目录
1、AI大模型测试中,QA核心工作之一是需要评估从哪些方面评估模型的表现,准备好测试集
[2、 QA需要针对评估模型表现需要的指标进行统计](#2、 QA需要针对评估模型表现需要的指标进行统计)
[3、 QA 需要掌握的技术](#3、 QA 需要掌握的技术)
一、AI测试与传统测试的区别
|-------------------|-----------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|
| 指标 | 传统软件测试 | AI大模型测试 |
| 测试目标 | "代码逻辑是否正确" 传统测试是"对答案" 工程质量:功能正确性、性能、兼容性等 | "模型表现是否可靠",AI测试是"看表现" 工程质量 + 评估模型效果 (如准确率、召回率)、鲁棒性 (抗干扰能力)、公平性 (避免偏见)和安全性(防攻击) |
| 测试对象与逻辑 | 确定性代码逻辑,输入固定则输出唯一,测试用例基于明确的业务规则设计 输入一样,输出确定唯一; | 面向概率性模型,相同输入可能因数据、上下文或随机性产生不同输出,测试需评估其统计规律和泛化能力 输入一样,输出不确定不唯一(一题多解); 本质上: AI测试是基于风险/概率的统计类测试 关键: 如何评估模型输出好还是不好? |
| 测试数据 (多样性+丰富度+量级) | 覆盖功能、性能等,数据量小且格式固定 | 海量(引流)、多样化的真实数据,数据质量直接决定模型表现,测试方法更侧重统计分析、对抗测试和A/B测试 |
| 测试流程与挑战 | 业务测试+回归测试针对代码变更 | 因模型会随数据分布变化而退化,需要分析数据、模型结构等问题, QA大部分时间在和数据打交道,并防止模型退化。 |
| 测试关注内容 | 工程质量有无满足 + 测试效率 | 工程质量 + 模型效果(准确率、召回率、避免偏见、安全性等等) |
| | | |
| | | |
[传统软件测试 VS AI大模型测试]
注: AI大模型产品测试,大致也可以分为两类:
第一类:测试**++基于AI的输出的应用程序。++** 基于AI的第三方工具不需要任何VIP处理; 它们可以被视为黑匣子,就像您可能使用的"常规"确定性第三方产品一样。 将精力集中在测试自己的产品在收到AI输出时是否表现正确。这部分偏工程质量保障。
第二类:++测试实际的机器学习/人工智能模型系统本身。 更加侧重评估模型本身的表现。 这里分成几个问题:++
++1、 模型的表现结果 如何评估++
**++2、准备测试数据集, 评估++**与失败的测试用例相关的风险。 比如, 将健康的患者送去接受更多检查的风险很小。 将患病的患者送回家可能会有致命的危险。
数据集需要考虑的点:
- 考虑与训练集、开发集的差异性
- 数据丰富度/复杂度/量级。可以自动化构造数据、 线上引流、人工构造等方式快速构建数据集。
- 业务上看重的指标。 比如,广告推荐类业务,很看重新用户点击、新视频点击、热点视频曝光率等等指标。 那么 数据集需要增加新用户、新视频、热点视频的比例。
