引言
在上一篇文章中,我们学习了网络爬虫的基础知识,包括如何发送HTTP请求、伪装浏览器和获取网页内容。今天,我们要更进一步,学习如何从网页中提取我们真正需要的信息。爬虫的工作就是从海量的HTML代码中,精准地找到并提取出需要的数据。
我们今天将学会:使用正则表达式匹配特定模式的文本、使用XPath定位网页中的元素、爬取排行榜、电影信息和图片和将提取的数据保存到文件中。
一、正则表达式(re):文字的"精准搜索器"
1、什么是正则表达式?
正则表达式是一种基于特定模式对文本进行匹配、查找、提取或替换的强大工具。在网页爬虫中,它常被用来从复杂的HTML源代码中提取有规律或特定格式的数据(如网址、邮箱、电话号码等)。
2、使用正则表达式爬取虎扑热榜
让我们先看看如何使用正则表达式爬取虎扑热榜:
import requests
import fake_useragent
import re
# 向url发送请求
header = {"User-Agent": fake_useragent.UserAgent().random} # 生成的随机用户代理字符串
r = requests.get("https://m.hupu.com/hot", headers=header)
r.encoding = r.apparent_encoding # 自动检测编码
# 使用正则表达式提取热点标题
# 正则表达式解释:匹配">标题文字</div><div class"这种模式中的标题文字
result = re.findall(r'"hot_hot-page-item-title__HL2kw">(.+?)</div><div class', r.text)
# 打印结果
for i, j in enumerate(result):
print('热点第', i+1, '话题:', j)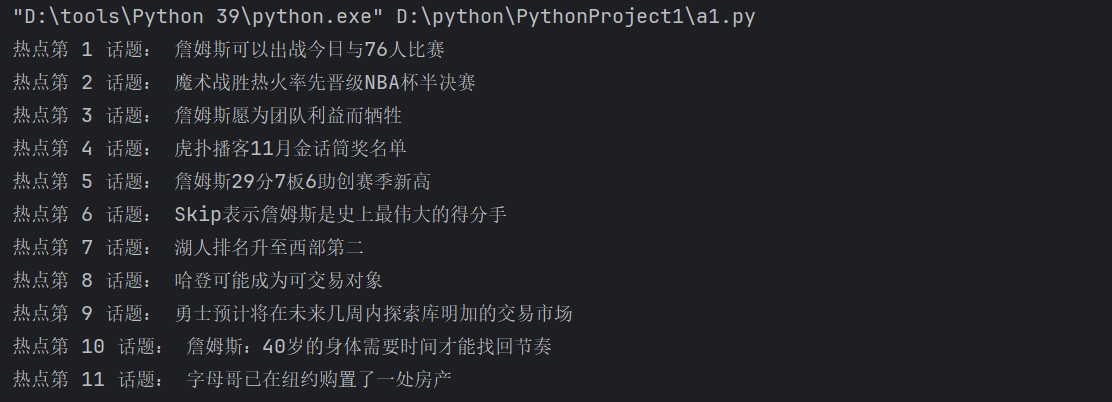
使用 re.findall() 函数和正则表达式从网页源代码中提取特定内容。正则表达式 "hot_hot-page-item-title__HL2kw">(.+?)</div><div class 的匹配逻辑如下:
1)、固定开头:"hot_hot-page-item-title__HL2kw"> 匹配目标内容前的固定HTML标签片段。
2)、捕获内容:(.+?) 使用非贪婪模式匹配任意字符(除换行符外),确保捕获到尽可能短的符合条件的内容,直到遇到结束标记。
3)、固定结尾:</div><div class 匹配内容后的固定结束标记。
该正则表达式会提取所有位于 "hot_hot-page-item-title__HL2kw"> 和 </div><div class 之间的文本内容(例如文章标题、项目名称等),并返回一个包含所有匹配结果的列表。
二、XPath解析:网页的"GPS导航"
1、什么是XPath?
