多模态大模型的崛起,正在重新定义我们理解与使用 AI 的方式。当模型能够像人类一样,将图像、文本、语音、视频等信息自然融会贯通时,它便获得了更完整、更真实的世界视角。跨模态的统一认知让 AI 不再停留在"看见""听到"的感知层面,而是能够读懂语境、推演逻辑、辅助决策,展现出向通用智能迈进的关键能力。随着算法、数据与算力的不断进化,多模态大模型正加速从实验室走向产业深处,在越来越多的应用场景中持续释放价值,引领智能时代的全面升级与加速到来。
司南持续关注大模型的发展动态,基于闭源评测基准 ,近期针对国内外主流多模态模型进行了全面评测,现公布司南多模态模型 11 月评测榜单。
需要提示的是:由于榜单规则,为提升闭源评测集榜单的时效性与先进性,我们对部分旧模型进行了移除,并测试了他们的最新版本。
综合榜单解读
整体性能排名
-
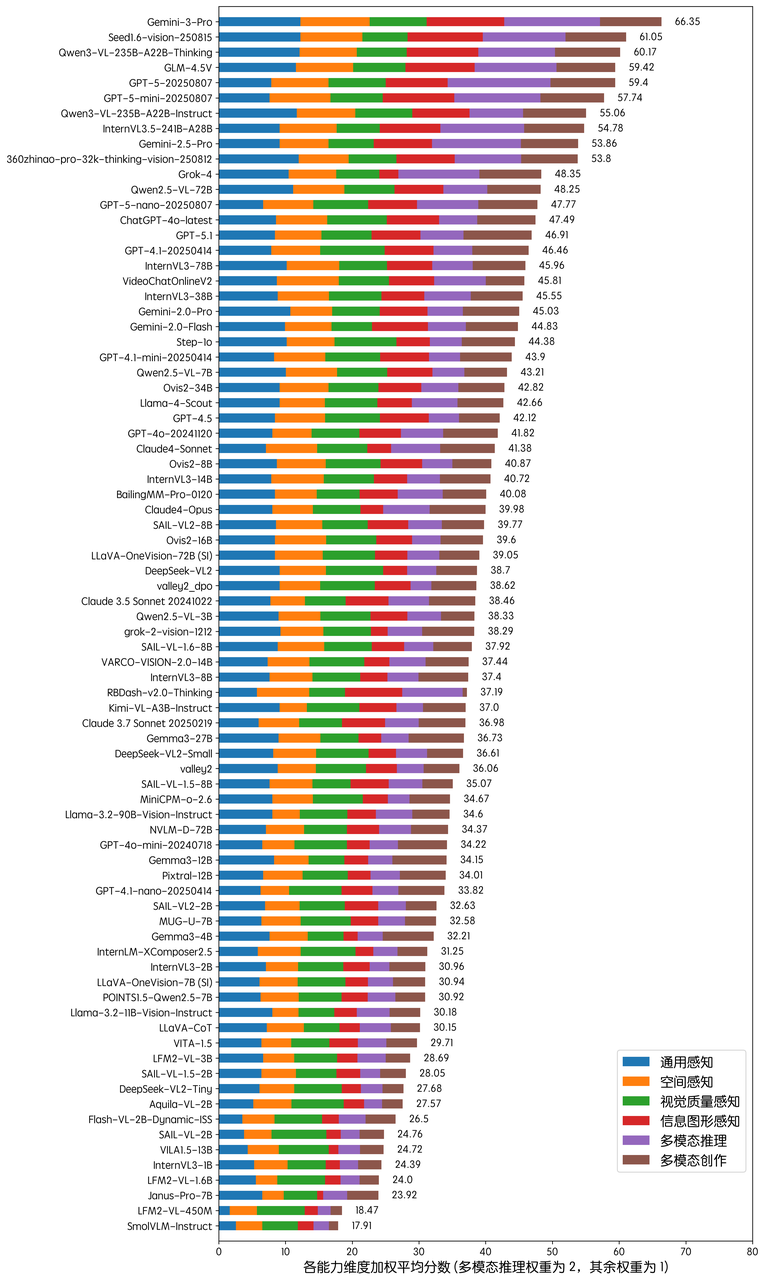
本次评测中,随着 Gemini-3-Pro 的发布,榜单的最高得分再创新高,达到了 66.35。
-
