前言
在数据驱动的今天,许多企业需要从多个网站抓取结构化数据,用于AI训练、SEO优化、市场分析、价格监控等场景。但传统的数据采集工作往往面临诸多挑战:编写和维护爬虫需要大量技术投入,扩展新网站速度慢,遇到反爬机制时又容易失效。这些痛点让许多团队在数据获取环节耗费过多精力。
AI Scraper Studio是新的技术趋势,凭借 AI 驱动的自然语言交互能力,为这些难题提供了全新解决方案。接下来,我们就从实际需求出发,详细聊聊Bright Data如何改变数据采集的工作模式 。
一、传统数据采集的痛点
- 开发与维护成本高。传统数据采集需要技术人员熟练掌握 Python、JavaScript 等编程语言,还要懂 CSS 选择器、XPath 等页面解析技术,编写一个能稳定运行的爬虫脚本往往需要数天时间。
- 反爬应对能力弱。如今,主流网站都配备了反爬机制,从简单的 IP 封锁、User - Agent 验证,到复杂的 Cloudflare 防护、动态验证码,甚至是基于行为分析的反爬系统,传统爬虫往往束手无策。
- 扩展新域效率低。当业务需要从新的网站采集数据时,传统方案意味着要重新编写一套爬虫脚本,从分析页面结构、定义数据字段,到调试运行、应对反爬。
- 数据一致性难保障。不同网站的页面结构差异巨大,即使是同一类型的网站,数据格式也可能各不相同。传统爬虫需要为每个网站单独处理数据清洗和格式化,很容易出现数据字段缺失、格式不统一等问题。
二、AI Scraper Studio的创新价值
AI Scraper Studio的核心价值在于通过 AI 自然语言驱动的创新模式,彻底改变了传统数据采集的工作方式,将数据采集的门槛从 "专业技术人员" 降低到 "普通业务人员"。这不仅节省了开发时间,还让业务人员能够更直接地参与数据获取过程。
1. 自然语言生成爬虫的技术原理
AI Scraper Studio背后的技术原理并不复杂,但实现了显著的创新:
- 网站结构分析:系统首先访问目标网站,分析其HTML结构、CSS类名、DOM树等
- 语义理解:通过NLP模型理解用户输入的自然语言描述,如"采集所有产品名称和价格"
- 爬虫生成:基于分析结果和语义理解,自动生成相应的爬虫逻辑
- 执行与调试 :系统执行爬虫,返回测试数据,用户确认后部署
这个过程通常只需要几分钟,而传统爬虫开发可能需要数天甚至数周。
2. AI自愈能力:应对网站变化的智能修复
当目标网站结构发生变化时,AI Scraper Studio的AI模型会自动检测变化,并调整爬虫逻辑。这个"自愈能力"是AI Scraper Studio的核心优势。
自愈能力的工作流程:
- 系统定期检查网站结构
- 发现结构变化后,生成新的爬虫逻辑
- 通过AI模型验证新逻辑的有效性
- 自动部署新爬虫,确保数据采集连续性
相比传统方案,这种自愈能力将爬虫维护时间从数天缩短到几分钟。
3. 多维度定制能力
AI Scraper Studio并非"一刀切"的解决方案,它提供了多维度的能力:
- 通过自然语言描述需求,系统自动生成爬虫
- 进入内置IDE,对生成的爬虫脚本进行微调
- 结合自然语言描述和代码微调,实现最优化的采集效果
- 这种设计确保了AI Scraper Studio既适合非技术用户,也能满足技术团队的深度定制需求。如果使用有问题可以与技术专家联系,提供全面、详细的技术方案!
三、详细使用指南:从注册到数据交付
- 注册与界面介绍
1、创建SERP API
(1)注册并登录
注册链接,注册非常的简单,输入邮箱即可,现在注册就会体验金!
