数据库中的联合查询(多表查询)也是一个很重要的内容
1.联合查询
1.1 概念
**1)**联合查询的目的:查询到数据的完整信息;
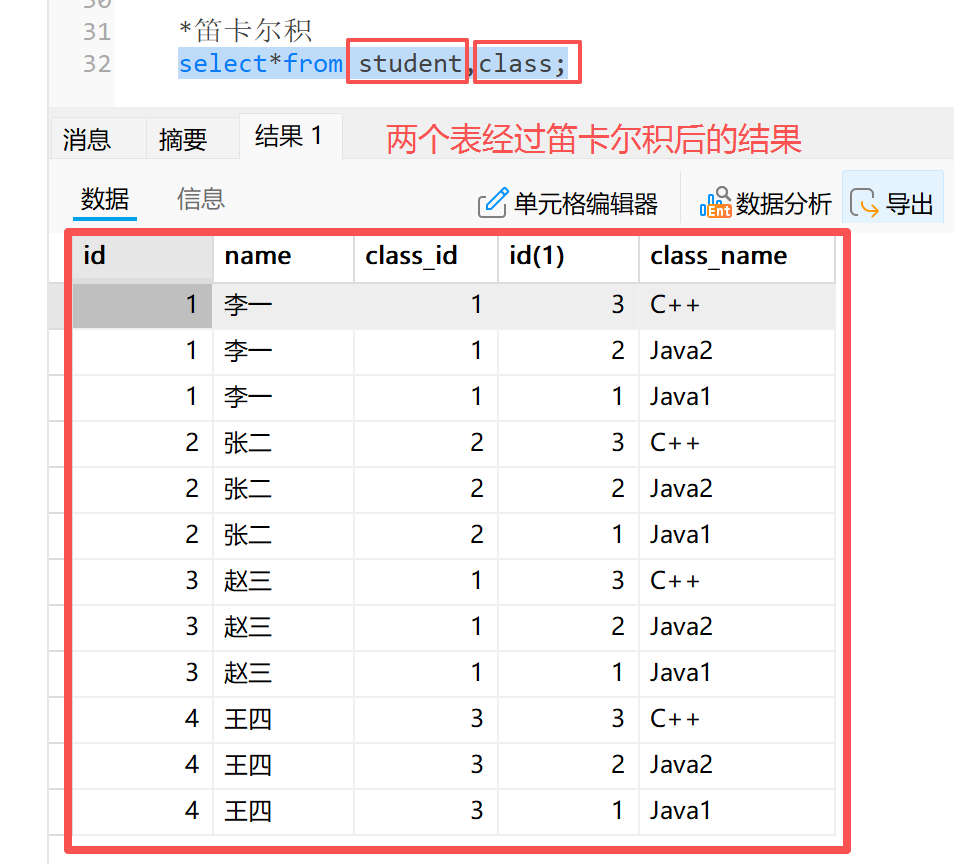
**2)**如何进行联合查询:笛卡尔积
**3)**笛卡尔积是什么?当表 A ( m 行 ) 和表 B ( n 行 ) 进行笛卡尔积运算时,理论上会生成 m * n 行的表
**4)**笛卡尔积在联合查询中的应用:当两个或多个表没有正确连接条件时,通过笛卡尔积可以生成所有可能的组合集
1.2 举例:完整的联合查询过程
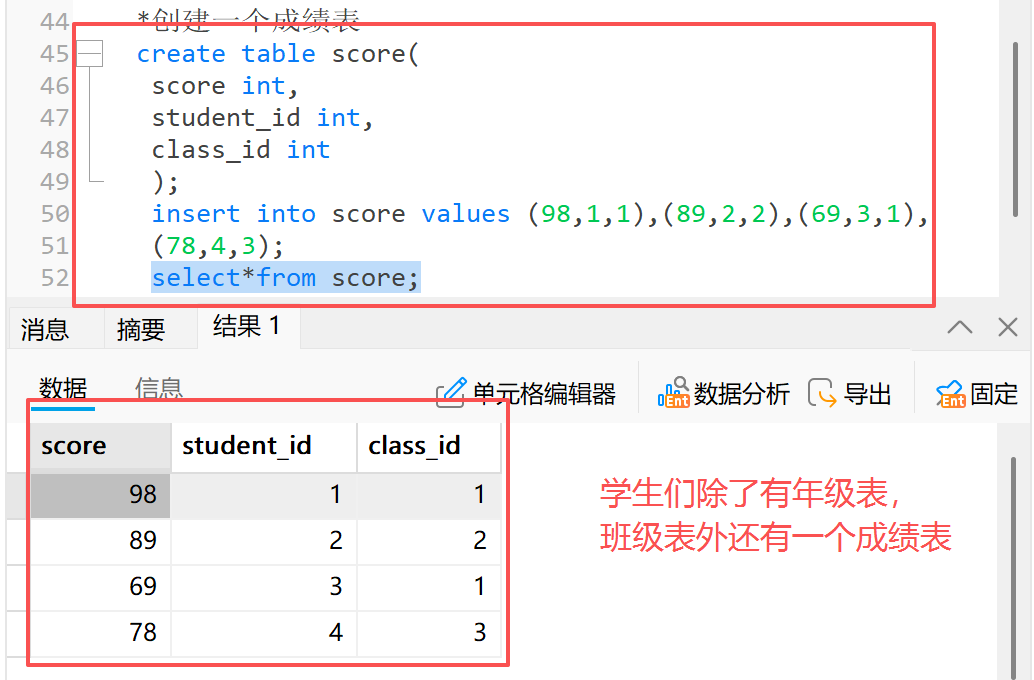
前置准备:准备两个表,分别是学生表和班级表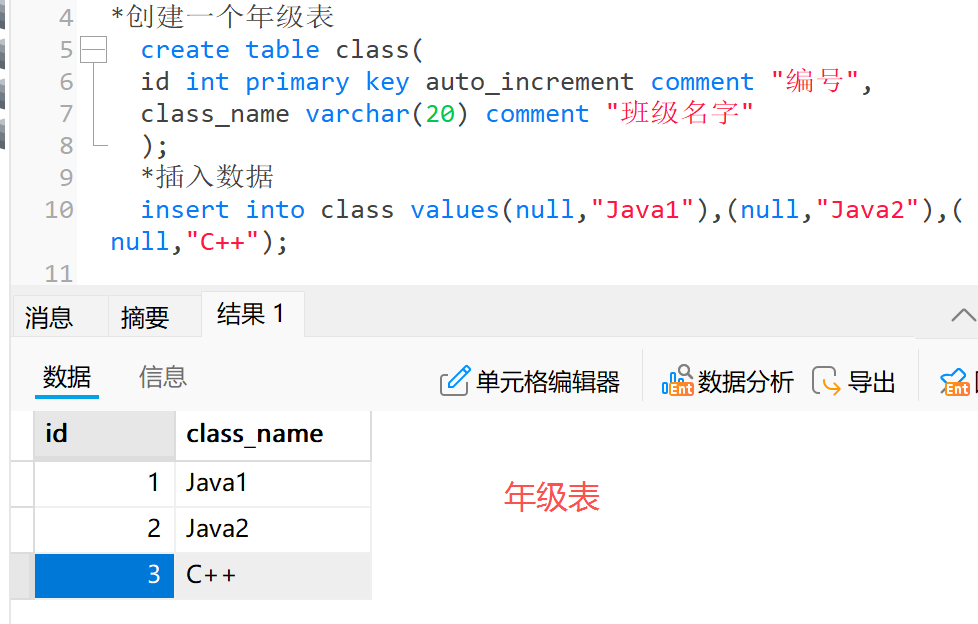
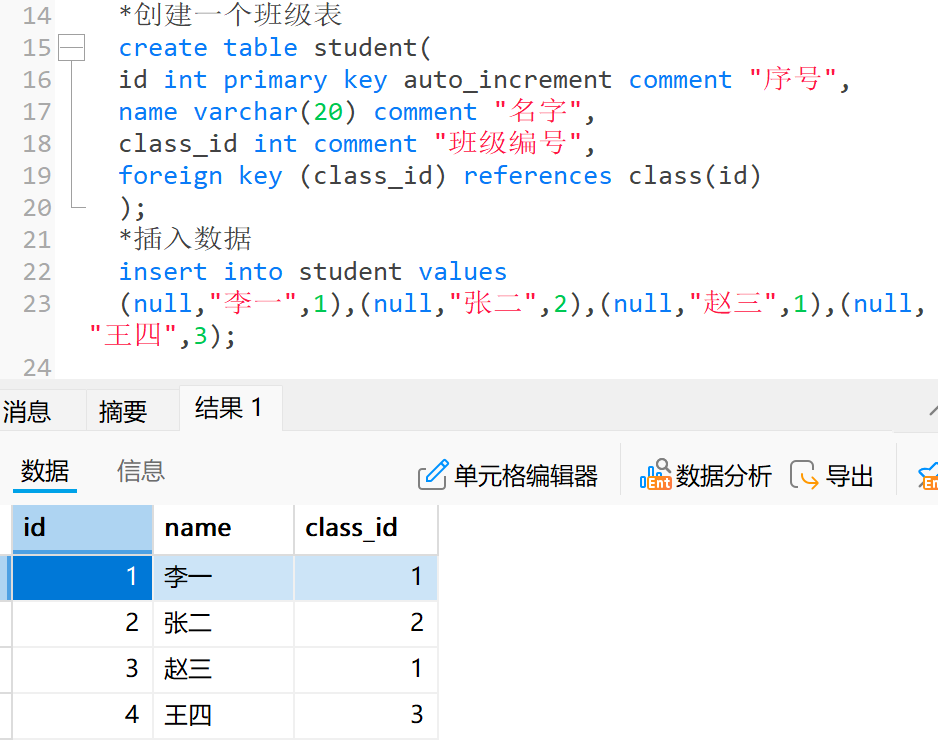 问题:查询学生 id = 4 的学生的详细信息,包括班级信息和个人信息
问题:查询学生 id = 4 的学生的详细信息,包括班级信息和个人信息