在整体性能上,Gemini-3-Pro 在空间感知能力上的大幅度领先以及在信息图形感知能力上的优势,助力其以大比分领先第二名的 Seed1.6-vision-250815,而其在视觉质量感知和多模态创作领域虽仍居于前列,但仍无法达到全方面领先。
-
在其他本次新上榜的模型中,OpenAI 的 GPT-5.1 在综合能力上有所下降,但在多模态创作领域却能斩获最高分,印证了 OpenAI 对 GPT-5.1 的 "更具对话感、更加温暖" 的宣传。Qwen3-VL-235B-A22B-Thinking 则再次成为最强开源多模态模型。
深层洞察
开源模型再次冲击榜单新高,推理模型优势明显
-
开源模型 Qwen3-VL-235B-A22B-Thinking 跃居第三,超越 GLM-4.5V ,成为开源模型中排名第一的模型,进一步巩固了国产多模态模型在开源赛道的领先地位。
-
值得关注的是,推理模型,如 Qwen3-VL-235B-A22B-Thinking、GLM-4.5V,在多模态推理、信息图形理解两个领域拥有普遍的优势,也导致推理模型普遍能够在总榜单中获得更高的排名。本次新入榜的 RBDash-v2.0-Thinking,在多模态推理维度获得了显著高于同参数量级指令模型的得分,展现了 Thinking 模式在该领域的有效性。
