峰-下划线规则)时可以用这个注解绑定
private String username;
/**
* 密码
*/
private String password;
/**
* 注册手机号
*/
private String phone;
/**
* 详细信息
*/
private Stringinfo;
/**
* 使用状态(1正常 2冻结)
*/
private String status;
/**
* 账户余额
*/
private Integer balance;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 更新时间
*/
private LocalDateTime updateTime;
/**
* 测试表外字段
*/
@TableField(exist = false)//表示这个字段不是表中的字段
private String redundantField;
}1.枚举处理器
以往在苍穹外卖中,我们通常使用的是常量类来统一管理常量,这里引入枚举,这是更加常见的常量管理办法。可以看到下面我们定义了两个常量(枚举实例,必须具备下面声明的字段value和desc),一个是NORMAL,一个是FROZEN。
我们在这里需要解决的问题是,如何将枚举类的数据放入数据库中,这里我们就可以通过注解来解决这个问题,
@EnumValue 标记value字段,这是存入数据库的值,后续操作也是操作的这个值。
@JsonValue是标记JSON序列化后需要转化成的值,例如后续我们在输出用户状态时,我们将以一个JSON格式输出,输出的就是 {"status": "正常"} ,而不是{"status": "NORMAL"} 或 {"status": 1}
java
@Getter
public enum UserStatus {
NORMAL(1,"正常"),
FROZEN(2,"冻结"),
;
@EnumValue
private final int value;
@JsonValue
private final String desc;
UserStatus(int value,String desc) {
this.value = value;
this.desc = desc;
}
}所以我们的User可以改成:
java
/**
* 使用状态(1正常 2冻结)
*/
private UserStatus status;2.JSON处理器
我们原先是使用String来展示userInfo的,现在我们使用一个类来描述userInfo:
java
@Data
@NoArgsConstructor
@AllArgsConstructor(staticName = "of")
public class UserInfo {
private Integer age;
private String intro;
private String gender;
}所以User可以改为:
java
/**
* 详细信息
*/
private UserInfo info;这样就会出现一个问题,我们应该怎样把这个类存储进数据库,那肯定可以想到是用JSON格式字符串存储,那就只有一个问题了,就是如何转换,以往我们是通过一个工具类手动转换的,很麻烦,这里我们可以使用新的解决方法------mp提供了注解:
java
/**
* 详细信息
*/
@TableField(typeHandler = JacksonTypeHandler.class)
private UserInfo info;这就是JSON处理器了,这个注解标记让这个成员变量转换成JSON格式(在更新和插入时序列化、查询时反序列化),参数是转换器类(可自选不同公司的处理器)
但是别忘了使处理器生效,在User类上添加这个注解,让结果集自动映射:
java
@TableName(value = "user", autoResultMap = true)五、分页插件的使用
mp的分页插件的使用其实就是让我们自己写一个pageHelper,Page类是mp提供的工具类,用于封装分页的信息。
1.整体思路
首先需要在配置类中添加分页插件,在这里可以设置最大的分页数、使用的数据库类型等等。
java
@Configuration
public class MybatisConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//1.创建分页插件
PaginationInnerInterceptor paginationInnerInterceptor = new PaginationInnerInterceptor(DbType.MYSQL);
paginationInnerInterceptor.setMaxLimit(1000L);
//2.添加分页插件
interceptor.addInnerInterceptor(paginationInnerInterceptor);
return interceptor;
}
}然后创建分页所需的DTO和query:
这里注意辨析:
1**.Page**是核心类,用于存放分页参数、存放查询结果(所以通常会创建两个Page的对象)。
2.PageQuery 是用于存放前端传回的请求参数的类。
3.PageDTO 是存放返回结果的类。
java
@Data
@ApiModel(description = "分页结果")
public class PageDTO<T> {
@ApiModelProperty("总条数")
private Long total;
@ApiModelProperty("总页数")
private Long pages;
@ApiModelProperty("集合")
private List<T> list;
}
java
@Data
public class PageQuery {
private Integer pageNo;
private Integer pageSize;
private String sortBy;
private Boolean isAsc;
}共分为四步:
-
构造分页条件(页码、大小、排序)
-
进行分页查询
-
封装VO结果
-
返回分页DTO
java
@Override
public PageDTO<UserVO> queryUsersPage(UserQuery query) {
String name = query.getName();
Integer status = query.getStatus();
//1.构造查询条件
//1.1分页条件