**1)**确定参与查询的表:年级表和班级表
**2)**加条件,筛选有效数据( student 表中的 class_id 与 class 表中的 id 列的值相等 )
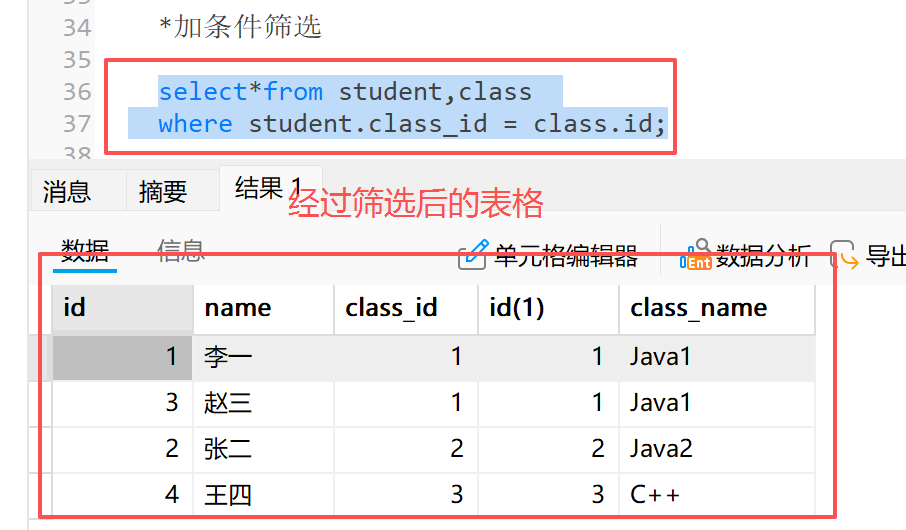
通过 "表名.列名" 可以消除同名列的二义性
2.连接
2.1 内连接
内连接得到的是两个表中同时存在的数据
2.1.1 语法
内连接主要有两种格式:
sql
格式1:
select 字段 from 表1, 表2 where 连接条件 and 其他条件;
格式2:
select 字段 from 表1 inner join 表2 on 连接条件 where 其他条件; 2.1.2 举例:查询 " 王四 " 同学的成绩
**1)**格式 1 :
sql
*格式1
select*from score,student
where score.student_id = student.id
and student.name = "王四";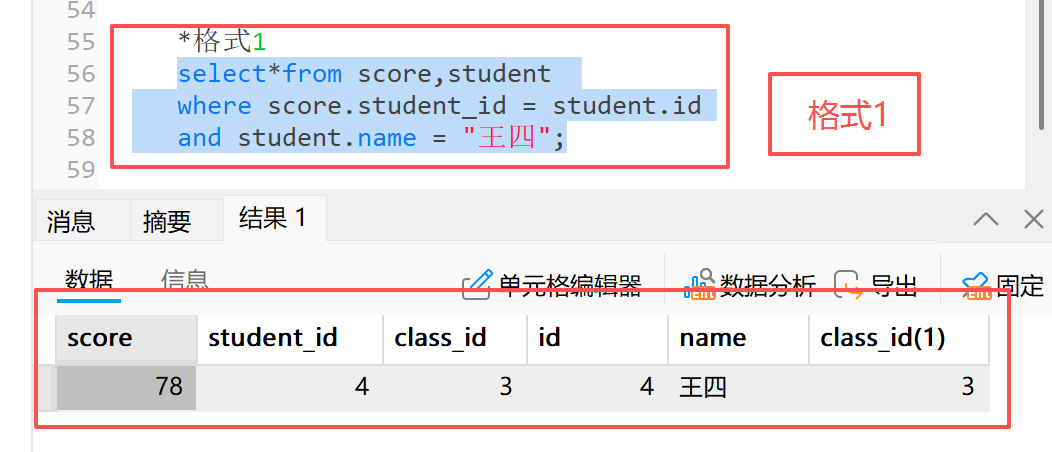