- 关注业务场景。 比如,广告推荐类业务,会根据性别、职业、年龄、地域、时段等场景进行不同推荐。 那么测试数据集中,需要性别、职业、年龄、地域、时段等场景对应比例的数据。
3、排除数据偏差/badcase.要排除神经网络中的偏差,您需要仔细分析测试结果(尤其是失败的结果)
例如,AI大模型癌症检测, 可以比较算法对吸烟者和非吸烟者图像的成功率。 如果存在明显差异,则该算法可能在训练期间变得有偏差。
例如,正负样本量相差很大时,测试集本身也不能很好评估模型。
二、AI大模型测试的独特挑战
1. 幻觉与内容真实性
大模型生成的文本流畅但可能偏离事实,存在"幻觉"问题,导致输出不准确或虚构内容。
1.1 很多答案有很大主观性,图好看不好看、写的作文好不好等等。
1.2 没办法穷举用户所有的输入,可能完全不知道用户如何输入
2. 安全性与对抗攻击
模型面临提示词注入、越狱等攻击风险,需测试其对抗恶意输入的能力,确保生成内容安全可控
3. 性能与资源消耗
大模型推理和训练对算力需求极高,测试需关注响应速度、资源占用(如GPU/CPU、内存)及可扩展性,确保高效稳定运行。
4. 数据隐私与合规性
测试需确保模型训练和推理过程符合数据隐私法规(如GDPR),防止敏感信息泄露,并评估其内容过滤机制。
6. 可解释性与伦理对齐
模型的"黑箱"特性使其决策过程难以解释,测试需评估其可解释性,并确保输出内容符合伦理标准,避免偏见和有害内容。
- 多模态理解与冲突处理
多模态模型(文本+图像+音频)让测试复杂度升级,混合输入测试 :需同时模拟文本、图片、音频请求; 跨模态一致性 :使用CLIP Score等指标评估图文相关性。资源监控:视觉模型显存占用更高,需针对性优化。
三、AI大模型测试对QA的要求
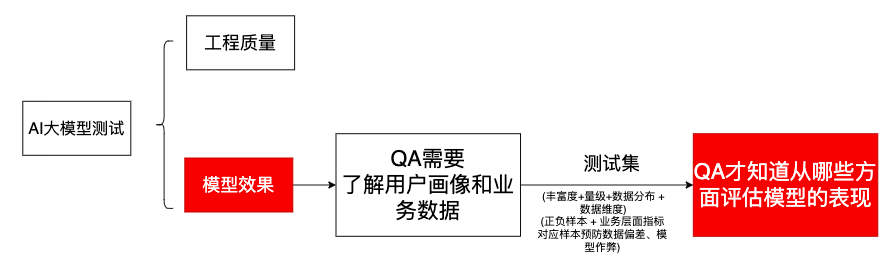
++本质上,AI大模型测试中,QA80%时间都在和数据集的准备打交道。 所以需要测试人员 理解业务、 熟悉数据、特别是需要了解产品的用户画像、 知道用户要分成多少类。++
1、AI大模型测试中,QA核心工作之一是需要评估从哪些方面评估模型的表现,准备好测试集
2、 QA需要针对评估模型表现需要的指标进行统计
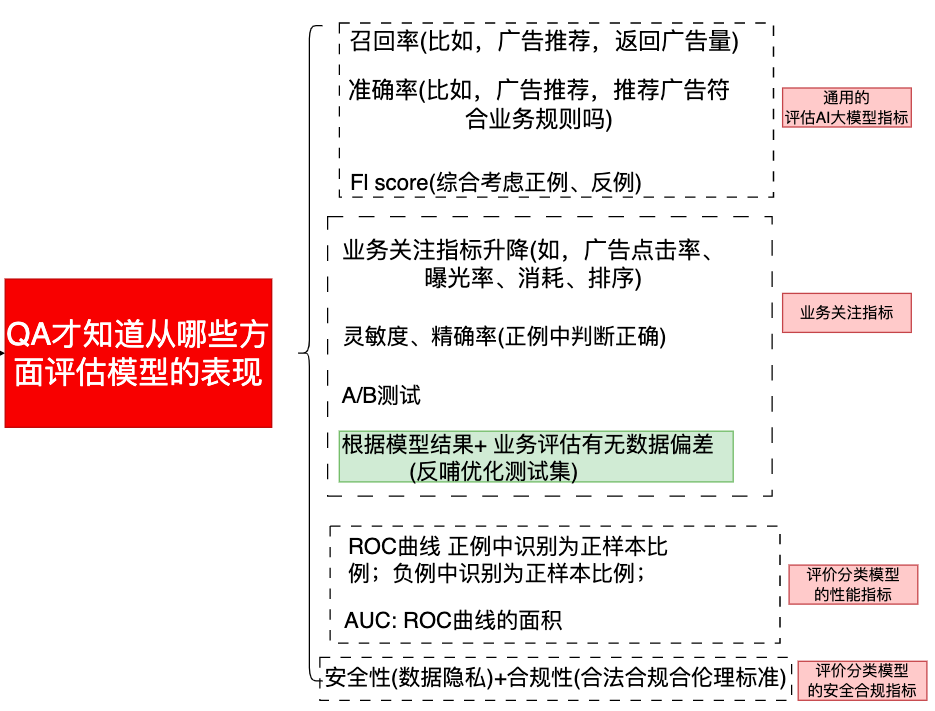
注意: 如果其中的3类指标在AI大模型设计中已经包含了,QA不需要重复实现了。AI大模型设计中没有包含的指标,QA需要数据集来统计。
3、 QA 需要掌握的技术
|----------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 需要解决的问题 | 技术手段 |
| 需要准备丰富度、均匀度、量级、无偏差等的测试集 (正向、反向样本比例),完成数据采集-分析-统计 | 1、线上引流、 自动化构造数据、利用公开的测试集(比如,分类模型可以用一些公开的图像库) 2、数据处理技术(结构化数据spark,hive,图像数据等等清洗、处理) 注:QA大部分时间都是对数据处理,比对AI算法本身的理解更重要 |
