目录
[一、CAP 理论:被泛化的 "分布式存储专属法则"](#一、CAP 理论:被泛化的 “分布式存储专属法则”)
[1.1 三大特性的精准定义与本质](#1.1 三大特性的精准定义与本质)
[1.2 核心误区:"三选二" 实为 "P 前提下的 C/A 二选一"](#1.2 核心误区:“三选二” 实为 “P 前提下的 C/A 二选一”)
[1.3 关键事实:90% 分布式系统无需实践 CAP](#1.3 关键事实:90% 分布式系统无需实践 CAP)
[二、BASE 理论:ACID 的 "分布式替代方案",而非 CAP 的延伸](#二、BASE 理论:ACID 的 “分布式替代方案”,而非 CAP 的延伸)
[2.1 三大特性的设计逻辑与实践场景](#2.1 三大特性的设计逻辑与实践场景)
[2.2 核心澄清:BASE 与 CAP 的本质差异](#2.2 核心澄清:BASE 与 CAP 的本质差异)
[三、认知拨乱反正:CAP 与 BASE 的适用边界与协同逻辑](#三、认知拨乱反正:CAP 与 BASE 的适用边界与协同逻辑)
[3.1 CAP 的适用边界:仅针对 "数据副本场景"](#3.1 CAP 的适用边界:仅针对 “数据副本场景”)
[3.2 BASE 的实践价值:覆盖全场景的 "分布式容错思想"](#3.2 BASE 的实践价值:覆盖全场景的 “分布式容错思想”)
[3.3 协同案例:电商系统中的 CAP 与 BASE 结合](#3.3 协同案例:电商系统中的 CAP 与 BASE 结合)
[四、总结:分布式理论的 "取舍本质"](#四、总结:分布式理论的 “取舍本质”)
在分布式架构的学习路径中,CAP 与 BASE 理论常被贴上 "相辅相成" 的标签,多数开发者对其应用场景、核心定义及相互关系存在固化认知。然而,深入拆解分布式系统的本质与理论起源会发现:CAP 理论并非所有分布式系统的 "必修课",BASE 理论也绝非 CAP 的延伸,二者分属不同维度的设计思想,却共同构成了分布式架构权衡的底层逻辑。本文将从理论定义、认知误区、实践边界三个层面,重新梳理两大理论的核心价值。
一、CAP 理论:被泛化的 "分布式存储专属法则"
CAP 理论由 Eric Brewer 于 1998 年提出,2002 年经数学证明确立,其核心是分布式系统中一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者不可兼得。但多数解读忽略了一个关键前提:CAP 的应用场景存在严格边界,并非所有分布式系统都需遵循。
1.1 三大特性的精准定义与本质
CAP 的三个特性并非 "通用概念",而是针对带数据副本的分布式存储场景(如主从集群、多主集群)设计,需结合 "数据同步" 这一核心动作理解:
| 特性 | 核心定义 | 本质诉求 | 关键细节 |
|---|---|---|---|
| 一致性(C) | 同一时刻,所有副本节点对同一数据的读取结果完全一致;写入更新后,后续所有节点的读取需返回最新值 | 数据正确性 | 事务场景中,"写入完成" 以事务提交为标志,提交前所有节点读旧值仍满足一致性 |
