Bright Data AI Scraper Studio:一句话生成企业级爬虫
最近和几个做AI的朋友聊天,发现大家都被同一个问题困扰:数据采集。一个朋友的团队为了采集100个网站的数据,投入了2名高级工程师,写了3周代码,结果上线第二天就因为反爬机制挂了一半...
更要命的是,老板又说要再加50个网站,工程师当场崩溃:每个网站都要重新分析DOM结构、写CSS选择器、调试代码...这活干到猴年马月?
如果我告诉你,有一种方式能让你用一句话就生成爬虫代码,你信吗?
今天给大家介绍Bright Data最新推出的AI Scraper Studio------真正的"prompt驱动爬虫生成"技术,让数据采集从"写代码"变成"说需求"。
一、传统爬虫开发的三大痛点
痛点1:开发周期长,人力成本高昂
真实场景:
某AI创业团队需要采集电商网站的产品数据来训练推荐模型。产品经理说:我们需要采集10个主流电商平台的数据。
技术负责人一听,头都大了:
python
# 每个网站都要写一套爬虫代码
# 分析页面结构
# 写CSS选择器
# 处理分页逻辑
# 应对反爬虫机制
# 数据清洗和结构化
# 错误处理和重试...
预计开发时间:
- 单个网站:2-3天
- 10个网站:20-30天
- 人力成本:2名高级工程师 × 1个月 = $20,000+更要命的是:网站一改版,代码就挂了,又要重新开发...
痛点2:多网站扩展困难,规模化遇瓶颈
企业级数据采集的挑战:
需求:采集100个垂直电商网站的商品数据
现实:
- 每个网站结构不同,无法复用代码
- 100个网站 × 2天开发 = 200人天(约8个月)
- 维护成本:每月至少20%的网站会改版
- 团队压力:工程师的时间全耗在重复劳动上
结果:项目延期6个月,团队士气低落,核心AI算法没时间优化痛点3:AI/SEO/AEO时代的数据采集新挑战
什么是AEO(AI Engine Optimization)?
定义:AEO是一种针对AI搜索引擎(如ChatGPT、Claude、Perplexity)进行内容优化的策略,目的是让你的品牌、产品在AI生成的答案中获得更高的曝光度和引用率。
就像以前做SEO是为了在Google搜索结果中排名靠前,现在做AEO是为了在AI聊天机器人的回答中被提及。比如当用户问"最好用的项目管理工具是什么?"时,你希望AI回答时提到你的产品。
- 🔧 实际作用:它能帮你在AI时代占据信息入口,提升品牌影响力
- 💡 核心理解:简单来说就是"让AI记住你、推荐你"
- 🎯 业务价值:AI引用一次,相当于传统广告曝光10000次
新时代的数据采集挑战:
- 多平台数据:需要同时采集YouTube、TikTok、Instagram、Twitter、知乎、小红书...
- 数据复杂度提升:不仅要内容,还要评论、互动、情绪、用户画像
- 实时性要求:品牌监控需要小时级甚至分钟级更新
- 规模爆炸:AI训练需要百万级甚至千万级的数据样本
某AI SEO工具公司的需求:
任务:监控品牌在10个平台的提及情况
数据源:
- YouTube产品评测视频(含字幕+评论+情绪分析)
- TikTok带货视频(含互动数据+流量趋势)
- 小红书种草笔记(含用户画像+传播路径)
- Twitter讨论串(含情绪分析+影响力用户)
...
传统方案:10个平台,10套爬虫,10倍的工程复杂度 ❌
需求:一套系统,自适应所有平台 ✓如果是你来设计这个数据采集系统,你会考虑哪些因素?代码复用性?可维护性?还是...有没有可能根本不需要写代码?