**2)**格式 2 :
sql
*格式2
select*from score inner join student
on score.student_id = student.id
where student.name = "王四";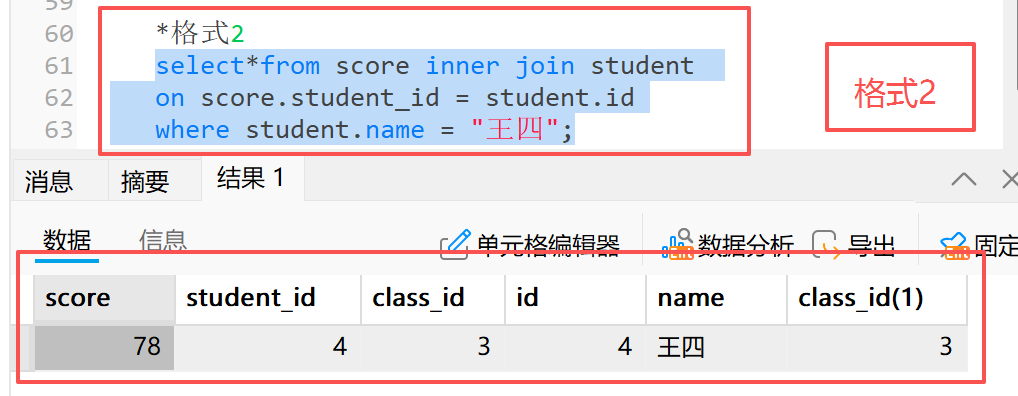
2.2 外连接
外连接又分为左外连接、右外连接和全外连接( MySQL 不支持全外连接,这里不做介绍);对于外连接,只能用join on 这一种格式(以下的示例表格是新创建的,代码放到最后)
2.2.1 左外连接
1) 概念:返回左边表格的全部数据,右侧表格若没有数据则用 null 表示
**2)**语法:
sql
*左外连接
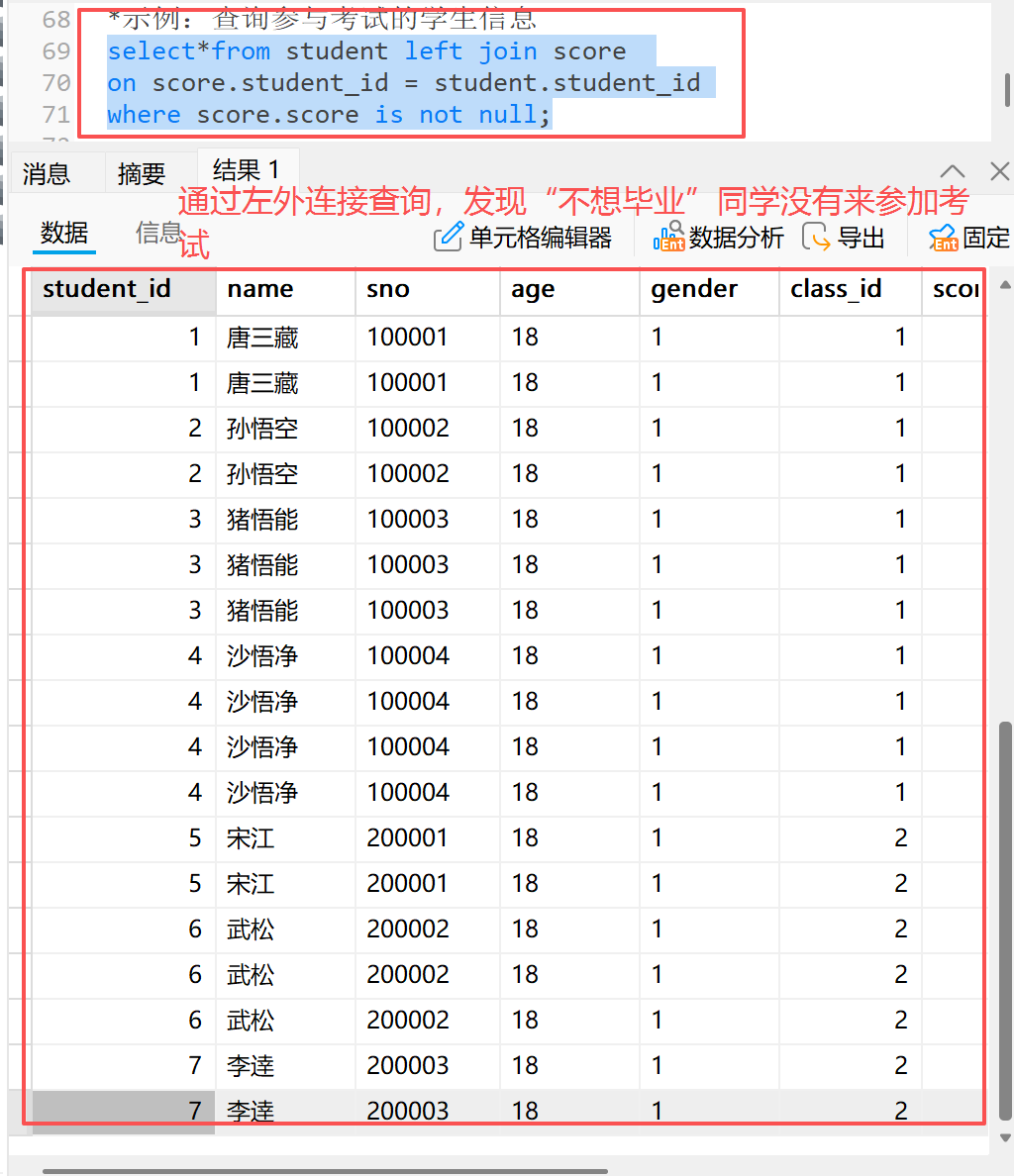
select 字段名 from 表1 left join 表2 on 连接条件;**3)**示例:查询未参与考试的学生信息
2.2.2 右外连接
