数据库表设计是构建高效、可靠数据库系统的核心环节,其流程需兼顾业务需求、数据完整性、性能优化及扩展性。以下是数据库表设计的标准化流程及关键要点:
一、需求分析阶段
- 明确业务目标
- 与业务方、产品经理沟通,梳理核心业务流程(如用户注册、订单处理、库存管理等)。
- 确定数据存储需求(如用户信息、交易记录、日志数据等)。
- 识别数据实体与关系
- 抽象出业务中的关键实体(如用户、商品、订单)。
- 分析实体间的关联关系(如一对多、多对多),例如:
- 一个用户可下多个订单(1:N)。
- 一个订单包含多个商品(通过订单明细表实现多对多)。
- 定义数据范围与约束
- 确定数据量级(如用户量、日活数据量)。
- 识别数据约束条件(如用户名唯一、年龄范围限制)。
二、概念设计阶段
- 绘制ER图(实体-关系图)
- 使用工具(如PowerDesigner、Draw.io)可视化实体及其关系。
- 示例:用户(User)与订单(Order)通过"下单"关系关联,订单与商品(Product)通过"包含"关系关联。
- 规范化初步检查
- 避免数据冗余(如不将商品价格重复存储在订单表中)。
- 初步识别可能的多对多关系(需通过中间表拆解)。
三、逻辑设计阶段
-
表结构设计
-
字段定义 :
- 字段名:清晰表达含义(如
user_id而非uid)。 - 数据类型:选择合适类型(如
INT、VARCHAR(255)、DATETIME)。 - 约束:主键(PK)、外键(FK)、唯一键(UK)、非空(NOT NULL)、默认值(DEFAULT)。
- 字段名:清晰表达含义(如
-
示例表 :
CREATE TABLE users ( user_id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(50) NOT NULL UNIQUE, email VARCHAR(100) NOT NULL UNIQUE, created_at DATETIME DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE orders ( order_id INT PRIMARY KEY AUTO_INCREMENT, user_id INT NOT NULL, total_amount DECIMAL(10,2) NOT NULL, order_date DATETIME DEFAULT CURRENT_TIMESTAMP, FOREIGN KEY (user_id) REFERENCES users(user_id) );