-
而在视觉质量感知领域,反而是小模型和非推理的指令模型获得了相对优势。可见 Thinking 模式也非各个领域的万能灵药。
闭源模型突破瓶颈,有望引领多模态模型能力的进一步提升
-
Gemini-3-Pro 相比 Gemini-2.5-Pro 实现全维度提升:通用感知、空间感知、信息图形、多模态推理等领域均有显著进步,展现了 Google 在多模态领域的持续迭代能力。
-
Gemini-3-Pro 打破了上一季度第一梯队模型集中在 60 分左右的格局,以总分 66 分大比分领先,这展示了多模态模型的进步仍有不俗潜力,相信在 Gemini-3-Pro 的刺激下,各大模型厂商也将能够愈战愈勇,将多模态模型的整体水平带上一个新的台阶。
-
GPT-5.1 模型在多模态创作领域获得了显著提升,和 Qwen3-VL-235B-A22B-Thinking 共同打破了多模态创作领域的得分纪录。但值得注意的是,GPT-5.1 在其他领域表现欠佳,整体得分仅达到 GPT-5-nano 水平,可见 GPT-5.1 是一个有些偏科的选手,也许是 OpenAI 为了回应前段时间 GPT-5 "缺少人情味" 的指摘,在创作领域重点发力。不知面对 Gemini-3-Pro 的挑战,OpenAI 后续会交出一份怎样的答卷。
榜单规则说明
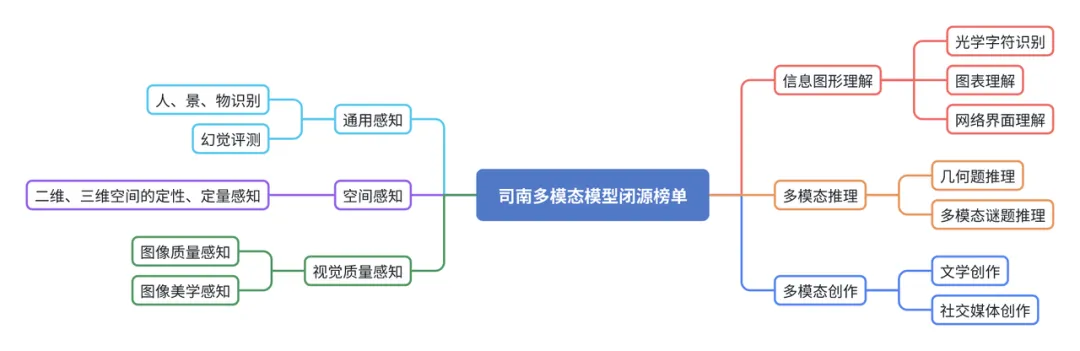
本榜单基于闭源测试数据 ,对不同多模态模型在 通用感知、空间感知、视觉质量感知、信息图形理解、多模态推理、多模态创作 六大能力维度上的表现进行了评测,并基于 归一化分数 计算模型的平均得分进行排序。闭源评测基准拥有较为丰富的题目类型,包含单选、多选、填空、开放性创作等,且为中英文双语,可以同时考验模型的多语言理解能力。

子维度能力解读
通用感知
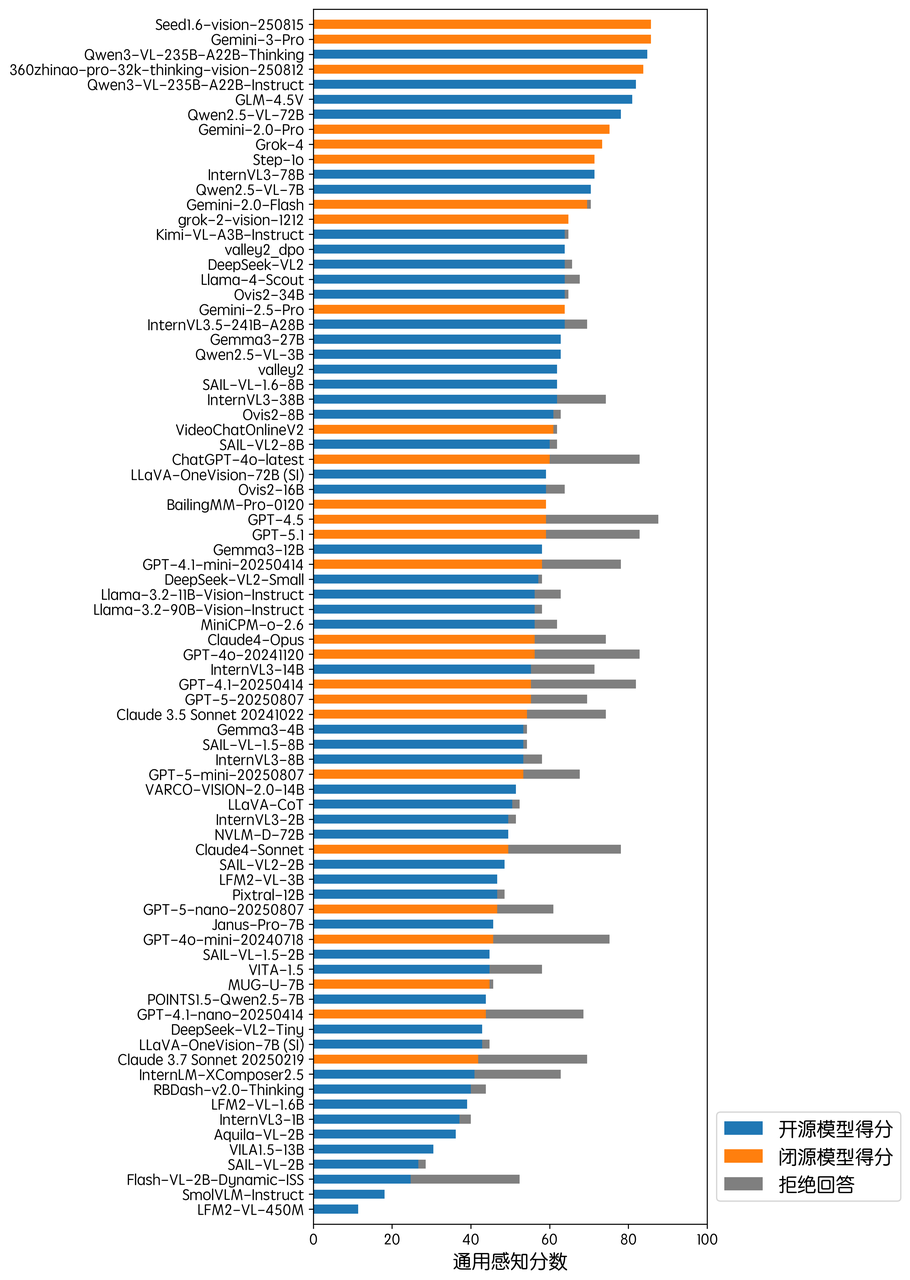
在通用感知能力方面,闭源模型 Seed1.6-vision-250815 与 Gemini-3-Pro 并列第一。在通用感知测试中存在涉及人物识别的问题,其中 GPT 模型在此问题上现象比较严重,一定程度上影响了得分情况。下方的性能展示图片标注了每个模型的拒答比率。