二、Bright Data的三种数据采集方案
在解决上述痛点之前,我们先来了解一下Bright Data提供的三种数据采集方案。每种方案都有其适用场景,根据你的需求和技术背景选择最合适的即可。
方案1:Web Scraper API - 开箱即用的标准化方案
一句话概括:调用API,直接获取常见网站的标准化数据。
适合人群:
- 需要采集主流网站(Amazon、eBay、LinkedIn等)
- 只需要标准字段,不需要自定义
- 追求快速接入,不想处理技术细节
核心特点:
- ✅ 预定义的爬虫模板,开箱即用
- ✅ 标准化的数据结构,无需清洗
- ✅ 几行代码即可调用
- ❌ 仅支持有限的网站列表
- ❌ 字段固定,无法自定义
典型场景:电商卖家需要采集Amazon竞品价格,使用预定义API即可。
方案2:IDE自定义开发 - 完全可控的专业方案
一句话概括:在Bright Data的IDE中编写完全自定义的爬虫代码。
适合人群:
- 有编程能力的技术团队
- 需要采集任意网站(包括非常规网站)
- 有复杂定制需求(登录、多步骤操作等)
- 愿意投入时间维护和优化代码
核心特点:
- ✅ 完全自定义,无限制
- ✅ 适用于任何网站
- ✅ 可实现复杂业务逻辑
- ❌ 需要编程能力
- ❌ 开发和维护成本高
典型场景:需要登录后台系统采集内部数据,或处理复杂的动态加载逻辑。
方案3:AI Scraper Studio - 智能化的最佳平衡 ⭐推荐
一句话概括:用自然语言描述需求,AI自动生成爬虫代码。
适合人群:
- 需要快速扩展多网站数据采集
- 追求开发效率和可维护性的平衡
- 初期零代码,后期可深度定制
- 想要"prompt驱动"的全新体验
核心特点:
- 自然语言生成爬虫,2分钟上线
- 用于任意网站
- 网站改版?一键重新生成
- 需要时可进入IDE优化
- 兼顾易用性和灵活性
典型场景:AI训练数据采集、品牌监控、竞品分析等需要快速扩展到多个网站的场景。
三、AI Scraper Studio:prompt驱动的爬虫革命
什么是AI Scraper Studio?
Bright Data AI Scraper Studio是全球首个真正意义上的"自然语言驱动爬虫生成"平台。
传统方式 vs AI Scraper Studio:
传统方式:
1. 分析网页结构 (30分钟)
2. 写CSS选择器代码 (1小时)
3. 处理分页逻辑 (1小时)
4. 应对反爬虫 (2小时)
5. 数据清洗 (1小时)
6. 测试调试 (2小时)
总计:7-8小时
AI Scraper Studio:
1. 输入一句话:"采集这个网站的所有产品标题、价格和评价"
2. 点击"生成"
3. 爬虫代码自动生成完毕
总计:2分钟 技术原理简述:
是 否 用户输入自然语言prompt AI解析需求 智能分析目标网页结构 自动生成爬虫脚本 集成Bright Data全球代理网络 执行数据采集 网站变动? 一键重新生成 持续稳定运行 结构化数据输出
AI Scraper Studio的5大核心优势
Prompt驱动,分钟级上线
官方定义:通过自然语言处理技术,将用户的文本描述自动转换为可执行的爬虫代码,无需编写任何代码即可完成复杂的数据采集任务。
就像跟一个超级聪明的助手说话一样------"帮我把这个网站的所有产品信息抓下来",然后他就自动帮你写好代码、部署好服务、开始采集数据。你只需要说,不需要动手。
- 比喻角度:就像以前打车要自己开车,现在叫个滴滴就行
- 核心理解:简单来说就是"把技术活变成了沟通"
- 实际作用:让非技术人员也能完成专业爬虫开发
实际对比:
传统方式:
def scrape_product(url):
# 100+行代码
headers = {...}
response = requests.get(url, headers=headers, proxies=proxies)
soup = BeautifulSoup(response.text, 'html.parser')
products = soup.select('.product-item')
# 处理分页、错误重试、数据清洗...
...
AI Scraper Studio:
prompt: "采集https://example.com所有产品的标题、价格、评分、销量和商品链接"
↓ (2分钟后)
✓ 爬虫已生成并部署
✓ 数据采集中...