| 可用性(A) | 合法请求在有限时间内返回非错误响应(成功 / 合理提示),不因部分节点故障导致系统整体不可用 | 服务持续性 | 响应速度需在用户可接受范围,拒绝 "无限阻塞" 或 "5xx 错误",允许返回 "限流提示" 等非成功响应 |
| 分区容错性(P) | 节点因网络故障(断网、抖动)或动态增减形成孤立分区时,系统仍能提供核心服务 | 抗故障能力 | 本质是对 "节点动态变化" 的处理能力,新节点加入、老节点下线均视为 "临时分区" |
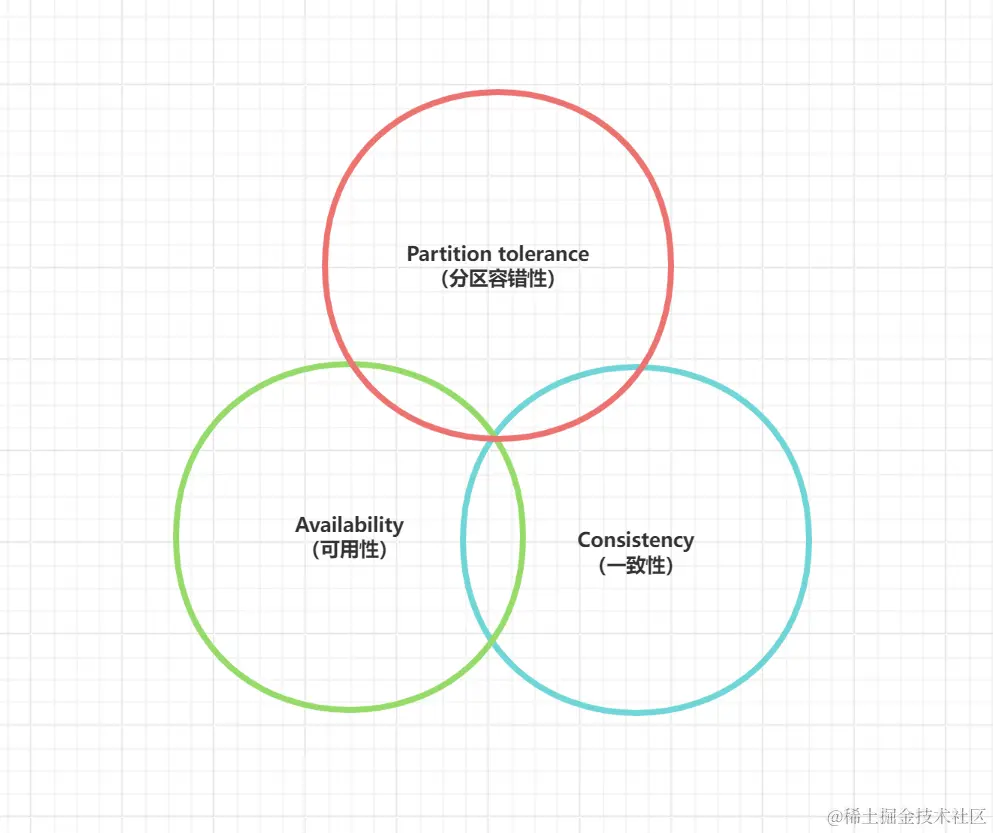
1.2 核心误区:"三选二" 实为 "P 前提下的 C/A 二选一"
传统解读将 CAP 简化为 "三者选其二",但分布式系统的本质是 "多节点通过网络协同"------网络故障不可避免,分区容错性(P)是分布式系统的必选项,放弃 P 意味着系统退化为 "多节点部署的单体系统",失去分布式的扩展性与容错能力。
因此,CAP 的实际权衡逻辑是:在保证 P 的基础上,只能在 C 和 A 之间二选一,不存在 "CA 分布式系统":
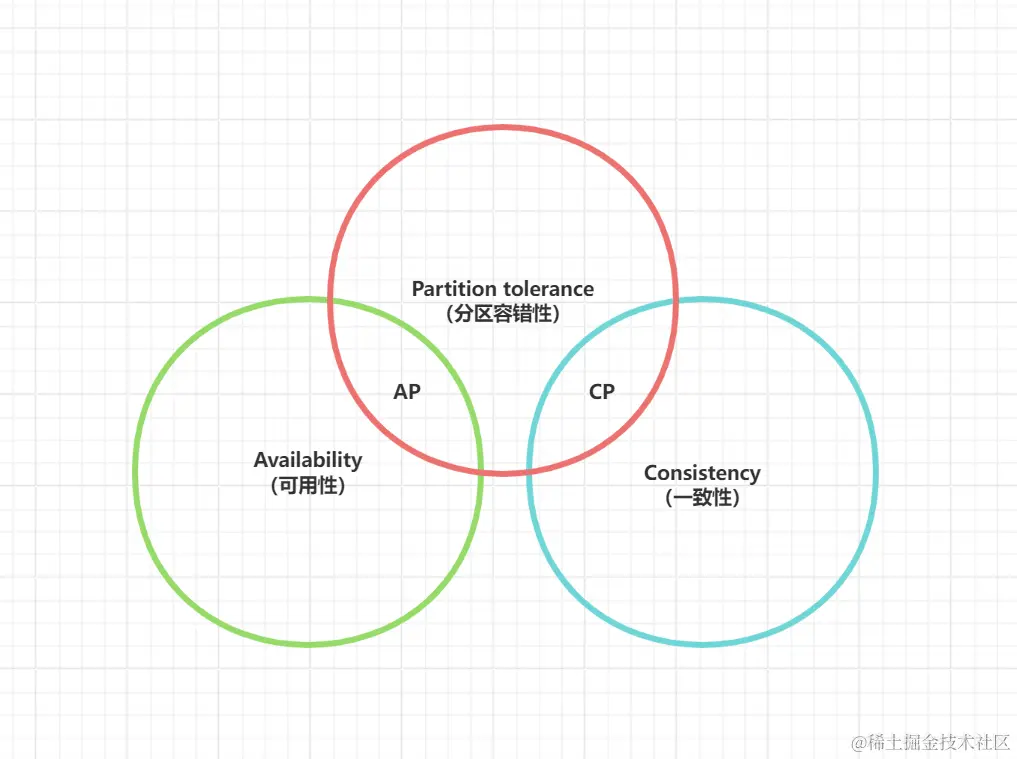
- 选 CP(一致性 + 分区容错):为保证数据一致,分区时暂停可能导致不一致的服务(如写操作)。例如 ZooKeeper 的 Leader 选举期间,系统暂不可写;银行转账需等待所有节点数据同步完成,否则拒绝交易。
- 选 AP(可用性 + 分区容错):为保证服务可用,分区时允许节点用本地数据响应,接受数据暂时不一致。例如 Redis 主从集群的异步复制,主节点写入后立即返回,从节点同步有延迟,但故障时从节点可快速切换为主节点提供服务。
- 选 CA(一致性 + 可用性):仅存在于单机系统(如本地 MySQL),无网络分区风险,数据写入即一致、节点存活即可用;分布式环境下因网络不可靠,CA 架构必然因分区故障导致整体瘫痪。
1.3 关键事实:90% 分布式系统无需实践 CAP
多数开发者接触的分布式系统(如微服务业务层、无状态 API 服务)属于非存储型分布式系统,这类系统仅处理业务逻辑,不存储核心数据(数据最终落地于数据库、Redis 等存储组件),自然无需考虑 "数据副本同步" 问题,也就不存在 CAP 权衡。
真正需要实践 CAP 的,是分布式存储组件(如 Redis、MySQL 主从、ZooKeeper、注册中心):
- 注册中心需存储 "服务地址列表",若选 CP(如 etcd),则分区时暂停服务注册以保证地址一致性;若选 AP(如 Eureka),则允许节点用本地缓存响应,接受短暂的地址不一致。
- 分布式锁场景:用 Redis 实现时优先 AP(快速响应锁请求,容忍极端情况下的锁竞争);用 ZooKeeper 实现时优先 CP(通过节点临时节点保证锁的唯一性,分区时暂不可用)。
二、BASE 理论:ACID 的 "分布式替代方案",而非 CAP 的延伸
BASE 理论由 eBay 架构师于 2008 年在《Base: An Acid Alternative》中正式提出,其核心是基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventually Consistent) 。多数解读将其视为 "CAP 中 AP 方案的补充",但论文原文明确指出:BASE 是分布式场景下 ACID 理论的替代品,与 CAP 分属不同维度。
