 "记忆"是AI-Agent开发中最核心、也最具挑战的一环。
"记忆"是AI-Agent开发中最核心、也最具挑战的一环。
这几乎是业界共识。
从LangChain、MemGPT/Letta、Mem0到AWS Bedrock AgentCore、各类调研论文都反复强调:
没有强大记忆的Agent,顶多是个"健忘的工具调用器";有了它,才真正从"聊天机器人"进化成能持续学习、个性化、长期规划的智能体。
最近互联网上热度稳居第一的 OpenClaw 成功的一个核心原因,正在于其强大而巧妙的记忆系统。
一、LLM没有记忆
大语言模型(LLM)本质上是无状态(stateless)的:
你每次调用它的聊天,它都只看当前Prompt,完全不记得上一次说了什么,无一例外!
你说:"你好,我是李雷。"
LLM回:"你好李雷,有什么是我可以帮助您的吗?"
你说:"告诉我,我叫什么?"
LLM回:"抱歉,我不知道您的姓名。"
如果你尝试过直接通过API直接和各类LLM对话,一定知道它们是完全没有记忆的。
这时候有人会很疑惑:"春哥,不对啊,我和某包/某问/某宝对话的时候,它们分明是有记忆的。"
没错,那是因为这些聊天窗口和APP,本质已经做了一定程度的优化和简单记忆,简单来说,你和它的每次对话,实际上发给LLM的消息,包含了你们的整个聊天记录。
- 你看到小美:"小美你好,我是李雷。"
- 小美回复:"李雷你好,我是小美。"
- 这次你学聪明了,给递过去一个清单,上面记载了你们刚才的聊天记录,顺便你问:"你复述一遍,我是谁?"
- 小美微笑:当然,你是李雷。
没错,你现在用到的看起来有记忆的LLM 聊天工具,其实每轮会话都把所有聊天记录都塞进去。

二、为什么说"记忆"是最核心的一环?
记忆模块正是把LLM从"单次响应机"升级成"有状态智能体"的关键桥梁,它赋予Agent以下三种核心能力:
-
经验积累:能记住错误与成功,是智能的基本要求。无需多言。
-
环境探索与适应: 根据历史记录决定下一步行动。
比如,推荐餐厅时知道"你上周吃川菜很开心",就会优先推辣的,而不是每次都从零猜。
-
知识抽象与泛化: 从具体交互中提炼高层次偏好/规则。
"春哥喜欢吃辣→周末喜欢重口味→下次旅行推荐火锅店"。这才是真正的"自我进化"。
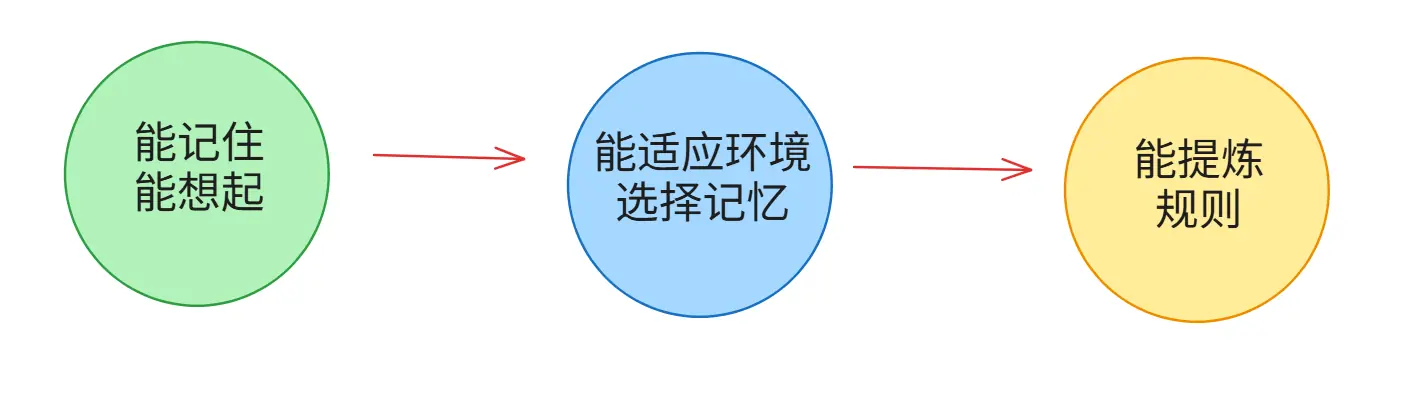
简单来说:
没有记忆的Agent每次都"从零开始",无法个性化、无法多轮连贯、无法长期优化。
而有了记忆的Agent真正具备了:感知-记忆-规划-行动-反思的闭环,成为可信赖的"数字伙伴"。
这也是为什么几乎所有成熟Agent框架(ReAct、Reflexion、Generative Agents、Mem0、Letta等)都把Memory列为与Planning、Tool Use并列的核心模块之一。
AWS的 Agentic AI 实践系列甚至直接说:
"记忆系统是为了克服LLM的根本局限性。"
三、为什么它同时是最有挑战的一环?