✓ 已采集 1,234 条产品数据开发时间对比:
| 任务 | 传统方式 | AI Scraper Studio |
|---|---|---|
| 单个网站 | 2-3天 | 2分钟 |
| 10个网站 | 20-30天 | 20分钟 |
| 100个网站 | 200-300天 | 3小时 |
| 学习成本 | 需要Python/爬虫经验 | 会打字就行 |
一键应对网站变动
技术能力:
- 智能检测:自动监测网站结构变化
- 一键重新生成:网站改版?点击"Regenerate"即可
- 全球代理支持:集成Bright Data 7200万+住宅IP池
- 反爬虫自适应:自动应对封锁、验证码、地理限制
真实场景对比:
传统方式:
2024-01-01: 爬虫上线 ✓
2024-01-15: 网站改版,爬虫挂了 ✗
2024-01-16: 工程师分析新结构 (4小时)
2024-01-17: 修改代码并测试 (6小时)
2024-01-18: 重新部署 ✓
维护成本: 10小时工程师时间
AI Scraper Studio:
2024-01-01: 爬虫上线 ✓
2024-01-15: 网站改版,系统自动检测 ⚠️
2024-01-15: 点击"Regenerate"按钮
2024-01-15: 新爬虫生成完毕 ✓
维护成本: 1分钟点击操作可控性比较高
渐进式设计哲学:
入门用户
纯prompt操作 进阶用户
微调参数 专业用户
IDE代码优化 技术团队
完全自定义
三个层次的灵活性:
层次1:零代码prompt(适合90%场景)
用户输入:
"采集https://news.example.com最新100篇新闻的标题、作者、发布时间、正文内容和评论数"
系统理解:
✓ 目标网站:news.example.com
✓ 采集数量:100篇
✓ 数据字段:title, author, publish_time, content, comment_count
✓ 自动处理分页
✓ 自动去重层次2:参数微调
javascript
// 在Web界面点击"高级设置"
{
"max_pages": 10,
"delay_between_requests": 2000, // 每次请求间隔2秒
"user_agent": "custom",
"geo_location": "US", // 模拟美国IP
"include_comments": true,
"max_comments_per_article": 50
}层次3:IDE代码级优化(适合复杂场景)
javascript
// 进入IDE,查看并优化生成的代码
export default async function scraper(page) {
// AI自动生成的基础代码
await page.goto(url);
// 你可以添加自定义逻辑
await page.waitForSelector('.article-list');
// 自定义数据提取
const articles = await page.$$eval('.article-item', items => {
return items.map(item => ({
title: item.querySelector('.title').innerText,
author: item.querySelector('.author').innerText,
// 添加自定义字段处理
customField: processCustomLogic(item)
}));
});
return articles;
}企业级交付,支持大规模持续运行
多种数据交付方式:
python
# 方式1:REST API调用
import requests
response = requests.post(
'https://api.brightdata.com/v1/scraper/run',
headers={'Authorization': 'Bearer YOUR_TOKEN'},
json={
'scraper_id': 'abc123',
'urls': ['https://example.com/page1', 'https://example.com/page2']
}
)
# 方式2:Webhook自动推送
# 数据采集完成后自动POST到你的服务器
config = {
'webhook_url': 'https://yourdomain.com/webhook',
'events': ['scraper.completed', 'scraper.failed']
}
# 方式3:云存储集成
# 自动保存到S3/Azure/GCS
config = {
'output': {
'type': 's3',
'bucket': 'your-bucket',
'path': 'scraped-data/{date}/{scraper_id}.json'
}
}
# 方式4:数据库直连
# 直接写入MySQL/PostgreSQL/MongoDB
config = {
'output': {
'type': 'postgresql',
'connection': 'postgresql://user:pass@host:5432/db',
'table': 'scraped_products'
}
}数据格式支持:
- JSON(推荐,适合API和AI训练)
- CSV(适合Excel分析)
- Parquet(适合大数据处理)
- NDJSON(适合流式处理)
- 自定义格式(通过代码转换)
企业级调度能力:
yaml
# 调度配置示例
schedule:
type: cron
expression: "0 */6 * * *" # 每6小时执行一次
concurrency:
max_parallel: 1000 # 最大并发1000个任务
retry_policy:
max_retries: 3
backoff: exponential
monitoring:
alerts:
- type: email
trigger: failure_rate > 5%
- type: slack
trigger: completion三、5分钟上手实战:从prompt到生产级爬虫
第1步:注册账号并选择AI Scraper Studio
-
使用邮箱/GitHub/Google账号注册
-
验证邮箱后自动登录Dashboard
-
在Dashboard中选择"Web Datasets" → 点击"构建网络爬虫"
第2步:用自然语言生成你的第一个爬虫
进入构建爬虫页面之后,选择一个数据集,然后进入之后。来到个人的数据库配置界面,这里面会有引导生成代码的步骤。
场景示例:采集电商产品数据
在AI Scraper Studio界面中,你会看到两个输入框:
🔗 目标网站URL:
https://www.amazon.com/s?k=laptop
采集需求描述:
采集搜索结果页面的所有笔记本电脑产品信息,包括:
- 产品名称
- 价格
- 评分(星级)
- 评论数量
- 产品图片URL
- 产品详情页链接点击"生成爬虫"按钮,等待10-30秒...
