概述
Redis 主从复制是一种数据同步机制,它允许一个 Redis 服务器(称为 主服务器/Master )将其数据复制到一个或多个 Redis 服务器(称为 从服务器/Slave/Replica)。这是 Redis 实现高可用性、可扩展性和数据冗余的核心技术之一。
一、核心作用
-
数据冗余与备份:
- 核心作用:从服务器是主服务器数据的实时热备份。当主服务器数据丢失或损坏时,可以从从服务器恢复,是实现数据持久化的另一种有效方式。
-
读写分离与负载均衡:
- 核心作用 :主服务器通常处理写操作 和强一致性读操作 ,而从服务器可以处理大量的读操作。通过将读请求分流到多个从服务器上,可以显著提升系统的整体读吞吐量和并发能力。
- 注意:由于复制是异步的,从服务器上的数据可能存在毫秒级的延迟,适用于对数据一致性要求不非常严格的读场景(如缓存、报表查询)。
-
高可用和故障恢复的基石:
- 核心作用 :主从复制是构建 Redis Sentinel(哨兵) 和 Redis Cluster(集群) 等高可用架构的基础。当主服务器发生故障时,可以通过哨兵自动将一个从服务器提升为新的主服务器,实现服务快速切换,保证业务的连续性。
-
横向扩展读能力:
- 核心作用:当读请求成为瓶颈时,可以简单地通过添加更多从服务器来线性扩展读性能,而无需升级主服务器硬件。
二、详细工作原理
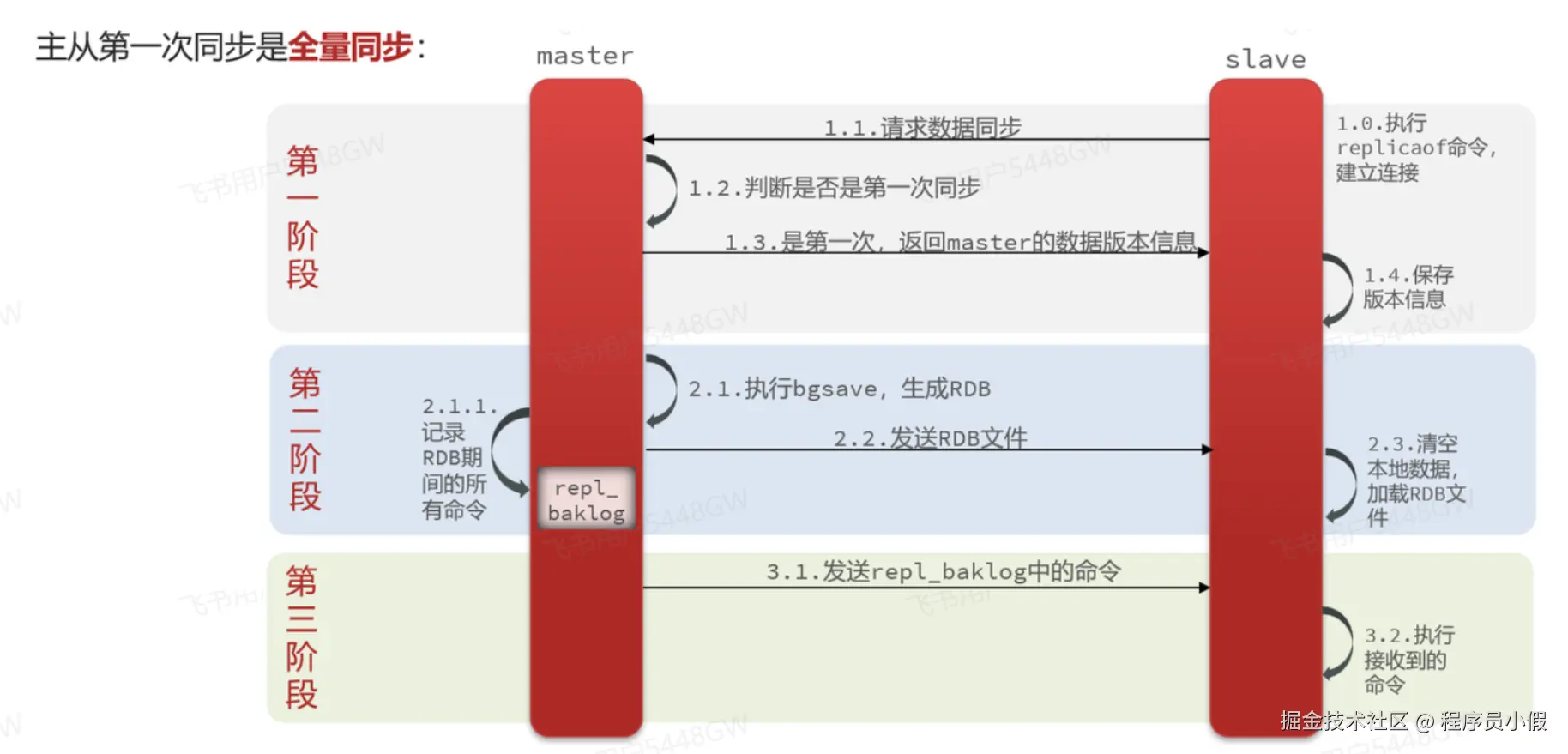
整个复制过程可以分为三个阶段:连接建立阶段 、数据同步阶段 、命令传播阶段。
阶段 1:连接建立与配置
- 配置从节点 :在从服务器配置文件 (
redis.conf) 中设置replicaof或在运行时使用REPLICAOF命令。 - 建立连接 :从服务器根据配置,向主服务器发起一个 Socket 连接 ,并发送
PING命令检查通信是否正常。 - 身份验证 :如果主服务器设置了
requirepass,从服务器需要发送AUTH命令进行密码验证。 - 端口监听 :从服务器还会建立一个 复制积压缓冲区监听端口,等待主服务器后续发送数据。
阶段 2:数据同步(全量/部分同步)
这是复制过程中最核心、最复杂的部分。Redis 2.8 之后,使用 PSYNC 命令取代了旧的 SYNC 命令,支持部分重同步,极大地优化了断线重连后的效率。
-
全量同步:
-
触发条件 :从服务器是第一次连接主服务器,或者从服务器记录的复制偏移量 已经不在主服务器的复制积压缓冲区中。
-
过程:
- 从服务器发送
PSYNC ? -1命令请求全量同步。 - 主服务器执行
BGSAVE命令,在后台生成当前数据的 RDB 快照文件。 - 主服务器将 RDB 文件通过网络发送给从服务器。在生成和传输RDB期间,新的写命令会被缓存在内存的复制客户端缓冲区中。