记忆不是简单"存下来就行",而是一个动态、智能、全生命周期系统,涉及"写-管-读"三大难题,远比选个大模型或加个工具调用难得多。
这涉及到了几个核心矛盾:
3.1 规模与效率的根本矛盾
首先,记忆会堆积增长。
第一轮会话是输入1条,输出1条,公计2条。
第二轮会话,则需要输入3条(包含新的输入和历史的2条),输出1条。
第三轮:输入5条......
如此一来,输入的Token长度,会迅速膨胀。
Token长度膨胀必然带来几个问题:
- 成本变高,Token就是金钱
- 性能变差,Token越长,性能越差
- AI变笨,Token过长会稀释AI的注意力,让它无法把握重点
- 超出最大Token限制

即便使用了我们前面讲到的RAG系统,RAG的准确检索率也会成为新的问题。
3.2 "写什么"与"怎么写"极难决策
能不能直接把你和豆包的对话过程完全记下来作为RAG文档的原材料呢?
答案是不能。
举个例子: 如果聊天记录里包含了大量关于 "xx爱吃辣椒"的讨论,比如:"刘备爱吃辣"、"关羽爱吃辣"等一堆人爱吃辣的对话,再入库"我讨厌吃辣"这一条数据。
在进行RAG检索"用户是否爱吃辣"这条信息时,就非常容易在检索出的前几条全是"xx爱吃辣"这种数据,从而完全污染检索结果。
得到了完全相反的结论。
所以,目前主流的做法是,在做长期记忆时,并不是无脑入库,而是必须经过加工处理:
- 提取有效信息
- 压缩成精炼的文本
- 抽象成知识图谱
目前Agent社区的主流做法依然是:
- 短期记忆放上下文
- 长期记忆放向量库+图数据库
但如何自动判断"这个事实值得永久保存"仍是开放问题,需要继续进行探索。
3.3 想说忘记不容易
业界常说:"教Agent记住不难,教它正确遗忘才是最难的。"
以下是一些目前业界常用的手段:
-
需要反射(Reflection):定期让LLM对记忆做总结、合并、冲突解决。
-
需要遗忘机制:模拟人类艾宾浩斯遗忘曲线,按重要性×时间衰减自动删除低价值记忆。
-
还要处理记忆漂移(Memory Drift):业务规则变了,老记忆不能继续误导新决策。
总的来说,这一步就是以真实的人类记忆为参考,想方设法让AI的记忆力和人类相似,让它们忘掉不重要的事情,把发生的多个事情总结成一条记忆,并在只记住新的规则。
所以,遗忘与选择正确的记忆,是一门手艺活儿。
3.4 检索的精准性与实时性
当我们人类在面对一个任务时,本能地就会寻找记忆里对于类似事情的处理经验:
- 当时我做了XX事情,非常有效
- 某次我做了XX事情,结果惨败
- 我某次成功做成了,前提是我先做了XX,再做了XX
- 还有次,我做的事情虽然不是和本次一模一样,但也可以参考......