系统自动完成:
- ✅ 分析目标网页结构
- ✅ 生成爬虫代码
- ✅ 配置反爬虫策略
- ✅ 部署到Bright Data全球网络
- ✅ 开始采集数据
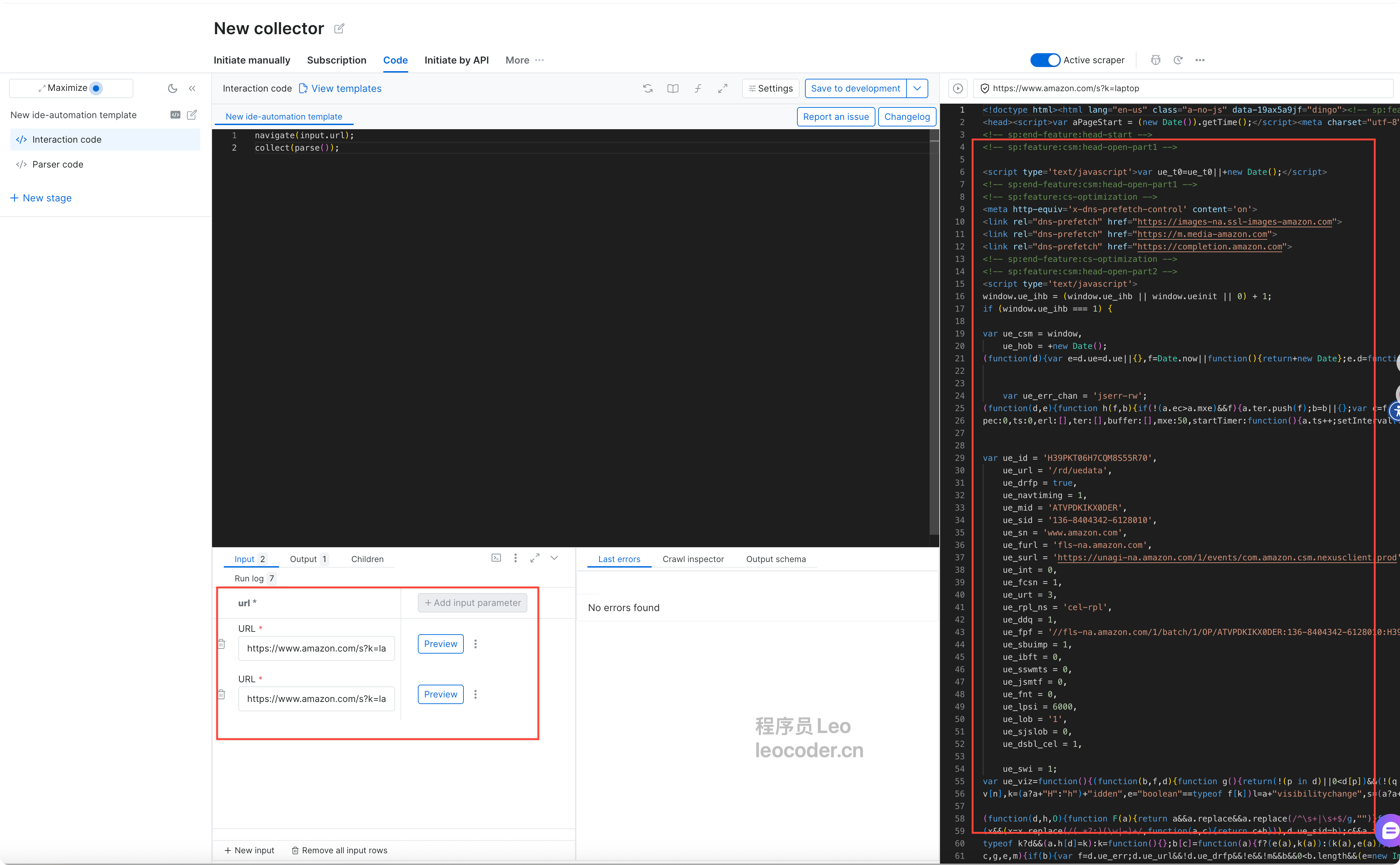
看到这个界面就说明代码以及生成成功了,点击preview预览接口,然后就可以下载它给我生成的json数据。
生成的爬虫代码预览:
javascript
export default async function scraper(page, context) {
const url = context.url;
await page.goto(url);
// 等待产品列表加载
await page.waitForSelector('[data-component-type="s-search-result"]');
// 提取产品数据
const products = await page.$$eval('[data-component-type="s-search-result"]', items => {
return items.map(item => {
const titleElement = item.querySelector('h2 a span');
const priceElement = item.querySelector('.a-price-whole');
const ratingElement = item.querySelector('.a-icon-star-small span');
const reviewElement = item.querySelector('[aria-label*="ratings"]');
const imageElement = item.querySelector('img.s-image');
const linkElement = item.querySelector('h2 a');
return {
title: titleElement?.innerText || '',
price: priceElement?.innerText || '',
rating: ratingElement?.innerText?.split(' ')[0] || '',
reviews: reviewElement?.innerText || '',
image: imageElement?.src || '',
link: linkElement?.href || ''
};
});
});
return products;
}第3步:运行爬虫并获取数据
点击"运行"按钮后,系统开始执行:
⚡ 任务已启动
🔄 使用Bright Data全球代理网络
📍 当前使用:美国弗吉尼亚州代理
⏳ 预计完成时间:30秒
进度:
[████████████████████] 100% (已采集 16/16 个产品)
✓ 采集完成!
