当教育从传统的"黑板+粉笔"迈向"科技+人文"的融合时代,学习空间的意义也在悄然重塑。对新东方而言,校区早已不只是传授知识的教室,而是连接学生、家庭与未来成长的智慧教育社区。在这里,孩子们收获的不仅是扎实的英语词汇或清晰的数学逻辑,更是新东方所倡导的"终身学习、全球视野、全面成长"的教育理念------通过沉浸式课堂互动、个性化学习路径和多元素养拓展,学生能真切感受到OMO(线上线下融合)教学体系带来的学习效率跃升、"新东方云教室"如何实现跨地域优质资源共享,以及AI学情诊断如何将模糊的进步感知转化为精准的成长图谱。新东方正以"教育平权"的初心,把高质量教育资源从地域和阶层的壁垒中解放出来,转化为可体验、可参与、可共创的成长旅程。
这种以学习者为中心的教育革新,让每一所新东方校区都成为智慧教育生态中的活力节点。无论是位于城市核心商圈的学习中心,还是扎根社区的素质成长空间,都在持续沉淀关于学生学习行为、家长服务期待、课程适配效果及区域教育需求的动态数据流。这些数据若仅用于日常排课或招生统计,其深层价值将难以释放;唯有通过标准化、自动化的采集与分析机制,将其转化为结构化的地理信息与教育资产,才能真正赋能战略决策------支撑校区布局的科学规划、服务半径的合理划定、师资与课程资源的动态调配,乃至未来"线上学习---线下实践---家庭教育"三位一体生态的智能协同。这不仅是运营模式的升级,更是新东方向"以数据驱动教育体验进化"迈出的关键一步。
本文旨在通过程序化方式,调用新东方官方公开接口,自动化采集全国新东方校区的结构化信息。利用 Python 的 requests 库发起标准 HTTP GET 请求,可高效获取包含校区名称、所属省市区、详细地址、高德经纬度坐标、营业时间、开设课程类型等字段的 JSON 响应。通过对这些数据的整合与地理可视化,我们不仅能清晰描绘新东方当前"以学生为中心、数字化驱动、场景化落地"的线下教育网络布局密度与区域渗透策略,还可为潜在校区选址、就近报班推荐、区域教研资源精准投放、素质教育生态联动(如与研学营地、国际课程中心协同)提供可量化的决策依据------这正是"用数据理解新东方智慧教育生态"的一次实践,也深刻呼应了新东方"终身学习、全球视野、全面成长"的教育使命与"用心做教育,用爱筑未来"的品牌初心。
新东方官方门店查询入口:上海新东方-综合性学习服务平台-新东方官网
我们在主页下滑找到,"校区和报名点",点击进入就可以看到对应的校区信息;
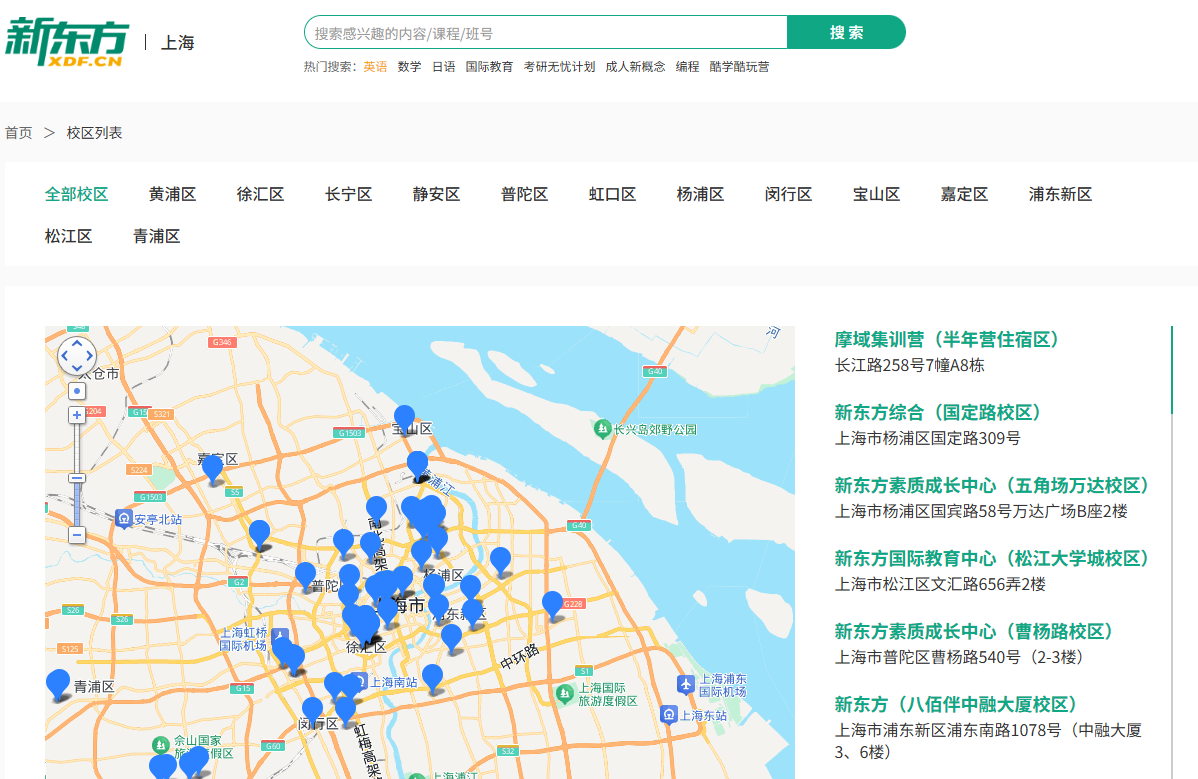
因为新东方不是全国都有门店,所以我们先获取所有有门店的地级市编码;

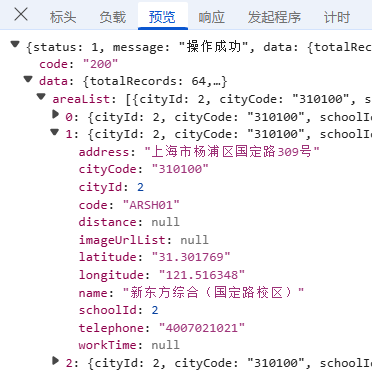
首先,我们找到门店数据的存储位置,然后看3个关键部分标头、 负载、 预览;
**标头:**通常包括URL的连接,也就是目标资源的位置;
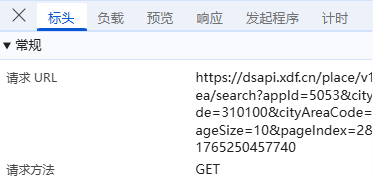
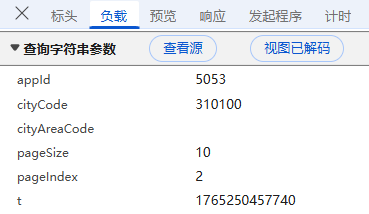
**负载:**对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到新东方的响应请求包括citycode城市编码,pagelndex当前页码等一些负载数据,整体内容没有进行加密;
**预览:**指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据在data里;
第一步:利用requests库发送HTTP请求获取所有地级市级城市名称及编码表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