这是生物生存的本能和经验的意义所在,而这些事情的本质,正是最记忆的检索,可以说检索能力正是很多时候区分人与人差距的核心所在。
因此,Agent开发也必须面临同样的问题:
如何尽可能搞效率、高准确性、能关联检索地找到那些和当前任务相关的记忆。
实际生产中,检索质量直接决定Agent是否"靠谱"。
坏检索 = 自信的错误决策。
3.5 跨会话一致性
假设有一位年轻女性在和Agent对话。
1月1日,她说:我是素食主义者。
一个月后的2月1日,她突然说:今晚想吃牛排。
如果Agent傻乎乎地直接用第1次的记忆回答:"您是素食主义者,我不推荐牛排",用户会很尴尬,这虽然准确检索到了记忆,但显然不是优秀的策略。
但如果Agent完全忘记了1月1日的记忆,又会显得"健忘"。

正确的做法是:
- Agent必须能检测到冲突(新信息和老记忆矛盾)
- 然后智能解决:要么更新记忆("用户现在偶尔吃肉了"),要么问用户确认("您之前说过是素食主义者,现在想吃牛排吗?口味有变化吗?")
这被称为"跨会话一致性"。
做不到的话,用户会觉得Agent"精神分裂"或者"记性很差",体验极差。
3.6 数据隐私性
意思就是:
用户随时有权把自己产生的所有记忆数据删掉,而且必须删得干净、删得可控。
无论是从法律法规层面,还是用户体验层面而言,这都是非常必要的场景。
举个例子:
- 用户跟Agent聊了半年的情感经历、身体健康数据、工资数字......
- 某一天用户说:"把我所有关于前任的记忆都删掉!" 或者 "把我的健康数据全部删除!"
- Agent必须能精准删除指定部分(而不是一股脑把所有记忆清空),同时还要保证剩下的记忆依然一致。

这在技术上非常难:
- 记忆往往是碎片化存储在向量数据库里的(不是一条一条完整的对话)
- 删除一条"事实"可能会影响其他相关记忆(连锁反应)
- 还要记录删除日志、支持用户查询"我哪些数据被记住了?"
正因为这些,Reddit、LinkedIn、X上开发者反复吐槽:"Memory才是Agent生产落地的真正瓶颈,框架和模型都不是"。
四、当前主流解决方案与趋势
4.1 Mem0(目前最受欢迎、采用率最高)
GitHub 47K+星,1300万+下载,Q3 2025单季1.86亿次API调用。
可以说,Mem0 是2026年事实上的"内存标准"。
亮点:
- 混合存储:向量 + 图谱(Graph Memory) + 键值(实体关系追踪超强)
- 记忆压缩引擎:自动把聊天历史压缩成极致优化的表示,token成本降低90%、延迟降低91%
- 支持事实(facts)/情节(episodic)/语义(semantic)/程序(procedural)/关联记忆
- 自改进机制 + 冲突自动解决 + 包含/排除规则(隐私神器)
4.2 Letta(原MemGPT,虚拟内存分页鼻祖)
定位:"LLM操作系统"风格,最像人类长期记忆的管理方式。
- 代码Agent专属,git版本化 + 并行协作
- 支持多并发会话共享记忆(同一个Agent同时跟10个用户聊,记忆互通)
- 记忆优先的编码Agent,在Terminal-Bench上拿下开源第一
- Agent自己管理内存(读/写/分页/压缩),支持无限上下文。
4.3 LangMem(LangChain生态专属,长记忆SDK)
和LangChain以及其底层LangGraph深度集成,使用起来最方便。
三大记忆类型:
- Semantic(事实/知识)
- Episodic(经历/事件)
- Procedural(流程/技能)
4.4 Zep(时序知识图谱王者)
核心武器:Graphiti 时序知识图谱(双时态模型:事件发生时间 + 记忆写入时间)。 亮点:
- 长时序任务准确率领先(LoCoMo基准单次检索80.32% @ 189ms)
- 自动标记过时事实、追踪关系演化("用户以前喜欢A,现在改B")
- Entity Types(结构化实体)支持自定义领域知识。
适合:企业级、需要追踪"变化"的场景(CRM、合同管理、供应链Agent)。
一句话总结现状:
记忆层已经从"可选项"变成了Agent基础设施的标配,就像2024年的向量数据库一样。
- Mem0最通用
- Letta最极客
- Zep最企业
- LangMem在LangChain技术栈下最省心。
五、小结
本文,我们只是从概念层面稍微了解了一下Agent开发中,"记忆"的难顶之处。
但是纸上得来终觉浅,我们还得真正实操才能感受到它的核心和难点所在。
我们将撰写demo,并实际去吃一吃记忆的苦。
但在此之前,我们还得先认识一下LangChain,因为这是目前最火的Agent开发框架,我准备使用 LangChain + LangMem 这套最热的组合。
敬请期待!
