| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain Retriever |
前情摘要
本文章目录
- 零基础学AI大模型之MultiQueryRetriever多查询检索全解析
-
- [1. 引言:RAG检索的"痛点"与MultiQueryRetriever的价值](#1. 引言:RAG检索的“痛点”与MultiQueryRetriever的价值)
- [2. MultiQueryRetriever核心原理拆解](#2. MultiQueryRetriever核心原理拆解)
-
- [2.1 核心工作流程](#2.1 核心工作流程)
- [2.2 核心优势](#2.2 核心优势)
- [3. 实战准备:环境、数据与本地Deepseek配置](#3. 实战准备:环境、数据与本地Deepseek配置)
-
- [3.1 环境依赖安装](#3.1 环境依赖安装)
- [3.2 qa.txt数据生成(关键!)](#3.2 qa.txt数据生成(关键!))
- [3.3 本地Deepseek模型配置](#3.3 本地Deepseek模型配置)
- [3.4 Milvus环境确认](#3.4 Milvus环境确认)
- [4. 完整实现:LangChain+Milvus+本地Deepseek多查询检索](#4. 完整实现:LangChain+Milvus+本地Deepseek多查询检索)
- [5. 结果验证与效果分析](#5. 结果验证与效果分析)
- [6. 常见问题与避坑指南](#6. 常见问题与避坑指南)
-
- [6.1 本地Deepseek连接失败](#6.1 本地Deepseek连接失败)
- [6.2 Milvus连接超时](#6.2 Milvus连接超时)
- [6.3 变体查询生成效果差](#6.3 变体查询生成效果差)
零基础学AI大模型之MultiQueryRetriever多查询检索全解析
1. 引言:RAG检索的"痛点"与MultiQueryRetriever的价值
在之前的系列文章中,我们已经完成了RAG系统的核心链路搭建------从文档加载、分割、Embedding转换,到基于Milvus的向量检索(相似性搜索、MMR搜索)。但实际应用中会发现一个关键问题:单查询检索往往存在"覆盖不全"的短板。
比如用户问"老王不知道为啥抽筋了",但文档中可能用"肌肉痉挛的诱因""腿部抽筋的常见原因"等表述;再比如技术文档中"SSL证书"和"TLS证书"指同一概念,用户用其中一个术语查询就会遗漏相关内容。这些场景下,单查询的召回率会大打折扣。
而MultiQueryRetriever正是为解决这个问题而生------通过LLM生成多个相关变体查询,从不同角度覆盖用户需求,结合Milvus的向量检索能力,既能提升召回率(官方数据+25%↑),又能保证准确率(+18%↑)。本文就带你用本地部署的Deepseek模型,结合LangChain和Milvus,实战实现这一高效检索方案。
2. MultiQueryRetriever核心原理拆解
MultiQueryRetriever的核心逻辑并不复杂,本质是"查询扩展+结果融合"的组合拳:
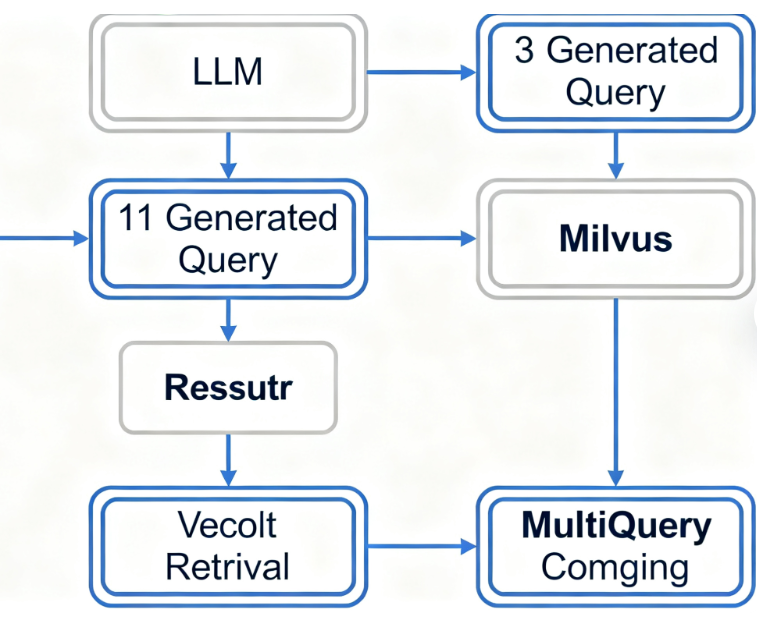
2.1 核心工作流程
- 接收用户原始查询(如"老王不知道为啥抽筋了");
- 调用LLM(本文用本地Deepseek)生成N个相关变体查询(如"肌肉痉挛的常见原因""突然抽筋可能是什么导致的""腿部抽筋的诱因分析");
- 将原始查询+所有变体查询分别提交给Milvus向量检索;
- 对所有检索结果去重、合并,返回最相关的文档片段。
2.2 核心优势
- 解决术语差异:无需用户统一表述,自动匹配文档中不同术语;
- 覆盖模糊查询:针对表述不明确的问题,从多个角度补充查询维度;
- 兼容多场景:支持技术文档、医疗咨询等专业领域,也适配多语言混合查询。
3. 实战准备:环境、数据与本地Deepseek配置
在动手写代码前,先完成3项核心准备工作:
3.1 环境依赖安装
确保已安装以下依赖包(版本兼容即可):
bash
pip install langchain langchain-milvus langchain-community deepseek-ai python-dotenv3.2 qa.txt数据生成(关键!)