2. 详细操作步骤
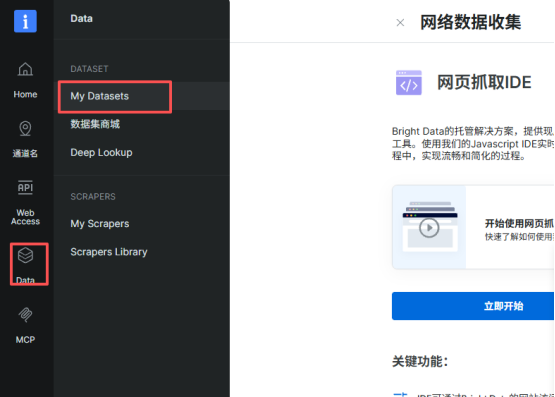
(1)在左侧导航栏点击Data中的My Datasets。
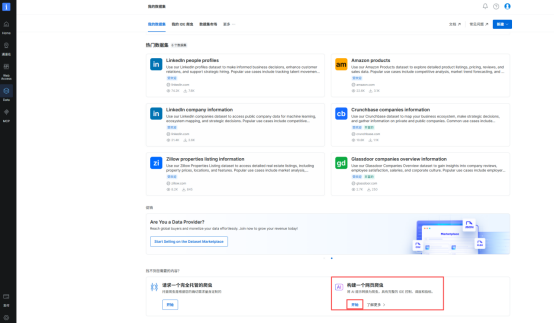
(2)滑到页面最下方,可以看到"构建一个网络爬虫",点击开始。
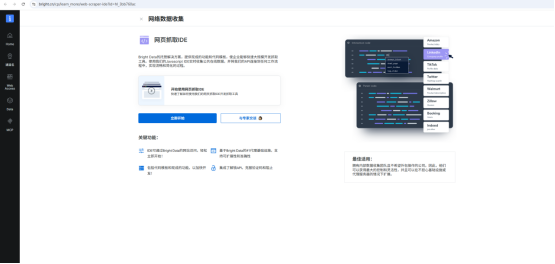
(3)可以看到AI Scraper Studio 就是帮你用"大白话"生成代码,获取到你想获取的数据。
(4)先介绍以下页面中的内容,
"Enter a target URL" 处需要输入你想获取的页面url;
"Tell us more about what you're trying to scrape":表示请再详细说一说您打算抓取的内容是什么。
同时bright data 还提供了几个现有的模版,亚马逊、YouTube、Facebook、LinkedIn 。
这里我们直接使用Facebook模板,获取比尔盖茨facebook的内容。
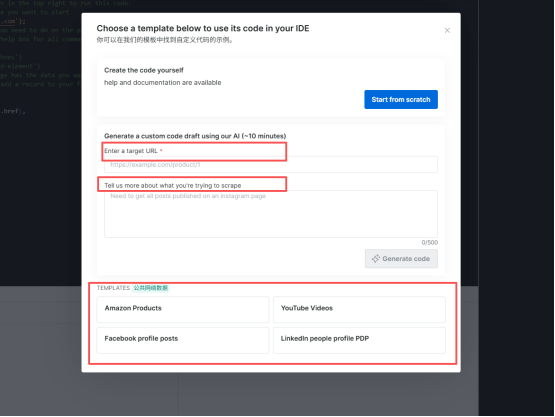
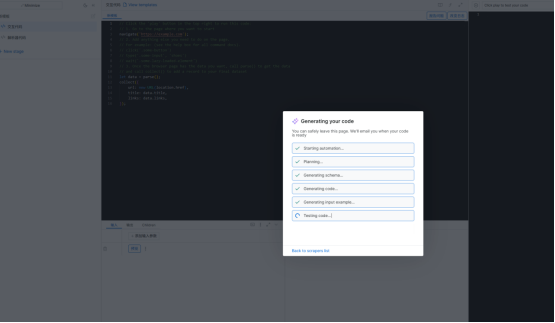
(5)输入完url与想要获取的内容就可以点击"Generate Code",让AI帮你生成代码,等待几分钟即可。
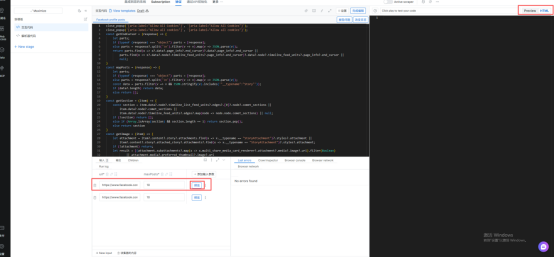