-
-
规范化处理
- 第一范式(1NF) :确保字段原子性(如不拆分姓名到
first_name和last_name除非必要)。 - 第二范式(2NF):消除部分依赖(如订单明细表需包含订单ID和商品ID作为复合主键)。
- 第三范式(3NF):消除传递依赖(如用户表中不存储城市名称,仅存储城市ID并关联城市表)。
- 第一范式(1NF) :确保字段原子性(如不拆分姓名到
-
反规范化优化(根据场景)
- 在读多写少的场景下,适当冗余数据以提高查询性能(如订单表中存储用户姓名而非仅用户ID)。
四、物理设计阶段
- 索引设计
- 主键索引:自动创建,确保唯一性。
- 外键索引 :加速关联查询(如为
orders.user_id创建索引)。 - 查询优化索引 :为高频查询条件创建索引(如
WHERE status = 'paid')。 - 避免过度索引:索引会降低写入性能,需权衡。
- 分区与分表策略
- 分区:按时间(如按月分区订单表)或范围拆分大表。
- 分表:水平拆分(如用户表按用户ID哈希分表)或垂直拆分(如将用户信息拆分为基础表和扩展表)。
- 数据库选型
- 根据业务需求选择关系型(MySQL、PostgreSQL)或非关系型(MongoDB、Redis)数据库。
- 考虑事务支持、扩展性、成本等因素。
五、验证与优化阶段
- 数据完整性验证
- 插入测试数据,检查约束是否生效(如唯一键、外键)。
- 模拟异常场景(如重复插入、外键关联不存在)。
- 性能测试
- 使用工具(如JMeter、sysbench)模拟高并发查询/写入,评估响应时间。
- 分析慢查询日志,优化索引或SQL语句。
- 安全与合规检查
- 确保敏感数据加密(如密码使用哈希存储)。
- 符合数据保护法规(如GDPR、CCPA)。
六、模型建立
使用navcat进行模型的创建
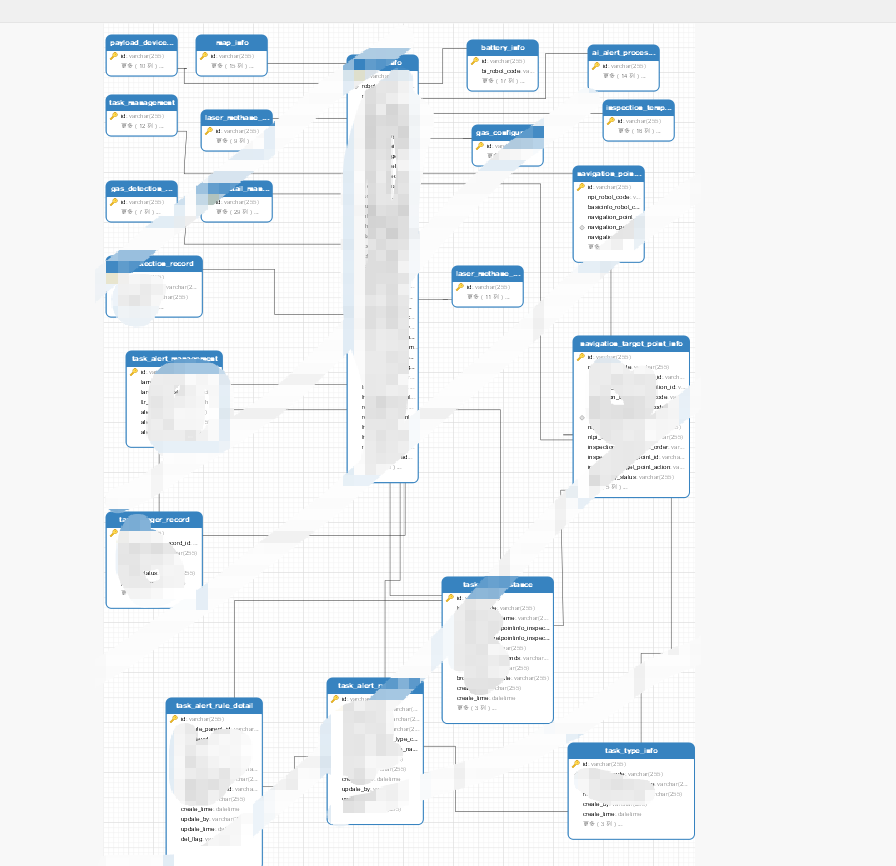
将设计好的数据库表导出sql并在新的连接中导入sql文件
然后使用dbword连接导入的数据库
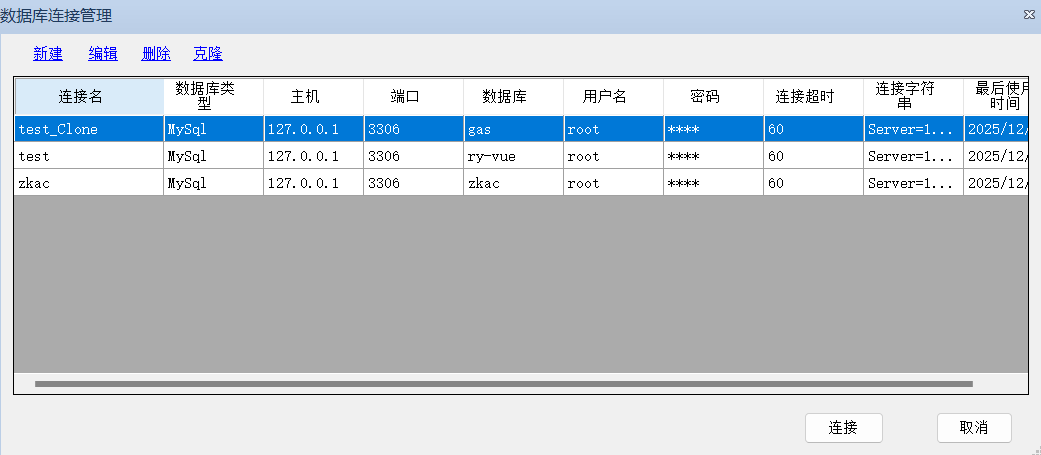
然后导出word即可