kafka采用了追加日志的格式将数据存储在磁盘上,整体的结构如下图: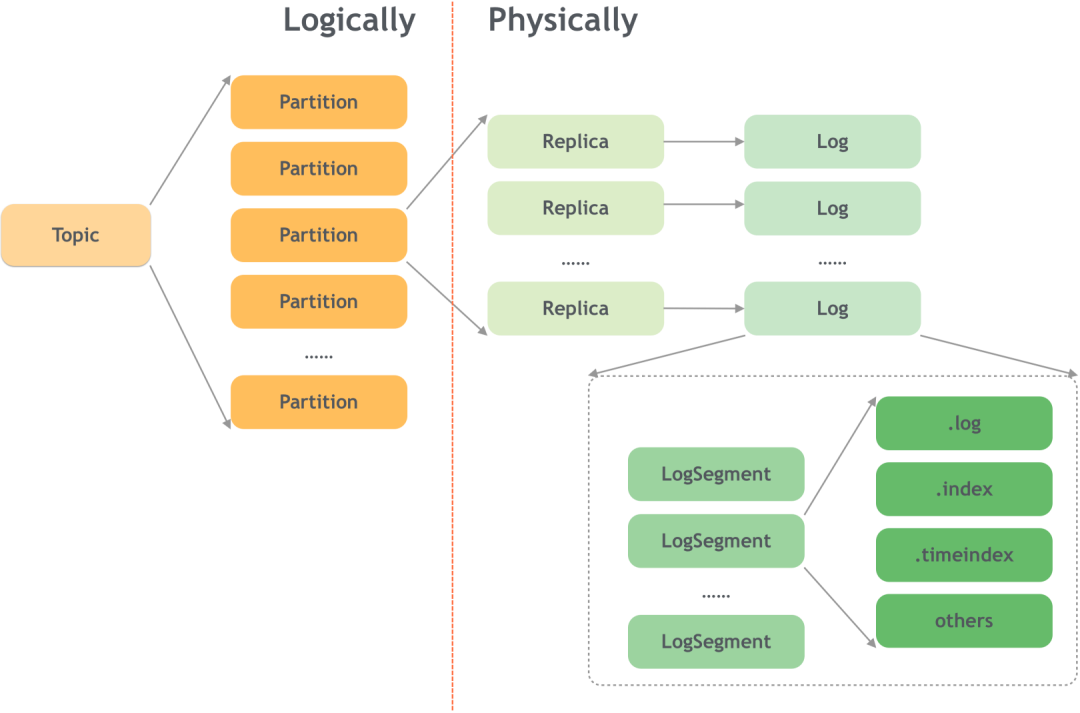
本文使用大模型生成,可能有误,仅作参考使用
1 基本概念
主题(Topic)和分区(Partition)
- 每个主题可以分成多个分区,每个分区在物理上对应一个文件夹。
- 分区是Kafka水平扩展和并行处理的基本单位。
分区目录结构
- 分区在磁盘上表现为一个目录,其命名规则为:<topic_name>-<partition_id>。例如,主题test的第0个分区,其目录名为test-0。
每个分区实际上由多个日志段(LogSegment)组成。日志段是Kafka数据存储的最小单元,包括一个日志文件(存储消息)和两个索引文件(偏移量索引和时间戳索引)。
日志段文件命名
- 日志段文件以该日志段的第一条消息的偏移量(BaseOffset)命名,固定20位数字,不足的用0补齐。例如,第一个日志段文件名为00000000000000000000.log。
2 分区目录示例
text
00000000000000012345.log
↑ ↑
固定20位数字 扩展名
(起始偏移量)
text
/tmp/kafka-logs/
├── topic1-0/ # 主题topic1的第0分区
│ ├── 00000000000000000000.index # 偏移量索引文件
│ ├── 00000000000000000000.log # 数据日志文件
│ ├── 00000000000000000000.timeindex # 时间戳索引文件
│ ├── 00000000000000012345.index
│ ├── 00000000000000012345.log
│ └── leader-epoch-checkpoint # Leader epoch检查点
├── topic1-1/
└── __consumer_offsets-49/ # 消费者偏移量主题分区活跃Segment
- 当前正在写入的Segment称为活跃Segment
- 只有活跃Segment可写,其他Segment只读
3 日志文件(.log)
- 存储实际的消息数据。
- 消息是顺序追加写入的,因此写入性能很高。
消息格式(V2版本,Kafka 0.11.0之后)
日志文件由多条消息组成,每条消息的格式如下:
text
消息批次(RecordBatch):
baseOffset: int64
batchLength: int32
partitionLeaderEpoch: int32
magic: int8 (当前版本为2)
crc: int32
attributes: int16
lastOffsetDelta: int32
baseTimestamp: int64
maxTimestamp: int64
producerId: int64
producerEpoch: int16
baseSequence: int32
消息数组(多条Record): # 消息数组
length: varint
attributes: int8
timestampDelta: varint
offsetDelta: varint
keyLength: varint
key: byte[]
valueLen: varint
value: byte[]
Headers: 可变长度的头部信息消息批次(RecordBatch)
- Kafka将多条消息封装在一个批次中,称为RecordBatch,然后一次性写入日志文件。
- 批次中的消息共享一些公共字段,如baseTimestamp、producerId等,这样可以减少存储空间。
4 偏移量索引文件(.index)
- 用于快速定位消息在.log文件中的物理位置。
- 每个索引条目包含两个字段:相对偏移量(4字节)和物理位置(4字节)。
- 相对偏移量是相对于该日志段基准偏移量(BaseOffset)的差值。
- 物理位置是消息在日志文件中的起始位置。
text
每个索引条目8字节:
offset: int32 # 相对偏移量(相对于该segment的baseOffset)
position: int32 # 在.log文件中的物理位置(字节位置)offset 表示 消息的逻辑序号,position 表示 消息在文件中的字节位置。
- 相对偏移量 = 实际偏移量 - baseOffset
- 实际偏移量 = baseOffset + 相对偏移量
例如,假设日志段的BaseOffset是100,那么偏移量105的索引条目中,相对偏移量为5,物理位置为1050(表示从日志文件的第1050字节开始)。
