介绍
AI Ping 是一个大模型 API 聚合与调度平台。它的核心价值在于,将一个复杂的"模型市场"和繁琐的技术集成工作,简化成了一个稳定、统一的接口。
点击专属链接进入即可获取30元的算力金:https://aiping.cn/#?channel_partner_code=GQCOZLGJ

其最强大的功能是 智能路由。你可以这样理解它:你不再需要手动为每个任务指定具体使用哪个模型(deepseek、即梦、doubao、Qwen等模型)。你只需要提出需求,智能路由系统就会像一位经验丰富的调度员,根据多种因素自动为你选择当前最优的"执行者"。
这些因素包括:
-
任务类型:是创意写作、复杂推理还是简单问答?系统会匹配最擅长的模型。
-
成本控制:在保证效果的前提下,自动优先选用成本更低的模型。
-
性能与可用性:实时监控各API的响应速度和稳定性,避开拥堵或故障的线路。
这个功能带来的直接好处是:你获得了更高的整体成功率、更优的响应速度以及更低的综合成本,而无需自己编写复杂的调度和维护代码。它让开发者从"模型运维"中解放出来,回归到业务逻辑本身。
应用示例
安装claudecode
在Windows安装claudecode
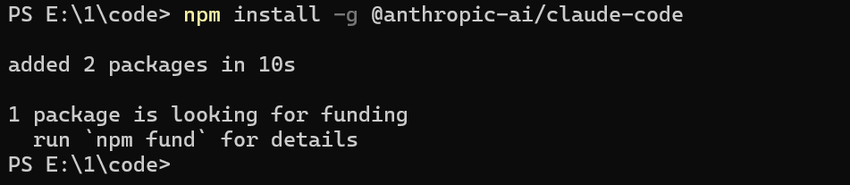
获取API
这里我们前往AI Ping平台获取API,点两下就行了
py调用
然后这里我们使用py一键调用(这就是官方模版,可直接用,官方的模型多了一个}需要删除)
python
import requests
headers = {
'Authorization': '<API_KEY>',
'Content-Type': 'application/json',
}
response = requests.post('https://aiping.cn/api/v1/chat/completions', headers=headers, json={
'model': 'DeepSeek-R1-0528',
'messages': [
{
'role': 'user',
'content': 'What is the meaning of life?'
}
]
}
)
response.encoding = 'utf-8'
print(response.text)输出结果