| 需要评估测试集样本本身是否有偏差。 比如,样本中每一个分组需要有足够样本,对应样本太少,不足以评估模型效果。 | 注: QA需要有熟悉业务 + 用户画像 ,可能需要业务侧人员一起评估 |
| 获取召回率R、准确率P、Fl score=2PR/(P+R) | 查看模型本身已经统计这些指标 可能需要做指标的自定义对比; |
| ROC曲线、AUC指标来评估分类模型的性能指标 | 1、查看模型本身已经统计这些指标 2、一些机器学习库,如Spark已经有相关算法去统计AUC |
| 统计业务含义指标,比如,广告推荐系统,统计曝光、点击、消耗、排序等指标,可能很关注新用户点击、新视频点击等 | 1、根据业务关注指标进行统计; 2、一般可以调用业务侧接口或服务获取这些数据。 |
| 有了上述的指标后,需要评估有无数据偏差: 比如,根据性别、职业、年龄、地域、时段等场景进行不同推荐。 那么需要评估模型结果是否真的按性别、职业、年龄、地域、时段等场景进行推荐 | 1、可以新旧模型对比结果; 2、 一般可以调用业务侧接口或服务获取这些数据并进行判断 |
| 找badCase并反向对模型优化 | |
| 关注具体业务下的模型指标: 比如,图像检测模型,IOU衡量检测框和真实框之间的重叠程度。该值越大检测结果越准确。 比如,OCR识别文字,目标检测-定位文字位置-识别出文字 比如,NLP评估 | QA需要熟悉业务,并且学习业内最佳实践: 1、召回率+准确率(主流评估方法) 2、整行准确率 3、相似度算法 评价编辑距离:2个字符串的相似度 比较识别的文本和实际文本的相似度(多种相似度算法) |
| 其他NLP评估: 评估有歧义,给出的结果没有标准答案 一个语言多种表达同一个意思,评估是主观的(比如,中英翻译) 注: 统计参考答案、模型答案的相似度是大模型测试常见手段。大模型很多测试方法可以参考NLP比较相似度的思路 | QA可以用多种方法: 1、 多人投票打分 2、 相关专业人员介入评估 3、分而治之 用语句,每个段落来综合统计整体翻译情况 4、准备几个参考答案,依次计算模型生成结果与参考答案的相似度(又回到了相似度问题) 5、利用开源项目模型/行业公开的数据集和指标,如bert模型,可以统计文本相似度 + 精准率+召回率+Fl score指标 |
| 安全内容审核测试、 安全性(数据隐私)+合规性(合法合规合人类伦理标准)测试、敏感词测试 | 1、 找公开的中文敏感词数据集 https://github.com/fighting41love/funNLP 2、 构造数据集 3、Safety-Prompts :一个专注于中文场景的提示数据集和工具集,其核心目标是帮助研究人员和开发者系统性地测试模型在各种潜在危险场景下的表现,并指导模型生成更安全、合规的输出 **4、**SuperCLUE是中文通用大模型综合性评测基准,旨在评估中文通用大模型的综合效果、与国际模型的对比及人类基准差距 |
[QA测试AI大模型的技能]