1) 概念:返回右边表格的全部数据,左侧表格若没有数据则用 null 表示
**2)**语法:
sql
*右外连接
select 字段名 from 表1 right join 表2 on 连接条件;2.3 自连接
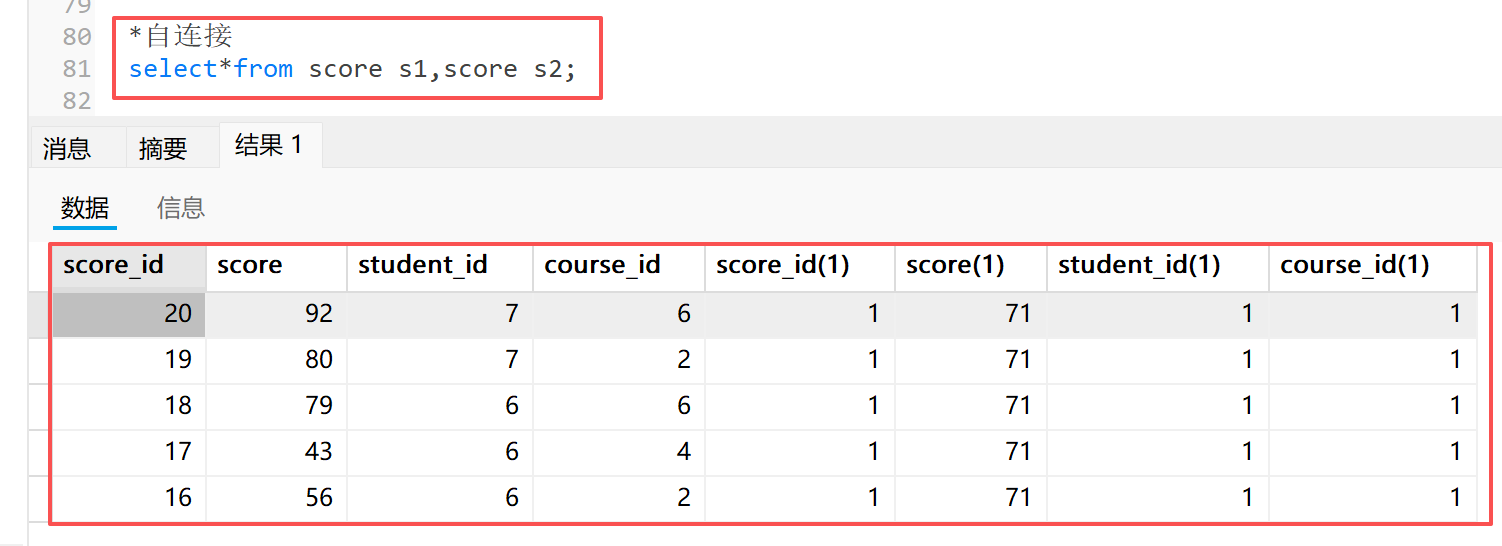
**1)**概念:自连接就是自己与自己的笛卡尔积,本质上是为了 " 把行关系转化为列关系 "
**2)**条件:需要表存在唯一标识符,字段类型匹配,使用别名区分两个列
3.子查询和合并查询
3.1 子查询
把一个select 语句的结果当作另外一个select 语句的条件,也可以理解为嵌套查询
3.1.1 单行子查询
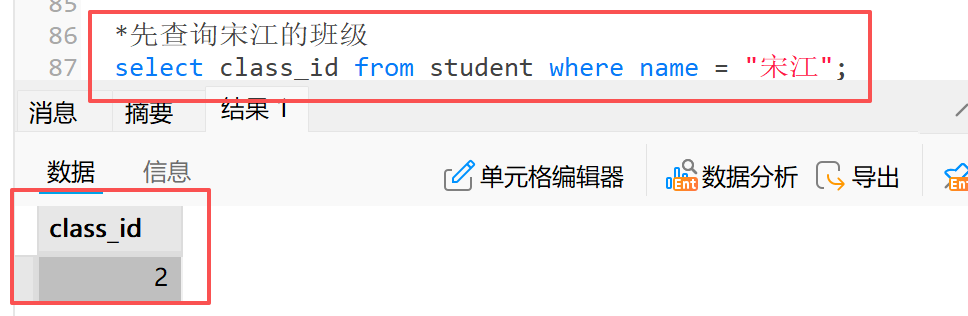
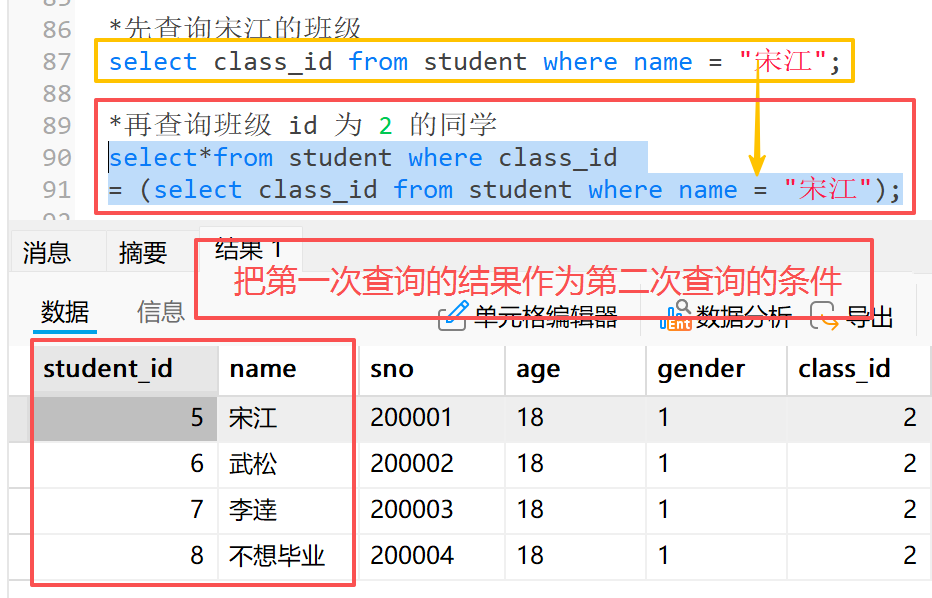
示例:查询与 " 宋江 " 同学同班的同学
**1)**首先先查询宋江的班级
**2)**再查询班级 id 为 2 的同学
3.1.2 多行子查询