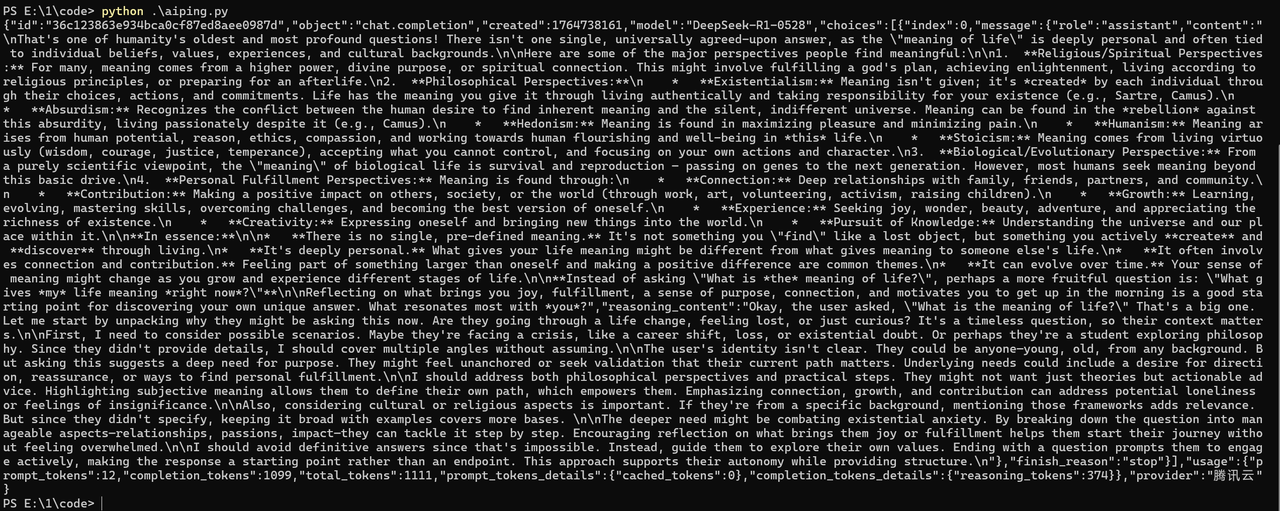
这是我没有做任何调整,就添加了模型输出的结果,比较难懂也难看
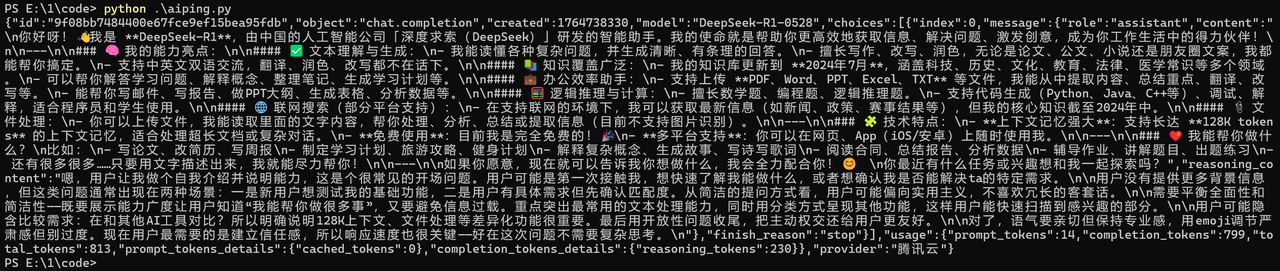
然后我重新调整一下语言并让他针对具体的问题做回答
Code开发
现在我们开始code开发,我们需要先前往C盘下面的users里面的administrator文件夹下面进入.claude目录,然后创建json文件添加:
bash
{
"env": {
"ANTHROPIC_BASE_URL": "https://aiping.cn/api/v1/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<YOUR_API_KEY>",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_MODEL": "Kimi-K2-Thinking",
"ANTHROPIC_SMALL_FAST_MODEL": "Kimi-K2-Thinking",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "Kimi-K2-Thinking",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "Kimi-K2-Thinking",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "Kimi-K2-Thinking"
}
}
应用实战
我们在cmd模式下输入claude即可进入(这里我们可以自己创建一个文件夹,然后右击选择"在终端打开"即可进入命令行)
今天我们创建一个黑客加/解密在线工具。
接下来投喂提示词
bash
实现一个加解密在线工具
支持各种的加解密语法(包含base64、base32、凯撒、AES、md5等)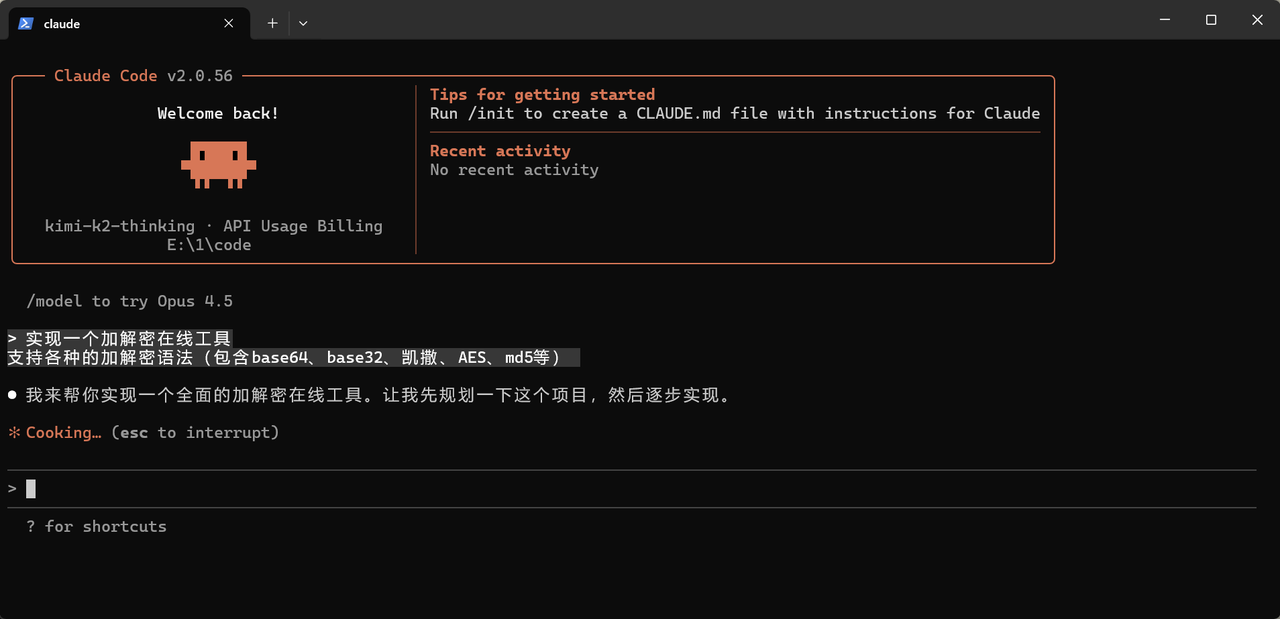
然后接下来就是一路等等等,一路yesyesyes
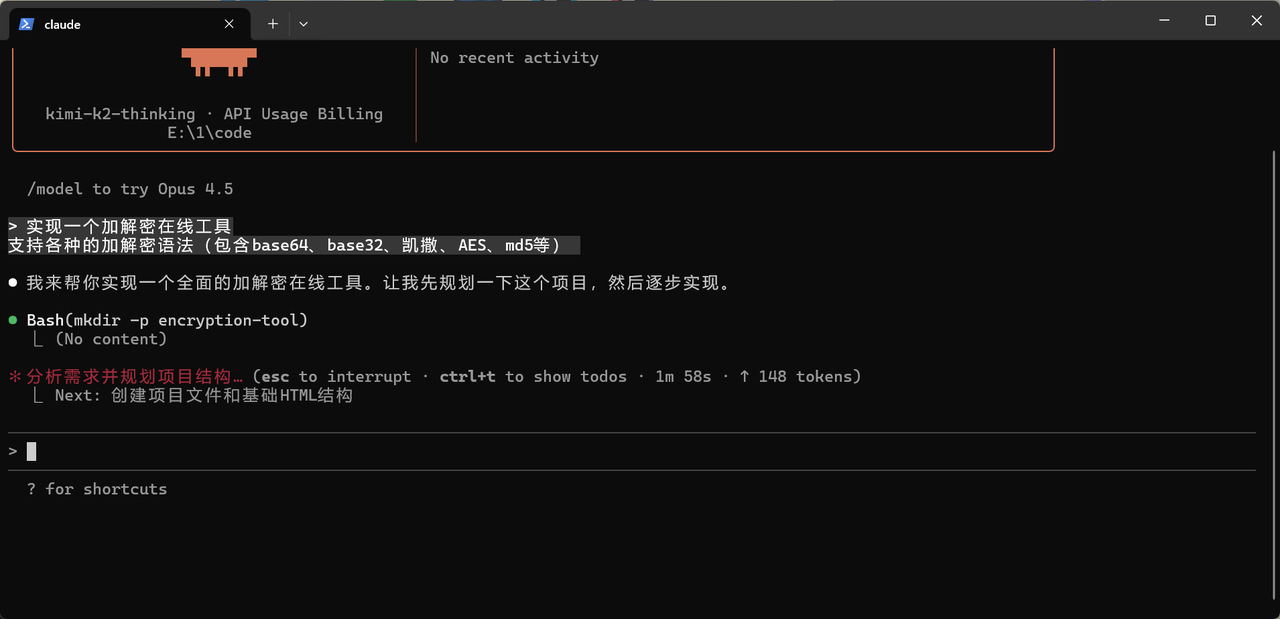
也是搞完了,让我们去看看效果如何

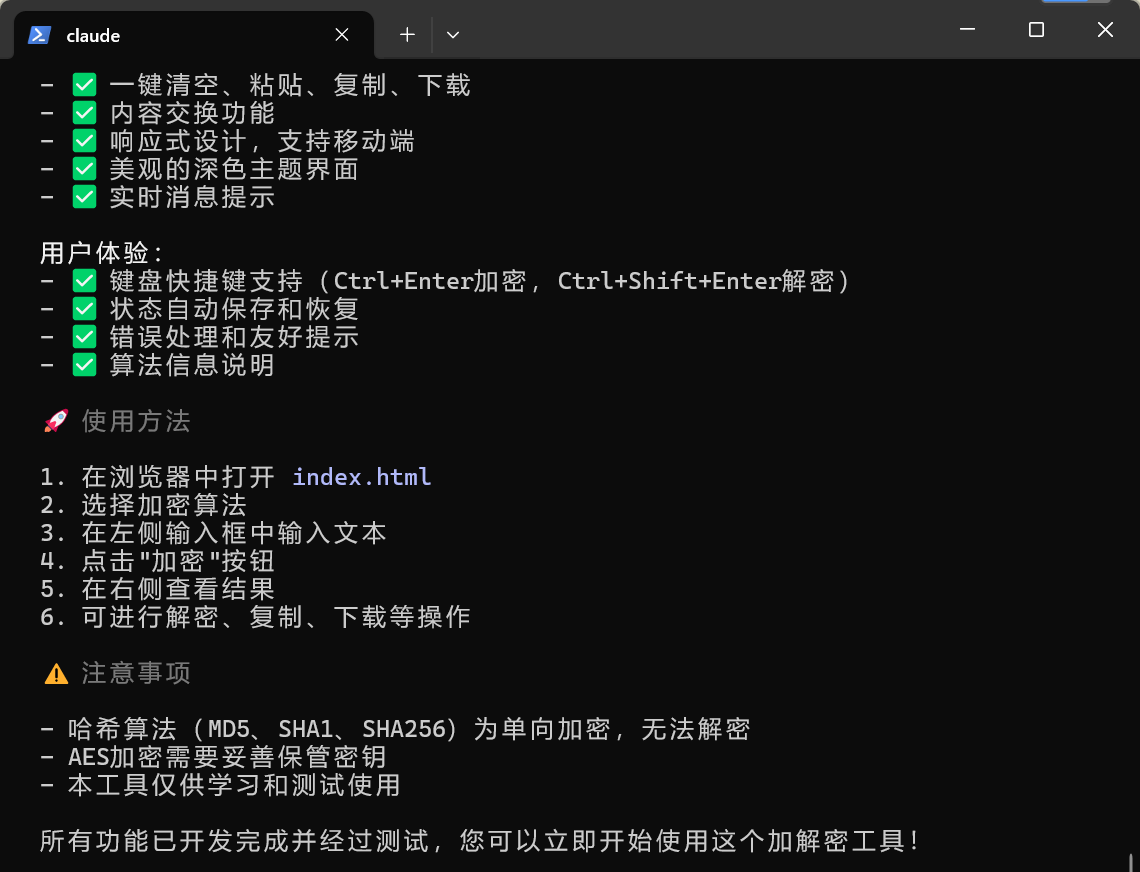