Page<User> page = Page.of(query.getPageNo(), query.getPageSize());
//1.2排序条件
if (StrUtil.isNotBlank(query.getSortBy())) {
//不为空
page.addOrder(new OrderItem(query.getSortBy(), query.getIsAsc()));
}else {
//为空,默认更新时间排序
page.addOrder(new OrderItem("update_time", false));
}
//2.分页查询
Page<User> p = lambdaQuery()
.like(name != null, User::getUsername, name)
.eq(status != null, User::getStatus, status)
.page(page);
//3.封装VO结果
PageDTO<UserVO> dto = new PageDTO<>();
//3.1总条数
dto.setTotal(p.getTotal());
//3.2总页数
dto.setPages(p.getPages());
//3.3当前页数据
List<User> records = p.getRecords();
if(CollUtil.isEmpty(records)){
dto.setList(Collections.emptyList());
return dto;
}
//3.4拷贝user的VO
List<UserVO> vos = BeanUtil.copyToList(records, UserVO.class);
dto.setList(vos);
//4.返回
return dto;
}这里比较让人疑惑的一点,就是为什么会创建两个Page的对象,这是因为在使用lambda构造器时,我希望查出来的数据直接就封装成一个page对象,但是这当然需要按照一定规则了,比如当前页数和每一页的条数,所以我们将这个规则单独封装成一个Page对象,后续要封装查询的对象时,我们将这个规则对象作为参数传入构造器,于是就能按照这个规则拿到查询后的每一页的结果集了,所以第二个Page对象我们用于存放查询结果。
2.封装
可以看到上面的代码很多而且很繁琐,这个时候肯定会选择封装,我们将上面部分封装到PageDTO中的一个方法中去,下面部分封装到PageQuery中去:
java
@Data
@ApiModel(description = "分页结果")
public class PageDTO<T> {
@ApiModelProperty("总条数")
private Long total;
@ApiModelProperty("总页数")
private Long pages;
@ApiModelProperty("集合")
private List<T> list;
public static<PO,VO> PageDTO<VO> of(Page<PO> p ,Class<VO> clazz){
//封装VO结果
PageDTO<VO> dto = new PageDTO<>();
//1总条数
dto.setTotal(p.getTotal());
//2总页数
dto.setPages(p.getPages());
//3当前页数据
List<PO> records = p.getRecords();
if(CollUtil.isEmpty(records)){
dto.setList(Collections.emptyList());
return dto;
}
//4拷贝user的VO
List<VO> vos = BeanUtil.copyToList(records, clazz);
dto.setList(vos);
return dto;
}
}
java
@Data
public class PageQuery {
private Integer pageNo;
private Integer pageSize;
private String sortBy;
private Boolean isAsc;
public <T> Page<T> toMpPage(OrderItem ... orders){
// 1.分页条件
Page<T> p = Page.of(pageNo, pageSize);
// 2.排序条件
// 2.1.先看前端有没有传排序字段
if (sortBy != null) {
p.addOrder(new OrderItem(sortBy, isAsc));
return p;
}
// 2.2.再看有没有手动指定排序字段
if(orders != null){
p.addOrder(orders);
}
return p;
}
public <T> Page<T> toMpPage(String defaultSortBy, boolean isAsc){
return this.toMpPage(new OrderItem(defaultSortBy, isAsc));
}
public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc() {
return toMpPage("create_time", false);
}
public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc() {
return toMpPage("update_time", false);
}
}最终我们的Service就简化为了:
java
@Override
public PageDTO<UserVO> queryUsersPage(UserQuery query) {
String name = query.getName();
Integer status = query.getStatus();
//由于在PageQuery类中我们将上述步骤封装成了泛型,所以这里一行代码就可以实现了
Page<User> page = query.toMpPageDefaultSortByUpdateTimeDesc();
//分页查询
Page<User> p = lambdaQuery()
.like(name != null, User::getUsername, name)
.eq(status != null, User::getStatus, status)
.page(page);
return PageDTO.of(p,UserVO.class);
}