- 从服务器清空自身旧数据,然后加载接收到的 RDB 文件,将自身数据状态更新到与主服务器执行
BGSAVE时一致。 - 主服务器将复制客户端缓冲区中积累的写命令发送给从服务器,从服务器执行这些命令,最终达到与主服务器完全一致的状态。
- 从服务器发送
-
缺点:非常消耗主服务器的 CPU、内存、磁盘 I/O 和网络带宽,尤其是数据量大时。
-

-
部分同步:
-
触发条件 :从服务器短时间断开后重连,并且它之前同步的偏移量仍然存在于主服务器的复制积压缓冲区中。
-
过程:
- 从服务器发送
PSYNC命令,其中runid是主服务器的唯一ID,offset是从服务器当前的复制偏移量。 - 主服务器判断
runid是否与自己一致,且offset之后的数据是否还在复制积压缓冲区内。 - 如果条件满足,主服务器回复
+CONTINUE,然后仅将从offset到缓冲区末尾的写命令发送给从服务器。
- 从服务器发送
-
优点:效率极高,只传输少量缺失的数据,对资源影响小。
-
关键概念解释:
- 复制偏移量:主从服务器各自维护一个偏移量计数器。主服务器每次传播N个字节的命令,其偏移量就增加N。从服务器每次接收到N个字节,其偏移量也增加N。通过对比偏移量可以判断数据是否一致。
- 复制积压缓冲区 :主服务器维护的一个固定长度的先进先出队列 。它持续记录最近传播的写命令。其大小通过
repl-backlog-size配置,是决定能否进行部分同步的关键。 - 服务器运行ID:每个Redis实例启动时都会生成一个唯一的运行ID。从服务器会记录主服务器的ID。当主服务器重启变更后,运行ID改变,从服务器会触发全量同步。
阶段 3:命令传播(增量同步)
数据同步完成后,复制进入稳定阶段。
- 持续同步 :主服务器每执行一个会修改数据集的写命令(如
SET、LPUSH等),都会异步地将这个命令发送给所有连接的从服务器。 - 从服务器执行:从服务器接收到命令后,会在自身的数据集上执行相同的命令,从而保持与主服务器的最终一致性。
- 异步特性 :整个命令传播过程是异步 的。主服务器发送命令后不会等待从服务器的回复。这意味着在极端情况下,如果主服务器在命令发送后立即宕机,该命令可能丢失,导致从服务器数据稍旧。这是Redis复制在性能 和强一致性之间做的权衡。
三、重要特性与配置
- 异步复制:默认且最常用的模式,性能好,但存在数据丢失的极小窗口期。
- 可配置的"最小副本数" :通过
min-replicas-to-write和min-replicas-max-lag配置,可以让主服务器在连接的从服务器数量不足或延迟过高时,拒绝执行写命令。这在一定程度上提高了数据的安全性,牺牲了部分可用性。 - 无磁盘复制 :通过
