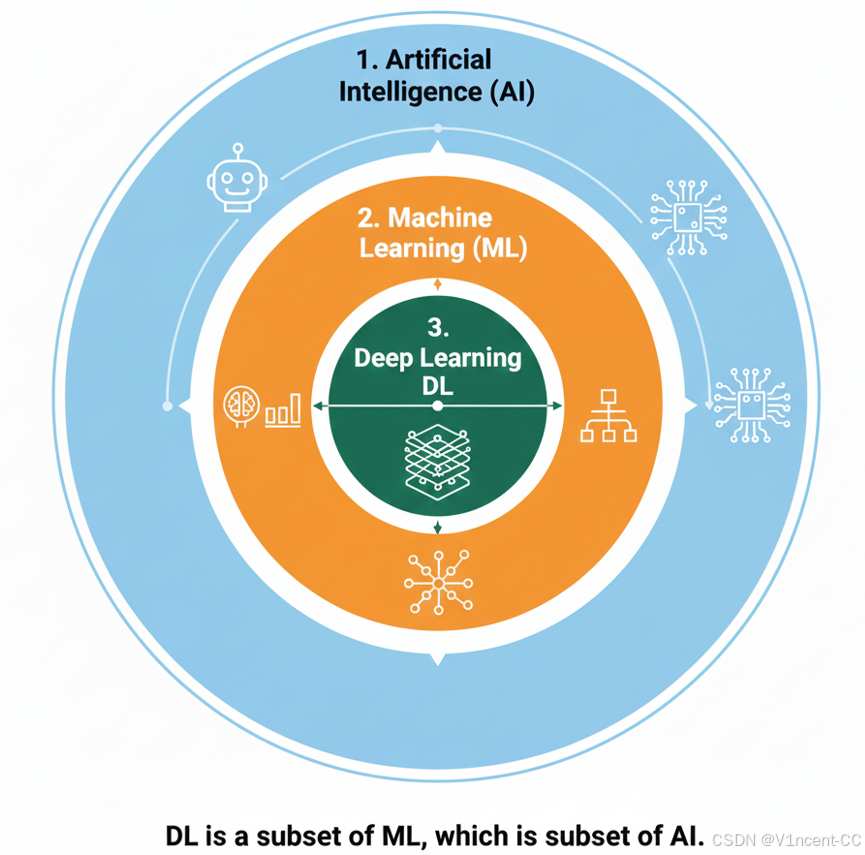
机器学习(Machie Learning)是人工智能的一个子集,而深度学习(Deep Learning)又是机器学习的一个子集。近些年人工智能领域的技术突破,实际上是来自其核心的"深度学习"技术突破,本文将带你了解深度学习的本质、它所依赖的神经网络结构,以及当今驱动AI革命的三大核心模型。
一、什么是深度学习
深度学习是一种特殊的机器学习算法 ,通过模仿人脑神经元的工作方式,利用多层网络从原始输入数据(如图像、文本)中逐步提取和学习越来越抽象、复杂的特征,深度学习的"深度"来源于神经网络中多个的隐藏层,在AI术语中,深度学习 和神经网络是同义词。
神经网络本质是一个超大的数学函数(根据一组输入A,计算输出B),它包含很多"神经元"(神经元就是一个相对简单的函数,但把它们像乐高一样堆叠起来就可以得到极其复杂的函数,能极其准确地学习A到B的映射),这些神经元处理信息并将其传递给下一层神经元,类似大脑神经元处理信息的方式。
1.1 神经网络的构成
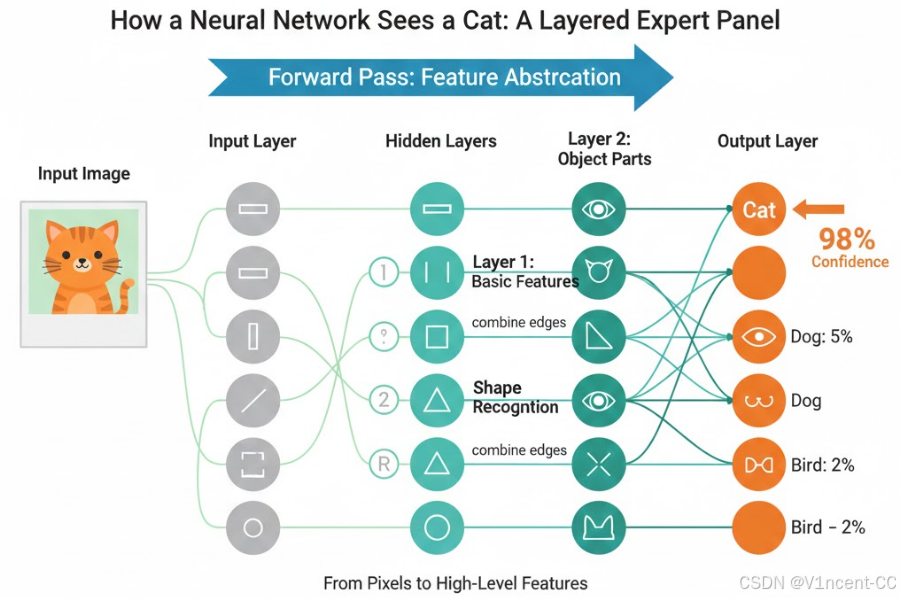
你可以把神经网络想象成一个由多层专家组成的 "专家评审团",当处理复杂的任务时,比如判断一张图片上是不是一只猫,第一层神经元可以识别图像中的基本特征(例如边缘),下一层可能会将这些边缘组合起来识别形状,再下一层可能会识别毛发图案,依此类推,直到最后一层将整幅图像识别为一只猫。
一个基本的神经网络由3个相连的层组成:输入层、一个或多个隐藏层、输出层。
- 输入层 (Input Layer):收信息的人,负责接收外部世界的原始数据。
- 隐藏层 (Hidden Layers):核心的"专家评审团",一般有多层,负责分析、提炼和整合信息,这是网络"深度思考"的地方。
