高并发对于后端系统而言既是挑战,也是检验架构成熟度的重要指标。无论是推荐系统、API 网关、还是营销活动接口,只要涉及大量用户访问,就不可避免要面对 QPS(Queries Per Second,每秒请求数) 的极限问题。
这篇文章结合实际经验,从 QPS 的计算原理 → 并发和 DAU 的关系 → 不同 QPS 的部署架构 全面整理,形成一套可落地的服务性能扩展指南。
1. 什么是 QPS?怎么计算?
QPS 的定义非常简单:
QPS = 一段时间内处理的请求总数 ÷ 时间(秒)
举例:10 秒处理了 30000 个请求
→ QPS = 3000
压测工具(ab/wrk/JMeter)也会直接输出类似:
Requests per second: 2987.12这就是 QPS。
2. QPS 与并发量(Concurrency)不是一回事
很多人容易混淆:
| 名称 | 含义 |
|---|---|
| 并发数(Concurrency) | 同一时刻正在处理的请求数量 |
| QPS | 每秒能完成多少个请求 |
两者之间的大致关系:
QPS ≈ 并发数 / 平均响应时间 RT(秒)
例如:
- 并发 1000
- 平均响应时间 0.2 秒
则 QPS ≈ 1000 / 0.2 = 5000
这意味着如果想提升 QPS,提高并发能力和降低 RT 两者缺一不可。
3. DAU 与并发的经验映射(行业标准)
互联网行业中有非常稳定的统计规律:
峰值并发 ≈ DAU × 0.01% ~ 0.1%
典型推荐系统(首页推荐、详情页推荐)通常是:
并发 ≈ DAU × 0.03% ~ 0.08%
对照表如下:
| DAU | 峰值并发(典型) | 峰值 QPS(RT=200ms) |
|---|---|---|
| 1 万 | 3~8 | 15~40 |
| 10 万 | 30~70 | 150~350 |
| 50 万 | 150~350 | 750~1750 |
| 100 万 | 300~600 | 1500~3000 |
因此,一个系统想达到 3000 QPS ,通常需要 100 万级 DAU。
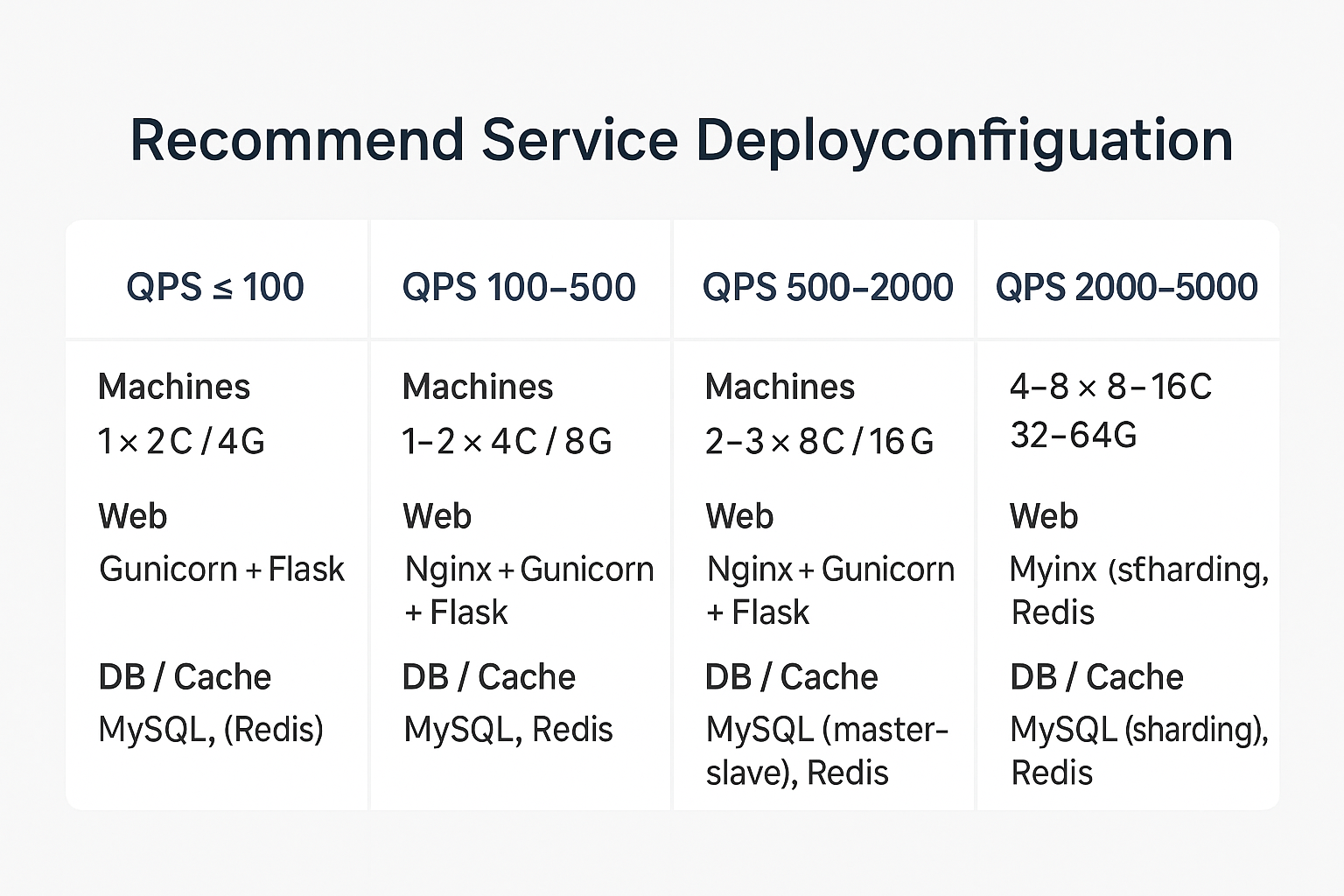
4. 不同 QPS 场景下的部署架构建议
以下提供不同 QPS 阶段的实战部署方案(尤其针对 Python Flask + Gunicorn + gevent + MySQL + Redis 的常见技术栈)。
⭐ 场景 1:QPS ≤ 100
适用于小业务 / 内部工具 / 测试环境。
推荐架构:
-
机器:1 台 2C / 4G 或 2C / 8G
-
gunicorn:
workers = 2 worker_class = "gevent" worker_connections = 200 timeout = 30 -
MySQL / Redis:可与应用共机
-
监控:简单日志即可
几乎不用考虑扩展问题。
⭐ 场景 2:QPS 100~500
适用于小型线上推荐接口 / 省级运营商单入口业务。
推荐架构:
-
应用:1 台 4C / 8G(建议双机部署)
-
gunicorn:
workers = 4 worker_class = "gevent" worker_connections = 400 keepalive = 5 max_requests = 2000 -