XPath是一种专为XML和HTML设计的路径查询语言,它通过直观的路径表达式直接导航和定位文档中的节点,能更好地理解标签的层次结构,因此在提取网页数据时更具可读性。所以XPath适合定位结构化文档中的特定区域,而正则则适合对提取出的文本进行精细的模式匹配。
2、安装lxml库
在使用XPath之前,我们需要安装lxml库
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple3、XPath基础语法
假设我们有一个test.html文件:
<html>
<head>
<title>测试页面</title>
</head>
<body>
<div class="song">
<p>第一段</p>
<p>第二段</p>
<p>第三段</p>
<img src="image1.jpg" />
</div>
<div class="tang">
<p>段落</p>
<ul>
<li><a href="page1.html">第一页</a></li>
<li><a href="page2.html">第二页</a></li>
<li><a href="page3.html">第三页</a></li>
</ul>
</div>
</body>
</html>让我们使用XPath提取数据:
from lxml import etree
# parse 提供解析本地html文件的方法
tree = etree.parse("test.html")
# 获取title标签的文本
print("1. 页面标题:", tree.xpath("/html/head/title/text()")[0])
# 获取第一个div中的所有p标签文本
print("2. 第一个div的所有段落:", tree.xpath("/html/body/div[1]/p/text()"))
# 获取第二个div中的第二个p标签文本
print("3. 第二个div的第二个段落:", tree.xpath("/html/body/div[2]/p[2]/text()"))
# 使用属性定位:获取class="song"的div中的第二个p标签文本
print("4. class='song'的div的第二个段落:", tree.xpath("/html/body/div[@class='song']/p[2]/text()")[0])
# 使用//表示多个层级:获取所有class="song"的div中的p标签文本
print("5. 所有class='song'的div中的段落:", tree.xpath("//div[@class='song']/p/text()"))
# 获取所有文本内容:/text() vs //text()
print("6. 直接子文本:", tree.xpath("//div[@class='song']/p[2]/text()")[0])
print("7. 所有后代文本:", tree.xpath("//div[@class='song']//text()"))
# 获取属性值:获取img标签的src属性
print("8. 图片地址:", tree.xpath("//div[@class='song']/img/@src")[0])
# 获取链接地址
print("9. 第一个链接地址:", tree.xpath("//div[@class='tang']/ul/li[1]/a/@href")[0])4、XPath语法
表达式 描述 示例
nodename 选取此节点的所有子节点 div
/ 从根节点选取 /html/body/div
// 从匹配选择的当前节点选择文档中的节点 //div
. 选取当前节点 .//p
.. 选取当前节点的父节点 ../@id
@ 选取属性 //div/@id
* 匹配任何元素节点 //div/*
@* 匹配任何属性节点 //div/@*
text() 选取文本 //h1/text()
[n] 选取第n个元素(索引从1开始) //li[1]
[last()] 选取最后一个元素 //li[last()]
[position()<3] 选取前两个元素 //li[position()<3]
[@属性名] 选取具有指定属性的元素 //div[@class]
[@属性名='值'] 选取属性等于指定值的元素 //div[@class='song']
contains(@属性名, '值') 选取属性包含指定值的元素 //div[contains(@class, 'son')]
and 逻辑与 //div[@class='song' and @id='div1']
or 逻辑或 //div[@class='song' or @class='tang']三、实战案例:使用XPath爬取虎扑热榜
现在让我们使用XPath的方法再来爬取一下虎扑热榜:
import requests
from lxml import etree
import fake_useragent
header={"User-Agent":fake_useragent.UserAgent().random} #生成的随机用户代理字符串
# 发送请求获取网页
r = requests.get("https://m.hupu.com/hot",headers=header)
# 将HTML文本转换为可解析的对象
tree = etree.HTML(r.text)
# 找到所有包含热点的article标签下的div
a_list = tree.xpath("//article[@class='hot_hot-page__jgBZU']/div")