视觉质量感知
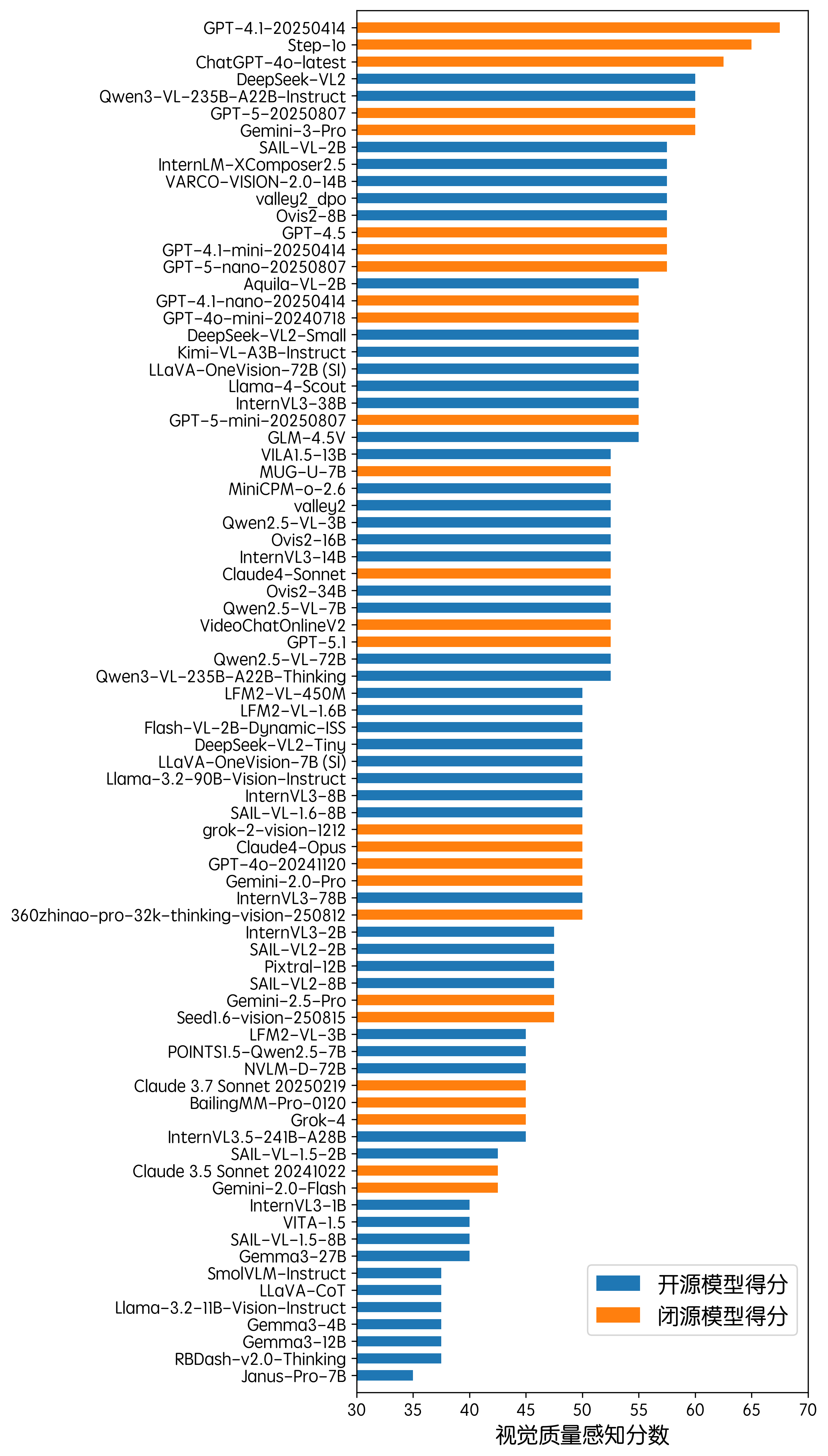
在视觉质量感知方面,在前 5 名中 Qwen3-VL-235B-A22B-Instruct 为本次榜单新近上榜,此类任务涉及对图像缺陷的判断,这一特殊的任务类型,使很多综合实力很强的模型得分不高,而一些小模型,如 SAIL-VL-2B、OVis2-8B 反而获得了较高的得分。
空间感知
在空间感知方面,很多新模型都获得了较大幅度的提升。最为亮眼的当属 Gemini-3-Pro,在此能力上大幅领先其他模型,展现了 Gemini 在世界知识上的强大能力。同样亮眼的是新上榜的 VideoChatOnlineV2,获得了与 Seed1.6-vision-250815 并列第一的好成绩。

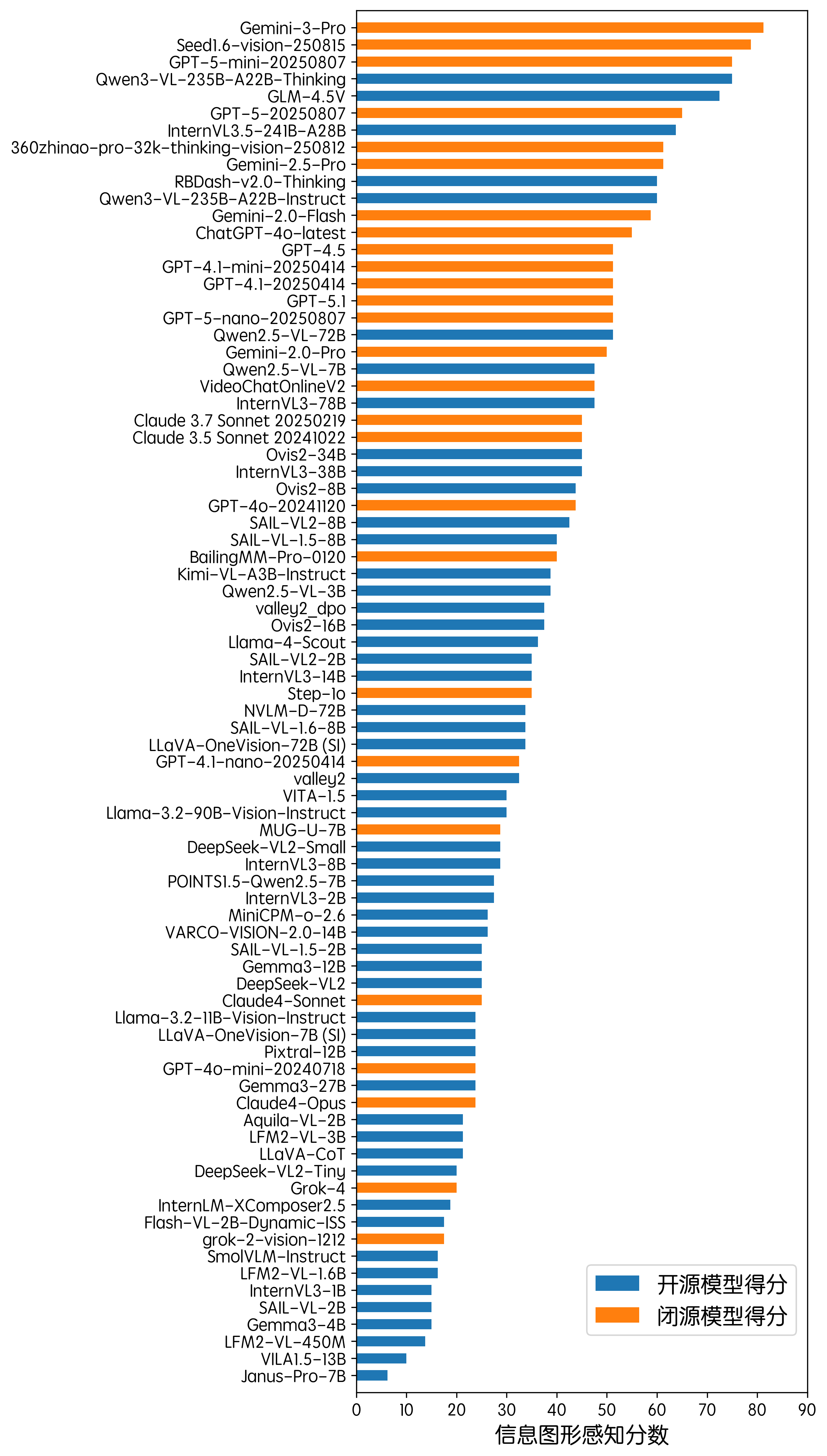
信息图形感知