2.1 三大特性的设计逻辑与实践场景
BASE 的诞生源于 "分布式事务难以满足 ACID 强一致性" 的痛点 ------ 跨节点事务因网络延迟必然存在 "中间态",ACID 拒绝中间态,而 BASE 则通过 "容忍中间态、追求最终一致" 解决这一矛盾:
(1)基本可用(BA):牺牲部分可用性,保障核心功能
"基本可用" 并非 "降低可用性",而是故障时主动放弃非核心功能,确保核心服务正常,常见实践包括:
- 响应时间损失:正常 0.5s 返回的商品详情,大促时延迟至 3s,但仍能打开;
- 功能降级:双十一期间关闭 "商品评价导出""历史订单统计" 等非核心功能,释放资源保障下单、支付;
- 限流熔断:负载超阈值时,拒绝新请求并返回 "稍候重试",避免系统雪崩。
(2)软状态(S):允许中间态,不影响整体可用
"软状态" 是 BASE 的核心突破 ------ 允许系统存在 "数据未同步完成的中间态",且该状态不阻塞核心服务。例如:
- 分布式下单场景:商品服务扣减库存后,订单服务尚未创建订单,此时 "库存已减、订单未建" 即为中间态;
- 缓存更新场景:基础数据更新后,缓存尚未刷新,此时 "基础数据新、缓存数据旧" 即为中间态。
关键区别:ACID 拒绝中间态(事务要么提交要么回滚),BASE 则认为 "中间态是分布式事务的必然产物",只要不影响服务可用性即可接受。
(3)最终一致性(E):中间态短暂存在,最终达成一致
"最终一致性" 是对 "软状态" 的补充约束 ------ 中间态不能永久存在,需通过异步机制(定时同步、补偿事务)在一定时间内转为 "终态",确保系统整体数据一致。例如:
- 缓存刷新:基础数据更新后,通过定时任务(如每 5 分钟)重新聚合数据并刷新缓存,最终保证缓存与基础数据一致;
- 分布式事务补偿:下单时若订单创建失败,通过消息队列触发 "库存回滚",将中间态恢复为 "库存未减、订单未建" 的初始态。
2.2 核心澄清:BASE 与 CAP 的本质差异
多数资料将 BASE 视为 "CAP 的延伸",但二者的 "一致性""可用性" 定义完全不同,属于 "跨维度理论":
| 对比维度 | CAP 理论 | BASE 理论 |
|---|---|---|
| 一致性定义 | 副本节点的数据同步一致性(聚焦 "数据副本") | 分布式系统的状态一致性(聚焦 "事务流程") |
| 可用性定义 | 主从集群的服务连续性(部分节点故障不影响整体) | 分片 / 分库系统的部分可用(单个分片故障仅影响局部用户) |
| 核心目标 | 解决 "数据副本同步" 的权衡问题 | 解决 "分布式事务强一致性" 的落地问题 |
| 对标对象 | 无(分布式存储专属) | ACID 理论(分布式事务的替代方案) |
例如:Redis 主从集群的异步复制,既符合 CAP 的 AP 选择(容忍数据暂时不一致,保证可用性),也契合 BASE 的 "软状态 + 最终一致性"(主从同步延迟为中间态,最终数据一致)------ 这并非 "BASE 是 CAP 的延伸",而是 BASE 的高维度定义可向下兼容 CAP 场景。
