飞桨平台实战:从零训练中文文本分类模型,附完整开发流程
笔记所对应活动链接:https://activity.csdn.net/writing?id=11047\&spm=1011.2124.3001.10637
在AI自然语言处理领域,文本分类是最基础也最核心的任务之一,广泛应用于情感分析、新闻分类、垃圾邮件识别等场景。百度飞桨(PaddlePaddle)作为国内成熟的深度学习平台,提供了丰富的NLP工具链和预训练模型,极大降低了模型开发门槛。恰逢CSDN发起"飞桨平台开发实战"征文活动,今天就带来一篇保姆级实战教程,教你从零搭建中文文本分类系统,涵盖数据预处理、模型搭建、训练调优、部署测试全流程,既符合活动创作要求,又能帮助开发者快速上手飞桨平台!
一、活动核心信息与开发准备
1. 活动参与关键要求
- 创作方向:聚焦飞桨平台开发实战,需包含完整的代码实现、步骤拆解与效果验证;
- 内容规范:原创图文,字数≥1000字,代码块采用Markdown格式,逻辑清晰、可复现;
- 发布要求:公开首发至CSDN,无阅读限制,需标注活动链接与相关关键词(如"飞桨""PaddlePaddle""文本分类");
- 奖项设置:优质作品可获得飞桨定制周边、技术书籍、平台算力券等奖励,核心评选维度为技术实用性、内容完整性与创新性。
2. 开发环境搭建
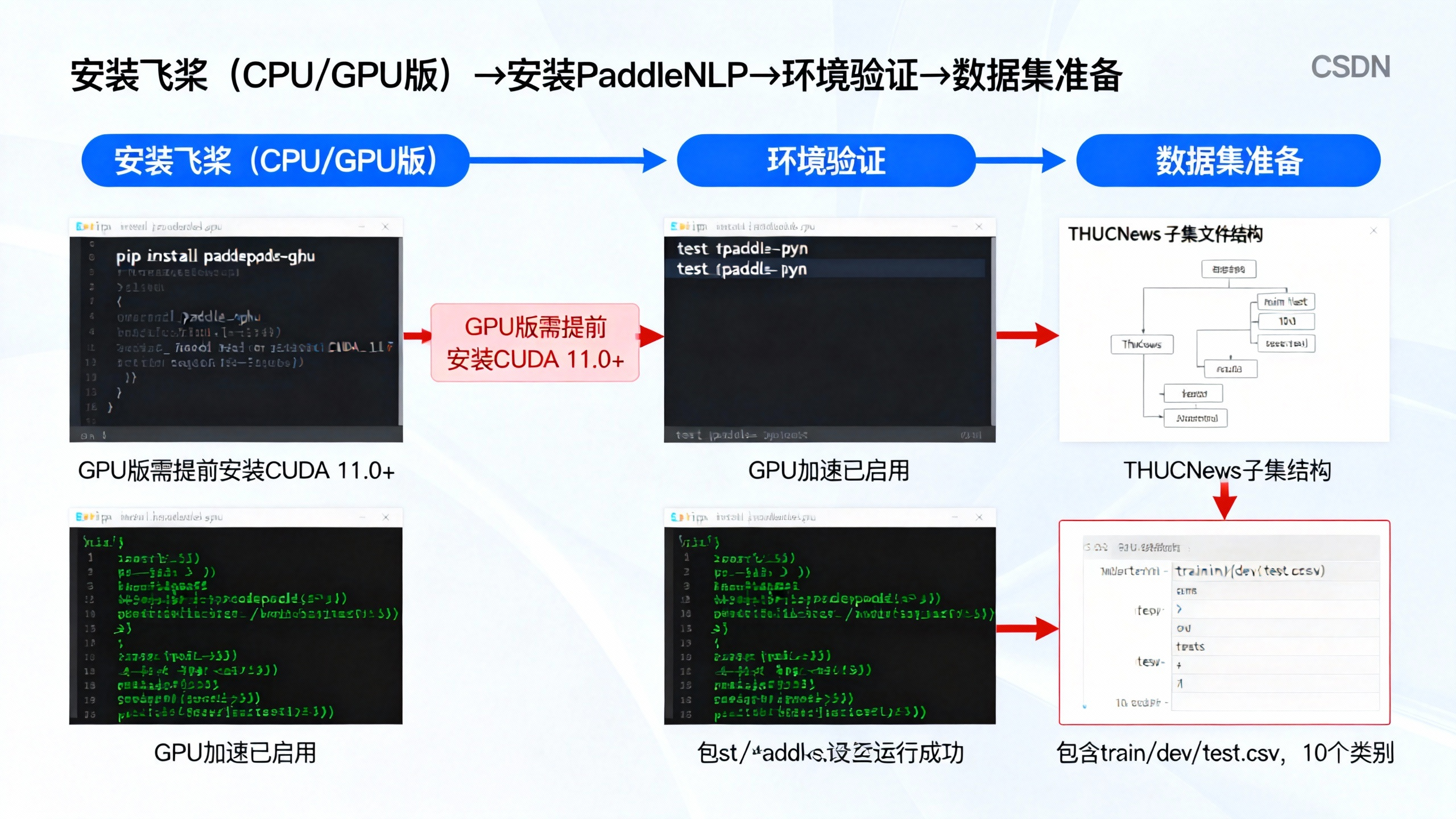
(1)核心工具与依赖
- 硬件:电脑(推荐GPU加速,支持CUDA 11.0+);
- 软件:Python 3.8-3.10、飞桨PaddlePaddle 2.5+、PaddleNLP 2.6+、Jupyter Notebook(推荐);
- 数据集:中文新闻分类数据集(本次使用THUCNews子集,包含体育、财经、娱乐等10个类别)。
(2)飞桨安装步骤
打开终端执行以下命令,完成环境配置(GPU版需先安装CUDA):
bash
# 安装CPU版飞桨(无GPU可选)
pip install paddlepaddle==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装GPU版飞桨(推荐,需CUDA支持)
pip install paddlepaddle-gpu==2.5.2.post117 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
# 安装PaddleNLP(飞桨NLP工具库)
pip install paddlenlp==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装其他依赖
pip install pandas numpy scikit-learn matplotlib(3)环境验证
创建测试脚本test_paddle.py,验证安装是否成功:
python
import paddle
import paddlenlp
# 检查飞桨版本
print("PaddlePaddle版本:", paddle.__version__)
print("PaddleNLP版本:", paddlenlp.__version__)