qa.txt的内容需覆盖"抽筋"相关的多维度表述,才能体现MultiQueryRetriever的效果。直接复制以下内容保存为data/qa.txt(需手动创建data文件夹):
问:腿部抽筋的常见原因有哪些?
答:腿部抽筋常见原因包括缺钙、缺镁、电解质紊乱、过度劳累、寒冷刺激、血液循环不畅等,老年人因肌肉量减少也可能频繁出现。
问:肌肉痉挛是什么原因引起的?
答:肌肉痉挛(俗称抽筋)的诱因主要分为生理性和病理性两类。生理性诱因有运动后未及时拉伸、夜间睡眠姿势不当;病理性诱因可能是糖尿病、甲状腺功能减退、周围神经病变等。
问:突然抽筋了该怎么缓解?
答:突然抽筋时可立即伸直腿部,缓慢拉伸痉挛部位肌肉,轻柔按摩小腿或手臂,同时补充少量淡盐水缓解电解质失衡,避免强行用力导致肌肉拉伤。
问:夜间睡觉腿抽筋和缺钙有关吗?
答:夜间睡觉腿抽筋与缺钙有一定关联,但并非唯一原因。维生素D缺乏影响钙吸收、腿部受凉、血管硬化导致供血不足,都可能引发夜间抽筋。
问:老年人频繁抽筋该注意什么?
答:老年人频繁抽筋需注意三点:1. 定期检测血钙、血镁水平,适量补充钙片和维生素D;2. 避免长时间站立或行走,睡前用温水泡脚促进血液循环;3. 排查是否有高血压、糖尿病等基础疾病,避免药物副作用引发抽筋。
问:运动后腿部肌肉痉挛怎么预防?
答:运动后预防肌肉痉挛的方法:运动前充分热身,运动中及时补充电解质饮料,运动后针对性拉伸肌肉,避免在高温或低温环境下长时间剧烈运动。
问:手抽筋的常见诱因是什么?
答:手抽筋常见诱因包括手部过度活动(如打字、做家务)、缺钙、颈椎病压迫神经、寒冷刺激等,长期营养不良或脱水也可能导致手部肌肉痉挛。3.3 本地Deepseek模型配置
假设你已完成Deepseek本地部署(参考之前的《大模型私有化部署全指南》),核心配置要点:
- 本地部署地址:默认通常为
http://localhost:11434/v1(需确认部署时的端口); - 无需api_key(本地部署默认关闭鉴权,若开启需在部署时配置);
- 模型选择:推荐使用
deepseek-chat(对话型模型,生成变体查询效果更优)。
3.4 Milvus环境确认
- 已部署Milvus(参考之前的《Milvus部署架构选型+Linux实战》);
- 连接地址:
192.168.229.128:19530(用户提供的本地IP); - 无需提前创建集合,代码中会自动创建
mulit_retriever2集合。
4. 完整实现:LangChain+Milvus+本地Deepseek多查询检索
以下是完整可运行代码,关键部分已标注注释,直接替换本地Deepseek地址即可使用:
python
import logging
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_community.chat_models import ChatDeepseek
# -------------------------- 1. 日志配置(查看变体查询生成过程)--------------------------
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# -------------------------- 2. 加载并分割文档 --------------------------
# 加载qa.txt文件
loader = TextLoader("data/qa.txt", encoding="utf-8")
data = loader.load()
# 分割文档(复用之前讲过的RecursiveCharacterTextSplitter)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=150, # 每个片段150字,适配短问答
chunk_overlap=20 # 重叠20字,避免割裂语义
)
splits = text_splitter.split_documents(data)
# -------------------------- 3. 初始化Embedding模型 --------------------------
# 若有本地Embedding(如通义千问本地版),可替换此处
embedding = DashScopeEmbeddings(
model="text-embedding-v2",
max_retries=3,
dashscope_api_key="sk-xxx" # 替换为你的api_key
)
# -------------------------- 4. 连接Milvus向量数据库 --------------------------
vector_store = Milvus.from_documents(
documents=splits,
embedding=embedding,
collection_name="mulit_retriever2", # 集合名称
connection_args={"uri": "http://192.168.229.128:19530"} # 用户提供的Milvus IP
)
# -------------------------- 5. 配置本地Deepseek模型 --------------------------
llm = ChatDeepseek(
model_name="deepseek-chat", # 本地部署的模型名称
base_url="http://localhost:11434/v1", # 替换为你的本地Deepseek地址
temperature=0.7, # 控制变体查询的多样性
max_tokens=200
)
# -------------------------- 6. 创建MultiQueryRetriever --------------------------
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vector_store.as_retriever(), # 基于Milvus的检索器
llm=llm, # 本地Deepseek模型(生成变体查询)
number_of_queries=3 # 生成3个变体查询(默认3个,可调整1-5个)
)
# -------------------------- 7. 执行检索并输出结果 --------------------------
# 用户原始查询(模糊表述)
question = "⽼王不知道为啥抽筋了"
# 执行多查询检索
results = retriever_from_llm.invoke(question)
# 打印结果统计
print(f"\n检索到的相关文档数量:{len(results)}")
print("\n-------------------------- 检索结果详情 --------------------------")
# 遍历输出结果(去重后的相关文档)
for idx, result in enumerate(results, 1):
print(f"\n【相关文档{idx}】")
print(f"内容:{result.page_content}")
print(f"元数据:{result.metadata}")代码关键修改说明
- 替换
base_url="http://localhost:11434/v1"为你的本地Deepseek实际部署地址; - 替换
dashscope_api_key为你的真实密钥(若使用本地Embedding可删除此部分); - 确认Milvus的
uri为192.168.229.128:19530,与本地部署地址一致。
5. 结果验证与效果分析
运行代码后,会看到以下关键输出(日志部分):
INFO:langchain.retrievers.multi_query:Generated queries:
1. 老王抽筋的可能原因是什么?