- 输出层 (Output Layer) :给出最终结论的人,根据分析结果,给出一个最终的答案或预测。
1.2 深度学习的主要训练模式
深度学习继承了机器学习的三种主要学习范式:
- 监督学习(Supervised Learning): 这是最常见的训练方式,神经网络通过研究大量 带标签(已知正确答案) 的数据来学习映射关系。例如,给神经网络看猫的图片,并告诉它"这是猫"。
- 无监督学习(Unsupervised Learning): 神经网络在没有明确标签的情况下,自行发现数据中的结构、模式和内在联系(例如,将相似的客户群体进行聚类)。
- 强化学习(Reinforcement Learning): 神经网络通过与环境的互动,根据获得的奖励或惩罚来学习采取最佳的行动策略,以最大化长期收益(例如,自动驾驶或训练AI下棋或游戏)。
二、 神经网络的学习过程
神经网络的学习是一个不断迭代优化的过程,目标是最小化预测结果与真实结果之间的误差。
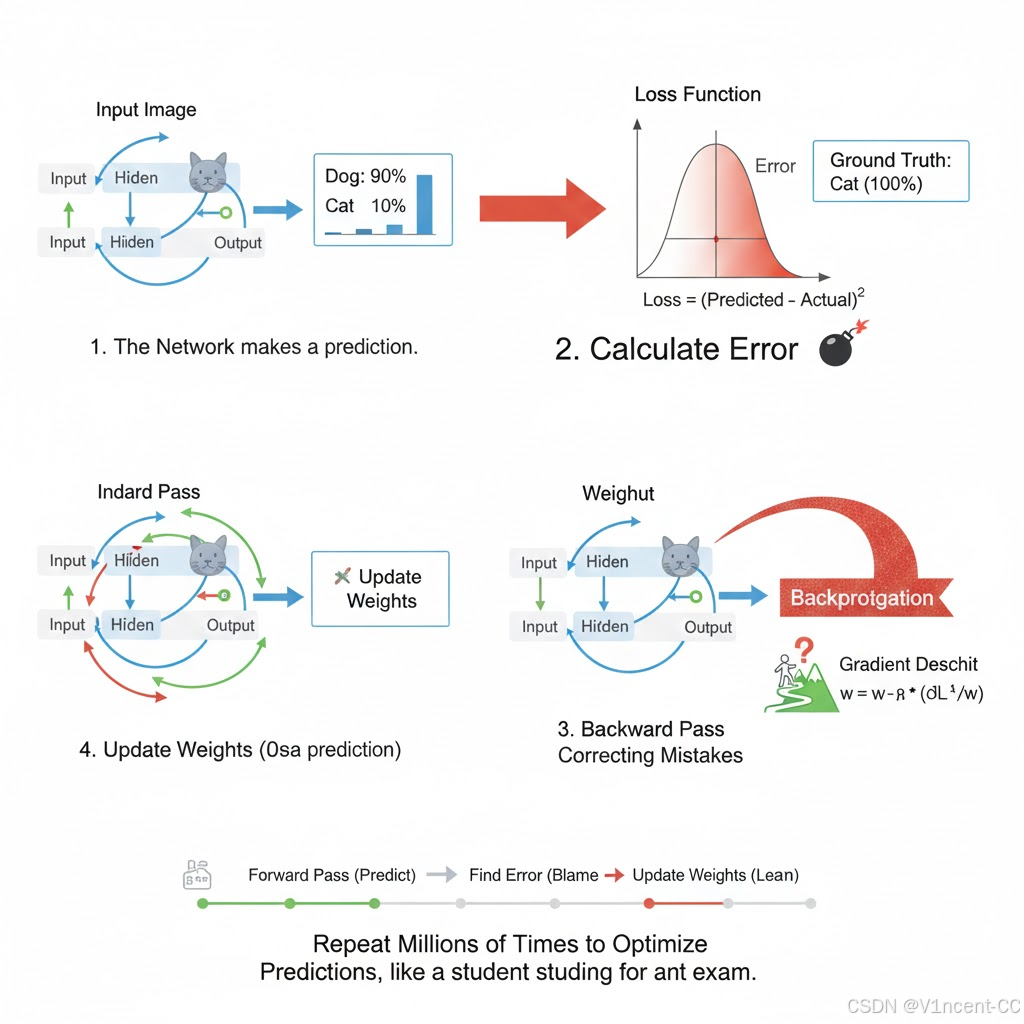
神经网络的学习就是通过"前向传播"产生预测,利用"损失函数"发现预测与真实标签之间的"误差",再通过"反向传播"将误差反向传播回网络,并使用"梯度下降"算法不断微调网络中的"权重:
- 前向传播:在信息前向传播的过程中,每个神经元之间的连接都有一个 "权重" (www) ,你可以把它理解为这个输入信号对下一个神经元激活的"重要性"。
- 发现误差:在训练开始时,网络的权重是随机初始化的,所以其预测结果往往是错误的,为了衡量预测结果(输出)与正确答案(标签)之间的差距,我们使用一个损失函数来量化"误差"的大小,损失值越大,表示模型的预测越不准确。
- 反向传播:当发现预测错误时,会通过一个叫做反向传播的机制,把这个误差从输出层反向传回给所有的专家(隐藏层),告诉他们:"你们做错了!"