稀疏索引设计:
- 不是每条消息都有索引
- 每隔log.index.interval.bytes字节(默认4KB)建立一条索引
- 节省空间,查找时使用二分查找
5 时间戳索引文件(.timeindex)
- 用于按时间戳查找消息。
- 每个索引条目包含两个字段:时间戳(8字节)和相对偏移量(4字节)。
- 时间戳是消息的时间戳(可能为创建时间或追加时间,取决于配置)。
- 相对偏移量同样是相对于BaseOffset的差值。
text
每个索引条目12字节:
timestamp: int64 # 时间戳
offset: int32 # 相对偏移量6 日志清理
Kafka提供了两种日志清理策略:
(1)日志删除(Log Retention)
- 基于时间:默认7天,超过即删除。
- 基于大小:日志段文件超过一定大小即删除。
- 基于偏移量:保留最新的数据。
text
log.retention.hours=168 # 保留7天
log.retention.minutes=null # 更细粒度配置
log.retention.ms=null # 毫秒级配置
text
log.retention.bytes=-1 # 无限大小
log.segment.bytes=1073741824 # 每个Segment 1GB(2)日志压缩(Log Compaction)
- 日志压缩在后台由一个专门的压缩线程执行,它会重写日志段文件,只保留每个键的最新消息。
- 对于每个键,只保留最新版本的消息。
- 用于主题的压缩策略,适用于变更日志(changelog)场景。
text
cleanup.policy=compact # 启用压缩
delete.retention.ms=86400000 # 删除标记保留24小时压缩过程:
- 仅保留每个key的最新值
- 创建新的Segment文件
- 删除旧的Segment文件
- 保留墓碑消息(tombstone)一段时间
7 日志段滚动
日志段不会无限增长,当达到一定条件时会滚动创建新的日志段。条件包括:
- 时间:默认7天,即7天后即使当前日志段未满,也会创建新的日志段。
- 大小:当前日志段文件大小超过log.segment.bytes(默认1GB)时,创建新的日志段。
text
# Broker配置
log.segment.bytes=1073741824 # 1GB,Segment大小阈值
log.roll.ms=168 * 60 * 60 * 1000 # 7天,时间阈值
log.roll.hours=168 # 7天,兼容配置8 高效的磁盘利用
8.1 预分配空间
text
log.preallocate=false # 默认不预分配- 预分配可以减少文件碎片,但可能浪费空间
8.2 文件描述符管理
text
num.io.threads=8 # 用于日志读写的工作线程数
num.network.threads=3 # 网络线程数8.3 操作系统优化
text
# 推荐Linux配置
vm.swappiness=1 # 减少交换
fs.file-max=1000000 # 增加文件描述符限制9 存储优化技巧
9.1 选择合适的日志段大小
text
# 权衡:大Segment vs 小Segment
log.segment.bytes=1073741824 # 1GB(推荐)
# 太大:清理不灵活,恢复慢
# 太小:索引文件过多,性能下降9.2 索引密度优化
text
log.index.interval.bytes=4096 # 默认4KB一个索引条目
# 增大 → 索引更稀疏,查找稍慢,空间更省
# 减小 → 索引更密集,查找更快,空间占用更多9.3 批量刷盘
text
log.flush.interval.messages=10000 # 每10000条消息刷盘
log.flush.interval.ms=1000 # 每1秒刷盘
log.flush.scheduler.interval.ms=2000 # 刷盘调度间隔10 故障恢复机制
10.1 恢复检查点
text
leader-epoch-checkpoint 文件内容:
版本号
Leader Epoch数量
[epoch起始偏移量, leader epoch]
示例:
0
2
0 0
1 10010.2 损坏检测与修复
bash
# 使用Kafka工具检查和修复
kafka-run-class.sh kafka.tools.DumpLogSegments \
--files /tmp/kafka-logs/topic-0/00000000000000000000.log \
--print-data-log