在信息图形感知方面,同样是 Gemini-3-Pro 取得了排名第一的成绩,但分差并没有领先第二名的 Seed1.6 太多。开源模型则相较上期榜单在这一方面有一定性能提升,Qwen3-VL-235B-A22B-Thinking 追平了 GPT-5-mini-20250807,另外一个新上榜的模型 RBDash-v2.0-Thinking 以 38B 的参数量同样跻身前十名的行列,期待开源模型能够在后续取得更好的成绩。
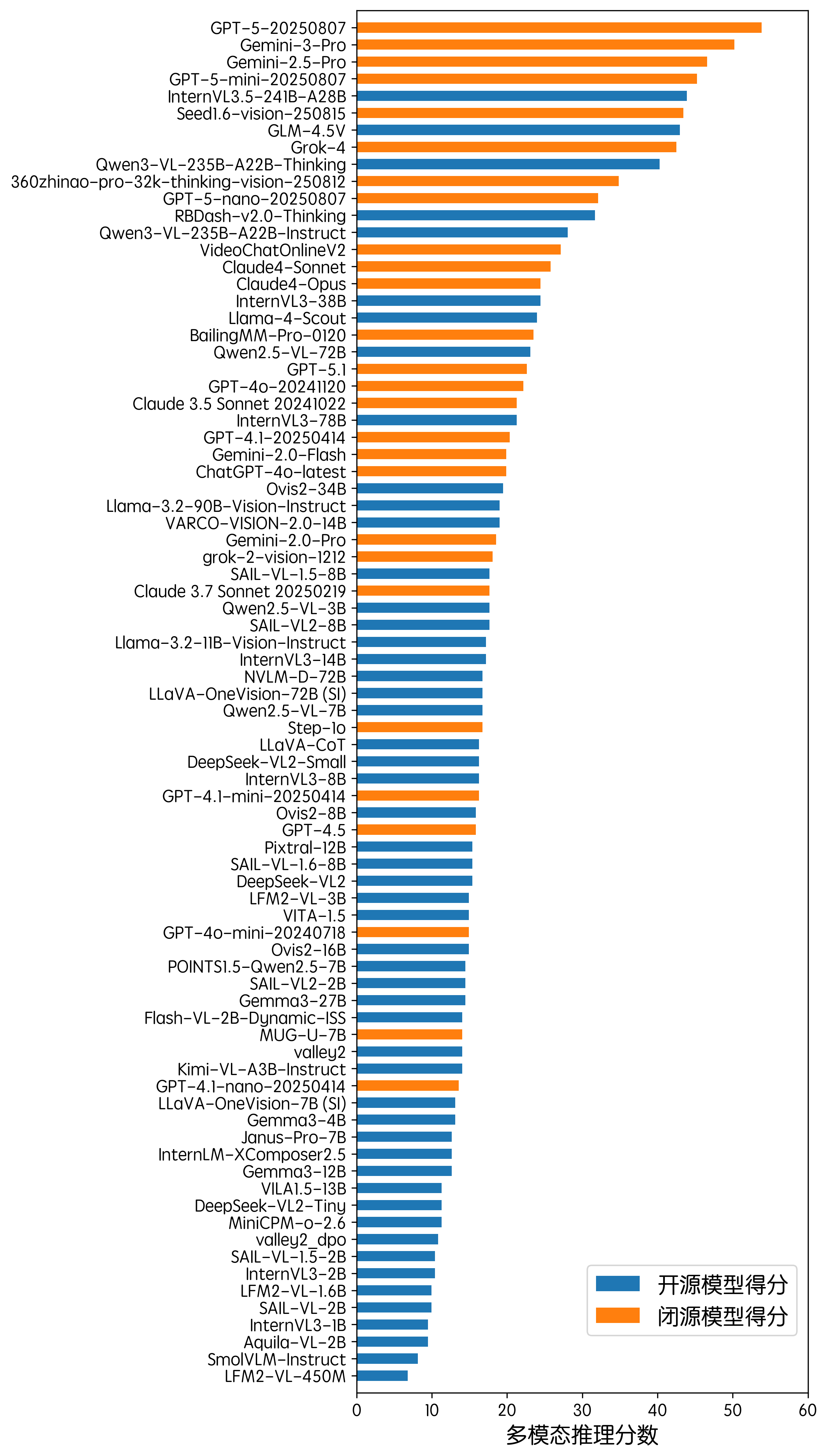
多模态推理
在多模态推理方面,GPT-5-20250807 在评测中维持了第一名的成绩,而 Gemini-3-Pro 则超越了前代 Gemini-2.5-Pro,成为了新的第二名。总体而言,闭源模型在推理能力方面占据较强的统治地位,开源模型仍在持续追赶中,Qwen3-VL-235B-A22B-Thinking 跻身前十,而开源模型中的第一名依然是 InternVL3.5-241B-A28B。
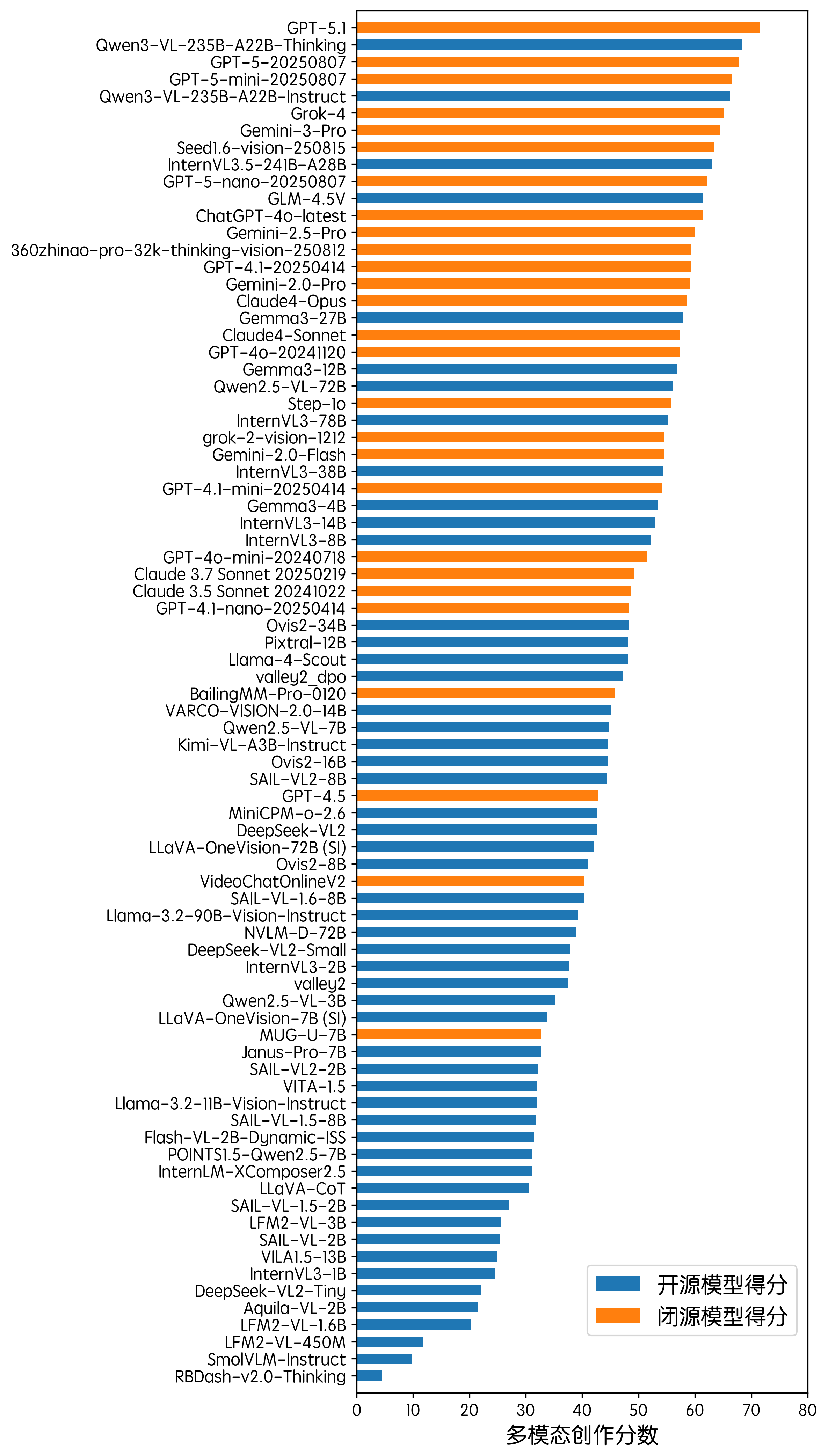
多模态创作
在多模态创作方面,GPT-5.1 异军突起,虽然在其他维度的能力仅为中上游,但在多模态创作能力上较第二名打出了一个较大的分差,可见 GPT 在创作领域的补强卓见成效。而 Qwen3-VL-235B-A22B-Thinking 和 Qwen3-VL -235B-A22B-Instruct 的表现同样亮眼,两个模型双双强势进入前十名,打破了此前闭源模型在此维度的大幅领先地位。
评测题目示例
通用感知

问题
图中的景点是什么,位于哪个城市
答案
'鸟巢', '北京'
视觉质量感知
问题
What factor has the most negative impact on the visual quality of this image?
A. The overall blur.
B. The color distortion on the cat's fur.
C. The motion blur on the cat's face.
D. The underexposure in the background.

答案
C
空间感知
问题
Where is the toy car?