- 梯度下降(修正权重):神经网络微调每个连接上的"权重",让那些导致错误结论的权重降低,让那些有助于正确结论的权重提高,所谓学习就是不断调整这些"权重"的过程。
神经网络不断重复 "前向传播 → 发现误差 → 反向传播 → 修正权重" 这个循环,通过数百万次迭代,网络参数逐渐收敛到一个最佳状态,使得模型的预测能力达到最优,就像一个学生在准备一场有标准答案的考试,通过不断做题来提升自己的能力。
三、深度学习模型简介
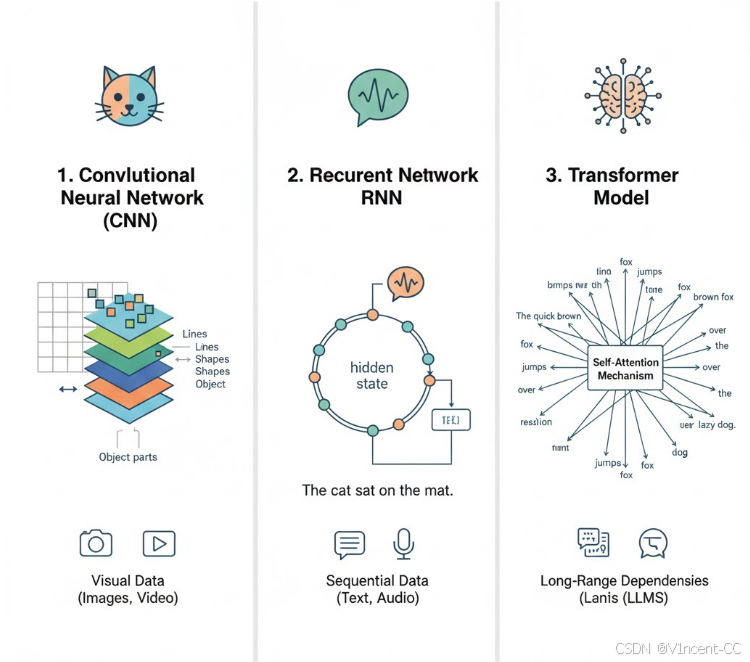
深度学习中采用了各种类型的神经网络,每种网络都有其独特的优势和常见的用例,最常见的有卷积神经网络、循环神经网络以及转换器(Transformer),它们在"自然语言处理"和"计算机视觉领域"发挥着重要作用。
- 卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,受人类视觉系统启发,特别擅长处理具有空间局部性的图像、视频等网格结构数据,通过模拟视觉皮层的工作原理,能够有效地从图像中提取特征,并具备对物体位置不敏感的平移不变性(不受该对象在图片中位置变化的影响)。
- 循环神经网络(Recurrent Neural Network, RNN)适用于序列数据处理。其核心在于循环连接和隐藏状态,使其能够处理变长序列,并对序列中的上下文信息具备"记忆"能力,但是传统 RNN 存在长期记忆困难问题。
- 基于转换器的模型(Transformer)是近年来在自然语言处理(NLP)领域取得重大突破的深度学习模型。与传统的RNN不同,Transformer完全基于自注意力机制(Self-Attention)来处理序列数据,使得模型能够同时关注序列中的所有部分,高效地捕捉长距离依赖关系,并支持大规模并行计算,是现代 LLM 的基石。
后续我们将进一步详细了解这3种模型的工作机制。