python
import requests
import csv
url = "https://dsapi.xdf.cn/portal/v1/pc/city/list"
params = {"appId": 5053, "cityCode": "440300", "t": 1765247231812}
headers = {
"sign": "aeef9d96b57f6d186329aaf75083ab1a",
"User-Agent": "Mozilla/5.0"
}
res = requests.get(url, params=params, headers=headers)
data = res.json()
# 自动提取列表(兼容 data 或 data.list)
items = data.get("data") if isinstance(data.get("data"), list) else data.get("data", {}).get("list", [])
# 过滤有效字段
rows = [{"name": i["name"], "code": i["code"]} for i in items if "name" in i and "code" in i]
# 保存 CSV
with open("xdf_cities.csv", "w", encoding="utf-8-sig", newline="") as f:
w = csv.DictWriter(f, fieldnames=["name", "code"])
w.writeheader()
w.writerows(rows)
print(f"已保存 {len(rows)} 个城市到 xdf_cities.csv")数据会以csv表格的形式,保存在运行脚本的目录下,数据标签包括:name(市名称)、code(市编码);
我们得到了所有107个市级行政区编码列表之后,我们就可以通过遍历列表里面的城市数据,进而获取全国的门店信息;
**第二步:**利用requests库发送HTTP请求遍历107个城市编码,并获取所有新东方门店数据,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
python
import requests
import csv
# === 1. 配置请求 ===
url = "https://dsapi.xdf.cn/place/v1/area/search"
params = {
"appId": 5053,
"cityCode": "310100", # 上海
"cityAreaCode": "",
"pageSize": 10,
"pageIndex": 2, # 第2页
"t": 1765273903098
}
headers = {
"sign": "c2d0d5d9c9cc7776ede4af46ca9abd05",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
# === 2. 发送请求 ===
print("正在请求数据...")