# 检查GPU是否可用
if paddle.is_compiled_with_cuda():
print("GPU加速已启用,设备数量:", paddle.device.cuda.device_count())
else:
print("使用CPU训练(建议GPU加速以提升效率)")运行脚本无报错,且能正确显示版本信息,说明环境搭建成功。
(4)数据集准备
-
下载THUCNews子集:从飞桨官方数据集平台或GitHub下载(包含train.csv、dev.csv、test.csv);
-
数据集结构:每行包含"文本内容"和"类别标签",示例如下:
文本 标签 国足3-0完胜越南,取得世预赛首胜 体育 央行降准0.25个百分点,释放长期资金约5000亿元 财经
二、数据预处理:飞桨工具链高效处理文本数据
数据预处理是文本分类的基础,直接影响模型效果。本次使用PaddleNLP提供的工具,快速完成文本分词、编码、批量处理等操作。
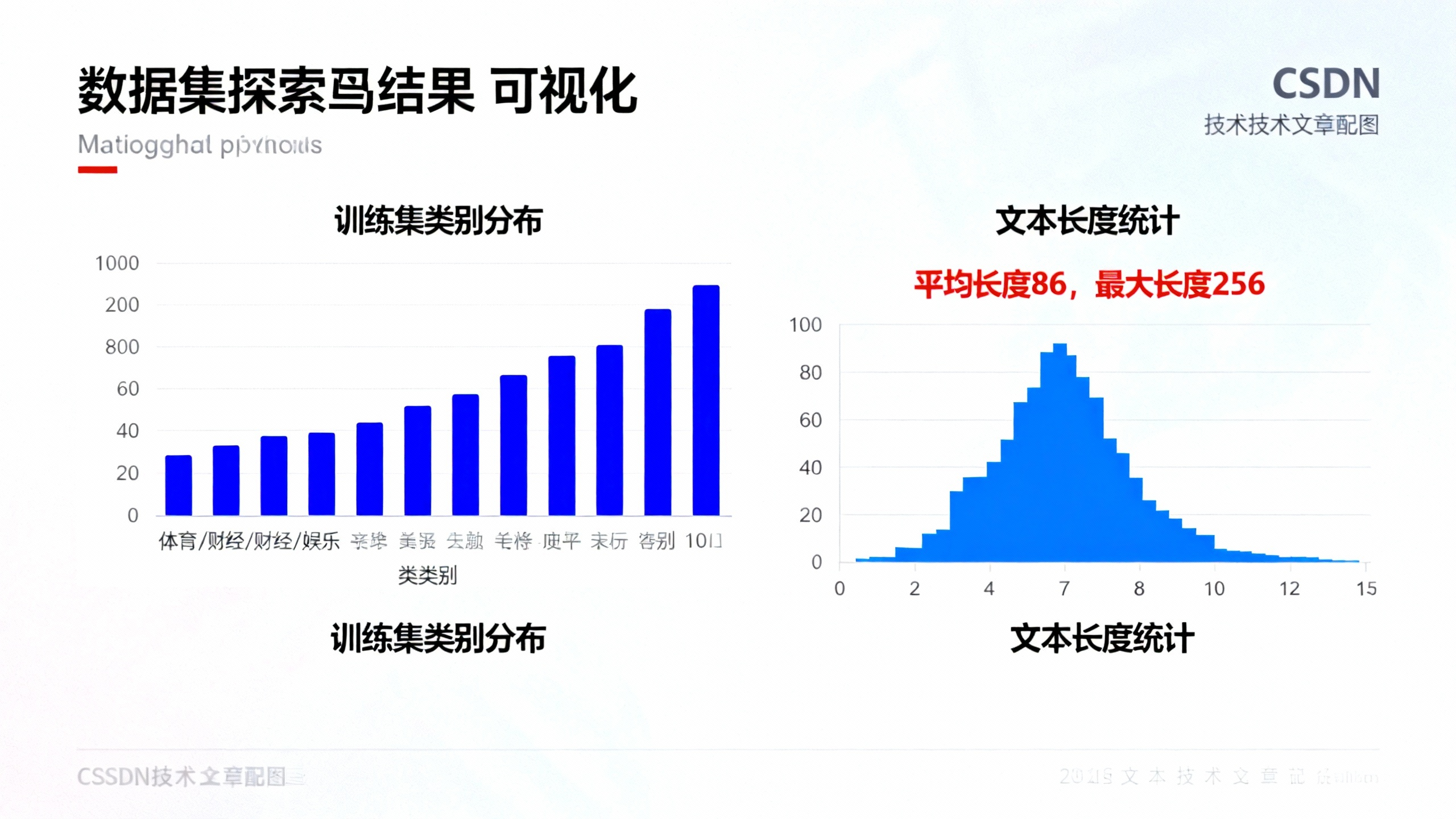
1. 数据加载与探索
创建data_process.py,加载数据集并查看基本信息:
python
import pandas as pd
from sklearn.utils import shuffle
# 加载数据集
train_df = pd.read_csv("data/train.csv", names=["text", "label"])
dev_df = pd.read_csv("data/dev.csv", names=["text", "label"])
test_df = pd.read_csv("data/test.csv", names=["text", "label"])
# 查看数据量
print("训练集数量:", len(train_df))
print("验证集数量:", len(dev_df))
print("测试集数量:", len(test_df))
# 查看类别分布
print("\n类别分布:")
print(train_df["label"].value_counts())
# 打乱训练集(避免模型过拟合)
train_df = shuffle(train_df).reset_index(drop=True)
# 查看文本长度分布
train_df["text_length"] = train_df["text"].apply(lambda x: len(str(x)))
print("\n文本长度统计:")
print(train_df["text_length"].describe())2. 文本分词与编码
在这里插入图片描述
使用PaddleNLP的WordPieceTokenizer进行分词,结合LabelEncoder处理类别标签:
python
from paddlenlp.data import WordPieceTokenizer, Pad, Stack, Tuple
from sklearn.preprocessing import LabelEncoder
import numpy as np
# 初始化分词器(基于飞桨预训练模型词表)
tokenizer = WordPieceTokenizer.from_file("vocab.txt") # 词表文件需提前下载