MySQL:独立实例(读写同库即可)
-
Redis:单机版即可
-
重点:优化 SQL,增加 Redis 缓存
此阶段可以靠单机支撑 QPS 300~400。
⭐ 场景 3:QPS 500~2000
适用于多入口调用的推荐平台,如 APP 首页、多个业务线共用接口。
核心策略:开始水平扩展 + 数据库拆分
应用层
-
2~3 台 8C / 16G
-
每台 gunicorn:
workers = 6 worker_class = "gevent" worker_connections = 500 timeout = 30
数据层
- MySQL 主从
- 读写分离(读走从库)
- Redis 主从或哨兵
架构优化
- 用户画像缓存(Redis)
- 召回结果缓存
- 热度产品缓存
- 推荐理由异步化(MQ)
此阶段是多数省级推荐系统的常态。
⭐ 场景 4:QPS 2000~5000
适用于省级统一推荐平台 / 多场景大流量并发。
推荐架构:
应用层(核心)
-
4~8 台,8C / 16G(或 16C / 32G)
-
gunicorn:
workers = 6~8 worker_class = "gevent" worker_connections = 800
服务拆分
- user-profile-service(用户特征)
- recall-service(ICF/UCF/热度/规则)
- ranking-service(DeepFM/DNN)
- reason-service(大模型理由生成,强制异步)
数据层
- MySQL 分库分表
- Redis Cluster
流控
- 限流(用户级 / IP级)
- 熔断(超时自动跳过某些服务)
- 灰度发布
这是完整的省级推荐平台架构。
⭐ 场景 5:QPS 5000~10000+
适用于全国级推荐系统 / 多省统一调度 / 多业务大入口平台。
此时 Python 不一定适合作为主要承载层(更适合模型推理 / 特征服务)。
架构转型方向:
- 高频服务切换为 Go / Java
- 引入 服务网格(Istio/Envoy)
- 多机房部署(容灾)
- Redis Cluster + TiDB / ClickHouse
- Kafka 全链路实时埋点
- GRPC 服务化、流量动态调度
此档位已经是阿里 / 字节 / 腾讯级别架构。
5. 针对推荐系统的特别提示
推荐接口属于 "组合型 IO 密集接口":
- 查 Redis
- 查 MySQL
- 多路召回
- 模型打分
- 大模型推荐理由(如有)
因此单机 QPS 通常会比纯计算或 Hello World API 要低。
Flask + gevent 单机安全 QPS 通常为:
- 4C 机器:200 ~ 400
- 8C 机器:400 ~ 800
所有部署建议均基于这一现实情况。
6. 总结:如何为你的业务选择架构?
可以用一句话快速判断:
目标 QPS ÷ 单机安全 QPS(≈300~600)≈ 需要的机器数量
例如你目标是 QPS 2000:
- 单机安全 QPS = 500
- 需要机器 ≈ 2000 / 500 = 4 台(再 ×1.3 冗余)
- → 5~6 台即可