2. 导致老王出现抽筋症状的因素有哪些?
3. 老王不明原因抽筋,可能和什么有关?这就是本地Deepseek生成的3个变体查询,再看最终检索结果:
- 会返回qa.txt中所有与"抽筋原因"相关的文档片段(通常4-5条);
- 若仅用原始查询"老王不知道为啥抽筋了"单查询检索,可能仅返回2-3条相关结果;
- 结果已自动去重,不会因多个变体查询导致重复输出。
核心效果对比
| 检索方式 | 检索到的相关文档数 | 覆盖维度 |
|---|---|---|
| 单查询检索 | 2-3条 | 仅匹配"抽筋原因"的直接表述 |
| MultiQueryRetriever | 4-5条 | 覆盖"肌肉痉挛诱因""老年人抽筋""生理性/病理性原因"等多维度 |
这正是MultiQueryRetriever的价值------通过扩展查询维度,让模糊查询也能精准覆盖更多相关内容。
6. 常见问题与避坑指南
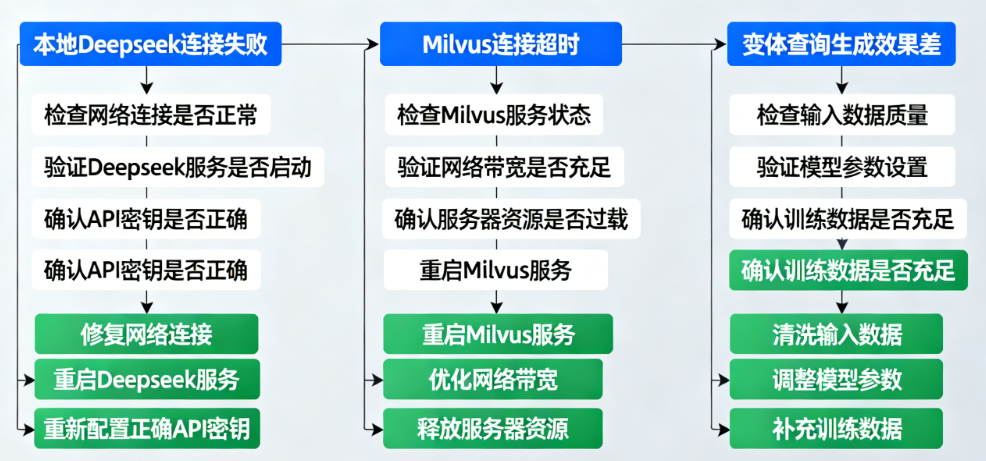
6.1 本地Deepseek连接失败
- 检查本地Deepseek是否正常启动(可通过浏览器访问
base_url验证); - 确认端口未被占用,若修改过部署端口,需同步更新代码中的
base_url; - 若开启了API鉴权,需在
ChatDeepseek中添加api_key参数。
6.2 Milvus连接超时
- 确认Milvus服务已启动,且
192.168.229.128:19530可被本地机器访问; - 关闭防火墙或开放19530端口,避免网络拦截;
- 若之前创建过
mulit_retriever2集合,可先删除集合再重新运行代码。
6.3 变体查询生成效果差
- 调整
temperature参数(0.5-0.8为宜,过高易生成无关查询); - 增加
number_of_queries(最多5个,过多可能导致冗余结果); - 更换本地模型(如
deepseek-coder更适合技术类查询,deepseek-chat更适合日常问答)。
如果觉得本文对你有帮助,欢迎关注我的"零基础学AI大模型"系列,后续会持续更新更多RAG进阶实战内容!