A. Beneath the books.
B. Behind the books.
C. Above the books.
D. Next to the books.

答案
D
信息图形感知
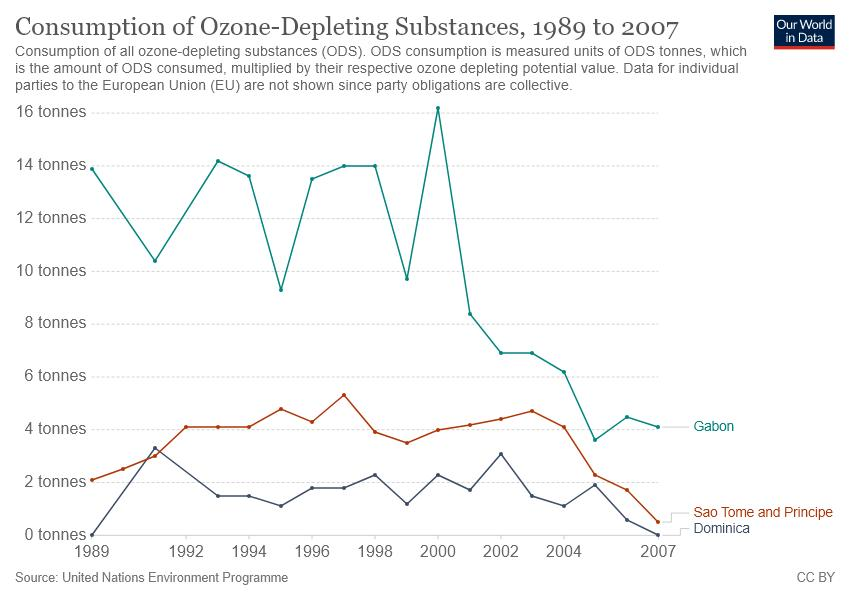
问题
只有在哪一年Sao Tome and Principe的臭氧物质消耗量低于Dominica?
答案
'1991'
多模态推理
问题
从所给的四个选项中,选择最合适的一个填入问号处,使之呈现一定的规律性。
答案
D
多模态创作
问题
Assume you are A regular customer makes a purchase at this shop and wants to write a review of this shop on the yelp platform.

Here's a photo I took, I went to this shop for repairs and got great service!
Please follow the requirements below to Write a shop review, guess what shop it is, and express in the review that this shop has fair prices, good service, and great technology.
-
Keep the review concise (3-4 sentences) and focus on key aspects of the experience.
-
Include sensory details or personal experiences to make the review engaging.
-
Identify the shop type and guess the service purchased.
-
Highlight the shop's service attitude and service content.
CRITERIA. {'subjective requirement': '1. Authentic Yelp Review Style\n1.1 Use an informal, authentic tone typical of Yelp customer reviews.\n1.2 Write a concise review (3-4 sentences) that highlights key aspects of the experience.\n1.3 Include sensory details or personal experiences (e.g., how the service felt, interactions with staff, or impressions of the shop) to make the review engaging and relatable.', 'groundtruth alignment': '1. Accurate Shop and Service Identification\n1.1 Correctly identify the shop type and its purpose (i.e., Go to a car repair shop to repair scratches on car doors).\n1.2 Highlight the key features of the shop, i.e. fair prices, good service, and advanced technology, as specified in the prompt.\n\n2. Sentiment and Consistency\n2.1 Ensure the review reflects a positive sentiment aligned with the context, showcasing satisfaction with the service and experience.'}
参考答案:(由 GPT-4o 创作)
"I recently visited this auto body repair shop to fix some scratches and dents on my car, and I couldn't be happier with the results! The staff was incredibly friendly and professional, walking me through the repair process and offering fair pricing. Their advanced tools and technology made the repairs seamless, and my car looks as good as new. Highly recommend this place for anyone needing quality auto body work!"
注意事项
-
多模态模型闭源评测基准及对应的榜单每季度更新一次,于每季度最后一个月的月初发布 (3 / 6 / 9 / 12 月)
-
新模型厂商若想参与该季度榜单评测,可在每季度的第 2 个月(2 / 5 / 8 / 11 月)的 25 日前 写邮件至 opencompass@pjlab.org.cn 申请评测
-
仅支持开源或对外提供 API 服务商业化模型
-
若为开源模型参与榜单评测,请提供 Hugging Face 或 ModelScope 模型权重及链接;API 模型参与评测,提供 API 网址链接,并写明模型版本
-
若为 API 模型,推荐提供 OpenAI 标准接口 API,非 OpenAI 标准接口需要在 VLMEvalKit 算法仓库中提 PR 以支持该模型
-
为保证和真实用户获得完全一样的模型使用体验,对于 API 模型,司南均通过常规采购渠道获取,不接受厂商提供的 key
了解更多
多模态模型闭源评测榜单已同步上线至司南官网,欢迎大家访问查看更详细的评测数据!
https://rank.opencompass.org.cn/
同时,司南评测过程中所用到的工具链均在 GitHub 开源,诚挚邀请您在学术研究或产品研发过程中使用~