(6)点击预览,运行AI生成的代码,预览是有超时时间的,如果太久会失败哦。右上角的Preview可以看到爬取到的页面,HTML是爬取到的页面源码。预览用于快速验证字段是否准确,不会消耗额度。
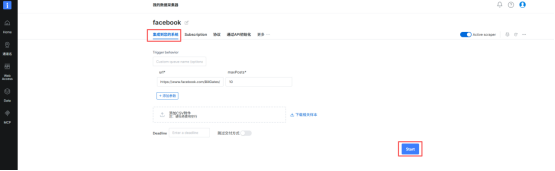
(7)我把名字修改为facebook,然后点击集成到您的系统,再点击start。
(8)我们等待完成获取数据,随后点击下载,这里可以选择需要的格式。我们下载下来看一下爬取的数据是否正确。点击选择json格式。
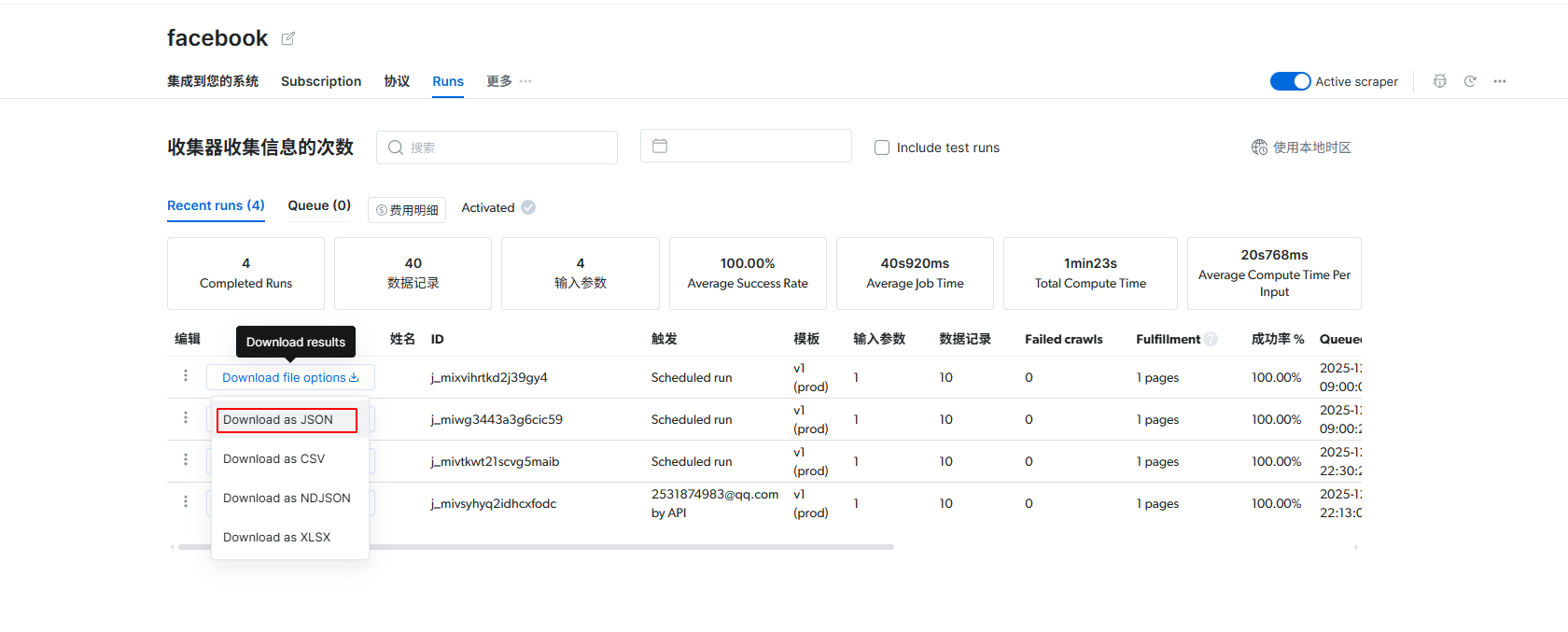
(9)可以看到就是我们想要的数据,获取数据非常的简单!

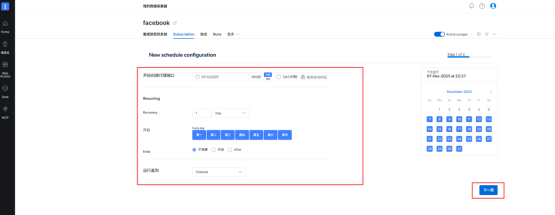
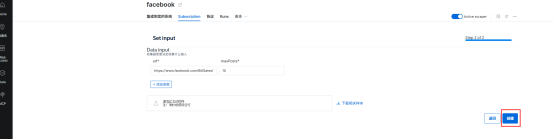
(10)还可以定时进行爬取数据,点击Subscription,可以按需选择日期。点击下一页并创建,可以实现定时更新数据,非常非常方便!
四、结语
在数据驱动的时代,高效获取结构化数据是每个企业成功的关键。AI Scraper Studio通过将自然语言描述转化为数据采集管道,彻底改变了传统的爬虫开发模式。它不仅节省了大量开发和维护成本,还提升了数据获取的敏捷性和准确性。
无论你是技术团队的负责人,还是业务分析师,AI Scraper Studio都能为你提供一个简单、高效的数据获取解决方案。快去体验一下!!现在注册立刻体验金-链接,用一句简单的描述生成一个爬虫,感受数据采集方式的革命性变化吧!