嵌套的循环中可以返回多行数据,使用 in / not in
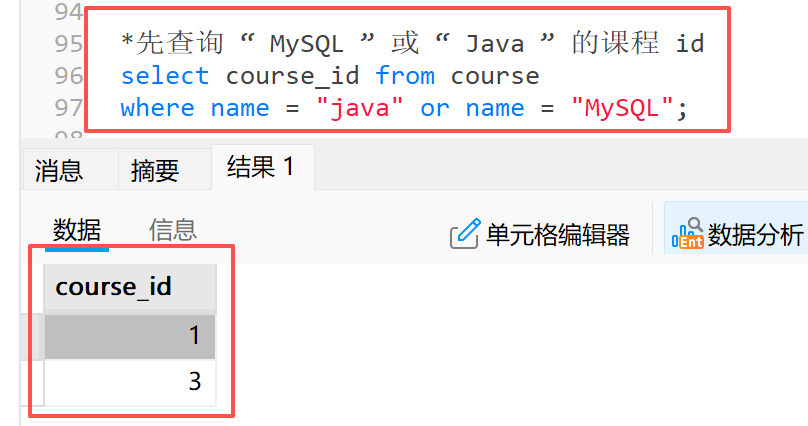
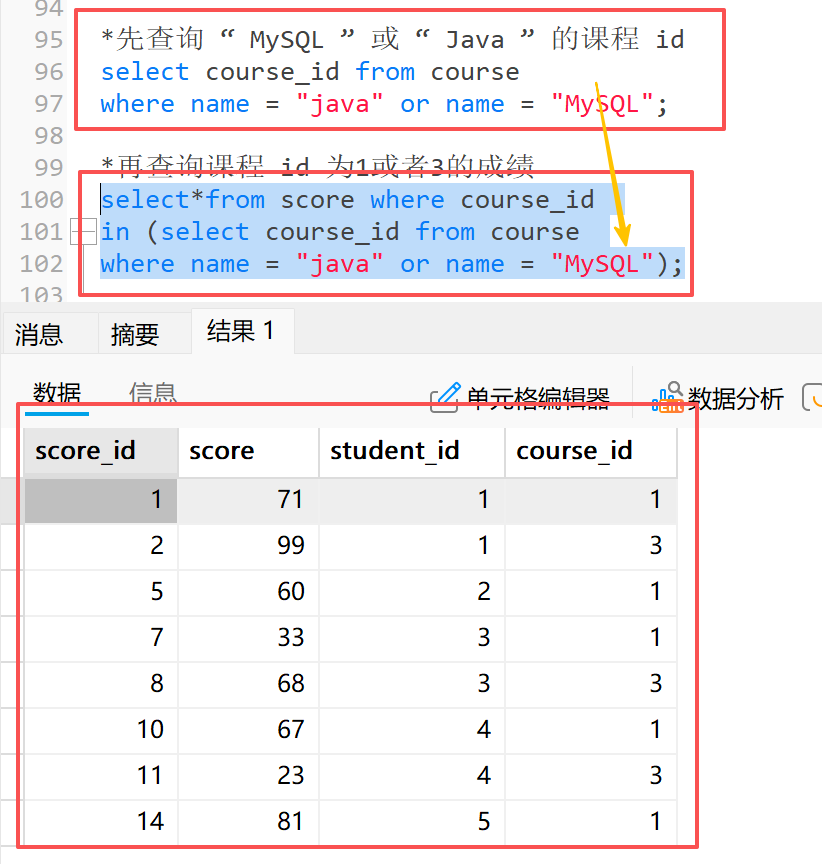
示例:查询 " MySQL " 或 " Java " 课程的成绩
**1)**先查询 " MySQL " 或 " Java " 的课程 id
**2)**再查询课程 id 为 1 或者 3 的成绩
3.1.3 多列子查询
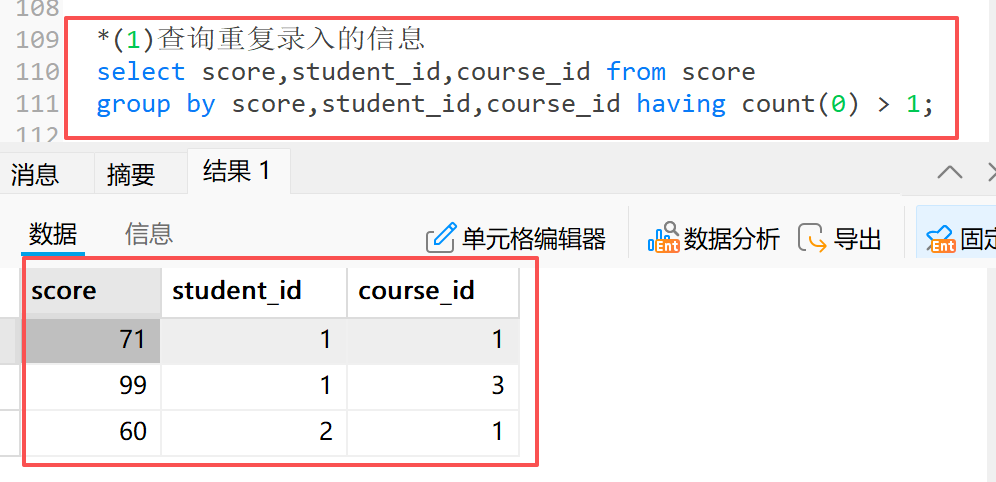
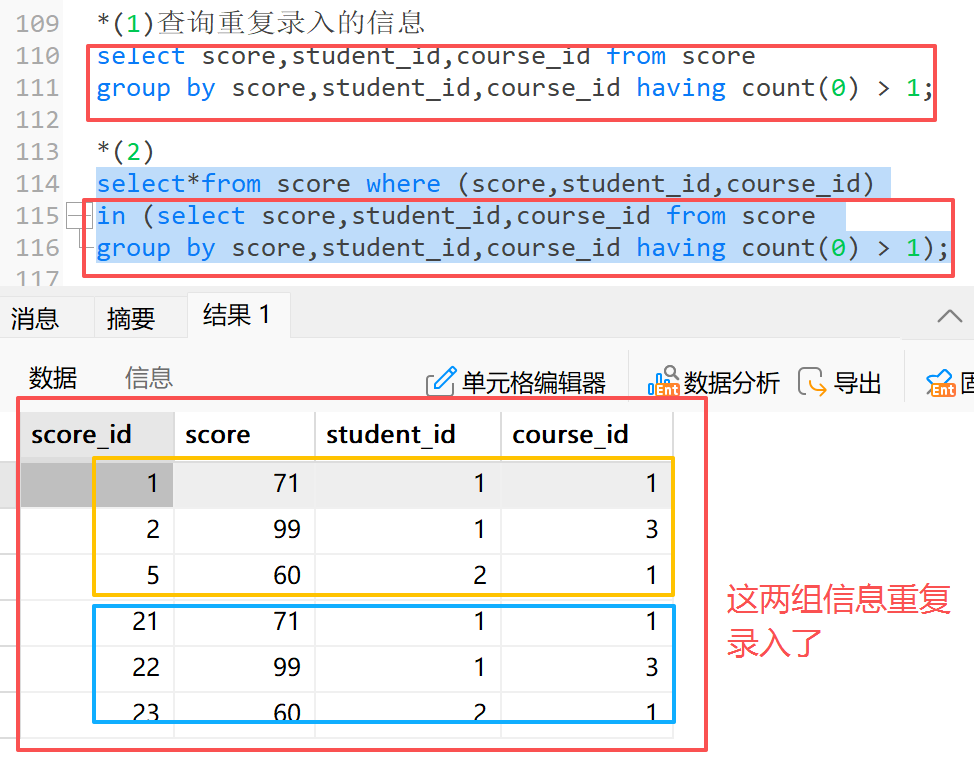
示例:查询重复录入的分数
**1)**查询重复录入的信息
**2)**查询重复录入的所有信息
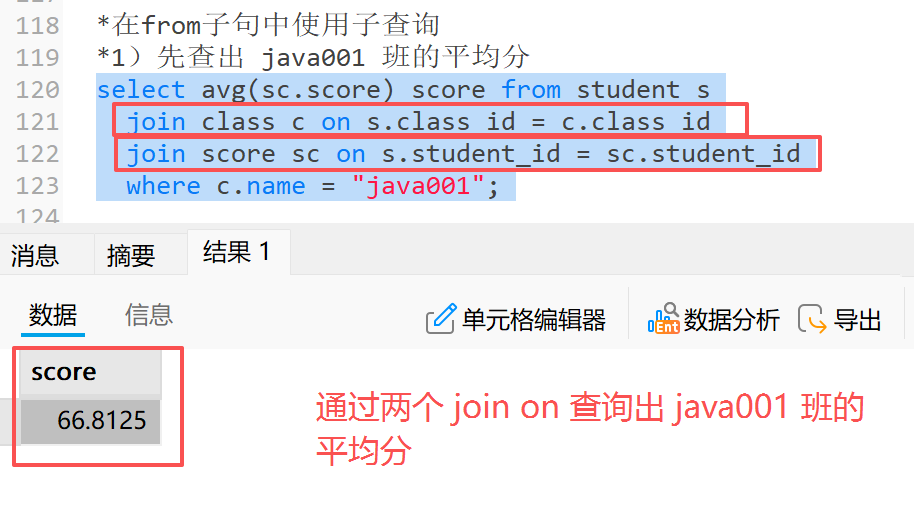
3.1.4 在 from 子句中使用子查询
**示例:**查询所有比 " java001 " 平均分高的班级的成绩信息
**1)**先查出 java001 班的平均分
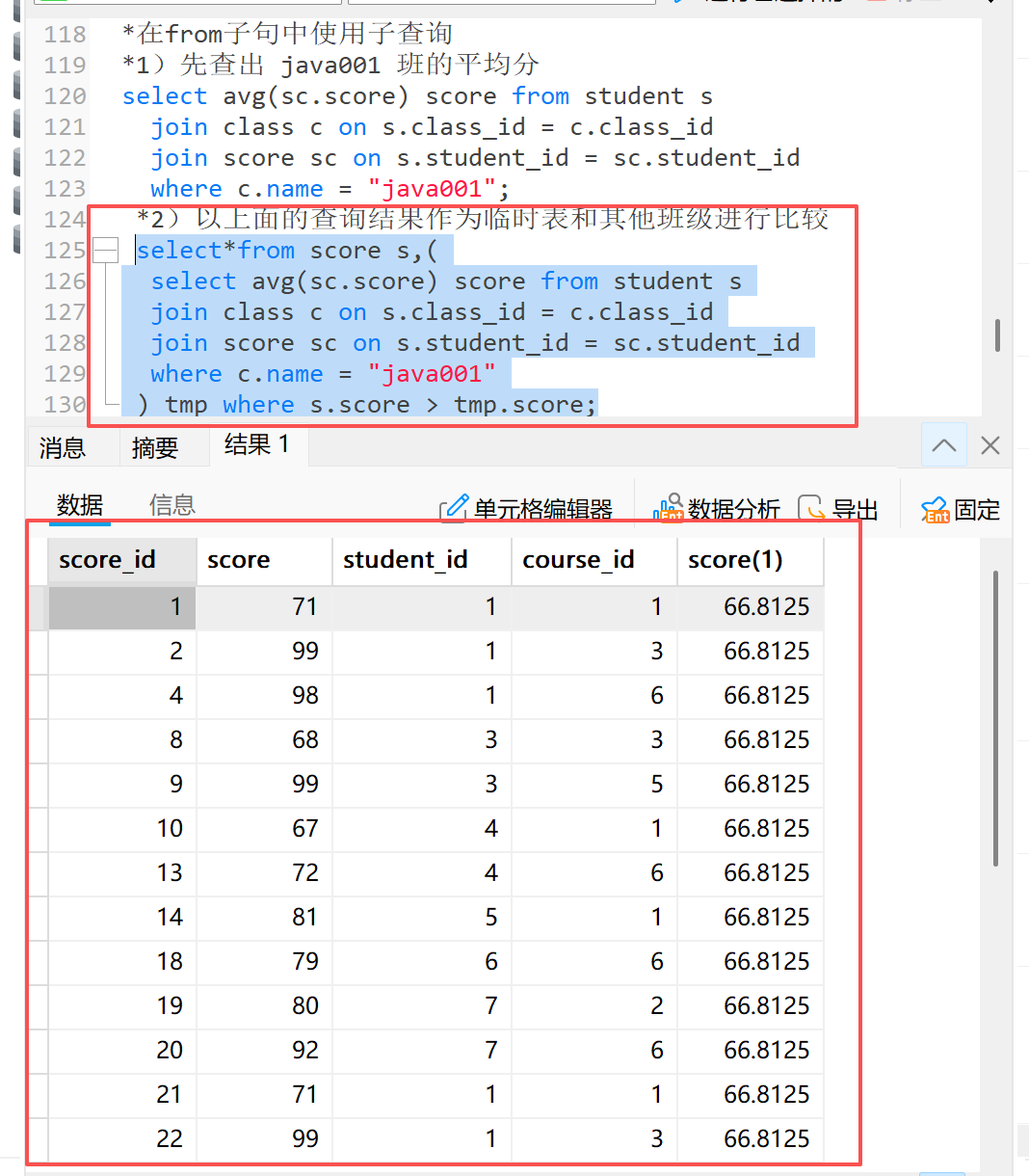