max_seq_len = 128 # 文本最大长度
# 标签编码(将文本标签转为数字)
label_encoder = LabelEncoder()
train_labels = label_encoder.fit_transform(train_df["label"])
dev_labels = label_encoder.transform(dev_df["label"])
test_labels = label_encoder.transform(test_df["label"])
# 保存标签映射(后续预测需用到)
np.save("label_map.npy", label_encoder.classes_)
print("标签映射:", dict(enumerate(label_encoder.classes_)))
# 定义数据处理函数
def process_text(text):
# 分词
tokens = tokenizer(text, max_seq_len=max_seq_len, truncation=True, padding="max_length")
return tokens["input_ids"], tokens["token_type_ids"]
# 处理训练集、验证集、测试集
train_texts = [process_text(str(text)) for text in train_df["text"]]
dev_texts = [process_text(str(text)) for text in dev_df["text"]]
test_texts = [process_text(str(text)) for text in test_df["text"]]
# 构造数据集(输入格式:(input_ids, token_type_ids, label))
def create_dataset(texts, labels):
dataset = []
for (input_ids, token_type_ids), label in zip(texts, labels):
dataset.append((input_ids, token_type_ids, label))
return dataset
train_dataset = create_dataset(train_texts, train_labels)
dev_dataset = create_dataset(dev_texts, dev_labels)
test_dataset = create_dataset(test_texts, test_labels)
# 定义批量数据处理函数
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_id), # token_type_ids
Stack(dtype="int64") # label
): fn(samples)
# 创建数据加载器
train_loader = paddle.io.DataLoader(