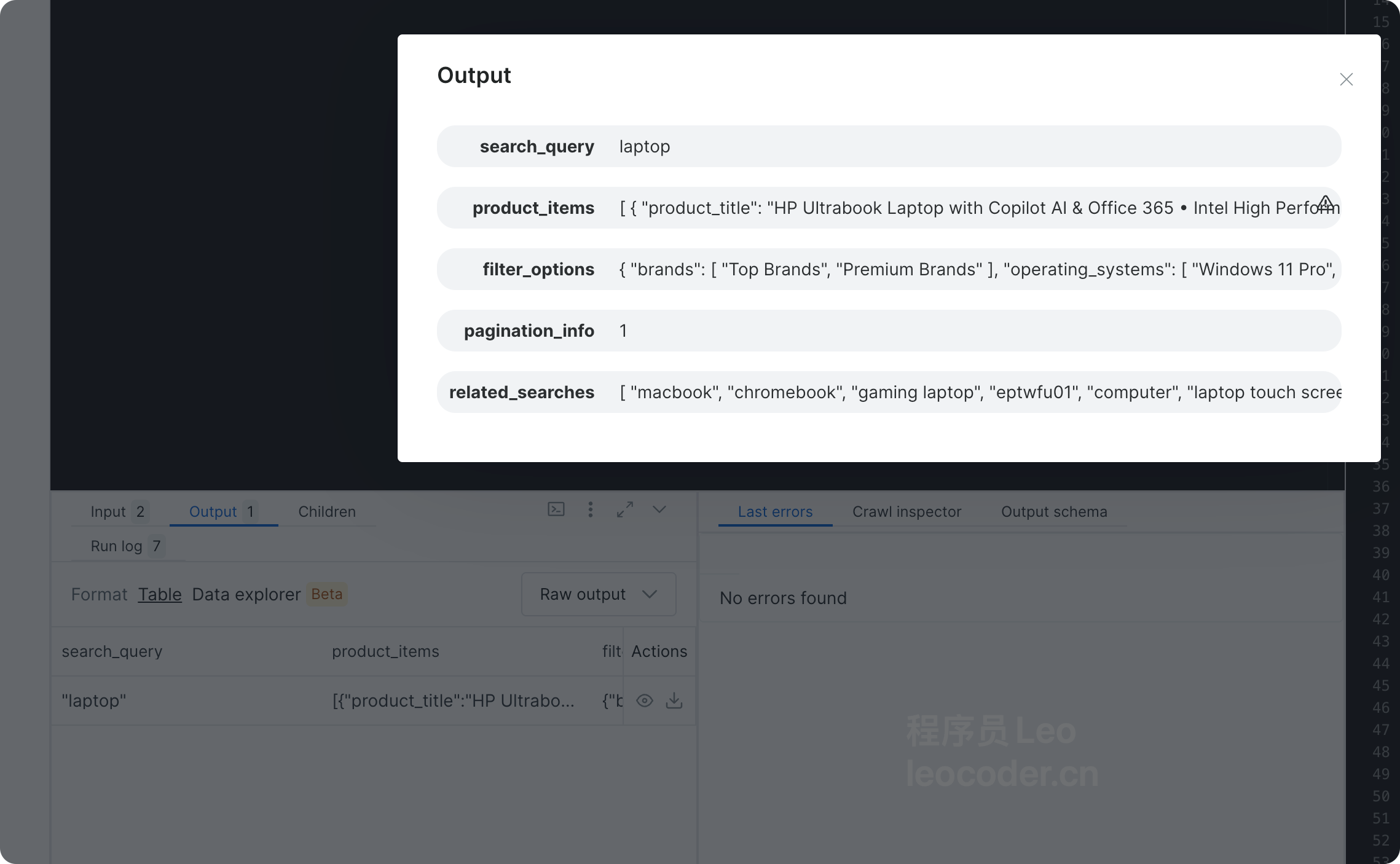
💾 数据已保存到: /Users/gaoziman/Downloads/lines.json数据预览:

json
{
"scraped_at": "2024-12-05T10:30:00Z",
"total_items": 16,
"data": [
{
"title": "HP Ultrabook Laptop with Copilot AI & Office 365 • Intel High Performance CPU • 8GB RAM • 1.3TB Storage (320GB SSD and 1TB OneDrive) • Windows 11 w/o Earbuds",
"current_price": "$269.99",
"original_price": "$679.99",
"discount": "60% OFF",
"rating": "4.5",
"reviews": "789",
"popular_indicator": "1K+ bought in past month",
},
{
"title": "HP 15.6 inch Laptop, HD Touchscreen Display, AMD Ryzen 3 7320U, 8 GB RAM, 128 GB SSD, AMD Radeon Graphics, Windows 11 Home in S Mode, Natural Silver",
"current_price": "$376.96",
"original_price": null,
"rating": "4.5",
"reviews": "885",
"popular_indicator": "10K+ bought in past month",
"amazon_choice": true,
},
{
"title": "Apple 2025 MacBook Air 13-inch Laptop with M4 chip: Built for Apple Intelligence, 13.6-inch Liquid Retina Display, 16GB Unified Memory, 256GB SSD Storage",
"current_price": "$749.99",
"original_price": "$999.00",
"discount": "25% OFF",
"rating": "4.8",
"reviews": "4200",
"is_best_seller": true,
}
// ... 还有13个产品
]
}数据统计分析:
从采集的16款笔记本电脑数据中,系统自动完成了以下统计:
价格分析:
- 价格区间:124.99 - 749.99
- 平均价格:约 $308.18
- 最优惠产品:HP 14 Laptop (167.00,原价229.99,节省27%)
- 最高端产品:Apple MacBook Air M4 ($749.99,Best Seller标识)
- 折扣幅度:27% - 63%(大部分产品提供优惠)
品牌分布:
- HP品牌:7款产品(占比43.75%)- 市场主导地位
- Lenovo:3款产品(18.75%)
- 其他品牌:Acer、Apple、Dell、Samsung各1款
- 热门关键词:"AI"、"Copilot"、"Touchscreen"频繁出现
用户评价分析:
- 平均评分:4.38星(整体质量优秀)
- 高评分产品(≥4.5星):10款(占62.5%)
- 评论数最多:HP 14 Laptop(4,400条评论)
- 最高评分:Apple MacBook Air M4(4.8星,4,200条评论)