**2)**以上面的查询结果和其他班级进行比较
3.2 合并查询(union)
合并查询可以把两个或者多个查询语句的结果,合并到一起,同时去重
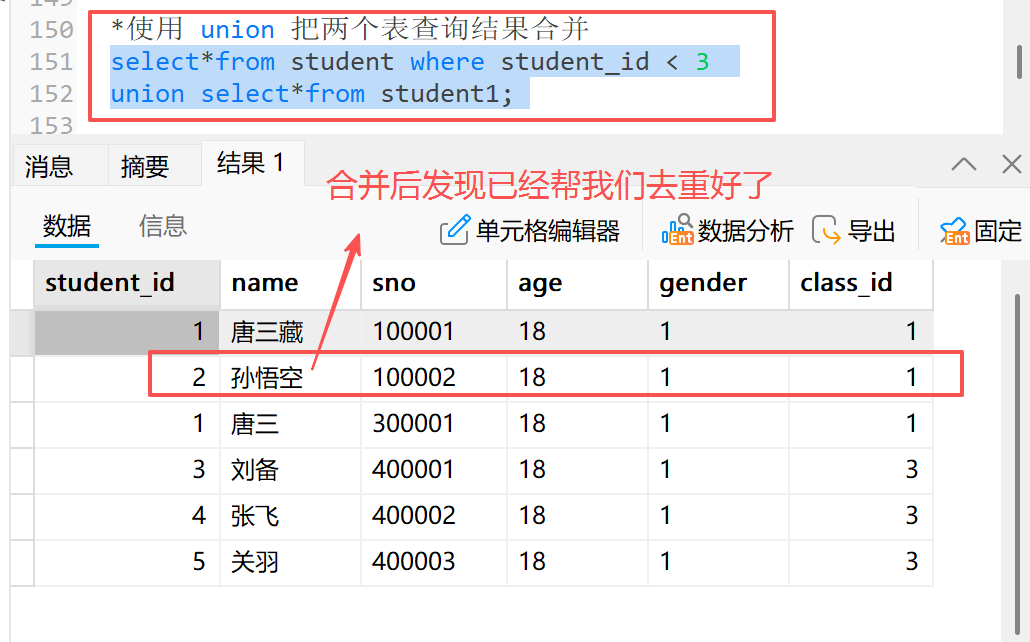
3.2.1 union 合并并去重
示例:查询学生表中 id < 3 的同学和学生表 1 中的所有同学
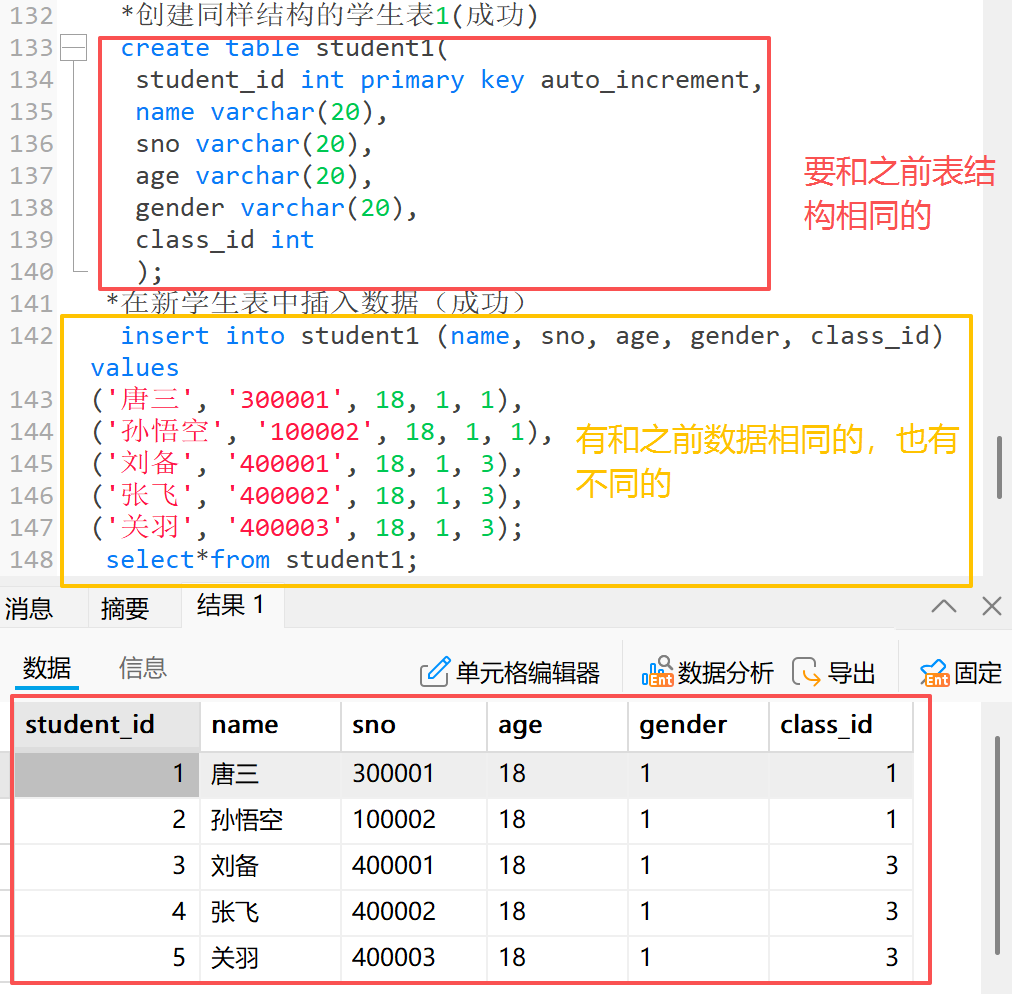
**1)**这里创建了一个新的学生表 1 ,和之前的学生表有相同数据也有不同数据
2) 使用union把两个表查询结果合并
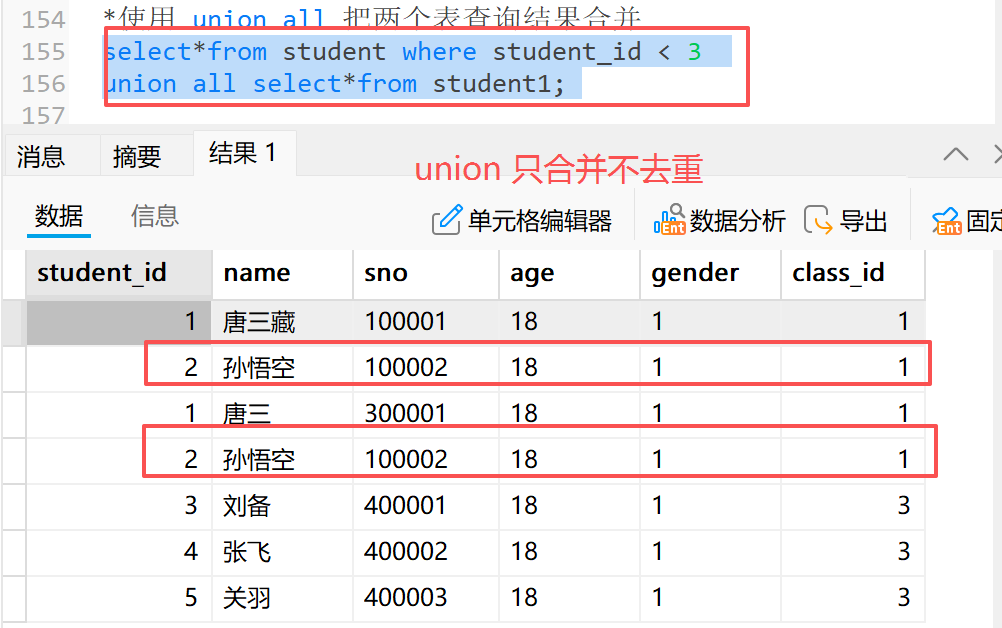
3.2.2 union all 只合并不去重
4.一些扩展问题(答案来自网络)
4.1 NTP 协议是什么?
NTP(Network Time Protocol,网络时间协议)是互联网上最广泛使用的时间同步协议,它的核心作用就是让网络中的计算机、服务器等设备的时间保持一致,精度能达到毫秒甚至微秒级别。