response = requests.get(url, params=params, headers=headers)
if response.status_code != 200:
print(f"请求失败,状态码: {response.status_code}")
exit()
data = response.json()
if data.get("status") != 1 or data.get("code") != "200":
print(f"接口返回错误: {data.get('message')}")
exit()
area_list = data["data"]["areaList"]
print(f"获取到 {len(area_list)} 条记录")
# === 3. 提取指定字段 ===
fields = ["code", "name", "telephone", "longitude", "latitude", "address"]
rows = []
for item in area_list:
row = {
"code": item.get("code", "") or "",
"name": item.get("name", "") or "",
"telephone": (item.get("telephone", "") or "").strip(),
"longitude": item.get("longitude", "") or "",
"latitude": item.get("latitude", "") or "",
"address": item.get("address", "") or ""
}
rows.append(row)
# === 4. 保存为 CSV ===
output_file = "xdf_store.csv"
with open(output_file, "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fields)
writer.writeheader()
writer.writerows(rows)
print(f"数据已成功保存到: {output_file}")获取数据标签如下,code(门店id)、name(门店名称)、telephone(门店电话)、address(门店地址)、lng & lat(地理坐标),其他一些非关键标签,这里省略;
这里有1个tips,就是在运行脚本之前,需要同时替换自己查询页面里面的 "pageIndex" 页码、 "t" 时间戳、 "sign" 标签,"citycode"城市编码,这4个参数,才能成功运行脚本,而且还有时效性,但是这里倒是任一一个页码里面就有当前城市的全部门店数据,所以只要挑一页,运行即可;
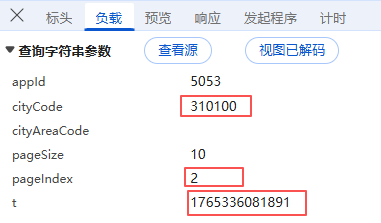
因为每个城市的参数不一样,所以不能直接使用同一个参数访问其他城市数据,所以只能一个个城市复制对应页码、时间戳、标签、城市编码四个参数进行替换,来进行访问,107个城市都是如此,emmm,暂时没想到便捷的方法~