热度指标分析:
- "10K+ bought in past month":4款产品(超级爆款)
- "5K+ bought in past month":3款产品(热销产品)
- "1K-2K bought in past month":5款产品(稳定销售)
- Amazon's Choice:1款(HP 15.6 inch Touchscreen)
- Best Seller:1款(Apple MacBook Air M4)
市场洞察:
- AI概念强势崛起:排名第1的产品标题包含"Copilot AI",虽然仅售$269.99但折扣高达60%,说明AI功能成为重要卖点
- 性价比是王道:250-400价格区间的产品最受欢迎,占据"10K+ bought"的主流位置
- HP统治地位明显:43.75%的搜索结果来自HP品牌,远超其他竞争对手
- 高端市场稳中有升:Apple产品虽然价格最高($749.99),但4.8星评分和Best Seller标识证明高端用户忠诚度极高
- 触摸屏成标配:多款产品强调"Touchscreen",反映市场需求变化
这些数据可以直接用于:
- 电商运营策略调整(定价、库存管理)
- 竞品分析和市场定位
- 营销文案优化(突出"AI"、"性价比"等关键词)
- 供应链决策(HP产品需求量大)
- 广告投放策略(关注250-400价格段)
四、其他两种方案
在深入了解了AI Scraper Studio的强大能力后,让我们再来看看另外两种方案。这样你就能做出更全面的选择。
方案1:Web Scraper API - 标准化数据采集
介绍:
Web Scraper API是Bright Data为常见网站预先开发好的标准化爬虫服务。你只需要调用API,传入参数(如关键词、页数等),就能直接获取结构化的数据。
适合人群:
- 需要快速上手,无编程基础
- 采集常见网站(亚马逊、eBay、LinkedIn等)
- 使用预定义的数据字段
使用场景示例:
python
# 采集Amazon产品数据
from brightdata import WebScraperAPI
api = WebScraperAPI(api_key="YOUR_KEY")
# 直接调用预定义的Amazon爬虫
results = api.scrape_amazon_products(
keywords="laptop",
country="US",
max_pages=5
)
# 返回标准化的数据结构
for product in results:
print(f"{product['title']}: ${product['price']}")优势:
- 开箱即用,无需编写代码
- 数据结构标准化,无需清洗
- 反爬虫策略已内置
- 按需付费,成本可控
局限性:
- 仅支持有限的热门网站
- 字段固定,无法自定义
- 不适合特殊需求场景
适用场景:
- 电商卖家监控竞品价格
- 市场研究采集标准化数据
- 快速验证商业idea
方案2:IDE自定义开发 - 完全可控的专业方案
介绍:
如果你有编程能力,并且需要采集的网站不在Web Scraper API的支持列表中,或者有非常特殊的定制需求,那么可以使用Bright Data的IDE来编写完全自定义的爬虫代码。
适合人群:
- 有编程能力的技术团队
- 需要采集任意网站(包括非常规网站)
- 有复杂的定制化需求(如需要登录、多步骤操作等)
- 愿意自行维护和升级代码
使用场景示例:
javascript
// 在Bright Data IDE中编写完全自定义的爬虫
export default async function scraper(page, context) {