repl-diskless-sync配置,主服务器可以直接将 RDB 内容通过网络发送给从服务器,而不需要先落盘。适用于磁盘IO慢的网络环境。 - 级联复制:从服务器也可以有自己的从服务器,形成树状复制结构,可以减轻主服务器在传播命令时的网络压力。
四、总结与形象比喻
你可以将 Redis 主从复制理解为一个 "出版-订阅"模型 或 "领导-跟随"模型:
- 主服务器 就像出版社,负责撰写和出版新书(写命令)。
- 复制积压缓冲区 就像是出版社的近期稿件仓库。
- 从服务器 就像各地的书店。
- 全量同步 就像书店第一次进货,需要把出版社的所有库存书籍(RDB)全部运过来。
- 部分同步 就像书店临时补货,只从出版社的近期稿件仓库里拿最新出版的那几本书。
- 命令传播 就像出版社每出版一本新书,就立即寄送给所有订阅的书店。
作用:这个系统让书店(从服务器)始终有书可卖(数据可读),即使总社(主服务器)暂时关闭,也能从其他大型书店(另一个从服务器)调货,保证了图书销售系统(Redis服务)的稳定和高效。
面试回答
Redis 主从复制主要用来实现数据的冗余备份、读写分离和高可用。它的核心就是让一个主节点的数据自动同步到一个或多个从节点上。
原理上,我把它分为三个阶段:
- 建立连接阶段
从节点启动后,会通过slaveof命令或者配置指向主节点,然后向主节点发送PSYNC命令请求同步。主节点收到请求后,会生成一个 RDB 快照文件(bgsave 方式),同时用缓冲区记录这期间的新写命令。 - 数据同步阶段
主节点把生成的 RDB 文件发送给从节点,从节点清空自己的旧数据,然后加载这个 RDB 来恢复数据。如果在生成 RDB 期间主节点有新的写操作,这些命令会先保存在一个叫"复制缓冲区"的地方。 - 命令传播阶段
RDB 同步完成之后,主节点会把复制缓冲区里的写命令以及后续的所有写命令,以 AOF 重放的方式发送给从节点,从节点执行这些命令,从而和主节点保持实时一致。之后主节点每执行一个写命令,都会异步发送给从节点。
另外,Redis 2.8 之后支持了部分重同步:如果从节点短暂断连后又恢复,主节点可以根据复制偏移量和复制缓冲区,只发送断开期间缺失的那部分命令,而不需要全量同步,这大大提升了复制的效率。
主从复制的作用主要有三点:
- 数据备份
从节点相当于主节点的一个实时备份,一旦主节点数据丢失,可以从从节点恢复。 - 读写分离
主节点负责写,从节点可以分担读请求,这样提升整体读的吞吐量,适合读多写少的场景。 - 高可用基础
主从复制是 Redis Sentinel 和 Redis Cluster 实现高可用的基础,主节点挂了之后,可以手动或自动将一个从节点提升为主节点,继续提供服务。