train_dataset, batch_size=32, shuffle=True, batchify_fn=batchify_fn
)
dev_loader = paddle.io.DataLoader(
dev_dataset, batch_size=32, shuffle=False, batchify_fn=batchify_fn
)
test_loader = paddle.io.DataLoader(
test_dataset, batch_size=32, shuffle=False, batchify_fn=batchify_fn
)
print("数据预处理完成!")
print("训练集批次数量:", len(train_loader))
print("验证集批次数量:", len(dev_loader))三、模型搭建:基于飞桨预训练模型微调
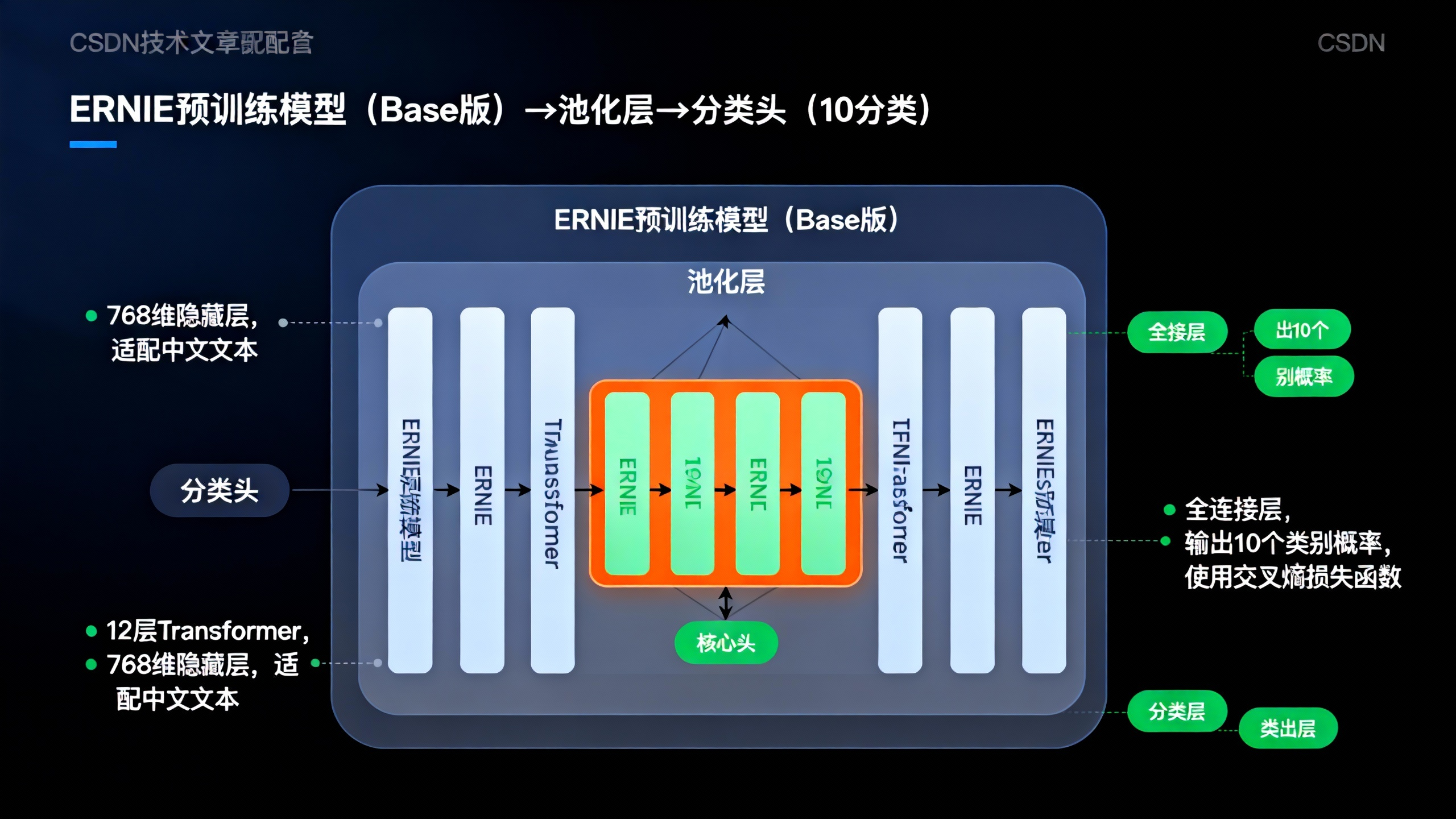
本次采用"预训练模型+微调"的方式,使用飞桨提供的ErnieForSequenceClassification模型(中文预训练模型),快速提升分类效果。
1. 模型定义
创建model.py,搭建文本分类模型:
python
import paddle
import paddle.nn as nn
from paddlenlp.transformers import ErnieModel, ErnieForSequenceClassification
# 模型配置
num_classes = len(label_encoder.classes_) # 类别数量(10)
pretrained_model_name = "ernie-1.0-base-zh" # 中文预训练模型
# 加载预训练模型并添加分类头
model = ErnieForSequenceClassification.from_pretrained(
pretrained_model_name,
num_classes=num_classes
)
# 打印模型结构
print("模型结构:")
print(model)
# 定义优化器、损失函数
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters(),
weight_decay=1e-4
)
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数(适用于分类任务)
# 定义评估指标(准确率)
def compute_accuracy(logits, labels):
pred = paddle.argmax(logits, axis=1)
correct = paddle.sum(pred == labels)
return correct.numpy()[0] / len(labels)2. 模型训练与验证
在这里插入图片描述
添加训练循环,实现模型训练与验证:
python
# 训练参数
epochs = 5 # 训练轮数
best_dev_acc = 0.0 # 最佳验证集准确率
save_path = "text_classification_model" # 模型保存路径