三、认知拨乱反正:CAP 与 BASE 的适用边界与协同逻辑
理解两大理论的关键,是明确其 "适用场景的优先级":CAP 解决 "分布式存储的副本同步" 问题,BASE 解决 "分布式事务的状态一致" 问题,二者可在同一系统中协同作用,但绝非 "从属关系"。
3.1 CAP 的适用边界:仅针对 "数据副本场景"
CAP 理论的核心是 "数据多副本如何同步",因此仅适用于存在数据副本的分布式存储组件,以下场景无需考虑 CAP:
- 分片式存储(如 Redis Cluster、MySQL 分库分表):每个节点存储不同数据,无 "副本同步" 需求,自然不存在 CAP 权衡;
- 无状态服务(如微服务业务层):数据存储于外部组件,服务本身仅处理逻辑,无需关心数据一致性;
- 消息队列(如 Kafka):核心是 "消息投递",而非 "数据存储一致性",仅需保证消息不丢失,无需 CAP 权衡。
3.2 BASE 的实践价值:覆盖全场景的 "分布式容错思想"
BASE 的定义维度高于 CAP,可应用于所有分布式场景,其核心价值是提供 "容错 - 降级 - 最终一致" 的完整方法论:
- 微服务治理:服务熔断(基本可用)、请求重试(软状态过渡)、分布式事务补偿(最终一致);
- 大数据处理:离线计算任务允许 "中间结果暂存"(软状态),最终通过多轮迭代输出一致结果(最终一致);
- 缓存系统:缓存穿透时降级为 "返回默认值"(基本可用),缓存更新延迟视为 "软状态",定时刷新保证最终一致。
3.3 协同案例:电商系统中的 CAP 与 BASE 结合
以电商 "下单 - 支付 - 库存" 流程为例,两大理论的协同逻辑清晰可见:
- CAP 选择 :
- 库存数据库(MySQL 主从):选 CP,同步复制保证库存数据一致,避免超卖(数据安全性优先);
- 商品缓存(Redis 集群):选 AP,异步复制保证缓存高可用,接受短暂的库存数据延迟(用户体验优先)。
- BASE 落地 :
- 基本可用:支付高峰时关闭 "优惠券领取" 非核心功能,保障下单、支付;
- 软状态:下单后 "库存已减、支付未完成" 为中间态,允许用户在 30 分钟内完成支付;
- 最终一致:支付超时未完成时,通过定时任务触发 "库存回滚",将中间态转为初始态。
四、总结:分布式理论的 "取舍本质"
CAP 与 BASE 理论的价值,并非提供 "通用公式",而是教会开发者 "在不确定性中寻找平衡":
- CAP 的本质是 "存储取舍":分布式存储组件需根据 "数据安全性" 与 "可用性" 的优先级,在 C 和 A 之间选择,无需盲目追求 "二者兼得";
- BASE 的本质是 "事务妥协":分布式事务无法满足 ACID 强一致性时,通过 "容忍中间态、追求最终一致",在可用性与数据一致性间找到平衡点;
- 实践原则:业务驱动技术选型 ------ 金融交易(支付、转账)优先用 CP+ACID 保证数据安全;电商秒杀、社交 feed 流优先用 AP+BASE 保证用户体验。
分布式架构的核心矛盾是 "不确定性"(网络不可靠、节点会故障),CAP 与 BASE 理论的真正意义,是帮助开发者跳出 "完美主义陷阱",理解 "取舍是常态,平衡是目标"------ 没有 "最优架构",只有 "最适合业务的架构"。