// 完全自定义的复杂采集逻辑
// 1. 先登录
await page.goto('https://example.com/login');
await page.type('#username', context.credentials.username);
await page.type('#password', context.credentials.password);
await page.click('#login-button');
await page.waitForNavigation();
// 2. 搜索产品
await page.goto('https://custom-website.com/search');
await page.type('#search-input', context.keyword);
await page.click('#search-button');
// 3. 处理复杂的动态加载
await page.waitForSelector('.product-list');
// 滚动加载更多内容
let previousHeight = 0;
while (true) {
const currentHeight = await page.evaluate('document.body.scrollHeight');
if (currentHeight === previousHeight) break;
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)');
await page.waitForTimeout(2000);
previousHeight = currentHeight;
}
// 4. 提取自定义字段
const data = await page.$$eval('.product-item', items => {
return items.map(item => ({
title: item.querySelector('.title')?.innerText,
customField1: item.getAttribute('data-custom'),
customField2: calculateSpecialValue(item) // 自定义处理逻辑
}));
});
// 5. 数据后处理
return processData(data);
}优势:
- 完全自定义,无任何限制
- 适用于任何网站
- 可实现复杂业务逻辑
- 集成Bright Data全球代理网络
局限性:
- 需要编程能力(JavaScript)
- 开发和维护成本较高
- 网站改版需要手动修改代码
适用场景:
- 需要登录后采集内部数据
- 处理复杂的多步骤交互
- 采集特殊网站(小众、定制化)
- 有特殊的数据处理需求
五、如何选型?三种方案全面对比
现在你已经了解了三种方案的详细情况,让我们来看看如何根据你的实际需求选择最合适的方案。
选型决策树
六、总结:数据采集的范式转变
写在最后
2024-2025年,我们正在经历数据采集领域的一次重大变革。
传统爬虫开发的"黄金时代"已经过去,取而代之的是AI驱动的智能化数据采集时代。
这不是说传统的爬虫技术没有价值了,而是说对于90%的数据采集需求,我们有了更好的选择。
就像现在还有人开手动挡汽车,但大部分人都选择了自动挡------不是因为手动挡不好,而是因为自动挡更适合大多数场景。
如果你有以下需求:
- AI训练数据采集
- 市场数据监控
- SEO/AEO优化
- 电商竞品分析
- 内容聚合
- 任何需要大规模数据采集的场景
不妨试试AI Scraper Studio,它可能会颠覆你对爬虫开发的认知。