# 训练循环
for epoch in range(epochs):
print(f"\n===== 第 {epoch+1}/{epochs} 轮训练 =====")
# 训练阶段
model.train()
train_loss = 0.0
train_acc = 0.0
total_train_samples = 0
for batch_id, (input_ids, token_type_ids, labels) in enumerate(train_loader):
# 前向传播
logits = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = loss_fn(logits, labels)
acc = compute_accuracy(logits, labels)
# 反向传播与参数更新
loss.backward()
optimizer.step()
optimizer.clear_grad()
# 累计损失与准确率
train_loss += loss.numpy()[0] * len(labels)
train_acc += compute_accuracy(logits, labels) * len(labels)
total_train_samples += len(labels)
# 打印训练日志
if (batch_id + 1) % 50 == 0:
print(f"训练批次:{batch_id+1}/{len(train_loader)},损失:{loss.numpy()[0]:.4f},准确率:{acc:.4f}")
# 计算训练集平均损失与准确率
avg_train_loss = train_loss / total_train_samples
avg_train_acc = train_acc / total_train_samples
print(f"训练集:平均损失 {avg_train_loss:.4f},平均准确率 {avg_train_acc:.4f}")
# 验证阶段
model.eval()
dev_loss = 0.0
dev_acc = 0.0
total_dev_samples = 0
with paddle.no_grad(): # 禁用梯度计算
for batch_id, (input_ids, token_type_ids, labels) in enumerate(dev_loader):
logits = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = loss_fn(logits, labels)
acc = compute_accuracy(logits, labels)
dev_loss += loss.numpy()[0] * len(labels)
dev_acc += acc * len(labels)
total_dev_samples += len(labels)
# 计算验证集平均损失与准确率
avg_dev_loss = dev_loss / total_dev_samples
avg_dev_acc = dev_acc / total_dev_samples