效果如下
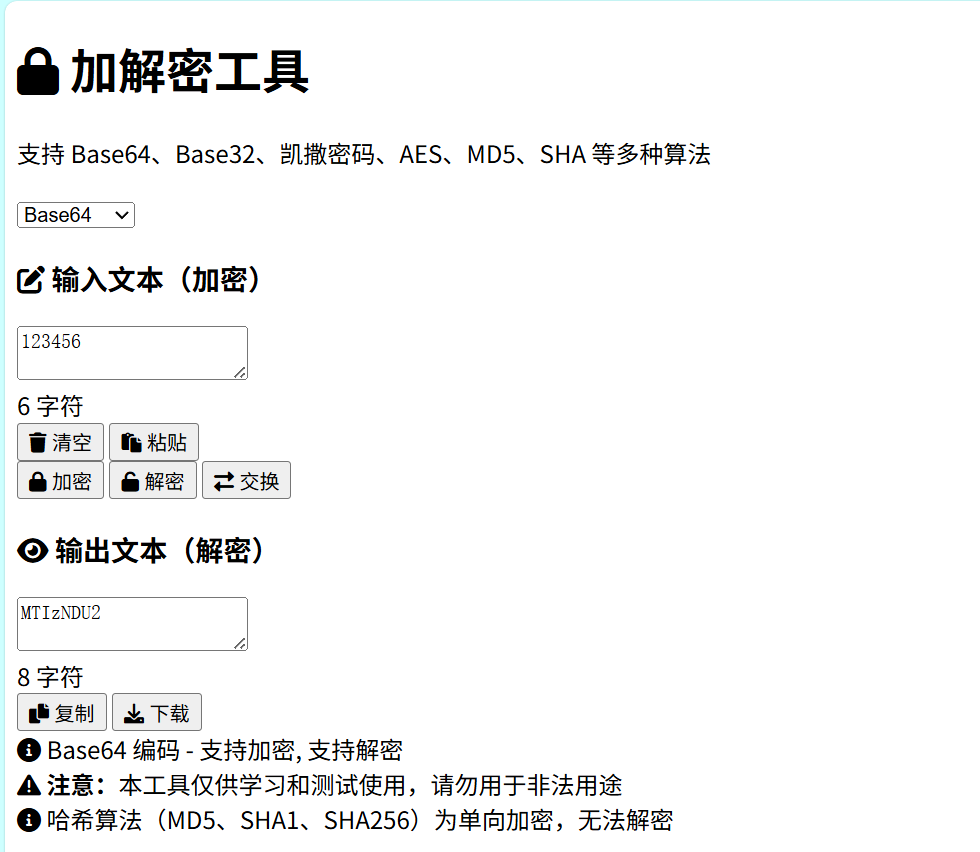
实操验证
这里我通过其他平台的在线工具验证了base64加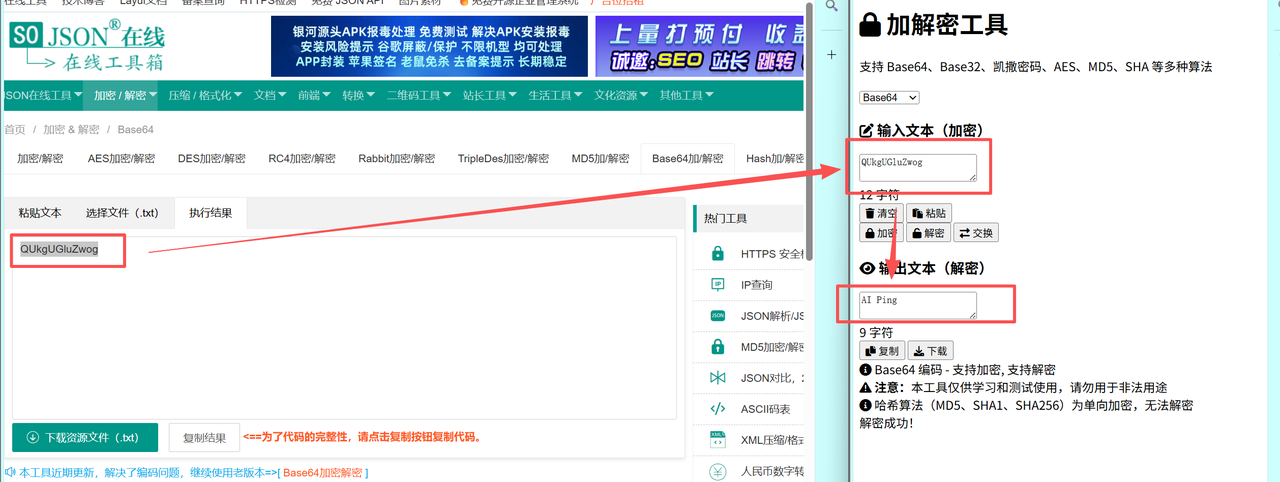 解密的工具,完美解密,效果如下图
解密的工具,完美解密,效果如下图
总结
对于许多开发者和团队来说,接入和使用大模型的过程,往往伴随着一些现实的麻烦。比如,模型那么多,到底哪个最适合自己手头的任务?每次换模型或者试新模型,都要重新研究一遍各自的API文档,调试不同的参数格式。项目真正跑起来后,还要操心并发请求怎么分配、如何管理令牌成本,这些琐碎但又关键的问题,常常会分散宝贵的精力。
AI Ping 所做的,就是把这些共通的麻烦事接手过来。它提供了一个统一的接入点,让你用一个标准的调用方式,就能访问到多个主流模型,省去了反复适配的功夫。平台会根据你的需求、模型的性能和当前的资源情况,帮你智能地调度请求。更重要的是,所有的使用量和成本都清晰可见,让你能心中有数,专注于构建应用功能本身,而不是底层复杂的调用逻辑。这本质上是一个服务于开发者的效率工具,旨在让技术集成变得更简单、更可控。