第三步: 坐标系转换,由于新东方门店数据使用的是百度坐标系(BD-09),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从BD-09转换为WGS-84坐标系。我们可以利用coord-convert库中的bd2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的门店坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
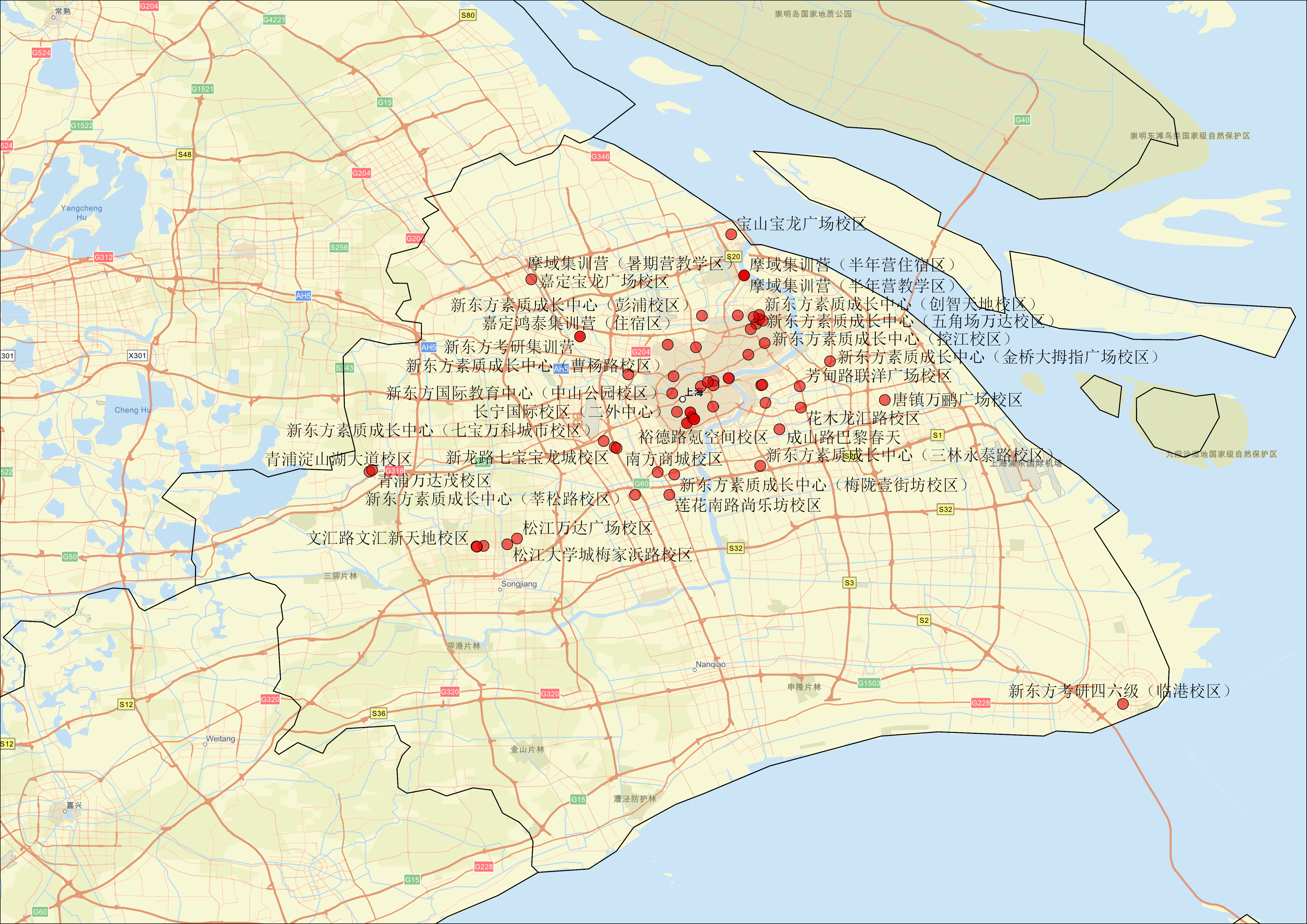
接下来,我们以上海新东方门店分布情况为例,进行看图说话:
从这张上海新东方门店分布图 可以看出,其布局呈现出高度集中的城市核心区特征,并以"中心辐射、多核联动、梯度覆盖 "为基本逻辑。整体来看,门店密集分布在浦东新区 和黄浦区 等传统教育消费高地,尤其在陆家嘴金融贸易区、世纪大道沿线、南京西路商圈以及徐汇滨江带 形成多个高密度集群。这些区域不仅是上海的经济与文化中心,也是高端住宅区、国际学校和外籍人士聚集地,家庭对优质教育服务的需求旺盛。数据显示,仅浦东新区就占据了全市门店总数的近40%,而黄浦、徐汇、静安三区合计占比超过35%。这种"资源向高价值城区倾斜"的策略,既保障了品牌影响力,也提升了单店运营效率。
浦东新区是新东方在上海的战略重心 ,其门店布局不仅数量最多,且呈现明显的功能分区趋势。例如,在张江高科技园区周边 ,有多家校区围绕地铁2号线和16号线站点设立,服务于大量科技企业员工家庭,主打"学科+素养双轨制 "课程体系;而在前滩国际商务区 ,新东方则推出了融合艺术、STEAM与国际化课程的综合学习中心,定位中高端家庭,强调"全人成长 "理念。此外,世博板块 依托城市更新红利,成为新的教育热点区域,部分校区已入驻大型商业综合体(如前滩太古里、世博源),实现"教育+生活+社交 "一体化场景体验。值得一提的是,金桥、唐镇等成熟居住区 也设有多个网点,反映出新东方对"社区渗透型服务网络"的重视------通过缩短通勤距离,提升家长接送便利性,增强用户粘性。
值得注意的是,尽管市中心区域门店密集,但新东方并未忽视郊区潜力市场 的长期布局。例如在闵行区 ,门店沿地铁1号线、10号线延伸,覆盖莘庄、七宝、虹桥商务区等人口密集地带,满足大量刚需家庭的学业辅导需求;嘉定新城 和宝山顾村 等地也设有独立校区,选址靠近大型住宅项目或交通枢纽,体现了"地铁+教育 "的协同开发模式。更值得关注的是,松江大学城 附近有一处显著网点,主要面向高校学生群体,提供考研、留学语言培训等成人教育服务,拓展了品牌在非K12领域的影响力。而在奉贤、崇明等远郊区域虽仅有零星布局,但其选址均位于政府重点规划的新城或生态宜居区,显示出新东方对未来人口迁移趋势的前瞻性判断------即随着城市空间外扩,教育需求也将随之延伸。
新东方在上海的门店布局不仅是一张地理坐标图,更是一幅教育需求与城市发展深度融合的地图 。它清晰揭示出:优质教育资源正向城市核心与新兴增长极双轮驱动 ,同时通过科学布点实现"从城市中心到社区末端 "的无缝衔接。这一格局既反映了新东方在资源调配上的系统性思维,也为未来在其他城市的扩张提供了可复制的"智慧教育网络模型 "。更重要的是,每一个红色标记背后,都代表着一个家庭对未来的期待,一次孩子成长的起点,一种"用教育点亮人生"的信念践行。这正是新东方始终坚守的初心所在。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。