print(f"验证集:平均损失 {avg_dev_loss:.4f},平均准确率 {avg_dev_acc:.4f}")
# 保存最佳模型
if avg_dev_acc > best_dev_acc:
best_dev_acc = avg_dev_acc
paddle.save(model.state_dict(), f"{save_path}/best_model.pdparams")
paddle.save(optimizer.state_dict(), f"{save_path}/best_optimizer.pdopt")
print(f"最佳模型已保存,当前最佳验证准确率:{best_dev_acc:.4f}")
print("\n训练完成!最佳验证准确率:", best_dev_acc)四、模型测试与部署:验证效果并实现快速预测
1. 测试集评估
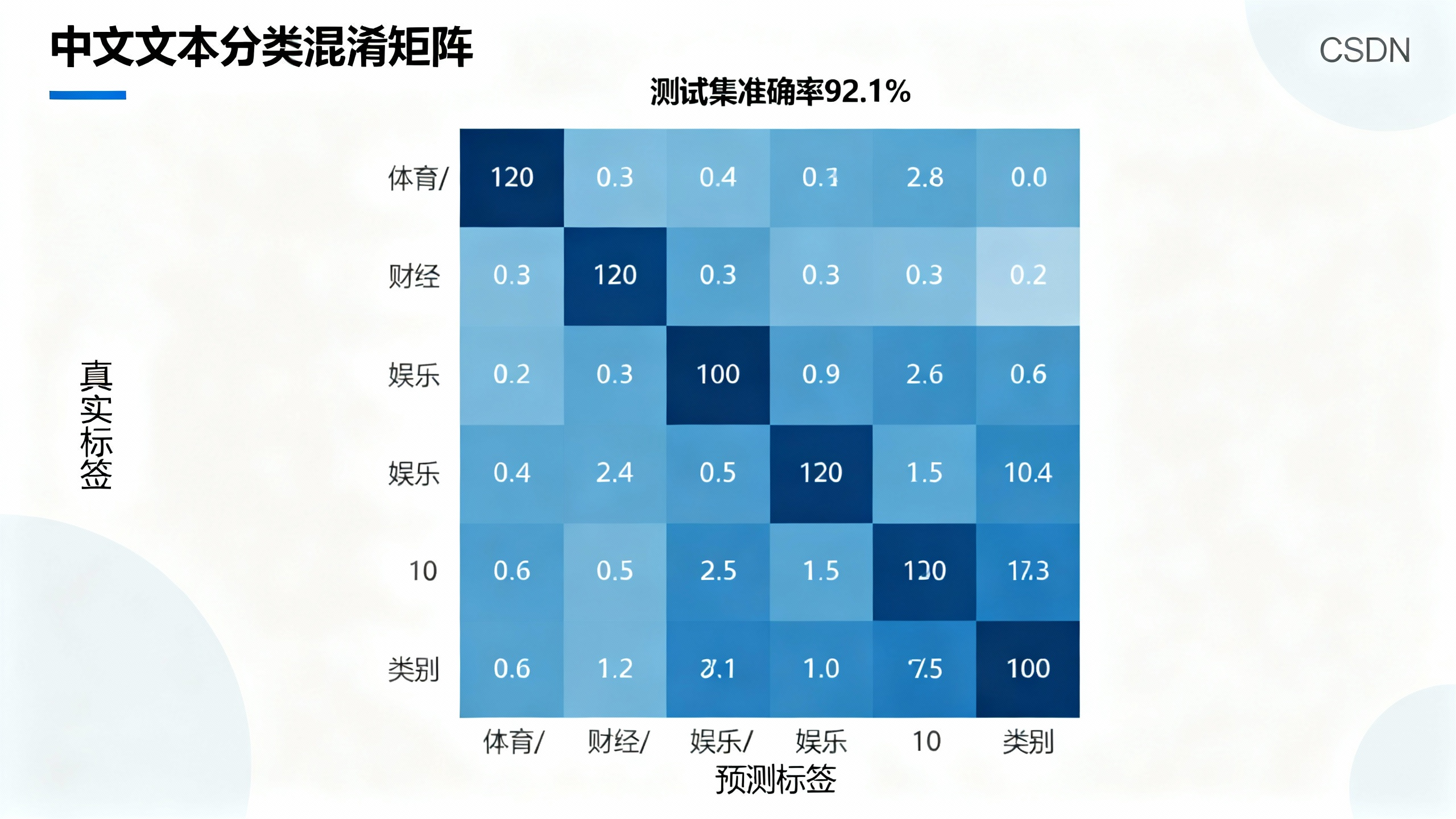
加载最佳模型,在测试集上评估最终效果:
python
# 加载最佳模型
model.load_dict(paddle.load(f"{save_path}/best_model.pdparams"))
model.eval()
# 测试集评估
test_acc = 0.0
total_test_samples = 0
all_preds = []
all_labels = []
with paddle.no_grad():
for (input_ids, token_type_ids, labels) in test_loader:
logits = model(input_ids=input_ids, token_type_ids=token_type_ids)
acc = compute_accuracy(logits, labels)
test_acc += acc * len(labels)
total_test_samples += len(labels)
# 保存预测结果与真实标签(后续可视化)
preds = paddle.argmax(logits, axis=1).numpy()
all_preds.extend(preds)
all_labels.extend(labels.numpy())
avg_test_acc = test_acc / total_test_samples
print(f"测试集准确率:{avg_test_acc:.4f}")
# 混淆矩阵可视化
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文显示
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(12, 10))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues",
xticklabels=label_encoder.classes_,
yticklabels=label_encoder.classes_)
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.title("文本分类混淆矩阵")