# 遍历每个div,提取热点标题
for i, j in enumerate(a_list):
try:
# 在每个div中查找热点标题
result = j.xpath("./section/div[2]/text()")
print('热点第', i+1, '话题:', result[0])
except:
pass # 如果提取失败,跳过继续下一个
四、实战案例:爬取豆瓣电影信息
接下来让我们开始更复杂的爬取信息,来爬取豆瓣电影信息。
首先我们要安装必要的库:
# 安装fake_useragent库
pip install fake_useragent -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装lxml库
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
import fake_useragent
import requests
from lxml import etree
import re
# 豆瓣电影Top250的URL
url = 'https://movie.douban.com/top250'
# 设置请求头,使用随机User-Agent
header = {"User-Agent": fake_useragent.UserAgent().random}
# 发送HTTP请求
resp = requests.get(url, headers=header)
# 获取响应内容
result = resp.text
# 打开文件,准备保存数据
fp = open("douban.txt", "w", encoding="utf8")
# 数据解析
tree = etree.HTML(result)
# 找到所有的电影列表项
li_list = tree.xpath("//ol[@class='grid_view']/li")
# 遍历每个电影列表项
for li in li_list:
try:
# 提取电影名称
film_name = li.xpath("./div/div[2]/div[1]/a/span[1]/text()")[0]
# 提取电影演员和导演信息
film_actor = li.xpath("./div/div[2]/div[2]/p[1]/text()")
# 使用正则表达式提取导演和主演信息
film_daoyan = re.match("导演: (.+?) (.+)主演: (.+)", film_actor[0].strip()).group(1)
film_zhuyan = re.match("导演: (.+?) (.+)主演: (.+)", film_actor[0].strip()).group(3)
# 提取上映年份
film_year = re.match(".*?(\d+).*", film_actor[1].strip()).group(1)
# 提取电影评分
film_star = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0]
# 提取电影短评
film_quote = li.xpath("./div/div[2]/div[2]/p[2]/span/text()")[0]
# 打印结果
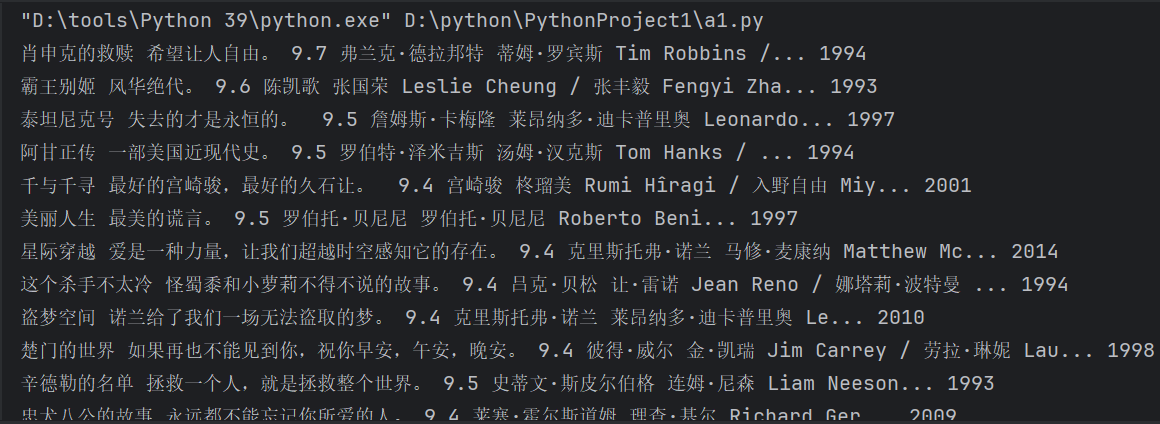
print(film_name, film_quote, film_star, film_daoyan, film_zhuyan, film_year)
# 将结果写入文件,用#分隔
fp.write(film_name + '#' + film_quote + '#' + film_star + '#' +
film_daoyan + '#' + film_zhuyan + '#' + film_year + '\n')
except Exception as e:
print(e) # 打印错误信息
pass # 跳过这个电影,继续下一个
# 关闭文件
fp.close()代码有点复杂让我们逐步来分析
第一部分:提取电影名称:
film_name = li.xpath("./div/div[2]/div[1]/a/span[1]/text()")[0]这个路径表示:./ 从当前li元素开始、div 第一个div子元素、div2 第二个div子元素、div1 第一个div子元素、a a标签、span1 第一个span标签、text() 提取文本内容
第二部分:提取导演和演员信息:
film_actor = li.xpath("./div/div[2]/div[2]/p[1]/text()")
film_daoyan = re.match("导演: (.+?) (.+)主演: (.+)", film_actor[0].strip()).group(1)
film_zhuyan = re.match("导演: (.+?) (.+)主演: (.+)", film_actor[0].strip()).group(3)获取包含导演和演员信息的文本,使用正则表达式提取信息,文本格式可能是:"导演: xx 主演: xx/xx",正则表达式:"导演: (.+?) (.+)主演: (.+)",第一个分组(.+?)匹配导演名字(非贪婪模式),第二个分组(.+)匹配"导演: 和"主演:"之间的内容(通常是空格),第三个分组(.+)匹配主演名字。
第三部分:提取上映年份:
film_year = re.match(".*?(\d+).*", film_actor[1].strip()).group(1)文本格式可能是:"1994 / 美国 / 犯罪 剧情",正则表达式:".*?(\d+).*";.*? 匹配任意字符,非贪婪模式;(\d+) 匹配一个或多个数字(年份);.* 匹配剩余的任意字符。
第四部分:提取评分和短评:
film_star = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0]
film_quote = li.xpath("./div/div[2]/div[2]/p[2]/span/text()")[0]提取评分和提取短评(可能不存在,所以放在try-except中)。
第五部分打印并保存结果:
print(film_name, film_quote, film_star, film_daoyan, film_zhuyan, film_year)
fp.write(film_name + '#' + film_quote + '#' + film_star + '#' +film_daoyan + '#' + film_zhuyan + '#' + film_year + '\n')打印结果并将结果写入文件,用#分隔。
注意在爬虫中,异常处理非常重要,因为网页结构可能发生变化从而导致某些元素可能不存在(如有些电影可能没有短评),网络可能不稳定,网站可能有反爬虫机制,所以当我们使用try-except可以确保程序在遇到错误时不会崩溃,而是跳过错误继续执行。
五、实战案例:爬取图片并保存到本地
最后让我们爬取网页中的图片信息并保存到本地中:
import fake_useragent
import requests
from lxml import etree
import os
# 计数器,用于给图片命名
n = 0
def count():
global n
n += 1
return n
# 新建一个文件夹用于存储图片
if not os.path.exists("./Picture"):
os.mkdir("./Picture")
# 设置请求头
head = {
"User-Agent": fake_useragent.UserAgent().random
}
# 循环爬取多页图片
for i in range(1, 3): # 爬取第1页和第2页
# 构造URL
url = f'https://10wallpaper.com/List_wallpapers/page/{i}'
# 发送请求
resp = requests.get(url, headers=head)
# 获取响应内容
result = resp.text
# 解析HTML
tree = etree.HTML(result)
# 找到所有包含图片的p标签
p_list = tree.xpath("//div[@id='pics-list']/p")
# 遍历每个p标签
for p in p_list:
# 获取图片的缩略图URL
img_url = p.xpath("./a/img/@src")[0]
# 构造完整图片URL
img_url2 = 'https://10wallpaper.com' + img_url
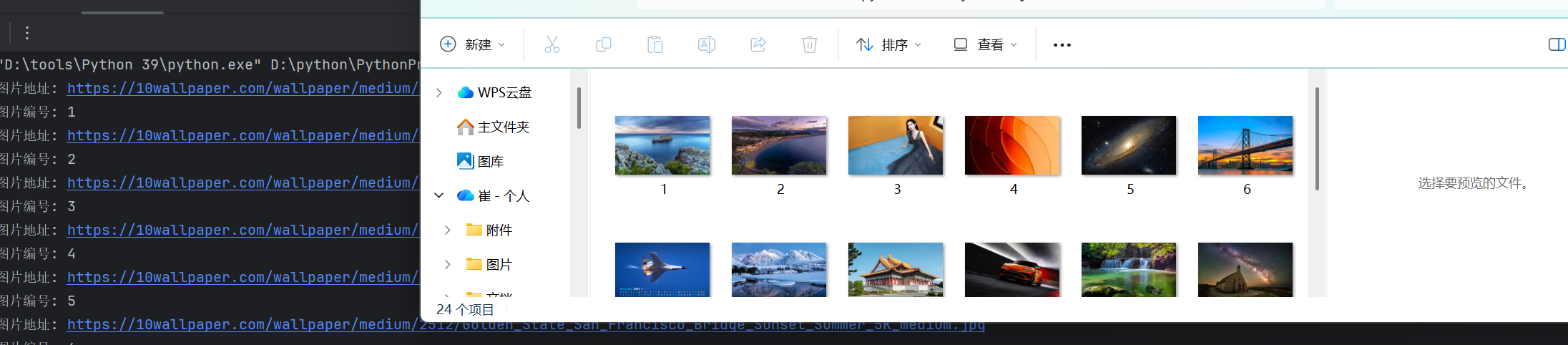
print("图片地址:", img_url2)
# 获取图片编号
img_name = count()
print("图片编号:", img_name)
# 下载图片
img_resp = requests.get(img_url2, headers=head)
# 保存图片
with open(f"./Picture/{img_name}.jpg", "wb") as fp:
fp.write(img_resp.content)
print("图片下载完成!")这里我们也来逐步分析一下代码:
第一部分:创建图片保存目录:
if not os.path.exists("./Picture"):
os.mkdir("./Picture")检查是否存在Picture目录,如果不存在,创建目录。
第二部分:构造分页URL:
for i in range(1, 3):
url = f'https://10wallpaper.com/List_wallpapers/page/{i}'使用f-string格式化URL,range(1, 3)生成1和2,表示爬取第1页和第2页。
第三部分:提取图片URL:
p_list = tree.xpath("//div[@id='pics-list']/p")
for p in p_list:
img_url = p.xpath("./a/img/@src")[0]
img_url2 = 'https://10wallpaper.com' + img_url找到所有包含图片的p标签,从每个p标签中提取图片URL,提取缩略图URL(可能是相对路径),将相对路径转换为绝对路径。
第四部分:下载和保存图片:
img_resp = requests.get(img_url2, headers=head)
with open(f"./Picture/{img_name}.jpg", "wb") as fp:
fp.write(img_resp.content)下载图片内容,以二进制写入模式打开文件,wb'表示以二进制写入模式打开文件,将图片的二进制内容写入文件。
到这我们就学会了基本的爬虫知识并且可以在网页中爬取我们所需要的信息了,注意在我们爬取图片等信息时记住要尊重版权,控制下载速度:不要过快下载,以免给服务器造成压力,检查文件格式:确保保存的文件扩展名正确,遵守robots.txt:检查网站是否允许爬取图片。