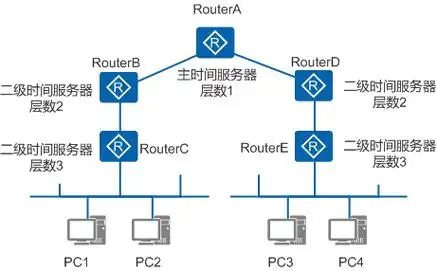
简单来说,它就像是一个"网络时钟",通过分层的时间服务器架构,确保所有设备的时间与权威时间源(如原子钟、GPS)同步,这对于日志记录、金融交易、科学实验等对时间敏感的应用至关重要。
4.2 数据库在后端系统中是运行效率最低的吗?
在后端系统中,数据库操作通常是运行效率最低的环节,因其直接关联数据存储与检索,受硬件资源、索引设计、SQL 优化等多重因素影响,未优化时可能导致性能骤降(如全表扫描效率低至索引查询的千分之一),但通过分库分表、读写分离、缓存机制(如 Redis )等手段可显著提升性能;相比之下,网络通信和业务逻辑的瓶颈更依赖架构设计,优化后对整体效率影响较小,因此数据库是需优先优化的核心重点。
4.3 MySQL 字符串的查询字串的位置函数下标是从1开始?
1) MySQL 系统:
字符串查询位置函数(如 LOCATE、POSITION、INSTR)的下标从 1 开始计数。
2) 其他系统:
部分数据库(如 Oracle)遵循相同规则,但 C 语言等编程语言下标从 0 开始
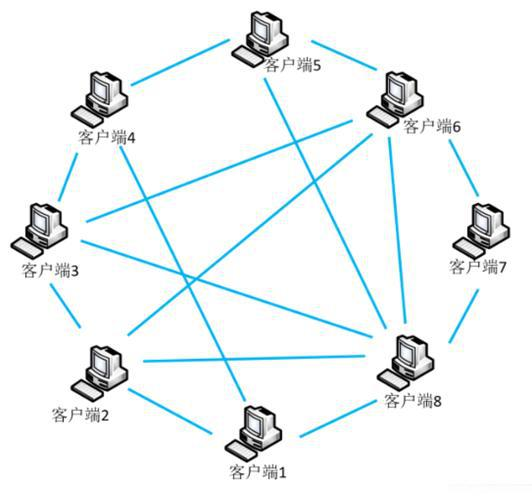
4.4 P2P 是啥?网络通信的两种模型,边缘计算又是什么?
**1)**P2P(点对点)是一种对等网络模型,允许网络中的每个节点同时作为服务提供者和服务请求者,直接进行数据交换和资源共享,无需中央服务器。其特点包括可扩展性、高性价比和隐私保护。网络通信的两种主要模型是 P2P 和客户端-服务器(C/S)模型。
**2)**边缘计算是一种分布式计算模式,将计算任务从云端或中心服务器迁移到网络边缘(如边缘服务器、物联网设备),以减少延迟、提高数据处理速度和节省带宽。其核心思想是利用靠近数据源的计算资源,实现实时分析和决策。
下面是上面演示的代码,可以略过
sql
*创建课程表(成功)
create table course(
course_id int primary key auto_increment,
name varchar(20)
);
*插入数据(成功)
insert into course(name) values("java"),("c++"),("MySQL")
,("操作系统"),("计算机网络"),("数据结构");
*创建班级表(成功)
create table class(
class_id int primary key auto_increment,
name varchar(20)
);
*插入数据(成功)
insert into class(name) values("java001"),("c++001"),("前端001");
drop table student;
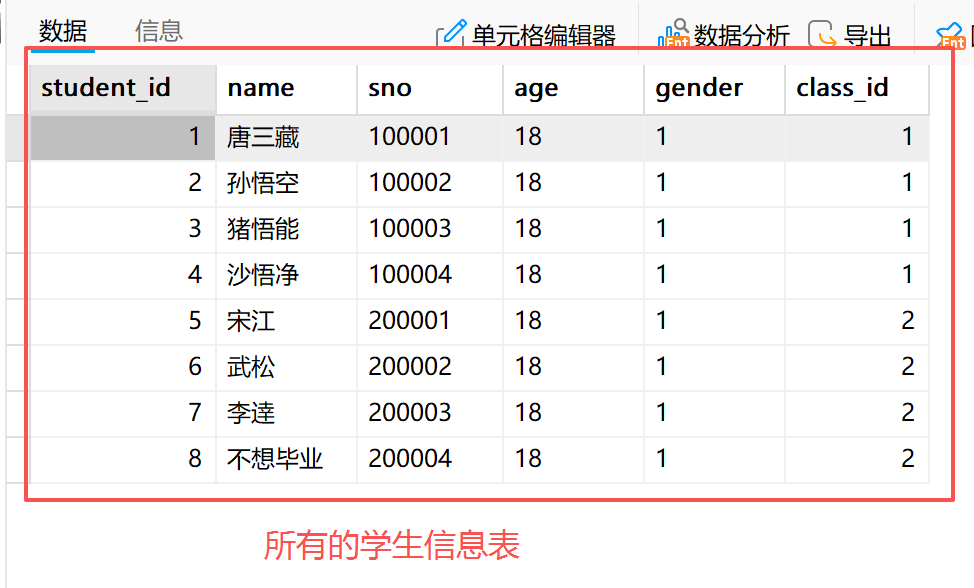
*创建学生表(成功)
create table student(
student_id int primary key auto_increment,
name varchar(20),
sno varchar(20),
age varchar(20),
gender varchar(20),
class_id int
);
*在学生表中插入数据(成功)
insert into student (name, sno, age, gender, class_id) values
('唐三藏', '100001', 18, 1, 1),
('孙悟空', '100002', 18, 1, 1),
('猪悟能', '100003', 18, 1, 1),
('沙悟净', '100004', 18, 1, 1),
('宋江', '200001', 18, 1, 2),
('武松', '200002', 18, 1, 2),
('李逹', '200003', 18, 1, 2),
('不想毕业', '200004', 18, 1, 2);
*创建成绩表(成功)
create table score(
score_id int primary key auto_increment,
score int,
student_id int,
course_id int
);
*在成绩表中插入数据(成功)
insert into score(score, student_id, course_id) values
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
(60, 2, 1),(59.5, 2, 5),
(33, 3, 1),(68, 3, 3),(99, 3, 5),
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
(81, 5, 1),(37, 5, 5),
(56, 6, 2),(43, 6, 4),(79, 6, 6),
(80, 7, 2),(92, 7, 6);
select*from class;
select*from student;
select*from score;
select*from course;
*示例:查询参与考试的学生信息
select*from student left join score
on score.student_id = student.student_id
where score.score is not null;
*示例:查询没有学生的班级
SELECT c.*
FROM student s
RIGHT JOIN class c
ON c.id = s.class_id
WHERE student.student_id IS NULL;
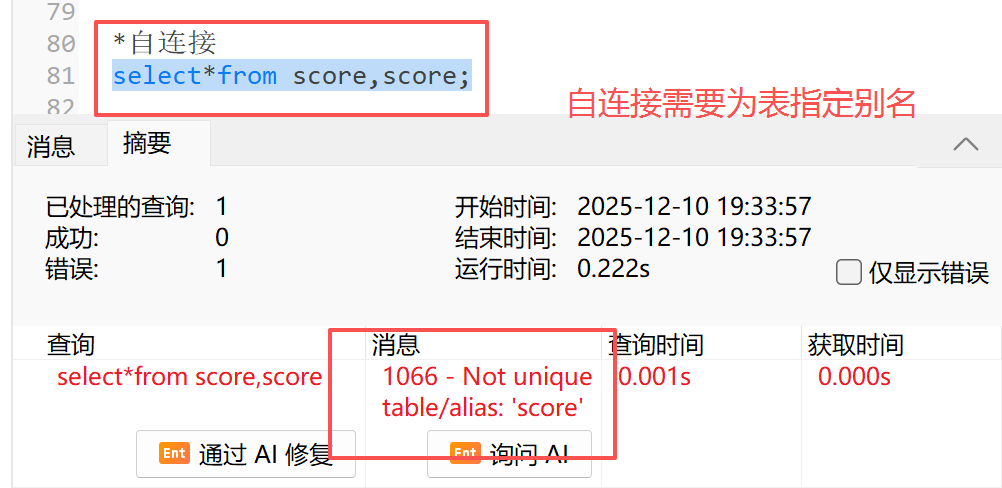
*自连接
select*from score s1,score s2;
*子查询
*单行子查询
*先查询宋江的班级
select class_id from student where name = "宋江";
*再查询班级 id 为 2 的同学
select*from student where class_id
= (select class_id from student where name = "宋江");
*多行子查询
*先查询 " MySQL " 或 " Java " 的课程 id
select course_id from course
where name = "java" or name = "MySQL";
*再查询课程 id 为1或者3的成绩
select*from score where course_id
in (select course_id from course
where name = "java" or name = "MySQL");
*多列子查询
insert into score(score,student_id,course_id) values
(70.5,1,1),(98.5,1,3),(60,2,1);
*子查询中返回多个列
*(1)查询重复录入的信息
select score,student_id,course_id from score
group by score,student_id,course_id having count(0) > 1;
*(2)
select*from score where (score,student_id,course_id)
in (select score,student_id,course_id from score
group by score,student_id,course_id having count(0) > 1);
*在from子句中使用子查询
*1)先查出 java001 班的平均分
select avg(sc.score) score from student s
join class c on s.class_id = c.class_id
join score sc on s.student_id = sc.student_id
where c.name = "java001";
*2)以上面的查询结果作为临时表和其他班级进行比较
select*from score s,(
select avg(sc.score) score from student s
join class c on s.class_id = c.class_id
join score sc on s.student_id = sc.student_id
where c.name = "java001"
) tmp where s.score > tmp.score;
*创建同样结构的学生表1(成功)
create table student1(
student_id int primary key auto_increment,
name varchar(20),
sno varchar(20),
age varchar(20),
gender varchar(20),
class_id int
);
*在新学生表中插入数据(成功)
insert into student1 (name, sno, age, gender, class_id) values
('唐三', '300001', 18, 1, 1),
('孙悟空', '100002', 18, 1, 1),
('刘备', '400001', 18, 1, 3),
('张飞', '400002', 18, 1, 3),
('关羽', '400003', 18, 1, 3);
select*from student1;
*使用 union 把两个表查询结果合并
select*from student where student_id < 3
union select*from student1;
*使用 union all 把两个表查询结果合并
select*from student where student_id < 3
union all select*from student1;