plt.savefig("confusion_matrix.png", dpi=300, bbox_inches="tight")
plt.show()2. 快速预测接口开发
实现单条文本快速预测,方便实际应用部署:
python
import numpy as np
# 加载标签映射
label_map = np.load("label_map.npy", allow_pickle=True)
# 定义预测函数
def predict_text(text):
# 文本预处理
input_ids, token_type_ids = process_text(text)
# 转换为paddle张量
input_ids = paddle.to_tensor([input_ids], dtype="int64")
token_type_ids = paddle.to_tensor([token_type_ids], dtype="int64")
# 模型预测
model.eval()
with paddle.no_grad():
logits = model(input_ids=input_ids, token_type_ids=token_type_ids)
pred_label_idx = paddle.argmax(logits, axis=1).numpy()[0]
pred_label = label_map[pred_label_idx]
return pred_label
# 测试预测功能
test_cases = [
"中国男篮击败伊朗队,晋级亚洲杯四强",
"A股三大指数集体上涨,新能源板块领涨",
"最新电影《XX》票房破10亿,口碑爆棚",
"人工智能技术在医疗领域的应用取得新突破"
]
print("\n预测测试:")
for text in test_cases:
pred = predict_text(text)
print(f"文本:{text}")
print(f"预测类别:{pred}\n")五、开发踩坑与优化方向

1. 常见问题及解决方案
- 问题1:模型训练时loss不下降→解决方案:调整学习率(建议1e-5~3e-5)、增大批次大小、检查数据预处理是否正确;
- 问题2:GPU内存不足→解决方案:减小
max_seq_len(如从128改为64)、降低批次大小(如从32改为16); - 问题3:类别分布不均衡→解决方案:使用加权损失函数、对少数类样本过采样;
- 问题4:预训练模型加载失败→解决方案:检查PaddleNLP版本与模型名称匹配,确保网络通畅(可手动下载模型文件)。
2. 模型优化方向
- 模型层面:尝试更大型的预训练模型(如
ernie-3.0-base-zh)、添加dropout层减少过拟合; - 数据层面:扩大数据集规模、使用数据增强技术(如同义词替换、文本截断/拼接);
- 训练层面:使用学习率调度器(如ReduceLROnPlateau)、采用早停策略(Early Stopping)避免过拟合;
- 部署层面:使用飞桨推理引擎(Paddle Inference)优化推理速度,将模型部署为API接口。
六、活动参与指南与总结

1. 符合活动要求的核心亮点
- 技术实用性:提供完整可复现